融合知识图谱和深度学习方法的问诊推荐系统
2021-08-07武家伟孙艳春
武家伟,孙艳春,3+
1.北京大学 信息科学技术学院,北京 100871
2.北京大学 高可信软件技术教育部重点实验室,北京 100871
3.北京大学(天津滨海)新一代信息技术研究院,天津 300450
随着互联网的发展,近几年,出现了很多互联网医疗服务,例如腾讯医疗、寻医问药、好大夫等。它们掌握着庞大的疾病、医院等结构化信息,但提供给用户的服务非常有限。多数服务网站仅仅提供检索和在线咨询医生等功能,少数网站提供简单的疾病自诊服务,但多数仅允许用户输入一个症状关键词,给出的疾病列表冗长,使用并不方便,缺乏医生医院的智能推荐服务。而在日常生活中,人们经常需要根据症状确定自己可能患有的疾病,并需要寻找对这类疾病诊治效果出色的医院及相应医生,上述的互联网医疗服务无法满足这样的需求。
为此,本文提出了一种基于知识图谱、深度学习和社交媒体构建问诊推荐系统的设计与实现方法。以寻医问药网站结构化的疾病信息构建“疾病-症状”知识图谱,从多个方面的信息出发为用户提供疾病自诊服务,同时利用知识图谱的结构化信息挖掘用户可能患有的潜在疾病,丰富推荐选项。以好大夫网站的评论数据为样本,结合现有的服务质量评价指标分析北京各家医院医生的服务质量,从多个维度为用户提供医生医院推荐服务。
本文的主要贡献包括以下几个方面:
(1)设计实现了一种基于知识图谱的疾病诊断算法,查询知识图谱获取初始疾病推荐备选集,基于知识图谱嵌入模型,利用知识图谱结构化信息丰富疾病备选集,使之更为容易推荐出用户可能潜在的疾病,提高推荐准确率。
(2)根据患者评论等社交媒体数据,创新性地结合现有的医疗服务质量评价指标以及深度学习方法,给出了医生医院的评分模型,为用户提供医生推荐服务。
1 相关工作
1.1 疾病诊断算法
传统的疾病诊断包括基于代数运算和基于推荐系统两类方法。目前普遍认为医疗诊断存在着大量不完整、不确定和不一致的信息,因此,许多学者选择采用FS(fuzzy set)和NS(neutrosophic set)去建模症状和疾病之间的关联,并将患者症状的FS 或NS 与不同疾病之间进行相似度比较确诊用户患有的疾病。例如,De 等人将FS 引入疾病诊断任务中[1],Ye 等人则是基于单值NS,使用多种相似度计算方法完成疾病诊断任务[2-4]。基于推荐系统的思路,Davis 等人根据用户的诊断记录以及患者画像预测患者未来患某疾病的概率[5],Ali 等人则是将NS 与推荐系统结合起来,构建NRS(neutrosophic recommender system)完成疾病诊断任务[6-7]。
随着机器学习的流行,越来越多的学者尝试使用机器学习技术完成疾病诊断任务。Raval等人基于患者症状关键词以及化验数据,使用反向传播算法训练单层神经网络,完成疾病诊断任务[8]。除此之外,还有一些学者根据医学图像来为患者确定可能患有的疾病,例如Acharya 等人基于心电图,使用卷积神经网络(convolutional neural networks,CNN)识别心肌梗塞的发生[9],Esteva 等人同样使用CNN 完成了皮肤癌的分类工作[10],更多类似的工作可以参考文献[11]。
综合分析,基于FS 和NS 的疾病诊断算法需要对病症进行细致的建模,与用户输入的自然语言文本差距较大,并不便于用户使用。基于推荐系统的方法则需要大量用户的历史诊疗数据,涉及到用户隐私。而且,上面两种方法都未考虑年龄、性别等对疾病诊断的影响。在现有的可以借鉴的以机器学习为基础的工作中,多数都使用了医院的化验数据等,在本文用户自诊的应用情境中,这样的方法参考意义并不明显。
1.2 医疗知识图谱
知识图谱是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系。其基本组成单位是“实体-关系-实体”三元组,以及实体及其相关属性-值对,实体间通过关系相互联结,构成网状的知识结构[12]。医疗知识图谱作为知识图谱的子集,针对其构建方法以及应用场景,学术界已经开展了许多研究工作。
国内外知名的医疗知识图谱包括DrugBank(https://www.drugbank.ca/)、SNOMEDCT(systematized nomenclature of medicine-clinical term)(http://www.snomed.org/)、CMeKG(Chinese medical knowledge graph)(http://zstp.pcl.ac.cn:8002/)等。在学术研究领域,学者基于EHR(electronic health records)构建了多种用途的知识图谱。Rotmensch 等人通过贝叶斯网络从EHR 中抽取医学概念,获得实体和关系,构建了“疾病-症状”的知识图谱[13]。Wang 等人提出了一种SMR(safe medicine recommendation)的框架,根据EHR,并融合ICD-9 ontology 和DrugBank 等其他数据来源构建“病人-疾病-药物”的知识图谱,并训练知识图谱嵌入,使用其连接预测任务完成药物推荐[14]。Li 等人则是给出了从EHR 中构建知识图谱的八个经典步骤,指出他们构建的知识图谱可以用于医疗诊断辅助系统、医疗信息检索和知识迁移等场景[15]。同样,也有学者对医疗知识图谱的构建进行了综述性的研究。侯梦薇等人就医学知识表示、医学知识抽取和医学知识融合等核心技术方面对当下各种模型做了介绍和评判,同时他们也对当下医疗知识图谱的应用场景做了归纳:临床决策支持系统、医疗语义搜索引擎、医疗问答系统等[16]。
综合分析,特定的医疗服务需求通常需要构建特定的医疗知识图谱。目前,通过EHR 数据构建知识图谱的技术已经相当成熟,这些方法普遍需要从半结构化文本中抽取医学概念,过程涉及机器学习等自然语言处理手段,较为复杂。然而,对于本文疾病诊断的功能需求,构建“疾病-症状”知识图谱即可,使用互联网上大量已有的可靠来源的结构化疾病信息,可以极大降低构建知识图谱的复杂性。
1.3 医疗评论相关分析技术
情感分析(sentiment analysis)是对人们关于商品、服务、组织、人、事件及其属性等的观点、情感和情绪等主观性信息的提取和分析[17]。医疗评论的情感分析大致可以分为两类:情感极性分析和情感属性提取。
对于情感极性分析,Qiu 和Biyani 等人对CSN(cancer survivors' network)的评论构建学习模型,对文本情感极性进行二分类,以此建模用户情感状态变化,辅助社区更好地提供服务[18-19]。Salas-Zárate 等人结合糖尿病医学模型知识,使用N-gram 对于糖尿病相关的推特进行了情感极性分类[20]。对于情感属性提取,Hao 等人基于好大夫医疗网站2006—2014 年的评论数据,构建了隐狄利克雷分配(latent Dirichlet allocation,LDA)模型,抽取出来了疗效、寻医过程等主题模型,并进行了简单的情感分析[21]。
综合分析,医疗评论的情感分析技术并不先进,没有使用当下热门的深度学习模型,且多数工作停留在分析情感本身,没有从情感信息中进一步挖掘可用信息,如服务满意度等。本文将会结合医疗服务评价指标,对情感信息进一步挖掘,构建医生医院服务质量评价模型,用于推荐服务。
2 问诊推荐系统的设计与实现
本文构建的问诊推荐系统的架构图如图1 所示。该推荐系统接受用户输入的症状信息,包括症状关键词(必需)、症状描述、年龄和性别等,最终推荐的结果包括最有可能的三种疾病和相应推荐就医的医院及医生。推荐系统主要包括两个服务:疾病诊断服务和医生推荐服务。推荐步骤总共包括四步,分别为构建疾病备选集、扩展疾病备选集、筛选排序和医生医院推荐等。下面将会依次讲解问诊推荐系统的实现。
2.1 构建知识图谱
本文选择寻医问药网站的数据为来源构建知识图谱。寻医问药网站是一家互联网医疗健康服务平台,作为该行业的先驱品牌,成立数十年来多次获奖,在互联网医疗中具有广泛影响力(http://www.xywy.com/about/index.html)。本文使用了寻医问药网站上公开的8 802 种疾病信息(截止到2020 年2月),包含的内容主要有疾病症状描述、疾病症状关键词、疾病易患人群、疾病发病率、疾病科室、疾病的并发症等信息。
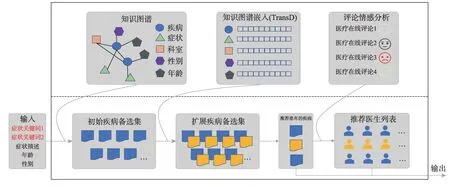
Fig.1 Framework of recommendation system for medical consultation图1 问诊推荐系统框架图
由于寻医问药网站的信息多为结构化的,本文进行了简单的预处理,主要从易患人群进一步抽取易患人员性别和易患人员年龄等信息。其中年龄根据360 百科新年龄分段(https://baike.so.com/doc/7018130-7241025.html#7018130-7241025-1)信息,并稍做修改,分为胎儿、婴幼儿、少儿、青少年、青年、中年和老年等7 个年龄分段。结合本文的功能需求,本文最终设计的知识图谱结构如表1 和表2 所示。

Table 1 Entities of knowledge graph表1 知识图谱实体

Table 2 Relations of knowledge graph表2 知识图谱关系
本文使用Neo4j(https://neo4j.com/x)图数据库存储知识图谱。构建完毕后,知识图谱一共包含实体15 418 个,关系85 303 个。
2.2 医疗评论分析
本文选择好大夫网站评论作为数据来源。好大夫网站是一个互联网医疗平台,成立于2006 年,业务发展广泛,在医院/医生信息查询、图文问诊、电话问诊、门诊预约等领域取得显著成果,受到了医生、患者的广泛认可(https://www.haodf.com/info/aboutus.php)。本文使用了好大夫网站2018 年和2019 年的公开数据,包括各大医院在线医生的评论数据共133 667 条。
本文对好大夫网站的评论数据进行了预处理,删除无效的中英文字符,使用Python 第三方开源库zhconv(https://github.com/gumblex/zhconv)对评论文本进行繁简体转换,同时为了修正评论文本口语化表达中的一些常见错误,本文使用Python 第三方开源库pycorrector(https://github.com/shibing624/pycorrector)对评论文本进行语言纠错。
为了从评论数据获得医院服务质量的评估,本文从SERVQUAL 模型出发标注评论数据。SERVQUAL模型由Berry 等人于1988 年提出,用于衡量服务质量,包含5 个维度,分别为Tangibles(用于衡量服务提供商环境设施及服务人员外表等方面的表现)、Reliability(用于衡量服务提供商兑现承诺的能力)、Responsiveness(用于衡量服务提供商帮助顾客迅速提高服务的愿望)、Assurance(用于衡量服务人员的知识、礼节以及表达出自信和可信能力)、Empathy(用于衡量服务提供商关心并为顾客提高个性化服务的愿望和能力)[22]。随后,Babakus 和Mangold 对SERVQUAL 的每个维度进行了一些修改,并将其应用到医院医疗服务的评价,验证了SERVQUAL 评价医疗服务质量的合理性[23]。
本文对SERVQUAL 模型也进行了微调,给出了评论标注的原则。由于好大夫网站数据鲜有涉及到评价医院硬件设施以及医护人员着装等的评论,因此舍弃Tangibles 评价维度。另外,在医疗评论数据中,关于Responsiveness 和Empathy 的评价内容过于相近,因此本文将两者合并为一个评价维度,记为R&E。Reliability 对应于评论中对于疗效的描述,常见的表述有“病情有所好转”“病情反而加重了”等;R&E 对应于评论中关于医生诊疗态度的描述,常见的表述有“医生非常耐心,和蔼可亲”“医生非常不耐烦”等;Assurance 对应于评论中患者对医生治疗水平的整体评价,常见的表述有“医术高超”“水平一般”等。每个维度标注的情感极性有三种:积极、中性和消极,标注评论共6 019 条。
本文使用BERT(bidirectional encoder representations from transformers)[24]模型进行患者评论分析,BERT 模型由Google 于2018 年提出,相比于已有的预训练语言模型如ELMo(embeddings from languages models)[25]等模型,BERT 创新之处在于双向Transformer 模型的使用。BERT 由Google 在33 亿词的语料上,使用16 个TPU(tensor processing unit)集群,以Masked LM 和Next Sentence Prediction 作为训练任务得到,代价昂贵,但是同时它的表现也非常亮眼,一经提出便刷新了GLUE(general language understanding evaluation)中11 个自然语言处理任务中的最佳成绩。本文加载官方中文预训练模型chinese_L-12_H-768_A-12(https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip),并在下游根据任务进行微调设计BERT 模型。按照9∶1 比例划分标注评论数据集为训练集和验证集,最终在验证集上的表现如表3~表5 所示。
根据3 个维度的混淆矩阵,得到BERT 模型在3个维度的精确率分别为78.4%、88.1%、93.4%;召回率分别为86.7%、87.5%、97.2%。由于第三维度缺少真实的消极评论数据,它的结果偏离统计规律,因此最终精确率和召回率计算消除了该部分的影响,效果良好。本文基于医疗服务质量评价指标,使用深度学习模型分析评论的情感极性,后文将会基于此结果给出医生、医院的综合评分。
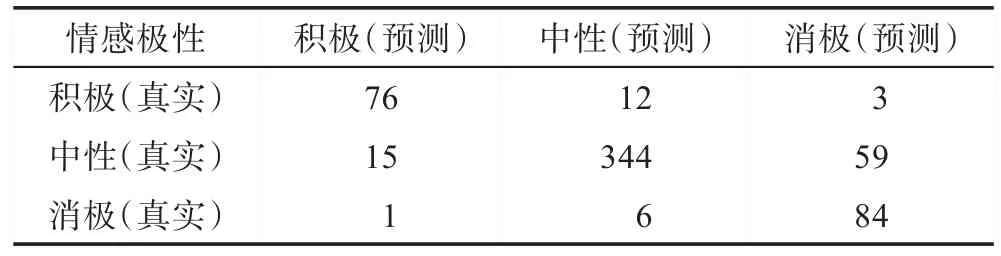
Table 3 Validation performance on reliability dimension表3 Reliability 维度验证结果
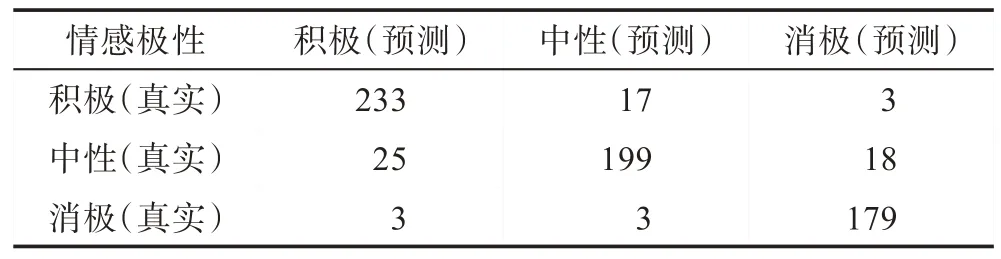
Table 4 Validation performance on R&E dimension表4 R&E 维度验证结果
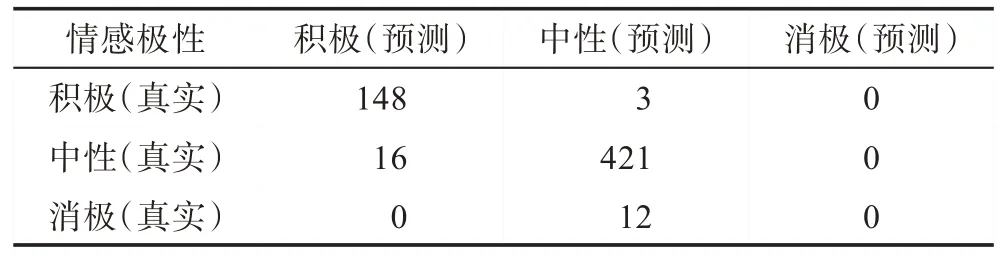
Table 5 Validation performance on Assurance dimension表5 Assurance维度验证结果
2.3 疾病诊断服务
2.3.1 构建疾病备选集
该部分主要根据用户输入的关键词信息,匹配知识图谱中的疾病,并按照疾病发病率和关键词匹配程度对可能的疾病进行排序,关键词匹配程度在排序中拥有更高的优先级,筛选出前15 个疾病作为备选集。
2.3.2 扩展疾病备选集
为了提高疾病诊断的准确性,本文选择以TransD[26]模型训练知识图谱嵌入,该模型在TransE[27]、TransH[28]和TransR[29]等模型上发展而来。TransE 模型由Bordes 等人提出,主要理论基础是词向量平移不变性。TransE 模型认为关系向量r是头实体向量h到尾实体向量t的平移,即:

其中,h表示头实体向量,r表示关系向量,t表示尾实体向量。该模型假设同一实体在任何关系下的表示都是一样的,因此TransE 模型在处理一对一关系时表现良好,然而针对一对多、多对多等复杂关系时稍显乏力。为此,TransH 模型被提出,它认为头实体向量和尾实体向量需要在关系向量的超平面上做投影,即:
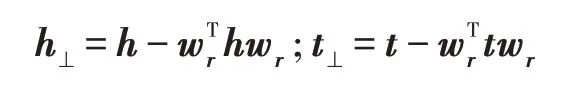
然后成立:
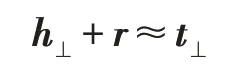
其中,wr表示关系向量r的超平面的法向量。TransH模型的弊端在于它仍然假设实体和关系处于相同的语义空间,这限制了它的表达能力。而TransR 模型在此基础上,更进一步使用投影矩阵(Mr)完成了投影操作,即:
但是对于同一关系,TransR 模型给出的投影矩阵是完全相同的,并没有考虑到头尾实体之间的差异性,且其投影操作涉及到矩阵计算,训练复杂度大大提高。
而TransD 模型认为投影是实体与关系之间的交互,并不仅仅只与关系有关,并且TransD 的计算复杂度相对于TransR 有所降低。它给出的投影矩阵及h⊥和t⊥计算如下:
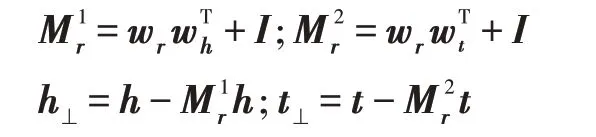
本文使用OpenKE[30]实现TransD 模型,从全局的图谱结构信息给出关系和实体的向量表示,并根据欧式距离的相近,给出与备选集中每种疾病最相似的疾病,加入备选集。此举意在挖掘用户可能患有的潜在疾病,丰富推荐选项,提高疾病诊断的准确率。
2.3.3 筛选排序
该部分根据用户i输入的4 个维度对备选集中的疾病打分并排序,选择最高的3 种疾病推荐给用户。对于某个疾病j,其评分公式为:

其中,Sage、Ssex、Skey、Sdes分别表示疾病j在易患人群年龄、易患人群性别、症状关键词和疾病描述等方面与用户i输入的相似度。其中年龄和性别相似度的判断都是基于简单的字符串匹配。Skey的计算公式如下:

其中,Keyi、Keyj分别表示用户i输入的症状关键词集合和疾病j拥有的症状关键词集合。
Sdes的计算方法为将疾病备选集的描述作为文本集合D,并对其进行分词处理,去除中文停用词,中文停用词表参考百度公司提供的停用词表(https://github.com/goto456/stopwords/blob/master/baidu_stopwords.txt)。设最终得到的词汇集合为{t1,t2,…,tn},然后针对文本集合中的每个文本按照TF-IDF(term frequencyinverse document frequency)算法计算所有词语的TFIDF 值,得到TF-IDF 矩阵:
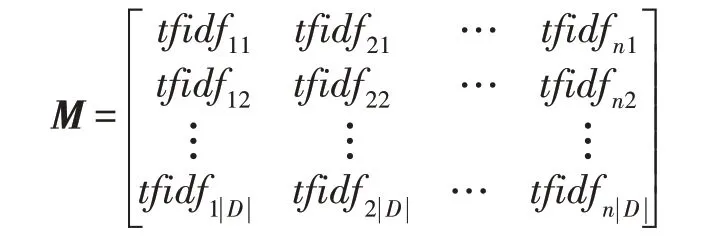
其中,tfidfij表示词语ti在文本Dj中的TF-IDF 取值。最后对用户输入的疾病症状描述也通过相似的方法计算其TF-IDF 向量,随后与矩阵M中的行向量按照余弦相似度计算方法得到备选集中每个疾病的Sdes。
2.4 医生推荐服务
在前面的章节中,本文已经使用BERT 模型对评论进行了情感极性分析工作,得到了所有医生评论中3 个维度的好评数量、差评数量和中性评价数量。本文基于威尔逊区间法给出医生乃至相应科室的评分,威尔逊计算公式如下(https://en.wikipedia.org/wiki/Binomial_proportion_confidence_interval):

其中,p表示好评率,n表示评论总数,zα为分位数,用于表述该分数的置信度。威尔逊区间法具有良好的区分度,同时也具有如下性质:
(1)得分归一化;
(2)当p不变时,n越大,分子减小速度小于分母减小速度,得分越高,当n趋近于无穷大时,得分趋近于p。换言之,该评分方式在总评论数量高时会认为好评率可靠,而在总评论数量较少时认为好评率不可靠,这符合认知。
在实际应用的过程中,本文选择zα为2(即置信度约为95%),并对威尔逊区间法做了一点改动。威尔逊区间法适用的前提是仅存在正面和负面两种评论,但是本文实际应用场景中有中性评论。因此,在计算好评率的时候,本文将一半的中性评论当作正面评论,另外一半归为负面评论。
在获得医生和医院科室的评分信息之后,根据2.3.3 小节得到的疾病信息,选择相应的科室,推荐4个最好的医院,每家医院推荐4 位最好的医生。本文还加入了一些经验规则:优先推荐在好大夫网站统计中相应科室在全国名列前茅的医院以及优先推荐类别更高的医院,如三甲医院等。
3 验证
3.1 疾病诊断算法的验证
本文从年龄、性别、关键词和症状描述4 个角度出发,综合给出可能患有的疾病。同时,本文利用知识图谱的结构信息给出用户可能潜在患有的疾病,丰富了推荐选项。而目前的工业界以及学术界没有类似的工作出现,于是,本文采取构建测试集的做法进行疾病诊断算法的准确性验证。
本文从寻医问药网站选择各个科室常见的50 种疾病,例如感冒、鼻炎、中耳炎等,然后结合百度百科网站上的疾病症状信息,使用自然语言重新组织,作为假想用户症状描述输入,结合寻医问药网站关键词信息,构建用户测试用例。此为测试集T1。测试集T2是在测试集T1中每条疾病增加一定量并发症的关键词信息作为混淆得到,并发症信息从寻医问药网站获取。
在测试集上,算法运行的结果如表6 所示。可以看到,在加入并发症信息后,算法的准确度有了较大的下滑。一方面是因为额外信息的干扰,另一方面,某些疾病由于其本身症状关键词不多,加入并发症关键词后导致混淆效果放大。此外,由于百度百科与寻医问药网站疾病信息来源并不相同,两者对于同一疾病的描述不尽相同。例如疾病唇炎,百度百科上给出了多种分类,如肉芽肿性唇炎、光化性唇炎等,而寻医问药网站,对于唇炎仅仅给出了一般的症状描述,这也是导致准确率不够理想的一个原因。尽管算法在有些样例中并不能准确地诊断出患者患有的疾病,但是给出的推荐结果中包含了与之相似的疾病或者相同科室的疾病,这样的结果可以接受。
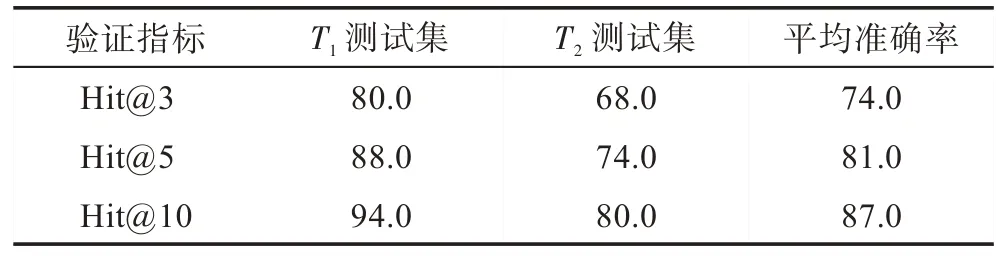
Table 6 Accuracy of disease diagnosis algorithm表6 疾病诊断算法验证准确率 %
3.2 医生推荐算法的验证
该部分的验证采取问卷调查的方式。问卷主要面向北京大学学生,问卷选择了3 种在学生群体比较常见的疾病呼吸道感染、荨麻疹和鼻炎。每种疾病设置了相同的问题,询问对象是否患有过该疾病,是否在北京地区治疗过该疾病以及对本文推荐系统给出的医生和医院推荐的认可度。最终回收问卷57份,验证结果如表7 所示。

Table 7 Result of questionnaire表7 问卷调查结果
在所有患过该疾病并在北京地区就诊过的调查对象中,鼻炎部分仅有1 例医生推荐错误,荨麻疹部分仅有2 例医院推荐错误和3 例医生推荐错误,呼吸道感染部分仅有1 例医院推荐错误和1 例医生推荐错误。综合问卷结果,本文提出的问诊推荐系统对医院推荐的准确度为93.57%,对医生推荐准确度为90.91%,效果良好。
4 结束语
本文设计实现了一种医疗问诊推荐系统,构建“疾病-症状”知识图谱为用户提供疾病自诊服务,同时利用社交媒体的评论数据,结合质量服务评价指标,使用深度学习模型给出医院医生的服务质量评价模型,为用户提供更好的推荐服务。
相比于已有的互联网医疗服务,本文构建的系统允许用户输入性别等多方面的信息,综合给出合理的疾病推荐。同时,本文利用了知识图谱的结构化信息,可以挖掘用户可能患有的潜在疾病,丰富推荐选项。本文还创新性地将医疗评论和医疗服务质量挂钩,为用户提供更加开放合理的推荐服务。
本文的工作仍有许多可以改进的地方:(1)本文构建的知识图谱比较简单,没有对病人群体进行更多特征的刻画,例如既往病史、吸烟史等,未来可以考虑将知识图谱扩充为“病人-疾病-症状”的模式。(2)本文对医疗服务质量的评估并未涉及到医院技术水平等信息,而这本身也是SERVQUAL 模型的一个缺陷。早在1990 年,Bopp 便已经指出患者的评价不能衡量医院服务的技术水平[31],Brown 和Swartz 也在使用SERVQUAL 模型时发现医院的技术水平实际上也是医院服务质量的重要一环[32]。未来可以考虑从其他数据来源刻画医院的技术水平信息。
