基于深度递归信念网络的风电功率短期预测方法
2021-08-11李宏仲孙伟卿
李宏仲,付 国,孙伟卿
(1.上海电力大学电气工程学院,上海市 200090;2.上海理工大学机械工程学院,上海市 200093)
0 引言
由于风电集中大规模接入,给电力系统安全、稳定、经济运行带来严重影响[1],而精准的风电功率预测可以减轻其对电网的不利影响。
目前,风电功率预测方法主要分为两大类,统计法和物理法[2]。其中,物理法是根据地表信息和气象数据作为初始边界条件,使用数学模型进行推理求解[3];统计法是通过历史数据的特性建立统计模型,进一步预测未来时刻的风电功率[4],主要包括时间序列法和人工智能法[5]。由于各种方法都存在不同方面的误差,为了降低单一方法的误差上限,加权各种预测方法或者融合不同方法的优势构建组合预测模型也是一个研究方向[6]。
相比研究不同的预测方法,从预测误差产生的机理去提高风电预测的精度显得尤为重要,文献[7]从风电的波动程度、功率幅值和预测方法等因素出发,发现风电波动剧烈的时间段预测误差明显增大;文献[8]采用多重分形理论提取风速波动特征并叠加预测误差,使得预测精度进一步提高;文献[9]研究了不同波动过程下预测误差的分布,发现风电的不同波动类型对应不同的误差范围。为了分析波动误差的影响因素,文献[10]根据波动误差和气象信息之间的相关性搭建误差修正模型;文献[11]通过误差分布的动态云模型对风电功率的不确定性进行精细化量测。以上文献表明风电波动过程影响风电预测误差,因此,本文通过图聚类快速提取和聚合波动过程,构建分类预测模型以进一步改善风电的预测性能。
近年来,大量专家学者将深度学习应用到预测领域。文献[12]采用递归神经网络(RNN)预测风速和风电功率;但RNN在训练过程中容易出现梯度消失的问题,使用tanh激活函数结合交叉熵损失函数可以解决梯度消失的问题。文献[13]将深度信念网络(DBN)和长短期记忆(LSTM)网络用于时序预测中;文献[14]采用DBN和堆栈自编码(SAE)同时预测风速,结果显示DBN的预测误差更小。以上研究均表明采用DBN模型可以提高预测精度,但DBN弱化了时序间的相关性[15-16]。考虑到RNN能够反映时序间的相关性,因此可用RNN取代受限波尔兹曼机(RBM)中的隐含层,并分阶段堆叠RNNRBM得到深度递归信念网络(DRBN)的模型结构[17]。
不同于单纯引入机器学习或者人工智能的预测算法,本文应用改进摇摆窗算法识别风速波动过程,并采用广度优先搜索邻居(BFSN)算法对风速波动过程进行聚类。然后,根据聚类结果将风速波动划分为低出力过程、小波动过程、大波动过程和尖峰波动过程4类。最后,通过DRBN建立相应的分类预测模型,并将待预测日的风速数据按照不同波动过程分别输入至训练完成的模型中进行功率预测。
1 风速波动过程的识别与聚类
随着风速、风向、气压、空气密度等气象条件的变化,风速将出现不同程度的波动,但目前风机大多具有自动偏航系统且空气密度在短时间内不会剧烈变化。因此,风速的不同波动是影响风电功率波动的主要原因。本文识别并聚合风速的不同波动过程作为分类预测的输入数据。
1.1 摇摆窗算法识别风速波动过程
摇摆窗算法[9]在风速波动过程识别中仅需要人为选取一个窗宽参数ε。摇摆窗算法识别风速波动过程的原理如图1所示,图中以15 min为1个时段。
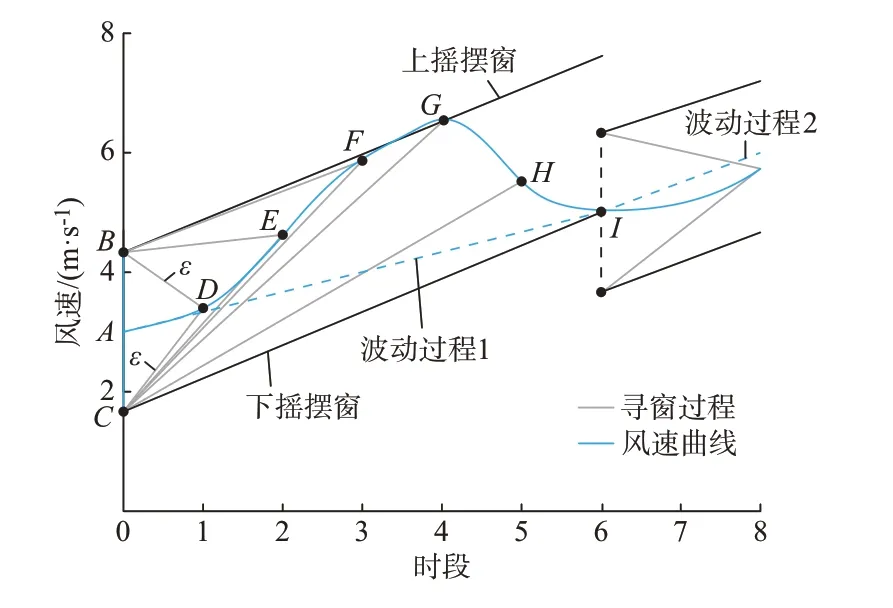
图1 摇摆窗算法识别波动过程的原理图Fig.1 Principle diagram of identifying fluctuation process by swing window algorithm
从图1可知,ε的选取对于波动过程的识别至关重要,ε的值过小会导致识别结果中大部分为小幅波动,ε的值过大则会使得识别结果均为大幅波动而忽略了小幅的波动。在风速的波动识别中,应当根据实际情况选取合适的ε值。
摇摆窗算法的波动过程识别原理如下:

式中:Dup(t)和Ddown(t)分别为上、下摇摆窗;v0为初始时刻的风速;T为总时段;v(t)为t时刻的风速,从t=0开始计算上、下摇摆窗,寻窗过程中当满足式(2)的约束条件时,即完成一个波动过程的识别处理。

其中,tm=mint是指取满足Dup(t)≥Ddown(t)的最小时刻为此波动过程的终止时刻。
由式(2)可知,在波动识别过程中存在如下2种特殊情况:①很可能在一个连续同趋势的波动过程中包含一个拐点,导致在每段波动过程中都会忽略掉一个数据点;②附录A图A1所示的2个连续相同趋势的波动识别中,上、下摇摆窗未平行时便进入下一个波动过程,将会漏掉一个相同趋势的波动过程。
因此,本文对传统摇摆窗算法做如下改进:①每完成一次波动识别的迭代过程都要判断终止点与前后2个采样点的风速之差是否同号;②从上摇摆窗取得最大值时的第2个采样点开始,分别判断此时与前后2个采样点下摇摆窗的数值之差是否同号。则波动过程识别的终止条件变为:

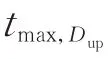
1.2 风速波动过程的聚类方法
本文基于BFSN[18]算法聚类风速的波动过程。BFSN算法在进行聚类分析时,需要输入距离参数r和形状参数λ,下面以风速波动过程的聚类为例说明其具体含义。
1)距离参数r
距离参数r可以理解为2个风速波动过程是否能作为邻居的阈值,用于控制各类别之间的距离。为了减小训练模型个数并区分不同波动对预测模型的影响,取r为相异度矩阵D[19]的平均距离,然后观察聚类结果修正距离参数r,将波动过程聚合为低出力、小波动、尖峰大波动和大波动[8]。相异度矩阵D中 的 元 素 为 动 态 弯 曲 距 离di,j[20],表示2个 波动过程的相似程度,若小于判别阈值r,则可视为邻居,D的表达式如式(4)所示。

2)形状参数λ
λ∈(0,1)用于控制聚类的形状,若某风速类别Vt中已经包含了m个波动过程{v1,v2,…,vm},一个新的风速波动过程vq要归入此类,则需满足:


风速波动过程聚类步骤如下。
步骤1:输入风速的波动过程集合。
步骤2:输入聚类参数r和λ。
步骤3:求解波动过程集合的相异度矩阵。
步骤4:随机选择一个波动过程作为新类的初始对象。
步骤5:邻居划分,从新类的初始对象出发,基于BFSN算法的原则,根据距离参数r判别此波动过程的邻居。
步骤6:搜索聚类,根据λ判断是否将邻居归入此类,遍历所有邻居即完成了此类别的聚类。
步骤7:判断是否完成集合中所有波动过程的聚类,若仍有未聚类的对象,转至步骤4,直至完成集合中所有波动过程的聚类。
2 基于DRBN的风电功率预测
本文构建的DRBN的信息传递过程见附录A图A2,包括前向生成过程和误差反馈过程。其中,误差反馈包括2个方向:时间维度间的横向误差反馈和RBM相邻各层间的纵向误差反馈。
2.1 基于DRBN的模型架构
2.1.1前向生成网络
DBN是Geoffrey Hinton[21]在2006年 推 导 出 来的一种生成模型,通过训练各层的RBM可以提取并拟合数据的高阶特征。但是传统的DBN不能反映时刻之间的相关信息,考虑到RNN在时序预测方面具有较好的泛化性能,可以将RBM中隐含层信息由RNN替代共同构成RNN-RBM模型[22],其模型结构如图2所示。

图2 RNN-RBM模型的结构图Fig.2 Structure diagram of RNN-RBM model
图2中每个蓝色边框里面表示一个RBM,绿色边框里面包含按时间序列展开的RNN,h(t)和v(t)分别表示t时刻RBM中的隐含层的输出和可视层的输入,其条件生成概率P(v(t),h(t))为:

式中:h(t)/A(t)表示在A(t)条件下的h(t);A(t)为t时刻之前所有{(v(t−1),h(t−1))}集合。
RNN-RBM模型带有反馈连接的深层结构,可以表达时序数据间的相关性,因此其模型结构除了与隐含神经元和可见神经元有关外,还与上一时刻数据相关。利用式(7)和式(8)可分别计算可见层和隐含层的参数,状态u(t)通过式(9)进行更新。

式中:b(t)和c(t)分别为t时刻可见层和隐含层的偏置;Wuv、Wuh、Wuu、Wvu为连接权 重;σ(⋅)为 激活函数;b(0)、c(0)、u(0)为被赋予一个随机值的初始状态,RNN-RBM模型参数通过使用b(0)、c(0)和权重进行训练。
DRBN由RNN-RBM模型逐层训练堆叠而成,见附录A图A3。假设DRBN有k层网络结构,输入序 列F={v(1),v(2),…,v(t),…,v(T)},长 度 为T;输出的元素为Ô(t),隐含层与输出层的权重为Q(t),输出层的激活函数为g(⋅),则模型的前向生成过程为:

式 中:Wvu,i和Wuu,i分 别 为 权 重Wvu和Wuu的 第i个元素;ci(t)为隐含层偏置的第i个元素。
2.1.2误差反馈网络
误差反馈网络可以确保此网络模型向全局最优的方向修正。设t时刻DRBN的输出值为Ô(t),实际功率值为O(t),则该时刻的预测误差为:

通过计算式(12)的导数得到误差E1(t)和E2(t)的梯度。
1)误差E1(t)在各层RNN-RBM模型之间传递,设该方向的误差梯度为Eg,i−1(t),分析式(11)可知误差梯度仅与权重Wvu,i有关,即
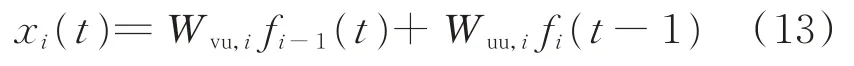

式中:xi(t)为与误差E1(t)和E2(t)相关的中间函数;σi−1为第i−1个激活函数。
2)误差E2(t)沿时间序列传递,设该方向的误差梯度为Eg,i(t−1),分析式(11)可知误差梯度仅与权重Wuu,i有关,即

2.1.3基于交叉熵理论的损失函数
损失函数是为了统计模型输出误差的情况,而交叉熵可以表示2个概率分布之间的接近程度。为了比较风电历史功率分布与模型输出分布之间的相似程度,本节基于交叉熵理论的损失函数来有效处理均方误差损失函数中参数更新过慢的问题,以尽量避免误差反馈的优化过程陷入局部最优解。假设风电功率历史数据服从分布p,模型输出值服从分布q,则其交叉熵D(p,q)为[23]:

式中:pi和qi分别为分布p和分布q中的第i个元素,共有n个元素。
对式(16)变形可知,第1部分为已知的历史功率数据,对每次损失函数的计算结果没有影响,可以忽略不计。余下部分作为预测模型的损失函数,即

损失函数的取值越小,表示历史功率分布与模型输出分布之间的相似程度越高,即预测误差越小。
2.2 基于DRBN的风电功率预测算法流程
本文首先利用第1章提出的方法识别并聚类风速波动过程,然后分类训练基于DRBN的模型参数,最后输入按照波动过程聚类后的风速预报数据,分类预测短期风电功率。具体算法流程见图3。
3 算例分析
3.1 仿真数据和评价指标
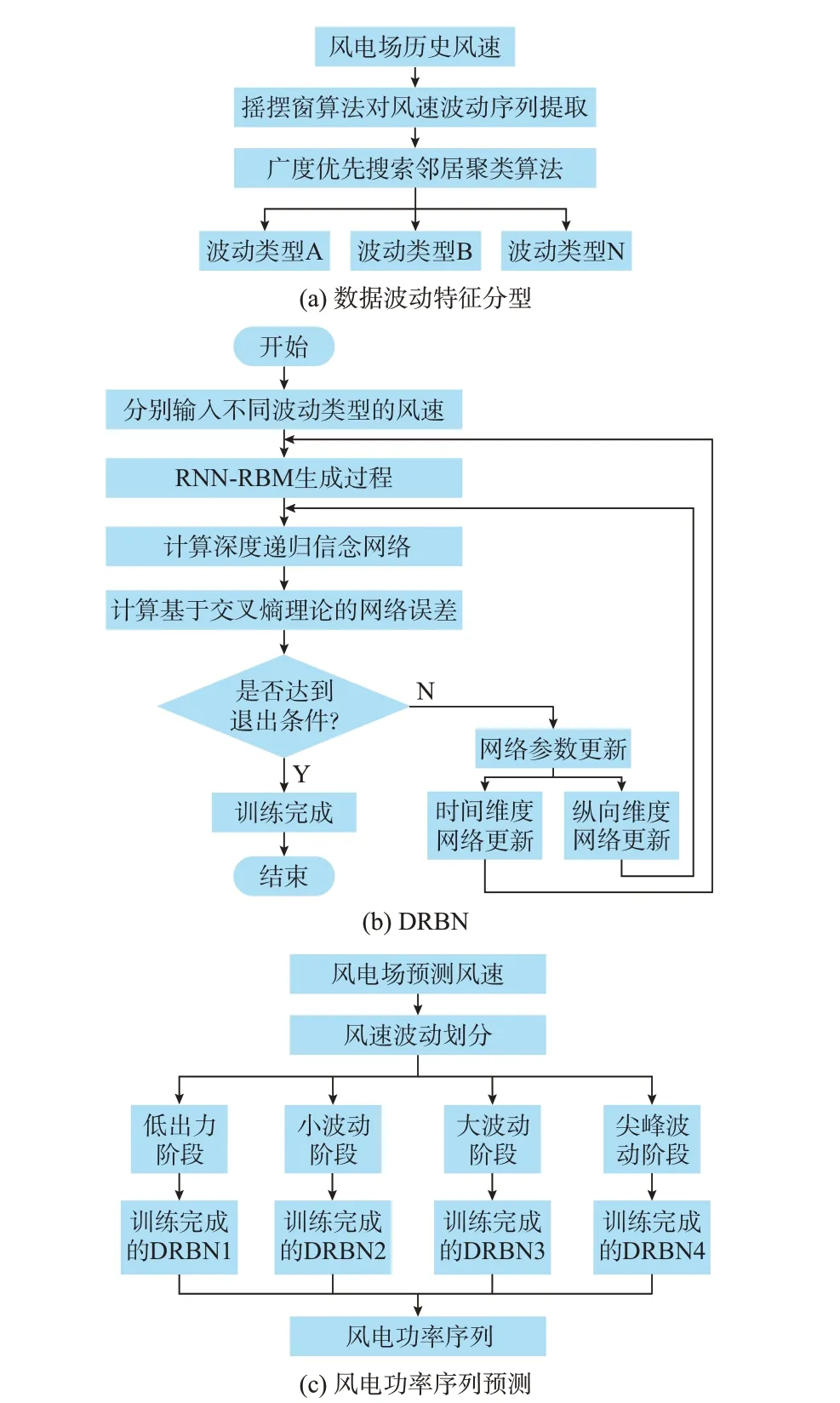
图3 基于DRBN的风电功率预测算法流程图Fig.3 Flow chart of wind power forecasting algorithm based on DRBN
本文选取中国某一风电场2017年11月至2018年10月的风速和对应的风电功率数据对预测模型进行验证分析。该风电场的额定装机容量为100 MW,将全年的风速分为大风期和小风期,以2017年11月至2018年2月的风速作为大风期训练数据,用于预测2018年3月的风电功率。以2018年4月至2018年9月的风速作为小风期的训练数据,用于预测2018年10月的风电功率,数据采样间隔为15 min。
本文分别选择传统的DBN、支持向量机(SVM)、SAE等预测方法对预测效果进行对比分析,以验证所提方法的有效性。预测评价指标选取平均绝对误差(NMAE)和标准均方根误差(NRMSE),以及评价2个数据序列相似程度的互相关系数。
3.2 风速波动数据的划分与聚类
本文模型共计28 800个风速训练数据,受篇幅所限选取其中144个波动过程识别后的风速数据进行展示,摇摆窗算法的窗宽ε取最大风速的5%,波动识别结果如附录B图B1所示。
根据1.2节风速波动聚类方法流程对模型训练数据进行自动聚类,聚类参数r=0.2,λ=0.1,选取大风期2月和小风期7月的风速聚类结果进行展示,如附录B图B2和图B3所示,共划分了低出力过程、小波动过程、大波动过程和尖峰大波动4类波动过程,不同波动过程的样本数量见表B1。
3.3 风速波动数据处理与网络层数确定
摇摆窗算法提取波动过程的时间长度不一致容易致使网络模型调优过程收敛性能差。因此,在数据输入DRBN之前需要统一每个波动过程的数据长度。
以每个波动类型中数据个数最大的波动确定模型的结构,将小于此时间长度Tmax的波动,在其波动数据的首端和末端分别填充数据0,但是在训练和预测过程中,考虑到波动数据时序间的相关性,设置自动忽略首端和末端为0的数据。例如某波动过程vi,样本个数Ti<Tmax,数据补充规则如式(18)所示,将缺少的数据平均补充至首端和末端。
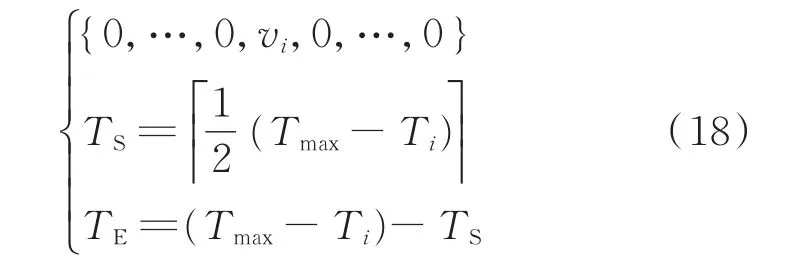
通过风电功率预测结果的NMAE的变化情况确定最佳的网络层数。

式中:k为RNN-RBM模型的网 络层数;kRNN-RBM为初始 设 置 的RNN-RBM模 型 的 网 络 层 数;εNMAE,k为RNN-RBM模型网络层数为k时风电功率预测的平均绝对误差。
由附录B表B2可知,随着网络层数的增大,NMAE先减小后增大,不同的波动过程精度不再提高时具有不同的网络层数,其中,低出力波动过程和小波动过程的最佳层数为3,大波动过程和尖峰波动过程最佳层数为4。
3.4 仿真结果分析
按照本文所提方法将低出力波动过程、小波动过程、大波动过程和尖峰波动过程的数据个数依次设置为20、20、25和15,训练优化网络参数,最后根据2018年3月和10月的风速预测数据,得到按照波动划分的预测结果。
1)不同波动过程的预测结果
为了验证本文所提方法的先进性,对比了分类和未分类预测情况下的预测精度,如表1所示。

表1 不同方法下各波动过程的风电功率预测结果误差Table 1 Wind power forecasting errors of each fluctuation process with different methods
对于不同波动边界点预测结果不一致的情况,以波动较平缓的预测结果为准,即按照低出力波动过程、小波动过程、大波动过程和尖峰波动过程的顺序对相邻波动边界点的预测结果进行选取。
从表1可知:①低出力和小波动过程的预测精度高于风速快速变化的大波动和尖峰波动过程;②按照波动过程进行分类预测可降低未分类建模的预测精度;③本文所提预测方法无论相比传统人工智能方法(如SVM)还是同自动编码的SAE都能减小其预测误差;④在不改变模型的情况下,提高气象预报的预测精度,可以进一步优化预测结果,因此未来可采用数值天气预报对不同风况下气象数据所包含的物理特性进行更深度的分析,以期提升气象预报信息的准确度。
利用4种方法得到的预测结果如图4所示,可以看出,经过对DBN改进后的预测方法具有最高的预测精度,功率预测曲线和该地区实际的风机出力趋势一致。

图4 某一预测日各种预测方法对比Fig.4 Comparison of various forecasting methods for a certain forecasting day
根据预测结果,得到各种预测方法的相对误差见附录B图B4。方法B、C、D、E分别代表本文所提方法、DBN、SVM和SAE方法。从相对误差序列图中可以看出,本文所提方法的总体相对误差偏小,没有极端突变误差的出现,预测结果的稳定性较好。
2)算法效率
DRBN方法的损失函数值随训练次数变化趋势对比见附录C图C1。由图C1可知,未分类DRBN方法训练60次可收敛至最优解,而通过识别训练样本的相似性,分类DRBN方法训练40次即可收敛到最优解,并且除了尖峰波动其余波动类型的损失函数在收敛时均小于未分类DRBN方法。大风期和小风期下不同算法的仿真时间见表C1。
从附录C表C1中的仿真时间可知,SAE方法耗时最长,SVM方法作为浅层模型耗时优于其他3种深度学习方法。本文方法在DBN方法的基础上添加了反馈连接,使其训练和预测的过程中每个时刻的预测结果增加了上一时刻的权值信息,因此,其仿真时间相比DBN模型有所增加,但预测精度高于其他3种方法。
3)横向、纵向误差反馈分析
为了验证DRBN方法的横向、纵向误差反馈网络对风电功率预测精度的影响,对横向和纵向误差反馈网络做如下处理,一是不考虑横向误差反馈,二是不考虑纵向误差反馈。以大风期为例,2种处理方式下的预测结果见附录C表C2。
由附录C表C2的结果可知,增加横向、纵向误差反馈网络后,可以减小误差,改善预测精度。当不考虑横向误差反馈时,相关性系数指标随之降低;当不考虑纵向误差反馈时,预测精度NMAE和NRMSE分别下降了1.09%和1.55%。
4 结语
针对目前风电功率短期预测中存在的较大误差,本文首先识别并聚类风速波动过程,然后采用DRBN方法对不同的波动过程进行预测,最后通过和其他方法进行对比分析,得到如下结论。
1)通过对比4种预测功率的平均绝对误差和均方根误差,验证了本文所提方法可以减小机器学习方法的预测误差,提升DBN和SAE方法的预测精度,并降低了其他预测方法在波峰、波谷存在较大预测误差的问题。
2)本文按照风速波动进行分类预测可以提高未分类的预测精度。
3)DRBN方法采用横向、纵向误差反馈可以有效降低单一反馈网络下的误差。
分析本文涉及的预测方法,SVM方法受核函数影响较大,当出力模式或者风速出现骤变时,预测结果会出现相位误差导致预测规则无法匹配;DBN和SAE方法利用RBM与自编码器进行预训练,通过挖掘风速数据间隐含的非线性特征和深层变化规律,可以得到较好的预测结果,但对于风资源强烈的随机波动预测效果不佳。因此,未来可以进一步优化寻优算法降低模型的复杂度和训练时间,分析网络模型的训练参数和风况之间的相关性来提高预测精度。
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
