提升固态存储设备读取性能的方法
2021-09-16李明江段星辉
李明江,段星辉,陈 仁
(1.黔南民族师范学院 计算机与信息学院 人工智能与大数据应用技术研究所,贵州 都匀 558000;2.黔南民族师范学院 计算机与信息学院,贵州 都匀 558000;3.中科院上海技术物理研究所 中国科学院红外探测与成像技术重点实验室,上海 200083)
0 引 言
近年来,由于基于闪存的固态存储设备具有速度快、延时低、功耗低、抗震、体积小[1]等优点,固态存储设备在存储领域中得到广泛的使用。但闪存具有其自身的一些问题,比如写前擦除、寿命有限、读取次数有限、读写速度不一致等[2]。基于闪存的固态存储设备通过闪存转换层(flash translation layer,FTL)来管理闪存。FTL的主要作用是管理逻辑地址(LBA)到物理地址(PPA)的映射。基于不同粒度的映射,FTL有块映射、页映射以及混合映射等地址映射方式[3],其中页映射具有最好的读写性能,因此为主流固态存储设备所使用。然而,基于页映射的映射表很庞大,需要大容量的缓存来存放。然而在一些固态存储设备中,出于成本和功耗考虑,没有配备大容量的缓存存储映射表,映射表只能部分存储在有限的控制器SRAM上,其绝大部分则存储在闪存上。有限的SRAM限制了无DRAM设备的读取性能,尤其是随机读取性能,因为设备首先需要访问闪存获取映射关系,然后再根据该映射关系从闪存中读取用户数据。在有限的SRAM空间,如果能尽可能多缓存映射关系,则能减少对闪存的访问,从而提升设备的读取性能。这是包括本文在内的很多论文解决该问题的一个思路。本文提出的另一个想法是利用有限的SRAM资源,缓存尽可能多热数据的映射关系,因为热数据的访问速度对用户体验有直接的影响,而冷数据的访问速度则对用户体验没有那么大的影响。
1 无大缓存存储设备的主要FTL算法
对性能要求高的固态硬盘(如企业级固态硬盘),一般都配有大容量的DRAM来存放映射表。对读写I/O来说,由于整个映射表都存储在DRAM中,固件可以快速获取读写所需的映射关系,读取或者更新映射关系都很迅速(只需访问DRAM),因此读写性能很好。
如何在无DRAM的固态硬盘中实现基于页映射的FTL,国内外有很多研究,最为经典的FTL算法是DFTL[4],其它很多FTL算法都是在此基础上衍生和改进的。
DFTL基本思想是把整个映射表按映射页管理,所有映射页都存储在闪存上,映射页按需加载到缓存(cached mapping table,CMT)中,而全局翻译目录(global translation directory,GTD)用以存储这些映射页在闪存中的物理地址,它常驻SRAM。对读写I/O来说,它首先在CMT中查找该逻辑页的映射关系,如果命中缓存,则直接根据该映射关系读取闪存获得用户数据;如果没有命中缓存,则查找GTD,找到所需映射页的物理地址,然后从闪存中读取映射页到缓存中,最后固件根据该映射关系获得用户数据。
DFTL的顺序读取性能很好,因为一个映射页加载到缓存中后,对接下来的很多笔读,都能发生缓存命中,无需访问闪存便能获得该逻辑地址对应的物理地址;但对随机读取来说,因为CMT大小有限,对每笔读取来说,发生映射页缓存命中概率很低,因此很多时候它都需要访问两次闪存才能最终获得用户数据,随机读取性能差。
为提高映射页缓存的命中率,在DFTL的基础上,文献[5]提出LAST++,其思想是根据主机的读写负荷,对顺序写入的数据,采用块映射,而对随机写入的数据,采用页映射。这种方式能减小整个映射表大小,对同样大小的映射页缓存,缓存命中率会有一定的提升。但这种混合映射方式实现起来很复杂,因为要同时兼顾块映射管理和页映射管理。
文献[6,7]提出的FTL算法,其基本思路相似,即在DFTL的基础上,对顺序写入的,采用更粗的映射粒度,对随机写入的数据,采用更细的映射粒度。更粗的映射粒度能减小映射表的大小,提升映射页的缓存命中率。但这些算法有个弊端,就是顺序写的数据中如果加入少量的随机写(这在实际使用场景中是经常发生的,比如顺序写的文件中加入文件元数据的写入[6]),粗的映射粒度就不能使用,因此无法提升页缓存命中率。其实,LAST++存在同样的问题。
另外,这些FTL算法对热冷数据无差别对待。其实,在有限的SRAM空间缓存冷数据的映射关系是没有意义的,因为这些数据很少被用户访问,它们访问速度的快慢对用户体验没有大的差别。
2 本文工作
读取速度的快慢,尤其是热数据的读取延时和性能,和用户体验息息相关。低延时和高速的读取访问能大大提升用户体验,反之亦然。为改善无DRAM大缓存的存储设备的读取延时和性能,本文调研了业界和学术界最新的设计方法(如第1节所述),在他们工作的基础上,本文创造性提出以下方法:
(1)用户在实际使用固态存储设备时,存在很多顺序写入以及大数据量的写入[8],这些数据写入产生的映射具有逻辑地址和物理地址连续的特点。连续的映射关系很适合压缩,本文通过压缩连续映射关系以让有限的缓存空间存储更多的映射关系;
(2)用户在实际使用存储设备时,顺序写和随机写可能交错写入[9],为保证顺序写入的数据在闪存物理空间连续(不被随机写打断),本文提出让顺序写入的数据和随机写入的数据存储在不同的闪存物理块上。分离存储保证更多的连续物理地址映射,从而有助于提升映射表的压缩率;
(3)用户在使用存储设备时,虽然存储设备上存储了很多数据,但经常访问的数据往往有限。因此,本文提出只缓存热数据的映射表,从而在有限的映射缓存空间能存储更多的有助于提升用户体验的映射关系;
(4)普通用户在使用存储设备时,设备很多时候都是空闲的,因此本文提出利用设备空闲时间预取和压缩热数据的映射表,达到提升热数据访问速度的目的。
在设计和实现以上算法的基础上,本文还设计实验比较了不同FTL算法之间的读取性能差异,并对实验结果做了理论分析。
3 算法设计
3.1 映射表压缩
为减小映射表的大小,本文的思路是压缩映射表,让有限的映射表缓存能存储尽可能多的映射关系,来达到提升映射表缓存命中率的目的。
注意到无论是在基准测试(benchmark tests)中,还是在实际用户使用存储设备过程中,都会有很多的顺序写入或者大数据量的写入(比如视频、图像、大文件等),这些数据的写入,会产生很多的连续的物理地址。比如write(0,1024)(起始LBA为100,写入1024个逻辑页)写入,产生表1所示的映射。
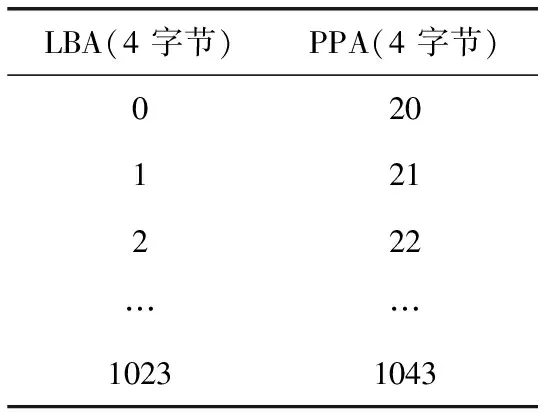
表1 传统映射表示例
对这些逻辑地址和物理地址都连续映射,采用游程编码的方式,把它们用另外一种形式表示,见表2。

表2 映射描述符表示例
把其中的条目称为映射描述符,包括“起始LBA,起始PPA,连续长度”3个域。同样的映射关系,用表1传统的页映射管理形式,它们需要4096字节来缓存,而采用游程编码压缩后,表2只需10字节就能表示同样的映射关系,所需SRAM空间大大减小。
在DFTL的映射页缓存(CMT)基础上,所提算法加入映射描述符缓存(mapping descriptor cache,MDC)用以缓存游程编码后的映射描述符。为减小查询开销和内存使用空间,MDC通常只有几KB。在第4节实验结果部分提供了不同MDC大小下的软件查询开销。
当加入MDC缓存后,设备处理主机读取命令步骤如下:
(1)FTL查找传统的映射页缓存(CMT),看该LBA对应的映射页是否在CMT,如果命中缓存,返回该LBA对应的物理地址,跳到(4);否则,走到(2);
(2)FTL查找新加的映射描述符缓存(MDC),看该LBA是否落在其中某个映射描述符内,如果在,则返回该LBA对应的物理地址,跳到(4);否则,走到(3);
(3)查找全局翻译目录(GTD,即映射页物理地址表),找到LBA对应的映射页的物理地址,然后读取所需的映射页到映射页缓存,同时,FTL遍历该映射页以压缩其中的连续映射关系,如满足条件则新的映射描述符会被加入到MDC中。
(4)根据该LBA对应的物理地址读取闪存获得该用户数据,返回给主机。
伪代码如下:
输入:LBA,逻辑地址
输出:PPA,物理地址
if(LBA hit CMT)
{//LBA所对应的映射页在映射页缓存CMT中
return PPA from CMT;
}
else
{
if(LBA hits MDC)
{//LBA落在映射描述符缓存MDC中
PPA =(LBA-Start_LBA)+ Start_PPA
return PPA;
}
else
{//CMT和MDC都没有命中
PPT_Index = LBA/PPT_SIZE;//获得该LBA对应的映射页编号;
PPT_PPA = GTD[PPT_Index];//查找GTD获得所需加载映射页的物理地址;
根据物理地址PPT_PPA加载映射页到映射页缓存CMT;
遍历映射页看是否能加入到MDC;
return PPA;
}
}
3.2 顺序写入和随机写入数据分开存储
对连续的写入,或者大数据的写入,会产生连续的地址映射,有利于映射数据的压缩。但在实际用户使用存储设备的过程中,在连续数据写入过程中会有随机的写入,如文件系统层在写入大文件数据的时候,中间会写入管理文件相关的元数据。随机写入会导致连续的地址映射中断,不利于映射关系的压缩。
举例来说,两个连续的写write(0,64)和write(64,32),写入到的闪存空间起始物理地址为0,则一个映射描述符(0,0,96)可以描述两个命令产生的映射关系。如果在两个命令中加入了一个不连续的命令write(200,1),则需要两个映射描述符来描述之前两个命令产生的映射关系,见表3。

表3 连续物理地址被中断的例子
如果对加入到MDC的映射描述符有限制的话,比如连续长度需大于32,则表中第3条映射关系不会被缓存,导致更多的映射关系没有被缓存,从而导致缓存命中率降低。
为避免随机的写入中断顺序写的映射关系,本文提出把顺序写入的数据和随机写入的数据分开写在不同的物理块或者超级块。以上面3个写入命令为例,由于write(0,64)和write(64,32)是连续的写入命令,因此它们会写在起始物理位置为0的闪存空间(如图1中的超级块A);而write(200,1)是随机写入,因此它的数据会被写到另外的闪存空间,比如起始物理位置为10000的闪存空间(如图1中的超级块B)。
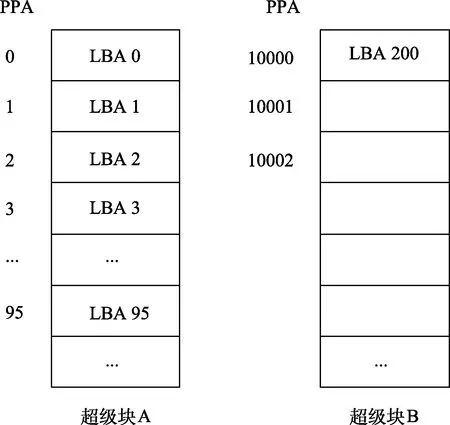
图1 顺序数据和随机数据分开存储示例
顺序写入的数据和随机写入的数据分开存储让连续的命令write(0,64)和write(64,32)具有连续的物理地址,它们的映射关系这样就可以被一个映射描述符(0,0,96)描述,提升了映射表的压缩率,有限的缓存空间MDC可以缓存更多的映射关系,映射缓存的命中率得到提升。
3.3 区分冷热数据
尽管用户的存储设备上存储了很多数据,但很多时候,用户只会频繁访问其中的一部分数据,这部分数据被称作热数据,相反,那些不经常访问的数据则称为冷数据。要提升用户体验,重在提升热数据的访问速度。
FTL对整个用户存储空间进行划分,比如每1 GB为一区间,128 GB的存储设备则被划分成128个用户区间,见表4。对每个用户区间,FTL维护它的读取次数:如某个LBA被主机读取,其所在的用户区间的读次数则加1。
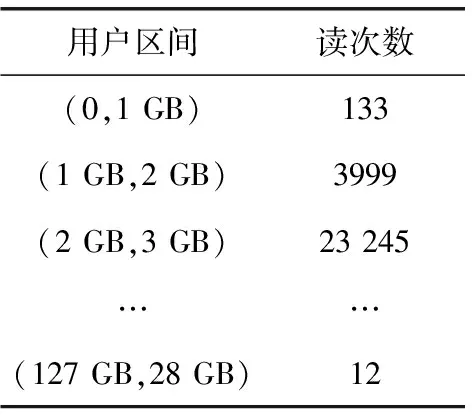
表4 用户区间读计数表例子
比如,在表4的基础上,read(0,10)命令处理完后,其所在的用户区间读次数应该加10,即用户区间(0,1 GB)的读次数变成143。
FTL可以把读次数最多的若干个用户区间定义为热数据,其它用户区间则定义为冷数据。由于映射关系的缓存空间有限,FTL没有必要缓存冷数据的映射关系,而是在有限的空间缓存更多的热数据对应的映射关系,有助于提升热数据的缓存命中率,从而提升用户体验。
3.4 更新映射描述符缓存(MDC)
有两个时机映射页会被压缩成映射描述符加入到映射描述符缓存MDC:一是当读取某个LBA发生映射页缓存不命中的时候,FTL会去闪存上加载该映射页到缓存CMT,在这个时候,FTL会去遍历该映射页,如果有很多的连续物理地址存在该映射页,则它们会被压缩成映射描述符而被加入到MDC;另外一个时机是存储设备空闲的时候,FTL会把所有热数据对应的映射页读取上来,然后遍历这些映射页,压缩那些连续的映射关系,压缩成的映射描述符可能被加入到映射描述符缓存中。
映射缓存中缓存的映射关系越多,则映射缓存命中率越高,系统读取性能越好。为在有限的缓存空间缓存尽可能多的映射关系,该算法制定如下更新描述符缓存的规则:
FTL只会把热数据对应的映射关系更新到映射描述符缓存;
对加入到映射描述符缓存中的映射描述符做限制,即只有物理地址连续个数超过某个阈值(如32个)的描述符才能加入到缓存中;
当MDC缓存满了的时候,当需要添加新的映射描述符,如果待加入的描述符其连续的物理地址长度大于缓存中最短的那个描述符,则取代该描述符加入缓存中,否则放弃添加新的映射描述符到缓存。
这些规则的定义,能保证有限的MDC空间缓存尽可能多的映射关系,尤其是热数据的映射关系。
4 实验结果
本文使用FlashSim[10]仿真软件来评估该算法性能。FlashSim是一款开源的SSD模拟器,它是一款事件驱动的、模块化的基于C++的模拟器,内置了多种FTL策略,能够提供响应时间、能耗的模拟及许多额外的统计信息。在FlashSim内置的DFTL算法的基础上,实现映射压缩、顺序和随机数据分开存储、区分冷热数据和后台加载热数据映射表并进行压缩。
实验使用FlashSim模拟128 GB存储设备,该存储设备有4个32 GB的Flash组成,每个通道上挂一个Die。具体参数见表5。

表5 存储设备配置
映射页缓存CMT大小为256 KB,可以缓存64个4 KB大小的映射页;映射描述符缓存MDC大小为2 KB,由于每一个描述符大小为10字节,因此可以缓存大概200个映射描述符。在处理每笔读取命令的过程中,需要查找映射描述符,在本实验平台上实测软件查询2 KB的MDC需要额外多出1 μs,因此MDC不能配置太大,否则查询成本太高。如20 KB的MDC查询时间为10 μs,意味着读取的延时增加10 μs,系统读取性能大大减小。图2给出了不同MDC大小配置下的MDC查询时间。
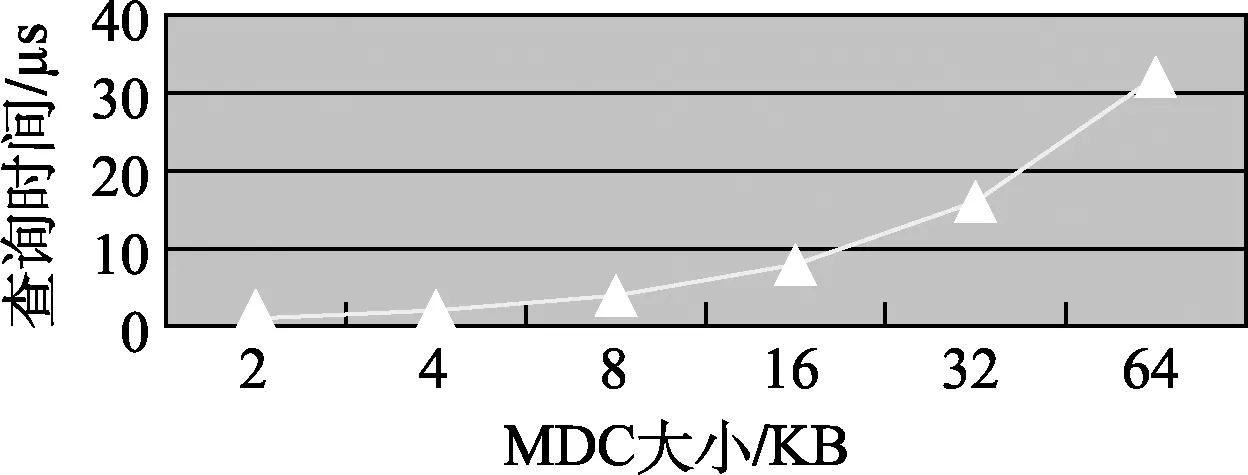
图2 MDC查询时间和其缓存大小的关系
实验设计1:目的是测试压缩映射表对数据读取性能的提升。
测试方法:
(1)顺序填满整个盘;
(2)不同LBA范围内测试数据的读取性能。
结果(如图3所示)分析:由于DFTL只用256 KB CMT缓存映射表,因此映射表缓存命中率随着LBA测试范围扩大,命中率逐渐下降,具体见表6。

图3 本文算法和传统FTL随机读取性能对比
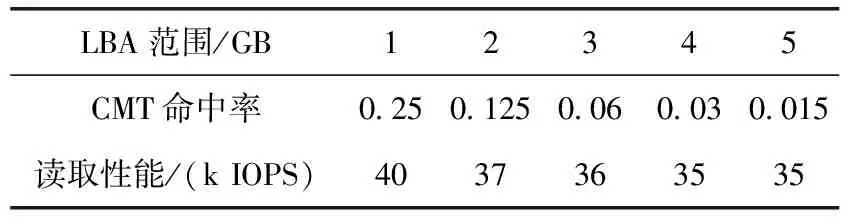
表6 DFTL映射缓存命中率和读取性能
由于本文算法采用了映射表压缩,并使用MDC来缓存压缩后的映射描述符。2 KB的MDC能缓存200个映射描述符,每个映射描述符可以描述256 MB(超级块的大小,一个超级块需要一个描述符),因此50 GB LBA范围内的映射关系可以被存储在MDC中。因此,如果LBA读取范围在50 GB之内,则发生100%的映射缓存命中,读取数据的时候无需从闪存上读取映射关系。从实验数据可以看出,50 GB LBA测试范围内,4 KB平均读取性能约为70 K IOPS,平均延时为68 μs,但从50 G LBA范围开始,随着LBA测试范围加大,其性能逐渐变差,命令延时也加大,因为缓存命中率慢慢变低,需要更大概率从闪存上读取映射关系。
由于MDC缓存的映射描述符有限,不能覆盖整个用户空间的数据,这也是本文提出只缓存热数据映射关系的原因。在本实验中,如果用户热数据在50 GB(128 GB中有50 GB数据被经常访问)之内,则在读取这些热数据的时候,能发生100%的MDC缓存命中,从而加快热数据访问的性能和延时,从而改善用户体验。
注意到LAST++在顺序填充满盘的情况下,它能做到全盘范围内保持一个高的随机读取性能,那是因为完全顺序写入时,LAST++采用的是块映射,映射表相对页映射来说大大减小,因此其所有映射关系可以缓存在SRAM。
实验设计2:目的是测试顺序写入的数据中夹杂着少量的随机写,然后测试读取性能。
测试方法:
(1)顺序填满整个盘,但在填盘的过程中,每写1 MB的用户数据,插入一个随机写的数据,用以模拟平时文件的写入(文件系统在写入用户数据的同时也会写入文件元数据);
(2)不同LBA范围内测试数据的读取性能,比较顺序写入的数据和随机写入的数据分开存储和统一存储两者对随机读取性能影响,以及和传统DFTL,LAST++性能的对比。
结果分析:从实验结果(如图4所示)可以看出,如果顺序写入的大数据和随机写入的小数据混合存储,其4 KB读取性能和DFTL(没有映射表数据的压缩)差不多。这是因为,每写入1 MB的数据,则需要一个映射描述符。由于MDC只能缓存200个左右的映射描述符,也就是说只能缓存200 MB左右的用户数据的映射关系(见表7),和CMT缓存映射关系差不多,因此在性能和延时上,混合存储和DFTL性能差不多,都远远不及分开存储的性能。
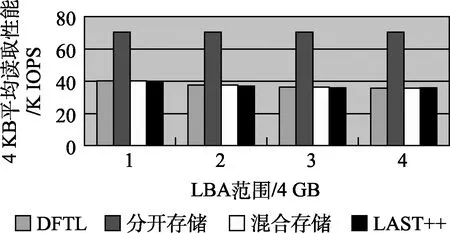
图4 混合存储和分开存储性能对比

表7 混合存储和分开存储覆盖的LBA范围
结果还发现,在实验1顺序填盘情况下表现优异的LAST++,在碰到这种随机和顺序混合填盘的情况下,其性能退化成DFTL性能。LAST++的基本思想是对顺序写入采用块映射,对随机写入采用页映射。在此测试中,随机写入打断了顺序写入,导致顺序写入量不足一个闪存块,无法实现块映射,演变成纯粹的页映射,因此无法减小映射关系,最后导致其读取性能跟DFTL性能一样。
5 结束语
针对不带大缓存的固态存储设备读取性能和延时差的问题,本文采用游程编码的方式压缩和缓存热数据的映射表、顺序写入的数据和随机写入的数据分开存储、大数据写入和小数据写入分开存储等方法,提升读取命令的映射缓存命中率,来提升用户访问热数据的读取性能,从而改善用户在使用移动存储(比如手机、平板上使用的存储设备)或不带DRAM固态硬盘时的使用体验。对企业级的固态存储设备,虽然一般都配有大容量的DRAM作为缓存,但随着存储设备容量越来越大,还是存在缓存不能容纳整个设备映射表的问题,因此,本文提出的算法也适用于这些企业级应用的固态存储设备。
