基于边缘云环境的工作流调度与卸载决策算法
2021-09-16金俭,郑倩
金 俭,郑 倩
(1.黄河科技学院 现代教育技术中心,河南 郑州 450063;2.郑州轻工业大学 软件学院,河南 郑州 450002)
0 引 言
随着智能终端设备的广泛流行,移动终端所能执行的应用类型越来越多样化,如图像处理、面部识别及增强现实等应用,越来越多地运行在移动终端[1]。以上应用类型的任务构成并非单纯的完全串行或并行结构,而是更为复杂的工作流结构。处理工作流应用需要高性能处理资源,以获取更好的用户体检[2,3],边缘云任务卸载即是在这种背景下产生的[4,5]。利用卸载,用户可将任务需求从本地卸载到能力更强的边缘云上执行,凭借边缘云的性能优势,加快任务执行效率,节省本地能源消耗。然而,工作流任务的特殊结构及移动客户端与边缘云服务器间的无线通信条件为工作流任务调度与卸载决策带来了挑战,体现在:①延时敏感型应用在本地执行势必导致较长响应时间,部分卸载方法需要在考虑执行时长和本地能耗基础上进行任务卸载,这是带约束条件的优化问题;②任务卸载执行虽然可以性能更强的云端资源处理本地任务,但传输时延、传输能耗及通信环境均会对卸载决策产生影响,卸载决策需考虑多方面因素;③调度时长和能耗优化作为两个冲突目标,在实际卸载决策过程中需均衡考虑。若要降低调度时长,势必要卸载更多任务至边缘云,但过多传输时间反过来会增加响应时间,同时会额外增加传输能耗;为了降低本地能耗,同时会导致更多任务卸载执行,而这同样会带来调度时长增加。
为了实现移动客户端能量约束条件下的工作流调度效率的优化,在边缘云中设计一种卸载决策算法PCTSO。算法重点解决了待调度任务的优先级确定问题和连续依赖工作流任务的卸载决策问题,在提升任务执行并行度的同时,还可以优化工作流的执行效率和移动客户端的能量消耗。
1 相关研究
有关边缘云环境中的任务调度与卸载决策问题,文献[6]提出一种以最小化移动客户端的能耗,满足任务执行截止时间约束的任务卸载算法。文献[7]通过检测每个边缘云的每个时槽决定任务是在本地执行还是卸载执行,所设计的卸载决策算法可以通过线性规划方法在满足能量约束的情况下最小化任务执行的总延时。为了降低本地能耗,满足延时约束,文献[8]提出基于Lyapunov优化的动态卸载算法。文献[9]在多用户应用分割与卸载环境下设计了离线卸载算法,实现了执行延时的优化。文献[10]提出基于马尔可夫决策的朵云任务卸载算法。但是,朵云受限于无线网络覆盖,服务连续性较差,无法应用在边缘云卸载决策问题。文献[11]同样利用马尔可夫决策对卸载决策进行了建模。文献[12]设计了博弈分布式卸载决策算法,文献[13]联合考虑通信资源和计算资源分配,设计了迭代任务卸载算法。对于工作流结构的边缘云中的任务卸载决策问题,文献[14]将容错机制考虑在任务卸载中,有利于恢复边缘云的任务执行。文献[15]提出将每个任务卸载至朵云中,实现移动客户端的执行延时和执行能耗的最小化。模型中,若一个任务卸载至朵云,则其后继任务也会被检测是否卸载至相同朵云中执行。在执行延时和能耗同步降低时可将其进行卸载至朵云。文献[16]设计了负载均衡的工作流卸载算法LBOA,该算法更多考虑的是将移动终端的负载均匀地分布于边缘云端和移动客户端,没有过多考虑调度效率和执行能耗问题。文献[17]设计了面向边缘侧卸载的两阶段工作流调度算法,通过隐性马尔可夫链预测负载量,从而保证任务调度的成功率。文献[18]提出了基于遗传算法的任务卸载方法,有效实现了移动服务的执行效率与执行能耗的平衡。文献[19]设计了一种多重资源卸载能耗模型,利用粒子群算法对该模型下的任务调度进行了求解,在满足响应时间约束的同时降低了设备能耗。算法同样解决的是工作流式任务的调度与卸载决策问题,但侧重于以单个任务作为决策基准,不考虑任务关联性。文献[20]将卸载决策问题建立为能耗和时延加权的凸优化问题,并设计了基于乘子法的卸载决策策略,证实了终端能耗和执行时延远低于本地执行。文献[21]同样是以卸载决策问题的联合凸优化为基础进行任务卸载的求解,降低了任务执行开销。以上两篇文献则主要侧重于单纯的串行或并行任务,不是更为复杂的工作流结构任务的调度与卸载决策问题。综合考虑已有工作,对于任务的卸载决策通常是一种one-by-one模式的。现实情况是,卸载任务和本地执行任务可能是工作流结构中的一条路径,是否可以将处于一条路径上的若干任务集进行整体卸载是值得研究的问题,此时不仅可以节省大量的任务间数据的传输时间,还可以降低本地设备的执行能耗。
2 基本模型
表1首先给出主要的符号定义说明。

表1 符号说明
2.1 系统模型
边缘云系统中,假设拥有一个可提供多虚拟机VM实例的边缘云服务器,其可用的虚拟CPU(vCPUs)集合定义为Cv cpu,Cv m为虚拟机实例集合,则|Cv m|≤|Cv cpu|。令vi表示虚拟机实例i,ci,j表示虚拟机实例i上的vCPUj,且ci,j∈Cv cpu。假设边缘云服务器拥有固定数量的虚拟机实例数量,即|Cv m|为固定值,无法重新开启新的虚拟机实例。
2.2 工作流模型
对于一个工作流,其任务之间拥有数据依赖性。每个任务可视为一个指令集,即一个可执行单元。每个移动客户端拥有一个工作流的执行需求。现令总工作流数量为M,即表示移动客户端的数量也为M。将每个工作流表示为Wk=Gk(Vk,Ek),工作流集合定义为W。为了简化表达,可将移动客户端的所有工作流联合为一个更大规模的工作流W进行调度,定义为W=G(V,E),任务和边分别定义为ti∈V和ei,j∈E。伪任务STARTtpstart可作为合并工作流的入口任务(也称开始任务),伪任务ENDtpend可作为合并工作流的出口任务(也称出口任务)。同时,wpstart=wpend=0,即两个伪任务的负载量均为0。通过生成合成工作流结构,每个任务可根据其优先级同步进行调度。
工作流结构中,令pred(ti)表示ti的前驱任务集合,succ(ti)表示ti的后继任务集合。若pred(ti)=∅,则称ti为START任务;若succ(ti)=∅,则称ti为END任务。
如图1描述了多个工作流如何合并为一个工作流W及每个工作流任务如何分配与调度的过程。图中,3个工作流W1、W2和W3合并为W。W中,伪START任务和伪END任务被添加为新的START任务和END任务。不失一般性,伪START任务和伪END任务与其它任务的通信时间均为0。
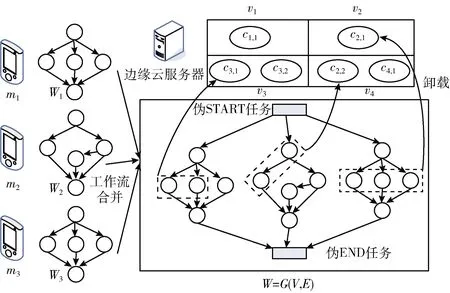
图1 工作流合并调度
2.3 代价模型
令任务ti的负载为wi。ti生成的数据量,即从ti发送至tj的数据量为di,j。对于伪START任务和伪END任务,wpstart=wpend=0,dpstart,i=dj,pend=0,且ti,tj∈V。任务ti在mk上的处理时间定义为
(1)
数据量di,j在mk与边缘云服务器之间无线链路上的传输时间定义为
Tc(di,j,rk)=
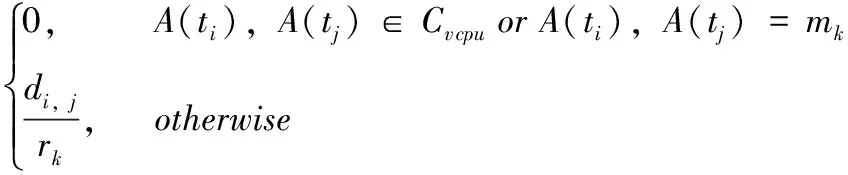
(2)
式中:A(ti)表示ti的分配目标,A(ti)∈Cv cpu表明ti在边缘云的vCPU上执行,rk表示边缘云服务器与mk间的无线数据通信速率,根据香农理论可定义为
(3)
式中:βk表示mk的通信带宽,pk表示mk的发送功率和接收功率,gk表示mk与基站间的信道增益,ω表示背景噪声功率,CNk表示mk利用的通信信道。显然,若移动客户端利用相同的信道,则rk会变小。
定义Eexec(ti,mk)为在mk上执行ti的能耗,Ein(ei,j,mk)为边缘云至mk间ei,j的传输能耗,Eout(ei,j,mk)为mk至边缘云间ei,j的传输能耗,分别定义为
Eexec(ti,mk)=τkwi
(4)
式中:τk表示每个mk∈M在单位周期内的能耗因子,假设对于mk∈M和ti∈V,wi∝Eexec(ti,mk)。发送和接收能耗分别表示为
Ein(ei,j,mk)=pkTc(di,j,rk),A(ti)∈Cv cpu
(5)
Eout(ei,j,mk)=pkTc(di,j,rk),A(tj)∈Cv cpu
(6)
2.4 调度时长
本节描述如何确定每个任务ti在调度目标A(ti)上的开始执行时间Ts(ti,A(ti)),进而推导出任务调度时的整体调度时长。定义Tf(ti,A(ti))为ti的完成时间,则
Tf(ti,A(ti))=Ts(ti,A(ti))+Tp(ti,A(ti))
(7)
式中:A(ti)∈M∪Cv cpu。令fList表示空闲任务集,即其前驱任务已被调度的任务集。对于fList中的每个任务,可以推导出任务的数据就绪时间。数据就绪时间DRT为所有前驱任务中的最大数据到达时间,且DRT应为每个任务的最早开始时间,实际开始时间要晚于DRT,原因在于:当一个任务th∉pred(tj)在tj之前调度,且A(th)=A(tj)时,任务tj无法开始执行。任务tj在mk上的DRT推导为
(8)
式中:若A(tj)∈Cv cpu且A(ti)∈Cv cpu,或ti和tj均被分配至mk时,有Tc(di,j,rk)=0。然后,可以利用DRT推导任务在调度目标上的开始执行时间Ts(tj,A(tj))为
Ts(tj,A(tj))=
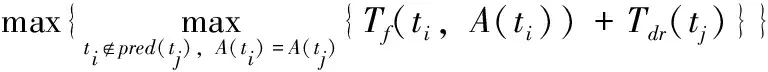
(9)
工作流的调度时长即为END任务的完成时间,定义为
Tf(tend,A(tend))=Ts(tend,A(tend))+Tp(tend,A(tend))
(10)
2.5 调度目标函数
综合以上模型,边缘云中工作流调度与卸载决策的优化目标函数可定义为
minTf(tend,A(tend))
(11)
约束条件为
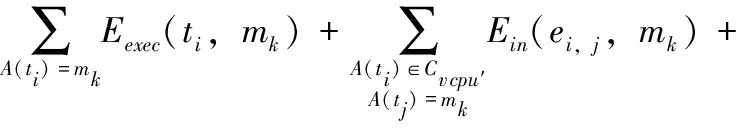
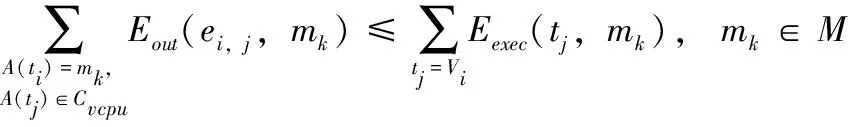
(12)
(13)
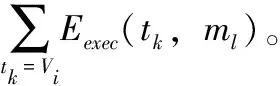
3 PCTSO算法设计
3.1 算法总体流程
如2.2节所述,来自所有移动客户端的工作流可以合并为一个整体工作流结构W=G(V,E)。式(12)表明,每个移动客户端的任务调度能耗必须小于或等于初始执行能耗。初始状态下,每个移动客户端mk拥有其自身的工作流任务Wk=Gk(Vk,Ek)。初始调度时长SLinit(Wk)和初始调度能耗Einit(mk)可以分别定义为
(14)
(15)
由目标函数可知,PCTSO算法需要实现Tf(tend,A(tend))≤SLinit(Wk),且对于每个mk∈M,Einit(mk)需要尽可能降低。
算法1给出了PCTSO算法的完整执行流程。算法输入为边缘云服务器的vCPU集合、移动客户端集合M以及合并工作流W。算法输出为工作流中每个任务与vCPU集合和移动客户端间的调度关系,其中包含着任务卸载决策和任务调度解。UEX表示未调度任务集合,fList表示空闲任务集合。步骤(1)对UEX和fList进行初始化。步骤(2)~步骤(14),算法执行迭代步骤,输出UEX≠∅时的调度方案。步骤(3)选择在fList中拥有最大优先级level的目标调度任务tpivot。然后,步骤(4)调用算法2的CTSO算法生成从任务tpivot开始的连续任务集合Sfree。对于Sfree中的每个任务,按序将其分配至vCPU的空闲时槽中,以便尽可能早的执行,即步骤(7)、步骤(8)。最后,算法通过追溯succ(t)对UEX和fList进行更新,且t∈Sfree,即步骤(9)、步骤(10),或Sfree=∅时如步骤(12)~步骤(14)执行。当追溯完所有任务后,即UEX=∅时,算法完成调度过程,返回调度解。
算法1:PCTSO算法执行过程
输入:vCPU集合Cv cpu,移动客户端集合M,合并工作流W
输出:ti∈V至Cv cpu∪M间的映射调度方案
/*UEX为未调度任务集,fList为空闲任务集*/
(1)UEX←V,fList←START tasks
(2)whileUEX≠∅do
(3)tpivot←the task satisfying Equ.(18)fromfList
(4)Sfree←CTSO(tpivot)
(5)ifSfree≠∅then
(6)whileSfree≠∅do
(7)t←head ofSfreeand removetfromSfree
(8) assigntto the idle time slot of a vCPU via the insertion-based technique
(9) removetfromUEXandfList
(10) updatefListby tracingsucc(t)
(11)else
(12) assigntpivotto the idel time slot ofmk
(13) removetpivotfromUEX
(14) updatefListby tracingsucc(tpivot)
(15)return映射调度解
图2为PCTSO算法的执行流程。接下来需要进一步解决的问题是:
图2 PCTSO算法执行流程
(1)如何从fList中选择待调度目标任务,即如何决定任务优先级;
(2)如何决定需要卸载至边缘云上或移动客户端执行的任务集合。
3.2 基于优先级的任务选择机制
任务选择即从空闲任务列表fList中选择调度任务。定义在mk上任务ti至END任务的剩余时长为
(16)
假设ti在mk上执行,则ti的开始时间可通过式(9)推导得到。则任务选择的优先级level(ti)可定义为
level(ti)=Ts(ti,A(ti))+Tp(ti,mk)+rlevel(ti)
(17)
式中:Ts(ti,A(ti))表示ti在mk上执行时的开始时间,level(ti)表示如果ti之后的每个任务分配至边缘云,调度时长的占优路径。算法试图通过最小化处于占优路径上的任务的开始时间实现调度时长的最小化。对于属于fList内的每个任务,满足以下条件的任务将被选择为目标调度任务
(18)
3.3 基于连续任务选择的卸载机制
由于无法确保可以通过将任务分配至边缘云vCPU使其得到比在移动客户端mk上更小的调度时长和能耗,因此,如果通过将任务插入至vCPU的空闲时槽中可以得到更小的调度时长和能耗,即可以接受任务卸载至该vCPU执行。以下对如何实现降低调度时长作出描述。首先,假设选择的调度任务为ti∈fList,且假设ti从mk卸载至vCPUcp,q。那么,卸载任务ti的时间差值计算为
ΔTp(ti)=Tp(ti,cp,q)-Tp(ti,mk)
(19)
ΔTs(ti)=Ts(ti,cp,q)-Ts(ti,mk)
(20)
同时,Tc(di,j,rk)为最新生成,tj∈succ(ti),tj调度于mk上。因此,通过卸载ti降低调度时长的一个条件是
ΔSL(ti)=Tc(di,j,rk)+ΔTp(ti)+ΔTs(ti,A(ti))≤0
(21)
式中:ΔSL(ti)表示ti之后调度的所有任务,在没有数据等待时间的情况下,调度时长的增加值。尽管如果卸载ti,可得ΔSL(ti)>0,但仍然存在一种可能:即卸载ti和tj,ΔSL(ti∪tj)≤0,tj∈succ(ti),Tc(di,j,rk)远大于Tp(tj,A(tj)),由于Tc(di,j,rk)是边缘云虚拟机本地计算值。由此可见,卸载相互关联的多个任务可能导致在移动客户端的调度时长和能耗的同步降低。假设ti为从fList中选择的卸载侯选任务,且假设ti+1∈succ(ti),ti+2∈succ(ti+1),…,ti+r∈succ(ti+r-1)。对于ti+j∈succ(ti+j-1),假设除了任务ti+j-1,在pred(ti+j)内的任务已经被调度。定义该类任务为Sfree的输入,即满足以下条件的任务均被放入Sfree内
(22)
式中:假设ts调度于mk上。图3展示了Sfree的生成示例,假设ti为从fList内选择的任务。示例假设对于Sfree={ti},ΔSL(Sfree)>0,即如图3(b)所示。而如果更多任务添加至Sfree,则ΔSL(Sfree)<0,如图3(c)和图3(d)所示。从图3(b)~图3(d)可以观察到,对于ΔSL(Sfree)>0的主要影响因素是Cv cpu中vCPU与移动客户端mk间的通信时间,该通信时间仅发生在Sfree内的最后一个任务的数据通信输出上。如果该通信时间小于Sfree内的任务执行时间之和ΔTp(Sfree),则有ΔSL(Sfree)<0。因此,尽管有ΔSL(ti)>0,ΔSL(Sfree)<0依然有可能成立,这取决于新生成的通信时间与Sfree内处理时间之和之间的关系。
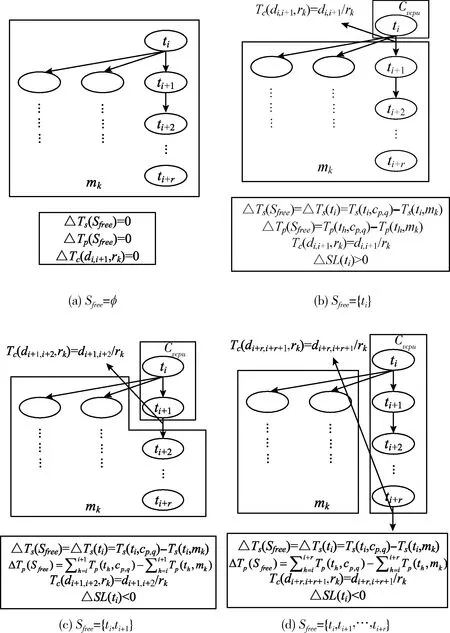
图3 连续任务选择卸载示例
能耗约束方面,对于属于Vk的所有任务,必须满足以下条件才能进行所选任务的调度
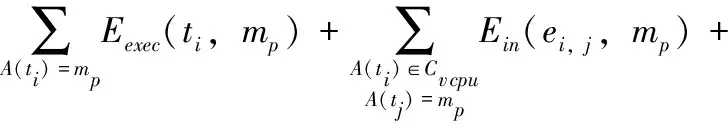
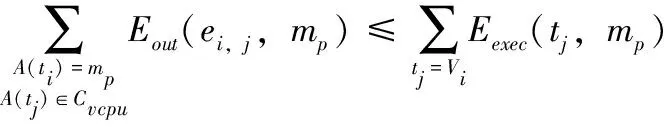
(23)
如果满足式(22)和式(23),在Sfree内的每个任务可被选择为卸载调度任务,并被插入至vCPU的空闲时槽中,实现最小化的Tf(tk,cp),tk∈Sfree。
推导Sfree的详细过程如算法2所示,将其命名为连续任务选择卸载决策算法CTSO。算法输入空闲任务集合fList中拥有最大优先级的任务,输出连续选择卸载任务集合。步骤(1)~步骤(3)对相关参数进行初始化操作,其中,tmin表示对于ΔSL(Sfree)的最佳任务。步骤(4)~步骤(16),算法通过追溯Sfree内tpred的后继任务以构造Sfree。步骤(8)中,如果ΔSL(Sfree)得到最小值,且ΔSL(Sfree)≤0,则可以将任务t添加为tmin以更新Sfree。否则,Sfree不发生变化,即步骤(13)~步骤(15)。步骤(4)~步骤(16)中,假设Sfree拥有两条以上记录,步骤(17)中,算法检测Sfree={ti} 的情形。然后,算法返回Sfree。接受卸载ti的条件是ΔSL≤0,即:每个任务添加至Sfree时,算法寻找Sfree,使得ΔSL(Sfree)最小化,且ΔSL(Sfree)≤0。由于在每个任务添加至Sfree时,ΔTs(ti,A(ti))不发生变化,仅能观察到Tc(di+r,s,rk)和∑ti∈SfreeΔTp(ti)的变化行为。
算法2:CTSO算法执行过程
输入:集合fList中拥有最大level的任务ti
输出:Sfree:连续选择任务集
(1)Sfree←{ti}
(2)tpred←ti,tmin←∅
(3)ΔSLpre←ΔSL(Sfree)
(4)whileS←chkFreeCandidate(tpred)≠∅do
(5)tmin←null
(6)whilet∈Sdo
(7)Sfree←Sfree∪{t}
(8)ifΔSL(Sfree)≤ΔSLpre∧ΔSL(Sfree)≤0then
(9)if(23)is satisfied withA(t)∈Cv cpu,t∈Sfreethen
(10) ΔSLpre←ΔSL(Sfree)
(11)tmin←t
(12)else
(13)Sfree←Sfree-{t}
(14)else
(15)Sfree←Sfree-{t}
(16)tpred←tmin
//若没有任务添加至Sfree,则需要检测Sfree={ti}的情形
(17)ifSfree={ti}then
(18)ifΔSL(Sfree)>0∨(23)条件不满足then
(19)Sfree←∅
(20)returnSfree
//函数chkFreeCandidate()定义,用于判断当前任务是否是侯选空闲任务,可放入Sfree中。
(21)FunctionchkFreeCandidate(tcan)
(22)Sout←∅,FindFly←true
(23)whiletsuc∈succ(tcan)do
(24)whilet∈pred(tsuc)do
(25)ift=tcanthen
(26)continue
(27)else
(28)ift∈UEXthen
(29)FindFlg←false
(30)break
(31)ifFindFlg=truethen
(32)Sout←Sout∪{tsuc}
(33)FindFlg←true
(34)returnSout
4 仿真分析
4.1 实验配置
通过工作流仿真平台WorkflowSim[22]与云计算环境仿真平台CloudSim的有效融合进行边缘云中工作流的卸载与调度仿真,软件开发环境为JDK1.7.0.51,硬件开发环境为Inter(R)Core i-7-5600U 2.6 GHz型号CPU,内存为8 GB。为了实现对于PCTSO算法的实验仿真,仿真平台WorkflowSim在CloudSim的基础上进行层次拓展,提供工作流层次的仿真。在平台中,以有向无环图定义工作流模型,以顶点定义任务。由于工作流任务数巨大,平台还引入task clustering技术将任务进行集群。PCTSO算法具体通过扩展WorkflowPlanner类实现,在getPlanningAlgorithm()方法中进行添加。表2给出了相关仿真参数配置,其中,参数CCR表示工作流中计算密集型任务与通信密集型任务间的比例。实验利用随机生成的工作流结构和Montage科学工作流结构进行测试,具体应用可以模拟创建移动手机端的图像处理任务量。
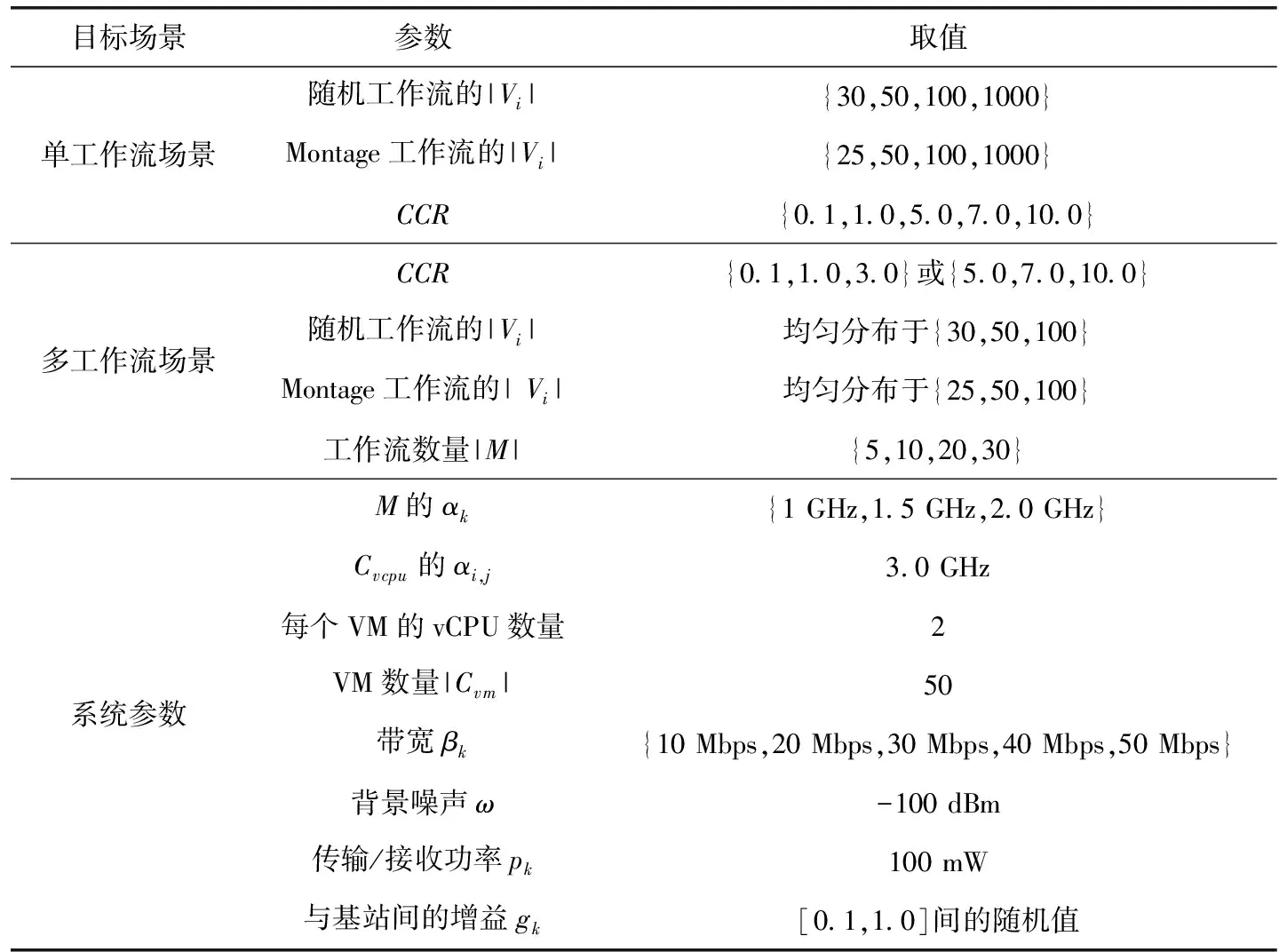
表2 仿真参数配置
除了能耗因素外,引入调度时长比率SLR进行性能比较分析,定义为
(24)
式中:CPw表示根据总执行时间得到的工作流W的关键路径,SL表示工作流W的调度时长。假设每个vCPU拥有相同处理频率,则ci,j在不同vCPU之间取值也相同。
选择以下几个算法进行性能对比:第一种算法为本文算法的低级版本non-PCTSO。该算法与PCTSO的区别在于:以单个任务为单位判断卸载时是否能在调度时长和调度能耗上得到优化,而没有考虑其后继任务的卸载决策问题,与本文的连续任务选择卸载机制完全不同。第二种算法为能效感知卸载算法EAOA[15],算法同步考虑了时间和能耗的约束,并建立了工作流调度跨度和执行能耗的多目标优化模型,与本文不同的是没有考虑多工作流的卸载决策以及没有考虑连续多任务的卸载问题。第三种算法为负载均衡的工作流卸载算法LBOA[16],该算法更多考虑的是将移动终端的负载均匀地分布于边缘云端和移动客户端,没有过多考虑调度效率和执行能耗问题。
4.2 单工作流测试场景
实验首先进行单工作流调度场景的性能测试,实验中获取了在变化的CCR和任务量的情况下20次实验得到的调度时长和调度能耗的均值情况。图4是两种工作流结构得到SLR指标情况。从图4(a)、图4(b)的结果看出,对于单工作流的调度场景而言,当增大CCR的取值时,算法的调度时长是递增的,这是由于CCR增大即表明工作流结构中的计算密集型任务的数量比例的增加,这势必会相应增加任务的执行时间,SLR指标也相应增加。本文提出的PCTSO算法在所有CCR取值下均得到了最小的调度时长。当CCR=7.0和10时,PCTSO与non-PCTSO间的SLR差距变得更大,这是由于在non-PCTSO算法中仅有拥有更小数据输出的任务可被卸载,导致任务卸载量较小,大部分任务集中于移动客户端上执行,任务执行效率会远低于边缘云端的任务执行效率。而在PCTSO算法中,更多任务卸载至边缘云执行,能耗也得到了有效降低。LBOA算法在相对较低的CCR取值时调度时长接近甚至低于EAOA算法,此时工作流结构中的任务类型并没有太大差别,计算密集型和通信密集型任务数量差距不大。但随着CCR的增加,LBOA也显示出一定优势,说明在单工作流场景下负载均衡的任务调度方式可以更好有效利用本地资源和边缘云端资源。单随机工作流和单Montage科学工作流的测试中算法的演变趋势不变,但由于Montage工作流多以I/O密集型任务为主,性能表现还是略有差异。表3给出了单工作流场景下的不同算法的能耗节省比例,表中的取值是对比所有任务在移动客户端执行时得到的执行能耗的节省比例。PCTSO的原始意图是可以确保其能耗大幅小于移动客户端的执行能耗,并不能达到最小化能耗。然而,由于算法中的卸载任务数量大于non-PCTSO,故在所有的CCR取值下,其能耗性能明显优于non-PCTSO算法以及另外两种对比算法。EAOA和LBOA两种算法的能耗节省比例始终比较相近,LBOA在多数的CCR取值下比EAOA节省更多的能耗,反应出负载均衡的思路可以有效降低总体能耗,利益于较少的任务卸载的同时,传输能耗也更少。EAOA虽然是多目标的优化模型,但是没有考虑工作流的任务结构,始终以单个任务为目标进行卸载决策,决策结果相比本文算法不是最优的。综合整体结果来看,连续分配信赖型任务可以导致更好的能效。
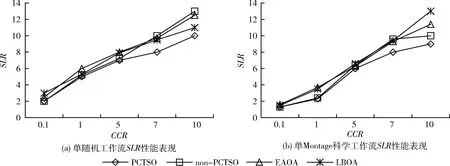
图4 单工作流执行情形
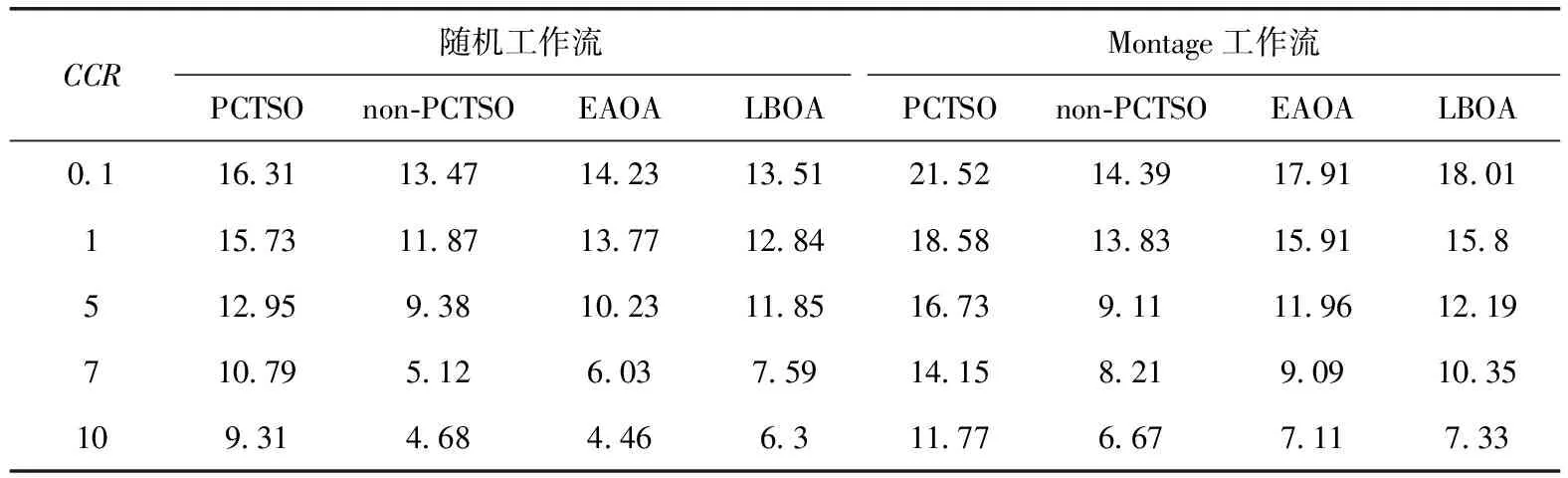
表3 单工作流场景下的能耗节省比例/%
4.3 多工作流测试场景
多工作流情形中的调度时长为所有工作流中的最大时长,本实验测试了不同规模的多工作流执行场景,并取结果的均值。从图5(a)、图5(b)可以看到,在所有工作流规模下,PCTSO算法均拥有最佳的SLR表现,其调度时长平均低于3种对比算法约30%左右,这与单工作流执行场景类似,说明了PCTSO算法的连续任务选择的卸载机制在降低整体工作流调度时长方面是有效可行的。总体来说,调度工作流数量的增加会使得调度时长(所有工作流中的最大时长)有所增加。在多随机工作流结构中,3种对比算法的SLR表现起伏较大,说明对于任务的卸载决策并不能生成在调度效率上比较稳定的结果。本文的PCTSO算法始终以工作流任务的层次结构为基础,首先基于任先级选择待调度任务,然后以该任务为基础,考虑与之关联的连续任务集的卸载决策,而不是以单个任务为基础做卸载决策,有效提升任务执行的并行度及调度效率。表4给出多工作流场景下的能耗节省比例情况。显然,PCTSO算法的能效也是最高的,non-PCTSO的能耗节省值低于另外两种对比算法,这也印证了连续任务选择的卸载机制是可以有效降低调度时长和调度能耗的。EAOA与LBOA两种的能耗节省比例与单工作流调度场景结果相似,LBOA算法略优。在考虑传输能耗和传输延时的情况下,结合工作流任务结构特征做出卸载决策显然比单个任务的卸载决策具有更高的效率。
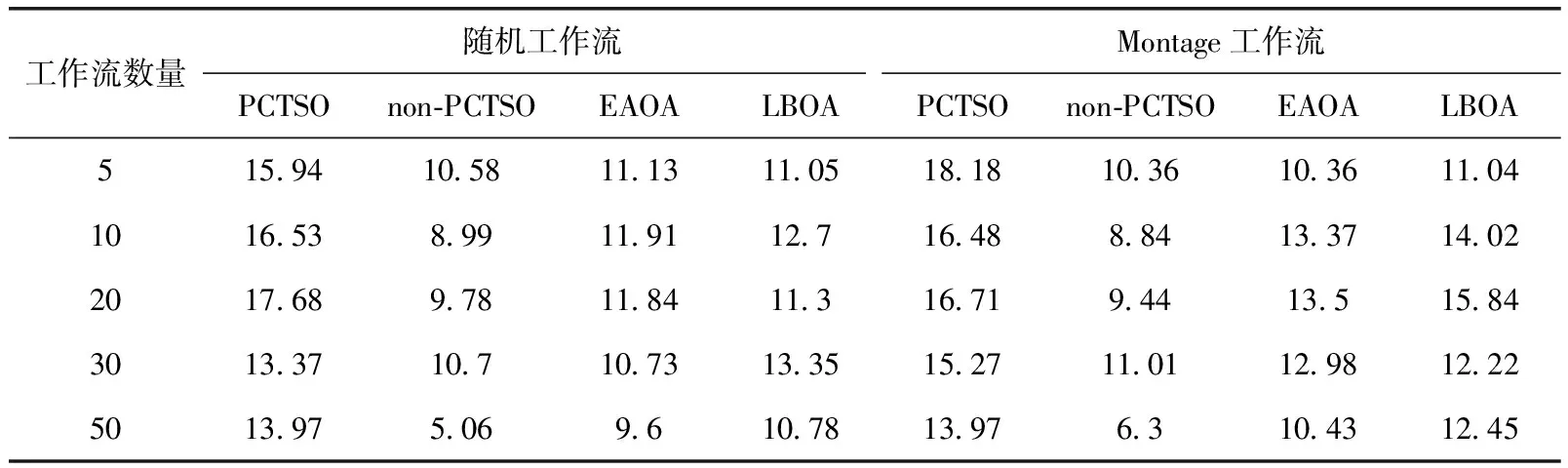
表4 多工作流场景下的能耗节省比例/%

图5 多工作流执行情形
5 结束语
本文以优化执行时长和降低移动端能耗为目标,提出一种基于边缘云环境的工作流调度与卸载决策算法。算法首先依据工作流内任务间的结构层次特点,设计了基于优先级的待调度选择机制;然后设计了基于连续任务选择的卸载机制,验证了连续依赖型任务的整体卸载可以更有效利用边缘云端服务器资源,提升任务执行并行度。利用不同规模的随机工作流结构和Montage科学工作流进行了仿真测试。结果表明:①该算法在满足能量约束的同时,基于连续任务选择的卸载机制的调度效率可以平均提高约25%;②在相同工作流调度规模下,算法的执行能耗可以降低约15%。实验结果表明该算法是有效可行的。进一步的工作可以在考虑通信链路可靠性的基础上,设计相应的任务卸载决策算法,从而实现更加安全可靠的工作流任务卸载与调度策略。
