基于协同过滤的课程推荐系统的设计与实现
2021-09-14马庆祥
马庆祥
(重庆工商职业学院 重庆 401520)
一、课程推荐系统的开发环境的设计思路
(一)本系统所涉及的开发环境基础主要是安装Spark及集成Hadoop等相关核心组件:
✧安装Spark
✧集成Hadoop
✧集成Hive
✧集成Flume
为了更高效地完成系统的搭建及运行,系统中需要使用Spark集群,因此首先安装Spark;为了使Spark能访问到Hadoop,因此,需要集成Hadoop,Spark的离线计算需要稳定的数据源,还需要使用Hive搭建数据仓库,并与Spark集成;为了能以最简便的方式采集日志数据,因此需要使用Flume。

图1 环境搭建路线图
二、智能选课推荐系统设计思路
在已经搭建好的大数据应用平台的基础上,进入对智能选课推荐系统编程开发前,需要完善系统的设计,主要思路及技术路线如下:
✧爬虫设计
✧设计用户的交互界面✧设计日志的输出格式
✧设计推荐流程与选择推荐算法
✧设计数据模型
为完成智能选课推荐平台,需要搜集课程数据。因此,本案例将使用Scrapy爬虫框架从部分免费公开的课程资源平台爬取数据和使用Requests爬虫框架调用相关API直接获取数据。数据获取后需要建立数据库表将数据存入Mongodb,然后在用户交互界面进行查询。
在用户操作页面的时候,后台记录用户的操作行为,并形成日志。此时Flume组件将日志转发到HDFS或者Kafka,为Spark提供数据。Spark拿到数据后一方面开始执行推荐功能,一方面完成数据看板的统计功能。

图2 智能选课推荐系统设计思路图
三、爬虫程序的设计
爬虫的主要任务就是抓取课程网站的数据。为了尽量快速,并采集足够多的数据,这里使用分布式爬虫。爬虫结构如图3所示[1]。
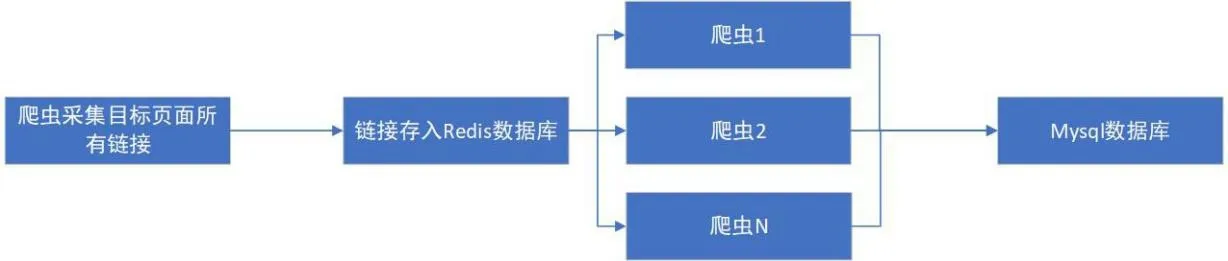
图3 爬虫结构设计图
第一步,开发一个简单的爬虫,获取所有课程待爬取页面的链接,将这些链接存入Redis。
第二步,开发采集课程详细信息的爬虫,并接入Redis。
最后,同时运行第一、二步的爬虫,并将第二步的爬虫部署到不同的计算节点上,并全部启动,整个采集过程就会按流水线式的执行。
四、交互页面的设计
(一)未注册用户访问页面的设计
如图4所示,是未注册用户的访问页面。在这个页面未注册用户可以注册,也可以查询课程信息。这些信息是根据默认情况下给未注册用户推荐的热门课程。
图4 默认推荐列表
未注册用户进入站点后,点击注册跳转到注册页面,如图5所示。
图5 系统注册页面
(二)注册用户页面的设计
未注册用户注册完毕后就是注册用户,注册用户进入系统后也会查看自己的课程列表页。这一列表页就是根据用户的操作数据,系统进行大数据分析然后形成的推荐列表。如图6所示。

图6 ALS算法推荐
在该页面用户可以给课程打分、打标签进行分类等操作。
(三)课程详情页的设计
未注册用户、注册用户都可以查看课程详细信息,如图7所示。
图7 课程详情
(四)管理员页面的设计
管理员进入后台后,展示的课程列表就不再是推荐的了,而是自然数据形成的列表。管理员在列表页可以点击编辑按钮,修改课程信息,也可以点击删除按钮删除该课程,也可以点击详情按钮查看该课程的详细信息,包括用户评分等。具体如图8所示。
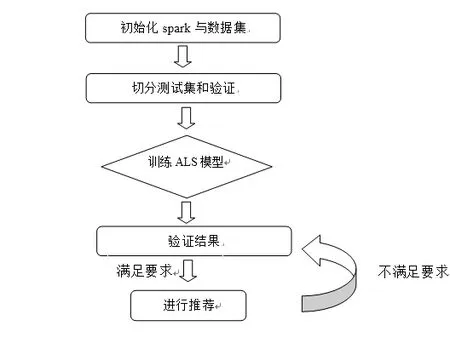
图8 管理员操作页
(五)推荐流程设计
采用普通的推荐方式,比如推荐热门课程,采用的逻辑就是将课程点击率、观看人次、推荐量等数据汇总起来,然后选出前十名或者前二十名。这种推荐方式考虑更多的是部分学生的共性,即大家都喜欢的课程,但是却没有照顾到学生的个性化需求。为了让更多的课程有机会被推荐,在系统中设计推荐模型的分析,即基于协同过滤的方式来实现课程的推荐。推荐流程如图9所示,首先将用户行为数据存入Mysql或者log日志文件,然后通过Sqoop将Mysql数据和Flume将Log数据上传到HDFS,使用Hive和Spark进行分析推荐,最后将数据存入Mysql。用户刷新页面,即可看到推荐列表[2]。

图9 推荐流程设计图
五、基于Spark-ALS的协同过滤算法(核心算法的设计与应用)
(一)协同过滤
协同过滤是一种根据用户对各种产品的交互与评分来推荐新产品的推荐系统技术。协同过滤吸引人的地方就在于它只需要输入一系列用户/产品的交互记录,协同过滤算法能够根据这些交互记录知道哪些产品之间比较相似(因为相同的用户与它们发生了交互)以及哪些用户之间比较相似,然后可以作出新的推荐。交互记录分为“显式”反馈(例如在选课网站上进行课程评分)和“隐式”反馈(例如用户访问了一个课程的页面但是没有对课程评分)。
(二)显式反馈与隐式反馈
推荐系统依赖不同类型的输入数据,最方便的是高质量的显式反馈数据,它们包含用户对感兴趣的课程进行明确的评价。但是显式反馈数据不一定总是找得到,因此推荐系统可以从更丰富的隐式反馈信息中推测用户的偏好。
隐式反馈类型包括观看课程的历史、浏览课程的历史、搜索课程的模式甚至鼠标动作等。许多研究都集中在处理显式反馈,然而在很多应用场景下,应用程序重点关注隐式反馈数据。因为可能用户不愿意评价课程或者由于系统限制我们不能收集显式反馈数据。在隐式模型中,一旦用户允许收集可用的数据,在客户端并不需要额外的显式数据[3]。
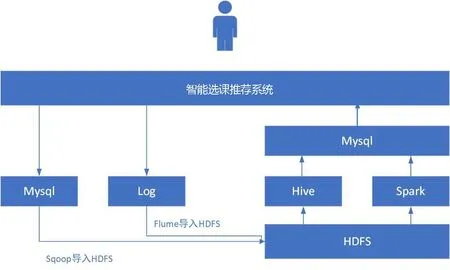
图10 ALS算法应用流程图
六、结束语
本论文的研究内容是基于协同过滤推荐算法的智能选课系统在教育教学课程资源个性化推荐方面的应用与实践。在我国高校教育教学领域,该研究内容还处于发展阶段,但基于推荐模式的算法已经在诸如电商平台、社交平台、短视频平台等进行了大量的商业化运作和应用。
基于协同过滤的课程推荐系统的运用以及对它们经验的借鉴,有助于促进选课系统性能上的加强以及促进学生在选课质量方面提升,是该领域的主要意义和价值。同时,我们注意到,高等院校以外的精品课堂、云课堂等在线课程运营商,有着相当丰富的在线课程资源,通过本系统研究的成果,结合校内在线课程资源,双渠道合力,必定能打造一个高可用、高性能、高效率的个性化智能选课推荐系统。
