基于注意力特征融合的SqueezeNet 细粒度图像分类模型
2021-10-14李明悦何乐生龚友梅
李明悦,何乐生,雷 晨,龚友梅
(云南大学 信息学院,云南 昆明 650500)
细粒度图像分类问题的目标是对子类进行识别,如区分不同种类的狗、鸟、飞机等,是计算机视觉领域一项具有挑战性的研究课题. 细粒度图像分类难点在于子类别间细微的类间差异和较大的内类差异. 传统的分类算法不得不依赖于大量的人工标注信息,但随着深度学习的发展,基于深度卷积特征的算法被大量提出,深度卷积神经网络为细粒度图像分类带来了许多新的机遇,促进了该领域的快速发展.
文献[1]提出的姿态规范化细粒度识别框架,首先使用可变形部件模型通过语义部件的特征点计算物体级别和部件级别的包围盒,然后对语义部位图像块进行姿态对齐操作. 文献[2]提出的Deep LAC 模型将语义部件定位、对齐和分类3 个组件统一到一个卷积神经网络模型中. Zhang 等[3]提出的PS-CNN (Part-Stacked CNN)也是一个利用语义部件进行细粒度分类的框架. Wei等[4]提出的Mask-CNN 框架在细粒度图像语义部件定位和分类方面都取得了较好的结果. 以上的分类方法需要利用物体标注框、部位标注点等额外的人工标注信息. 基于弱监督学习的细粒度图像分类模型能有效克服大量标注带来的成本. 如Lin 等[5]提出的双线性模型,该模型包括两个超分辨率测试序列(Visual Geometry Group,VGG)网络,其中一个VGG 用于定位物体,另一个VGG 用于对定位物体进行特征提取,但一个VGG 网络有近一百多万个参数,使模型计算量变大. 文献[6]提出的用深度残差网络提取细粒度图像的卷积特征,然后挑选强区分性区域,并额外引入了特征金字塔网络强化学习,虽实现了较高的分类准确率,但是网络结构复杂,并且在挑选强区分性区域时增加了网络的计算消耗.
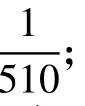
因此,本文提出用轻量级卷积神经网络代替以往细粒度图像分类模型中的特征提取网络. 首先使用在ImageNet 预训练好的3 个典型的轻量级卷积网络在常用的3 个公开的细粒度数据上进行验证,通过对网络的微调得出了3 种轻量级模型的平均识别率、模型参数量、模型内存大小和运行速度,其中SqueezeNet 模型运行速度快、参数最少,使用SqueezeNet 作为特征提取网络能解决现有细粒度算法中模型庞大、结构复杂等问题;然后针对网络分类时存在识别图像判别性特征较差的问题,将Convolution Block Attention Module( CBAM) 和Squeeze-and-Excitation(SE)这两个注意力机制模块嵌入到SqueezeNet 结构中,使改进后的网络自动识别到更具区分的判别性区域;接着将嵌入了注意力机制的Fire4 和Fire8 的特征进行融合得到注意力特征图,与网络最后一层特征图进行双线性融合,提高模型对具有判别性特征的识别能力;最后将本文的模型在3 个训练集上训练至收敛后,最终在测试集上嵌入CBAM 模块的分识别率分别提高了8.96%、4.89%和5.85%,嵌入SE 模块分别提高了9.81%、4.52%、和2.30%. 将本文的模型进一步与InceptionV3[10]等其他细粒度算法进行比较,得出本文提出的模型能达到目前优秀细粒度图像分类算法的识别率的同时,模型内存只有15 MB,参数量只有200 万左右,在性能上有一定的优势.
1 本文方法
本文首先将输入的原始图像进行预处理. 预处理包括将图像裁剪到 448×448 像素,并对裁剪后的图像进行旋转、缩放等几何变换,然后将预处理后的图像送入本文改进后的SqueezeNet 进行特征提取. 为了提升网络对细粒度图像局部判别性区域的识别能力,在原始SqueezeNet 的每个Fire 模块中嵌入注意力机制模块,原始Fire 模块的特征矩阵会经过注意力机制模块并预测出一定的注意区域.注意力机制模块中生成的注意力特征与网络最后一层卷积层输出的全局特征进行双线性融合,以此来增强特征,最后经过Softmax 层进行分类,与Ground Truth 作Loss 计算,使模型不断迭代优化网络. 本文方法的算法总框图如图1 所示.

图1 本文方法总框图Fig. 1 The general block diagram of the method in this paper
1.1 SqueezeNet轻量级卷积神经网络是当前深度学习发展的重要研究方向之一,目的是为了解决如何将神经网络部署到嵌入式设备的问题. 目前主流的轻量级卷积神经网络有SqueezeNet,MobileNet和ShuffleNet 以及它们的变种. MobileNet 采 用了传统网络中的Group 思想,即限制滤波器的卷积计算只针对特定的Group 中的输入降低卷积计算量,提高了移动端前向计算的速度. ShuffleNet 采用了channel shuffle 操作解决信息流通不畅问题,增强了模型的学习能力.
SqueezeNet 最主要的结构就是类似Inception网络结构的Fire 模块(Fire module). 一个Fire module包含一个squeeze 卷积层和一个expand 卷积层,如图2 所示. SqueezeNet 模型首先将3×3 卷积核替换为1×1 卷积核,然后减小输入到3×3 卷积核的输入通道数,尽可能将下采样放在网络后面的层中.SqueezeNet 还采用了平均池化层代替传统卷积神经网络中的全连接层,有效减少了模型的参数. 正是以上的优点,使得SqueezeNet 计算效率提高,Fire 模块也能很好地提高识别性能.

图2 SqueezeNet 网络结构Fig. 2 The network structure of SqueezeNet
1.2 改进 的SqueezeNet在细粒 度图像分 类中,不同类别之间的差异是非常细微的,包含具有判别性的区分信息往往是存在于图像的局部区域中. 例如区分赫里氏带鹀和金帝沙鹀,鸟类专家可能会通过鸟嘴巴的形状、腹部、羽毛的颜色;区分红色奥迪和红色雪弗兰,可能需要通过车牌、车灯样式等;区分两架不同种类的飞机可能需要通过飞机的机头、机尾,甚至是飞机窗口的数量. 因此对于细粒度分类问题,识别到具有区分度的局部特征是至关重要的.
在识别细粒度图像局部细节方面,Lin 等[5]提出的双线性网络(Bilinear-CNN)是最早引入注意力机制的模型,利用2 个相同的卷积神经网络分支关注不同区域的特征,卷积网络A 用于对识别目标的部件进行定位,网络B 用于对网络A 检测到的部件与局部区域的位置进行特征提取,通过向量外积的方式聚合2 个分支的特征得到最后的特征表示. Fu 等提出循环注意力网络(Residual Attention Networks)[11],采用一个编解码结构的注意力模块,对中间特征图通过Enconder-Decoder 方式得到一个3 维的attention map,如下所示:
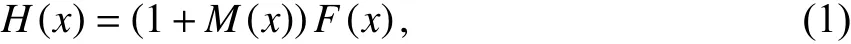
其中,H(x) 表示经过网络分支后输出的特征图,掩膜分支的输出特征图为M(x),F(x) 是由一个深层的卷积神经网络结构来学习拟合,学习的是输出和输入之间的残差结果.
从式(1)可以看出以往细粒度算法中的注意力方法通常是输入特征图的所有通道进行融合. 而本文使用的注意力方式是将注意力机制模块嵌入到原网络的结构中. 本文提出的第1 种嵌入方式是使用CBAM[12],该模块是一个注意模块的前馈卷积神经网络. 为减少计算量,CBAM 不直接计算3 维的attention map,将CBAM 嵌入原SqueezeNet 的每个Fire 模块之后,原始Fire 模块中的特征图会分别经过全局最大池化和全局平均池化,输出两个通道又分别经过多层感知机,将多层感知机输出的特征进行逐元素相加,再用sigmoid 函数激活,生成最终的通道注意力(channel attention)特征图Mc(F),如下所示:
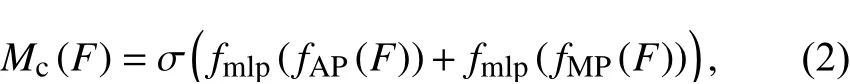

本文提出的第2 种嵌入方式是将SE(Squeezeand-Excitation)模块[13]嵌入到SqueezeNet 的Fire模块,其生成注意力特征的过程如下:
步骤 1 原始Fire 模块层的特征矩阵会经过SE 模块,将一个通道上的空间特征编码为一个全局特征,采用全局平均池化输出该层c个特征图的数值分布情况,如下所示:

其中 ,uc表示第c个通道的特征,FGAP(·) 表示全局平均池化.
步骤 2 采用

sigmoid 形式的门机制让网络学习各个通道间的非线性关系. 其中W是网络的权重,函数g(·) 是池化函数, σ (·)是sigmoid 函数 .
步骤 3 为了降低模型复杂度以及提高泛化能力,采用包含两个全连接的瓶颈(bottleneck)结构将特征降维,降维系数r是超参数,本文将r设为12,然后用ReLU 函数激活,最后将学习到的各个通道的激活值乘以原始特征得到最终的注意力特征图y:

加入SE 结构的注意力机制可以让模型更加关注信息量最大的通道特征,抑制那些不重要的通道特征;CBAM 结构的注意力则是既考虑到不同像素的重要性,又考虑到了同一通道不同位置像素的重要性. 这两种注意力机制模块都可以无缝集成到现有的卷积神经网络里,与网络一起进行端到端的训练,并且只会增加很小的计算消耗. 嵌入注意机制的Fire 模块结构如图3 所示. 图3(a)是在Fire 后嵌入CBAM 模块,是本文的第1 种嵌入方式,图3(b)是本文提出的第2 种嵌入方式. 将原始的SqueezeNet 中的Fire 模块分别替换成由图3 两种方式改进的Fire 模块,使网络整个具有注意力机制,对原始的特征进行权值重标定.
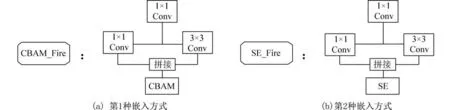
图3 Fire 模块引入注意力机制Fig. 3 The Fire module introduced attention mechanism
1.3 注意力特征融合双线性网络只考虑了最后一层卷积特征作为特征表示,这对于细粒度图像分类来说是不够的,因为中间卷积特征同样包含物体局部特征属性,这使得有利于细粒度图像分类的信息丢失.
如图4 所示,为了增强网络对局部判别性特征的识别能力,本文提出将SqueezeNet 原始的Fire模块替换成基于注意力机制的Fire 模块. 首先将改进后的Fire4 和Fire8 输出的特征提取出来,采用双线性池化的方式得到一个融合后的新的注意力特征图;然后将新的注意力特征图与网络最后输出的全局特征按元素相乘后,得到局部特征图;最后再进行全局平均池化及拼接,得到一个新的张量,作为线性分类层的输入进行分类. 注意力机制融合的具体过程如下:
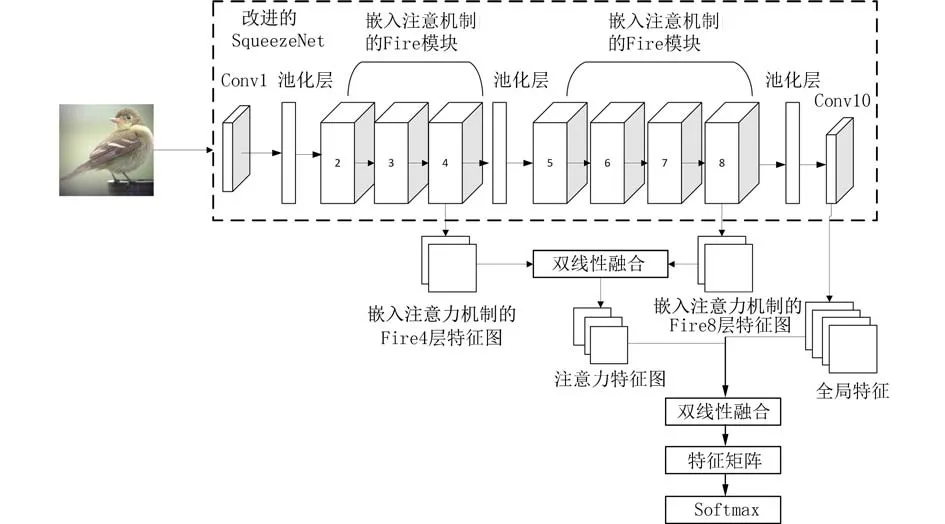
图4 细粒度图像分类网络的总体结构Fig. 4 The overall structure of fine - grained image classification network
步骤 1 首先设Fa1和Fa2分别是带有注意力机制的Fire4 层和带有注意力机制的Fire8 层的输出特征,将特征Fa1的所有通道的值形成一个1×D1的向量ma1, 特征Ca2的所有通道的值形成1×D2的向量ma2,按

计算两个Fire 层融合后的融合特征.
步骤 2 采用全局平均池化或全局最大池化函数对融合特征按公式(5~7)汇聚成一个新的注意力特征:


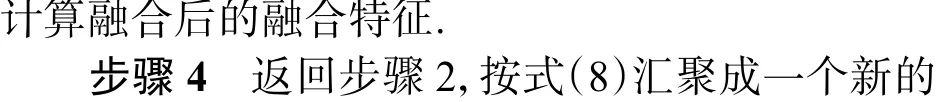

2 实验方法与结果
2.1 实验数据集实验用到的数据集是3 个公开的细粒度数据集. CUB-200-2011 鸟类数据集包括200 种鸟类,其中有5 994 张训练图像和5 794 张测试图像[14]. Stanford Cars 汽车数据集包含196 种车辆,训练集有8 144 张,测试集有8 041 张,关键特征包括车辆制造商、款式、生产日期. FGVC-Aircraft Benchmark 飞机数据集有102 种不同的飞机,一共10 200 张飞机图像[15].
2.2 训练过程和评价指标实验使用Windows 系统和基于Pytorch 框架,在NVIDIA GeForce RTX2080 GPU 上进行.
实验1:先将典型的轻量级卷积神经网络在大规模数据集ImageNet 上进行训练,得到的预训练模型迁移到细粒度数据上继续训练. 预训练网络训练时,先把每张图片缩放到500×500 像素,然后随机裁剪448×448 像素并进行数据增强后输入到网络中,对预训练网络进行微调:采用随机梯度下降(Stochastic Gradient Descent,SGD)对网络进行权值优化更新[16],即每次用一小批样本计算. 根据本文算法中的数据特征,选取学习速率为0.001. 对于ShuffleNet、MobileNet 两个网络采用全连接层分类,SqueezeNet 使用自适应平均池化函数进行分类. 测试时将中心裁剪448×448 像素的图片输入网络中,并对预训练模型进行微调,最后选取网络性能最佳的SqueezeNet 模型进行改进,进一步提高识别率.
实验2:将本文改进的SqueezeNet 模型又一次在细粒度数据集上进行验证. 训练过程中先把每张图片缩放到500×500 像素,然后随机裁剪448×448 像素输入到网络中,每张图像均进行归一化操作,损失函数采用Softmax-Loss,网络权值优化更新依然采用SGD 优化器,经过衰减步长次迭代后更新学习速率 γ 乘以衰减系数 α. 基础学习速率设为0.01,衰减系数设为0.1,动量(momentum)设为0.9,迭代次数设为200 次[17]. 测试时将中心裁剪448×448 像素的图片输入网络中,最后将识别结果与改进前的网络进行对比,并与其他细粒度模型进行网络性能的对比.
本文使用分类准确率、模型参数量、模型内存大小,以及在测试集上消耗的时间作为评价指标.为了实验结果的准确性,采用十折交叉验证(10-fold cross-validation)并取平均值作为最后的结果.
2.3 实验结果分析本文首先使用预训练好的轻量级网络在3 个常用的细粒度数据集上进行实验验证,为了分析网络的性能,将3 种轻量级卷积神经网络在测试集上的识别率、运行时间做了如表1~3 详细的对比,其中运行时间指的是模型在测试集上运行的速度. 参数量和模型内存大小的对比如图5 所示.
从表1~3 的结果中可以看出,轻量级卷积神经网络也可以用于细粒度图像的分类识别,而且SqueezeNet 在飞机类和汽车类数据测试集上的运行时间都在30 s 以内,网络运行效率更快. 从图5可以看出,SqueezeNet 网络相比于其他两种轻量级卷积网络,以及相较于如VGG、ResNet 这种传统的深度卷积神经网络都具有模型性能上的优势,只有约100 万个参数,模型大小也是最轻量的. 但未改进的SqueezeNet 在细粒度数据集上的分类准确率还比较低,这是因为细粒度的分类难点在于具有判别性的特征存在于图像的局部细节中,直接使用典型的卷积网络不能较好地克服这个难点,因此本文的第2 个实验将模型性能较好的SqueezeNet进行改进,在原网络的Fire 模块中嵌入了两种注意力机制模块,第1 次嵌入CBAM 注意力模块,第2次嵌入SE 模块,将改进后的网络在3 个细粒度数据集上进行实验验证和对比.
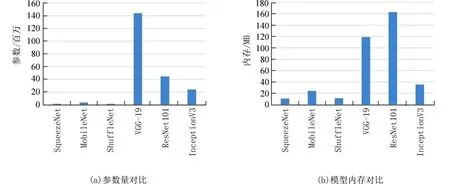
图5 网络参数量和内存对比Fig. 5 Network performance comparison on parameters and memory
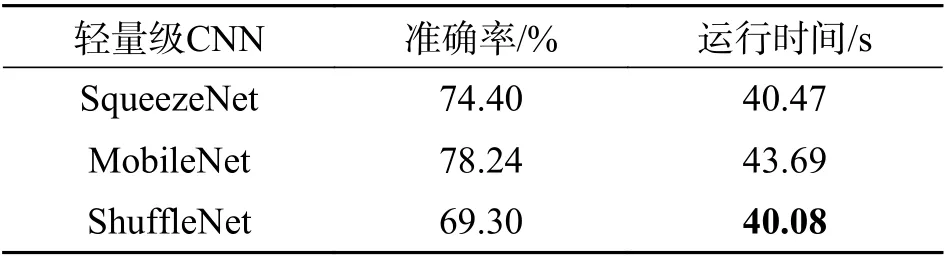
表1 CUB-200-2011 实验结果Tab. 1 Experimental results of CUB-200-2011
表4 展现了网络模型改进前后在3 个数据集的测试集上分类准确率的结果比较. 改进后的SqueezeNet 细粒度图像分类模型,由于对原始SqueezeNet 网络进行了注意力模块的嵌入,让模型能够定位到更具有判别性的局部区域. 受双线性模型的启发,对注意力模块的特征进行了双线性融合,增强了对图像特征的识别能力. 因此,因此改进后的模型在鸟类、飞机类和汽车类数据集上取得了相对较好的效果,嵌入CBAM 模块,准确率在3 个数据集上依次提高了8.96%、4.89%、5.85%;嵌入SE 模块,准确率依次提高了9.81%、4.52%、2.30%.图6 的热力图效果对比展示了SqueezeNet 网络嵌入注意力机制后,模型能更加集中到目标对象更具有判别力的区域. 如图6 第1 列对鸟的识别中,原网络能识别到鸟的整个躯体,但加入注意力机制后,CBAM 模块能帮助网络定位到鸟尾部区域,SE 模块能定位到尾部和头部眼睛的区域;第2 列对汽车识别中,嵌入的CBAM 模块能帮助模型更好地识别到车灯上;在飞机识别中,两个注意力机制模块不仅增强了模型对机头、机尾的识别能力,CBAM模块还能识别到飞机的机翼部分,体现了本文的改进方法能够提高模型强化注意力特征区域的能力,而特征融合也能进一步增强图像的特征,提高模型对特征的识别能力.

图6 注意力机制嵌入效果对比Fig. 6 The effects comparison of the attention embeddingmechanism
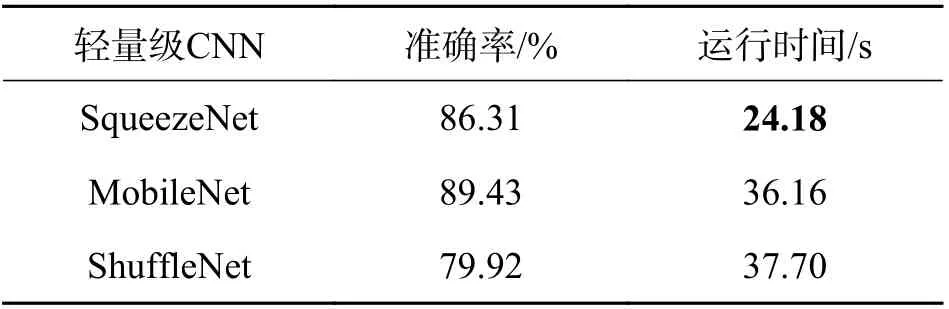
表2 Stanford Cars 实验结果Tab. 2 Experimental results of Stanford Cars
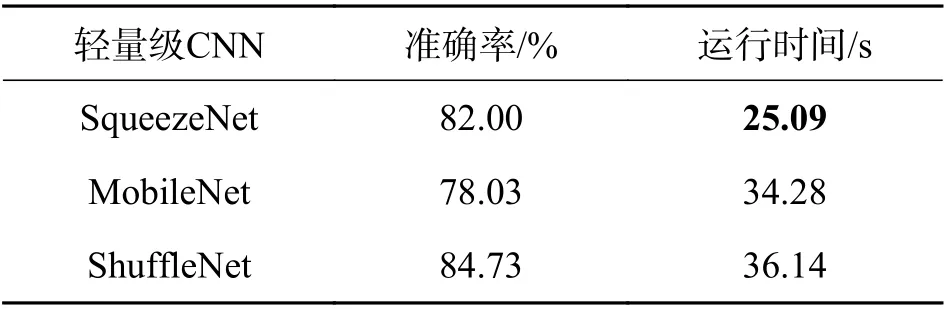
表3 FGVC-Aircraft Benchmark 实验结果Tab. 3 Experimental results of FGVC-Aircraft
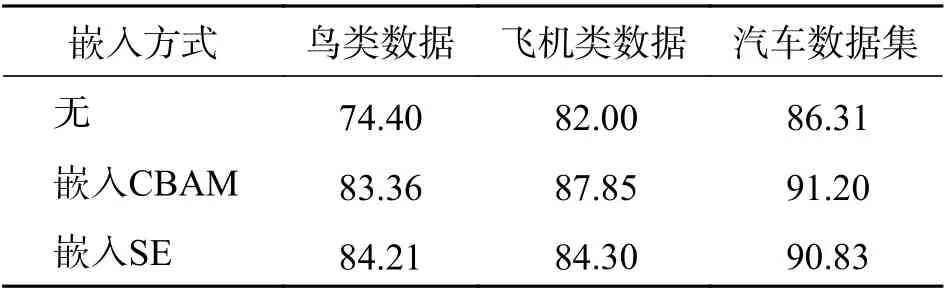
表4 改进前后模型的准确率对比Tab. 4 Comparison of the model accuracy before and after improvement %
表5 是不同的细粒度图像分类算法在3 个细粒度数据集上分类准确率的结果比较. 从表5 可以看出,本文提出的嵌入注意力机制模块和特征融合的SqueezeNet 细粒度图像分类模型,在3 个细粒度数据集上的识别准确率上取得了相对较好的分类准确率. 其中,嵌入CBAM 模块和特征融合后,模型在鸟类、汽车类、飞机类数据上的准确率分别达到了83.36%、91.20%、87.85%;嵌入SE 模块,模型的分类准确率分别是84.21%、90.83%、84.30%,均高于VGG-19 网络,并且本文提出的基于注意力特征融合的SqueezeNet 模型在与其他深度网络的识别率相当的情况下,改进后的模型内存大小只有15 MB,只是IinceptionV3 网络的

表5 各模型的实验结果对比Tab. 5 The experimental results comparison of each model
3 结束语
本文首先提出使用3 种典型的轻量级卷积神经网络用于细粒度图像分类,并进行了两次实验.实验1 通过对预训练的网络模型进行微调,得出轻量级网络能用于细粒度图像分类,并且选择了模型参数、内存大小和运行速度都比其他神经网络更有优势的SqueezeNet 作为图像特征提取网络,可以解决现有细粒度图像分类算法用传统较深的卷积网络识别时带来的参数多、模型庞大等问题. 针对细粒度识别的难点进行改进,在原SqueezeNet结构中嵌入了两种注意力机制模块,增强网络对识别对象的局部判别性区域的能力,并将嵌入注意力机制的网络的中间层输出的特征图与网络的最后一层输出的特征图进行特征融合,全局平均池化后分类. 实验结果证明了改进后的网络相比于改进前的网络,其准确率有了明显的提高,并且与其他细粒度算法相比,本文提出的细粒度分类模型大小只有15 MB,属于较轻量的分类模型,未来的研究方向将考虑用目标检测中多尺度[20]的方法,提高网络的特征提取能力.
