配电终端多源异构数据的跨模态聚合算法
2021-09-25刘海姣李今宋邓清飞田昕泽张腾飞
陈 娜,刘海姣,李今宋,邓清飞,田昕泽,张腾飞
(1.南瑞集团有限公司,江苏 南京 211106;2.南京邮电大学 自动化学院 人工智能学院,江苏 南京 210023)
0 引言
配电物联网是配电技术与物联网技术深度融合产生的一种新型配电网络形态[1-2]。配电物联网各个环节重要参数的在线监测,为配电环节的科学运维提供智能辅助决策依据;而进一步提升电网运行安全水平,则依赖于配电物联网管理平台海量感知信息的智能管理和数据处理分析技术[3]。
配电物联网管理平台可以实现链接管理、数据处理、设备管理、应用管理和标识管理等功能,而平台信息安全是保障业务和数据安全、支撑公司应用发展的首要前提。为了规避网络数据安全问题,国家电网环境中部署了防火墙、入侵检测系统和防病毒软件检测系统等一系列的安全设备,以全方位监测网络环境中出现的攻击和威胁。然而,安全设备的简单堆积并没有彻底解决复杂的网络环境中出现的各种各样的问题,甚至大量的冗余告警信息反而影响了管理员应对系统中遭受的重要攻击的及时性。为了应对这些问题,帮助管理员从海量安全数据中分析并明确发生的攻击与威胁,需要对这些安全数据进行有效的管理和分析。其中,通过对多源数据进行聚合以减少冗余信息、挖掘各个设备之间信息的联系,是主要的解决方案[4]。
文献[5]提出了一种基于感知语义的窄带物联网多源异构数据聚合方法,其通过分析窄带物联网中的集中式和分布式模式,提出了基于语义感知的多源异构数据聚合以形成统一的聚合模式,消除数据冗余并延长网络寿命。文献[6]针对网络安全防御设备产生的大量冗余告警信息存在的数据琐碎、误警率高等问题,提出一种改进的多源异构数据的聚合方案,综合分析告警类型、源IP、目的IP、目的端口及时间间隔几个属性,总结出4条规则,并在聚合过程中动态更新时间间隔阈值,提高聚合精确度。文献[7]通过核典型关联分析方法学习网页图像和关联的文本的语义表达,其中语义空间提供了图像和文本之间共同的表达方式,使得图像和文本之间可以进行比较。文献[8]提出了转移网络方案,其可以通过学习域不变的表达方式和较好的赋值方案来量化源域样本的可转移性。文献[9]用最大均值差异法在再生核希尔伯特空间中学习源域和目标域之间可迁移的部分,但只利用了特征匹配,却忽略了样本可以重新调整权重的问题。文献[10]通过最大平均差异法减少源域和目标域之间的分布欠适配,并对通用空间中的每一种特征值类型的数据分布进行比较。
现阶段,配电物联网终端对数据采集和共享的要求显著提高[11],海量电网安全监测数据是配电物联网终端自动化运维、全景态势感知、个性化功能推荐、综合能源协调运行等高级应用决策依据的来源[12]。虽然数据存在的形式不同,但都用于描述同一事物或事件;而信息检索需要的往往不只是同一事件单一模态的安全监测数据,也可能需要其他模态的安全监测数据来丰富配电物联网终端对同一事物或事件的认知,此时就需要跨模态算法来实现不同模态数据的综合分析和处理。针对当前海量安全数据监测的需求,本文对海量数据进行综合分析和处理,提出一种跨模态的多源异构安全监测数据聚合算法,揭示其中隐藏的逻辑关联,发现攻击者的真正意图,从而对网络攻击行为进行预防和响应,实现对整个网络安全态势的有效监控。
1 安全数据聚合理论
数据聚合技术[13]是指网络中的中间节点在接收到前驱节点的数据后并不直接转发,而是对接收到的数据和自身节点感知的数据进行某种运算(例如:求平均值运算、求和运算、求最大/最小值运算等),最后生成单个数据并转发给后继节点。数据聚合减少了节点的能耗及带宽等资源;鉴于传感器节点的能量及带宽等资源是受限的,数据聚合延长了网络的生命周期,因此成为物联网技术中的关键技术之一。
安全数据聚合理论包括数据集成技术与多源信息聚合技术。数据集成解决的关键问题是如何将互相关联的分布式异构数据源集成到一起,屏蔽底层数据源差异,使用户能够以透明的方式访问这些数据源[14]。多源信息聚合要解决的关键问题是如何通过对多方面的信息进行有规则的组合,解决语义异构[15]问题,进而推导出更多有价值的信息。
传统的安全数据理论方法主要用于单模态源域(只包含单一数据)和单模态目标域(只包含单一数据)的情况。在此基础上,一些多模态源域(包含多种辅助数据,如电力系统的频率、节点电压水平、主变压器和线路的负载率)的安全数据聚合理论方法被提出。文献[16]提出了一种结构框架,可以从源域中的多种模态获得有判别力的并且可转移的特征值。文献[17]提出了一种深度域的自适应结构,可以探寻视觉数据库中的潜在域。然而,由于在真实世界的场景中,源域中的物体类别总是要大于目标域中的物体类别,使得传统的跨模态安全数据聚合理论方法很难在真实世界的场景中使用。相较于跨模态域的自适应方法,部分域的自适应方法主要关注目标域中的物体类别数小于源域中的物体类别数的任务。文献[18]提出了选择性对抗网络,可以通过对抗网络和赋权值机制选出源域中不包含在目标域中的类别。文献[19]提出了着重赋值对抗网络(importance weighted adversarial net)以提高获取源域样本的概率,使源域中的样本可以在域的对抗网络中被赋值。
2 多源异构安全监测数据聚合算法
为了应对复杂的网络环境中出现的各种攻击与威胁问题,本文提出一种多源异构安全监测数据聚合算法。该算法通过构建各类型安全监测数据域的自适应方法来对网络威胁进行更加全面地描述,并进一步挖掘潜在的未知网络威胁。不同类别的安全检测数据包含大量不同的有辨别能力的信息,可以帮助配电物联网终端对网络威胁有更好的认知。同时,在真实世界中,源域和目标域有着不同的数据分布,并且存在不相等的类别数目。本文旨在将所解决的问题和提出的算法建立在更加真实的场景上,并通过缩小源域和目标域之间的最大均值差异来解决源域和目标域的欠适配问题;同时在源域中添加多种安全检测数据信息并考虑源域和目标域中的类别不平等情况;最后借助非负矩阵分解以获得强健的视图不变的子空间。通过多源异构安全监测数据聚合算法,使得通过源域中已知的类别为目标域中未知的类别勾画出一种准确的边界成为可能。
如图1所示,通过分解和子空间学习,可为原始数据中的安全告警数据(实心的红色、黄色、蓝色和绿色图案)和网络日志数据(空心的各种颜色图案)探索模态不变的子空间;并在多源异构数据的融合阶段,为多源异构数据探索不随模态变化的子空间。本文所提方法可以在低维空间中对混合的类别和随模态改变的结构进行拆解,并通过添加的图形对这些结构进行正则化处理。图中,融合过的数据用半透明的颜色表示。
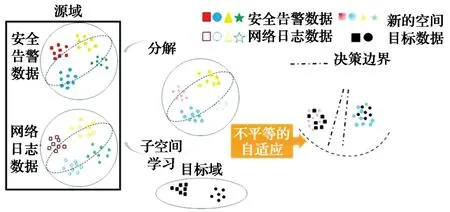
图1 多源异构数据聚合算法示意图Fig. 1 Schematic diagram of multi-source heterogeneous monitoring data aggregation algorithm
在自适应分布嵌入的阶段,算法会提高条件分布和边缘分布的重要性,通过获得对齐目标域(黑色方块和圆圈)和转换过的源域(半透明的方块和圆圈)的决策边界,预防目标域中的样本被错误地估计。
原始数据源域s中包含带标签的各种类型安全监测数据:安全告警数据s1、网络日志数据s2和系统日志数据s3等,s={s1,s2,s3, …,sn}。原始数据源域s的标签集合可以用Ys表示,未知网络目标域t的标签集合用Yt表示。
假设Ps为原始数据源域s的边缘分布,Pt为未知网络目标域t的边缘分布,且Ps≠Pt;同时各带标签数据的条件分布p(Ys|s1)≠p(Ys|s2)≠…≠p(Ys|sn)≠p(Yt|t)。算法第一阶段的目标是,通过寻找视图不变的子空间,获得转换过的源域snew1和转换过的目标域snew2。第二阶段的目标是,使用转换过的源域snew1,预测出未知网络目标域t的标签Yt,即潜在的未知网络威胁。通过域的自适应,缩小域之间的边缘分布(Ps,Pt)和条件分布(p(Ys|s1),p(Ys|s2), …,p(Ys|sn),p(Yt|t))的偏移;然后通过自适应地调节这两个偏移,构建各类型安全监测数据域的自适应方法,以对网络威胁做出更加全面的描述。借助非负矩阵分解,获得强健的视图不变的子空间。
2.1 多源异构数据跨模态
为了加强学习系统的辨别能力,通过共同学习,把各种类型安全监测数据连接到一个模型中。在安全监测数据嵌入阶段,首先获取源域中有标签的各种类型安全监测数据中的共享潜在基和单独子空间,并利用非负矩阵分解去探索各种类型安全监测数据之间共享的成分,目标函数为
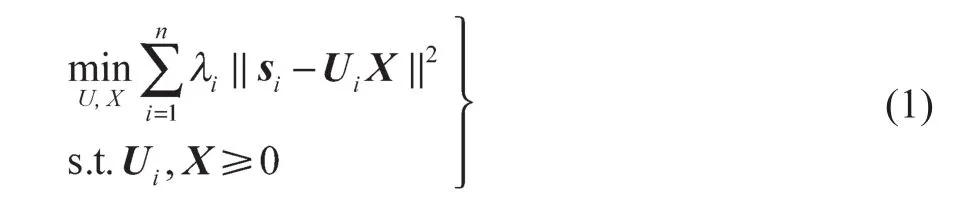
式中:U——基矩阵;X——系数共享矩阵;λi——平衡各种类型数据重要性的参数,由于安全数据聚合中默认各种类型安全监测数据是同样重要的,故设定λi=1。
由于非负矩阵分解不能发现数据空间本质的、具有辨别能力的结构,为了尽最大可能地保护安全监测数据的重要结构,可以通过概率分布的方法解决这个问题。算法通过Jensen-Shannon散度来缩小各种安全监测数据的概率分布:
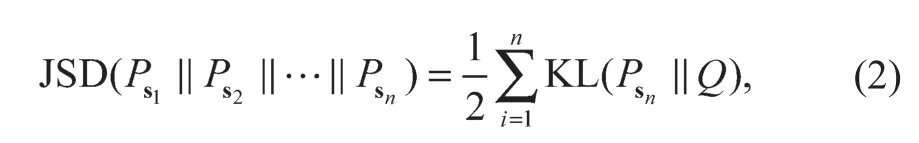
结合式(1)和式(2),可以得到最终的目标函数:
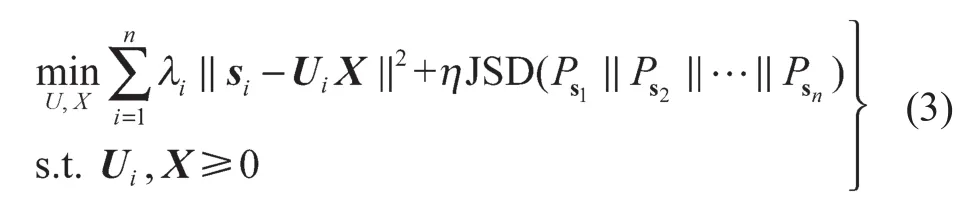
式中:η——控制表达式(2)的平滑度的参数。
最后,通过正交投影将深度数据信息的知识迁移到目标数据库,去对齐共享的潜在特征空间和目标域中的数据:
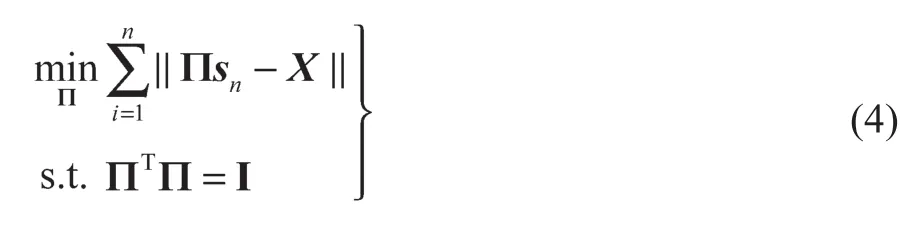
式中:I——单位矩阵;Π——目标域的正定投影。
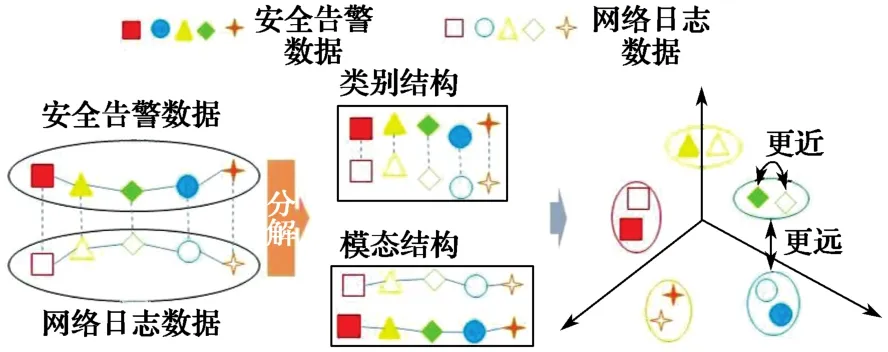
图2 安全数据在不同类别与模态下的距离Fig. 2 Distance of security data in different categories and modes
2.2 源域和目标域之间的欠适配
在自适应嵌入阶段,为了使特征值匹配,在再生核希尔伯特空间中非参数的最大均值差异被缩小:
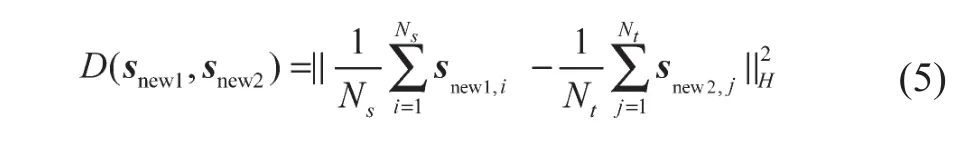
式中:Ns——snew1中样本的个数,Nt——snew2中样本的个数,
同时,为了调整样本权重,算法对共享的潜在空间样本缩小其结构稀疏2和1范数。在这个步骤中,需要解决的是如何在共享的潜在空间和映射所得到目标域之间同时匹配特征值并调整样本权重,从而得到一个自适应的分类器。在实际应用中,训练样本和测试样本之间是存在域的欠适配问题。在这种情况下得到的特征结果是不准确的,会影响系统的识别能力。
2.3 源域和目标域之间的不平等
源域和目标域的欠适配问题在大多数非监督域的自适应情境下是难以被忽略的。2.1节和2.2节中的方法解决了如何使用多源异构数据和域的欠适配问题。值得注意的是,在本项目中,为了研究更适合现实中的情景,假设源域的标签数大于目标域中的标签数,也就是每一个域中类别的概率都不相同。因此,对类别不平等的问题,采用条件分布的估计:
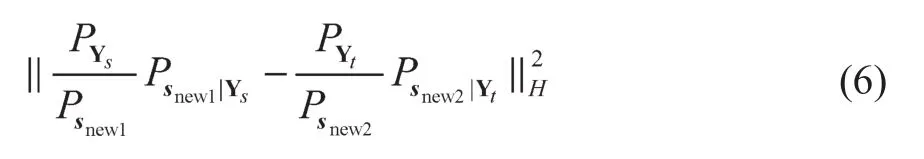
式中:PYs,PYt,和分别为Ys,Yt,snew1和snew2的边缘分布;为与Ys之间的条件分布;为与Yt之间的条件分布。snew1和snew2的类先验值用来估计和,对条件分布的散度需要估计边缘分布PVnew1和PVnew2。可以对每种类别数据构建出所需要的权重矩阵,最终可以得到被训练后的自适应分类器f。由于源域中有标签的数据和目标域中无标签的数据来自不同的分布,使用交叉验证无法获得最优参数,于是选用不需要调整交叉验证参数的最近邻分类器为基础分类器。分类器将通过整合各类型安全监测数据,对是否产生网络威胁做出判断。
3 实验分析
为验证算法的有效性,本文通过实验对几类安全监测数据进行算法评估。在配电物联网配电终端收集了10个不同类别不同的安全检测数据,包括电力系统的频率、节点电压水平、主变和线路负载率等,并对目标域的数据是否产生网络威胁进行评估。为了评估类别不平等的情况,在所有的任务中,10个有标签的安全监测数据被选取为源域数据,并随机挑选4~8个不含标签的安全监测数据作为目标域。为了进行全面且公平的比较,选择了3种不同的方法:
(1)多视角学习支持向量机(support vector machine, SVM2K)[7]。这种经典的方法在源域的训练中使用了多源数据。
(2)非监督域的自适应。通过样本迁移网络(example transfer network, ETN)[8]和迁移成分分析(transfer component analysis,TCA)[9],使用源域和目标域视觉特征值来训练分类器,然后预测目标数据标签。
(3)同时使用特权信息和非监督域的自适应。将从多视角到单视角的域适应(domain adaptation from multi-view to single-view, DA-M2S)[10]和鸡尾酒网络(deep cocktail transfer network, DCTN)[16]使用源域中的多源数据作为特权信息,同时减少源域和目标域数据分布之间的不匹配。
此外,从各类型安全监测数据中提取的不同特征值对结果的影响同样被考虑进来,浅层特征和深度模型特征被用来评估所提出的算法。对于浅层特征,安全监测数据提取梯度核描述子(kernel density estimation, KDES)特征值和局部二值模式(local binary pattern, LBP)梯度核描述子特征值;对于深度特征值,选择从预训练的Caffe模型中提取安全监测数据的卷积神经网络(convolutional neural network,CNN)特征值,特征值的维度为409 6。为便于分析,对算法的参数敏感度、收敛情况、T分布随机邻域嵌入(T-distributed stochastic neighbor embedding, T-SNE)进行可视化。
3.1 不同算法的识别准确度比较
各类型安全监测数据的不同特征值在上文提到的5种算法以及本文提出的多源异构安全监测数据聚合算法下得到的识别准确度如表1所示。
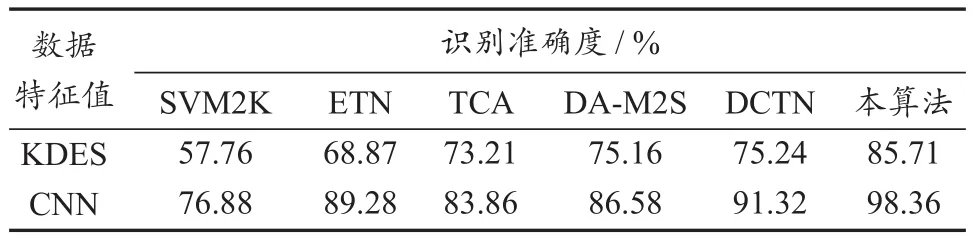
表1 不同算法的识别准确度Tab.1 Recognition accuracy of different algorithm
从实验结果可以看出,通过整合各类型安全监测数据,本文所提算法对目标域中的数据是否产生网络威胁较之前的方法做出了更准确的判断:相比DAM2S, ETN, TCA和DCTN算法,其判断准确度至少提高了7%;相比SVM2K算法,其判断准确度约提高了20%。SVM2K是经典的分类算法,但是由于没有考虑域的自适应问题,并没有展现出好的结果。DA-M2S虽然解决了域的自适应问题,但并没有考虑源域中可以有多种模态的情况,导致效果远不如本文所提算法的。ETN和TCA是经典的域自适应方法,但由于做了源域和目标域之间类别数目相等的非真实世界的假设,导致结果并不理想。DCTN虽然能够解决源域中存在的多模态和域的自适应等问题,但由于其参数过多,导致目标函数收敛困难,使得DCTN比本文所提算法的结果要差。本算法基于CNN特征值的分类混淆矩阵如图3所示。可以看出,数据6,7和10均被识别正确;其余数据,识别出现了不同程度的误差。
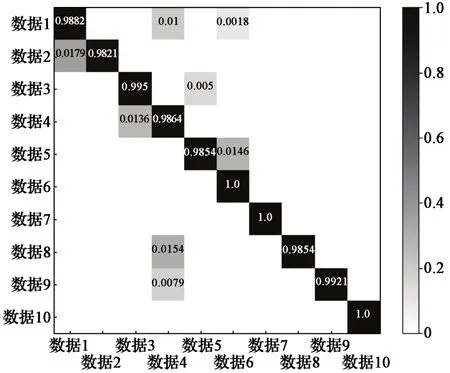
图3 基于CNN特征值的分类混淆矩阵Fig. 3 Classification confusion matrix based on CNN eigenvalue
下面对算法的参数敏感度、收敛情况和T-SNE可视化进行进一步分析。
3.2 算法中参数η和λi的敏感度分析
不同特征值和不同参数下,算法的参数敏感度如图4所示。
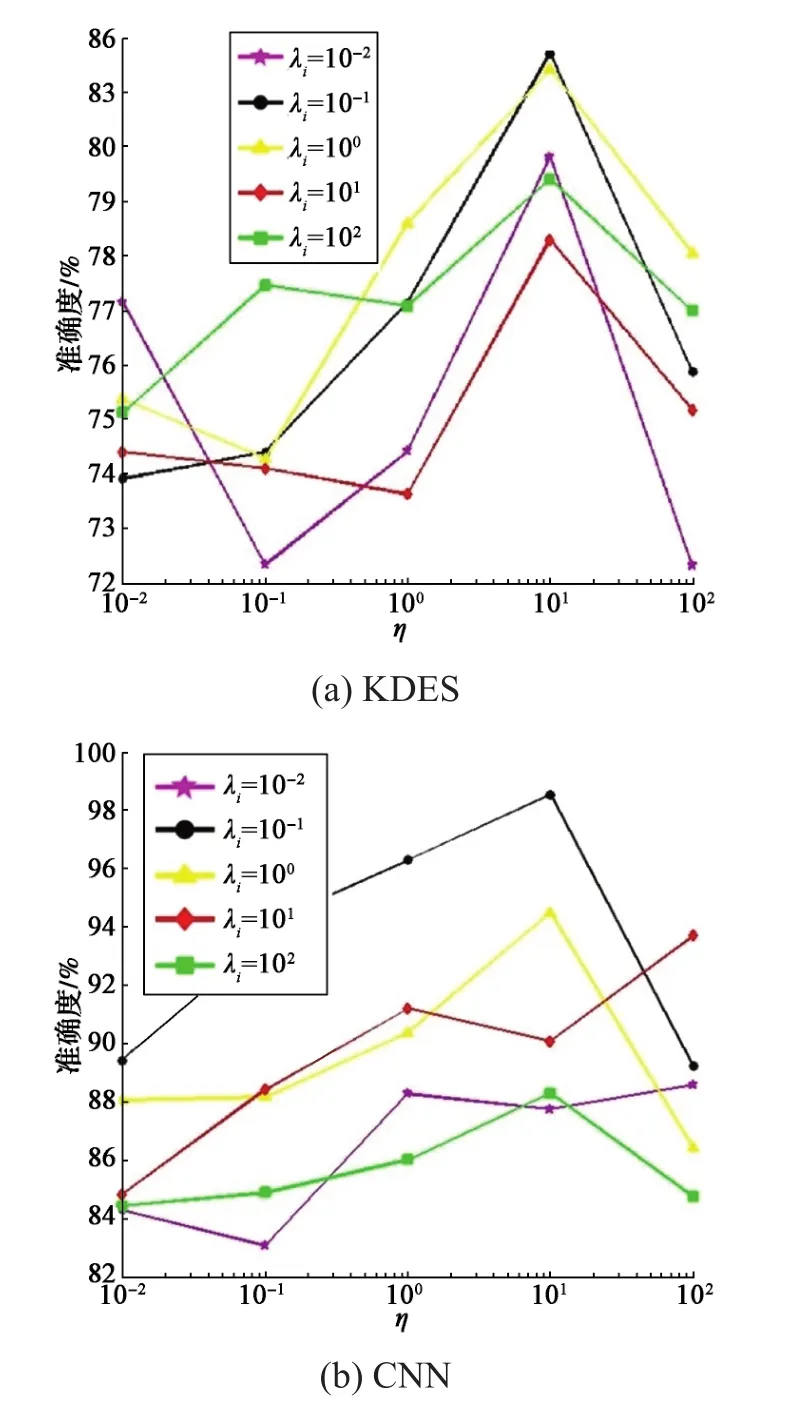
图4 不同特征值下算法参数敏感度Fig. 4 Sensitivity of algorithm parameters in the condition of different eigenvalues
从图4可以看出,无论特征值是KDES还是CNN,当η=10且λi=0.1的时候,算法的准确度最高。这个结果表明,本文所提算法具有较高的稳定性,其对参数的选择不敏感,无论选择何种特征值,都可以在η=10且λi=0.1的情况下得到最大的准确度。
3.3 算法收敛情况分析
不同特征值下算法收敛情况如图5所示。
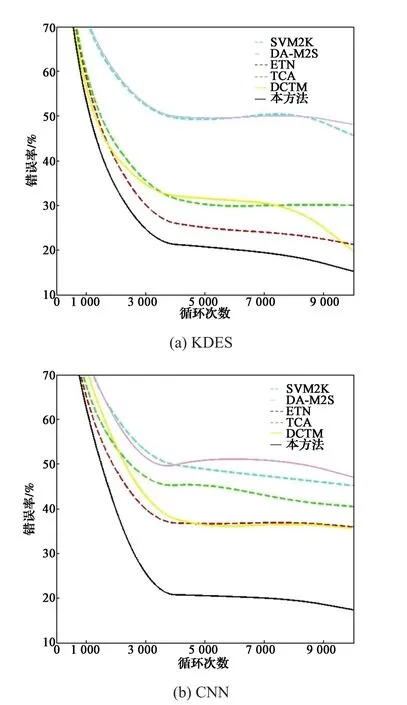
图5 不同特征值下算法收敛情况Fig. 5 Convergence of algorithm in the condition of different eigenvalues
从图5可以看出,本文所提算法随着循环次数的增加逐渐稳定,且在3 500次循环以后收敛到最低错误率,表明该算法是可收敛的且具有较快的收敛速度。其他方法虽然同样可以较快地收敛,但有着较高错误率。错误率表示所有判断错误的样本数占所有样本数的比例,其计算公式为
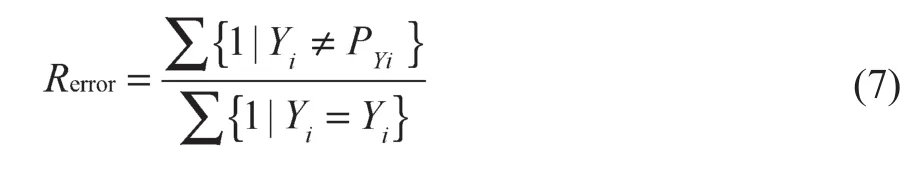
3.4 T-SNE可视度分析
通过T-SNE,DA-M2S方法和本算法在安全测试数据上深度特征值的表现被可视化。不同算法源域和目标域数据的T-SNE可视化如图6所示。图6(a)和图6(b)中,每一种颜色代表了一个类别,是将类别信息可视化;图6(c)和图6(d)中,两种不同的颜色分别代表源域和目标域中的数据,是将信息可视化。

图6 不同算法源域和目标域数据的T-SNE可视化Fig. 6 T-SNE visualization of data in source domain and target domain in the condition of different algorithms
从图6(a)和图6(c)可以看出,采用DA-M2S方法提取的特征值在T-SNE可视化下混在了一起,从而揭示了DA-M2S易错误地估计目标域中安全测试数据的原因。从图6(b)和图6(d)可以看出,本文所提算法成功地分离了目标域中各种不同的特征值,从而可以对未知的测试数据做出正确的评估。
4 结语
本文针对配电终端安全监测数据具有的多源和高度异构的特征并面对网络攻击与威胁安全的数据聚合的需求,提出了一种跨模态聚合算法。通过分解和子空间学习原始数据中的安全告警数据和网络日志数据,探索模态不变的子空间;通过共同学习,把各类型安全监测数据连接到一个模型,在自适应嵌入阶段,解决了源域和目标域之间的欠适配和不平等问题。与现有算法相比,本文所设计的算法具有对参数的选择不敏感、可收敛且识别准确率高等优点。
后续将通过深度学习建立类别不平等域的自适应学习模型,在此基础上将各类型安全监测数据信息特征进行融合,并且减少源域和目标域之间的欠适配,保持数据的结构信息;通过计算出的差,识别源域中包含的存在于目标域中的类别和不存在于目标域中的类别,从而更好地解决配电物联网管理平台信息的网络安全问题。
