混合粒子群优化算法求解模糊柔性作业车间调度问题
2021-09-08纪志成
蔡 敏,王 艳,纪志成
(江南大学 物联网技术应用教育部工程研究中心,江苏 无锡 214122)
车间调度在制造业和生产系统中起着举足轻重的作用,其根本目的是合理分配有限资源,实现生产效益最大化。柔性作业车间调度问题(Flexible job-shop scheduling problem,FJSP)作为传统的作业车间调度问题(Job-shop scheduling problem,JSP)的扩展,允许工序在其可加工机器集中选择不同的机器进行加工,提高了加工的灵活性,更符合企业实际的生产状况。因此,研究FJSP对于解决车间实际问题具有重要意义。
近年来,FJSP受到了广泛研究,越来越多的智能优化算法被用于求解FJSP。张晓星等[1]考虑到混合蛙跳算法易于陷入局部最优的问题,引入局部更新策略进行优化,提出改进的混合蛙跳算法求解FJSP;Nouiri等[2]提出一种分布式粒子群算法并应用于FJSP;王雷等[3]提出一种改进的免疫克隆选择算法求解FJSP,利用自适应变异算子提高全局最优解的质量;姜天华[4]引入变邻域搜索并结合遗传算子,提出一种混合灰狼优化算法求解FJSP。
文献[1-4]所研究的都是工序加工时间确定的FJSP。然而,在实际的生产车间中,存在着诸多不确定因素,比如机器故障等,导致不能获得准确的工序加工时间。这些不确定因素很可能导致生产计划和调度的失败,进而影响整个公司的生产效益。因此,不确定工序加工时间的模糊柔性作业车间调度问题(Fuzzy flexible job-shop scheduling problem,fFJSP)更符合实际车间状况,具有更重要的研究意义。目前国内外学者在fFJSP的研究中已经取得了很多成果。刘晓冰等[5]提出混沌量子粒子群算法求解fFJSP,引入混沌局部优化策略避免算法早熟,取得显著成效;Lin等[6]提出一种混合多元优化算法,引入路径重链和局部搜索提高算法求解fFJSP的性能;Lei等[7]提出一种协同进化遗传算法求解模糊最大完工时间,引入新的交叉算子和改进的锦标赛选择策略,开辟了遗传算法求解fFJSP的新思路;Gao等[8]提出一种改进人工蜂群算法,用于求解fFJS,取得了较好效果;Lin等[9]提出了混合生物地理学算法,采用局部搜索和路径重链技术提升算法性能,将算法成功应用于fFJSP。综上所述,当前fFJSP的智能优化算法大部分难以平衡全局和局部搜索能力,并且大多只是利用完全fFJSP(Total fFJSP,T-fFJSP)的算例进行分析研究,却忽视了更符合工厂生产实际的部分fFJSP(Partial fFJSP,P-fFJSP)。
本文重点研究P-fFJSP,针对工序加工时间不确定的fFJSP,提出一种混合粒子群优化(Hybrid particle swarm optimization,HPSO)算法。首先建立fFJSP数学模型,设计问题编码方式和解向量的映射规则,将模糊最大完工时间的求解过程映射为粒子在解空间的寻优过程。其次,在粒子群优化(Particle swarm optimization,PSO)算法的基础上引入惯性权重自适应调整策略,并对优秀粒子所映射的工序编码进行交叉操作,使用模拟退火算法(Simulated annealing algorithm,SAA)进行全局最优解的局部搜索。最后,将所提出的算法应用到5个Reman实例中进行仿真测试,结果验证了改进策略的有效性。
1 fFJSP模型
1.1 问题描述
fFJSP可以表述为:有n个独立的待加工工件J={J1,J2,…Jn},需在m台机器M={M1,M2,…,Mm}上加工。其中ni为工件Ji的总工序数,Oij表示工件Ji的第j道工序,其可以被机器集中的1台或多台机器加工。可以加工Oij的机器组成Oij的可加工机器集Mij。工序Oij在机器Mk上的加工时间用三角模糊数(Triangular fuzzy number,TFN)tijk=(t1,t2,t3)表示。隶属度函数图像如图1所示,其中t1和t3为模糊数上下界,分别代表加工时间的最小值和最大值,t2代表加工时间的最可能值,对应的隶属度为1。

图1 TFN隶属度函数图
fFJSP的求解过程可以表述成:在满足实际生产需求的条件下,解决工序排序和机器分配2个问题,使最大模糊完工时间最小。最大模糊完工时间最小可描述为
(1)
式中:tmax为最大模糊完工时间,ti为工件Ji的模糊完工时间。
fFJSP中工件和机器需满足如下约束条件:
(1)同一台机器同一时刻只能加工1道工序;
(2)每一道工序同一时刻不能由多台机器加工;
(3)处于加工状态下的工序不能中途停止加工;
(4)同一工件的工序间有先后加工顺序;
(5)不同工件之间不存在加工优先级。
表1为规模为3×3的模糊柔性作业车间的工序加工时间数据。其中“——”表示该道工序不能在该机器上加工。

表1 3×3 fFJSP模糊加工时间表
1.2 TFN的基本运算规则

(1)加法运算
(2)取大运算

(3)比较运算
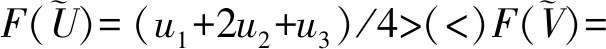


2 面向fFJSP的HPSO
2.1 PSO算法
PSO算法[10]是通过模拟鸟群觅食行为而发展起来的一种群智能优化算法。粒子具有速度和位置2个属性,粒子在迭代过程中会根据自己找到的当前个体最优解和整个粒子群的当前全局最优解来调整自己的速度和位置,其速度和位置更新公式为
(2)
式中:r1和r2为0到1之间均匀分布的随机数,ω为惯性权重,c1和c2为学习因子,pbesti为粒子i的个体最优位置,gbest为全局最优位置。个体最优位置和全局最优位置随着迭代不断更新优化。
2.2 编码与解码
本文采用基于工序的单层编码方式[11]。已知工序总数为N,工件总数为n,工序编码由N个1到n的数组成。工序编码和工序加工序列的对应关系如图2所示,加工时按照工序编码从左至右顺序进行,例如图1中工序的加工顺序为O21→O31→O32→O11→O12→O22→O33。
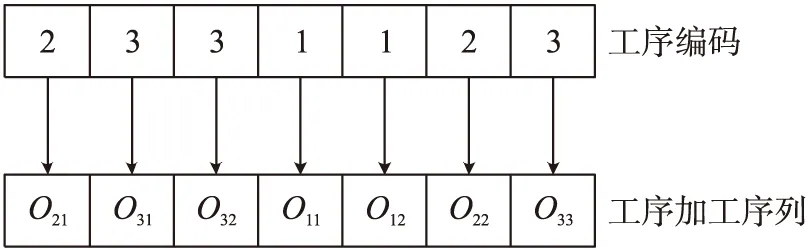
图2 工序编解码示意图
在机器分配问题上,选择让当前工序完工时间最小的机器进行加工。假如工序编码为[2,3,3,1,1,2,3],工序O21的可选加工机器集为M1、M2和M3,3台机器加工该道工序的时间分别为(6,7,9)、(5,6,8)和(7,10,12)。为使工序O21完工时间最小应选择M2作为加工机器,后一道工序O31则选择M3进行加工,以此类推。这种编解码方式简单高效,机器编码会随工序编码的改变而发生相应改变。
2.3 离散化
在HPSO中,种群按式(3)初始化
popi=lb+(ub-lb)*rand()
(3)
式中:ub、lb分别为解向量的上下边界,求得的第i个解向量popi是1个实数序列,不能直接作为fFJSP的解。因此实数序列需要通过某种规则映射为整数序列,实现个体位置与工序编码的转换。
整个转换过程如表2所示,其中k0为初始索引,ζ0为初始个体位置,χ0为初始工序编码,k1为降序排序后的索引,ζ1为排序后索引对应的个体位置,χ1为工序编码。在初始化粒子后,对初始个体位置做降序处理,得到降序后的粒子索引值,并根据工件的工序数,按k1索引值从小到大的顺序依次将实数粒子转换成整数粒子。如工件1有2道工序,对应k1的1、2应转换为1、1,依此类推,得到工序编码。工序编码与个体位置的转换与上述过程类似。
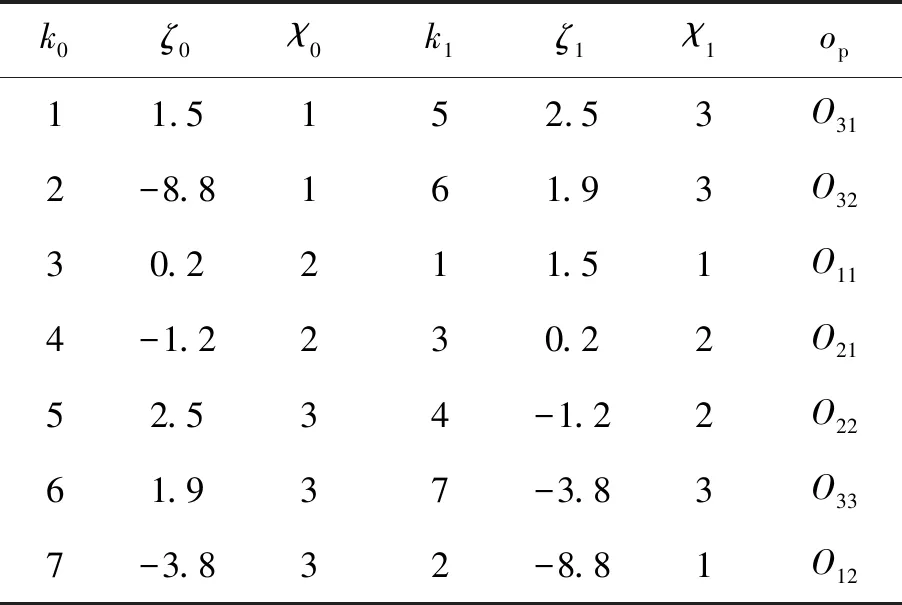
表2 个体位置与工序编码的转换表
2.4 混合策略
fFJSP是一类复杂的离散组合优化问题,虽然PSO算法有很好的寻优能力,但易早熟、易陷入局部最优,且求解离散问题的深度寻优能力不足。为使PSO算法更适于求解fFJSP,混合多种策略以提高算法性能。
2.4.1 自适应惯性权重
惯性权重ω是PSO算法中至关重要的参数,它可调节对解空间的搜索范围,影响算法的搜索寻优能力。一般将ω设置为线性递减,算法先全局搜索,后期更多地转为局部搜索,但该方法不能很好地应对复杂多变的非线性优化问题。因此,在PSO算法中引入ω自适应调整策略[12,13]。
自适应惯性权重中2个重要的参数为进化速度因子和聚集度因子。进化速度因子s定义为
(4)

定义全部个体当前适应度值的平均值Favg
(5)
则聚集度因子g为
(6)
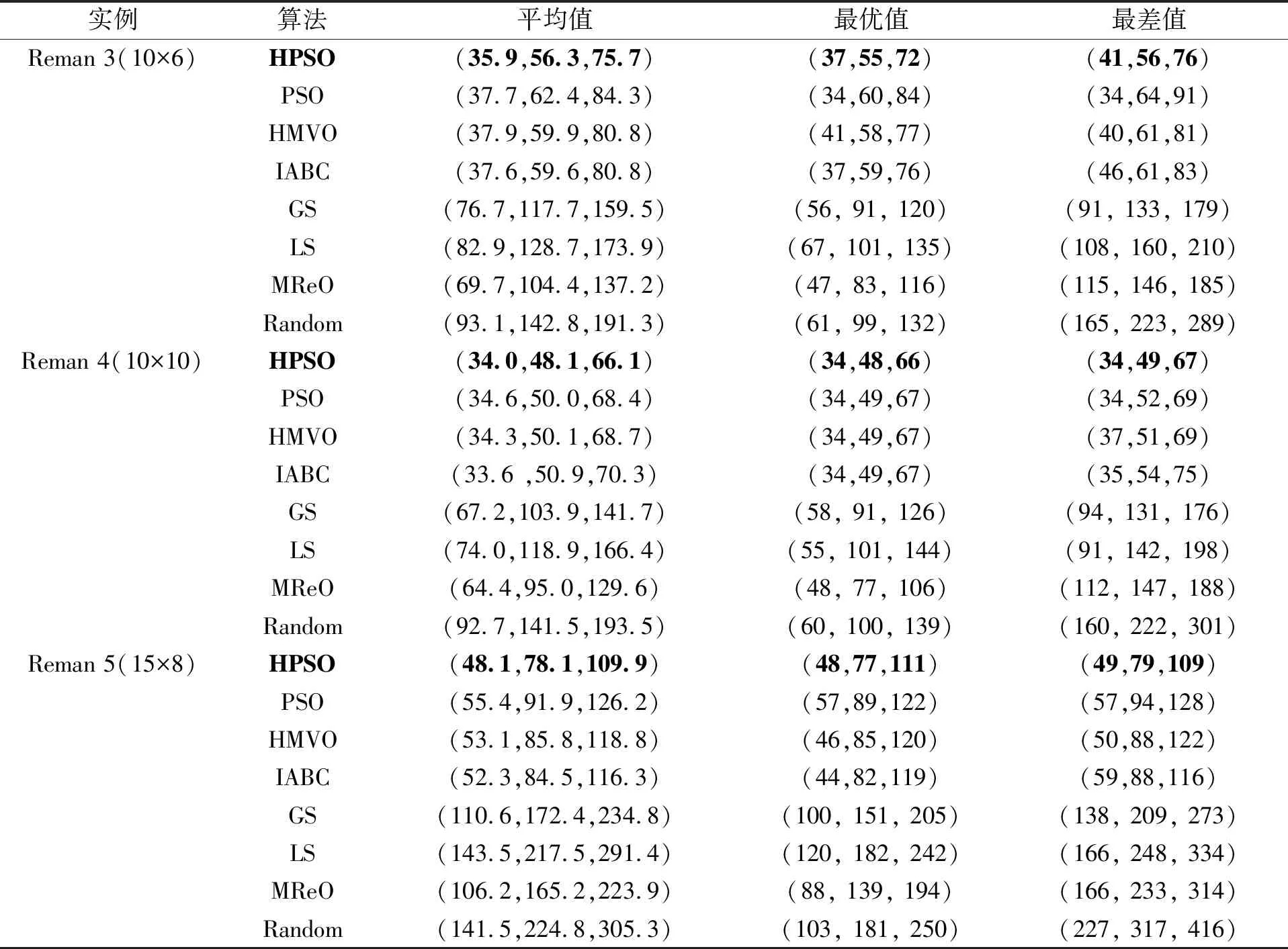
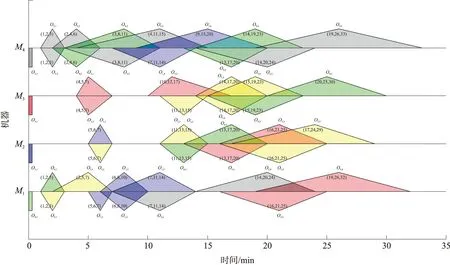
式中:0 自适应惯性权重考虑了搜索空间中粒子的情况。当s变大时,说明种群的进化速度变得缓慢,此时可减小ω,缩小算法的搜索区域,更利于局部搜索找到最优解;当g变大时,粒子聚集度升高,算法易陷入局部最优,这时要让ω增大,扩大粒子群搜索区域,使算法的全局搜索能力提高。 结合上述分析,为使PSO算法实现ω自适应调整策略,则ω应为s和g的函数,表示为 ω=f(s,g)=ω0-sωs+gωg (7) 式中:ω0取1。当ωs取0.40~0.60、ωg取0.05~0.20时,算法性能较好。 2.4.2 边界变异 在PSO迭代寻优过程中,粒子所处的位置可能会超出搜索域,形成无效粒子。一般做法是将超出边界的粒子拉回搜索域边界,这会导致粒子在边界处聚集,粒子位置的随机性降低,从而影响到算法的寻优性能,不利于找到全局最优解。 针对传统方法处理越界粒子存在的问题,采用更为合理的处理越界粒子的方法如下 (8) 2.4.3 交叉算子 为提高算法深度寻优性能,对工序编码进行优先工序交叉(Precedence operation crossover,POX)以期寻求更优解。POX交叉步骤如下: (1)将工件集J={J1,J2,…,Jn}随机地分为非空子集J1、J2; (2)将Parent1中属于J1的所有基因直接复制给Children1,Parent2中属于J1的所有基因直接复制给Children2; (3)将Parent2中属于J1的基因剔除,将其余基因按从左到右顺序依次复制到Children1;同样地,将Parent1中属于J1的基因剔除,将其余基因按从左到右的顺序依次复制到Children2。 图3为POX交叉示意图,J1={1},J2={2,3}。在每次更新全局最优位置之前,将适应度排名前40%的个体位置转换成工序编码,对其进行POX交叉。若交叉生成的新个体适应度优于原个体适应度,则用新个体适应度代替原个体适应度,并将新个体的工序编码转换成位置,用新个体位置替换原个体位置,实现优中选优,进一步提高算法求解离散问题的深度寻优能力。 图3 POX交叉示意图 2.4.4 模拟退火算法 模拟退火算法[15]是一种启发式随机寻优算法,其模拟固体高温退火的过程,主要步骤是产生1个新解,计算适应度值,利用Metropolis准则决定是否接受新解。若适应度值优于原适应度值,则接受新解;否则生成0到1的随机数,与P=e-Δf/T比较,若小于P则接受新解。其中Δf为每次产生的新适应度值与旧适应度值之差。算法每次迭代的温度为T0=T×η,其中T0为下次迭代温度,T为当前温度,η为冷却系数。这种局部搜索算法能够防止算法陷入局部最优并增强算法的深度寻优能力。 本文对每一代的全局最优解进行模拟退火局部搜索并保优。互换全局最优位置映射的工序编码中的任意2个工序,产生新解,计算其模糊最大完工时间。若优于旧解,则接受新解,并用新解替换旧解,否则以一定概率接受新解。这样处理可得到更多潜在的优秀解,在一定程度上避免陷入局部最优。 HPSO求解fFJSP的步骤如下: (1)确定算法的种群个数、迭代次数和可行搜索区域的上下限,并初始化种群和参数s、g、ωs、ωg; (2)求出当代个体的适应度值,并保存个体最优位置和全局最优位置; (3)根据式(2)和式(7)更新粒子位置,对越界粒子执行边界变异; (4)计算新个体的适应度,更新个体最优位置; (5)将适应度前40%的个体位置按2.3节的方法转换成工序编码,进行交叉,并保留较优解; (6)更新全局最优位置,利用模拟退火进一步探索更优的全局最优解并保优,再更新s、g; (7)判断算法是否达到设定的迭代次数,如果是则输出全局最优值,否则转到步骤(3)。 为验证本文算法求解fFJSP的有效性和优越性,根据文献[8]提供的Reman再制造实例数据进行仿真实验。选取前5个Reman实例数据,如表3所示。 表3 实例数据基本信息表 仿真所用电脑的硬件参数为:Windows 10系统,Intel(R)Core(TM)i5-8500 CPU @ 3.00GHz,8GB RAM。编程语言为MATLAB R2019a。 仿真参数设置:对于HPSO,搜索区域范围设为[-10,10],c1=c2=2,ωs=0.50,ωg=0.10,初始温度TS设为200,η=0.95。前4个Reman实例的种群数目设置为60,迭代次数为1 000;实例5种群数目为100,迭代次数1 500。对于PSO,ω=0.6,为使对比明显,计算前4个实例时,将种群数目设为100,Reman实例5的种群数目为150,其余参数与HPSO相同。其它算法参数见参考文献[8,16]。 为尽可能消除随机误差对仿真结果的影响,将HPSO和PSO分别独立运行30次,统计最大模糊完工时间的平均值、最优值和最差值,并与Hybrid multi-verse optimization(HMVO)[6]、改进人工蜂群(Improved artificial bee colony,IABC)算法[8]和4种启发式算法Local minimizing processing time(LS)rule、Global minimizing processing time(GS)rule、Most number of operations remaining(MReO)rule、Randomly select a job(Random)[8,16]的计算结果一并列入表4,运用TFN比较规则,得出各指标的最优结果并加粗显示。 表4 算法仿真结果对比表 续表4 由表4可知:对于Reman 1实例,HPSO求得的模糊最大完工时间的平均值、最优值和最差值与HMVO相同,最优值与IABC相同,其余值均好于PSO、IABC和4种启发式算法;对于后4个实例,HPSO得出的模糊最大完工时间的各项指标均好于其余算法。为直观显示调度结果,以Reman 1为例,画出其最优值(19,26,33)对应的调度甘特图,如图4所示。 图4 Reman 1最优值对应的甘特图 为验证交叉操作和模拟退火局部搜索的有效性,做分离实验,结果如表5所示。表5中HPSO(1)表示不加入模拟退火算法,HPSO(2)表示不加入交叉操作。相较于PSO,3项指标均有提升,但都差于HPSO,验证了改进策略是有效的。 表5 分离实验结果对比表 为直观对比HPSO和PSO的求解结果,选取后4个实例,将HPSO和PSO求得的所有模糊最大完工时间去模糊化后,得出图5的收敛曲线。 图5 收敛曲线图 图5刻画了模糊最大完工时间的变化情况。由图5可知,在有限的运算资源条件下,HPSO的收敛曲线均在PSO的下方,求得的模糊最大完工时间整体小于PSO,说明HPSO能够得到更好的调度解。随着实例数据量的增大,HPSO依然保持领先优势,具有很好的求解稳定性。以Reman 5为例,HPSO的领先优势更加明显,且具有更强的深度寻优能力,其在求解大规模fFJSP上更具有竞争力。同时,改进算法在一定程度上能够改善PSO易陷入局部最优的问题。此外,由于PSO的种群数目多于HPSO,消耗的CPU资源更多,但是HPSO运行结果却比PSO好,说明本文HPSO算法更适合求解fFJSP。 本文提出了一种HPSO算法求解以最小化最大模糊完工时间为目标的fFJSP。首先引入自适应惯性权重,使算法能够保持较强的全局和局部寻优能力;其次,为提高算法深度寻优能力,对优秀个体映射的工序编码进行交叉操作;最后,利用模拟退火算法进行全局最优解的局部搜索,探索更为优质的解。对比仿真实验结果表明,本文算法在不同规模的实例数据下都能够得到更好的调度解,在解决fFJSP方面具有一定的有效性和优越性。

2.5 算法步骤
3 仿真实验
3.1 仿真实例与参数设置

3.2 仿真结果分析



4 结束语
