基于代码属性图和Bi-GRU的软件脆弱性检测方法
2021-08-17肖添明管剑波蹇松雷张建锋
肖添明 管剑波 蹇松雷 任 怡 张建锋 李 宝
(国防科技大学计算机学院 长沙 410073)
软件脆弱性是指软件在开发、部署、执行整个过程中存在的缺陷,不法分子可利用这些缺陷绕过系统的访问控制、非法窃取较高的权限等,这可能造成用户隐私数据泄露、数字资产被盗、系统信息被更改等安全问题,从而导致企业和个人巨大的经济损失和名誉损失.随着现在软件系统的复杂度越来越高,规模越来越大,脆弱性代码出现的频率也在不断提升.根据美国国家漏洞数据库(National Vulnerability Database, NVD)[1]公布数据显示,2018年公布的脆弱性代码数目为16 511个,2019年公布的脆弱性代码数目为17 305个,2020年公布的脆弱性代码数目为18 352个.从数据中可以看出,脆弱性代码出现的次数一直在不断上升,因此及时发现软件中存在的脆弱性代码是一份十分重要的工作.
目前检测软件脆弱性的方法主要有静态、动态和混合3大类.静态方法主要是通过分析软件源代码来检测脆弱性,并不运行软件,对运行环境的要求较低,检测的普适性更强.传统的静态方法包括基于规则的分析[2]、代码相似性检测[3](即代码克隆检测)和符号执行[4]等方法.其中,基于规则的分析主要依靠专家人工去发现脆弱性代码的规则,并对源代码进行规则匹配来检测脆弱性;代码相似性检测是将源代码与脆弱性代码进行相似度比较,进而检测脆弱性;符号执行是将输入用符号来表征而不是具体值,将程序的执行过程和程序变量表征成符号表达式来发现脆弱性.传统的静态检测方法不能检测未知的脆弱性且误报率往往比较高[5].与静态方法不同,动态方法是通过实际运行软件来寻找脆弱性,因此可以发现软件运行时的错误.动态方法包括模糊测试[6]和污点分析[7]等方法.模糊测试主要是通过向目标系统提供非预期的输入并监视异常结果来发现软件脆弱性的方法;污点分析主要是通过实时监控程序的污点数据在系统程序中的传播来检测数据能否从污点源传播到污点汇聚点,进而检测软件中的脆弱性.动态测试方法检测准确率高,但通常十分耗时并且缺乏完整性,容易出现漏报的现象.混合方法结合了静态和动态分析技术,与静态方法相比降低了误报率,与动态方法相比减少了运行负载,但混合方法难以全部实现自动化检测,并且对未知脆弱性的检测效果相对较弱.
目前,软件规模越来越庞大和复杂,脆弱性形式也更趋向多样化,传统的软件脆弱性检测方法在处理复杂且多样化的脆弱性方面存在困难.与传统的软件脆弱性检测方法相比,基于机器学习的方法可以从海量数据中发现和学习规律,具有可自动寻找脆弱性的特点,减少了人工参与度,提高了检测的自动化程度.基于机器学习的软件脆弱性检测方法能通过学习已有的脆弱性代码特征检测出类似或未知脆弱性.与基于规则的分析方法相比,无需人工进行规则的提取,降低了人的主观性对于误报率和漏报率的影响等优势;机器学习算法具有自动学习脆弱性代码的特点,与代码相似性分析方法相比,在检测未知脆弱性方面有一定优势;与符号执行相比,无需分析程序的执行过程以构建执行路径,可检测的脆弱性类型更具有一般性;与动态方法相比,无需运行软件,只需分析软件源代码,降低了对运行环境的配置要求.因此,机器学习方法和工具被逐渐应用于软件脆弱性检测领域,代码表征方式和脆弱性特征提取是该领域的重要关注点.
基于机器学习的软件脆弱性检测方法通常分为4步:1)数据预处理.对数据集进行切分、标记等预处理操作.2)代码表征.利用抽象语法树或者代码度量等信息对源代码进行表示,并利用词向量模型将源代码的表示信息转换成数值型向量.3)特征提取.利用神经网络模型学习代码的向量表征,获取代码的高级表示.4)脆弱性检测.利用机器学习算法学习代码的高级表示,并以进行脆弱性检测.通过以上4步就可以利用机器学习的方法来进行脆弱性检测.由于单一软件中的软件脆弱性较少,而机器学习模型需要大量的数据来进行训练,因此可用于机器学习模型训练的真实数据集一般由多个软件的源代码混合而成.目前,现有方法已实现在多个软件源代码混合的真实数据集上做软件脆弱性检测,但其误报率和漏报率较高[8].研究发现,现有方法在代码表征过程中存在着语法和语义信息的损失[8].
机器学习算法能够有效学习到脆弱性代码的特征是提高脆弱性检测效果的重要因素之一,而在学习特征的过程中学习模型的输入数据比学习模型的选择更为重要[9].因此,为了提高特征提取模型和脆弱性检测模型输入数据的质量,本文在代码表征和特征提取2个阶段展开研究.本文提出了一种基于代码属性图(code property graph, CPG)和Bi-GRU(bi-directional gated recurrent unit)的软件脆弱性智能检测方法,主要改进有2个方面:改进代码的表征方式,降低代码表征过程中的信息损失,提高了表征能力;优化特征提取模型,提高了模型的脆弱性特征提取能力.本方法首先采用开源静态分析工具Joern[10]从源代码中提取出代码属性图,再从代码属性图中提取出抽象语法树序列、控制流图序列,然后利用Bi-GRU从序列中提取出脆弱性代码的特征,最后使用随机森林模型构建脆弱性检测器进行脆弱性检测.经实验验证,该方法可有效提高面向多个软件源代码混合的真实数据集的脆弱性检测效果,降低误报率和漏报率.本文的主要贡献包括3个方面:
1) 提出了一种基于代码属性图的软件脆弱性智能检测方法(vulnerability detection based on code property graph, VDCPG),该方法基于代码属性图对源代码进行表征,并根据在LibTIFF数据集上的实验结果选择基于Bi-GRU的特征提取模型对表征向量进行特征提取,降低了不同项目编码风格差异对脆弱性检测效果的影响.实验结果表明,该方法可有效提高面向多个软件源代码混合的真实数据集的脆弱性检测效果,与Lin等人[8]的方法相比,该方法的精确率和召回率最大提高了35%和22%.
2) 针对现有方法在代码表征能力不足的问题,提出了一种基于代码属性图的表征方式,利用从函数的代码属性图中提取的抽象语法树序列和控制流图序列对函数进行表征,以减少代码表征过程中的语法和语义信息的损失,提高表征能力.在本文实验中,与其他表征方式相比,基于代码属性图的表征方式最大可提高30%的精确率和18%的召回率.
3) 在特征提取阶段,基于Bi-GRU和Bi-LSTM(bi-directional long short-term memory)构建多个提取模型.通过实验发现,与基于Bi-LSTM构建的特征提取模型相比,利用Bi-GRU构建的特征提取模型最大可提高10%的精确率和6%的召回率.因此本方法选择利用Bi-GRU构建特征提取模型来挖掘脆弱性代码的特征,提高特征提取模型的脆弱性特征提取能力,进而改善了面向多个软件源代码混合的真实数据集的脆弱性检测效果.
1 相关工作
随着人工智能的发展,基于数据驱动的机器学习算法由于其智能化、可自动学习脆弱性代码特征的特点,被研究者们应用到软件脆弱性检测领域,覆盖了静态分析、动态分析以及动静态分析结合等典型场景.面向动态分析场景的研究主要针对缓解模糊测试、符号执行等动态分析方法存在的程序路径覆盖率低、路径爆炸以及约束求解难等问题,将机器学习方法用于测试输入生成与筛选、路径约束求解以及模糊测试参数配置预测等方面[11].
目前脆弱性检测主要基于静态分析的方法.在静态分析的场景下,基于机器学习的脆弱性检测方法可以分为基于词法、基于语法、基于语义3个层次[12].
在基于词法层的机器学习脆弱性检测方法中,Neuhaus等人[13]提出组件引用是脆弱性代码的特征,通过机器学习的方法从已知的脆弱性代码中寻找规律性,以此来检测脆弱性.Yamaguchi等人[14]提出了利用词法分析来识别函数中的API(application programming interface)调用并通过API符号的词嵌入向量来表示函数,然后再用机器学习挖掘API调用和脆弱性代码的关联以检测软件脆弱性.Wijayasekara等人[15]发现在被公开报告和修补的bug中,有一些软件并未进行修复的现象,提出一种利用文本挖掘技术从公开bug中来挖掘隐藏脆弱性的检测方法.Mokhov等人[16]提出了一种用于静态代码分析和指纹识别的机器学习方法.Pang等人[17]提出了把N-gram方法和基于统计的特征选择结合起来进行软件脆弱性检测的混合方法.
在基于语法层的机器学习脆弱性检测方法中,Yamaguchi等人[18]提出一种从源代码的抽象语法树(abstract syntax tree, AST)中提取特征,再利用机器学习来进行脆弱性检测的方法.该方法首先通过语法分析获取源代码的AST,再将AST映射到向量空间使其AST向量化,然后对大量的样本进行基于奇异值分解(singular value decomposition, SVD)的主成分分析,从而得到矩阵形式的脆弱性结构模式,最后以结构模式为基础,发现与脆弱性代码具有相似结构模式的代码函数.Wang等人[19]提出了一种基于快速序列聚类的软件脆弱性检测方法,该方法利用基于密度的聚类方法对得到的脆弱性序列进行分类,有效地缩小了软件脆弱性的检测范围,提高了脆弱性检测的准确性和效率.
在基于语义层的机器学习脆弱性检测方法中,Cheng等人[20]提出一种基于多子图联合进行代码表征,并用其进行脆弱性检测并定位的方法.Shar等人[21]针对基于机器学习的脆弱性检测方法只能在文件级和模块级对脆弱性进行检测的不足,提出了将机器学习与基于静态分析的脆弱性特征分析方法相结合的脆弱性检测方法,该方法利用静态污染传播分析获取脆弱性代码的特征,然后使用机器学习方法学习SQL(structured query language)注入和跨站脚本攻击(cross site scripting, XSS)脆弱性的模式,以检测脆弱性.Yamaguchi等人[22]针对在函数调用时由于缺乏输入检查而导致的脆弱性的现象展开了研究,提出基于聚类分析来挖掘函数的输入检查模式,缺乏输入检测或者输入检测不正确的函数即为脆弱性,并提供修复建议.Medeiros等人[23]针对已有的污染传播算法缺少对清理操作的识别而导致误报的问题,通过机器学习对污染传播分析的结果进行挖掘,获取脆弱性误报的模式,进而降低污染传播检测中的误报率.
基于语义层的机器学习脆弱性检测方法与其他2个层次的脆弱性检测方法相比具有可检测的脆弱性类型更多的优势,因此越来越多的研究者在语义层进行脆弱性分析的研究.在语义层的脆弱性检测方法中,依据分析对象,可以将其分为基于二进制文件的脆弱性检测[24-25]和基于源代码的脆弱性检测[23]2类.Grieco等人[24]提出一种在二进制文件上利用机器学习来检测内存损坏的方法.但由于二进制代码缺乏上层代码的结构信息和类型信息等,很难与上层代码建立对应关系,分析难度很大,因此基于二进制的代码的脆弱性检测算法相对较少.
基于源代码的机器学习脆弱性检测方法根据其检测的粒度又可以将算法分为文件级、函数级、代码段级3类.Shin等人[26]在文件级用复杂度、代码变化和开发人员活动作为特征来刻画脆弱性,并利用机器学习方法进行检测.Li等人分别以API调用[27]、语义特征[28]等为中心,将源代码切分成代码段,并将代码段的文本[29]或编译[30]后的汇编代码作为机器学习算法的输入以进行脆弱性检测.文件级的脆弱性检测存在无法精确定位脆弱性的位置和脆弱性漏报率高的问题.而代码段级的脆弱性检测由于缺少完整的语法关系,很难得到代码的语法结构信息,只能依赖源代码的文本信息进行脆弱性检测,但这会导致较高的漏报率和误报率.我们希望找到一种能够实现较高的脆弱性定位精度与较低的漏报率和误报率的方法,因此选择函数级作为算法的输入粒度展开研究.
软件脆弱性通常反映在源代码的语法结构中,尤其是在函数级别,因此许多研究者在函数级对脆弱性检测展开了研究.在基于机器学习的软件脆弱性检测方法中,数据预处理比分类器的选择更为重要[31],如何将源代码的文本表示形式转化成可用于模型计算的向量表示形式是至关重要的一步.目前常用的代码表征形式有代码度量、Token序列、抽象语法树和图.抽象语法树[32-33]和图[34-37]与代码度量和Token序列相比具有能保存更多代码语法和语义信息的优势,因此大部分研究者利用抽象语法和图对代码进行表征.Lin等人[8]利用CodeSensor[18]工具对源代码在函数级生成函数的抽象语法树,将抽象语法树进行深度遍历得到函数的向量表示,并通过Word2vec将向量映射成数值型向量,然后通过Bi-LSTM和随机森林的方法来进行脆弱性检测.Liu等人[38]在Lin等人算法的基础上引入迁移学习的框架来解决训练样本不足的问题.为了进一步解决训练样本不足和样本不平衡的问题,Lin等人[39]又提出通过2个Bi-LSTM模型来利用SARD(software assurance reference dataset)数据解决数据不足问题,并通过调整权重和损失函数来解决样本不平衡问题.Suneja等人[40]利用Joern工具生成函数的代码属性图[41](即CPG,包括抽象语法树信息、控制流信息和数据流信息的联合图型数据结构),然后将CPG图作为函数的特征表示输入到图神经网络中来进行脆弱性检测.
以上方法都能从脆弱性代码中学习到脆弱性代码的特征,在函数级对未知脆弱性进行检测,但在对多个软件源代码混合的真实数据集进行脆弱性检测时,有较高的误报率和漏报率.通过对现有方法和多个软件的真实数据集进行研究分析,发现在现有方法在代码表征过程中代码的语法和语义信息存在较大的损失以及数据集中存在着严重的正负样本不平衡现象,这是造成现有算法误报率和漏报率较高的主要原因.
2 脆弱性检测方法VDCPG
为了实现较高的脆弱性定位精度的软件脆弱性检测,需要在较细粒度实现脆弱性检测.文件级的检测粒度太粗,不满足细粒度的要求.而代码段级存在代码段切分困难和易出现漏报、误报的问题.函数级由于函数在源代码中分隔明显,具有易切分的优势.根据2006—2020年的Linux内核脆弱性数据显示,在可获取源代码的1 037个脆弱性中有574个脆弱性在单个函数内.因此,本方法选择以函数为单位进行特征提取和脆弱性检测.
针对现有方法在多个软件混合的真实数据集进行脆弱性检测时误报率和漏报率较高的现象,本文分析了现有方法中存在的问题并提出了改进方法.由于机器学习模型是数据驱动的,数据的提取方式和内容甚至比模型的选择更加重要[9].现有的函数级的基于机器学习的软件脆弱性检测方法一般使用神经网络和随机森林2个模型,分别实现特征提取和脆弱性检测的功能.这2个模型的输入分别是代码表征的结果和特征提取模型提取的代码特征.因此为了提高在多个软件混合的真实数据集上的脆弱性检测能力,本文对代码表征和模型提取2个阶段展开研究.
通过对函数级的基于机器学习的软件脆弱性检测方法的代码表征方式进行调查和研究发现,现有方法主要是利用抽象语法树对源代码进行表征,但抽象语法树缺少控制相关信息,存在着代码语法和语义信息的损失的问题.为了降低代码表征过程中语法和语义信息的损失,提高代码表征的表征能力,需要选择合适的表征方式对源代码进行表征.代码属性图[41]是一种用于代码查询的中间代码表示.它将多个不同的程序表示合并到一个联合图数据结构中.代码属性图本质是一个边带有标记的有向多重图,整合了抽象语法树、控制流图(control flow graph, CFG)和程序依赖图(program dependency graph, PDG)三种表示形式.由于代码属性图含有的信息比单一抽象语法树更加丰富和完整,因此本文选择利用代码属性图来进行代码表征.
由于不同项目之间的编码风格差异较大,直接利用函数的表征来进行脆弱性检测效果较差,因此,在得到函数的代码表征后,需要对代码表征中的信息进行进一步提取和抽象,降低不同项目之间的编码风格差异对检测效果造成的影响,挖掘出隐藏在代码表征中的脆弱性编程模式.在特征提取阶段,现有方法通常基于Bi-LSTM来构建特征提取模型,来挖掘代码表征中的脆弱性特征.但Bi-LSTM模型参数较多,其训练时间较长,同时也易出现过拟合现象.而Bi-GRU是Bi-LSTM的一种变体,与Bi-LSTM相比,Bi-GRU参数更少,具有训练速度更快和不易过拟合的优势.因此本方法选择利用Bi-GRU来构建特征提取模型.
针对2个阶段存在的问题,改进代码的表征方式,优化特征提取模型,提出了一种基于代码属性图和Bi-GRU的软件脆弱性检测方法.同时借助Joern工具本方法可以直接应用到实际的项目源代码文件上,无需将项目源代码切分成一个一个的函数,由Joern工具自动生成函数的代码属性图,因此本方法将数据预处理阶段与代码表征阶段进行合并,在对代码属性图中的信息进行提取时再进行相应预处理.本方法的整体框架示意图如图1所示,本方法通过3个步骤对待测软件进行脆弱性检测:1)代码表征阶段.利用Joern根据从源代码中生成代码属性图,并提取代码属性图中的信息作为函数的表征.2)特征提取阶段.利用基于Bi-GRU的特征提取模型提取函数表征中的脆弱性特征,获得函数的特征向量.3)脆弱性检测阶段.利用随机森林模型学习函数特征向量中的脆弱性特征,以此进行脆弱性检测.

Fig. 1 Software vulnerability detection method based on code property graph and Bi-GRU图1 基于代码属性图和Bi-GRU的软件脆弱性检测方法
3 基于代码属性图的代码表征
代码属性图是一个图形的数据结构,需要选择合适的方式去提取代码属性图中的信息.Suneja等人[40]利用图神经网络来学习代码属性图的特征,进而挖掘脆弱性代码的编程模式.但图神经网络更容易学习到图的结构信息而忽略掉节点中的代码等文本信息,并且将代码属性图转化成图神经网络的输入所需要的处理过程更加复杂.为了合理利用代码属性图中的信息,同时降低预处理的复杂度,本文选择先将代码属性图转换成序列,然后以序列来表征函数,最后再利用神经网络模型提取序列中潜在的编程模式.
基于函数的代码属性图的代码表征过程如图2所示.首先,从函数中生成函数的代码属性图;然后,提取代码属性图中的关键信息,将其转化成序列;接着将文本形式的序列映射成数值型的向量并根据设置的长度,对向量进行填充和截断操作保证向量长度一致;最后对向量进行词嵌入处理,把向量中的每个元素替换成对应的词向量,得到词嵌入向量.通过以上4步就可以得到函数的基于代码属性图的表征.

Fig. 2 Code representation extraction process based on code property graph图2 基于代码属性图的代码表征提取过程
3.1 生成代码属性图
为了得到函数的代码表征,首先需要生成每个函数的代码属性图,本文通过Joern[10]工具从源代码中生成代码属性图.Joern是一个用于分析基于C/C++项目的开源工具,它不需要进行编译和依赖库就可以从整个项目或者单个源文件甚至函数代码片段中提取每个函数的代码属性图.本文以一个简单的C语言函数为例,演示基于代码属性图的代码表征的过程.图3所示的是一个C语言的函数fun1.

通过Joern工具可在图3所示函数中抽取代码属性图,如图4所示.代码属性图是一个有向图,节点表示源代码,这包括低级语言构造(如函数、变量和控制结构),也包括高级构造(如HTTP端点).每个节点都有一个类型,它是节点所表示的源代码的类型,例如类型为“METHOD”的节点表示函数,类型为“LOCAL”的节点表示局部变量的声明.源代码之间的关系通过相应节点之间的边来表示.通过不同类型的边,可以表示同一图中的多种关系.边有“AST”“CFG”“CDG”“DDG”等类型,其分别表示2个节点之间语法关系、控制关系、控制依赖和数据依赖等关系.

Fig. 4 A CPG of function fun1图4 fun1函数生成的代码属性图
3.2 保留代码结构
在获得函数的代码属性图后,需要对代码属性图中的信息进行进一步提取,将其转化成向量的形式,以作为机器学习的输入,同时最大程度地保留代码的结构信息.在生成函数的代码属性图之后,通过Joern将代码属性图导出到Json文件中.代码属性图在Json文件中的储存形式如表1所示:

Table 1 Storage Form of fun1’s Code Property Graph in Json File表1 函数fun1的代码属性图在Json文件中的储存形式
在Json文件中,代码属性图中的每个节点都存在编号、类型和代码等信息,边是通过连接的2个节点编号所表示的.由于程序依赖图无法表示代码行内部的语法结构,不适合用于代码的结构化表征[42],因此只从代码属性图中提取抽象语法树序列和控制流图序列来表征函数.通过分析Json文件中的数据后发现,节点编号顺序含有了代码属性图的结构信息,因此根据Json文件中节点的编号和各节点之间的关系,以[类型,代码,类型,代码,…]的排序方式,从代码属性图中提取到抽象语法树序列和控制流图序列,以此来保存代码的结构信息,提取过程如算法1所示.
算法1.代码属性图序列提取算法.
输入:cpg为代码属性图;nodes为代码属性图中的节点,有编号(id)、代码(code)和类型(type)三种属性;edges为代码属性图中的边,有入节点编号(node_in_id)、出节点编号(node_out_id)和类型(type)三种属性.
输出:AST为抽象语法树序列,有节点编号序列(ids)和序列内容(tokens)两个属性;CFG为控制流图序列,有节点编号序列(ids)和序列内容(tokens)两个属性.
①nodes,edges←cpg
/*从代码属性图中提取出节点和边*/
② foredgeinedges:
/*遍历所有的边*/
③ ifedge.type==“AST” andedge.node_in_idnot inAST.ids:
/*当边为抽象语法树的边时,判断边的入节点编号是否在抽象语法树序列的节点编号序列中*/
④node=nodes.find(edge.node_in_id);
/*如果边的入节点编号不在抽象语法树序列的节点编号序列中,则找到对应的节点*/
⑤AST.token.append(node.type,node.code);
/*在抽象语法树序列的序列内容中加入对应节点的类型和代码*/
⑥AST.ids.append(node.id);
⑦ else ifedge.type==“AST” andedge.
node_out_idnot inAST.ids:
/*当边为抽象语法树的边时,判断边的出节点编号是否在抽象语法树序列的节点编号序列中*/
⑧node=nodes.find(edge.node_out_id);
/*如果边的出节点编号不在抽象语法树序列的节点编号序列中,则找到对应的节点*/
⑨AST.token.append(node.type,node.code);
/*在抽象语法树序列的序列内容中加入对应节点的类型和代码*/
⑩AST.ids.append(node.id);
node_in_idnot inCFG.ids:
/*当边为控制流图的边时,判断边的入节点编号是否在控制流图序列的节点编号序列中*/
/*如果边的入节点编号不在控制流图序列的节点编号序列中,则找到对应的节点*/
/*在控制流图序列的序列内容中加入对应节点的类型和代码*/
node_out_idnot inCFG.ids:
/*当边为控制流图的边时,判断边的出节点编号是否在控制流图序列的节点编号序列中*/
/*如果边的出节点编号不在控制流图序列的节点编号序列中,则找到对应的节点*/
/*在控制流图序列的序列内容中加入对应节点的类型和代码*/
为了更好地保留代码的语义信息,需对节点的源代码进行进一步处理.在程序的源代码中往往含有很多长短不一的字符串常量,而程序源代码中的字符串常量并不影响程序的功能,为了降低字符串常量对代码表征的影响,将代码中的所有字符串用“str”进行替换,如语句中存在“printf(“test”)”,将其进行替换后为“printf(“str”)”.节点中的源代码是以字符串的形式进行储存,需要对字符串进行分割,将变量、操作符、关键字分隔开,使转化后的序列语义正确,如在节点中的源代码是“intx”,将其按变量类型和变量分隔开变成“int”和“x”两个词,如表2所示,函数fun1的抽象语法树序列为[METHOD,fun1,PARAM,int,x,…],控制流图序列为[METHOD,fun1,test2,test2(x),operator.assignment,y,=,test2,(,x,),…].将控制流序列和抽象语法树序列合并得到的文本型向量可唯一的标识fun1函数.本文将从代码属性图中得到的控制流序列和抽象语法树序列组成的文本型向量称为ACS(abstract syntax tree and control flow graph sequence),每一个函数都可被唯一的ACS表示.

Table 2 Motivating Examples of How Function fun1 is Converted to AST and CFG in Serialized Format
3.3 标记和填充
由于后续的机器学习算法不能识别文本型向量,只能以数值型向量作为输入,因此需要将文本型向量转化成数值型向量.为了获取机器学习算法能识别的输入,需要构建一个映射来将向量的每个文本元素链接到一个整数.这些整数充当“标记”,唯一地标识每个文本元素.例如,将类型“METHOD”映射到“1”,将变量“fun1”映射到“2”,以此类推.通过用数字标记替换向量的文本元素,它们的序列保持不变.本方法通过keras分词器Tokenizer来实现这一功能,Tokenizer是一个用于向量化文本或将文本转换为序列的类,利用Tokenizer可以将由抽象语法树序列和控制流图序列组成的文本型向量转换成数值型的向量,如图1所示,通过Tokenizer可将文本型向量(METHOD,fun1,PARAM,int,x,…)转化成数值型向量(1,2,25,…).
由于机器学习模型的输入为同一长度的向量,为了统一输入向量的长度,需要对向量进行填充和截断.由于每个函数的大小不一样,得到的向量长度会不一样,2个不同函数的ACS长度可能还差别很大.为了平衡向量的长度和过稀疏性,应该选择一个合适的长度来填充/截断.对于长度大于L的向量,在对向量末端大于的部分进行截断,对于短向量,在向量末段使用零来填充,使所有向量长度统一为L.
3.4 保留代码语义
为了更好地保留代码的语义信息,对向量需要使用词嵌入进行处理.词嵌入将输入序列中的每个“词”表示为一个固定维数的向量.传统的嵌入方法可能将代码中的变量、类型或操作符(如“+”和“-”)转换为任意维向量,而忽略各个词之间可能存在的关系.Lin等人[8]通过将Word2vec的连续Bag-of-Words(continuous bag-of-words, CBOW)模型生成的词向量投影到二维平面上发现,语义相近的词在平面上的位置是相近的,这表明Word2vec的CBOW模型能较好地保留词之间的关系,进而保留代码语义.因此,本文也采用这种方式保留代码语义.
本文利用所有函数的文本型向量组成的语料库对Word2vec模型进行训练,得到映射集,在映射集中语料库中每一个出现频次达到阈值的词都会有一个唯一对应的N维的词向量.本方法通过在特征提取模型中加入映射层来实现向量的词.利用映射集将向量中的每个元素转换为N维的词向量,当元素没有对应的词向量时,使用全零的N维向量作为当前元素的词向量.
4 基于Bi-GRU的特征提取模型
本文利用了循环神经网络(recurrent neural network, RNN)可以保留序列顺序信息和降维的特点,来挖掘多个软件源代码的深层顺序特征.在RNN的基础上,采用一个由RNN、全局最大池化层、Dropout层和密集层组成的模型来提取抽象语法树和控制流图中的潜在序列特征.
4.1 特征提取模型的选取
RNN能够提取复杂的序列中的顺序信息,这使RNN广泛用于顺序相关数据的预测任务中.对于给定的时间步长t,RNN的输出yt不仅取决于当前的输入xt,还取决于时间步长t-1之前的累积信息.该特性为RNN提供了为当前预测保留过去有用信息的能力,从而使其成为解决NLP问题的强大工具.ACS的元素之间的顺序关系与自然语言中的上下文有很强的相似性,因此将RNN应用到本文场景中.因为ACS反映了代码样本的结构信息,所以改变任何元素的序列都会改变结构和语义含义.例如,向量(METHOD,fun1,PARAM,int,x,…)表示fun1函数有一个int类型的参数x.在改变“METHOD”和“PARAM”的序列后,向量(PARAM,fun1,METHOD,int,x,…)在语义上变得没有意义,参数声明应该跟在函数后.因此,本文将通过基于RNN的方法来提取脆弱性代码中的隐藏顺序特征,挖掘脆弱性源代码的编程模式.
通常,函数中的脆弱性代码的编程模式可以与许多行代码相关联.当将函数映射到向量时,与脆弱性相关的模式与向量的多个元素相关.标准的RNN能够处理短期依赖关系,比如元素“METHOD”后面应该接函数名“fun1”,但是在处理长期依赖关系时,比如捕捉与许多连续或间歇元素相关的脆弱性编程模式,标准的RNN无法处理.因此,使用RNN的变体Bi-LSTM和Bi-GRU来捕获长期依赖,以获取脆弱性代码的高级表示.
LSTM(long short-term memory)由输入门、输出门、遗忘门、细胞状态等构成.LSTM通过对细胞状态中的信息遗忘和记忆新的信息以保留对后续计算有用的信息和丢弃无用的信息,从而达到处理长期依赖的目的.Bi-LSTM其本质是一个双向的LSTM,可以同时处理前向和后向2个方向上的信息.对于时刻t的输出,前向LSTM层具有输入序列中时刻t以及之前时刻的信息,而后向LSTM层中具有输入序列中时刻t以及之后时刻的信息.通过Bi-LSTM可以有效地保留ACS的顺序特征,使神经网络模型可以学习到代码的结构信息.
GRU(gated recurrent unit)是LSTM的一种变体,它比LSTM的结构更简单,训练速度更快.在GRU中只有更新门和重置门,更新门决定时刻t以前的信息对当前时刻t产生的影响,而重置门决定如何将时刻t的输入信息与时刻t之前的累积信息相结合.通过门机制,GRU也可以提取序列中的长期依赖关系.Bi-GRU可以同时处理双向的顺序信息,因此通过Bi-GRU可以很好地挖掘代码中的结构信息,在数据量较少时,Bi-GRU的表现比Bi-LSTM更加优异.
4.2 过拟合的处理
为了避免出现过拟合现象,增强模型的鲁棒性,本方法在特征提取模型中加入Dropout层.Dropout[43]是在深度学习中用来缓解过拟合的一种手段,在一定程度上可以达到正则化的效果.它可以根据数值的阈值p,在每个训练批次中,随机选择隐藏层中的部分节点失效,以减少隐藏层节点之间的相互作用,达到减少过拟合现象的作用.由于在真实数据集中,脆弱性函数的数量较少,存在样本不平衡的问题,在进行模型训练时易出现过拟合现象.因此,尝试在模型中加入Dropout层来缓解过拟合,以达到更好的效果.
4.3 特征提取模型的训练与使用
由于Bi-GRU和Bi-LSTM在不同场景中各有优劣,为了更好地挖掘到代码中的深层特征,达到更好的检测效果,利用Bi-LSTM,Bi-GRU和Dropout构建多个模型,寻找特征提取效果最好的模型.通过在LibTIFF数据集上的初步实验发现,与基于Bi-LSTM的特征提取模型相比,基于Bi-GRU的特征提取模型脆弱性检测的准确率与召回率提高了5%以上,因此本方法选择利用Bi-GRU构建特征提取模型,模型结构如图5所示,在全局最大池化层之后增加Dropout层和密集层,形成一个完整的网络.由于脆弱性检测是一个二分类问题,因此设置特征提取模型的训练损失函数为二分类的交叉熵(binary_cross_entropy).在特征提取模型的训练阶段,使用不同软件项目的已知脆弱性代码混合的数据集训练特征提取模型.通过这些软件项目可以初始化网络参数,以学习脆弱性代码的低级特征.训练输入是从ACS映射得到的数值型向量.输入数据被分为训练集和验证集,用于构建和评估模型,并指导模型调优过程,以实现性能最大化.
尽管特征提取模型也可实现对代码进行脆弱性检测的功能,但在真实情况中,脆弱性代码在软件源代码中所占比重较低,存在着正负样本不均衡的问题,特征提取模型无法处理这一问题,导致特征提取模型的脆弱性检测能力较弱,误报率高,因此本方法只使用特征提取模型提取代码中的脆弱性特征,通过其他集成学习的方法来进行脆弱性检测,以降低正负样本不平衡带来的影响.在特征模型训练完成后,用经过预处理的从目标项目生成的数值型向量(带有有限标签)提供给训练好的网络,并从网络的池化层获得学习到的表示.给定一个长度L的序列作为网络的输入,学习到的表示是一个Z维的向量,称为函数的特征向量.

Fig. 5 The architecture of Bi-GRU network for learning deep CPG representations图5 学习深层CPG表示的Bi-GRU网络结构
5 基于代码属性图的脆弱性检测
在得到函数的特征向量后,需要进一步对特征向量中的脆弱性特征进行学习,以达到脆弱性检测的目的.由于在训练集中的脆弱性函数较少,大部分分类方法无法从训练集中学到脆弱性特征进行脆弱性检测,而随机森林是一个通过对训练集的多次采样构建多棵决策树来进行分类的集成分类器,有助于解决数据不平衡的问题,因此选择随机森林作为脆弱性检测器,学习从神经网络中得到的特征表示.由于现实中,脆弱性代码只占所有代码中很小的一部分,所以数据集会存在严重的正负样本不平衡的现象,因此将随机森林的class_weight参数设置为“balanced”,尽量降低代码不平衡带来的影响.本文利用少量带标签的特征向量对脆弱性检测器模型进行预训练,然后利用测试集来测试整个方法的脆弱性检测能力.
当使用脆弱性检测器来检测时,脆弱性检测器会输出每个代码样本可能为脆弱性代码的概率.通过对测试集中所有函数为脆弱性代码的概率进行排序,即可得到项目中最可能为脆弱性代码的函数.
6 实验与结果
使用本文提出的方法构建了一个基于代码属性图的软件脆弱性检测模型.本节将介绍对本文方法检测能力进行评价的度量标准以及评测数据集的构成和来源,并分别从ACS向量长度、代码表征方式和特征提取模型等方面验证本文所提出方法的有效性.
本文所有实验在一台配置为GPU(GeForce RTX 2060 SUPER),CPU(i7 10700,8核16线程)的计算机上进行,操作系统为Ubuntu18.04.4 LTS,内核为Linux kernel 4.18,采用Joern1.29进行代码解析,编程语言为Python3.7,GPU加速环境为CUDA10.1,cudnn7.6.5,相关依赖包分别为tensor-flow2.2.0,pandas1.0.1,gensim3.8.3,numpy1.18.1,h5py2.10.0,ijson3.1.2,Keras_Preprocessing1.1.2.
6.1 度量标准
本文方法的检测能力是通过以真实漏洞函数在函数列表所占比例来评测的,该列表根据模型预测的函数为脆弱性的概率进行排序.因此,方法的检测能力评估指标是top-k精度(记为P@K)和top-k召回(记为R@K).这些指标通常用于信息检索系统的上下文,如搜索引擎测量检索到的实际有关的文件在检索文档所占比例.在本实验中,P@K指top-k检索函数中脆弱性函数所占比例,其中R@K表示在检索到的前k个函数中脆弱函数所占的比例.P@K和R@K计算为
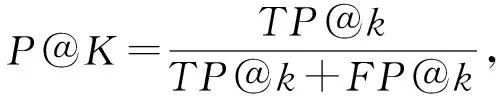
(1)

(2)
其中,TP@k为返回的k个样本中最有可能出现脆弱性的真实正样本,即实际发现的脆弱性函数;FP@k和FN@k分别为在k个样本中检索到的假阳性和假阴性样本.在实际情况下中,脆弱性函数的数量与非脆弱性函数的数量相比少很多.当检索top-k函数时,期望检索尽可能多的脆弱函数.在本实验中,将k设置成是一个在10~200之间的可调整数,以模拟由于时间和资源的限制而检索到的函数数量有限的实际情况.
6.2 数据集
为了构建验证改进代码表征方式对于脆弱性检测效果提升的消融实验(ablation experiment),本文实验选择以抽象语法树作为代码表征方式的Lin等人[8]的方法作为对比对象.由于应用场景不同或不符合消融实验的原则等原因,本文方法不与其他基于机器学习的函数级脆弱性检测方法[38-40]进行对比.
为了与Lin等人[8]的工作进行比较,本文实验在Lin等人[8]构建的脆弱性数据集上进行.脆弱性数据集包含来自6个开源项目的脆弱性和非脆弱性的函数,包括FFmpeg,LibTIFF,LibPNG,Pidgin,VLC Media Player和Asterisk,已被按函数切分并做了标记.该数据级脆弱性函数的标签是根据美国国家漏洞数据库(National Vulnerability Database, NVD)[1]和公共脆弱性数据库(Common Vulnerability and Exposure, CVE)[44]网站的数据进行标记的.该数据集中丢弃了跨多个函数或多个文件的脆弱性;除去已知的脆弱性函数,将剩余的函数视为非脆弱性函数.通过这些函数级的脆弱性数据可以在函数级构建脆弱性检测器,从而实现比在文件更细粒度的检测能力.在数据集中,所有的脆弱性函数的源代码的文件名中会含有脆弱性的CVE编号,因此将所有所在文件的文件名含有“CVE”字符串的函数标记为脆弱性函数,其余全部标记为非脆弱性函数.由于预处理方式的不同,从上述6个开源项目中获得的脆弱性代码样本数量和非脆弱性代码样本数量如表3所示.

Table 3 The Number of Vulnerability Functions in the Dataset表3 数据集中脆弱性函数数量
FFmpeg,LibTIFF,LibPNG这3个软件中脆弱性函数所占比例较高,有利于构建训练集和测试集,因此本文将分别使用这3个数据集作为待测软件,对本文方法进行测试.当选定好待测软件后,利用其他5个软件的数据对特征提取模型进行训练,然后将待测软件的数据划分成训练集和测试集,通过训练集训练脆弱性检测模型,并提供测试集对方法的脆弱性检测能力进行测试.
为模拟单一软件中已知脆弱性较少的实际情况,在这组实验中,在删去一部分由于函数切分错误导致无法提取代码属性图的函数后,将数据样本分为:30%的训练数据和70%的测试数据,经过本文方法和Lin的方法处理后,得到脆弱性函数数量和非脆弱性函数数量如表4所示.将训练集和测试集提供给训练好的特征提取模型来生成函数的特征向量,该模型是使用除待测软件外的其余5个软件的所有数据集进行训练,使用池化层的输出作为函数的特征向量.由训练集生成的特征向量将直接作为训练随机森林分类器的训练集;由测试集生成的特征向量作为测试集来测试训练过的随机森林分类器.

Table 4 The Number of Vulnerability Functions in the Training Set and Test Set表4 训练集和测试集中脆弱性函数数量
6.3 实验和结果
6.3.1 ACS最大长度的设定
由于不同函数的ACS长度差别较大,L的取值会影响到脆弱性检测的效果,该实验通过变化的取值判断其取何值时方法的脆弱性检测效果最好,以确定ACS的默认长度.
通过LibTIFF,LibPNG,Pidgin,VLC Media Player和Asterisk等5个项目的数据对基于Bi-LSTM的特征提取模型进行训练,模型参数如表5所示:
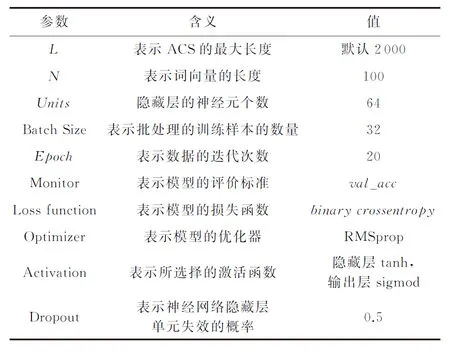
Table 5 Parameters of Feature Extraction Model表5 特征提取模型的参数

Fig. 6 Results of different ACS lengths on FFmpeg图6 不同ACS长度在FFmpeg上的结果
利用一部分FFmpeg项目的数据对基于随机森林的脆弱性检测模型进行训练,然后将剩余部分作为测试集测试模型效果,结果如图6所示.从图6中可知,在前10、前20、前40、前50和前200个方法预测的最可能的脆弱性函数,当L=2 000时,方法预测的真实脆弱性函数的数量最多,同时整体效果最好,因此在后面的实验中设置L=2 000.
6.3.2 与已有表征方法的对比实验
本实验通过对比不同表征方式对软件脆弱性检测效果的影响,以验证基于代码属性图的表征方式的有效性.Lin等人[8]利用CodeSensor[16]提取抽象语法树对代码进行表征,AST是以代码属性图中的抽象语法树作为函数的表征方式,ACS是以代码属性图中的抽象语法树序列和控制流图序列作为函数的表征方式,其特征提取阶段使用基于Bi-LSTM(无Dropout层)的特征提取模型提取特征,以随机森林作为脆弱性检测模型,由于不同表征方式生成的代码表征长度差别较大,本实验根据Lin,AST和ACS等3种代码表征方式在FFmpeg数据集上的检测效果,将特征提取模型输入长度分别设置成1 000,1 500,2 000,其余参数如表5所示.本文在FFmpeg,LibTIFF,LibPNG等3个数据集上,对3种表征方式的表征能力进行检测,其结果如表6所示.表6中加粗的数据为当前在3种基于不同表征方式的方法中表现最好的结果.
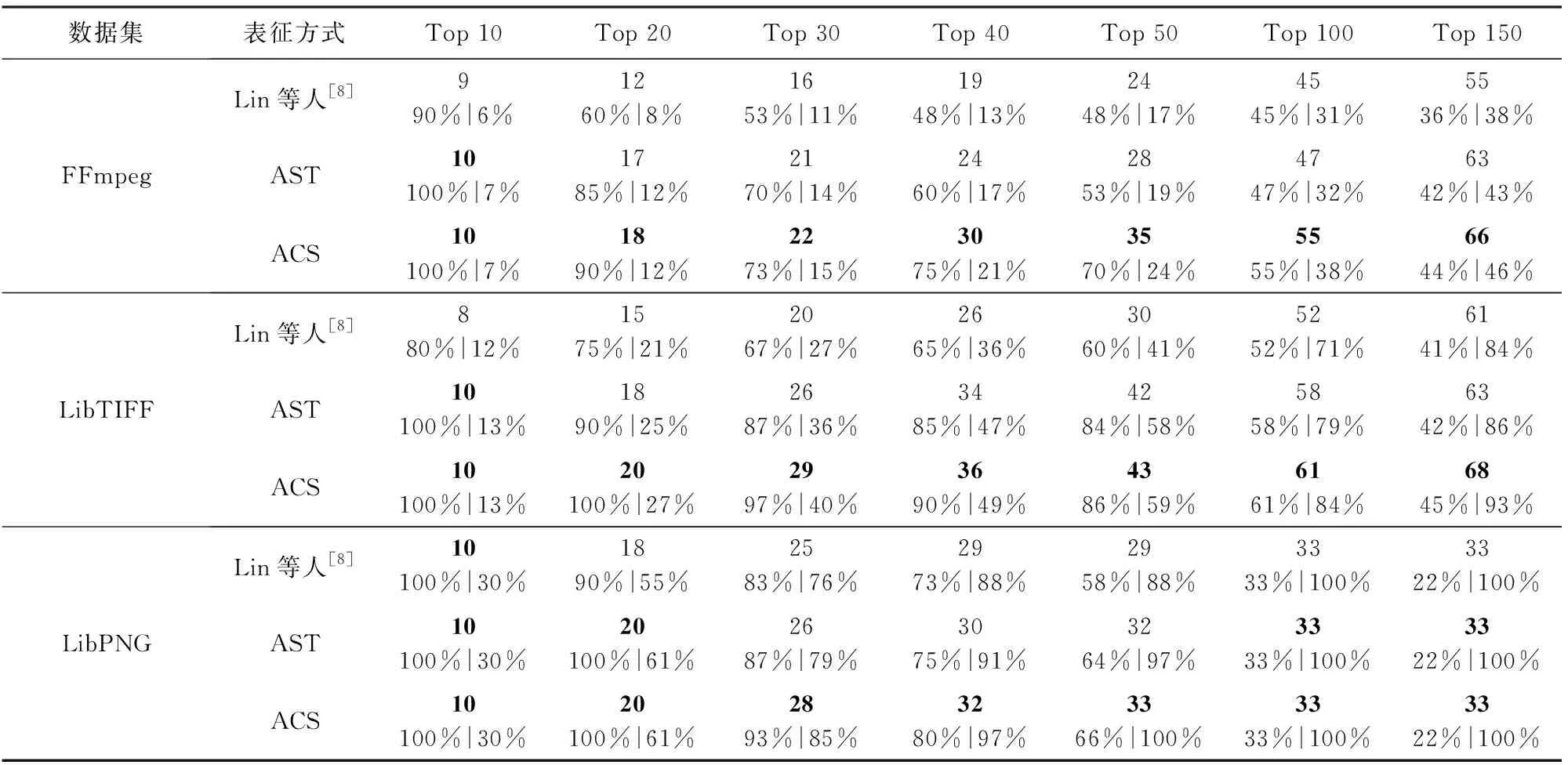
Table 6 The Results of Three Characterization Methods on Different Data Sets表6 3种表征方式在不同数据集上的结果
从表6中可以看出,与其他方法相比,以ACS作为表征方式的P@K和R@K在3个数据集中都是最高的.在LibPNG数据集上,基于ACS的方法预测的前50个最可能的脆弱性函数中包含了LibPNG中所有的脆弱性函数,其R@K达到了100%.与Lin等人[8]的方法相比,基于ACS的方法的P@K和R@K最大提高了30%和18%,而与基于AST的方法相比,基于ACS的方法的P@K和R@K最大提高了17%和8%.实验结果表明,在FFmpeg,LibPNG和LibTIFF数据集上,以ACS作为表征方式时,方法的脆弱性检测效果优于另外2种表征方式.
为了更直观地对比3种方法的结果,我们将3种方法在3个数据集上的精确率可视化成折线图,如图7所示.从图7(a)中可以看出,以ACS作为表征方式的方法预测的前10~150个最可能的脆弱性函数的P@K一直高于另外2种方法,在预测的前40个最可能的脆弱性函数中,以ACS为表征方式的方法比Lin等人[8]和以AST为表征方式的方法的P@K分别高28%和15%.从图7(b)中可知,在以LibTIFF作为待测软件时,基于ACS的方法预测的前20个最可能的脆弱性函数的P@K为100%,比另外2种方法表现更加优异.从图7(c)可知,基于ACS的方法在LibPNG数据集上预测的最可能前30个最可能的脆弱性函数P@K一直高于90%,与Lin等人[8]的方法相比,P@K提高了10%.
6.3.3 不同特征提取模型的脆弱性检测效果对比
本节将对比不同特征提取模型的脆弱性检测效果,以找到最合适的特征提取模型.我们基于Bi-LSTM,Bi-GRU和Dropout构建4个模型.4个特征提取模型的整体结构与图5的结构类似,模型参数如表5所示,Bi-LSTM_1的结构与图5相比,删去了Dropout层,并将Bi-GRU替换成了Bi-LSTM,而Bi-LSTM_2则只是将Bi-GRU替换成了Bi-LSTM,Bi-GRU_1与图5的结构相比,删去了Dropout层,而Bi-GRU_2的结构与图5的结构一致.
本实验分别将FFmpeg,LibTIFF,LibPNG这3个数据集作为待测软件对特征提取模型进行测试.在FFmpeg上进行测试时,从特征提取模型中获取FFmpeg数据集的特征向量,再用FFmpeg中训练集的特征向量训练脆弱性检测模型,最后用FFmpeg中的测试集来测试模型的脆弱性检测效果,其结果如表7所示.

Fig. 7 Detection performance comparison of three characterization methods图7 3种表征方式的检测性能比较
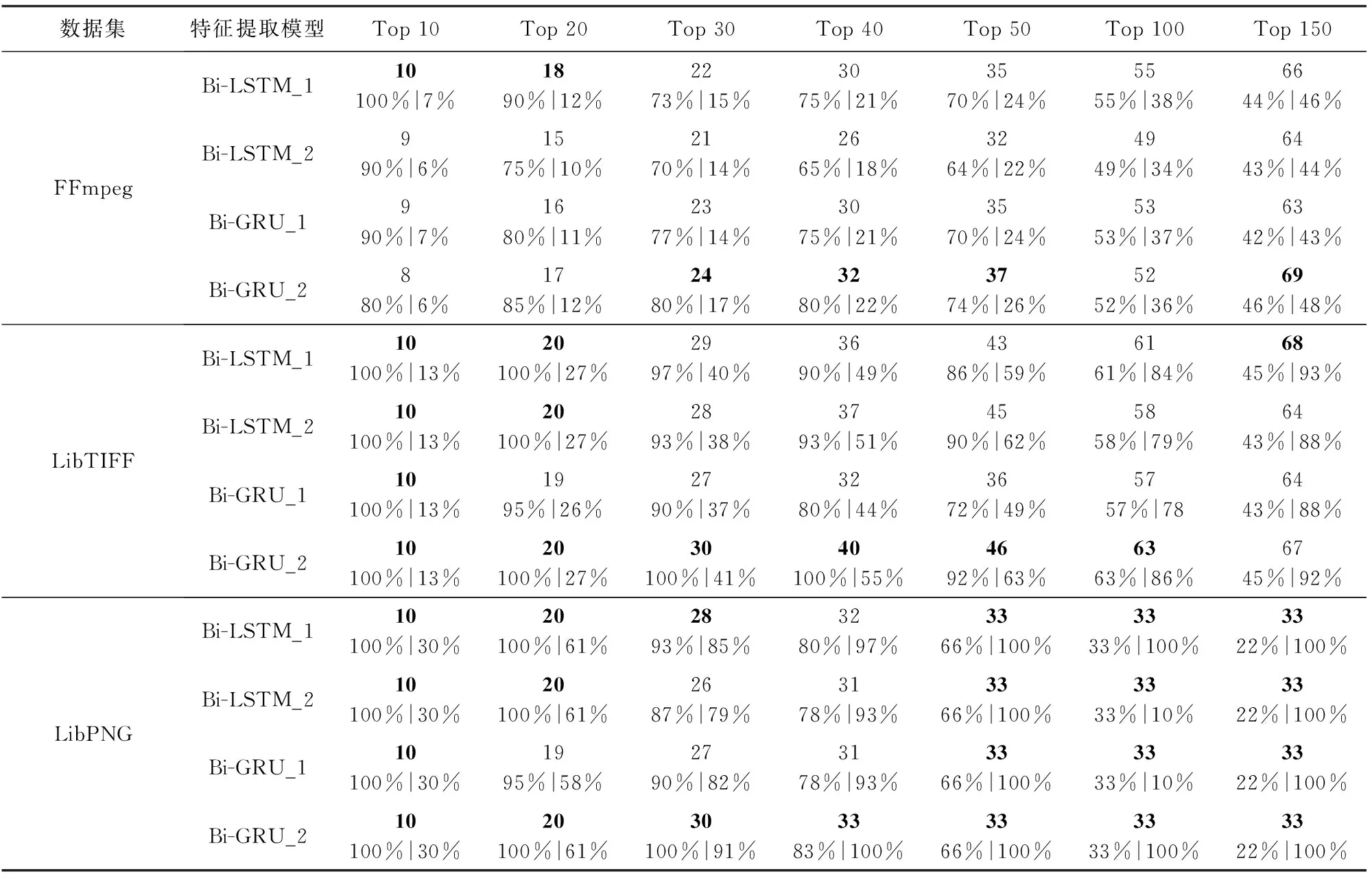
Table 7 The Results of Four Feature Extraction Models on Different Datasets表7 4种特征提取模型在不同数据集上的结果
从表7中可以得到,与Bi-LSTM_1相比,以Bi-GRU_2为特征提取模型的方法的P@K和R@K最大提高了10%和6%,同时由于Bi-GRU模型的参数更少,其训练时间会比Bi-LSTM模型的训练时间更少.因此,本方法使用Bi-GRU加Dropout层作为特征提取模型来进行特征提取.

Fig. 8 Detection performance comparison of four feature extraction models图8 4种特征提取模型的检测性能比较
将4个特征提取模型在3个数据集上的精确率绘制成折线图,如图8所示.从图8(a)可以看出,在FFmpeg数据集上,方法预测的10~150个最可能的脆弱性函数中,以Bi-GRU_2为特征提取模型的方法的R@K为最高的次数,同时在其预测的前150个最可能的脆弱性函数中,真正的脆弱性函数的数量达到了69个,占到了FFmpeg中脆弱性函数总数量的48%.在图8(b)(c)中可知,以Bi-GRU_2为特征提取模型的方法的R@K一直高于其他3种特征提取模型.在LibTIFF数据集上,以Bi-GRU_2为特征提取模型的方法预测前40个最可能的脆弱性函数的R@K达到了100%,优于其他3个模型.在LibPNG数据集上,以Bi-GRU_2为特征提取模型的方法预测的前40个最可能的脆弱性函数包含了LibPNG测试集中全部的33个脆弱性函数,R@K达到了100%.同时从图8中可知,在FFmpeg,LibTIFF和LibPNG这3个数据集上,Bi-LSTM_1的检测效果优于Bi-LSTM_2,这表明在Bi-LSTM的模型中加入Dropout层并没有带来效果提升,这是由于Bi-LSTM的参数较多,而数据集中脆弱性样本较少,加入Dropout层后,反而参数不能及时得到更新,从而导致检测效果变差,而Bi-GRU_2的检测效果优于Bi-GRU_1,这表明在Bi-GRU中加入Dropout层后能够提升检测效果,这是因为Bi-GRU中所含有的参数更少,加入Dropout层后反而能有效地学习到脆弱性函数的特征,增强模型的泛化能力.
6.3.4 不同方法的时间性能的比较
本节主要比较本文方法和Lin等人[8]方法在时间方面的性能.从表8中可以看出,本方法与Lin等人[8]的时间开销主要是模型训练阶段和预处理阶段,在检测阶段的时间差别不大.同时Lin等人[8]的方法必须先将项目文件中的函数提取出来,生成每个函数独立的代码文件,才能作为方法的输入.而VDCPG可直接输入项目中的代码文件,无需切分.本文的数据集是已经将源代码根据函数切分好的数据集,没有计算函数切分的时间,因此2种方法在实际情况中时间的开销会更接近.与增加的精确率和召回率而言,增加的时间开销是可接受的.
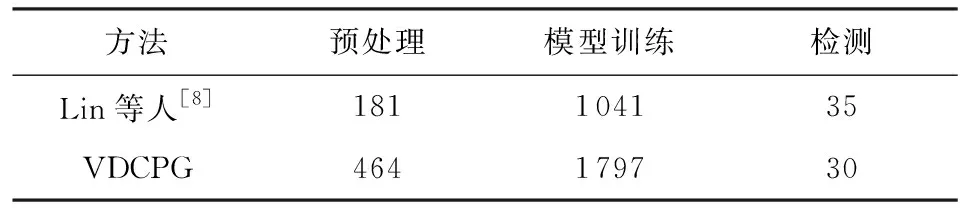
Table 8 Comparison of Time Performance
7 总 结
本文针对现有方法在多个软件混合的真实数据集进行脆弱性检测时误报率和漏报率较高的现象,在代码表征和特征提取阶段展开了研究,发现现有方法存在代码表征方式表征能力不足的问题,通过改进代码表征方式,提高表征方式的表征能力,优化特征提取模型,增强特征提取模型的特征提取能力,提出了一种基于代码属性图和Bi-GRU的软件脆弱性检测方法.实验结果表明,本文提出的基于代码属性图和Bi-GRU的软件脆弱性检测方法可提高面向多个软件源代码混合的真实数据集的脆弱性检测效果,降低误报率和漏报率.
