多中心联合配送模式下集货需求随机的VRPSDP问题
2021-08-28范厚明刘鹏程刘浩侯登凯
范厚明 刘鹏程 刘浩 侯登凯
车辆路径问题(Vehicle routing problem,VRP)是物流配送企业的核心问题,自Dantzig 等[1]在1959 年首次提出之后,众多学者对该问题展开了研究,并衍生出随机需求车辆路径问题(Vehicle routing problem with stochastic demand,VRPSD)、多中心车辆路径问题(Multi-depot vehicle routing problem,MDVRP)以及同时配集货车辆路径问题(Vehicle routing problem with simultaneous delivery and pickup,VRPSDP)等众多VRP 拓展问题.本文研究的多中心联合配送模式下集货需求随机的同时配集货车辆路径问题(Multi-depot vehicle routing problem with simultaneous deterministic delivery and stochastic pickup based on joint distribution,MDVRPSDDSPJD)是综合考虑了VRPSD、MDVRP、VRPSDP 及联合配送特点的科学问题.
近年来,有关MDVRP、MDVRPJD(Multidepot vehicle routing problem based on joint distribution)、VRPSD 问题已成为VRP 拓展问题研究的热点.葛显龙等[2]对基于联合配送的多中心开放式动态车辆路径问题进行研究,针对跨区域多中心联合配送的情况,建立“多对多”的网络配送机制,车辆配送完成后可就近返回任意配送中心,设计云遗传算法对问题进行求解.杨翔等[3]研究了带有模糊时间窗的MDVRP 问题,假设虚拟配送中心对多配送中心问题进行处理,设计了改进的蚁群算法对问题进行求解.Gruler 等[4]对带有随机需求的MDVRP 问题进行研究,设计了结合迭代局部搜索算法的模拟优化算法对问题进行求解.Alinaghian等[5]研究了多车厢多类型产品的MDVRP 问题,车辆从配送中心出发最终返回原配送中心,在配送过程中,针对同一种产品不允许拆分服务,设计了结合自适应大邻域搜索算法和变邻域搜索算法的混合算法对问题进行求解.葛显龙等[6]研究了需求可拆分模式下的集配一体化MDVRP 问题,设计改进遗传算法进行求解.陈呈频等[7]对多车型MDVRP 问题进行研究,车辆从配送中心出发对客户进行服务后,最终返回原配送中心,设计多染色体遗传算法对问题进行求解.Wang 等[8]研究了时变网络下的多中心车辆路径问题,提出了新的交通资源共享策略,结合节约算法、扫描算法和多目标粒子群算法设计了混合元启发式算法对问题进行求解.Li 等[9]研究了带时间窗限制的多目标绿色MDVRP 问题,设计改进蚁群算法对问题进行求解.可见,众多学者从时间窗、多车型、需求可拆分、随机需求以及配集货等方面进一步深化了对MDVRP 问题的研究.
多中心同时配集货车辆路径问题(Multi-depot vehicle routing problem with simultaneous delivery and pickup,MDVRPSDP)是集成了MDVRP 和VRPSDP 问题而展开的研究.该问题涉及多个配送中心的物流配送企业对同时具有配货需求和集货需求的客户点进行配集货服务.Li 等[10]研究了闭环式MDVRPSDP 问题,车辆从配送中心出发,服务完客户后返回原配送中心,设计基于迭代局部搜索的元启发式算法对问题进行求解.Kachitvichyanukul 等[11]研究了多中心多种配集货需求的车辆路径问题,针对不同的客户配集货需求,车辆可从任一位置出发,且无须返回原配送中心,设计基于粒子群的改进算法对问题进行求解.Soriano 等[12]对两个区域多中心配集货车辆路径问题进行研究,要求车辆服务完成后返回原配送中心,设计了自适应大邻域搜索算法对问题进行求解.Ben Alaia 等[13]对闭环式多车辆多中心配集货车辆路径问题进行研究,采用遗传算法和粒子群算法对问题进行求解.Bouanane 等[14]研究了带有库存限制的MDVRPSDP问题,并设计了一种结合最近仓库启发式算法、扫描算法和最远插入启发式算法的混合遗传算法进行求解.
综上文献梳理可见,在以下几个方面有待更深入的研究.1)现有对于MDVRP 问题的研究通常采用先分组后路径的方式,将客户划分到不同的区域,每个配送中心仅负责该区域内的客户,将MDVRP 问题转化为多个独立的单中心VRP 进行求解.该方法未能考虑到多个配送中心联合配送的优势,客户资源不能共享,难以对整个配送网络进行全局优化.2)未考虑多个配送中心之间车辆资源共享并设计适合其特点的车辆返回规则.在对闭环式MDVRP 问题的研究中,仅考虑了各配送中心对于客户资源共享,而对于车辆资源共享方面研究不足,导致车辆在完成配集货服务后仍需返回原配送中心,造成路径成本的增加.在对开放式MDVRP问题的研究中,车辆服务完客户后,通常采用就近返回任意配送中心的规则.在配送中心车辆数量有限的情况下,虽然就近返回配送中心规则会降低本次车辆调度的成本,但未能根据配送中心的需求进行合理的车辆分配,造成车辆的无序分配,使得下一次规划车辆路径受到限制.即需要先进行配送中心间的车辆调度,增加了额外的路径成本.3)针对MDVRPSDP 方面的研究,所涉及的客户集货量和配货量多为确定型,然而在许多实际配送服务中,常存在客户配货量已知、集货量不确定的情况.例如,在一个地区含有多个配送中心的玻璃制造公司对该地区客户进行服务,其中配货量可以通过客户订单来确定,而对于从客户手中收集的玻璃原材料,客户使用过程中损坏、剩余的废旧玻璃以及玻璃残次品的回收量无法得知,仅能根据以往的经验得知其服从的某种概率分布.以往的研究缺乏对于不确定环境下的MDVRPSDP 的研究.
MDVRPSDDSPJD 问题是集成上述三个方面而展开的研究,已有方法无法适用于MDVRPSDDSPJD 问题的原因在于以下两方面.1)已有文献对于车辆返回规则的算法设计无法应用于本文提出的适合车辆共享特点的车辆返回规则.2)在已有研究中,对于VRPSDP 问题的算法设计未考虑随机需求对于车辆实时载重量的影响以及随机需求引起的对于服务失败点的二次配送.在VRPSD 问题的研究中,未考虑由于客户双重需求引起的车辆初始装载量的设计.即传统对于VRPSD 问题的研究中,车辆从配送中心出发时,车辆初始装载量为满载(配货的情况)或者空载(集货的情况).然而针对MDVRPSDDSPJD 问题的研究,由于集货需求的随机性,必须考虑车辆的初始装载量情况,不能同传统VRPSD 问题一般,满载(或空载)出发对客户进行服务.
本文针对MDVRPSDDSPJD 问题展开研究,阐述MDVRPSDDSPJD 的衍生进程,并构建了两阶段MDVRPSDDSPJD 模型.预优化阶段基于随机机会约束机制以及车载量约束为客户分配车辆,生成预优化方案;重优化阶段针对服务失败的客户点采用重优化策略生成重优化路径.根据问题特征设计自适应变邻域文化基因算法对问题进行求解,并通过三组算例对本文的模型及算法进行验证.MDVRPSDDSPJD 问题之所以能应用到含有多个配送中心的物流企业实施多中心联合配送问题中,是由于含有多个配送中心的物流企业中有着唯一的决策者或各决策者之间思想与行为高度协调一致,且各配送中心之间不存在利益冲突或建有利益分配机制.因此,本文对MDVRPSDDSPJD 进行研究不仅进一步拓展了VRP 问题的理论研究,也有利于提高物流配送活动的效率,为制定科学合理的物流企业车辆调度计划提供理论依据,具有重要的理论和实践价值.
1 问题描述及模型建立
1.1 问题提出
经典的MDVRP 通常指在一个区域中含有多个配送中心的物流配送企业,车辆从某一配送中心出发,对客户进行服务后返回原配送中心.如图1(a)所示,车辆K1从配送中心V1出发,对客户 1、2、6进行服务后返回配送中心V1,车辆K2同理.
MDVRP 问题考虑的是客户仅具有一种需求,然而,在实际中存在客户同时具有配货和集货需求的情况,车辆在对客户进行服务时,需要同时满足客户的配、集货需求.仅具有配货(或集货)的单一需求的情况,可以看作是同时配集货问题的特例,即集货(或配货)量为0 的情况.由此,原问题便拓展成了MDVRPSDP 问题.由于配、集货量的加入,车辆的装载量不再是单一的增加(集货)或者减少(配货),需要考虑在行驶过程中车辆装载量的波动情况,车辆的实时装载量应始终小于车辆容量,因此该问题较单一需求的问题更加复杂.如图1(b)所示,车辆K1从配送中心V1出发,对客户1、2 进行服务后,由于车辆剩余空间无法满足客户6 的集货量需求,因此车辆K1返回配送中心V1;车辆K2从配送中心V2出发,经检验,发现车辆装载量可以满足客户4、5、3 的配、集货需求,车辆K2对客户4、5、3 服务后,返回配送中心V2;派出车辆K3从配送中心V1出发,对客户6 服务完成后,返回配送中心V1.

图1 MDVRPSDDSPJD 的衍生进程Fig.1 Derivation of MDVRPSDDSPJD
在MDVRPSDP 问题的基础上,考虑到客户配货量确定、集货量为随机变量以及多中心之间联合配送的情况,便形成了MDVRPSDDSPJD 问题.多中心联合配送机制打破了传统的分区域配送模式,从全局的角度出发对客户进行联合配送服务.此外,由于随机变量的引入,可能产生在某个客户点不能满足客户的需求,导致服务失败,车辆需返回配送中心后重新对服务失败的客户点进行服务.如图1(c)所示,假设车辆的预优化方案为V1-1-2-6-V1,V2-4-5-3-V2.车辆K1从配送中心V1出发,按照预优化方案,对客户 1、2 服务后,在客户6 处,由于客户随机集货需求的影响,经检验,车辆剩余空间无法满足其集货需求,车辆K1返回配送中心V1,客户6 为失败点;车辆K2从配送中心V2出发,按照预优化方案,对客户 4 服务完成后,经过预判断发现车辆剩余空间无法满足客户5 的需求,则车辆不再对客户5 进行服务,车辆K2提前返回配送中心V2;对于未完成服务的客户3、5、6 重新规划路径,由车辆K3从配送中心V2出发,按照重优化路径V2-5-6-3-V2对未完成服务的客户点进行服务,服务完成后返回配送中心V2.
本文综合考虑多个配送中心联合配送、客户资源共享、车辆资源统一调度、客户同时具有配集货需求以及客户集货需求的随机性,对MDVRPSDDSPJD 问题进行研究,构建两阶段求解方案.预优化阶段,车辆从配送中心出发按照预优化路径对客户进行服务;重优化阶段,对于预优化阶段服务失败的客户点进行重新优化.车辆服务完成后,按照车辆返回规则返回配送中心.
1.2 问题描述
本文研究的MDVRPSDDSPJD 问题描述如下.配送网络有完备的有向图G(V,E) ;所有节点集合VV c ∪V d{0},客户节点集合V c{1,2,···,n},配送中心集合Vd{n+1,n+2,···,n+m},节点0 为引入的虚拟配送中心编号,虚拟配送中心同其他实际配送中心相连接且同各个实际配送中心间的距离为0;边集合E{(i,j)|i,j ∈V},两节点i,j之间的路径成本为cij;k为可用配送车辆集合K{1,2,···,φ}的任一车辆,最大车辆数为φ,车辆容量为Q;客户节点i(i ∈V c) 的配货量为d i,选用泊松分布对客户点的集货需求信息进行表征[15],客户点i的集货量为随机变量ξi,相互独立并且服从泊松分布,客户点i的集货量为q的概率为P iqPr(ξiq),q0,1,2,···;0≤q ≤Q,i ∈V c,期望值 E[ξi]和方差Var[ξi]均为λ;假设客户无配送时间要求.决策变量xijk表示车辆k是否直接从点i到达点j,是为1,否为0;yik表示客户点i(i ∈V c)是否由车辆k服务,是为1,否为0.需要解决的问题是车辆从配送中心出发,对客户进行配集货服务后,返回配送中心,要求规划车辆行驶路径,使得总路径成本最低.
1.3 预优化阶段
在预优化阶段,考虑到客户点集货需求的随机性,本文引入随机机会约束机制对是否为客户点服务进行预判断.假设某一条预优化路径V k{s,t,e,w},V k ⊆V c,为车辆服务的客户序列集合,车辆从某一配送中心出发,按照预优化路径进行配送服务.当车辆对客户∑s,t,e服务完成后,其实时车载量可表达为Q ewk为车辆服务∑完客户e后而在访问客户w之前的车辆装载量,为车辆从配送中心出发时的初始装载量.在车辆访问客户点w前,引入随机机会约束机制对是否为客户点w提供服务进行检验,预先设置风险偏好值α,α ∈(0,1] .此时客户点w集货量与车辆服务完客户e后实时车载量应满足ξw ≤Q −Q ewk+d w,当随机约束以预设的偏好值水平α成立,则可以对客户点w进行配集货服务.即 Pr{ξw ≤Q −Q ewk+d w}≥α,α的设定取决于决策者在随机环境下基于风险偏好的喜好程度,α值越大,代表决策者的保守性越强,更重视服务的成功率;α值越小,代表决策者的冒险性越强,更希望用一辆车配送更多的客户.
在以往的闭环式MDVRP 问题的研究中,车辆服务完成后返回原配送中心,虽然保证了配送中心含有的车辆数平衡,考虑了配送中心之间的客户资源可以共享,但忽略了车辆资源的共享,造成路径成本的增加.在开放式MDVRP 问题的研究中,车辆服务完成后可就近返回任意配送中心,但就近返回规则存在着不合理性,因为在对配送中心进行选址时,其辐射范围、客户等均已考虑在内,并根据客户需求为其配备适量的车辆,因此配送中心所应含有的车辆数是受到限制的.然而车辆就近返回任意配送中心的规则会导致配送中心车辆数目的混乱,造成配送中心对车辆的需求数与所拥有的车辆数的不平衡,即车辆返回哪一个配送中心会影响到下一次路径优化时各配送中心含有的初始车辆数.若仍然按照以往的车辆就近返回规则,可能会产生额外的配送中心之间车辆调度的成本,随着规划次数的增加,各配送中心的车辆数将产生更大的无序性,甚至可能出现某配送中心无车辆可用的情况.综合考虑两种车辆返回规则的优缺点,并基于多中心联合配送的特点,本文提出新的车辆返回规则:车辆从配送中心出发,可返回任意配送中心,但应满足每个配送中心车辆的进出平衡,即配送中心驶离的车辆数应等于返回该配送中心的车辆数,保证每一次路径优化完毕后,各配送中心的车辆数不变.
1.3.1 模型建立
相应的MDVRPSDDSPJD 模型如下:
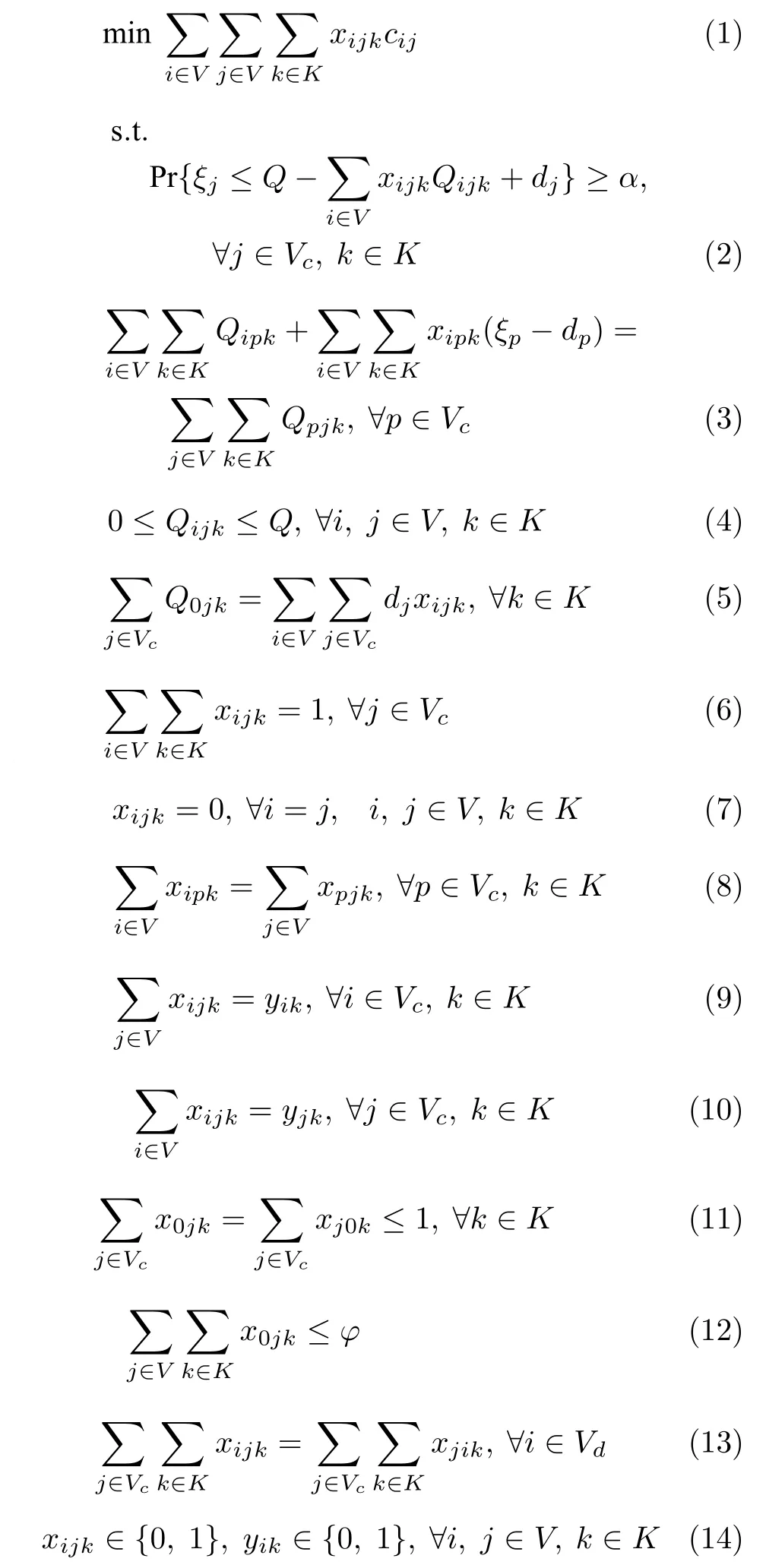
目标函数式(1)为最小化运输总成本;式(2)为随机容量机会约束,保证为客户j服务成功的概率大于等于预设的风险偏好值α;式(3)表示车辆k访问客户p前后的车辆负载平衡约束;式(4)表示车辆在访问客户i之后的车载量约束;式(5)为车辆初始装载量;式(6)表示每个客户只被一辆车服务;式(7)表示相同节点之间没有路径;式(8)为车辆进出平衡约束;式(9)和式(10)保证客户点被车辆服务时一定有路径与其连接;式(11)表示车辆被使用时只有一条服务路径且从虚拟配送中心出发,并最终回到虚拟配送中心;式(12)保证了从虚拟配送中心出发的车辆数不超过总车辆数;式(13)为从任意一个配送中心出发的车辆数等于返回该配送中心的车辆数;式(14)为决策变量取值约束.
1.3.2 随机机会约束确定型等价处理
式(2)为对单个客户点的随机机会约束,由单点随机机会约束式可以得到每条配集货路径的随机机会约束式,如式(15):

即在预优化方案中,对于任意的车辆k(k ∈K),每条路径中客户点的集货量之和不超过车辆装载量的概率大于等于预设的风险偏好值α.将随机机会约束式(15)转化为确定型的等价形式,进行预优化路径客户点的选取,可以在保证得到理论上的最优解时降低计算量.

存在常数τ满足τΦ−1(α) 时,(τ为α分位点),式(16)等价于:

进而有:

将期望值和方差代入式(18):
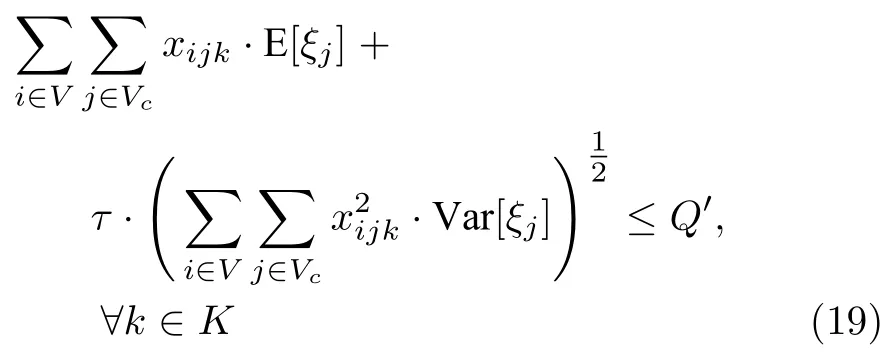
由于集货量服从泊松分布,期望值和方差相等且为λ,因而存在一个常数,使得式(15)转化如下:

1.4 重优化阶段
由于客户点集货量为随机变量,可能会导致车辆在到达某一个客户点时,车辆实时剩余空间无法满足客户的集货需求从而造成路径失败,对于服务失败的客户点称为失败点.由于预优化方案并不一定能完全实施,因此需要采取重优化策略对失败点进行合理规划.
在以往对随机需求问题的研究中,对于失败点的处理方法多为失败点返回策略、失败点前序点返回策略以及分离配集货策略三种[16−19].图2 给出了一个简单的示例,对不同的失败点重优化策略进行分析,实线代表预优化方案路径,虚线代表由重优化策略得出的路径.假设有两条预优化路径V1-1-2-6-V1、V2-4-5-3-V2(如图2(a)),V1、V2为配送中心,节点i和j之间的路径成本为cij,客户2 和客户5 为路径失败点.
1)失败点返回策略(如图2(b)).当车辆在客户2 处发生服务失败时,车辆返回配送中心后,再按照预优化方案继续对客户2 及其后续客户进行服务;客户5 同理.
2)失败点前序点返回策略(如图2(c)).在对客户2 进行服务前,对车辆剩余空间能否满足客户2 需求的期望值(或通过计算预选返回点得到路径方案的总体期望成本等方法)进行预判断,当车辆剩余空间大于等于该客户的需求期望时对其进行服务,否则车辆返回配送中心后再按照预优化方案对客户2 及其后续客户点进行服务;客户5 同理.
3)分离配集货策略(如图2(d)).若到达客户2时,车辆剩余空间无法满足客户2 的全部集货需求,则仅满足部分集货需求后,继续对其后续客户点进行服务;客户5 同理.最后将未完成服务的客户2和客户5 看作经典的VRP 问题进行求解.
上述三种策略中,失败点返回策略会造成路径的往返,导致路径成本的大量增加,而且失败点返回策略一定劣于失败点前序点返回策略,原因在于由三角形三边原理可知c12+c20>c10(客户5 同理);失败点前序点返回策略对点选择的要求严格,选取合适的返回点较为困难,对客户点不当的预判断易导致多余的返回,引起路径成本的增加;分离配集货策略缺乏对是否服务客户的预判断,可能产生多次服务客户的情况,降低客户的满意度并造成路径的往返,增加路径成本.鉴于以上三种方案存在的不足,本文采取文献[20]中所提出的路径失败点重优化策略并作出改进(如图2(e)).当车辆未能满足客户需求造成路径失败(客户2 处的失败原因)或通过预判断不对客户进行服务(客户5 处的失败原因)时,车辆返回配送中心,统计所有路径的失败点及失败点后续客户(客户点2、3、5、6),根据最近邻法求解原理,重新设计配集货路径,生成第二阶段重优化路径.在重优化路径中,客户点的集货量仍然是随机变量,因此重优化路径仍可能出现路径失败,对该情况执行失败点返回策略.由于在重优化阶段,失败点及其后续客户点的规模相对较小,而车辆的载重量较大,因此重优化路径中再次出现失败点的概率极小.
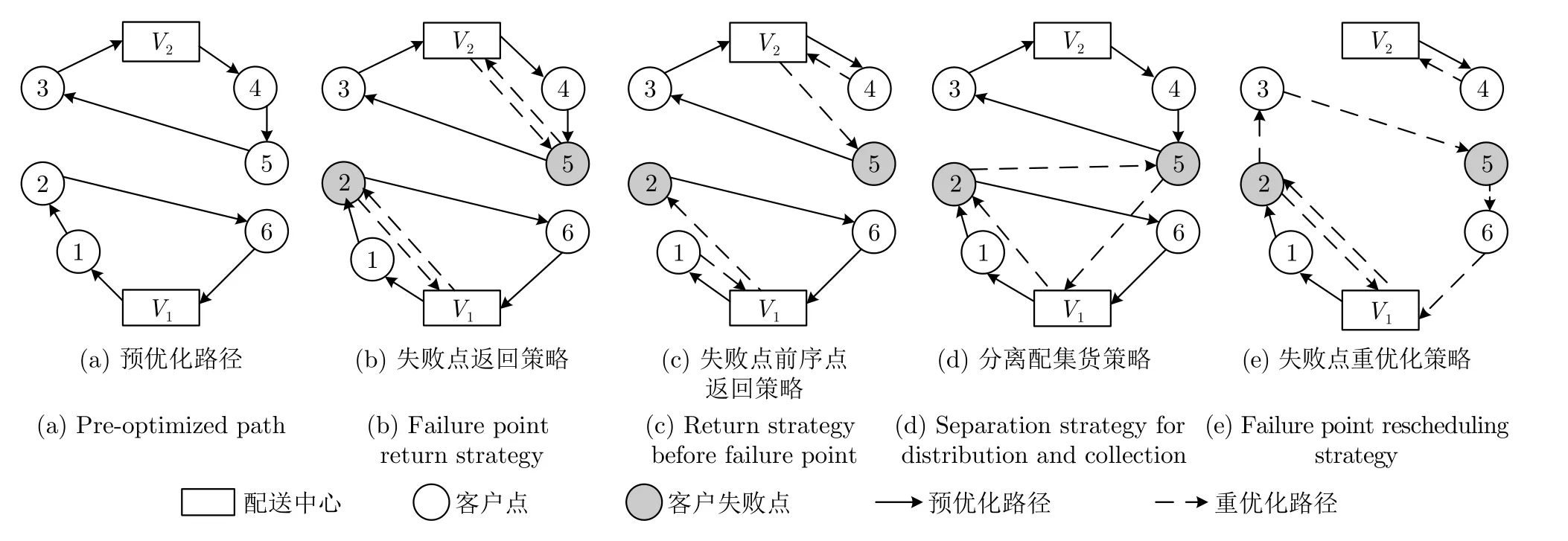
图2 不同失败点重优化策略对比图Fig.2 Different failure points re-optimized strategies
2 自适应变邻域文化基因算法
MDVRPSDDSPJD 是一类NP-hard(Non-deterministic polynomial-hard)问题,在以往对于VRP 及其拓展问题的求解算法中,元启发式算法具备较强的寻优能力,能在合理的时间内给出问题的近似最优解,广泛应用于各种VRP 拓展问题中,表现出了较强的竞争优势.其中,文化基因算法是基于文化进化理论中的隐喻机制而提出的,具有较强的全局搜索性能和局部搜索性能.变邻域搜索算法采用多个不同的邻域结构进行系统搜索,具有较强的局部搜索能力.因此,本文结合文化基因算法和变邻域搜索算法设计了自适应变邻域文化基因算法(Adaptive memetic algorithm and variable neighborhood search,AMAVNS),将变邻域搜索算法应用到文化基因算法的局部搜索策略中,加强种群的寻优能力;引入顺序交叉算子,加强种群个体间的交流;设计自适应邻域搜索次数策略和自适应劣解接受机制平衡进化所需的广度和深度,加快算法的收敛以及加强算法跳出局部最优的能力.本文的算法框架如图3 所示.
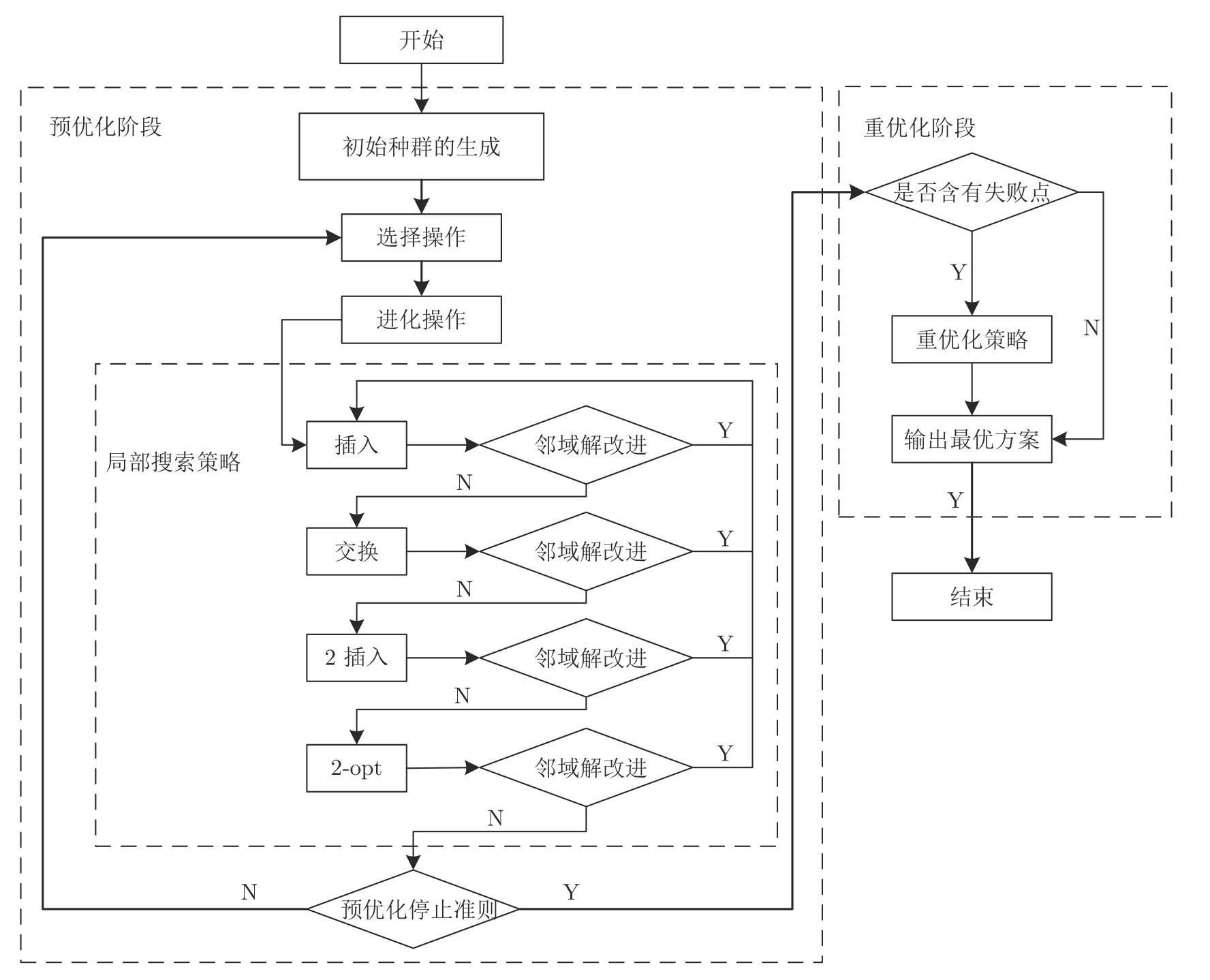
图3 自适应变邻域文化基因算法框架图Fig.3 The basic flow of adaptive memetic algorithm and variable neighborhood search
2.1 编解码方式及初始种群的生成
本文算法采用整数编码的方式,将客户的全排列存储到矩阵pop_route中,记录客户的服务顺序.解码方式分为两个阶段,第一阶段通过随机机会约束机制以及车辆载重约束检验,将客户按照初始排列顺序划分给车辆,当对下一个客户进行检验发现当前车辆不能满足要求时,派出新车对该客户进行服务;第二阶段根据每辆车首尾客户到配送中心的距离以及配送中心车辆进出平衡约束确定车辆的始末配送中心.本文给出一个简单例子来进行说明,如图4 所示,假设客户矩阵pop_route中客户排列为135674829,派出第一辆车按照客户排列顺序对第一个客户进行服务,在车辆派遣矩阵V eh_K中记录V eh_K(1)1,即第一辆车的初始服务客户为pop_route矩阵中的第一个客户;按照pop_route中客户排列顺序对下一个客户进行随机机会约束机制以及车辆载重约束检验,假设当对第四个客户6 进行检验时,不能满足检验要求,则派出第二辆车对客户6 进行服务,记录V eh_K(2)4 ;以此类推,直到最后一个客户检验完成.最后根据每辆车首尾客户到配送中心的最小距离确定始末配送中心,根据车辆进出平衡原则进行检查,对于不符合车辆进出平衡约束的配送中心进行调整,确定最终的始末配送中心.即车辆始发的配送中心矩阵V eh_K_sta以及车辆返回的配送中心矩阵V eh_K_end.客户排列最终解码路径如图5 所示.
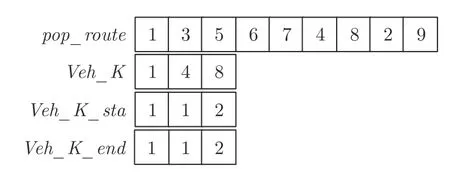
图4 编码方式示意图Fig.4 Encoding mode diagram
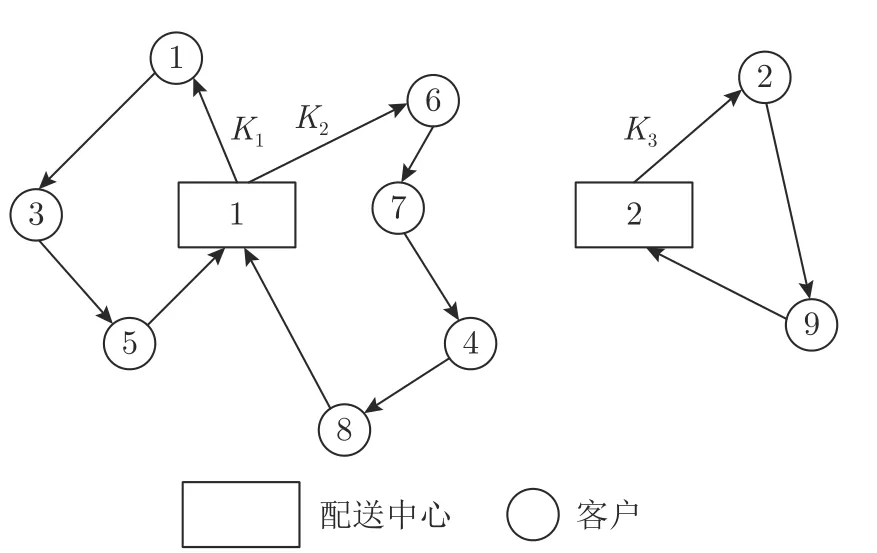
图5 解码路径图Fig.5 Decoding routing diagram
可以看出,仅需记录每辆车服务的首个客户的位置,就可以结合pop_route矩阵求得该车辆服务的客户顺序,在后续的进化操作以及局部搜索策略中也仅对编码长度固定的pop_route矩阵进行操作.采用客户排列顺序、车辆服务的客户以及车辆往返的配送中心分离编码的方式,可以使得在后续的迭代扰动时,总能生成可行解,避免了编码长度不固定以及对不可行解的修复困难等问题.
在生成初始种群方面,采用随机生成和最近邻法相结合的方式,既能够保证种群的多样性,又能通过最近邻解提高初始种群的质量,加快种群的收敛速度.
2.2 适应度函数
染色体的适应度函数根据目标函数式(1)进行构建.显然,目标函数值越大,染色体的适应度值越小,染色体S的适应度函数f S可以表示如下:

其中,ZS为染色体S的目标函数值.
2.3 选择操作
选择操作采用轮盘赌和精英保留相结合的策略.采用轮盘赌的方式,每个个体被选中的概率与其适应度函数值的大小成正比,即适应度函数值越大的个体被选中的概率就越高;反之,被选中的概率越低.采用精英保留策略,将每一代的最优个体进行保留,即用父代适应度值最优的个体替换掉子代适应度值最差的个体.采用轮盘赌和精英保留相结合的策略,可以在进化的过程中形成稳定的下一代,使得算法快速收敛.
2.4 进化操作
本文的进化操作选用顺序交叉算子.如图6 所示,对个体pop1 进行顺序交叉时,从种群中随机选取个体pop2,分别随机产生点位i11、i12,i21、i22.pop1随机点位i11、i12之间的部分作为新个体new_pop1的第一段;new_pop1的后续点位与pop2有关,即先消除pop2中包含pop1随机点位i11、i12之间的客户点,在消除过程中,pop2 中客户点的位置顺序不改变,再将消除后的客户点排列作为new_pop1的第二段,此时new_pop1 个体生成完毕.new_pop2同理.

图6 顺序交叉算子示意图Fig.6 The diagram of ordered crossover operator
2.5 局部搜索策略
文化基因算法的局部搜索策略是算法的核心功能之一,决定着算法的局部搜索能力,本文将变邻域搜索算法算法应用到局部搜索策略中,加强对种群的深度搜索.设定l个邻域结构集合N k{N1,N2,···,N l},对种群中个体x从第一个邻域结构N1开始扰动.若在预设的邻域搜索次数S n内未找到改进解,则执行下一个邻域结构.若在某一邻域结构内获得改进解x′,则令xx′,并返回第一个邻域结构重新开始迭代,直到循环到最后一个邻域结构仍未找到改进解时,搜索终止;或当变邻域搜索循环次数达到预设值M ax_S n时,搜索终止,算法进入下一阶段.本文采用如下4 种邻域结构,增强算法的局部搜索能力.
1)插入:随机选择一个客户点i,将其从原方案中移除,随机插入到某个客户点j的后面.如图7(a)所示,客户3 插入到客户6 的后面.
2)交换:随机选中两个客户点i和j,交换两客户点的位置.如图7(b)所示,客户3 和客户6 交换位置.
3)2-插入:在原方案中随机选择连续的两个客户点,将其插入到随机选择的客户点j的后面.如图7(c)所示,客户3、4 插入到客户6 后面.
4)2-opt:随机选择两客户点i和j,并将客户点间的顺序进行交换.如图7(d)所示,保持客户3的位置不变,客户4、5、7、6 逆序.

图7 邻域结构示意图Fig.7 Neighborhood structures
2.6 自适应机制
本文设计自适应邻域搜索次数策略和自适应劣解接受机制平衡进化所需的广度和深度,使算法跳出局部最优.
1)在算法迭代的不同时期,种群所需的扰动强度不同.在迭代初期,采用较低的邻域搜索次数,加快种群的收敛;随着最优解连续未改变次数的增大,增加邻域搜索次数,加强算法的搜索能力,并结合自适应劣解接受机制使算法跳出局部最优.本文的自适应邻域搜索次数策略所下.
a)设置初始邻域搜索次数为Sn1,最优解连续未改变的次数为Con_num;
b)若本次迭代后的种群最优解未改进,则令Con_numCon_num+1,SnSn+1;若迭代后的最优解存在改进,则令Con_num0,Sn1;
c)当最优解连续未改变的次数Con_num达到预设值Stop_num时,算法终止,输出最优解.
2)设计自适应劣解接受机制对是否接受扰动后的解进行判断,本文的自适应劣解接受机制如下.
a)设置阈值参数t,t1+Con_num/gen,gen为迭代的代数;
b)当扰动产生的新解x′满足f(x′)≤tf˙(x),则令xx′.
设置最小可接受劣解的代数M in_gen,即算法的前M in_gen代扰动操作禁止接受劣解,当算法迭代到中后期时,算法逐步陷入局部最优,劣解接受机制被激活.随着最优解连续未改变的次数Con_num的增加,t值逐渐增大,可接受劣解的范围也逐渐增大,增大种群的多样性,使得算法跳出局部最优.
3 算例验证及结果分析
本文选取了三类算例验证本文算法的有效性,包括MDVRP 算例、VRPSDP 算例和MDVRPSDDSPJD 算例,由于MDVRP 和VRPSDP 是本文研究的基础问题,因此首先选取MDVRP 算例和VRPSDP 算例对本文算法进行验证.本文算法编程工具采用MATLAB R2017b,操作系统为Windows10,电脑内存为8 GB,CPU 为Intel i7-7700,主频3.60 GHz.经过反复测试,本文算法参数设置如下:最大迭代次数M ax_gen800 ,种群规模Pop_size30 ∼150,初始变邻域搜索次数Sn1,最大邻域循环次数M ax_Sn1 000,最优解连续未改变的最大次数Stop_num20 ∼50,最小可接受劣解的代数M in_gen30 ∼100 .参数的设置值同对应算例中客户点规模n相关,当n ≤30 时,Pop_size设置为30,Stop_num设置为20,最小可接受劣解的代数M in_gen30;当 30 实验1.选取文献[21]中提出的MDVRP 算例,客户规模为30,含有3 个配送中心(A、B、C)且每个配送中心含有4 辆车,目前已有文献对该算例求得的最优解为116.01.表1 给出聚类分层法[22],狼群算法[23],文献[24]中提出的禁忌搜索算法、量子遗传算法、云量子遗传算法以及本文的自适应变邻域文化基因算法求解10 次的计算结果.其中文献[22]中聚类分层法采用分区域配送的方式,文献[23−24]以及本文算法均采用联合配送的方式进行配送.BK S为目前已有文献求得的最优解,Best、Worst、Avg分别为算法运行10 次所求得的最优解、最劣解和平均解,%Dev为算法求得的解同目前已知最优解的偏差,CPU为算法运行时间. 由表1 可以看出,在求解质量方面,文献[22]通过分区域配送方式将多中心问题转化为单中心问题进行求解,这种求解思想从本质上来看是局部优化的思想,求解效果最差.本文算法对现有最优解进行了改进,求得最优解为113.62,较原有文献求得的最优解改进了2.06%;在求解最劣解以及平均解方面,也均优于其他算法.在计算时间方面,本文算法运行时间仅为4.78 s,相较于其他算法,具有较强的竞争优势.表2 给出本文求解的车辆行驶路径.图8 给出了最短路径变化趋势图,可以看出本文算法可以在较少的迭代次数内快速收敛,当算法陷入局部最优解时,可快速跳出局部最优,具有较好的寻优性能. 图8 最短路径变化趋势图Fig.8 The iterative trend of optimal solution 表1 算法性能比较Table 1 Performance comparison of different types of metaheuristics 表2 本文算法求解路径Table 2 The algorithm solution path of this paper 实验2.选择由标准算例库提供的MDVRP 算例集对本文算法进行验证(算例集来源:http://neo.lcc.uma.es/vrp/vrp-instances/multiple-depotvrp-instances/).表3 给出了贪婪随机自适应搜索算法(GRASP/VND)[25]、遗传算法(GA)[26]、迭代局部搜索算法(ILS)[27]以及本文的AMAVNS 算法运行10 次的最优解.BK S为算例库中给出的已知最优解,Best为算法运行10 次所求得的最优解,%Dev为算法求得的最优解同已知最优解的偏差,CPU为算法平均运行时间. 由表3 可以看出,在对7 个标准算例的求解中,GRASP/VND 算法、GA 算法以及ILS 算法均未找到最优解.GRASP/VND 算法求解质量最差,求解最大偏差为11.85%,平均偏差4.81%;GA 算法求解质量一般,最大偏差9.05%,平均偏差3.12%;ILS 算法求解最大偏差6.09%,平均偏差4.51%.本文AMAVNS 算法求解速度略差于其他三种算法,但求解质量最优,求得其中两个最优解,最大偏差3.80%,平均偏差1.76%.验证了本文算法的有效性. 表3 MDVRP 算例结果比较Table 3 The results comparison of MDVRP instances 实验3.选择由Dethloff[28]提出的客户规模为50 的测试算例,算例根据两种不同的地理情况分为SCA(Scattered)和CON(Concentrated)两大类.表4 给出了禁忌搜索算法(TS)[29]、并行节约算法(EPSA3)[30]、节约蚁群算法(SavAnt)[31]、分散搜索算法(SS)[32]以及本文的AMAVNS 算法在SCA8和CON8 的20 个算例中运行10 次的最优解.Best表示算法求解该算例得到的最优值,%Dev表示每个算例中各算法的最优解同5 个算法中最优解的偏差,CPU为运行时间.图9 给出了本文算法在算例SCA8-0、SCA8-1 的求解路径图. 图9 实验3 部分算例的求解路径图Fig.9 The specific path diagrams of some cases of experiment 3 由表4 可以看出,在SCA8、CON8 共20 个算例中,TS 算法求得了其中6 个最优解,最大偏差2.65%,平均偏差0.83%,算法耗时较短;EPSA3算法求解运行时间最短,但求解质量最差,仅求得其中1 个最优解,最大偏差5.57%,平均偏差2.52%;Sav Ant 算法求解时间最长,求得4 个最优解,最大偏差2.69%,平均偏差0.61%;SS 算法求得其中6 个最优解,最大偏差2.65%,平均偏差0.83%;本文AMAVNS 算法求解速度良好,求解质量优于其他4 种算法,求得其中13 个最优解,最大偏差0.83%,平均偏差0.12%,在未取得最优解的算例中,偏差均保持在1%以内.再次验证了本文算法的有效性及算法的稳定性能. 表4 VRPSDP 算例结果比较Table 4 The results comparison of VRPSDP instances 实验4.由于现有研究没有关于MDVRPSDDSPJD 问题的标准算例,通过对标准MDVRP 算例p01 进行修改以适应本文的模型.p01 算例含有4 个配送中心(配送中心编号51~54),每个配送中心含有4 辆同质车辆,车辆容量为80,客户规模为50(客户编号1~50).客户的配、集货量由Salhi 等[33]提出的需求分离规则产生:x i和y i是客户的坐标,q i为客户i的原始需求,计算每个客户的比率r imin(x i/y i;y i/x i),由dir i q i和ξiq i d i计算得出该客户的配、集货量.在对客户进行配送路径优化时,客户的集货量是未知的,仅能知道客户需求服从λ6.34 的泊松分布.车辆从配送中心出发,服务完客户后返回配送中心.目标是规划车辆行驶路径,使得总路径成本最低.表5 给出传统的车辆返回原配送中心规则(规则1)和本文提出的车辆返回规则(规则2)在不同风险偏好值决策下分别求解20 次的计算结果.Best为该规则下求解的最优解,Avg为算法运行20 次的平均解,%Dev为规则2 在最优解和平均解方面相较于规则1 的偏差,CPU为算法运行时间.表6 给出算法所求最优解对应的车辆行驶路径. 由表5 可以看出,在不同风险偏好值决策下,求解结果具有明显的区别,规则1 在α0.7 时求得最优解533.85,平均值为624.97;规则2 在α0.7时求得最优解499.96,平均值为610.54.当风险偏好值α增大时,决策者偏向于保守型,希望以较大的概率成功服务客户.对于服务成功概率较小的客户点,选择不去配送,提前返回配送中心,导致在重优化阶段需要为其重新规划路径,造成了路径成本的增加.当风险偏好值α减小时,决策者偏向于冒险型,希望一辆车能够服务更多的客户.然而由于随机因素的影响,导致车辆剩余空间无法满足客户的集货需求,造成服务客户失败,需要折返配送中心后,重新为其服务.因此,冒险型决策的路径失败造成的额外路径成本要大于保守型决策的额外路径成本.基于此,本文建议决策者风险偏好值α取0.7 左右,既能防止由于α值偏大,一辆车服务客户数较少的弊端,又能避免由于α值过小,频繁折返配送中心,造成额外成本的增加. 此外,通过规则1 和规则2 的对比,可以看出,本文提出的车辆返回规则较传统的车辆返回原配送中心规则在最优解方面改进了6.35%,使用车辆数减少了一辆,在总的求解平均值方面改进了4.45%.这是由于传统的车辆返回原配送中心规则仅考虑了配送中心之间客户资源的共享,缺乏对于车辆资源的统一调配,导致车辆返回配送中心受到限制,造成路径成本的增加.实验结果表明,本文提出的车辆返回规则能够有效地降低路径成本,为多个配送中心之间车辆联合调度提供参考. 本文针对多中心联合配送模式下集货需求随机的同时配集货车辆路径问题进行了研究,主要结论如下. 1)本文提出的MDVRPSDDSPJD 问题不仅考虑了多中心联合配送、客户及车辆资源共享,而且考虑到客户同时具有配集货需求且集货需求为随机变量的情况,是对MDVRP、VRPSDP 等研究的进一步深化和拓展. 2)基于多中心联合配送的特点,提出车辆返回规则.即车辆从配送中心出发,可返回任意配送中心,但需保持每个配送中心车辆进出平衡.经验证表明,该规则较传统的车辆返回规则有明显的改进,能够有效降低企业的路径成本. 3)设计的自适应变邻域文化基因算法,将变邻域搜索算法引入文化基因算法的局部搜索策略中,提高了算法的寻优性能;设计的自适应邻域搜索次数策略和自适应劣解接受机制能够平衡算法进化所需的广度和深度,提高了算法跳出局部最优的能力. 4)通过多组算例对本文的模型及算法进行验证,结果表明,所建的模型及设计的算法能有效解决MDVRPSDDSPJD 问题,同其他类型的算法进行比较,本文算法寻优能力较强、搜索稳定,具有较强的优势. 本文的研究能为具有多个配送中心的物流企业实施多中心联合配送提供较好的解决方案.但需要指出的是,物流企业可能面临多重不确定环境且车辆调度会受到客户时间窗因素的影响,如何在时间窗约束下刻画和解决多重不确定环境下的车辆调度问题是未来需要继续研究的方向.3.1 MDVRP 算例分析




3.2 VRPSDP 算例分析

3.3 MDVRPSDDSPJD 算例分析
4 结论
