基于CEEMDAN和散布熵的飞行数据滤波
2021-09-16郗厚山
耿 宏,郗厚山
(中国民航大学 电子信息与自动化学院,天津 300300)
0 引 言
大型民航客机的飞行数据在飞行事故分析、视情维修、异常检测、飞行品质监控等方面起到重要作用[1,2]。由于飞行环境、飞机自身运动状态的复杂性及机载设备的电磁干扰等因素的影响,实际记录的飞行数据存在干扰噪声。因此,对飞行数据的有效去噪是其后续分析和各领域应用的重要前提。
传统的飞行数据滤波方法如低通滤波、卡尔曼滤波[3]、滑动多项式回归模型等,由于飞行数据具有非线性、非平稳的特征,处理后的数据在瞬变信号处容易产生局部震荡,去噪效果不佳。基于小波变换的飞行数据滤波目前已被较广泛应用[4,5]。文献[4]采取平稳小波去噪的方式滤除燃油流量、发动机N1等飞行参数的野值和噪声。基于小波变换的飞行数据滤波可以取得较好的去噪效果。但是需要依据经验或者进行大量的实验以选取恰当的小波基、分解层数,无自适应性。
自适应完备集合经验模态分解(complete ensemble empirical mode decomposition with adaptive noise,CEEMDAN)是一种基于数据自身时间尺度特征,将信号分解为固有模态函数(intrinsic mode function,IMF)的方法[6-8]。散布熵(dispersion entropy,DE)[9]可以用来分析时间序列的复杂性,它为判断各IMF分量的噪声含量提供了依据。故提出一种基于CEEMDAN和DE的飞行数据滤波方法,其具有自适应的优点,无需数据的众多先验知识。经该方法去噪后的飞行数据平滑性和相似性较好,满足实际应用的需求。
1 算法原理
1.1 CEEMDAN分解
CEEMDAN算法的基础是经验模态分解(empirical mode decomposition,EMD),但它弥补了EMD算法具有模态混叠的不足,且完备性较好[10]。CEEMDAN算法的具体分解过程为:
(1)求解时间序列x(t)的第一阶IMF和余项。向x(t)附加一系列自适应的辅助白噪声,构成新的时间序列xi(t)
xi(t)=x(t)+ω0ξi(t),i∈(1,2,…,I)
(1)
式中:xi(t)为第i次添加白噪声后的时间序列,ω0为噪声系数,ξi(t)为白噪声。I为添加辅助白噪声的次数。

(2)
(3)
(2)向余项r1(t)中继续添加若干辅助白噪声,构造一组新的时间序列r1i(t)
r1i(t)=r1(t)+ω1E1(ξi(t)),i∈(1,2,…,I)
(4)
采用EMD同(1)对r1i(t)进行处理,求得x(t)阶次为2的IMF以及余项,如式(5)、式(6)所示。记Ej(·)为EMD分解得到的第j个IMF分量
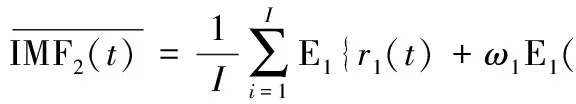
(5)
(6)
(3)重复执行式(7)、式(8)所示递推关系式,直到最后的余项序列不能继续进行EMD分解时停止,求得其余的IMF
(7)

(8)
最终时间序列信号x(t)被分解为
(9)
K为x(t)的最大分解阶次,R(t)为x(t)经CEEMDAN最后分解得到的余项。
1.2 飞行数据噪声分析
民航飞机的飞行数据主要通过快速存取记录器(quick access recorder,QAR)、飞行数据记录器(flight data recorder,FDR)等机载设备进行记录[1]。记录器按时间顺序采样,记录了起飞、爬升、巡航等各个飞行阶段飞机实际的性能数据和状态数据。但是,不同飞行阶段的数据变化特征具有较大差异,例如在起飞阶段空速、气压高度、发动机N1等参数变化快且幅度大,而在巡航阶段其变化相对稳定。这要求飞行数据滤波算法具有多尺度分析的能力。
此外,飞行参数包括大气环境参数、发动机参数、气动参数等不同类型的参数,这些参数中包含的噪声类型和表现形式也不尽相同。例如:周期性噪声常规情况下是由飞机各种电气干扰及某些部件的周期性机械运转导致,体现为数据中的窄谱峰;脉冲噪声具有持续时间短和幅度大的特点,一般由电磁干扰等随机性干扰引起,体现为数据中的野值;导致飞行数据中存在宽带噪声的诱因较多,比如大气紊流的干扰、量化噪声等,体现为短时间内频繁抖动的数据。因此,噪声对飞行数据的干扰在数据中主要表现为以下两方面:一是存在野值,即数据中的异常点;二是存在短时间内频繁抖动的数据,其变化趋势呈现锯齿状。上述两种现象为飞行数据的实际应用带来较大阻碍。
总体上,飞行数据中包含的噪声大多数为高频干扰信号,而民航飞机作为一个六自由度的刚体动力学系统,其运动频率相对较低,通常不会超过10 Hz。因此,对飞行数据的去噪相当于是一个低通滤波的过程,但是使用传统的低通滤波器去噪,其截止频率难以确定,需要针对不同的飞行参数进行大量实验,且去噪效果不是很理想。利用小波阈值去噪的方式对飞行数据滤波同样存在上述问题,在缺乏飞行数据先验知识的情况下,小波基和分解层数的选取需要通过大量的实验以及结果的比对才能确定。有时为了获得更好的滤波效果,针对不同类型的飞行参数需要重新选取小波基和分解层数,实际应用的计算量较大。
从算法的原理可知,CEEMDAN算法可以基于飞行数据自身的时间尺度实现飞行数据的自适应分解,得到一组从高频到低频分布的IMF分量。这些IMF分别包含了飞行数据中不同频率成分的信息,相当于对飞行数据按照频率的高低进行了划分。此外,CEEMDAN算法具有自适应性,可适用于不同类型的飞行参数,且不受飞行阶段的影响。
1.3 基于CEEMDAN的飞行数据去噪原理
利用CEEMDAN算法能够简便且高效地获得包含不同频率信息的飞行数据IMF。依据对飞行数据的噪声分析,数据中的干扰信号集中存在于频率较高的IMF中,而有用信号大多数存在于频率较低的IMF中。因此,CEEMDAN分解阶次较低的IMF所含有的有用信息较少且容易被噪声完全掩盖。借鉴低通滤波的思想,将前N-1阶频率成分较高的IMF直接去除,使用其余阶次的低频IMF和余项叠加,获得滤波后的飞行数据。在保留大部分有用信息的同时,实现去除飞行数据中野值和噪声的目的。记Ik(t)为飞行数据经CEEMDAN分解得到的第k阶IMF。则此方式滤波后的飞行数据s(t),其表达式如式(11)所示
(10)
(11)
但是,直接剔除前N-1阶高频IMF的方式存在两个问题:①界限N需要主观设定,存在不确定性;②直接剔除的方式可以有效去除飞行数据中的多数高频干扰噪声,但是仍有部分宽带噪声存在于包含有用信号分量中,影响最终的去噪效果。
故本文在使用CEEMDAN算法分解飞行数据后,借助散布熵会随着时间序列复杂度的提高而增大的特性判断飞行数据IMF的噪声含量,据此确定界限N,优化基于CEEMDAN的飞行数据滤波,消除其中的不确定性。其次,借助阈值法对界限N处的IMF滤波,解决常规CEEMDAN滤波后的飞行数据仍存有部分干扰噪声的问题。
2 基于CEEMDAN和散布熵的飞行数据滤波
2.1 基于散布熵的IMF分量噪声判断
CEEMDAN去噪通常需要指标判断IMF的噪声含量,以避免盲目剔除IMF分量造成信号失真的问题,目前常用的指标有排列熵[8]、样本熵等。本文选取散布熵作为评判指标,相对于样本熵和排列熵,它具有计算速度快且兼顾时间序列幅值间关系的优点。
散布熵的值会随着时间序列复杂度的提高而增大,据此特性可以分析经CEEMDAN分解获得的飞行数据IMF分量。若飞行数据的IMF分量的散布熵值较大,则说明该IMF分量越不规则,复杂性越强,包含较多的噪声信号;反之,则说明该IMF是原时间序列信号中的有用信息。因此,当相邻IMF的散布熵值发生突变时,说明两个IMF分量的噪声含量急剧减少或增加,故本文以相邻IMF分量散布熵比值最大处,作为界限判断含噪IMF,克服了CEEMDAN去噪需要主观确定界限N的困难。
散布熵的求解过程如下所示:
步骤1 给定长度为M的时间序列x={xi,i=1,2,…,M},首先利用标准正态累积分布函数(normal cumulative distribution function,NCDF)将其映射为y={yi,i=1,2,…,M}
(12)
式中:σ和μ分别为时间序列x的标准差和期望,且yi∈(0,1),然后将y中每个元素yi利用线性变换即式(13)映射为c个类别(1~c),组成新的分类时间序列zc
(13)
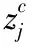
步骤2 对序列zc进行相空间重构,设嵌入维数取值为m,延迟时间取值为τ,则嵌入向量可表示为
(14)
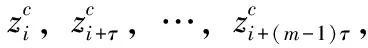
步骤3 对每种散布模式,计算其概率p(πv0,v1,…,vm-1),则按照Shannon信息熵的定义,散布熵的表达式定义为
(15)
De即为散布熵,常作为评判时间序列x不规则程度的指标。
2.2 阈值法去除IMF分量噪声
对于界限N处的飞行数据IMF,其散布熵相对较小,故IMF中有用信号占主导。因而可以使用阈值法去除临界IMF包含的少量干扰噪声。阈值法的去噪思想是噪声在飞行数据IMF分量中的系数幅值小于有效信号的系数幅值。通过选取适当的阈值,判定大于该阈值的IMF系数幅值为有用信号,保持其值不变;对于低于该阈值的系数幅值判定为噪声信号,将其减小至零,从而得到较为纯净的飞行数据IMF分量。
阈值法去除IMF分量噪声的核心在于阈值和阈值函数的选取,为避免将有用信号误当噪声信号去除的问题,此处采取一个相对保守的策略,即基于Stein的无偏似然估计阈值法[11]计算待处理IMF分量的阈值。
对待处理的IMF分量Ii(t),先对其每个采样点的IMF系数幅值求绝对值的平方,其值按照由小到大的顺序构成序列 {w1,w2,…,wL},L为Ii(t)序列的最大长度。若取 {w1,w2,…,wL} 第l个成员的平方根作为阈值,则该值作为阈值所造成的风险估计Risk(l),如式(16)所示
(16)
假若令风险函数Risk(l)取得最小值的 {w1,w2,…,wL} 序列元素索引为lmin,那么最终确定的第i个待处理IMF信号的阈值λi,其表达式为
(17)
阈值函数的选取一般采取两种形式,分别为硬阈值函数和软阈值函数[12]。若选用硬阈值函数处理临界IMF,会导致IMF出现不连续的间断点;软阈值函数虽然克服了硬阈值函数导致IMF分量产生间断点的问题,但其处理后的IMF分量与原IMF之间存在较大误差,会造成滤波后的飞行数据失真。目前,对阈值函数的改进较为成熟,有多种表达形式可供使用,且克服了上述两种形式存在的问题,实际应用效果良好。采用文献[12]得出的改进阈值函数,对IMF分量进行处理。改进的阈值函数的表达式为
(18)
式中:T=λe(1-α)(λ-|ωj,k|),u=1-e-α(|ωj,k|-λ)2,0≤α≤1。
2.3 算法实现
首先从译码后的飞行数据中选取待处理数据,通常将其保存成CSV格式。程序实现CEEMDAN算法,并设置辅助噪声的标准差,最大筛选迭代次数,进而利用CEEMDAN算法对待处理飞行数据分解,得到其众多IMF及余项。
其次,求解飞行数据各IMF的DE值即式(15)以及相邻IMF分量的DE比值(取前项与后项的比值),取DE比值最大处的IMF阶次作为界限N。界限N之前的飞行数据IMF分量,其中噪声信号占比较高,故直接将其去除;对包含少量噪声的IMF分量,采取式(16)和式(17)计算其阈值,进而使用改进阈值函数即式(18)对该IMF分量处理,去除IMF中系数幅值较小的数据,保留飞行数据IMF分量中的有用信号。
最后,通过对有用信号分量、余项以及阈值法处理后的IMF累加,以获得滤除干扰信号的飞行数据。算法流程如图1所示。

图1 CEEMDAN-DE飞行数据滤波算法流程
3 实验与分析
3.1 仿真数据去噪
为检验所提飞行数据滤波方法的实际应用效果,采用Matlab提供的标准bumps信号作为原始信号,其波形如图2(a)所示。向标准bumps信号添加白噪声作为仿真飞行数据,其波形如图2(b)所示,总采样点数为2048个,信噪比设置为9 dB。
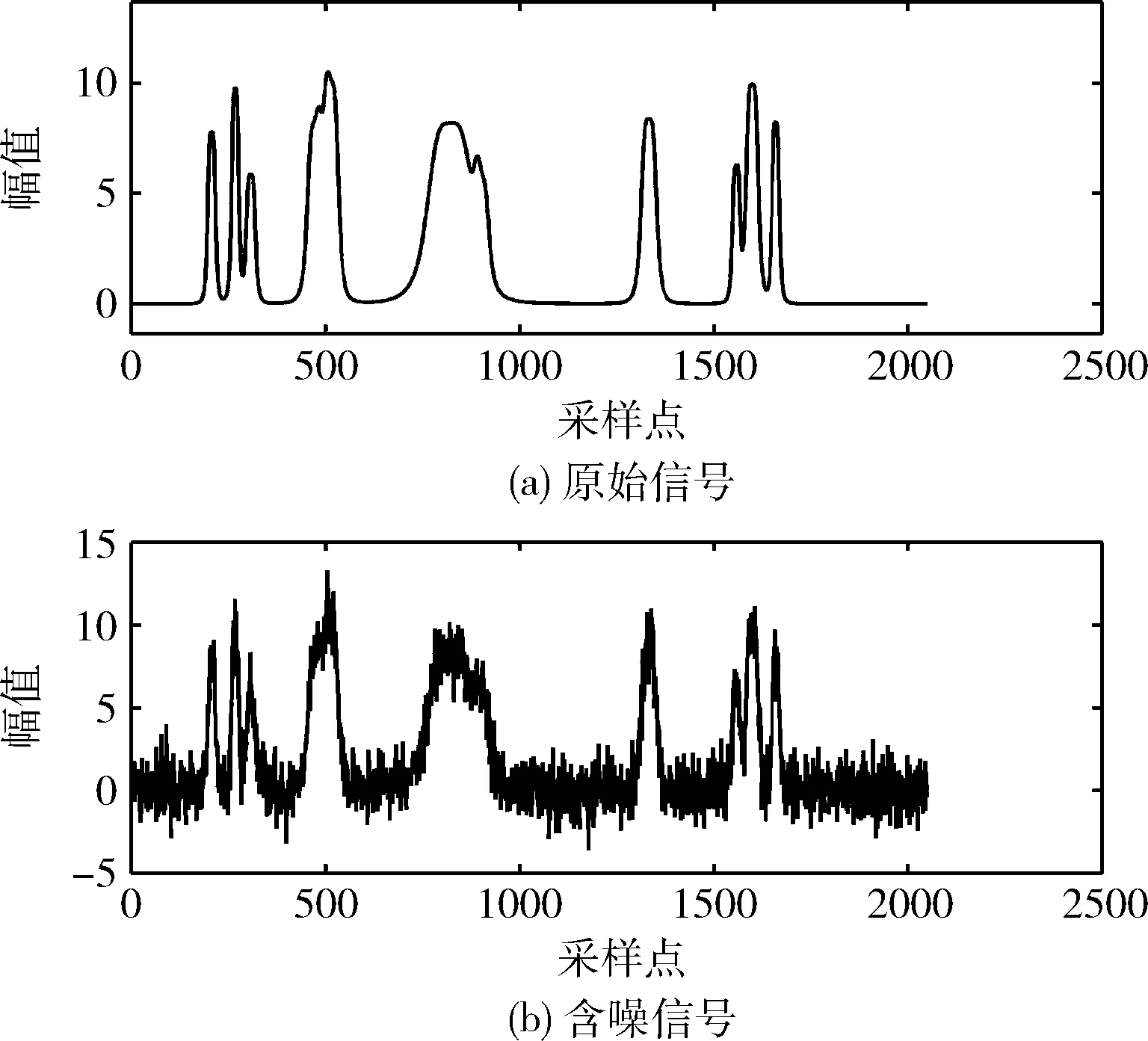
图2 原始信号与含噪信号
从图2(b)可以明显看出该bumps信号的轮廓完全被噪声掩盖,包含众多野值及剧烈抖动的数据。此外,采样后该信号与飞行数据同样为非线性离散时间序列,故可以作为验证数据。利用CEEMDAN算法分解含噪bumps信号,可获得其10个IMF及最后的余项,并计算全部IMF的散布熵。图3直观地展示了随CEEMDAN分解次数的增加,各阶次IMF散布熵的变动情况。图4展示了信噪比为9 dB的bumps经CEEMDAN算法分解得到的全部IMF的波形。
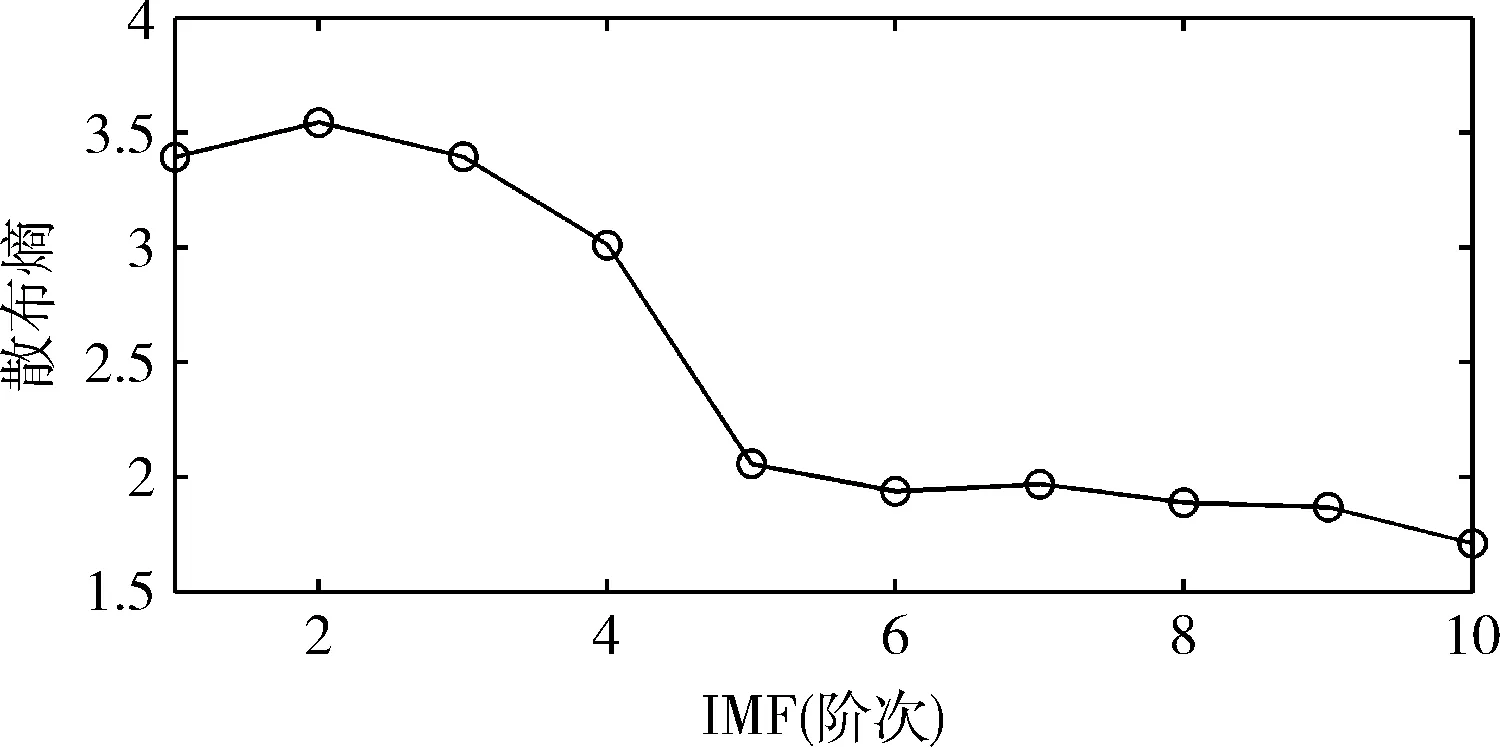
图3 各阶IMF分量的散布熵

图4 仿真数据经CEEMDAN分解后的IMF波形
通过计算,得到IMF1~IMF10的散布熵值为:[3.395,3.546,3.396,3.012,2.058,1.938,1.969,1.888,1.870,1.711],以及低阶IMF分量散布熵与相邻高阶IMF分量散布熵的比值为:[0.957,1.044,1.127,1.464,1.062,0.984,1.043,1.010,1.093]。IMF4与IMF5的散布熵比值最大,比值为1.464,说明在IMF4与IMF5分量之间噪声含量骤减而有用信号增多,如图3所示。因此,界限N取值为5,可以认为IMF1~IMF4分量中的有效信号完全被噪声掩盖,重构信号时将其直接去除;IMF5~IMF10分量的散布熵值较小,故在这些分量中有用信号的系数幅值占主导。但IMF5分量处在有效信号占主导的临界处,其包含有效信号的同时,不可避免地包含少量干扰信号,有待进一步处理。
通过观察图4(a)各阶IMF分量的波形可以进一步验证散布熵判断的准确性。IMF1~IMF4分量的波形紊乱,存在剧烈震荡,为噪声信号;IMF5分量中有用信号的波形较为清晰,但系数幅值在等于零处存在频繁地小幅度波动,且明显小于有用信号的系数幅值。因此,可以利用阈值法处理IMF的方式,将IMF5中的部分干扰噪声滤除。
为对比本文算法与EMD去噪、小波阈值去噪(小波基选为sym8小波,分解层数为5)以及传统CEEMDAN去噪算法的降噪效果,采用信噪比(signal-to-noise ratio,SNR)和均方根误差(root mean square error,RMSE)作为衡量指标,其结果见表1。

表1 各算法的SNR及RMSE
根据表1中各算法去噪后数据的信噪比和均方根误差,可以表明文本去噪算法在提高数据信噪比和保持与原始数据相似性方面,效果最好。
上述各种算法的实际应用效果,如图5所示,图中小框内的波形为信号第3个尖峰处的放大图。可以看出,EMD去噪算法对仿真数据的滤波效果不够理想,依旧含有较多频繁震荡的数据;经小波阈值去噪算法滤波后的数据虽然较为纯净,但在数据的第3个尖峰处过于平滑,丢失原bumps信号的部分细节信息,导致信号失真。传统CEEMDAN去噪算法虽然效果优于EMD去噪,但是未考虑临界IMF分量中包含的少部分噪声,导致去噪不彻底且波形平滑性较差。文中算法滤除噪声的结果,如图5(d)所示,其与原bumps信号波形的相似性最好,有效保持了在尖峰处的细节信息且波形相对平滑,无频繁震荡的数据。
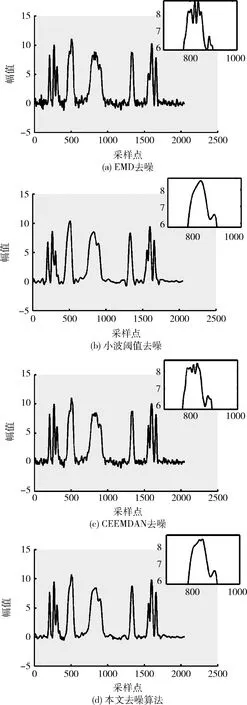
图5 去噪效果对比
3.2 实际飞行数据去噪
用于实验的飞行数据来源于某航空公司译码后的QAR数据,本文选取其中某航班一次完整飞行过程中记录的发动机N1数据进行去噪,以验证本文算法对实际飞行数据的滤波效果。所选取的飞行数据长约8000 s,真实记录了民航飞机在起飞、爬升、巡航等各个飞行阶段的发动机N1参数。发动机N1参数由涡扇发动机风扇的抬轮速度提供,能够表征发动机的推力大小,是用于民航发动机控制和监控的关键参数之一。实际记录的发动机N1数据如图6所示。
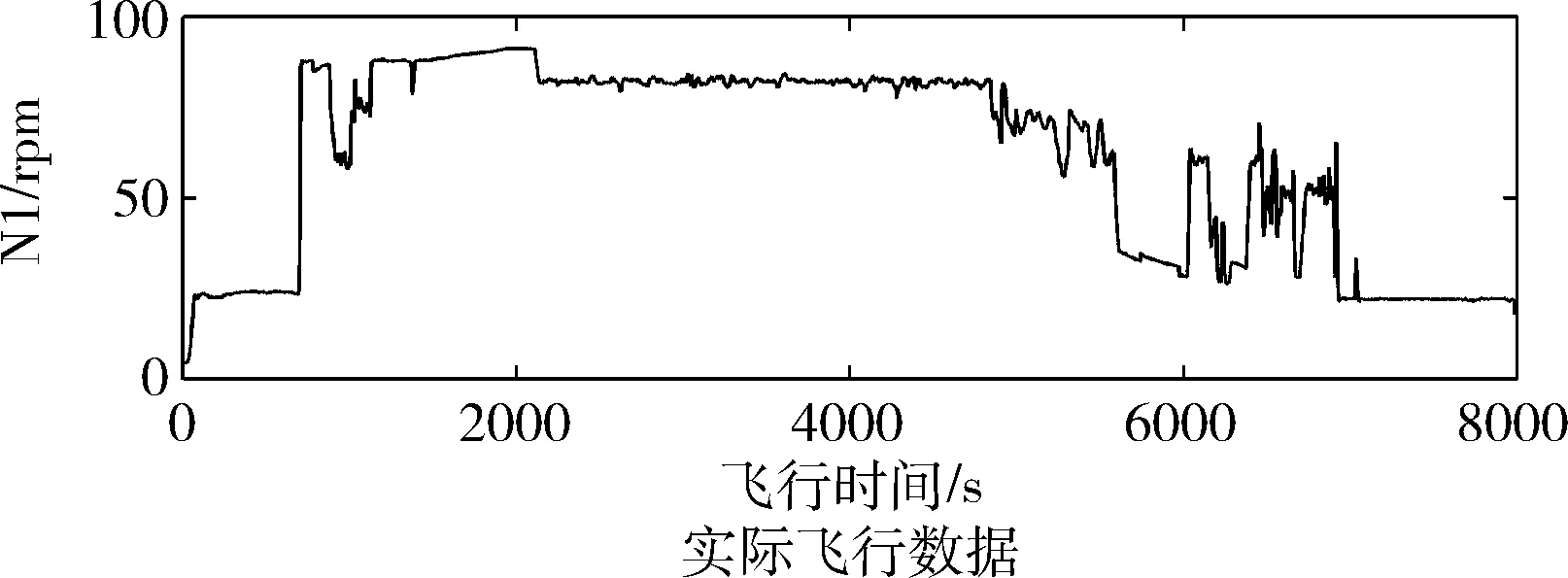
图6 实际飞行数据
如图6所示,实际发动机N1数据在飞机巡航阶段的变化较为稳定,但仍受到气流冲击等随机干扰的影响,导致存在小幅度频繁震荡;而在下降和进近阶段,为了实现准确的飞行速度控制,发动机的推力会较为频繁地改变。因此,发动机N1参数在这个阶段的波动较为剧烈,更容易受到各种干扰噪声的影响。故QAR实际记录的N1数据中会出现较多的野值点以及局部频繁震荡的数据;另外,数据中存在较多离散的窄谱峰。利用EMD算法、小波阈值以及本文算法分别对QAR记录的发动机N1数据进行滤波,其结果如图7所示,图7中小框内的波形为信号最后一个尖峰处的放大图。

图7 实际飞行数据去噪效果对比
在使用EMD对N1数据分解时,共获得15个IMF分量,通过多次实验验证,确定去除前5个被噪声掩盖的IMF可获得最佳滤波效果。从图7(a)所示波形得知,基于EMD的数据滤波虽有效剔除了N1数据中的野值,但因EMD存在模态混叠的问题,在原野值点处产生了震荡数据,导致重构后的N1数据波形不够平滑。
图7(b)为使用小波阈值法对发动机N1数据的滤波效果。在滤波过程中,为获得较好的效果分别使用MATLAB提供的db系列以及sym系列小波基多次进行实验,同时需要考虑分解层数的影响,滤波步骤相对复杂。最终,选取sym8小波作为小波基,分解层数设置为4,其阈值函数如式(18)所示,成功滤除了飞行数据中的野值。但是,对N1数据中众多局部小幅度频繁波动的数据,其滤除效果相对较差。
使用CEEMDAN算法对该发动机N1数据自适应分解,共获得13个IMF分量,借助散布熵可以快速辨别出前4个IMF为被噪声掩盖的IMF,将其去除。其次,使用阈值法对阶次为5的IMF进一步滤波,去除IMF系数幅值较小的数据,然后重构发动机N1数据,其波形如图7(c)所示。滤波结果能够较为真实地保持发动机N1数据在不同飞行阶段的变化特征,而且数据波形平滑、清晰,无毛刺、野值以及局部频繁波动的数据。
实验结果表明,本文滤波方法对实际飞行数据同样具有良好的滤波效果,且不受飞行阶段的影响。相比其它两种方式,其在滤波步骤上得到简化,且减少了局部震荡数据的存在。
4 结束语
为简便、有效地去除飞行数据中的高频干扰,提高后续分析结果的准确度,本文综合散布熵的特性以及CEEMDAN能自适应分解非线性时间序列信号的优点,提出一种飞行数据滤波方法。在缺乏飞行数据先验知识的状况下,使用CEEMDAN算法,基于数据自身的时间尺度实现了对飞行数据的自适应分解;借助散布熵,简单高效地识别出了包含噪声的飞行数据IMF,无需大量实验。从该方法实际应用于发动机N1数据的滤波效果可知,与QAR实际记录的N1相比,滤波后的N1数据波形平滑,无野值,有效地降低了高频干扰对飞行数据的影响。
