基于YOLOv3的改进行人检测算法研究
2021-09-08舒壮壮马苗苗
舒壮壮,单 梁,马苗苗,屈 艺,李 军
(南京理工大学 自动化学院,江苏 南京 210094)
随着自动驾驶、视频监控以及机器人视觉等领域研究的发展,行人检测作为其中的重要组成部分,具有极大的应用前景。近些年来深度学习的发展,也给行人检测提供了新的思路,与基于机器学习的行人检测算法相比较,基于卷积神经网络(Convolution neural network,CNN)的深度学习方法极大地推动了行人检测算法的发展。
传统行人检测算法的设计思想主要是先基于手工设计的特征算子提取行人特征,再利用机器学习的分类模型将检测问题转换为分类问题来确定行人的位置。Dalal等[1]提出经典的方向梯度直方图(Histograms of oriented gradients,HOG)模型,借助于梯度算子提取特征,再使用支持向量机(Support vector machine,SVM)分类模型将检测问题划分为若干个小方格中的分类问题以最终实现行人的检测。在传统的行人检测算法中,特征算子提取到的特征只能是该算子所关注的特征信息,无法充分利用图像中既有的全部信息,缺乏有效的图像表达能力,比如HOG模型中的算子仅仅关注梯度信息。
随着CNN的发展,行人检测算法的研究借助于CNN实现飞速发展。刘翔羽[2]针对手工设计算子提取能力不足的问题,创新地将CNN融入了传统算法。先是使用CNN提取图像的不同特征,再使用HOG算子提取CNN提取到的特征图中的梯度信息。与传统的HOG模型相比较,因特征提取能力变强而提升了检测精度。完全基于CNN的区域卷积神经网络(Region-convolution neural network,R-CNN)[3-6]系列目标检测算法的提出给行人检测算法带来了新的研究方向。基于快速区域卷积神经网络(Faster region-convolution neural network,Faster R-CNN)[5],Zhang等[7]针对行人检测中的遮挡难题提出遮挡处理区域卷积神经网络(Occlusion-aware R-CNN)行人检测算法,该算法将Faster R-CNN[5]的感兴趣区域(Region of interests,ROI)层中融入了人体特征信息并修改Faster R-CNN的损失函数,在法国国家信息与自动化研究所(Institut National de Recherche en Informatique et en Automatique,INRIA)数据集上得到了最佳结果。Li等[8]为减少不同行人尺度变化带来的影响提出Scale-aware Fast R-CNN行人检测算法,该算法使用分而治之的思想针对不同尺度的行人使用不同的子网络,各个子网络的输出融合后作为最后的输出结果,获得不错的检测结果。尽管R-CNN系列的算法提高了检测精度,但是实时性较差,消耗的计算资源也很大。Redmon 等[9]提出的YOLOv3目标检测算法平衡了检测实时性和精度,由于特征提取网络借鉴了ResNet[10]并且融入了特征金字塔网络(Feature pyramid networks,FPN)[11]结构,具备较强的多尺度特征提取能力,因此比Faster R-CNN[5]更加适用于多尺度行人检测。葛雯等[12]在原来的FPN基础上额外增加1个尺度来更好地检测极小体型行人。施政等[13]在YOLOv3中使用Darknet-53提取可见光和红外光2类状态下的特征,并结合了注意力机制(Attention mechanism),得到较好的行人检测结果。为更好地将行人检测算法应用于机器人这类缺乏计算资源的平台,本文提出一种基于YOLOv3的改进行人检测算法。
1 基于YOLOv3的改进行人检测算法
1.1 改进的先验框生成算法
YOLOv3在通用数据集MS COCO(Microsoft common objects in context)上使用K均值(K-means)聚类方法生成大中小全尺度物体的先验框。然而行人检测与通用目标检测相比,行人身体的长宽比基本是固定的(大致是1.5)。MSCOCO中很大一部分目标的长宽比与行人的比例差距较大,直接将所获得的先验框应用于行人检测将会增加训练模型的时间。

(1)先从给定样本X中随机挑选1个当作第1个聚类中心co。

(3)重复步骤(2)直到选择出K个聚类中心。
(4)在MSCOCO的行人子集上使用K-means算法获得先验框。
1.2 改进的特征提取网络
由于YOLOv3的特征提取网络Darknet-53为了提取不同尺度的特征信息而直接借鉴深度残差网络(Deep residual network,DRN)和FPN结构,所提取到的特征中会出现较多的与行人长宽比不匹配的信息,而特征提取网络提取到的特征很大程度上直接影响后续的检测定位部分的精度以及训练模型的时间。因此,针对Darknet-53应用于行人检测时提取到较多与行人不匹配的信息的问题,改进了当前Darknet-53的网络结构。
整个特征提取网络的第1部分尤为重要,它决定着整个特征提取网络从场景中提取到的特征信息量。Darknet-53以及其他借鉴ResNet的特征提取网络的第1层所使用的结构一般是1个3×3的卷积网络和1个池化层,来提取原始的特征信息。为从输入图中提取到更多特征,采用如图1所示的茎块层(Stream block)结构,可以在基本没有增加有效计算力的情况下有效地增加所提取到的特征信息量,且比通过增加第1个卷积层的通道数能融合更多的信息。

图1 茎块层结构图
原Darknet-53特征提取网络中主要使用的结构是如图2所示的稠密层(Dense layer),通过堆叠Dense layer形成Darknet-53。此类结构输出层只能获得单一尺度的感受野(Receptive field)。为获取不同尺度的感受野,本文将其改进为如图3所示的二路稠密层(Two-way dense layer)结构。其中1条分支使用的是和Darknet-53中的Dense layer一样的3×3的卷积核和1×1的卷积核,来提取特征;另1条分支摒弃了原来的“短路”设计,采用2个堆叠的3×3卷积核来提取大目标特征;因而在提取到特征信息的同时,能够更多地保留大物体尺度特征。

图2 稠密层结构图

图3 二路稠密层结构图
改进后的新特征提取网络依旧只使用3个尺度的特征融合,例如葛雯[12]的论文中新添加了1个更小尺度的特征融合设计,用于检测更低分辨率的行人,不仅无法显著提高mAP(Mean average percision),而且产生更大的计算量,降低了实时性,得不偿失。
1.3 改进的损失函数
在损失函数部分,针对目标定位损失使用L2范数计算损失值时存在的不足,提出了改进的方法。在YOLOv3的损失函数中,整个损失函数分为3个部分:目标定位偏移损失Lloc、目标置信度损失Lconf和目标分类损失Lcls。
在目标定位偏移损失中,YOLOv3使用L2范数计算预测框与真实框(Ground-truth boxes)之间的差值。
(1)

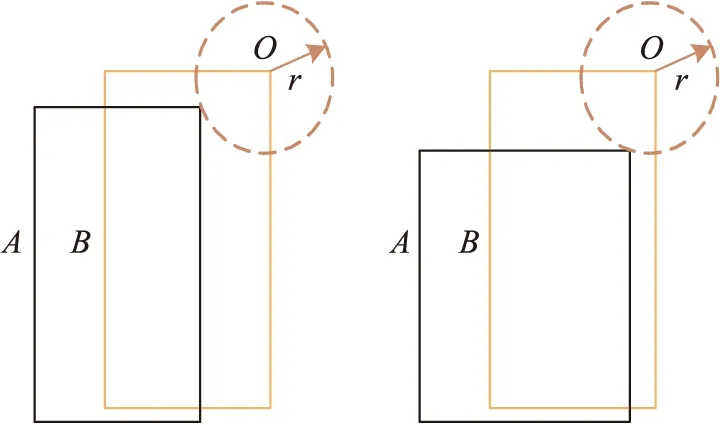
图4 L2损失函数失效场景示意图
针对以上问题,本文改进为基于交并比(Intersection over union,IoU)函数的变体广义交并比(Generalized intersection over union,GIoU)[14],来计算目标定位损失值。针对预测框Ai与对应的真实框Bi,损失值计算如下
(2)
(3)
(4)
式中:N是预测产生的矩形框个数,Ci是Ai与Bi的最小覆盖矩形。IoUi表征的是Ai与Bi的重叠程度,取值范围是[0,1]。当Ai与Bi接近完全重合时GIoU(Ai,Bi)=IoU(A,B)=1,而当Ai与Bi接近完全不重合时GIoU(Ai,Bi)=-1,因此GIoUi取值范围是[-1,1],1-GIoUi的取值范围是[0,2],总能为每次的检测做出有效反馈。而且改进的GIoU损失函数是1个有界函数,不容易发生梯度爆炸且具有尺度不变性,比L2更加适合作为损失函数。
在目标置信度损失Lconf中,采用二值交叉熵损失函数预测目标矩形框内存在目标的概率。
(5)
(6)

在目标类别损失Lcls中,同样采用二值交叉熵损失函数来预测目标矩形框内存在的行人对象。
(7)
(8)

总的损失值为3个损失值的加权和
Loss=λ1Lloc+λ2Lconf+λ3Lcls
式中:λ1、λ2、λ3是3个用于平衡损失值的平衡因子,在最终的代码实现中将λ1、λ2、λ3分别取为1(h×w×9)、1(h×w×9×2)、1(h×w×9×2),其中h、w是输入图像的高度和宽度,9是先验框的数量。
2 算法的实验结果分析
为了验证基于YOLOv3改进的行人检测算法的有效性,本实验使用MSCOCO训练集中的“person”子集来训练模型,分别使用MSCOCO测试集的“person”子集和自制的行人数据集作为测试集合来验证模型。
为更好提高召回率,并且减少最终所得的检测器对数据集特定样本的依赖性,在训练过程中对MSCOCO的“person”子集进行标准的数据增广(Data augmentation)操作,比如随机翻转、随机伸缩图像尺度、随机裁剪以及随机改变图像颜色(亮度、饱和度、对比度),并对数据进行简单的线性处理,使得在没有数据覆盖的区域能使用简单线性插值进行学习。
将训练所得检测模型在MSCOCO测试集中的行人子集以及自制的行人数据集上进行对比分析,验证模型皆在CPU i7 8700上进行推理实验。MSCOCO测试集上的结果如表1所示。
可以看出,YOLOv3算法经过改进,应用在行人检测上,不仅检测精度得到了提高,而且也几乎没有影响到实时性,对于缺乏计算资源且没有图形处理器(Graphics processing unit,GPU)的平台设备也适用。为了验证基于YOLOv3改进的行人检测算法在不同复杂场景下的泛化性能,采集了人群比较密集的样本621张,对样本进行行人标定,共有2 731个行人边界框,从准确数、误检数、成功率3个方面对算法进行比较分析,结果如表2所示。其中,对部分样本的行人检测效果如图5和图6所示。在图5(a)与图6(a)中,2个算法都能正常检测左侧稀疏的人群,而对右侧的严重密集重叠的3个人,YOLOv3算法只能检测出1个人,本文改进算法可以检测出2人。在图5(b)与图6(b)中也能发现,改进算法比YOLOv3可以更加精确地发现行人。从表1、表2以及图5、图6可以看出,基于YOLOv3改进的行人检测算法在不同的背景下的检测结果都相对原始的YOLOv3算法具有较大的提升,更加适合行人检测场合。

表2 自制数据集的2种算法结果表

图5 YOLOv3算法的检测结果图

图6 本文改进算法的检测结果图
3 结束语
与YOLOv3的通用目标检测算法相比,本文改进算法通过改进预处理过程的锚框、特征提取网络以及目标定位损失函数,使其更加易于提取行人特征并提供有效反馈,几乎不影响模型的推理速度,而且还提高了检测精度。因此本文改进算法更加适用于行人检测。未来还将继续研究行人检测如何更好地应用到移动机器人领域。
