基于DBSCAN的自适应聚类算法的研究与实现
2021-10-11陈小辉奚庆港
陈小辉, 奚庆港
(淮阴师范学院 计算机科学与技术学院, 江苏 淮安 223300)
0 引言
聚类算法是数据挖掘中的一种技术,而数据挖掘是从一堆数据中挖掘知识[1].聚类分析目前已经被广泛地应用于图像识别、生物学等领域.DBSCAN算法(Density-Based Spatial Clustering of Applicotions with Noise)的优点在于不仅可以发现任意形状的簇,还可以发现噪音点和离群点.由于该算法使用两个全局的参数,使得针对变密度数据集时聚类的效果并不出色,其原因在于DBSCAN算法对两个参数过于敏感且两个参数全局通用,而全局通用的参数较多时候需要人工判别.因此,一些学者针对自适应参数的 DBSCAN 算法进行了研究.Yue等[2]提出一种基于数据统计信息确定Eps参数的算法,通过该算法可以在更广的范围内搜索Eps参数,但是该算法中MinPts参数恒定设置为4的时候,也不能较准确地反映数据集的分布特性. 周红芳等[3]提出了I-DBSCAN(Improved Density-Based spatial Clustering of Applicotions with Noise)自适应聚类算法,利用聚类个数和噪声点个数的趋势作为聚类结果判别,寻找趋势稳定点处所对应的Eps和MinPts参数.但I-DBSCAN自适应聚类算法不足之处还需要人为进行判别.
本文针对DBSCAN算法对密度不同的数据集、符号型数据集聚类效果较差的不足,引入了对象密度的概念和统计学分析方法,得出Eps与MinPts的关系,通过最小二乘法进行函数拟合得到一条曲线,由曲线找到和核心点相近的对象,将其纳入簇内,随后进行不断遍历,最后实现聚类.实验结果表明,改进后的算法与DBSCAN算法及K-MEANS算法相比,对符号型数据集和数值型密度不均匀数据集聚类的效果更优.
1 DBSCAN算法概述
1.1 算法介绍
DBSCAN算法是典型的基于密度聚类算法,不仅能够判定各种形状的簇,还能通过两个参数识别数据集中的各个类以及判别噪声点.
1.2 算法的定义
DBSCAN算法需要用户输入两个参数Eps(半径)和MinPts(最少样本数目)[4].DBSCAN对于核对象的定义是在给定的Eps内包含MinPts个或以上个对象,即在该对象一定的邻域内的样本要超过一定的阈值.相关定义如下:
定义1(核对象) 一个样本p以Eps为半径的圆内的有超过一定数目(≥MinPts)的样本,则样本p称为核对象.
定义2(邻域ε) 领域内的点定义为NEps(p)={q∈D,dist(p,q)≤Eps},其中D代表数据集中所有对象,dist(p,q)代表样本p与样本q两者之间的距离.
定义3(直接密度可达) 在数据集D中,对象q在另一个对象p的Eps邻域内,且对象p为核对象的情况下,则称对象q从对象p直接密度可达.
定义4(密度可达) 在数据集D中,存在p1,p2,p3,…,pn,1≤i≤n,对于pi∈D,且pi是从pi-1的直接密度直达,则点pn从p1密度可达.
定义5(密度相连) 若存在一个对象o,使得对象p和q都从o密度可达,则称对象p和对象q密度相连.
1.3 算法的实现
DBSCAN算法流程[5]如下:
输入:数据集U,MinPts,Eps,
输出:各个不相交的簇.
Step 1: 从任一未访问过的样本开始并以这个样本为中心,判断是否为核心对象.若是核心对象则创建一个新类C,并将其邻域内的样本纳入到类C内;
Step 2: 在C内寻找其他未被访问的样本,若该样本为核对象,则将其邻域内所有样本纳入簇中;
Step 3: 重复Step 2直到簇C中不再增加新样本;
Step 4: 重复Step 1,2,3,直到所有对象都被归类.
1.4 相似度衡量
在聚类分析中,样本之间的相似度衡量是一个重要的研究点[6],对数据集采用合适的度量方法至关重要.相似度衡量常用距离度量,主要有欧氏距离、闵可夫斯基距离、曼哈顿距离、切比雪夫距离等.
1) 欧氏距离
在二维或三维空间中欧氏距离就是指两点之间的实际距离.在N维空间中,计算公式为
(1)
2) 闵可夫斯基距离
闵可夫斯基距离是一组距离的定义,计算公式为
(2)
当p=1时,该距离转化为曼哈顿距离.当p=2时,计算结果转化为欧氏距离.当p趋向于无穷时,即为切比雪夫距离.
1.5 评价指标
聚类算法的评价指标[7]又被称作“有效性指标”(validity index).为了对聚类的结果进行分析,需要借助聚类有效性评价法评估其聚类质量的优劣.
1) 调整兰德指数[8]
调整兰德指数(ARI)是用来衡量聚类效果的一个指标,该指标不会随着聚类标签的变化而变化,当真实标签为[0,0,1,1,2,2],预测标签为[0,0,2,2,1,1]或者[1,1,2,2,0,0]时,ARI的值是不变的. ARI取值为-1~1.兰德指数和调整兰德指数(R)定义分别如下:
(3)
其中n为样本总数.
(4)
2)V-Measure
V-Measure是同质性和完整性两者的调和平均.同质性和完整性的计算公式分别为
(5)
(6)
两者的调和平均V-Measure公式为
(7)
3) AMI(Adjust Mutual information)
调整互信息主要是用来衡量两个数据的分布程度.AMI的取值范围介于-1与1之间.AMI越大,说明结果和真实情况吻合度越高.互信息和调整互信息的定义为
(8)
(9)
2 改进的IDBSCAN算法
2.1 符号属性数据集的距离度量标准
在传统数值型的聚类算法中,两个样本之间的距离度量通常采用欧氏距离.针对符号属性的数据集使用式(10)作为距离计算方法.设数据集X有n个样本x1,x2,x3,…,xn.每个样本有A个特征,分别记为a1,a2,…,aA且这些特征均为符号属性.
每个样本之间的距离度量定义为
(10)
其中
(11)
通过该定义易得两个样本之间的距离.假设样本x1(a,b,c,d),样本x2(a,a,c,d),则x1和x2之间的距离为1.
2.2 样本的对象密度概念
当样本对象密度越大,该样本周边聚集的点就越多,反之该样本周边聚集的点就越少.
1) 数值型数据集的对象密度概念
假设数据集X是一个数值型数据集.对于数据集中的每个样本的对象密度可以定义为
(12)
其中A为属性集合.
2) 符号数据集的对象密度概念[9].
假设数据集U是符号数据集.定义数据集中的每个样本的对象密度为
(13)
显然,上述定义对象密度值最大值为0,最小值为-A,即
-|A|≤Dens(x)≤0
(14)
2.3 通过统计学概念寻找相似样本的方法
通过式(10)~(13)可得到样本间距离和样本的对象密度.对于每一个样本引入统计学的方法来寻找与相似样本.对于某一个样本xp,当取定样本有关的MinPts值时,其相应的Eps值可得,即该样本有关的Eps与MinPts.依照数据集的统计特性可以绘制出Eps与MinPts之间关系的图像.
数据集中样本的Eps与MinPts之间的变化关系如图1所示.从图1中可以看出Eps与MinPts之间存在某种变化关系,此时引入最小二乘法[10]进行曲线拟合,通过最小化误差平方和的方法来寻找与原始数据分布最为匹配的函数. 最小二乘法的计算公式为
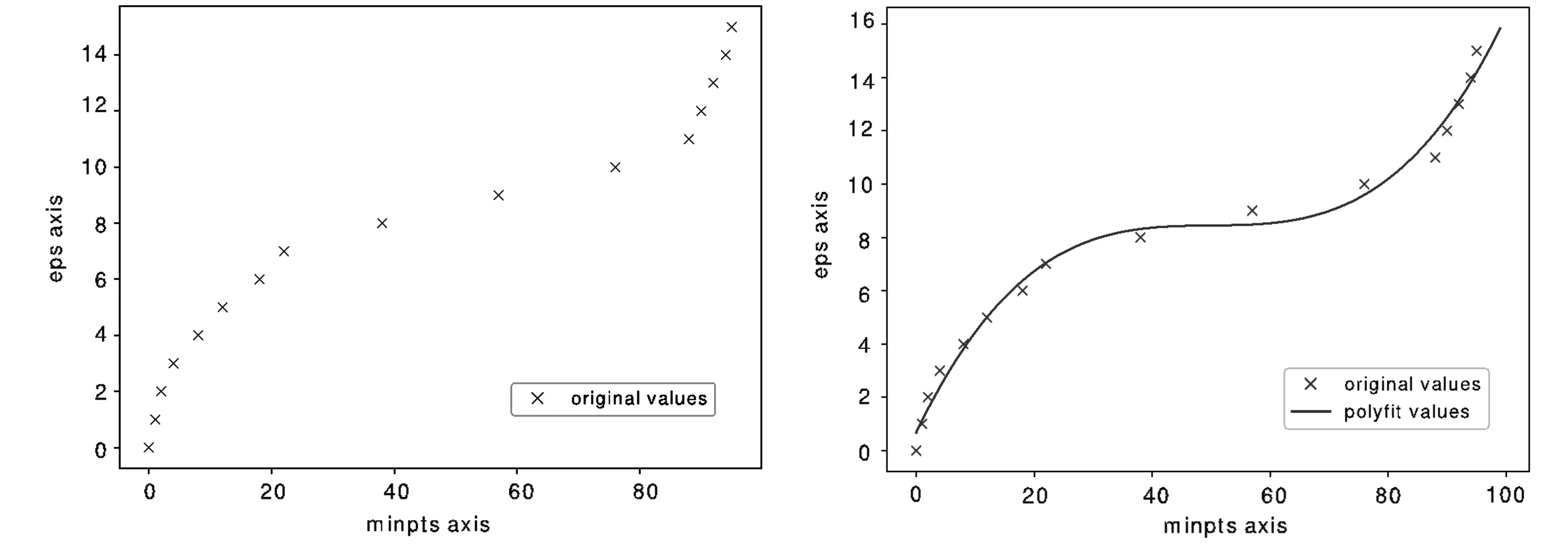
图1 MinPts与Eps变化图 图2 三次函数进行拟合
(15)
对图1中数据引入最小二乘法进行多项式的拟合.使用三次函数进行拟合的情况如图2所示;使用高次函数进行拟合的情况如图3所示. 由图2可知,在MinPts与Eps两者数据的拟合中,当函数次数过低时,拟合效果一般.因此将采用高次函数进行拟合.图2和图3的函数拟合曲线中存在拐点,通过拟合的曲线可找到了Eps与MinPts之间的函数关系.由图2和图3可知,使用高次函数进行函数拟合出现有多个拐点的情况,与数据集存在多个不同密度簇的情况一致.
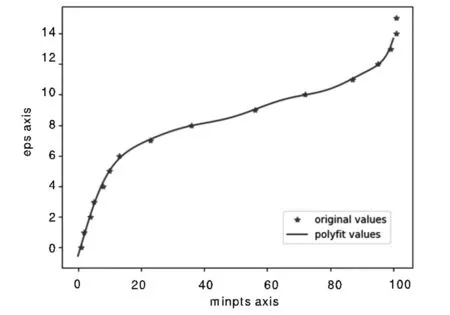
图3 高次函数进行拟合
经过实验可知,选择三次函数进行拟合的结果比较符合数据分布规律,同时较容易找到三次函数拟合曲线第1个拐点及该拐点处的对应Eps与MinPts的值.与数据统计特性相对应,在第1个拐点的左侧样本与核心目标对象更为相近,左侧目标与核心目标对象可以被分为一类.拐点右侧的样本与核心目标对象相对较远,不归属于核心目标对象所在类.
2.4 算法改进
依照上述内容,设计改进Improved DBSCAN算法,其实现流程如下:
1) 对于符号属性的数据集,通过式(10)计算样本之间的距离.针对数值型数据集,通过欧氏距离计算样本间的距离;
2) 通过式(12)和式(13)计算数据集中各个样本的对象密度,按各个样本的对象密度从大到小进行排序并将所有样本标记为未访问;
3) 开始依照样本的密度从大到小开始访问.首先访问密度最高的样本,将该样本作为核心对象,设置该样本为当前样本.接着从当前样本出发,分析样本的分布规律,通过最小二乘法进行函数拟合Eps与MinPts的关系,进而在曲线拐点处获得对应位置的Eps与MinPts的值.由此得到与该核心点相近的对象,将其纳入簇内,并将簇内的样本均标记为已访问;
4) 依照密度排序,查找下一个未被访问的样本,不断重复上述过程直到所有点样本均被访问.然后,找到两个具有公共点的簇进行合并,得到一个新的簇.最后得到若干个无公共交点的簇,即聚类结果.
给出的改进型DBSCAN算法流程如下:
输入: 数据集U,
输出: 各个不相交的簇.
Step 1: 计算各个样本的对象密度;
Step 2: 将各个样本以对象密度从大到小排序,并标记为未访问;
Step 3: 依据对象密度依次访问未访问过的样本,通过文中方法获取与当前样本有关的Eps与Minpts的值作为参数,并将该样本周边的样本纳入到簇内,将簇内的样本标记为已访问;
Step 4: 不断重复Step 3直到所有样本均已为访问;
Step 5: 进行相交簇的合并.
3 实验结果与分析
为了验证改进后的算法进行聚类的有效性,将其与两种经典的K-means、DBSCAN算法的聚类算法进行比较.使用若干个不同密度的仿真数据集和真实数据集对此3种算法进行比较.K-means算法只需要1个参数K,该参数K代表了聚类结果的簇的个数. DBSCAN算法需要两个参数,分别为Eps与MinPts. 在本实验中,Eps取值通常根据数据集本身的情况进行分配,MinPts的取值通常为数据集个数除以25.对于改进算法IDBSCAN,是自适应算法的不需要参数.
实验环境:macOS Mojave 版本10.14.3; 处理器2.6 GHz Intel Core i7; 内存16GB 2400 MHzDDR4; 图形卡RadeonPro 560X 4096MB.开发语言:Python.Python作为一种高级语言有跨平台性等优点.集成开发环境:PyCharm.
3.1 数值型数据集的实验分析
密度分布不均匀的数值型仿真数据集实验情况如图4所示. 从图4和表1~3可以看出,数据集由1个高密度簇和1个低密度簇组成.由于DBSCAN算法对两个参数的选择较敏感,而且不能对密度不均匀的数据集进行有效聚类.究其原因在于DBSCAN使用一组全局的Eps和MinPts参数进行聚类分析,因此聚类效果较差.K-means算法输入正确的簇数后,该算法对于边角的数据点未能够进行有效的分类.而对于基于DBSCAN改进后的算法IDBSCAN能够根据簇的密度进行自适应聚类.因此,针对密度不均的数据集时表现较好.

表1 数据集属性

表2 算法参数
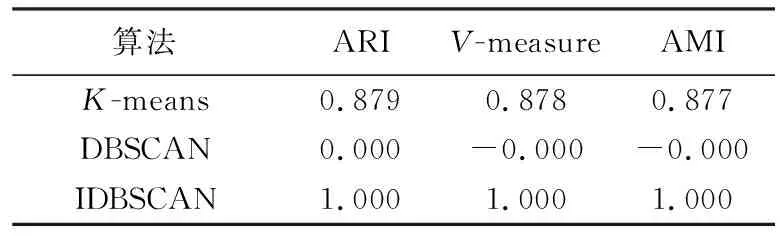
表3 算法性能

表4 数据集属性
3.2 符号型数据集的实验分析
该数据集是符号型真实数据集Soybean(大豆),共有46个样本,35个特征,4个簇.该数据集的特征值均为符号属性.通过表5和表6可知,DBSCAN对该数据集聚类的效果较差,K-means算法在某些重叠相似的样本上聚类效果也较差,而改进后的算法对大豆数据集聚类效果较好.

表5 算法参数
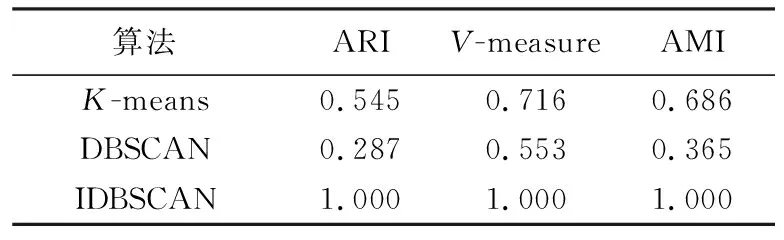
表6 算法性能
4 结论
DBSCAN算法作为一种经典的基于密度的聚类算法,通过两个全局的参数Eps与MinPts进行聚类. 由于DBSCAN使用全局的参数进行聚类分析,导致在处理非均匀密度数值型和符号型数据集时效果并不理想.因此,本文针对这种情况提出了一种基于DBSCAN的自适应聚类算法.该算法先引入了一个对象密度的概念,通过密度概念计算出每个样本的密度,提出一种基于统计学自适应寻找Eps与MinPts两个参数的方法.该方法通过引入最小二乘法的概念,对某一样本的Eps与MinPts的关系进行函数拟合,再通过计算这个函数的拐点来寻找Eps与MinPts两个参数.改进后的算法能够自适应的进行聚类. 为了评估改进后算法的性能,采用了若干个仿真和真实数据集进行聚类分析.实验结果表明,改进后的算法在处理非均匀密度数值型数据集和符号型数据集进行聚类分析时效果较好.
