超重及肥胖人群高尿酸血症发病风险预测模型的构建及评价
2021-10-11李禄伟黄倩施佳成刘晓玲王彩梅于萍吴岚覃洋江仁美于健
李禄伟 黄倩 施佳成 刘晓玲 王彩梅 于萍 吴岚 覃洋 江仁美 于健
桂林医学院附属医院1内分泌科,2检验科,3神经内科(广西桂林541001)
高尿酸血症是人体中由于各种病理机制导致尿酸生成增多或排泄障碍所引起的一种代谢性疾病。高尿酸血症在各个国家中均呈现高患病率[1],相关研究显示中国高尿酸血症的人群患病率为17.4%,痛风为1.1%[2-3]。大量研究证据表明高尿酸血症与心脑血管疾病的发生发展密切相关,是心肌梗死、中风等疾病的独立危险因素[4]。此前对10 项前瞻性研究的荟萃分析显示[5],BMI 每增加5 kg/m2,痛风风险就会增加55%,提示超重及肥胖人群本身便是高尿酸血症的重点发病人群[6-8]。减肥举措将有助于改善高尿酸血症[9],因此在超重及肥胖人群中进行高尿酸血症方面研究很有必要。本研究旨在通过在超重及肥胖人群中筛选出易患高尿酸血症的影响因素,并构建分类树和列线图两种预测模型,使用列线图对经分类树及logistic 回归筛选出的影响因素进行量化分析,采用三种验证方法对模型进行评估,从而为相关人群预防及控制高尿酸血症等提供参考,对于避免疾病发作具有一定的意义[10]。
1 资料与方法
1.1 研究对象在2019年8月1日至11月1日于桂林医学院附属医院进行健康体检的体检人群中,筛选出超重及肥胖者作为研究对象。调查对象均已知情同意。纳入标准:BMI ≥24 kg/m2;年龄≥18岁;自愿加入研究者。排除标准:妊娠期妇女;患有恶性肿瘤等重大疾病人群;严重肝肾功能不全者(肾功能不全达到尿毒症期,转氨酶超过正常上限3 倍以上);临床资料不全者。纳入研究共有5 098 例超重及肥胖者。研究对象年龄范围18 ~85岁,平均年龄(44.92±11.75)岁,随机抽取3 582例(70%)超重及肥胖者构建建模组,剩余1 516 例(30%)构建验证组进行内部验证。以有无高尿酸血症将超重及肥胖人群分为病例组和对照组。
1.2 问卷调查一般情况:姓名、性别、年龄,既往史:特殊用药史、疾病史。
1.3 体格测量体检工作人员采用经过校对的身高体重仪,测量研究对象身高体质量,计算体质指数(BMI),BMI=体质量(kg)/身高(m2)。安静休息5~10 min 后,测量右上臂肱动脉血压。
1.4 实验室检查所有受检者检查当天清晨空腹采集肘静脉血(5 mL)。使用生化分析仪检测:肌酐(Cr)、尿素氮(BUN)、空腹血糖(FPG)、总胆固醇(TC)、甘油三酯(TG)、高密度脂蛋白胆固醇(HDL⁃c)、低密度脂蛋白胆固醇(LDL⁃c)。
1.5 诊断标准高尿酸血症的诊断标准[11]定义:非同日2次血尿酸水平超过420 μmol/L。将体检人群体质量指数≥24 kg/m2定义为超重及肥胖人群[12]。高血压的诊断标准[13]:收缩压≥140 mmHg 和(或)舒张压≥90 mmHg。血脂异常诊断标准为以下任一项[14]:总胆固醇≥6.2 mmol/L;甘油三酯≥2.3 mmol/L;LDL⁃c ≥4.1 mmol/L;HDL⁃c<1.0 mmol/L。血糖异常诊断标准[15]为空腹血糖≥6.1 mmol/L。空腹血尿素氮≥7.1 mmol/L 为高尿素氮血症,空腹血肌酐水平:男性≥110 μmol/L,女性≥93 μmol/L 为高肌酐血症。
1.6 统计学方法所有数据使用Excel 2007 进行收集整理,使用SPSS 26.0、Rx64 4.0.3 进行统计分析,符合正态分布的计量资料以均值±标准差表示,组间比较行t检验;计数资料表示为例(%),组间比较行χ2检验。同时分别建立超重及肥胖人群高尿酸血症发病的分类树模型和列线图模型,进行内部验证,最后绘制受试者工作特征(ROC)曲线、决策分析曲线(DCA)、临床影响曲线(CIC)对两种模型进行评估,以P<0.05为差异有统计学意义。
2 结果
2.1 病例组和对照组临床与代谢特征的比较训练集和验证集中病例组患者的TG、Cr 水平高于对照组,而年龄、HDL⁃c 水平低于对照组,差异有统计学意义(P<0.05)。训练集和验证集参与者具有相似的临床特征,见表1。
表1 训练集及验证集病例组和对照组临床与代谢特征的比较Tab.1 comparison of clinical and metabolic characteristics between case group and control group in training set and validation set±s

表1 训练集及验证集病例组和对照组临床与代谢特征的比较Tab.1 comparison of clinical and metabolic characteristics between case group and control group in training set and validation set±s
变量年龄(岁)性别(男/女)高血压(有/无)Cr(μmol/L)BUN(mmol/L)TG(mmol/L)TC(mmol/L)LDL⁃c(mmol/L)HDL⁃c(mmol/L)FPG(mmol/L)训练集(n=3 582)对照组(n=2 295)45.57±11.34 1 328/967 514/1781 75.56±15.02 4.54±1.18 1.66±1.14 4.70±0.82 3.18±0.78 1.22±0.30 5.53±1.29病例组(n=1 287)43.54±12.34 1 199/88 376/911 88.85±16.62 4.78±1.22 2.31±1.41 4.83±0.86 3.27±0.81 1.07±0.25 5.52±1.02 t/χ2值⁃4.97 494.44 20.53 24.46 5.58 15.13 4.41 3.29⁃15.92⁃0.14 P 值<0.001<0.001 0.021<0.001 0.976<0.001 0.408 0.401<0.001 0.082验证集(n=1 516)对照组(n=969)45.69±11.49 566/403 226/743 75.567±14.71 4.52±1.13 1.71±1.21 4.71±0.81 3.17±0.77 1.21±0.30 5.45±1.21病例组(n=547)44.02±12.20 516/31 161/386 89.35±16.18 4.76±1.32 2.34±1.50 4.82±0.84 3.24±0.80 1.09±0.26 5.43±0.95 t/χ2值-2.66 220.80 6.86 16.89 3.73 8.84 2.61 1.66-8.03-0.36 P 值0.011<0.001 0.009 0.010 0.508<0.001 0.231 0.266<0.001 0.147
2.2 构建分类树模型分类树模型包括5 层,显示男性、Cr、TG、年龄、HDL⁃c、LDL⁃c 等6 个变量是超重及肥胖性高尿酸血症的影响因素,见图1。
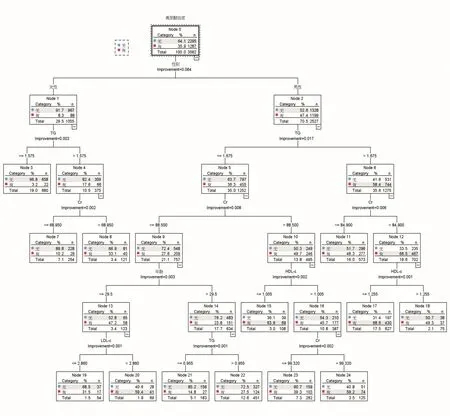
图1 超重及肥胖人群高尿酸血症发病风险的分类树模型(训练集)Fig.1 classification tree model of hyperuricemia risk in overweight and obese population(training set)
2.3 列线图(Nomogram)模型构建逐步向前logistic回归模型,结果显示男性、TG、LDL⁃c、Cr是超重及肥胖人群高尿酸血症的危险因素(P< 0.05),年龄≥29.5岁、HDL⁃c是保护因素(P<0.05),见表2。利用训练集中logistic 回归模型筛选出来的6 个影响因子构建超重及肥胖人群高尿酸血症发病的列线图模型,见图2。
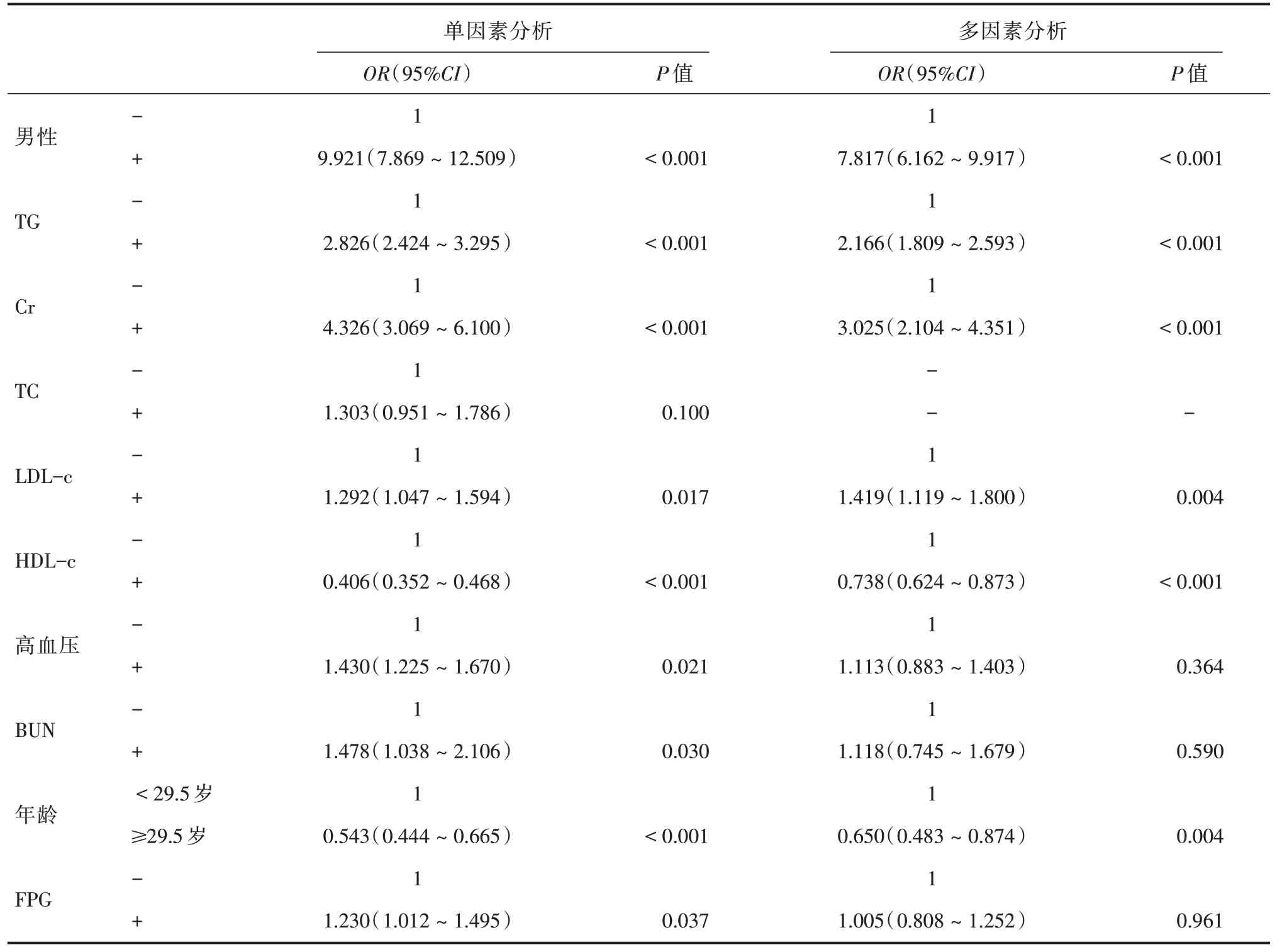
表2 超重及肥胖人群高尿酸血症影响因素的单因素及多因素logistic 回归分析结果(训练集)Tab.2 Results of univariate and multivariate logistic regression analysis on influencing factors of hyperuricemia in overweight and obese people(training set)
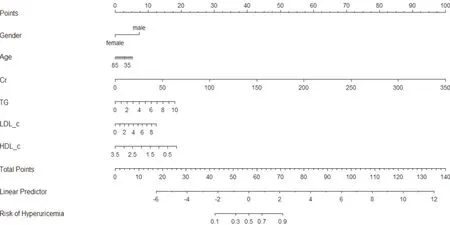
图2 超重及肥胖人群高尿酸血症危险因素的列线图模型(训练集)Fig.2 nomogram model of hyperuricemia risk factors in overweight and obese people(training set)
2.4 ROC、DCA、CIC 曲线训练集分类树模型ROC的AUC=0.791(0.777~0.804),Youden index =44.91%;训练集列线图模型ROC 的AUC = 0.787(0.773 ~ 0.800),Youden index = 46.31%;验证集分类树模型ROC 的AUC = 0.787(0.765 ~ 0.807),Youden index= 43.21%;验证集列线图模型ROC 的AUC=0.776(0.754~0.797),Youden index=42.31%,训练集和验证集两模型差异无统计学意义(训练集P=0.413,验证集P=0.154),见图3-5。
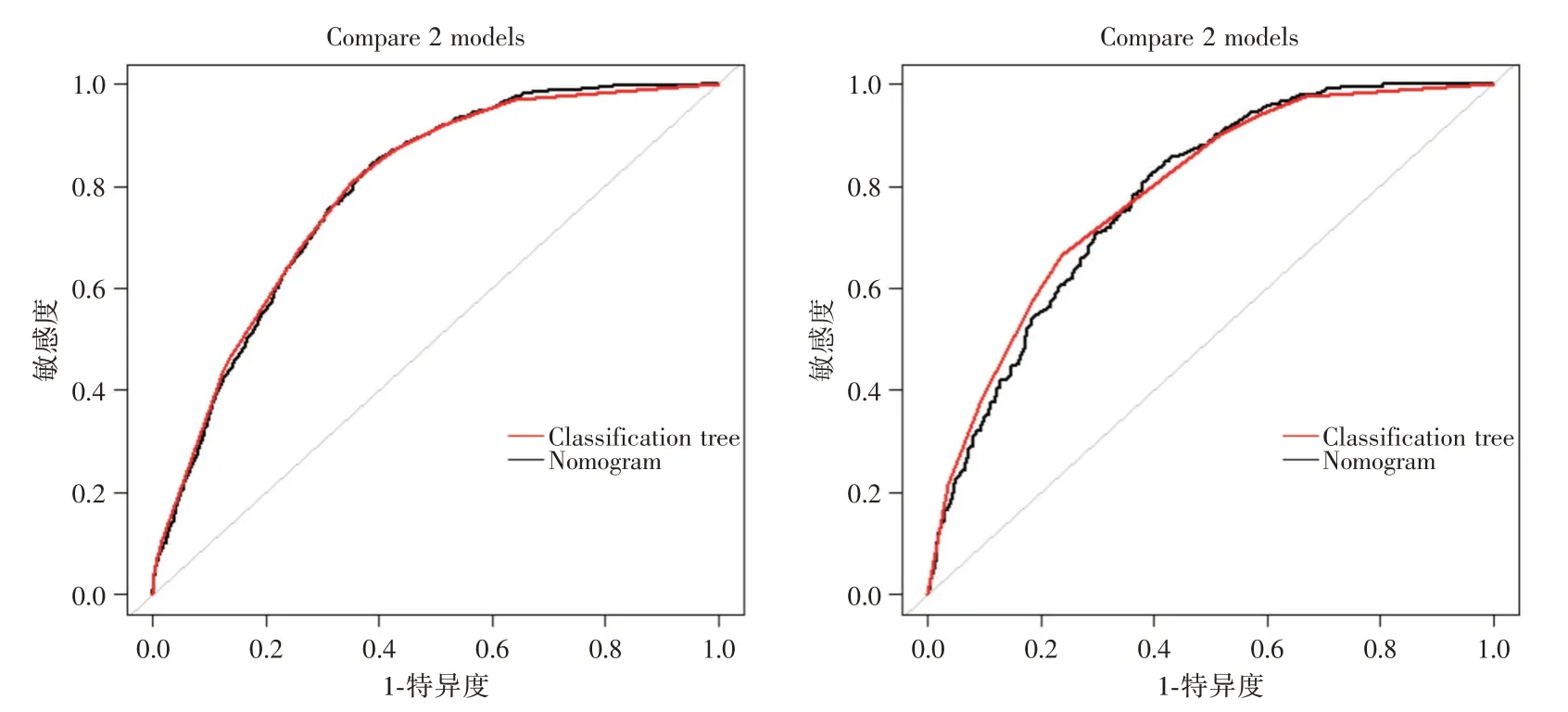
图3 ROC 曲线Fig.3 The ROC curve
3 讨论
本研究训练集中分类树模型结果提示男性、Cr、TG、年龄、HDL⁃c、LDL⁃c 等6 个变量是超重及肥胖性高尿酸血症的影响因素,同时也提示男性、TG、Cr 等3 个因素具有正向协同交互作用,分类树模型揭示了高尿酸血症的年龄段以29.5 岁分层,显示超重及肥胖人群高尿酸血症的发病年龄明显提前,与既往的研究类似[16-17]。表明青年肥胖患者为高危人群,更应加强尿酸的监测。
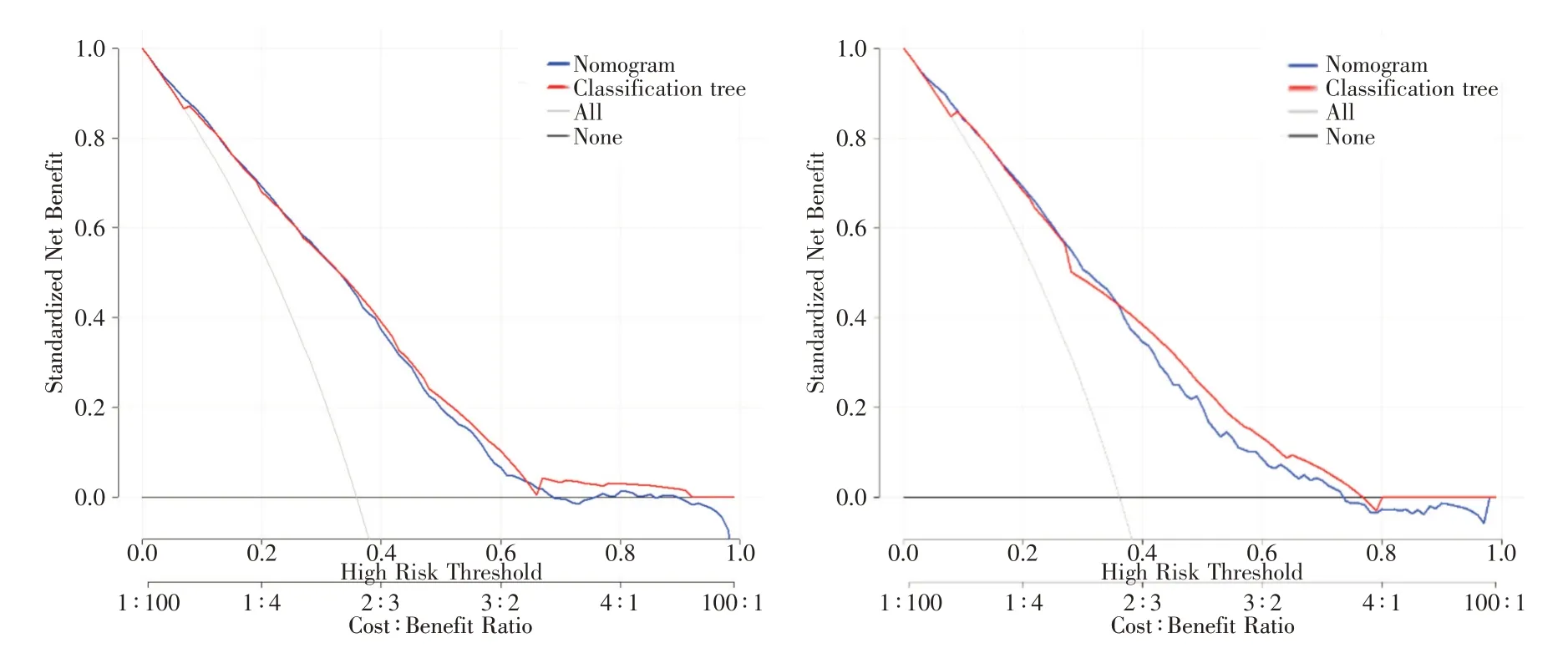
图4 DCA 曲线Fig.4 The DCA curve
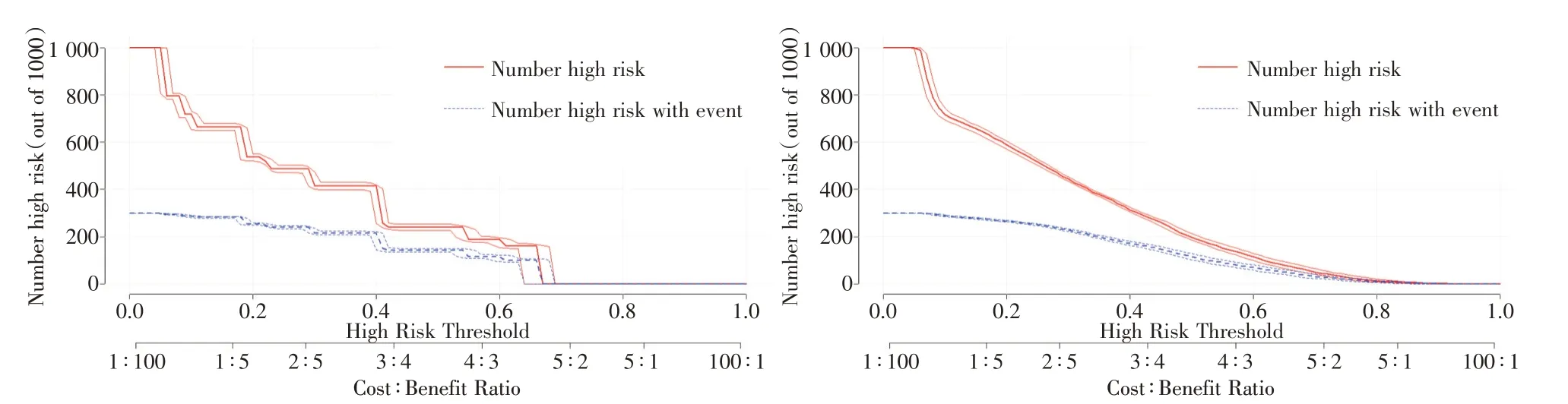
图5 CIC 曲线Fig.5 The CIC curve
本研究同时构建超重及肥胖人群高尿酸血症影响因素的列线图模型。首先经logistic 单因素和多因素回归筛选出来男性、Cr、TG、年龄、HDL⁃c、LDL⁃c 等6 个变量是超重及肥胖性高尿酸血症的影响因素,与分类树模型一致,既往研究也得出相似结论[18]。后进一步构建超重及肥胖人群的列线图模型,训练集中列线图风险评估总分为140 分,评分等于76 分预测概率高达95%,由此可见,列线图可以直观地展示logistic 回归模型筛选出的影响因素,并赋予其定量的风险评估分数,方便实用,可为超重及肥胖这一特定人群提供一个高尿酸血症评估的风险量表。本研究超重及肥胖人群构建的高尿酸血症分类树模型及列线图模型均提示男性是超重及肥胖人群高尿酸血症的高危人群,本研究结果显示男性的患病率(47.4%)远远高于女性患病率(8.3%),同时列线图模型男性评分为8 分,显示男性为高危人群需加强监测,既往研究也得出类似结果[19-20]。
本研究构建建模组进行训练集分析,构建验证组进行内部验证分析,最后采用ROC 曲线、DCA曲线、CIC 曲线对训练集和验证集两个预测模型进行评价,显示训练集和验证集两个模型的AUC 均为78%,均具有中等预测价值,约登指数均在42%以上,具有较高的准确性,两个模型对比的P值均>0.05,表明两个预测模型相差不大。
构建训练集和验证集两个模型DCA 曲线提示两条曲线较为接近,DCA 曲线横坐标表示患病风险概率(阈值概率),纵坐标表示两个预测模型在疾病诊断为阳性和阴性之间的利减去弊的关系,即预测模型诊断的净收益,阈值概率记为Pi;当Pi 达某个阈值(记为Pt),就界定为阳性。本研究在Pt 约为0.1 ~ 0.7 范围内,2 个模型的净受益率都高于0,表明两个预测模型都具有一定的临床实用性。训练集的CIC 曲线显示红色曲线(number high risk)以下,在每个Pi 下,被分类树模型和列线图模型划分为阳性(高风险)的人数;蓝色曲线(number high risk with event)为每个Pi 下金标准诊断为阳性的人数,表明分类树模型和列线图模型均有一定的临床影响价值。
然而,本研究属于单中心研究,没有同期其他中心研究进行验证,是本研究的缺陷,同时由于是体检人群,临床指标收集较少,下一步将有待联合多中心进行更大样本量的全面研究。
综上所述,本研究利用临床指标构建并验证了两种超重及肥胖人群高尿酸血症发病风险的分类树模型及列线图模型,筛选并赋予了影响因素的量化评分,同时运用三种模型验证方法对两种预测模型进行鉴别能力、准确性及临床实用性的全面评估,增加了本研究的应用价值,本研究可以帮助识别高危人群,并进行生活方式干预,对降低此类人群痛风、肾功能不全乃至心血管疾病的发生都具有一定的意义。
