一种基于P圈的BIER快速重路由算法
2021-08-26王文鼐庄金成
赵 光,陈 睿,王文鼐,庄金成,王 斌
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
预测表明,至2021年多媒体业务将占所有网络流量78%[1],其中多播类业务的承载优化成为网络技术发展的关键之一[2]。IP多播用于向多播组成员复制和分发内容,具有高效与并发的特点。传统IP多播的转发设备需要维持IP多播组的中间状态,降低了其扩展性[3]。BIER(Bit Index Explicit Replication)是一个基于分段路由(Segment Routing,SR)的新多播协议[4],它由源端或入口路由器定义转发路径并将控制信息随分组一同发送,网络中间路由器不再需要维护多播组状态,而是基于单播方式传送分组,业务得到显著增强。
IP单播本身并不支持快速故障保护[5],一旦通信链路或设备出现故障,在路由的重收敛过程中,业务会出现长时延和分组丢失等多种问题。这对时延和丢失敏感的业务,如流媒体、网络游戏以及线上视频会议等,极易造成性能降低甚至业务中断,需要采用相应的保护机制来快速恢复。
快速重路由(Fast Re-Route,FRR)为潜在网络故障提前计算备份路径,得到广泛关注。P圈(Preconfiguration Cycle,P-Cycle)是一种基于环结构的FRR方案[6],它利用空闲资源预先设置环形通道以实现对网络的快速保护。
关于P圈构造算法研究有很多,经典的P圈构造算法有Straddling Link Algorithm(SLA)[7]。SLA的做法是遍历拓扑中每一条边e,以e的两个端点作为起点和终点,利用Dijkstra算法在这两点之间找到两条分离且不包含e的路径,如果找到,则将两条路径首尾相连组成一个P圈。基于经典算法的改良算法有文献[8-10]。P圈的先验效率[8]指的是为一个P圈能保护的所有工作容量和配置这个圈所要消耗网络容量的比值。改良算法大多数追求的是构造出的P圈能够具有的更高先验效率,然而它们并没有考虑网络资源是否具有方向区分这个前提,构造出的P圈并不具有方向性。
文献[11]提出了一种保护光网络多播传输的P圈方式,优化了受保护的光网络的工作和备用容量。文献[12]提出了一种改进的P圈构造算法,该算法在选择扩展圈时考虑了扩展圈中未受保护的工作容量的冗余和方差,从而提高了保护效率并减少了资源消耗。目前基于P圈的多播业务保护算法都是针对传统IP多播,而BIER能实现极简的多播网络,基于此设计P圈业务保护相对而言更为简单经济。
在BIER协议实现多播业务的基础上,本文聚焦于P圈解决BIER多播的链路故障及快速重路由。技术出发点是,根据多播业务的特点构造有方向的P圈序列,并通过广度优先搜索(Breadth First Search,BFS)为中间路由器计算出BFR转发表(Bit Index Forwarding Table,BIFT)。通过对NSF拓扑(14个节点,21条链路)的仿真实验验证了算法的可行性。
1 技术背景与故障保护需求
IP多播沿多播树传送多播分组,为此要求转发路由器维护多播树状态。当多播组成员数量较大,路由器需要维护大量的转发状态;当有成员加入、退出多播组,路由器需要更新转发状态,这限制了IP多播的可扩展性。因此,在IP多播中实现路由保护是困难的。
BIER技术是一种新型多播技术,它将多播承载网络中的核心网部分替换为BIER域。BIER域包括位转发入口路由器(BFIR),位转发路由器(BFR)和位转发出口路由器(BFER)。
BFIR在发送多播分组到BFER时,将BFER的标识(BFR-id)信息编码到多播分组BIER头部中的比特位串(BitString)中。BFR通过BIFT转发多播分组。BIFT中有一列字段为转发比特掩码(FBM),它是由有相同下一跳的BFR-id进行逻辑或得到的。BFR将分组头部的BitString和F-BM进行逻辑与,复制有相同下一跳的多播分组并进行转发。
BIER本质上等同于IP单播,中间路由器不需要维护多播树状态,处理多播分组可以像单播一样通过BIFT复制转发分组。因此基于BIER的保护本质上是对IP单播的保护。
文献[13]介绍了几种IP单播的FRR机制,包括Not-Via Adresses、Loop-Free Alternates(LFA)、Remote LFA、Directed LFA等,文献[3]提出了2种针对BIER的FRR机制,包括LFA和基于隧道的FRR。LFA需要增加标识开销,仅能保护70%的目的地免受单链路故障的影响。基于隧道的FRR,要在路由表中引入大量的备份条目,存在较重的空间开销。
P圈也是一种常见的FRR机制,基于P圈的BIER多播路由保护目前尚无人研究。由于目前的P圈构造算法不能构造出具有方向的P圈,因此需要设计一个有向的P圈序列构造算法,并在生成的有向P圈序列上实现BIER的快速重路由。
2 算法描述
2.1 P圈序列构造
P圈序列构造算法利用初始链路并通过有向P圈构造算法构建出初始P圈,利用已构建P圈上的扩展链路扩展出新的P圈。由于拓扑的随机性,某一个初始P圈扩展出的P圈序列可能无法覆盖拓扑中所有链路,所以需要选择未遍历过的链路作为初始链路再次构建初始P圈,并扩展出其他的P圈序列。
拓扑中可能存在一些特殊的链路,这些链路不能通过有向P圈构造算法构造出P圈,所以无法通过P圈对这些链路进行保护,本文将此种链路称之为孤立链路。
如图1所示的拓扑,其中空心圆点中的数字代表节点的序号,实际可由BFR的BFR-id确定。链路(3,4)为一条孤立链路。P圈用节点序列表示,如{1,2,3,1}代表拓扑中的一个P圈。
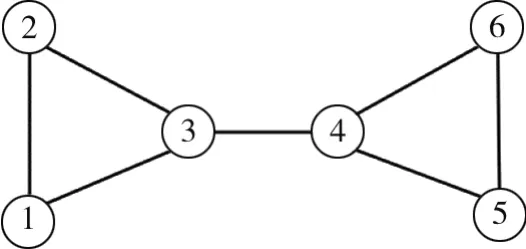
图1 孤立链路示例拓扑(空心圆点表示节点,连线表示链路)
根据有向链路e构造出有向P圈的算法伪代码如算法1所示。
算法1有向P圈构造算法
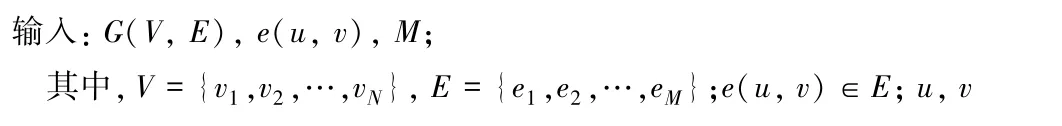

算法1是采用python格式语法描述。其中,输入参数G为网络拓扑,是节点集合V和链路集合E的序偶;参数e是从节点u指向节点v的有向链路;参数M是P圈构建时的标记链路集合。
算法1的第2行,调用Dijkstra[8]函数计算节点v到u的最短路径,计算时忽略M中的链路。因此,算法1计算出的最短路径和被标记的链路是分离的。由于Dijkstra函数返回的最短路径是v到u节点序列,所以算法1的第4行调用head函数在节点序列头部加入节点s,使其变成方向是u到v的P圈。
例如,针对图1所示的拓扑,传入的e(u,v)是有向链路(1,2),M包含e,则调用Dijkstra函数后返回节点序列{2,3,1},最后返回的P圈是{1,2,3,1}。如果是无法计算出最短路径的情况,如传入的e(u,v)是有向链路(3,4),则直接返回空序列。
P圈序列构造算法如算法2所示。
算法2的思想是遍历拓扑中所有链路,确定初始链路并构造出初始P圈,其他P圈通过已构造P圈上的扩展链路扩展得到。如果是无法构造P圈的链路,则加入到孤立链路集合中。当无法扩展出新P圈且拓扑中仍存在未遍历的链路时,则会在未遍历过的链路重新确定初始链路并继续扩展新P圈,直到所有链路都被遍历过。
算法2P圈序列构造算法


算法2中1至2行是初始化相关变量,3至10行是遍历拓扑中未被遍历的链路并生成初始P圈,11至31行的逻辑是根据初始P圈扩展出新P圈。
1至2行中,队列R代表最终得到的P圈序列;队列O代表孤立链路的序列;队列T是用来存储构造出且未被遍历过的P圈序列,是辅助算法执行的队列;序列F最开始等于拓扑链路集合,存储的是未被遍历过的链路。
3至10行中,pcycle函数即算法1表示的有向P圈构造函数。如果生成的初始P圈是空,则将当前链路加入到孤立链路集合O中,结束此次循环。否则,通过enque函数把生成的P圈加入到R和T中,进入扩展P圈逻辑。
11至21行中,edge函数是将以节点序表示的P圈转换成以有向链路表示的P圈,如{1,2,3,1}将转换成{(1,2),(2,3),(3,1)}。deg函数是求节点的节点度,当一条有向链路上的两端节点的节点度都大于等于2,该链路即为扩展链路。
22至24行中,为了确保扩展出的P圈不同于该链路所在的P圈,会去断开原P圈中的每一条边,再尝试构造新P圈。
25至31行中,通过循环扩展出所有包含扩展链路的P圈,下次循环会将上次循环生成的P圈中链路加到标记链路集合M中。通过hasNewEdge函数判断扩展出的新P圈是否拥有已生成P圈不包含的链路。如果函数返回是,则将其加入到队列R和T中;否则将忽略该P圈,并结束循环。
按照添加到队列R的先后顺序定义P圈的优先级大小,先添加到序列R的P圈优先级更高,P圈的优先级将作用于确定链路方向上。
由于每条链路只会遍历一次且拓扑中链路数目是有限的,所以本算法中的遍历有终止条件。
为了更形象地说明P圈序列构造算法,举例如下。图2(a)代表示例拓扑。
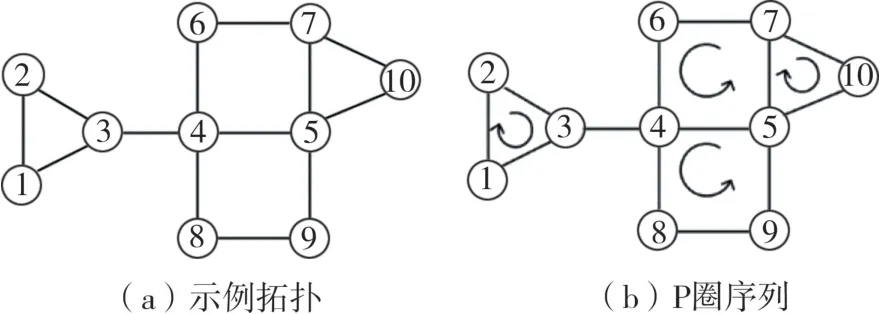
图2 P圈序列构造算法示例
初始化序列R、O、T和F。从F中弹出一条链路得到初始链路(1,2),构造出P圈{1,2,3,1}加入R、T中。从T中取出并把链路(2,3)、(3,1)从F中剔除。
此时F不为空且无法扩展出新P圈。链路(3,4)是链路(1,2)的后续链路,从F中弹出初始链路(3,4),因为无法通过(3,4)构造P圈,把链路(3,4)加入O中。
链路(4,5)是链路(3,4)的后续链路,弹出初始链路(4,5),构造P圈{4,5,7,6,4}。通过扩展链路(5,7)扩展出P圈{5,7,10,5},删除F中对应链路。
链路(4,8)是链路(4,5)的后续链路,弹出初始链路(4,8),构造P圈{4,8,9,5,4},删除F中对应链路。此时F为空,结束循环。最后生成的P圈序列如图2(b)所示。
2.2 生成路径
针对通过上述P圈序列构造算法生成的P圈序列,提出一种算法,先通过P圈优先级确定拓扑中链路的方向,再通过BFS思想,从源节点src出发,按链路的方向搜索,最终生成从src到其他节点的工作路径和保护路径集合。
生成工作路径算法如算法3所示。算法3生成工作路径算法


算法3中,1至5行是初始化过程;6至13行是通过P圈序列和孤立链路集合确定链路方向;14至22行是确定pre数组;23至30行是通过pre数组确定工作路径集合。
1至5行中,m表示拓扑的邻接矩阵。pre[i]代表第i个节点的父节点是第pre[i]个节点。U为BFS的辅助队列,T为已遍历节点的集合,W是工作路径集合。
6至13行中,按照优先级遍历P圈序列,当某条链路在多个P圈中,该链路的方向由优先级最高的P圈方向决定。11至13行表示对于孤立链路集合中的链路,规定其方向是双向的。最后m保存的是拓扑中所有链路的最终方向。
当确定拓扑中链路方向后,通过BFS确定src到其他节点的最短路径。
保护路径集合是从src到其他节点且逆着链路方向的最短路径集合,因此在生成工作路径算法上第9、10行将u和v互换,即可得到生成保护路径算法。
举例说明,图2(a)示例拓扑最终生成的P圈序列如图2(b)所示。在生成工作路径算法中,先通过P圈序列和孤立链路集合确定拓扑中链路方向,如图3(a)所示。因为链路(4,5)所在的P圈{4,5,7,6,4}比P圈{4,8,9,5,4}优先级高,所以该链路的方向最终是4指向5。生成保护路径算法中,链路方向如图3(b)所示。

图3 链路方向图
假设源节点src为序号4的节点,目的节点集D为其他剩余的节点。对应的工作路径集合如图4(a)所示,保护路径集合如图4(b)所示。

图4 节点4的工作路径和保护路径
在生成路径算法中,通过P圈序列和孤立链路集合确定拓扑中链路方向后,从拓扑的任何一点出发并沿着链路方向能到达拓扑中的其他任何点,证明如下。
为便于叙述,现假设如下:某条初始链路e1生成的初始P圈p1;通过p1上的扩展链路扩展出P圈序列R1;另一条初始链路生成并扩展出P圈序列R2。
情况1:从p1的某一点出发,当到达p1上的某条扩展链路e2时,因为通过e2扩展出的P圈p2拥有和e2一致的方向,所以可以通过e2的尾节点进入p2。如图3(a)中初始P圈{4,5,7,6,4},可通过节点7进入扩展P圈{5,7,10,5}。同理通过p2上的扩展链路可以进入基于p2扩展出的P圈,因此有结论:从p1上的任意一点能到达R1中的任意一点。
情况2:从R1中某一个P圈p3扩展出的P圈p4的某一点出发,当到达p3扩展出p4的扩展链路e3,可以通过e3的尾节点进入p3。同理可通过某条扩展链路进入某个扩展出p3的P圈,直到进入到初始P圈p1。又因为情况1结论,因此有结论:从R1中的任意一点能达到R1中的任意一点。
情况3:若R1和R2相邻,相邻关系有两种情况。如果R1和R2是通过某个共享节点连接,如图5(a)所示,则可以通过共享节点进入相邻的P圈序列。如果R1和R2是通过一条或多条孤立链路连接,如图5(b)所示,因为孤立链路是双向的,则可以通过孤立链路进入相邻的P圈序列。又因为情况2结论,因此得出结论:从某个P圈序列的任意一点能达到相邻的P圈序列的任意一点。

图5 P圈序列相邻情况
情况4:从拓扑中任意一点出发。如果该点不属于任何P圈序列,可通过孤立链路进入某一个P圈序列。从某个P圈序列中某点出发,可以根据情况3结论进入相邻P圈序列,从而进入任意P圈序列,最终可以到达拓扑中任意一点。
2.3 路由表
BFR通过查询BIFT转发多播分组。BIFT由三列组成。第一列表示目的节点的BFR-id,由SI(Set Identifier)和BitString组合而成,其中SI表示集合识别码,用来标识不同集合中BFR,BitString表示该SI下目的节点的BFR-id。图2(a)示例拓扑中,只有一个集合,所以SI为0。第二列代表F-BM。第三列代表转发分组到目的节点的下一跳BFR。
为了将工作路径和保护路径配置到路由表中,本算法在传统的BIFT上进行了改造。路由表条目分为两部分,第一部分代表正常情况下路由器执行的工作条目;第二部分代表当检测到工作路径上链路发生故障时,路由器执行的保护条目。
针对图4(a)对应的工作路径集合和图4(b)对应的保护路径集合,可得BFR-id为4的BFR的BIFT表,如表1所列。

表1 节点4的BIFT表
因为没有P圈对孤立链路进行保护,当孤立链路发生故障时,此算法无法进行保护。
本算法不能保证在同一时刻对工作路径上所有的链路进行保护。如果工作路径上多条链路同时出现故障,只要任意一条链路对应的保护路径和任一链路没有共享边,即能同时对多条链路进行保护;否则,同一时刻只能保护其中一个链路。
举例如下,如图3所示工作路径集合和保护路径集合。本算法可同时对链路(1,2)和链路(4,5)进行保护,因为(1,2)所对应的保护路径{1,3,2}和(4,5)没有共享边,且(4,5)对应的保护路径{4,6,7,5}和(1,2)没有共享边。对于链路(4,5)和链路(5,7),因为(4,5)对应的保护路径{4,6,7,5}和链路(5,7)有共享边,则同一时刻只能保护其中一条。
3 仿真和结果分析
3.1 算法结果
仿真采用NSF网络拓扑模型[14](14个节点,21条边),如图6(a)所示。

图6 NSF拓扑(虚线箭头表示3个P圈(P1、P2和P7))
SLA[7]算法会保存每一个生成的P圈,因此得到的P圈数目是巨大的。在算法2中,因为有hasNewEdge函数的限制条件,只有扩展出的P圈拥有已生成的P圈没有的链路时,才会保存该P圈,因此最终生成的P圈数目一定不会超过拓扑中链路的个数,这可以很好地限制P圈数目。
表2给出了本文所提算法与SLA[7]针对NSF拓扑的对比计算结果。

表2 P圈算法的对比结果
由表2可见,所提算法生成的P圈个数远小于SLA。这对于多播型业务树的构造,其计算复杂度可以得到有效控制。而先验效率降低的原因,是因为所提算法没有充分利用跨接边的潜力。此外,所提算法所具备的方向性参数,可用于多播保护路径的进一步优化。
通过P圈序列构造算法对NSF网络构造的P圈共有7个,没有孤立链路。按照优先级排序,生成的P圈序列如表3所示。
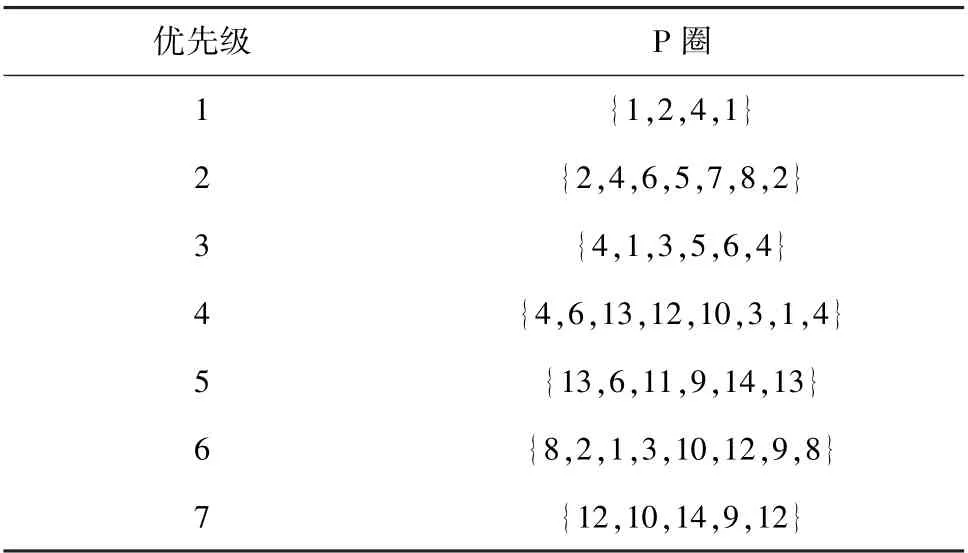
表3 NSF的P圈序列
在生成工作路径算法中,通过P圈序列和孤立链路集合确定拓扑中链路方向,NSF链路方向如图6(b)所示。其中图6(b)中虚线箭头表示的P圈有P1、P2和P7,对应表3优先级为1、2和7的P圈,表中其他P圈暂未在图中标出。需要注意的是,P圈方向和链路方向没有必然联系,如图6(b)中P7方向和最终链路方向(12,9)相反。链路方向需通过算法3和P圈序列确认。
通过算法3计算,可得BFR-id为1和4的BFR的BIFT表,分别如表4和表5所示。

表4 节点1的BIFT表

表5 节点4的BIFT表
3.2 快速重路由
每个BFR通过算法3确定工作路径和保护路径,配置BIFT。当检测到工作路径上链路出现故障,BFR可以将受影响业务迅速切换到保护路径上,从而实现快速重路由,达到快速恢复多播业务的目的。
在本方案中,采用为BIER分组添加外层的BIER头部实现路径的切换。
为了区分多播分组进入BIER域增加的BIER头和启用保护条目而新增的外层BIER头,需要在BIER头中设置一个比特大小的标记位Dbit作为区分依据。本算法利用BIER头中Rsv[15]字段作为Dbit字段。当BFR收到分组BIER头中Dbit字段为0的分组,将会查找BIFT中工作条目,并根据工作条目进行转发分组。相对地,当收到Dbit字段为1的分组,BFR将会查找BIFT中保护条目,并根据保护条目进行转发分组。
下面举例说明快速重路由过程。
如图6(a)所示NSF拓扑,当链路(1,2)发生故障时,BFR-id为1的BFR检测到BFR-id为2的BFR不可达,此BFR将会给下一跳是2的BIER分组新加一个BIER头,其中BitString设为2,Dbit字段设为1,并根据表4中的保护条目,转发给BFR-id为4的BFR。
当BFR-id为4的BFR收到该分组后,因为Dbit字段为1,所以会查询自己BIFT中保护条目,如表5所列,将分组转发给BFR-id为2的BFR。
当BFR-id为2的BFR收到该分组后,发现BitString代表的BFR是其本身,则会去掉最外层的BIER头,接下来根据内层的BIER头的BitString查找工作条目继续转发分组。
4 结束语
针对时延和丢包敏感的多播业务,需要采取保护机制来快速恢复业务。BIER是一个基于分段路由的多播技术。因为中间路由器不需要维护多播树状态,BIER本质上等同于IP单播。
本文在利用BIER协议实现多播的基础上,提出了一种全新的基于P圈的快速重路由算法,用以解决链路故障导致多播业务中断的问题。通过构造出有向的P圈序列确定链路方向,分布式计算每一个BFR的BIFT。当检测到链路出现故障时,启用BIFT的保护条目来快速恢复业务。通过本文讨论,可以发现本算法在实现时对BIER协议改动不大,因此适宜快速部署到BIER网络中。
