图像去噪方法概述
2021-08-07刘利平乔乐乐蒋柳成
刘利平,乔乐乐,蒋柳成
华北理工大学 人工智能学院,河北 唐山 063210
图像在采集、传输过程中因环境、成像设备和人为等因素的影响会受到不同噪声的干扰[1],导致采集的图像质量下降,给后续的特征提取、文本检测、图像分割等图像处理环节造成不可估计的影响,因此,需要对图像进行去噪处理。图像去噪作为计算机视觉研究领域中一个重要的研究方向,其目的是尽可能地减少或消除噪声对图像的干扰,使处理后的图像尽可能接近原始图像。图像去噪的实质是对数据本身恢复和重建,以起到排除污染的作用。由于真实噪声图像的不足,加性白噪声图像(additive white noise image,AWNI)被广泛用于训练去噪模型[2]。AWNI包括高斯、泊松、盐、胡椒和乘性噪点图像[3]。
图像去噪有着悠久的历史,最早的作品可以追溯到20 世纪50 年代[4]。最近的去噪方法激增主要归功于著名的块匹配3D(block-matching and three-dimensional filtering,BM3D)框架[5],该框架结合了自然图像的非局部相似性特征和变换域中的稀疏表示[6]。在早期阶段,图像去噪的许多相关工作都集中在过滤单通道灰度图像上。近年来,成像系统和技术的进步极大地丰富了多维图像(彩色图像)保存和呈现的信息,可以为真实场景提供更真实的表示。图像尺寸和维度的增长也对去噪提出了更高的要求。处理高维图像的一个主要挑战是如何有效利用多个通道或频谱的相互关联的信息,并且还要在噪声消除和细节保留之间找到平衡。在过去的二十年中,具有代表性的BM3D 方法已经以两种不同的方式成功地扩展到了多维图像。第一种策略是应用某种相关变换,以使在变换后的空间中,每个通道可以由某个有效的单通道去噪器独立过滤[7]。例如,CBM3D(color-BM3D)方法[8]对自然RGB 图像建立的对比度或YCbCr 颜色变换可以提供颜色数据的近似最佳解相关[9]。另一种替代解决方案是利用信道或频带相关性通过联合处理整个多维图像数据集来建模。为了实现这一目标,Maggioni等人[10]通过使用3D像素立方体将BM3D扩展为稀疏4D变换域协作滤波(BM4D),将其堆叠为4D 组。
尽管传统方法在图像去噪方面已经取得了相当不错的性能,但它们仍然存在一些缺点,包括需要针对测试阶段的优化方法,手动设置参数以及单个降噪任务的特定模型。近年来,随着神经网络架构变得更加灵活,深度学习技术获得了克服这些缺点的能力。
1 图像去噪的基本框架
图像中噪声的来源有许多种,这些噪声来源于图像采集、传输、压缩等各个方面。噪声的种类也各不相同,比如椒盐噪声、高斯噪声等,针对不同的噪声有不同的处理算法。
对于输入的带有噪声的图像v(x),其加性噪声可以用一个方程式来表示:
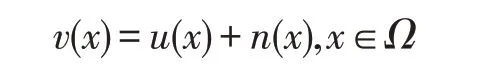
其中,x是像素;u(x)是原来没有噪声的图像;n(x)是噪声项,代表噪声带来的影响;v(x)是像素的集合,也就是整幅图像。从这个公式可以看出,噪声是直接叠加在原始图像上的,这个噪声可以是椒盐噪声、高斯噪声。理论上来说,如果能够精确地获得噪声,用输入图像减去噪声就可以恢复出原始图像。但现实往往不是很理想,除非明确地知道噪声生成的方式,否则噪声很难单独求出来。
1.1 传统去噪
根据去噪方法的特性将传统去噪方法分为了四类:(1)利用滤波去噪。汤成等人[11]提出了一种改进的曲率滤波算法,用投影算子代替传统曲率滤波的最小三角切平面投影算子,并修正正则能量函数,达到增强去噪能力,该算法有很好的强噪声去噪效果,但是不能自适应调整邻域内切平面投影算子,而且运行时间较长。张绘娟等人[12]通过设置适当的调整参数,动态选取固定阈值,增加调节因子来降低原小波系数和估计小波系数之间的恒定偏差,从而完成图像去噪。(2)利用稀疏编码去噪。李桂会等人[13]通过自适应匹配追踪算法求解稀疏系数,然后利用K 奇异值分解算法将字典训练成能够有效反映图像结构特征的自适应字典,然后将稀疏系数与自适应字典相结合来重构图像。袁小军等人[14]通过全局的相似块匹配,得到理想图像的稀疏系数估计;基于类字典和估计的稀疏系数来实现图像的去噪。(3)利用外部先验去噪。Buades 等人[15]提出了非本地图像降噪算法。常圆圆等人[16]利用奇异值分解和硬阈值方法对获得的多尺度相似矩阵进行协同来实现图像去噪。莫一过[17]将图像的结构先验和稀疏先验引入到图像复原处理中,分别提出了基于全变分和稀疏表示的两种改进算法。(4)利用低秩去噪。刘成士等人[18]利用低秩表示(low-rank representation,LRR)模型中的系数矩阵施加全变差(total variation,TV)范数约束,提出了一种全新的图像去噪方法。罗学刚等人[19]将相对全变差(relative total variation,RTV)融入加权核范数最小化(weighted nuclear norm minimization,WNNM),对WNNM 低秩表示模型施加RTV 范数约束,提出一种相对全变差加权核范数极小化(relative total variation and weighted nuclear norm minimization,RTV-WNNM)图像去噪方法,但是在图像去噪模型构建矩阵和优化求解过程中计算量较大,导致耗时较长。表1 显示了更多的传统去噪方法信息。

Table 1 Image denoising based on traditional methods表1 基于传统方法的图像去噪
在工程上,图像中的噪声常常使用高斯噪声N(μ,σ2)来近似表示,其中μ=0,σ2是噪声的方差,σ2越大,噪声越大。一个有效的去除高斯噪声的方式是图像求平均,对N幅相同的图像求平均的结果将使得高斯噪声的方差降低到原来的N分之一。算法非局部平均(non-local means,NL-Means),就是基于这一思想来进行算法设计的。在2005 年由Buades 提出,该算法使用自然图像中普遍存在的冗余信息来去噪声。与常用的双线性滤波、中值滤波等利用图像局部信息来滤波不同的是,它利用了整幅图像来进行去噪,以图像块为单位在图像中寻找相似区域,再对这些区域求平均,能够比较好地去掉图像中存在的高斯噪声。
对于传统的降噪器,通常仅使用嘈杂的图像来完成训练和降噪。许多有效的去噪算法都是以BM3D 算法作为基础提出来的。该算法的思想跟NL-Means 有点类似,也是在图像中寻找相似块的方法进行滤波,但是相对于NL-Means 要复杂得多。三维块匹配算法流程图如图1 所示。该算法主要分为两步:第一步是基础估计,把待处理图像分成固定大小的子模块,对图像中的每一块进行逐块估计,通过块与块之间的相似程度对其分组,并将这些块聚集到一个三维数组中,再对三维数组进行3D 变换,最后通过聚集对有重叠的块进行加权得到图像的基础估计。第二步是利用第一步得到的基础估计图像,对每一块进行第二次估计,再次通过块匹配找到与它相似的块在基础估计图像中的位置,匹配之后得到两个三维数组,对形成的两个三维数组进行联合维纳滤波,最后通过对重叠块的估计进行加权平均得到最终去噪图像。BM3D 算法是目前最有效的传统图像去噪算法,但是由于图像噪声复合的特殊性和复杂性,在复杂的纹理区域(大多为边缘区域)只有较少的相似块,因此达不到很好的去噪效果,导致出现细节丢失、模糊等现象。
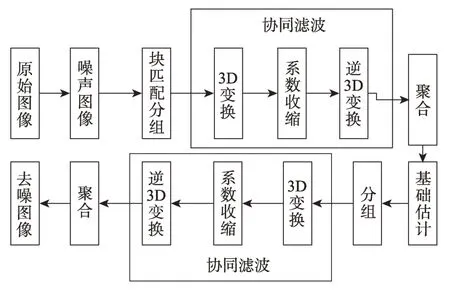
Fig.1 3D block matching algorithm flowchart图1 三维块匹配算法流程图
1.2 深度学习去噪
根据图像添加的噪声类型将深度学习去噪算法分为了四类:(1)对加性高斯白噪声图像去噪。Zhang等人[42]提出了一个将批处理归一化和残差学习技术结合的前馈去噪卷积神经网络(denoising convolutional neural networks,DnCNN)图像去噪模型,虽然这种去噪方法取得了异常突出的效果,但是整个算法需要迭代太多次才能获得一个较好的训练模型,整个算法的快速性和收敛性不够突出。Valsesia 等人[43]提出了一种基于图卷积的操作来创造了非局域的感受野,通过动态计算隐藏特征中图的相似性来得到自相似性的高效表达的图卷积神经网络(graph-convolutional image denoising,GCDN)模型,所提出的体系结构尚不能扩展到其他反问题,例如超分辨率。(2)对真实噪声图像去噪。Yan等人[44]直接从嘈杂的图像中提取噪声图,从而实现无监督的噪声建模,完成非配对真实噪声图像去噪。其网络架构为自洽生成对抗网络(selfconsistent generative adversarial networks,SCGAN)。Zhao 等人[45]提出了一种使用递归全卷积网络对黑暗突发图像进行端到端去噪,将原始的突发图像直接映射到sRGB(standard red green blue)输出,以生成最佳图像或生成多帧去噪图像序列的循环全卷积网络(recurrent fully convolutional network,RFCN)。虽然该去噪框架具有较高的灵活性,但并未将其框架扩展到视频去噪,并且该框架还没有达到可以移植的要求。(3)对盲噪声图像去噪。Yang等人[46]提出了一种使用端到端架构的多列卷积神经网络(multi-column convolutional neural network,MC-Net)从单幅图像估计噪声水平函数(noise level function,NLF)的新颖方法,但是该算法还没有实现对自然图像进行去噪。Yu 等人[47]提出了一种用于图像去噪的深度迭代向下卷积神经网络(deep iterative down-up convolutional neural network,DIDN),可以反复减少和增加特征图的分辨率,它能够使用单个模型处理各种噪声级别,而无需输入噪声信息作为解决方法。Chen 等人[48]提出的去噪方法GCBD(GAN-CNN based blind denoiser)是利用GAN 对噪声分布进行建模,并通过建立的模型生成噪声样本,与干净图像集合构成训练数据集,训练去噪网络模型来进行盲去噪。这种方法的局限性在于,假定噪声为零均值的加性噪声。(4)对混合噪声图像去噪。Zhang 等人提出的三层超分辨率网络(super-resolution network for multiple degradations,SRMD)是具有维数扩展策略的通用框架,可以处理多个甚至空间变化的降级。表2~表5 分别显示了基于深度学习的有关加性高斯噪声、实噪声、盲噪声和混合噪声图像去噪方法的更多信息。

Table 2 Additive white noise image denoising based on deep learning表2 基于深度学习的加性白噪声图像去噪
最初的深度学习技术在1980 年首次用于图像处理,并由Sullivan 等人[83]以及Zhou 等人[84]首次将深度神经网络进行图像去噪。深度神经网络具有相似或甚至比马尔可夫随机场模型在图像去噪方面更好的表示能力。Burger 等人提出使用多层感知器(multilayer perceptron,MLP)进行图像去噪。此外,他们将稀疏编码和预先训练过的深度神经网络结合起来。尽管这些深度神经网络在图像去噪方面取得了很好的性能,但这些网络并没有有效地探索图像的固有特征,因为它们只是将类似MLP 的网络级联起来。目前,经典的深度卷积神经网络DCNN 吸引了越来越多的研究人员,因为它可以通过大量数据来进行很好的自学习,不需要严格选择特征,只需要引导学习来达到期望的目的。它被广泛应用于图像预处理领域,如图像超分辨率。由于图像超分辨率的成功,一些研究人员尝试将DCNN应用于图像去噪。

Table 3 Real noise image denoising based on deep learning表3 基于深度学习的真实噪声图像去噪

Table 4 Blind noise image denoising based on deep learning表4 基于深度学习的盲噪声图像去噪

Table 5 Hybrid noise image denoising based on deep learning表5 基于深度学习的混合噪声图像去噪
前馈去噪卷积神经网络(DnCNN)用于图像的去噪,使用了更深的结构、残差学习算法、正则化和批量归一化等方法来提高图像的去噪性能。DnCNN 算法流程图如图2 所示。DnCNN 的深度架构:给定深度为D的DnCNN,由三种类型的层,展示在图2 中有三种不同的颜色。(1)Conv+ReLU:对于第一层,使用64 个大小为3×3×c的滤波器生成64 个特征图。然后将整流的线性单元ReLU 用于非线性。这里的c代表着图像通道数,即c=1 时为灰色图像,c=3 时为彩色图像。(2)Conv+BN+ReLU:对应于神经网络的2~(D-1)层,使用64 个大小3×3×64 的滤波器,并且将批量归一化加在卷积层和ReLU 之间。(3)Conv:对应于最后一层,c个大小为3×3×64 的滤波器被用于重建输出。

Fig.2 DnCNN denoising framework图2 DnCNN 去噪框架
总之,本文的DnCNN 模型有两个主要的特征:采用残差学习公式来学习,并结合批量归一化来加速训练。通过将卷积和ReLU 结合,DnCNN 可以通过隐藏层逐渐将图像结构与噪声分开。这种机制类似于EPLL(expected patch log likelihood)和WNNM等方法中采用的迭代噪声消除策略,但本文的DnCNN是以端到端的方式来进行训练的。
2 数据集
2.1 训练数据集
训练数据集[85]分为两类:灰度噪声图像和彩色噪声图像。灰度噪声图像数据集可用于训练高斯去噪器和盲去噪器。它们包括BSD400 数据集和Waterloo Exploration 数据集。BSD400 数据集由.png 格式的400 张图像组成,并裁剪为180×180 的尺寸以训练降噪模型。Waterloo Exploration 数据集包含4 744 个.png格式的自然图像。彩色噪声图像包括BSD432 数据集、Waterloo Exploration 数据集和polyU 数据集。具体来说,polyU 数据集由100 个真实的嘈杂图像组成,由5 个相机获得的尺寸为2 784×1 856 大小的图像,相机类型包括尼康D800、佳能5D Mark II、索尼A7 II、佳能80D 和佳能600D。
2.2 测试数据集
测试数据集[85]包括灰度和彩色噪声的图像数据集。
灰度噪声图像数据集由Set12 数据集和BSD68数据集组成。Set12 包含12 个场景图像。BSD68 包含68 张自然图像。它们用于测试高斯降噪器和盲噪声降噪器。
彩色图像数据集包括CBSD68 数据集、Kodak24数据集、McMaster 数据集、CC 数据集、DND 数据集、NC12 数据集、SIDD 数据集和Nam 数据集。Kodak24数据集和McMaster 数据集分别包含24 和18 个彩色噪点图像。cc 数据集包含15 个不同ISO 的真实噪点图像,即1 600、3 200 和6 400。DND 包含50 个真实噪点图像,干净图像由低ISO 图像捕获。NC12 包含12 个噪点图像,没有真实的干净图像。SIDD 包含来自智能手机的真实噪声图像,并且由320 对噪声图像和真实图像组成。Nam 包含11 个场景,这些场景以JPGE 格式保存。
3 实验结果
为了比较传统去噪方法及深度神经网络去噪方法的去噪性能,在Set12、BSD68、CBSD68、Kodak24、McMaster、DND、SIDD、polyU 和CC 上进行了定量和定性评估实验。定量评估主要是使用不同去噪器的峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性(structural similarity,SSIM)的值来测试去噪效果,定性评估是使用视觉图形来显示恢复的干净图像。
对于灰度高斯白噪声图像去噪,将传统去噪方法与深度学习去噪方法进行了比较,其中包括三种传统的去噪模型方法(即BM3D、WNNM 和EPLL),16 种基于深度学习的去噪方法,可以分为两类:分别针对每种噪声水平学习单个模型即DnCNN、NLRN(non-local recurrent network)、RNAN(residual nonlocal attention networks)、FOCNet(fractional optimal control network)、DRUNet(dense residual and combines U-Net)等和基于CNN 的方法经过培训可处理各种噪声水平即IRCNN(CNN denoiser prior for image restoration)和FFDNet(fast and flexible denoising convolutional neural network)等。NLRN 和RNAN 在网络体系结构设计中采用非本地模块,以便事先利用非本地映像。表6 显示出了在噪声水平为15、25 和50 的Set12 数据集上不同方法的平均PSNR 结果。加粗表示最优结果,下划线表示次优结果。可以看出DRUNet 达到了最佳PSNR 结果。在噪声水平为15、25 和50 的Set12 数据集上与传统去噪(即BM3D)相比,DRUNet 的平均PSNR 增益约为0.9 dB,其他的深度学习去噪方法相比于传统去噪方法也有很好的去噪性能,从中展现出了深度学习技术的优势。Set12数据集的平均PSNR 增益超过DnCNN、IRCNN 和FFDNet 约为0.5 dB。尽管NLRN、RNAN 和FOCNet针对每种噪声水平都学习了一个单独的模型,并且具有非常好的竞争性能,但它们无法胜过DRUNet。图3 显示了噪声水平为25 的Set12 数据集上不同方法对“House”图像的灰度白噪声图像去噪结果。其中去噪算法(c)~(e)是在Windows 10系统中的Matlab-R2019a 环境下完成,去噪方法(f)~(j)是在Windows 10 系统中的python3.6 搭载PyTorch 1.1.0 环境下完成的。从图3 中可以看出,DRUNet 比BM3D、IRCNN、FFDNet 还原的图像边缘更加锐利。DRUNet 仅去除了高斯白噪声,相比于BRDNet(batch-renormalization denoising network)保留了更多的细节,视觉去噪效果要优于BRDNet还原的噪声图像。
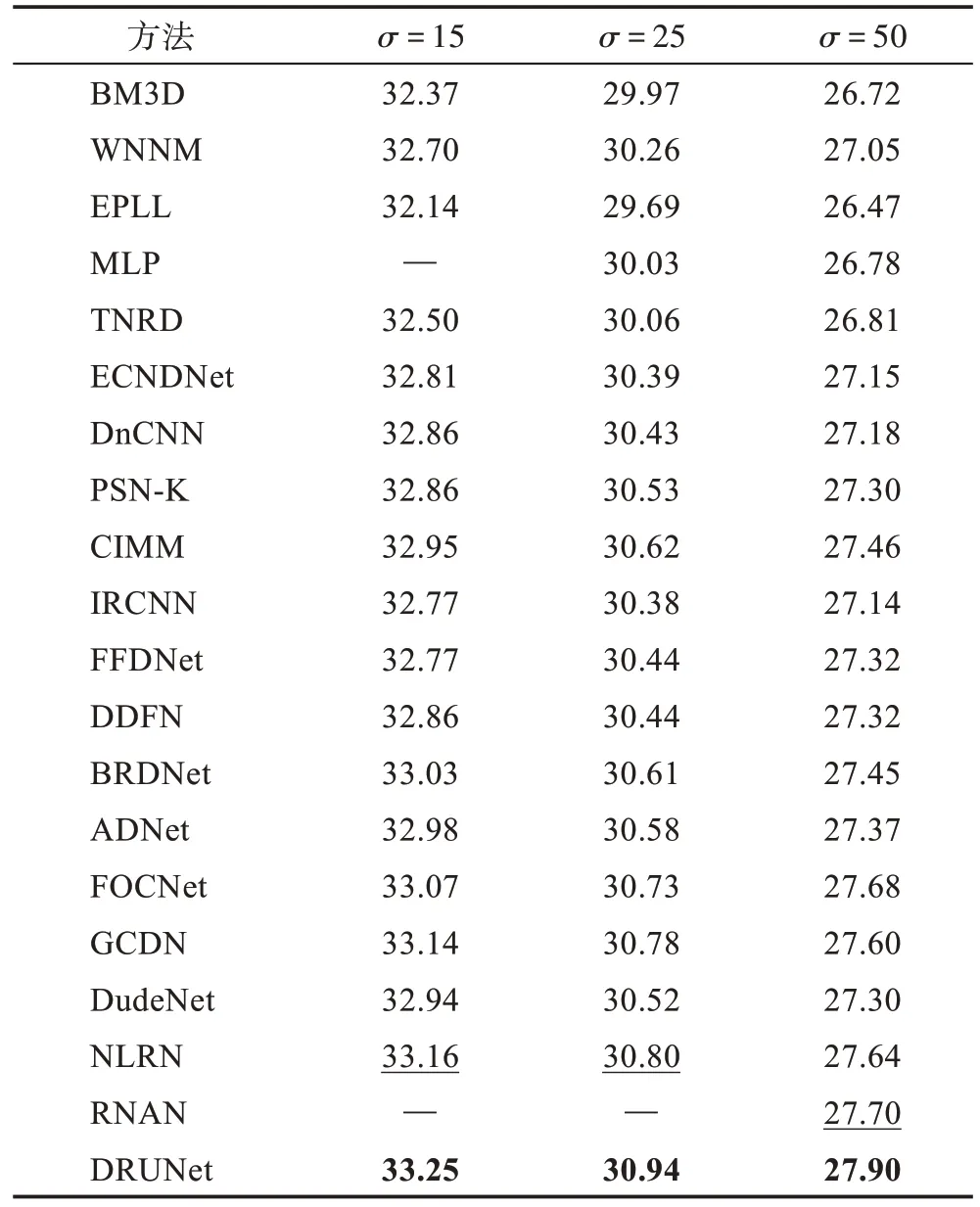
Table 6 Average PSNR of different methods on Set12 data set表6 Set12 数据集上不同方法的平均PSNR dB
由于现有方法主要关注灰度图像去噪,仅选用了几种去噪方法来对比分析。其中包括一种传统去噪(CBM3D)模型和六种深度学习方法来对彩色图像进行去噪。表7 显示了在CBSD68、Kodak24 和Mc-Master 彩色数据集上针对噪声水平15、25 和50 的不同方法的彩色图像去噪结果。加粗表示最优结果,下划线表示次优结果。与传统去噪(即CBM3D)相比,在CBSD68 数据集上DRUNet 的平均PSNR 增益约为0.8 dB,在Kodak24 和McMaster 数据集上的平均PSNR 增益更是高达1.5 dB 左右。相比DnCNN、IRCNN 和FFDNet 深度学习算法,DRUNet 的增益也有约0.5 dB 的增益,尽管ADNet(attention-guided CNN for image denoising)和BRDNet 对比前几种算法有了一定的提升,但是与DRUNet 相比还是有很大的不足,可以看出DRUNet 在三个彩色数据集上都表现出了较大的优势。图4 显示了来自噪声水平为50 的CBSD68 数据集的图像“296059”和McMaster 数据集的图像“15”上几种方法的视觉结果。其中CBM3D去噪算法在Windows 10 系统中的MatlabR2019a环境dB下运行,去噪算法(c)~(f)是在Windows 10 系统中的python3.6 搭载PyTorch 1.1.0 版本下完成的。从图4中可以看出,DRUNet 相比于其他方法可以恢复更多的细节和纹理。

Fig.3 Gray-scale image denoising results of different methods on“House”图3“House”上不同方法的灰度图像去噪结果
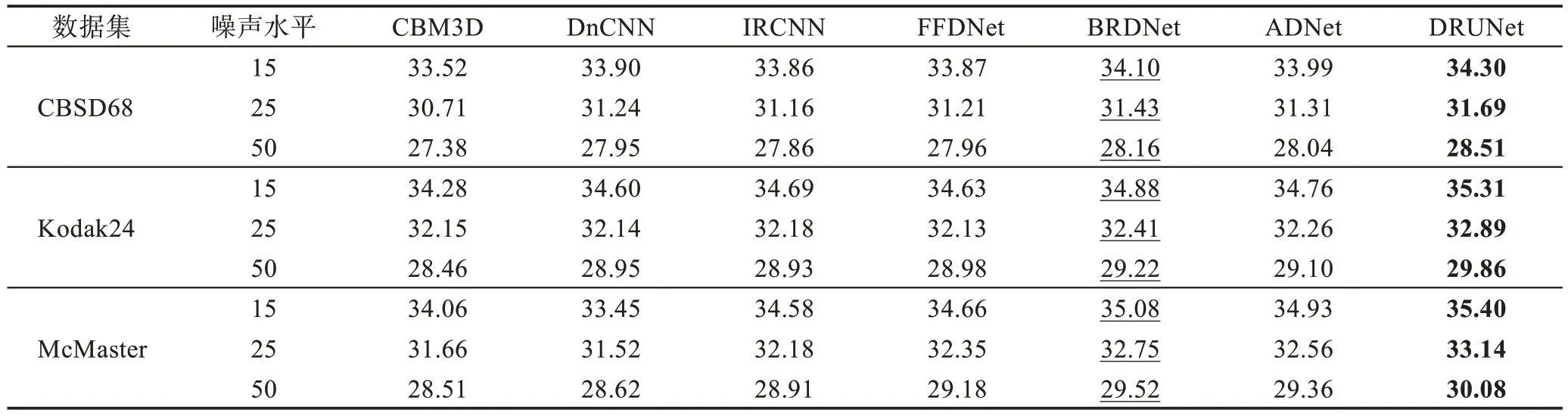
Table 7 Average PSNR of different methods on color data set表7 彩色数据集上不同方法的平均PSNR

Fig.4 Color image denoising results with different methods图4 彩色图像用不同方法的去噪结果
为了测试用于实噪声图像的深度学习技术的去噪性能,本文选择了DND、SIDD、PolyU 和CC 等公共数据集来设计实验。本文选择不使用NC12 数据集,是因为无法获得来自NC12 的真实的干净图像。将4种传统的降噪方法和16 种深度神经网络去噪方法进行比较。表8 显示了在DND 数据集和SIDD 数据集上不同去噪方法的PSNR(dB)和SSIM 值,加粗表示最优结果,下划线表示次优结果。从表中可以看出深度学习去噪算法在DND 数据集和SIDD 数据集上要比传统去噪算法有很大的优势,在SIDD 数据集上GMSNet(grouped multi-scale network)去噪算法比传统去噪(EPLL、BM3D、WNNM 和KSVD)的平均PSNR 增益最大更是达到14 dB 左右,相似度也高出了0.14 左右。在DND 数据集上GMSNet 系列也比传统的去噪方法高出了约5 dB,在两个数据集上与最近的深度学习算法相比GMSNet 系列算法同样也具有很大的优势。在DND 数据集和SIDD 数据集上的测试充分展现出了深度神经网络在图像去噪领域要比传统去噪方法有更好的去噪性能。值得注意的是,尽管MIRNet 在SIDD 数据集上表现出色,但在DND 数据集上表现不佳。这种差异突出了减少训练和图像降噪测试之间的图像域差距的重要性。表9显示了在CC15、CC60 及PolyU 数据集上不同去噪方法的PSNR(dB)和SSIM 值,加粗表示最优结果,下划线表示次优结果。可以看出传统去噪方法CBM3D、MCWNNM(multi-channel weighted nuclear norm minimization)和NLH(non-local Haar)在三个数据集上相比于深度神经网络算法DNCNN、FFDNet 和MIRNet展现出了非常有竞争力的性能,而深度神经网络方法并不总是展示出优于传统去噪器的优势,这在很大程度上是由于缺乏训练数据。
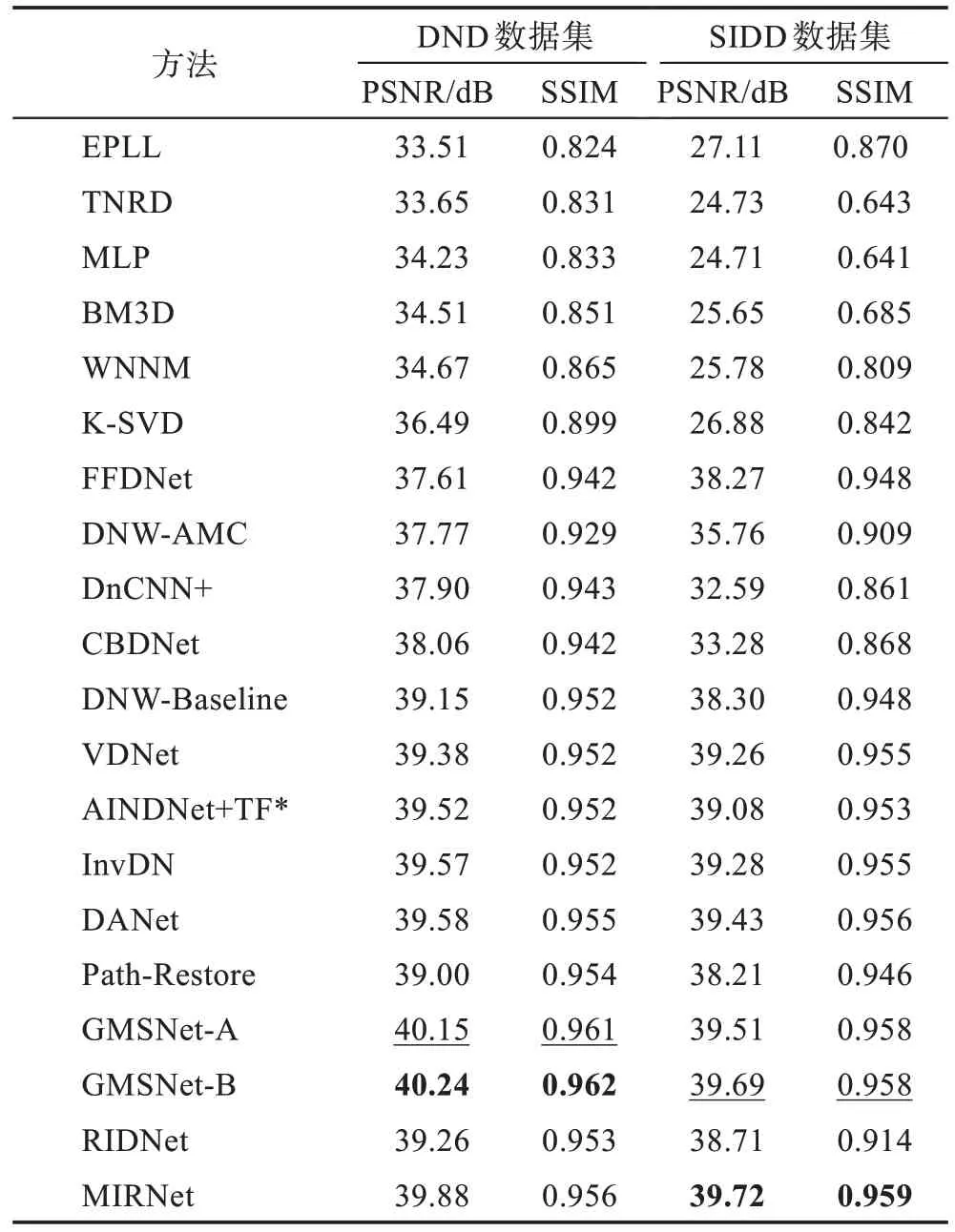
Table 8 PSNR and SSIM of different methods on two data sets表8 两个数据集上不同方法的PSNR、SSIM
众所周知,噪声在现实世界中是复杂的,并且不受制于规则。这就是为什么开发盲降噪技术,尤其是深度学习技术。比较不同深度学习技术的降噪性能是非常有用的。选择了在BSD68 数据集上用最新的去噪方法例如DnCNN、FFDNet、ADNet、SCNN(shrinkage convolutional neural network)和DudeNet(dual denoising Network)来设计实验。如表10 所示,显示了BSD68 数据集在不同噪声水平下每种图像去噪方法的PSNR(dB)值,加粗表示最优结果,下划线表示次优结果,可以看出DudeNet的PSNR优于SCNN约0.3 dB,ADNet 在SCNN 上的增益约为0.2 dB,而FFDNet 也有与DnCNN 不弱的去噪性能。FFDNet、ADNet 和DudeNet 在盲去噪方面有不弱于其他去噪方法的性能。
用于混合噪声图像降噪的深度学习技术在现实世界中,损坏的图像可能包含不同种类的噪声,这使得恢复潜在的干净图像非常困难。为了解决这个问题,已提出了基于深度学习技术的多退化思想。在这里,本文介绍了多退化模型的降噪性能。如表11所示,显示了在Set5、Set14、BSD100 和Urban100 数据集上不同方法在Bicubic 降采样退化下的PSNR 和SSIM 结果比较。加粗表示最优结果,下划线表示次优结果。SRMDNF 大大超过了SRCNN,相比DRRN(deep recursive residual network)和DnCNN-3 也 有0.1~0.4 dB 的增益。SRMDNF 无论是在小比例因子上还是在大比例因子上都取得了最佳的结果。

Table 10 Average PSNR of different methods on BSD68 data set表10 BSD68 数据集上不同方法的平均PSNR dB

Table 11 PSNR and SSIM under Bicubic downsampling degradation表11 Bicubic降采样退化下的PSNR、SSIM
4 结束语
近年来,图像去噪已成为具有潜在重要应用的有吸引力的研究课题。BM3D 方法的巨大成功极大地推动了许多相关降噪方法的出现,从传统的高斯去噪器到深度神经网络方法不等。本文比较、研究和总结了用于图像去噪的传统方法以及深层神经网络。首先,本文展示了用于图像降噪的经典的传统去噪的基本框架。然后,展示了用于图像降噪的深度学习的基本框架并且介绍了用于有噪声图像降噪的深度学习技术,包括加性白噪声、盲噪声、真实噪声和混合噪声图像降噪。接着比较了基准数据集上不同网络的去噪结果。尽管深度学习技术在图像去噪领域已经取得了巨大的成功,但最新的方法仍然存在一些局限性,将它们的应用限制在关键的实际场景中。最近,一种新趋势集中在如何共同处理图像去噪和其他计算机视觉任务[86]上,例如去雾[87]、去马赛克[88]、超分辨率[89]和分类。收集真实的基准数据集来进一步探索它们之间的相互影响是一件非常有趣的事情。
