基于特征表示增强的Web API 推荐
2021-10-14段云浩
段云浩,武 浩
(云南大学 信息学院,云南 昆明 650500)
随着服务计算和云计算的快速发展,组合现有的Web 服务应用程序编程接口进行软件开发已经成为一种高效的方法,这使得网络环境中Web API 的数量不断增长[1],对Web API 进行整理并注册登记的生态系统也随之出现. Mashup 是组合多种Web API 进行复合应用创建的技术,该技术极大地释放了开发者的生产力[2]. 但在Web API 数量持续增长的背景下,如何根据开发需求找到契合的Web API 进行Mashup 创建,已经成为了Mashup这一技术需要面对的下一个难题. Web API 推荐便是解决这一问题的重要方向[3]. 多种推荐方法和模型已经被应用于Web API 推荐中,这些方法可以分为基于协同过滤的推荐[4-6]和基于内容的推荐[7-11]. 基于协同过滤的推荐通过计算相似度,对相似用户或物品进行推荐,这类方法专注于发掘需求的相似性,能够共享相似项目的经验,在数据较稀疏的情况下也能够取得一定的效果. 但这类方法没有给予需求本身足够的关注,也就是说,基于协同过滤的推荐方法缺少对Web API 和Mashup之间的需求匹配,单纯基于相似性进行推荐还有可能导致Web API 推荐的冗余. 基于内容的推荐注重对Mashup 创建时功能描述的挖掘,通过建立开发需求与Web API 之间的关系提高推荐的准确性.这类方法重点关注对Mashup 语义特征的挖掘,因而在很大程度上依赖于描述文档. 但是,如果在描述文档中没有提供足够的信息,推荐结果将无法令人满意. 如何从数据出发,提高Web API 推荐的有效性,仍需结合有效的语义表示和深度学习等技术手段不断探索[9].
为了克服现有推荐模型的局限性,本文提出特征表示增强的Web API 推荐模型(Feature Representation Reinforcement Recommendation Model,F3RM). 方法针对Mashup 的描述文档,将描述文档映射至向量空间并利用近邻思想寻找与目标Mashup 相似的近邻Mashup;采用基于神经网络的特征提取模型学习目标Mashup、近邻Mashup 以及交互Web API 的语义特征表示并通过后两者对目标Mashup 语义特征表示进行增强;在增强特征表示基础上建立Mashup 需求到Web API 之间的联系,对Web API 进行筛选,最终将满足需求的Web API 作为面向Mashup 创建的推荐集合.
1 相关工作
Web API 数量的不断增加使得Web API 推荐的研究热度也不断上升. 作为服务计算中的热门话题,Web API 推荐可以采用一般项目推荐中的大部分方法进行,但这并没有考虑到如何将Web API融入到服务组合中,实现重用增值. 现有研究尽管给出了一些解决方法,但对于如何通过深度学习等技术手段完善开发需求与Web API 的匹配机制,提高组合推荐准确性和效果方面需持续探究. 现有方法主要分为两类:一类是基于协同过滤的推荐;另一类基于Mashup 的需求内容进行推荐.
1.1 基于协同过滤的Web API 推荐基于协同过滤的方法通过历史关系来进行预测,又称作基于记忆的方法. 此类方法利用相似信息进行推荐,个体通过合作的机制给予整体一定程度的信息回应,并记录下来以达到过滤的目的. Xia 等[6]基于主题模型对服务描述建模后,以类别为中心对服务聚类,再结合协同过滤对服务的类别进行相关性排名,预测每个类别内的服务排名顺序. Jiang 等[12]通过集成基于用户的个性化算法和基于项目的个性化算法过滤前K个相似用户和服务进行Web API 推荐.Cao 等[13]的方法结合了兴趣值和协同过滤对Web API 进行推荐. 通过将基于用户的协同过滤与基于项目的协同过滤相结合,Zheng 等[14]提出了一种Web 服务质量值预测方法,分析来自类似用户的服务质量信息帮助用户发掘合适的Web API.
1.2 基于内容的Web API 推荐基于内容的推荐对需求进行主题建模,利用需求与Web API 之间的相关性进行推荐,能够较为直接地获取到和需求相近的Web API. Cao 等[10]使用Mashup 服务之间的关系开发两级主题模型,以提高服务聚类的准确性,设计了基于协同过滤的Web API 推荐算法,利用从Mashup 与相应Web API 之间的历史调用推断出的Web API 之间的隐式协同调用关系,为每个Mashup 推荐不同的Web API. Li 等[15]使用关系主题模型对Mashup 和Web API 的标签和主题信息建模,由此计算Web API 之间的相似度和Mashup之间的相似度,使用Web API 的调用时间和类别信息推导它们的流行度,并通过因子机建模多个维度的信息,例如Mashup 和Web API 的相似度,Web API 的流行度等,以预测和推荐目标Mashup对应的Web API.
这些工作已经证明,结合推荐技术可以有效地提高Mashup 应用创建中Web API 筛选的效率. 但这些方法还未将深度学习应用于推荐系统中. 本文方法属于基于内容的Web API 推荐,探索了特征表示增强和深度学习在推荐系统的应用,取得了积极的成果.
2 基于特征表示增强的Web API 推荐
2.1 问题定义为了便于理解,本节给出与Web API 推荐相关的定义.

定义3Web API 推荐指创建一个Mashup 需要调用多个Web API. 通过对Mashup 文档描述dm的利用,依据用户对Mashup 开发的需求,建立开发需求到Web API 之间的关联,实现需求对应的Web API 推荐.
2.2 Web API 推荐流程如 图1 所 示,特 征 表示增强的Web API 推荐主要涉及3 个步骤:近邻Mashup 筛选、特征表示增强和Web API 推荐. 首先,基于目标Mashup 的文档描述的特征找到与其具有较高相似度的近邻Mashup;然后,利用神经网络的高维拟合及特征提取能力,对目标Mashup、近邻Mashup 以及目标Mashup 的类别标签学习得到特征表示,通过线性方法将语义特征表示组合得到增强特征表示;最后,基于增强特征表示计算需求与Web API 的相关程度,生成针对目标Mashup 的前K项Web API 推荐序列.
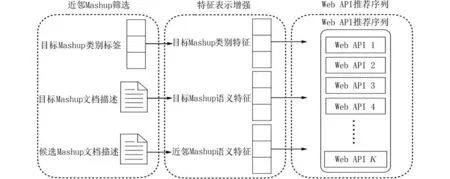
图1 特征表示增强的Web API 推荐流程Fig. 1 Web API recommendation process based on feature representation reinforcement
2.3 近邻Mashup 筛选文档描述相较于其他元数据包含了更加丰富的信息,不论是Mashup、Web API 或是开发需求描述,都是通过文档这一介质承载的. 因此,对Mashup 的文档描述建模和表示技术在基于内容的推荐方法中至关重要. 单个Mashup 或是Web API 文档描述具有的信息是有限的. 从表示增强的角度出发,运用相似Mashup 文档描述和交互API 文档描述对目标Mashup 的文档描述从特征向量的维度进行增强,这里的相似Mashup 即称为近邻Mashup.
合理选取目标Mashup 的近邻Mashup 是首先需 要 解 决 的 问 题. K 最 近 邻(K-Nearest Neighbor,KNN)算法是一个理论成熟的方法. KNN 方法的思路为在特征空间中,如果目标样本附近的K个最近(即特征空间中最邻近)样本的大多数属于某一个类别,则该样本也属于这个类别. 基于KNN 的思路,提出模型结构中的第一部分:近邻选择模块. 该模块选择文档描述在特征空间中的K个最近邻样本作为近邻Mashup,并输出目标Mashup 与近邻Mashup 文档特征.

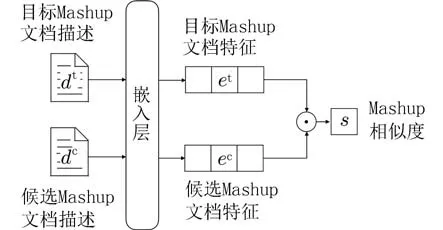
图2 近邻选择模块中的相似度计算Fig. 2 Similarity calculation in neighbor selection module


此时,得到目标Mashup 与任一候选Mashup 相似度. 通过循环完成目标Mashup 对候选集合中所有Mashup 的相似度计算后,选取相似度最高的前K个候选Mashup,K是设定的近邻Mashup 集合数量,即得到目标Mashup 的近邻Mashup. 目标Mashup及近邻Mashup 的文档特征作为近邻选择模块的输出以供下游任务使用.
2.4 特征表示增强传统的建模方法基于“词袋”模型,文本的词序和语法被忽略[17],特征的选择需要在模型中进行人工干预. 随着深度学习的进一步繁荣,人们已经极大地关注了使用深度神经网络来探索文本建模[18]. 由于神经网络模型具有特征选择的能力,可以利用词上下文实现更好的语义表示. 本节基于广泛使用的卷积神经网络[18],提出模型结构中的特征表示增强模块,模块结构如图3所示.

图3 特征表示增强模块Fig. 3 Module of feature representation reinforcement



3 实验和分析
3.1 实验数据集ProgrammableWeb 是一个规模巨大的在线API 生态系统,能够在其中找到超过20 000 个Web API. 这些Web API 覆盖了超过400个频繁被调用的种类,包括社交、音乐、地图等. 本文利用爬虫从ProgrammableWeb 中爬取了22 642个Web API 和8 484 个Mashup. 对于每个Mashup,获得4 种元数据:名称,描述信息,类别信息和Web API 交互信息. 对于每个API,获得3 种元数据:名称、描述和类别信息. 由于缺少上述对应的主要元数据中的1 个或多个,删除了267 个无效的Mashup和124 个无效的API.
经过初步的筛选,本文中的实验数据集包括8 217 个Mashup,1 647 个API,每 个API 至 少 被Mashup 调用了1 次. 其中,每个Mashup 包含平均17 个单词数量的文档描述,每个API 包含44 个单词数量的文档描述,平均每个Mashup 调用了2 个API. 为了进行性能评估,实验中使用留出法将数据集随机分为训练集、验证集和测试集,划分比例为8∶1∶1,分别包括6 573、822 和822 个Mashup.

图4 特征表示增强的Web API 推荐模型Fig. 4 Feature representation model enhanced web API recommendation
3.2 模型设置实验参数的选取直接影响最后的实验结果,包括预训练词向量维度、文档描述截取长度、优化函数、损失函数等. 本文中选取了表1中所示参数作为模型的设置,参数通过多次实验调节得出.
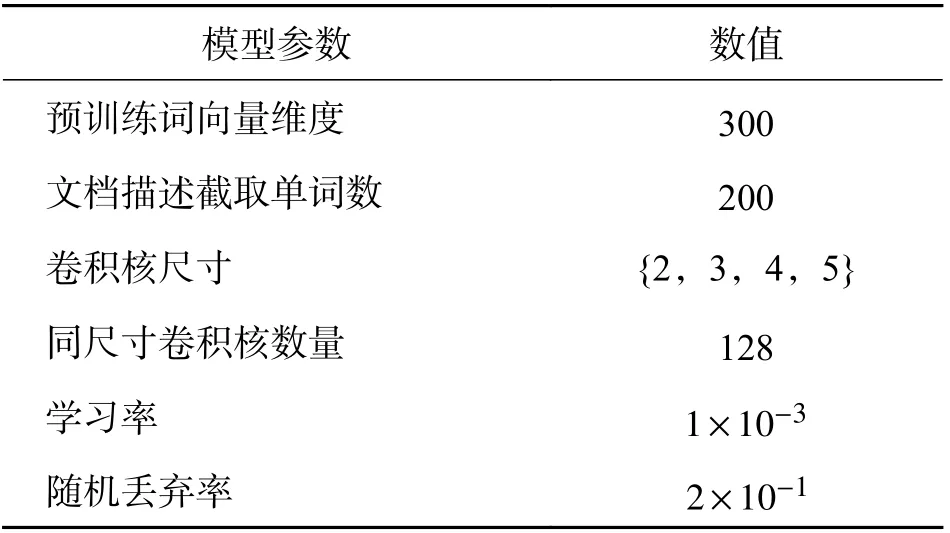
表1 模型超参数设置Tab. 1 Hyper-parameter settings in model
3.3 评估指标针对推荐系统评估研究,王根生等[19]和朱郁筱等[20]从不同的角度总结了评估方法,例如离线评估、用户调查和在线评估. 由于用户调查和在线评估的成本高昂,因此本文通过遵循当前的大多数研究,采用4 个离线评估指标:精准度(Precision)、召回率(Recall)、归一化折损累计增益(Normalized Discounted Cumulative Gain,NDCG)和平均精度均值(Mean Average Precision,MAP).
精度值和召回率是在信息检索和推荐领域中广泛使用的两种评估结果质量的方法. 其中精度值是Web API 推荐中实际匹配次数与推荐API 总数之比,衡量推荐的准确性,定义如下:


3.4.2 神 经 协 同 过 滤( Neural Collaborative Filtering,NCF)[21]神经协同过滤是推荐系统中一种极具竞争性的神经推荐模型. 对于本文中的应用场景而言,使用Glove.6B.300d 预训练词向量对目标Mashup 的文档描述初始化作为特征嵌入,通对Mashup 和Web API 之间交互关系的隐式反馈训练模型.
3.4.3 流行度模型(Popularity-based Recommendation,Pop) 流行度模型直接向用户推荐受欢迎度较高的项目,是推荐系统领域中常用的基准模型之一. 对于Web API 推荐这一任务,将流行度转化为Mashup 的类别出现频率以及Web API 交互频率. 也就是说,出现频率高的类别中的Web API 或交互频率高的Web API,都位于推荐列表的前列.
3.4.4 贝叶斯个性化排序(Bayesian Personalized Ranking,BPR) 贝叶斯个性化排序在推荐系统中广泛用于预测不同项目上的用户偏好. 给定一对Web API (ai/aj), 如果一个Mashupm调用了ai但没有调用aj,那么便得到一个三元组 (m,ai,aj),这意味着ai对于m的排名高于aj. 在本文的场景中,使用Glove.6B.300d 预训练词向量对目标Mashup 的文档描述初始化作为Mashup 的特征嵌入,并通过Mashup 和Web API 之间交互的隐式反馈训练模型.
3.4.5 特 征 表 示 增 强 的Web API 推 荐(Feature Representation Reinforcement Recommendation Model,F3RM) 在实验中,文档单词的截取长度设置为200,采用Glove.6B.300d 预训练词向量对嵌入层进行初始化,维数固定为300,卷积核窗口的大小设置为{2,3,4,5},每种尺寸有128 个卷积核. 使用Adam 作为优化器,学习率设置为 1 ×10-3,损失函数为BCE Loss. 此外,在训练过程中采用早期停止策略预防模型过拟合.
3.5 结果对比分析为验证本文提出方法的有效性,从不同维度将对F3RM 与所选基准方法进行比较. 各模型在4 个性能指标上的实验结果如表2 所示,达到最优性能的模型对应指标进行了标黑处理.

表2 各模型推荐性能比较Tab. 2 Recommendation performance comparison of each model
由于每个Mashup 仅与少量Web API 进行了交互(平均Web API 交互数为2),因此推荐序列的顶部较为关键. 当考虑到前5 名和前10 名的推荐项目时,这种趋势会更加明显. 因此,本文给出了前5 项与前10 项的预测指标评估数据. 通过性能的对比,CF 在各项指标中表现较弱,尤其是在NDCG 和MAP 指标中. CF 使用单词袋模型和向量空间模型来建模Mashup 文档,这使得其无法稳定运行,存在较大波动. NCF 的表现优于CF,NCF 的损失函数与本文模型的损失函数不同,这会导致较大的性能差距. Pop 取得不错的成绩,它的性能优于CF 和NCF. 对于BPR 来说,它是最具有可比性的模型. BPR 的优势在于直接进行排名的优化,在Preciosion@10 一项中取得了不错的成绩. 与所有基准模型相比,F3RM 在几乎所有性能指标上表现明显优于它们. 当N为5~10 时,F3RM 将基线方法的NDCG 提高了24.0%~24.9%,Recall 提高了30.3%~55.3%,MAP 提高了17.1%~20.1%,Precision提高了13.3%.
3.6 实例分析表3 是两个目标Mashup 在不同推荐方法下前3 项Web API 推荐结果. 目标Mashup 分别为Roamoo、Sleevenotes. 它们来自不同的应用类别和领域. 在表3 中,前3 项Web API推荐命中了真实值的Web API 进行了标黑.

表3 Web API 推荐实例分析Tab. 3 Case study on Web API recommendation
Roamoo 是一个具有照片,视频,评论,行程询问和社交网络功能的本地旅行应用. NCF 和BPR在这一实例中前3 项API 推荐没有命中真实值,CF、Pop 和F3RM 取得了良好的成绩,在前3 项API 的推荐中命中了一项.
Sleevenotes 是一个结合了多种媒体源的Mashup,它旨在为音乐爱好者提供高质量的音乐专辑,音乐专辑里不仅包含音乐作品,还有个人简介和其他背景的多种介绍. 该Mashup 以Flickr,Amazon,Music-Brainz 和Wikipedia 为基础. 在这一实例中,大部分模型命中一项达到合格的水平,Pop 没有命中,F3RM 命中了两项,达到优秀的水平.
通过实例分析,验证了所提出模型在Web API推荐这一任务中的有效性,并且超越众多基线对比模型,取得了优秀的成绩.
4 结论
为了解决面向Mashup 创建时Web API 推荐的局限性,本文提出了一种基于增强特征表示提高Web API 推荐准确率的模型F3RM. 该模型首先通过特征表示筛选与目标Mashup 相似的近邻Mashup;然后采用基于神经网络的语义特征提取操作提取目标Mashup、近邻Mashup 语义特征,利用线性方法结合类别标签进行特征表示增强,进行Web API 推荐. 在真实网络环境中数据集上的实验结果表明,F3RM 可以有效地提高Web API 推荐的准确性. 未来,将继续探索Web API 推荐任务中更多的可能性,实现更为高效的推荐.
