针对Tor的网页指纹识别研究综述
2021-08-17孙学良黄安欣罗夏朴
孙学良 黄安欣 罗夏朴 谢 怡
1(厦门大学信息学院 福建厦门 361005) 2(福建省智慧城市感知与计算重点实验室(厦门大学) 福建厦门 361005) 3(香港理工大学计算机系 香港 999077)
Web服务给人们的生活工作带来极大方便,但也使得私人信息大量地暴露于网络.例如,为提升体验,电子购物、银行服务和远程医疗网站跟踪和分析用户的消费习惯、经济和健康状况,可能会带来服务商信息泄露和不法分子窃取侵害的风险.因此互联网隐私保护越来越受到重视,主要措施包括加密通信和匿名访问.
加密通信协议从最初的SSL1.0(secure socket layer),发展到TLS1.3(transport layer security)[1],并成功应用于HTTPS(hyper text transfer protocol over secure socket layer)[2-3].2018年全站HTTPS化后,网页访问的明文传输数据越来越少,但访问过程产生的网络流量仍会暴露使用者的意图[4].例如分析未加密的DNS(domain name system)请求能获知用户要访问的网站;从数据包的目标IP地址能反向解析出域名;从TLS连接建立过程中的Client Hello和Server Certificate能获知明文域名信息.目前,DoT[5-6](DNS over TLS)和DoH[7](DNS over HTTPS)协议正致力于解决DNS加密问题;ESNI[8]和TLS1.3也将加密相关域名信息.相较于协议标准的缓慢升级,自由开源的隐私保护技术更受关注,Tor[9-10],AN.ON[11],FreeNet[12],I2P[13]等匿名访问网络应运而生.用户可以通过匿名网络在互联网上进行私密浏览、匿名访问和发布信息,不但保护隐私,还能防止追踪甚至避开网络审查.
尽管匿名网络加密了所有敏感信息,通过监听和分析网络流量仍能判断用户是否访问某个网页.因为构成每个网页的CSS(cascading style sheets)和JavaScript代码、图片、视频、广告等元素不完全相同,访问过程中产生的网络流量就有区别,例如数据包的大小、顺序和时间等非敏感信息可以形成网页指纹(Webpage fingerprinting, WF).将搜集到的网络流量与已知网页访问流量的指纹进行对比,就能获知用户访问的隐私信息.匿名网络技术给网页指纹识别带来许多新的挑战,已成为网络安全研究的热点.
但Tor等匿名网络也常常被不法分子滥用以遮盖其网络犯罪行为[14-16],严重违背了保护用户隐私和匿名性的设计初衷.若缺乏有效的监管技术,政府难以识别追踪隐藏在匿名网络中的非法地下网站,无法准确打击相关犯罪行动.因此,提高匿名网络的监管水平势在必行,而网页指纹识别的方法恰好能对匿名网络实施监管和审查.可见无论从隐私保护还是网络监管的角度来说,网页指纹识别都是需要重点关注的技术手段.为方便阐述,本综述将网页指纹的使用者(1)网页指纹的实际使用者可能是审查网络环境的管理/执法人员,也可能是侵害用户隐私的不法分子.统称为攻击者.
1 简 介
在网页指纹识别中,用户的身份可由IP或MAC(media access control address)地址、NAT(network address translation)记录等信息来确定;而攻击者通过监听用户访问页面的流量并分析其模式与特征,来判断用户当前访问的页面.该攻击者可以处于多个网络位置,例如与互联网服务提供商、Tor入口的控制者以及与用户处于同一AP接入点的恶意攻击者.早期研究将网页指纹识别视为匹配问题[17-19],对捕获的用户流量构造特征生成网页指纹,与已知网页指纹进行匹配从而判断其归属.如今,网页指纹识别以机器学习的视角转换为分类问题[20-21].攻击者首先使用提前收集的若干目标网页(也称受监视页面)的访问流量训练分类器,然后输入被捕获的用户访问流量,可输出分类结果,即判断用户访问了某个受监视页面.根据不同划分标准,如目标网络协议、特征提取、分类器选择、协议数据单元和浏览器模式,网页指纹识别可分为不同类型,如图1所示.
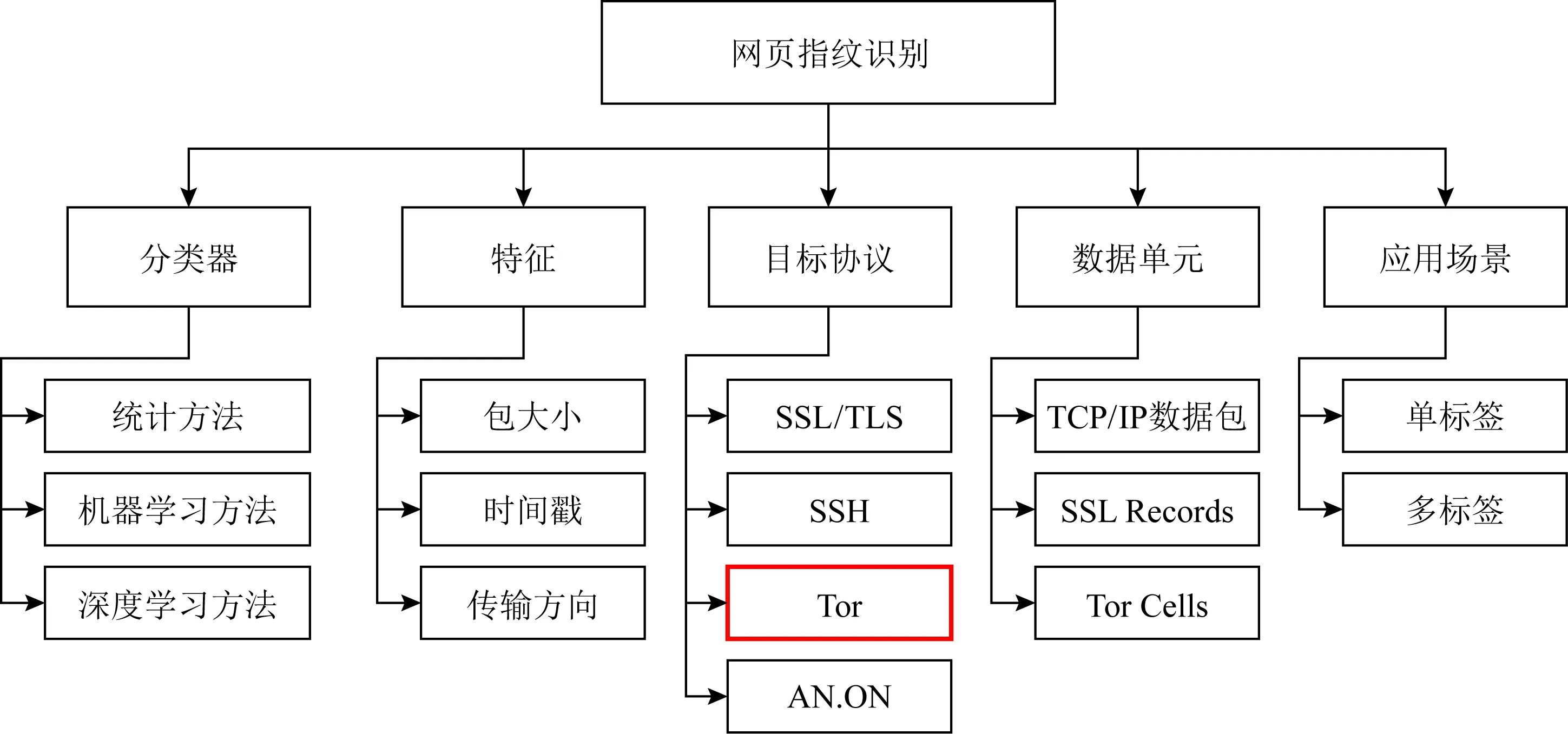
Fig. 1 The classification of Webpage fingerprinting identification图1 网页指纹识别的分类
由于加密程度较低,早期针对HTTP的识别[17]比较容易从流量中提取有用信息,来确定用户访问的网页.随着SSH(secure shell)和TLS加密网页的流行,研究者也有针对性地提出许多准确率高的网页指纹识别方法[21-25].由于SSH和TLS加密通信仅加密明文内容(例如通信内容),而不对流量本身的一些统计学特征进行加密(如数据包的大小和到达顺序等),因此攻击者可以将流量中独特的数据包大小与网页建立匹配关系[26],从而获知用户访问的页面.近年涌现了加密程度更高的网络,特别是以Tor为代表的匿名网络兴起给网页指纹识别带来新的挑战.Tor不仅通过多个中间节点的跳转隐藏了通信双方的真实身份,还通过分割流量数据为固定长度512 B的cell,并采用周期性切换circuit等匿名手段[9,27],消除了许多常用的流量特征,使早期的网页指纹识别失效[21].因此针对Tor加密流量的监管和识别成为亟待解决的重要问题.本综述将重点关注适用于Tor加密的匿名网页访问的网页指纹识别方法.
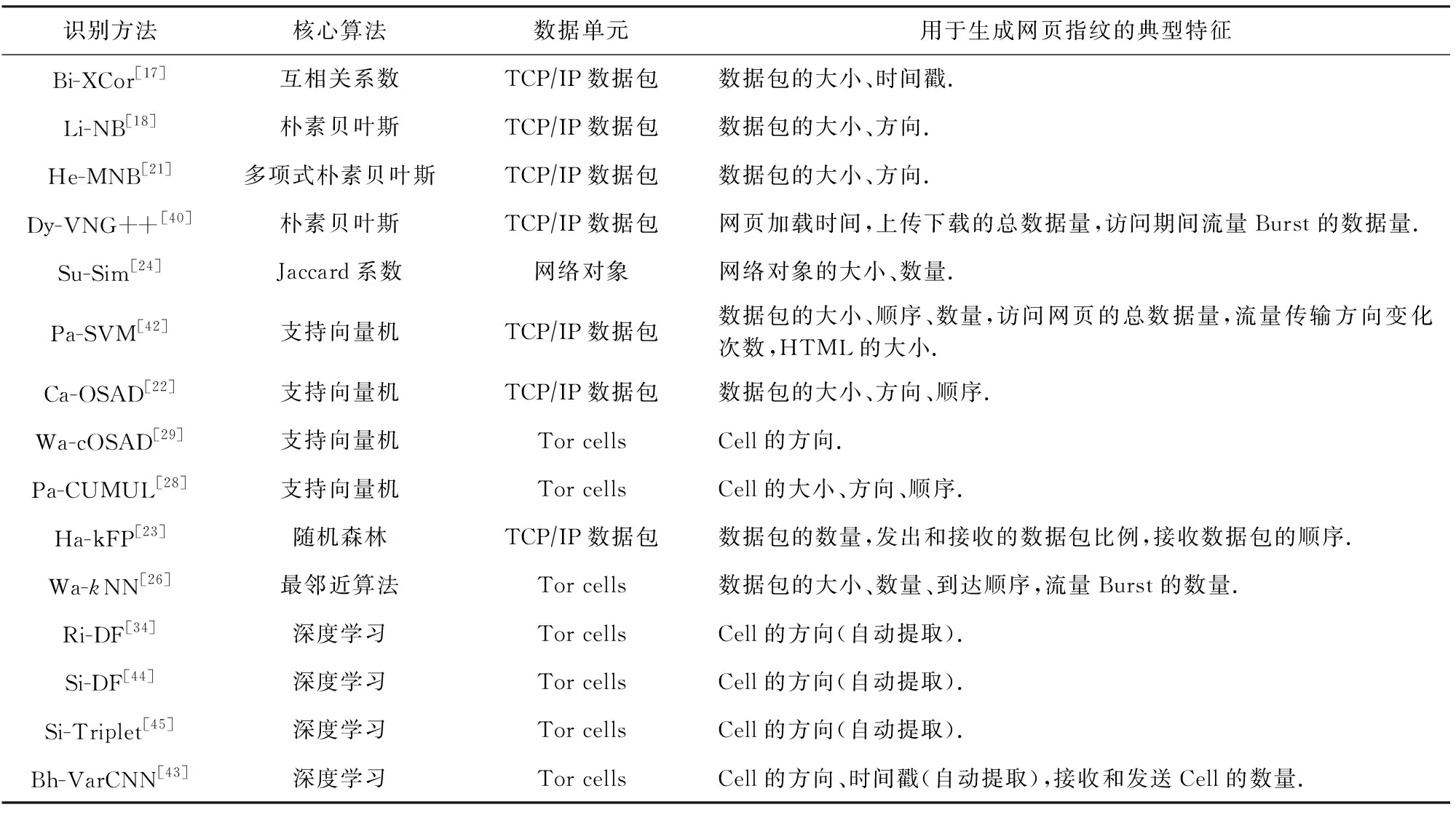
网页指纹识别需要从网络流量中提取特征,例如每个数据包的大小、传输时间、传输方向及到达顺序,以及一次完整的传输中所传输的字节数和数据包总数等.Panchenko等人[28]针对Tor通信,分别在Tor cell,TLS record,TCP packet这3种协议数据单元中提取特征并比较识别性能.实验表明,针对Tor加密流量,从Tor cell中提取特征能达到最好的识别效果,这与文献[29]提出的数据处理优化方法结论吻合.3.4节将对各种识别算法的特征提取和分类算法进行分析总结,然而如何提取流量特征实现准确的网页指纹识别,仍是一个开放问题.
单标签(single-tab)和多标签(multi-tab)浏览模式是以用户行为分类的基本应用场景.在单标签场景中,用户每次访问且仅访问一个页面;在多标签场景中,用户可以一次打开浏览器的多个标签,并同时访问多个页面.但单标签场景常被认为脱离实际[30],大多用户习惯一次性打开多个标签或者打开多个浏览器界面,而且在不关闭前一个页面时访问新页面[31-33].虽然现有的单标签网页指纹识别[34]已获得相当高的准确率,但往往无法直接用于多标签场景[30].因此,近期研究考虑更具实用性和挑战性的多标签情景.
现有解决思路是把多标签场景转换为多个单标签问题[35-38],然而转换过程并非简单的拆分.因为不同于单标签场景下追求高准确率,多标签网页指纹识别方法需要具备较强鲁棒性以抵抗标签间的复杂干扰.在用户使用浏览器时,多个标签页面并非同时打开(即存在时间间隔),找到这个时间间隔并对流量进行分割,就能获得多个单标签访问的流量记录,然后可以对分割好的网页访问流量实施网页指纹识别.解决多标签问题时,多标签判定、流量分割和流量分类的3个步骤是作为一个系统性问题来考虑,每一个前置步骤中的误差都会对后续步骤的准确率产生影响.因此多标签网页指纹的研究极具挑战,已成为相关研究的发展方向,具有重要的意义.
2 网页指纹识别的基础概念
2.1 针对Tor的网页指纹识别工作原理
用户通过Tor网络匿名浏览网页时,攻击者能够监听、标记且分离用户网页访问流量,也可以在多个网络位置进行网页指纹的识别.例如使攻击者和用户接入同一个AP或位于同一段通信链路,也可以由路由器管理者或互联网服务提供商(ISP)进行部署,其工作原理如图2所示.攻击者不会做出丢弃、修改或插入数据包等主动行为,只是被动地监听由用户发出的网络流.由于采用了Tor匿名技术,攻击者无法获取接收者的信息和通信内容,因为这些敏感信息已经被加密并且无法解密获得明文.于是攻击者分析网络流量中那些不受保护且可以轻松捕获的非敏感信息,例如一系列数据包的大小、顺序和数据包之间的时间差等.
网页指纹识别假设攻击者对于用户的访问环境已经具备一定了解.因此在准备阶段,攻击者能尽可能模仿与用户一致的访问环境,例如使用相同的终端设备、操作系统、桌面环境、网络环境和TBB(Tor browser bundle)版本配置.然后,用模仿的终端设备发起对一系列受监视页面的访问,分别记录访问流量,并从流量的非敏感信息中提取特征,训练分类器或指定匹配规则.在识别阶段,攻击者从监听到的用户网络流量中分割出网页访问流量,分析其中非敏感信息所形成的特征,并通过分类或匹配方法判断出用户所访问的网页是否属于受监视页面,以及属于哪一个受监视页面.
在Tor匿名网络中实现网页指纹识别是一项有挑战性的工作.首要任务是要从用户设备不断发出的网络流量中分割出网页访问流量,即流量分类.由于采用固定长度cell封装数据,Tor产生的流量中数据包大小分布与众不同.针对加密流量涌现了大量优秀的流量分类算法[39],网页访问流量的分割也愈加精确,还可以判断用户是否使用了Tor,为网页指纹识别打好了基础.接着从非敏感信息中提取有效特征,制定匹配规则或训练高效的分类器,开展网页指纹识别.本综述将分类介绍利用匹配方法、朴素贝叶斯(naive Bayes, NB)、支持向量机(support vector machine, SVM)、随机森林(random frost, RF)、最邻近算法(k-nearest neighbor,kNN),以及深度学习(deep learning, DL)方法对加密网页进行网页指纹识别的工作.
2.2 威胁场景
网页指纹识别的研究必须考虑2种公认的威胁场景:closed-world和open-world.在不同的场景,用户访问的网站列表具有不同的构成方式.
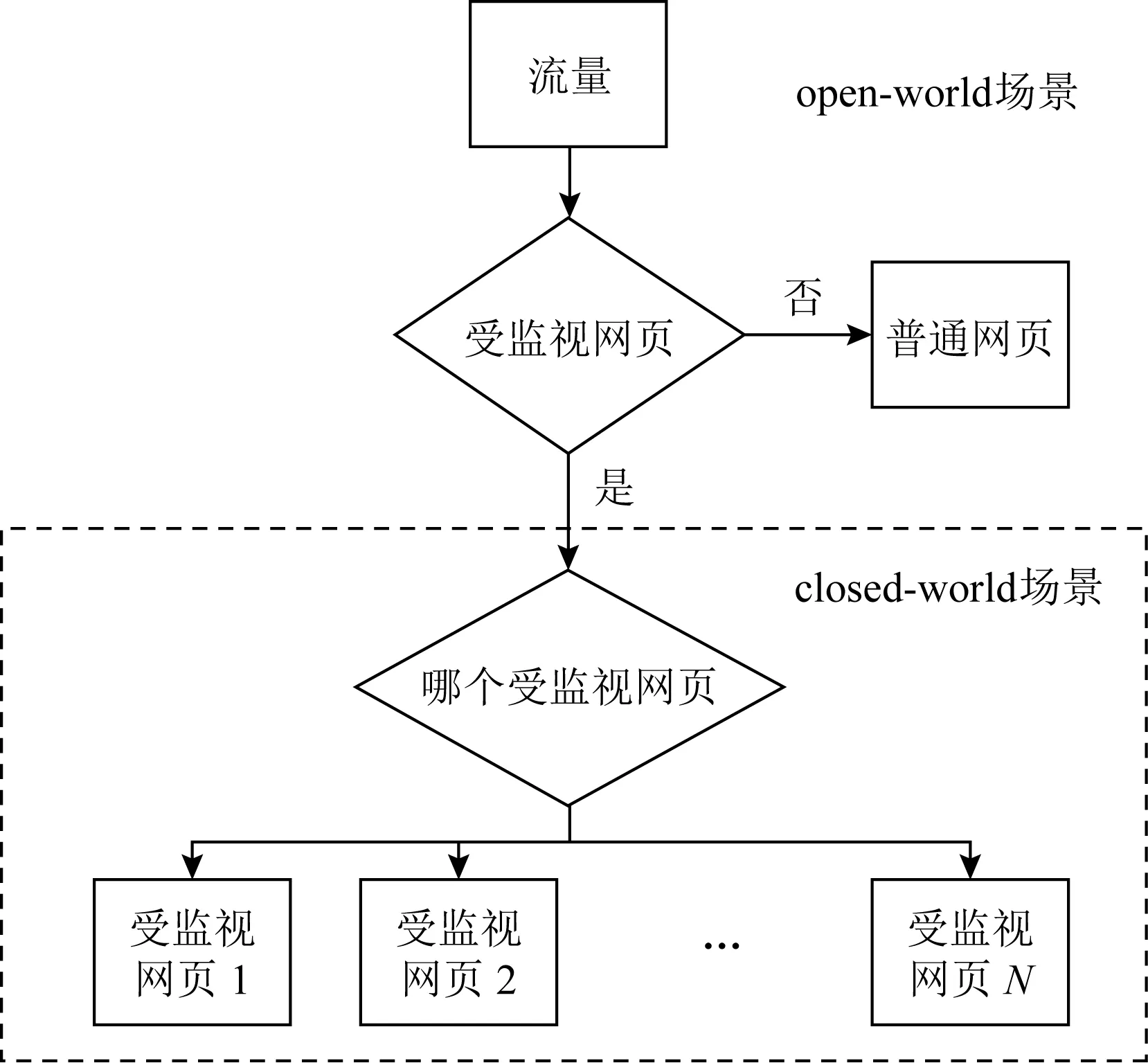
在closed-world场景,用户访问有限的N个受监视网页,而攻击者事先获知这些网站的集合.在准备阶段,攻击者对N个网页分别进行X次访问,搜集、分析并标注这些网页访问流量,用于设计匹配原则和训练分类器,一个受监视网页被视为一个类别.然后,攻击者将捕获的用户网络流量输入分类器,若能成功识别出用户访问的受监视页面(真实所属的类别),即可判定识别成功.此场景下的网页指纹识别,实际是一个经典的多分类问题,随机猜测也有1/N的成功率.但仅考虑closed-world场景的工作[17-18,21-22,40]往往被认为脱离实际[30,41],因为一般用户访问的页面数量大也难以预测,无法提前简化为固定集合.
在open-world场景[23-29,42-45],攻击者首先选取N个受监视页面,并对每个网页分别进行X次访问;同时选取M个普通网页,并对每个网页进行1次访问(通常N 由于网页指纹识别可以视作一个分类问题,因此机器学习的通用性能指标也适用,例如准确率(accuracy, Acc)、召回率(recall)、真阳率(true positive rate, TPR)、假阳率(false positive rate, FPR)和混淆矩阵(confusion matrix).针对closed-world和open-world威胁场景,还定义了更细致的评估方案.在closed-world,攻击者假设用户仅会访问N个受监视页面,属于多分类问题.因此使用Acc,TPR/FPR和混淆矩阵均能有效描述识别性能.而在open-world中,网页指纹识别分为2个阶段.第1阶段被视作2分类问题,即判断一段网页访问流量是否属于普通页面类别.如果是,则判断结束;否则进入第2阶段,对N个受监视页面进行多分类处理(相当于closed-world问题),如图3所示: Fig. 3 The workflow of open-world problem图3 open-world场景识别的流程图 因此,open-world可以选择2种评价体系:Two-*[17-21,37,42,44-45]和Multi-*[28,43],*代表着某种具体评价指标,例如准确率.在Two-*指标中,如果一个受监视页面被正确分类为受监视页面,则认为是TP(true positives),被错误分类为普通页面则认为是FN(false negatives).如果一个普通页面被正确分类为普通页面,则认为是TN(true negatives),否则被认为是FP(false positives).Multi-*指标则严格评估网页访问流量是否准确地被分成N+1个类别.当且仅当一组访问流量被正确地判断为其真实所属的受监视页面类别时,才会被认为是分类准确,识别成功.其后出现的实验数据,默认采用Two-*指标;若以Multi-*指标做参考,将特别注明. 有些学者还指出open-world的网页指纹识别不能简单地视为二分类问题,而是一个介于二分类和多分类之间的问题,需要定义新的性能指标.例如,Wang[46]在Two-*的基础上引入了WP(wrong positive)概念,代表一段网络流量被分类器成功判断为受监视页面,但是并不能正确找到其真实属于哪个受监视页面的情况,相关混淆矩阵定义如表1所示.同时提出应提高网页指纹识别的精确度来避免基率谬误(base-rate fallacy).基率谬误是指当受监视页面数量远少于普通页面时,即使分类器具有很好的性能表现,也有很大概率得到错误结论.假设受监视页面数为全部页面数的1/1 000,分类器拥有99%的TPR,1%的FPR,1%的FNR和99%的TNR.若一段网络流量被该分类器识别为受监视网页,那么根据贝叶斯定理,该判断的正确概率仅为9%.因此本综述在评价识别效果时(见第3节和第4节),必须考虑数据集的组成. Table 1 The Confusion Matrix Using WP[46]表1 引入WP的混淆矩阵 面向单标签的网页指纹识别,认为用户使用浏览器每次仅会访问一个页面,即只打开单个标签页.这类识别方法很多,本节根据所选取的匹配或分类算法进行分类介绍.由于没有公认的公开数据集,每个算法研究工作使用的数据集组成都有区别,然而无论是页面数量、流量样本数量,还是采集降噪方式都会对识别结果产生较大影响.为了保证算法分析的客观性,讨论识别效果时会说明所用数据集的参数,例如受监视页面数量N和普通页面数量M、对每个页面采集流量样本的次数X等.例如在识别准备过程,搜集N=5个真实受监视网页的访问流量,每个网页采集X=35次;收集M=4 000个普通网页的访问流量,每个网页采集1次,则数据集的规模(scale)记为5×35+4 000×1,即N×X+M×1. Su-Sim[24]是一种针对SSL/TLS加密网页的基于统计的识别方法.它从浏览器与代理的连接中分离出网络对象(Web objects),并使用网络对象的大小和数量计算Jaccard系数[47],以此衡量2段网络流量的相关性.通过相关性匹配,能在open-world场景(2 191个受监视页面和98 496个普通页面),获得75%的TPR.其局限性在于,当使用WEP(wired equivalent privacy)/WPA(Wi-Fi protected access)、SSH、通道(tunnel)和VPN(virtual private network)等方式访问网页时,网络对象无法从网络流量中分离出来. Bi-XCor[17]则根据访问流量之间的互相关系数(cross correlation)进行匹配,对每个受监视页面进行一次流量采集即可完成识别准备.在N=100的closed-world中,对经过加密或通过代理的流量,仅得到23%的准确率.由于没有考虑匿名通信网络填充数据包的情况,它将数据包大小作为特征之一,而Tor浏览器已经将cell的大小固定为512 B.可见,基于统计的方法大多无法适用于匿名网络. 3.2.1 基于朴素贝叶斯 不同于Bi-XCor[17],Liberatore等人[18]不再使用基于时间信息的特征,而是使用数据包的大小和方向设计了基于Jaccard系数和朴素贝叶斯分类器的网页指纹识别方法.在包括1 000个受监视页面的closed-world中,一次识别可获得73%的准确率;若允许多次识别,其准确率能提升到90%.同时提出识别准确率与受监视网站总数对数值(lbN)呈线性关系,并讨论了4种匿名化的流量填充对识别性能的影响.例如,将数据包全部填充至最大传输单元(maximum transmission unit, MTU)时,数据包大小的特征完全消失,识别准确率骤降至7.7%,而且开销极大. He-MNB[21]改进了Liberatore等人[18]的工作.虽然同样使用数据包的大小和方向信息作为特征,但它采用多项式朴素贝叶斯算法(multinomial naive Bayes, MNB)做分类.与朴素贝叶斯算法不同,MNB不直接计算一个特征向量归属每个类别的概率,而是使用在所有训练集上的聚合特征.在775个受监视页面的closed-world中,He-MNB针对Stunnel,OpenSSH,CiscoVPN,OpenVPN的网页访问,均达到了95%以上的识别准确率;但对匿名网络Tor和AN.ON 不适用,准确率仅为2.96%和19.97%. 3.2.2 基于支持向量机 Pa-SVM[42]在He-MNB[21]的基础上增加了衡量流量突发性的多个特征(如流量方向反转次数、HTML文档大小、总传送字节数、流量方向反转期间的数据包数量、不同大小数据包出现的次数、流入的数据包比例、数据包总数和TLS/SSL记录的大小等),并使用SVM做分类器.在775×20的closed-world中,Pa-SVM对匿名网络的性能大大提高,针对Tor和AN.ON流量,识别准确率分别提升到55%和80%.在3个模拟审查类别中(sexually explicit, Alexa top, ranked Alexa random),它最高取得了73%的TPR和0.05%的FPR,也是在open-world中第一个成功实施网页指纹识别的方法. 基于Pa-SVM[42]的手工构造的特征,Ca-OSAD[22]利用Damerau-Levenshtein距离[48]构建内核,建立了SVM分类器,进一步提升了针对Tor加密流量的识别效果.在100×40的closed-world下,针对Tor流量的识别准确率达到了87.3%.Wang等人[29]从数据搜集、数据处理和网页指纹分离3个方面对Ca-OSAD[22]进行改进.首先提取Tor cells而不是TCP/IP packets的特征信息,然后同时使用Damerau-Levenshtein和Optimal-String-Alignment这2种距离表征流量之间的差异.在100×40的closed-world中,针对Tor流量的识别可以达到91%的准确率;在4×40+860×1的open-world中,可获得96.9%的TPR,而相同数据集下Ca-OSAD的TPR为86.9%. Pa-CUMUL[28]更细致地分析Tor网页访问流量,通过统计Tor cells的长度和数量提取了104个有效特征,并使用RBF(radial basis function)内核构建了SVM分类器.针对Tor流量,Pa-CUMUL在100×90的closed-world中,最高取得了92.22%的准确率.在100×90+9 000×1的open-world中,达到了96.92%的TPR及1.98%的FPR. 3.2.3 基于随机森林 Hayes等人分析比较已有的特征选取方案,提出Ha-kFP[23]识别方法.它使用随机森林算法从流量记录的特征中生成具有强鲁棒性的叶子向量,最有效的特征包括:收到的TCP/IP数据包总数、收到和发出的数据包比例、数据包顺序统计等.这些向量被视为经过编码的网页指纹信息,然后使用kNN分类器计算网页指纹信息之间的距离并据此分类.针对Tor流量,在100×90的closed-world中,Ha-kFP可获得了91%的识别准确率;在30×80+16 000×1的open-world中,最高可取得了81%的TPR和0.02%的FPR. 3.2.4 基于最邻近算法 Wa-kNN[26]使用最邻近算法作为分类器,提取了大量的特征,例如数据包的顺序、收到和发出的数据包数量及流量突发的次数等,其特征总数量接近4 000.其中3 000多个特征是某个页面访问过程中传输的独特数据包大小,最终通过计算权重的方法进行了精简,因此未导致过长的处理时延.它判断一段流量样本所需的时间仅为Ca-OSAD[22]的1/4 500.在提取特征时,若抛弃独特数据包大小的特征,耗时还能缩短至1/4.Wa-kNN[26]在100×90的closed-world中,达到了91%的准确率,在100×90+5 000×1的open-world下,取得了85%的TPR和0.6%的FPR. Ri-DF[34]使用深度学习领域中的3个经典模型:堆叠降噪自动编码器(stacked denoising autoencoder, SDAE)、卷积神经网络(convolutional neural network, CNN)及长短期记忆网络(long short term memory, LSTM)完成了对网页指纹识别的测试,其使用特征提取网络自动地提取特征,而不再通过特征工程手动构建特征.其模型输入是表示Tor cells方向的序列.在100×2 500的closed-world中,由CNN构建的模型达到了最高的识别准确率96.26%.在200×2 000+400 000×1的open-world中,CNN仍取得了最好的效果:80.11%的TPR和10.53%的FPR. Si-DF[44]使用CNN进行特征提取并使用全连接层作为分类网络构建了分类器.与Ri-DF[34]相同,Si-DF仅使用Tor cells的方向作为特征.在95×800的closed-world中,Si-DF达到98.3%的识别准确率;在95×900+20 000×1的open-world中,通过调整置信度可获得最高精确度96%(TPR为68%),或最高TPR为96%(准确率为67%).这也验证了CNN模型的性能优势.Abe等人[49]也使用SDAE设计网页指纹识别方法,并在Wa-kNN[26]相同的数据集上测试.然而由于数据量不足,识别准确率为88%,弱于Wa-kNN.由此可见,利用深度学习进行网页指纹识别,需要依赖大量样本数据. 深度学习可以提高网页指纹识别效果,但巨大的数据量也增加了识别成本.例如Ri-DF和Si-DF识别的准备就需要花费数天来收集和训练数据[45].为此,Si-Triplet[45]使用(n-shot learning, NSL)来减少网页指纹识别对大数据样本的依赖性.Si-Triplet首先使用CNN构建特征提取网络提取特征,对流量样本记录编码,再使用kNN算法计算编码之间的距离,并据此分类结果完成网页指纹识别.在closed-world中,Si-Triplet使用100×25的数据集来训练特征提取网络,并对100个受监视页面进行CNN特征提取和kNN分类测试,可达到79.4%的识别准确率.而在同样条件下,基于传统机器学习的Pa-CUMUL[28]和Ha-kFP[23]识别准确率分别为42.1%和36.3%.在100×5+9 000×1的open-world中,使用同样的数据集进行特征提取网络的训练,再使用不同的数据集进行测试,Si-Triplet最大精确度为87.1%(TPR为80.8%). Bh-VarCNN[43]引入空洞卷积及残差网络构建了神经网络分类器.与Ri-DF[34],Si-DF[44],Si-Triplet[45]不同,Bh-VarCNN不仅通过特征提取网络从Tor cells的时间和方向序列中自动提取特征,还使用一些手工构建的特征(例如,数据包总数、接收和发出的数据包总数、结束和发出的数据包比例、总传输时间、数据包的平均传输时间).同时证明在较少样本量的情况下,Bh-VarCNN仍然能保持较高的准确率.例如,在100×100的closed-world中,Bh-VarCNN可以达到97.8%的识别准确率,而Si-DF[44]的准确率为93.6%.当样本充足时,在900×2 500的closed-world中,Bh-VarCNN达到了98.8%的识别准确率,而Si-DF为96.5%.在100×100+90 000×1的open-world中,Bh-VarCNN达到89.2%的Multi-TPR和1.1%的FPR.实验还指出,受监视页面和普通页面比例悬殊会导致大量误报,这与Wang[46]对基率谬误的讨论一致. Tik-Tok[50]还手动构建了8个基于Burst的时间特征,通过增强网页指纹识别方法对时间信息的利用能力,提升了现有网页指纹识别算法的可解释性以及抵抗干扰的能力.Burst是指流量中的小段同方向序列,如图4所示,每一段同方向的数据包被视为是一个Burst.受此启发,Ma等人[51]提出了Ma-Burst-DF,通过设计多尺度的Burst特征提取网络改进了Si-DF[44]的网络结构,并且创造性地提出了要将神经网络的输出作为指纹向量,接着使用随机森林算法对指纹向量进行分析最终输出分类结果,其模型性能和抵抗干扰的能力较Si-DF[44]有所提升.这种基于Burst的特征提取结构在Dy-VNG++[40]和Wa-kNN[26]中也有应用. Fig. 4 Structure of Burst图4 Burst结构 早期的网页指纹识别利用数据包的大小、时间等信息手动构建特征,并计算流量之间的相关度做匹配依据,例如Bi-XCor[17]和Su-Sim[24].接着,机器学习的经典算法被引入,在手动构造流量特征的情况下提升网页指纹识别的效果.首先被引入的是朴素贝叶斯,例如Li-NB[18],He-MNB[21],Dy-VNG++[40].由于在解决小样本的非线性问题中的独特优势,SVM算法也被广泛用于网页指纹识别.例如Pa-SVM[42],Ca-OSAD[22],Wa-cOSAD[29],Pa-CUMUL[28]通过自定义内核,有效提升了流量分类的能力.基于kNN算法的Wa-kNN[26]识别也达到了不错的效果.机器学习算法还可以用来提取特征,例如Ha-kFP[23]识别使用随机森林作为特征提取的工具,把最后一层叶子节点的输出作为流量的指纹编码,然后计算指纹编码之间的距离进行分类.进入深度学习时代后,网页指纹识别也逐渐地脱离了对手动构建特征的依赖,转而使用特征提取网络.例如,Ri-DF[34],Si-DF[44],Si-Triplet[45]均是由特征提取网络从[1,-1]的方向序列中自动生成的特征,并取得很好的识别效果;而Bh-VarCNN[43]则表明结合手动构建特征可以进一步提高识别性能. 根据表2的统计,数据包的时间和方向序列是2个最重要特征;数据包的数量、发出和收到数据包的比例、总传送时间、特定文件的大小和特殊数据包的大小等特征也常被网页指纹识别方法所选用.并且Li等人[52]分析了网页指纹的信息泄露(informa-tion leakage)情况,计算了网页指纹识别方法中常用特征所泄露的信息量,为手动构建特征的可解释性提供了理论支持.在基于深度学习的识别方法中,总字节数、流量反转次数等手动构建的特征往往能够在特征自动提取的基础上增强识别效果.但匿名网络中的识别一般不选取数据包大小,因为Tor的强制填充规则使其失去了特征表征能力.相比于TCP/IP层的数据包信息,从Tor cells层解析数据包的信息特征,能使分类器达到更好的效果[28].大量针对Tor流量的识别方法如Wa-cOSAD[29],Wa-kNN[26],Ri-DF[34],Si-DF[44],Si-Triplet[45],Bh-VarCNN[43],都选择Tor cells作为特征提取的对象. Table 2 The TypicalFeatures Used in WF Identification表2 网页指纹识别所使用的典型特征 表3对比了典型网页指纹识别方法的识别效果(为便于横向比较,仅列出实施一次识别的准确率).如果一项算法研究讨论了针对多种加密方式(如SSH,VPN,Tor)的网页指纹识别,主要比较针对Tor流量的识别准确率.在open-world下,默认使用Two-*指标;否则指定Multi-*指标(相关定义见2.3节).本节还描述了每种方法评估所依托的数据集N×X+M×1,并按照受监视页面数量N、普通页面数量M和训练样本采集数目X来讨论网页指纹识别的效果. Table 3 Performance of Single-tag WF Identification表3 单标签网页指纹识别的比较 在N×X的closed-world中,考虑的受监视页面越多则分类难度越大,对每个页面采集的训练样本越多则完成识别的开销越大.非深度学习算法的识别方法,对训练样本要求不高,X通常设为20和40.而基于深度学习的识别方法虽然能获得很高的识别准确率,但所需训练样本数目巨大.例如在95×800的closed-world中,Si-DF可以获得98.3%的准确率;在900×2 500的closed-world中,Bh-VarCNN的准确率高达98.8%,但它们的识别准备都非常耗时. 在N×X+M×1的open-world中,对网页指纹识别的评估往往受到普通页面与受监视页面比例的影响.普通页面越多,准确识别受监视页面的难度也就越大.表3中,Ri-DF的比例最高M/N=2 000/1,可获得80.11%的TPR.比例次高的是Bh-VarCNN(M/N=900/1),在严格的多分类指标下,准确率达到了89.2%的Multi-TPR.若结合closed-world中的表现,Bh-VarCNN方法的识别效果最佳. 基于深度学习的网页指纹识别方法需要依赖大量训练数据的支撑.在现实场景中,如果采集一个受监视页面流量需要花费20 s(考虑Tor缓慢的响应速度,实际上还会更多),一台设备24 h仅采集4 320个样本.若受监视页面增加,收集和训练数据的识别准备过程将更长.而网页指纹识别的效果往往会随着搜集数据和发起识别的时间间隔加大而衰减.因此少样本学习(few shot learning, FSL)的表现和实践性更值得关注.例如,Si-Triplet在M/N=90/1的open-world中取得89.3%的TPR,仅使用少量训练数据获得较好识别效果. 单标签页的网页指纹识别能达到很高的准确率,即使在open-world中的用户访问上万个网页,并且采用SSH及SSL等流量加密方法,攻击者也能通过训练网页指纹的识别算法准确地判断是否访问了某个受监视的页面.尽管用户使用Tor服务消除了数据包大小等信息以抵抗流量分析,但是随着相关研究的不断推进,针对Tor的网页指纹识别方法的效果也越来越好,多数防御手段被逐一打破.因此,基于网页指纹识别的攻击行为对用户隐私产生巨大威胁.早期的研究虽被诟病于脱离实际,但是随着识别算法从统计方法、传统机器学习,发展到最新的深度学习方法,针对Tor网页指纹识别在接近真实识别场景的实验环境中取得越来越好的效果. 多标签的网页指纹识别,认为用户在进行网页浏览时,会打开多个标签页同步访问多个网页.因为多个网页访问流量的相互叠加,面向单标签的网页指纹识别方法经常失效.解决这个问题的关键是准确判断一段网络流量是否包含多个页面的信息,如何准确分割各个网页流量,并设计分类算法对分割后的流量进行准确分类.本节将介绍多标签网页指纹识别的难点挑战与相关工作,然后比较这些研究的识别效果. 在多标签场景下,攻击者可以通过多标签流量判定以及流量分割2个步骤将问题转换为单标签网页指纹识别.如图5所示,如果一段流量记录被判定仅含有一个页面,则直接使用单标签识别方法进行特征提取和网页分类识别;如果判定含有多个页面,则进行流量分割后再分别转换为单标签识别问题.目前的多标签识别的研究[35-38]常采用这种思路. Fig. 5 The workflow of multi-tag WF attack图5 多标签页场景的识别流程 但是多标签场景并不是单标签网页指纹识别的一种简单扩展.首先单标签网页指纹识别方法无法直接运用于多标签场景的流量分类任务.Juarez等人[30]测试了5种单标签网页指纹识别方法在多标签场景下的表现:He-MNB[21]、Wa-cOSAD[29]、Dy-VNG++[40]、Pa-SVM[42]、决策树算法.实验表明这些方法在多标签场景的网页识别准确率不足20%,即识别无效.多标签下的网页指纹识别方法必须强调鲁棒性,有效抵抗多标签浏览行为带来的诸多干扰,例如多个页面访问的流量互相重叠、多标签判定算法的误差以及流量分割算法的误差.只有把多标签判定、流量分割及流量分类3个步骤进行整体化设计才能达到好的网页指纹识别效果. 基于数据包时间差的最邻近算法Wa-TkNN[35],可以准确判断一段Tor流量是否属于多标签浏览,准确率高达97%.它使用的特征包括cell间的最小和最大时间差,以及时间差的均值和方差等.如果一段流量被判定为多标签浏览,则使用kNN分类器来寻找不同标签页之间的流量分割点,所使用的特征包括分割点周围5个cell之间的时间差,以及分割点周围50个cell的时间差中的最大值、最小值和方差等.实验证明在3种多标签浏览情况下,网页流量的分割准确率分别为88%,63%,32%.这3种典型情况是:在第1个页面完全加载后有一段间隔再访问第2个页面(class1);在第1个页面完全加载后立刻访问第2个页面(class2);在第1个页面未完全加载完时就访问第2个页面(class3).可惜的是,Wa-TkNN[35]工作仅提出了判定和分割多标签流量的方法,并没有进一步设计基于此的网页指纹识别. Xu等人选取与Wa-TkNN[35]相同的流量特征,融合BalanceCascade[53]和XGBoost[54]分类器构建了一个二分类的分类器Xu-Boost[37].它通过独立地计算用户每一个发出的数据包是真实分割点的概率来寻找分割点,并且构建了随机森林分类器对分割后的流量进行分类.随机森林分类器使用数据流量总大小、cells数量等手动构建的特征,对第1个页面的分类达到了86.56%的Multi-TPR,及0.52%的FPR.可惜的是,Xu-Boost抛弃了分割点后的所有流量,仅对第1个页面进行分类. Gu-NB[38]假设第2个页面在固定时间差后打开(例如2s),因此省略网页间的流量分割过程,直接讨论如何分类2段相互干扰的流量.通过提取一段流量的TCP连接数量、流出/流入总带宽和数据包间时间差等特征,利用随机森林算法对2个页面进行了分类.第1个页面的分类识别达到了75.9%的准确率和22%的FPR;第2个页面则是40.5%的准确率及17.4%的FPR.然而Gu-NB[38]假设过于理想化,不能解决多标签网页指纹识别的实际问题;并且实验仅针对SSH流量,未证明其在Tor匿名网络中的作用. Cui等人[36]指出多标签场景下的网页指纹识别主要面对2种干扰:流量的缺失(missing)和重叠(overlapping).当用户进行多标签浏览时,攻击者将整段流量记录进行分割后,第1个页面容易缺失尾部的信息,而第2个页面的头部会受到第1个页面的尾部信息干扰.基于Wa-TkNN[35]判断多标签浏览的流量的能力,他们提出了相当完整的多标签网页指纹识别方法Cu-HMM[36].它首先使用隐马尔可夫模型对流量进行分割,再使用Sectioning算法对2段流量进行分类.Sectioning算法将每个页面的流量拆分为一些固定长度的小段,分别对每一小段进行分类,统计小段的分类结果即得到了整段流量的分类结果,其中使用的特征来源于Pa-CUMUL[28].closed-world实验表明,Cu-HMM识别对第1个页面和第2个页面分别达到了70.2%和69.2%的Top3准确率(分类器输出的概率最大3个类别中若包括正确类别,则认为分类正确).可惜它没有测试open-world的场景下网页指纹识别的效果,所以仍然存在一定改进的空间. 表4与表5对比了多标签网页指纹识别方法的分割与识别效果,时间间隔指的是开始访问2个网页之间的时间差,Esplit表示流量分割误差,Acc和TPR表示流量分割效果,规模记录了数据集组成方式.由于不同研究中采用的性能评价指标不同,并没有提供所使用的数据集以及实现代码.难以使用统一的单位来对比其性能和表现,因此表4与表5中仅采用文献中提供的评价指标与数值以供参考.另外由于由Gu-NB[38]假设固定的时间差,并跳过了流量分割过程,所以在表4中Gu-NB[38]分割指标的3项为空.而Wa-TkNN[35]仅考虑了多标签页场景下的流量分割问题,因此在表5中,Wa-TkNN[35]分类指标皆为空. Table 4 Performance of Multi-tab WF Split表4 多标签网页指纹分割的比较 % Table 5 Performance of Multi-tab WF Identification表5 多标签网页指纹识别的比较 显然,流量分割算法是多标签网页指纹识别成功的关键,精准的流量分割才能保证后续的分类算法的准确性.为了达到最好的识别效果,研究者需要提前分析流量分割算法的性能.然而不同分割算法猜测网页流量分割点的方法也不同,主要有2种:第1种,尽量让猜测的流量分割点与真实的距离不超过规定的数据包数目Y,例如Xu-Boost[37]和Wa-TkNN[35];第2种是把长为Ls的流量纪录为许多长度为Lsub的小段,如果猜测的流量分割点与真实的位于同一Lsub,则认为分割正确,例如Cu-HMM[36]. 为了方便描述和对比,需要定义一个指标用于衡量分割误差Esplit,即使一个分割点被判定为正确,仍然可能存在的误差.2种情况的误差计算公式分别为式(1)和式(2). Esplit=(Y/Ls)×100%, (1) Esplit=(Lsub/Ls)×100%. (2) Xu-Boost[37]和Cu-HMM[36]均达到80%以上的流量分割准确率,是目前效果最好的分割算法.而Wa-TkNN[35]由于过度依赖流量中的时间特征,虽然对2个网页流量间有间隔的情况可以达到较高的分割准确率,但是对2个网页流量有部分重叠的情况不能做出很好的分割,因此最终的分割性能不佳. 多标签网页指纹识别的第2个关键技术是流量分类算法.由于分割后的流量往往会存在缺失和重叠2种干扰[36],多标签网页指纹识别场景下的分类算法往往要具备更强的抗干扰能力. 在N×X+M×1的open-world中,Gu-NB[38]选取SSH而不是Tor流量,并省略流量分割的过程,因此2个页面75.9%和40.5%的分类准确率也难以证明其可用于真实的多标签情景.在受监视页面数量N=50时,Xu-Boost[37]的普通页面数量M是Gu-NB[38]的5倍.面对更困难的分类任务,Xu-Boost[37]把第1个页面的分类准确率提高到86.56%的Multi-TPR.但由于忽略了第2个页面的流量,并采用不同的数据集分别验证流量分割和分类性能,Xu-Boost的实验结果无法全面反映其真实性能. 在N×X的closed-world中,仅有Cu-HMM[36],得益于准确率80%的分割算法,并提出Sectioning算法有效抵抗了第2个页面流量头部所受到的干扰.Cu-HMM[36]对第2个页面的分类准确率达到了69.2%的Top3准确率,也是对第2个页面的分类准确率最高的识别算法. 多标签场景是网页指纹识别相关研究的未来发展方向,因为它更加贴近实际应用场景,对用户隐私的威胁也更大.攻击者可以用高准确率的分割算法削弱多标签浏览的影响,完成多标签场景的判定,并且进行流量分割,最后使用流量分类的方法识别网页,完成网页指纹识别.综合来看,Cu-HMM[36]的设计和实验最为合理,使用Wa-TkNN准确判定多标签网页流量,然后流量分割和流量分类的完整过程.其中除了Gu-NB[38]是针对SSH加密流量进行的分析外,Xu-Boost[37],Cu-HMM[36],Wa-TkNN[35]均针对的是Tor加密的流量.在多标签场景中,即使用户在短时间内打开多个页面,Tor也可能在此期间重新建立Circuit进行通信,而Circuit的切换会导致数据包数量及时间戳等信息发生变化,这些潜在的干扰都极大地增加了网页指纹识别的难度.对流量分割和分类算法的性能及抵抗干扰的能力的要求也就更加严格. 网页指纹识别的场景和假设越来越接近实际情况,从closed-world到open-world的进步显而易见.本节从实践角度出发,讨论威胁场景、条件假设、Tor版本、背景流量、采集数据和发起识别的时间差等因素对网页指纹识别效果的影响,如表6所示.在设计识别方法时,必须重视这些因素的影响. Table 6 The Influencing Factors Considered in Typical WF Identification表6 典型WF识别方法考虑的影响因素列表 绝大部分识别方法假设已知Tor浏览器版本及操作系统等用户信息,因此攻击者可以模仿用户的网络环境来进行数据的收集并做好识别准备工作.然而当用户的真实网络环境与攻击者模拟环境不完全相同时,网页指纹识别效果会大打折扣[28].目前仅有Si-Triplet[45]考虑了Tor版本的影响. 网页指纹识别应当充分考虑背景流量对识别效果的影响以提高其可实践性.大部分识别方法假设攻击者在捕获用户的网络流量后,能够完整且无重叠地切分出网页浏览的流量.例如,Wa-kNN[26]把Tor浏览器的自带流量(circuit建立和控制流量的SEND ME数据包等)都视为噪音进行过滤,以提高识别准确率.但这在现实网络环境中无法真正实现.正常的联网设备往往会持续不断地产生网络流量,即使攻击者仅采集用户的TLS流量也会被其他应用或者程序所产生的TLS流量干扰.只有Pa-SVM[42],Pa-CUMUL[28],Wa-Boost[37],Cu-HMM[36],Gu-NB[38],Wa-TkNN[35]方法通过手动添加噪声的方式测试了自身算法抵抗背景流量噪声干扰的能力.文献[55]提出可以通过在训练分类器期间加入目标页面内超链接的统计来提升训练器抵抗噪声的能力. 由于大部分网页是非静态的,网页指纹识别的效果往往会随着搜集数据和发起识别的时间间隔增加而衰减.网页指纹识别的数据搜集和分类器训练需要花费大量的准备时间[45].当用户进行网页访问时,当前网站很可能已经发生变化,例如视频网站首页往往会根据热度变化来排列节目的链接,页面之间插入的广告也在更新.因此,从识别准备到真正发起识别的时间越短越好,网页指纹识别的准确率会随着时间间隔增大而下降[18,24,34,44].网页指纹识别的时效性也是一个现实的挑战. 本综述从网页指纹识别的概念、原理和威胁场景出发,分类讨论面向单标签和多标签的典型识别方法.特别研究他们针对Tor等匿名网络的识别效果,并从不同角度讨论其性能优点、局限性及可实践性.5个问题值得进一步研究和讨论. 1) 设计更具实践性的网页指纹识别.现有的网页指纹识别方法研究普遍采用了较多的实验假设,例如closed-world、单标签浏览、无背景噪声及训练数据采集源与用户设备操作环境完全一致等,每一个假设因素都会对网页指纹识别效果产生较大影响.这些假设使现有识别方法缺乏实践性,虽然有研究者提出了一些针对多标签场景的网页指纹识别方法[35,38],也有研究者针对网页指纹的可实践性进行了讨论[30,35],但是网页指纹识别距离真正实用仍有不小差距.Tor project早于2013年已经将网页指纹识别视为某种潜在威胁[41],然而至今未推送任何主动防御措施.可见,设计更具实践性的网页指纹识别,比挫败某种主动防御更紧迫. 2) 针对Tor协议的特性设计网页指纹识别方法.网页指纹相关研究的热点虽然已面向Tor加密的网页访问,但研究者往往是通过提升分类器的性能及鲁棒性的方法来攻克Tor对流量分析技术的干扰.这类方法一般具有通用性,可以同时应对多种加密和防御手段.但对于使用最广泛的匿名访问网络Tor,研究者应该针对Tor协议本身的特性(例如未施加干扰的数据包间时间差、路由选择策略等)来开发更高效率的网页指纹识别方法,预期能达到更好的效果[50]. 3) 使用数据增强改进网页指纹识别.数据增强方法被广泛应用于图像处理领域,通过对图像进行遮挡、旋转、融合和尺度变换来扩展数据集,模糊分类器的决策边界.这些经过简单变换的样本与真实样本很接近,有利于提升分类模型的表现.网页指纹识别的研究,也可以通过数据增强的方法增加训练数据,提升模型的准确率.这种改进方案,不但降低了网页指纹识别对于大量真实数据的依赖,也大大减少了搜集数据训练分类器的准备时间. 4) 研究针对网页指纹识别的防御.随着网页指纹识别方法的发展,涌现了对应的防御措施[56-65].最基本的是通过填充垃圾包和主动延迟某些数据包(或组合),对网页访问流量进行保护,提高网页指纹识别的假阳率或降低其准确率.但这2种措施都会影响网页访问体验,过量添加垃圾包会对用户带宽带来额外负担,过长的数据包延迟会加大用户访问的时延开销.由于网页指纹识别的现有防御措施开销都比较大,难以实际部署到Tor等匿名网络中.平衡防御效果与开销成为一大难题,而在图像领域兴起的对抗网络技术为此打开了新思路,已有研究使用对抗样本解决网页指纹识别的威胁并且取得了不错的效果[63,65].防御者通过制造对抗样本产生足够针对网页指纹识别算法的网络干扰,同时保证这些干扰不会影响网络的正常通信. 5)增强网页指纹识别的网络监管能力.匿名网络能够提供用户匿名访问互联网的能力,有效地保护用户隐私.但若被不法分子滥用来进行非法活动,则增加了监管部门对网络犯罪的审查难度.网页指纹识别的研究能够被应用于合法的网络监管之中,防范不法分子对匿名网络的滥用.研究网页指纹识别方法的最终目的并不是破坏隐私保护体系,而是通过寻找可能的网页指纹识别方法来测试现有隐私保护体系的性能和潜在威胁,并且在法律准许的范围内进行有效的网络监管.通过不断对网页指纹识别方法的推进与研究,才能提出更好的隐私保护方案,增强对合法用户的隐私保护能力,增强对非法用户的网络监管能力.2.3 性能评估

3 面向单标签的网页指纹识别
3.1 基于统计的方法
3.2 基于传统机器学习的方法
3.3 基于深度学习的方法

3.4 算法和特征的选择
3.5 识别效果比较

3.6 本节小结
4 面向多标签的网页指纹识别
4.1 多标签网页指纹识别的特点
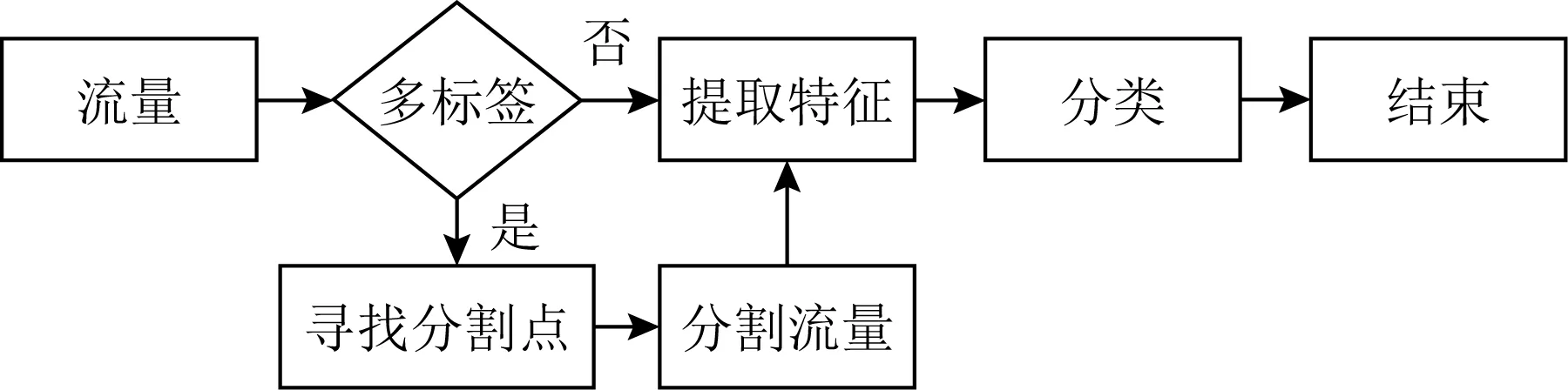
4.2 多标签网页指纹识别的相关方法
4.3 识别效果比较


4.4 本节小结
5 网页指纹识别的局限性

6 研究总结与展望
