跨模态检索研究文献综述
2021-08-07段友祥孙歧峰
陈 宁,段友祥,孙歧峰
中国石油大学(华东)计算机科学与技术学院,山东 青岛 266580
近年来,随着互联网的蓬勃发展、智能设备与社交网络的普及,多媒体数据在互联网上爆炸式地增长。这些海量的数据包括文本、图像、视频及音频等各种模态形式,同一事物会有多种不同模态数据的描述。这些数据在形式上“异构多源”,而在语义上相互关联。
单模态检索[1-2]为信息检索的传统方式,要求检索集与查询集为相同模态,如文本检索文本[3]、图像检索图像[4]、视频检索视频[5]等。以图像检索为例,单模态检索技术主要包括基于文本关键字检索、基于图像底层特征索引以及基于语义建模和匹配等。虽然这些方法对于单模态检索来说能取得较好的检索结果,但是获取到的信息仅仅局限于一种模态数据,这种单一模态信息检索已不能满足人们高效、全面、准确获得对象信息的需求。因此如何对描述同一事物的各种模态数据进行高效检索成为信息检索领域一个重要的研究课题。面对海量、互联的多媒体数据,人们渴望通过其中一种模态数据来检索相关联的其他不同模态的补充数据。如图1 所示,左侧通过图像检索出相关文本,右侧通过文本检索出相关图像,描述同一个事物的文本与图像属于不同模态的数据,这种不同模态数据之间的互检索方式称为跨模态检索。

Fig.1 Schematic diagram of cross-modal retrieval图1 跨模态检索示意图
当前解决跨模态检索问题的一般技术框架如图2所示:首先对不同模态数据的特征进行提取;然后对获取的特征表示进行建模,即建立不同模态数据特征之间的关联关系表示模型;最后通过表示模型和相关算法获得检索结果并排序。其中在大多数建模算法中都会遇到处于不同特征空间的数据之间无法直接进行比较的问题,这是多模态数据间所具有的特点,即底层特征(如图像的颜色,文本的关键字、词,视频的帧等)异构,高层语义相关,即语义鸿沟[6]。因此跨模态检索研究的难点问题是,如何关联不同模态的数据并度量处于不同特征空间的模态数据之间相似性。

Fig.2 Cross-modal retrieval framework图2 跨模态检索框架
进而如何深入挖掘模态间的结构信息以及语义关联,建立多模态数据特征关联模型是提升多模态检索精度的关键。基于对多模态数据中丰富信息进行分析,研究者采用不同的技术和方法提出了多种多模态数据特征关联表示模型。由于具有相同语义的不同模态数据之间具有潜在的关联性,使得构建公共子空间成为当前最主流的特征关联模型。其核心思想是将不同模态的数据特征映射到同一个公共子空间,从而为不同模态数据生成统一的特征表征形式,进而使其可以直接进行相似度度量。本文主要以跨模态检索的关键技术——公共子空间建模为主线,对跨模态相关研究进行综述,具体将其归纳总结为基于传统统计分析、基于深度学习和基于哈希学习三类技术。
1 问题定义
为了清晰起见,以两种模态类型X与Y为例,给出跨模态检索的定义。训练数据定义为D={X,Y},其中,这里n表示训练样本实例的数据量,xi表示来自X模态的第i个样本实例的特征向量。同样地,定义,其中yj表示来自Y模态的第j个样本实例的特征向量。可以提供训练数据的语义标签定义为,其中表示X模态第i个实例的语义标签向量,表示Y模态第j个实例的语义标签向量,用来表示该模态数据样本所属的语义类别。若两个模态数据xi与yj之间存在语义关联,则;否则,。
由于不同模态的数据的特征向量与xi和yj位于不同的特征表示空间,并且通常具有不同的统计属性,它们不能直接进行比较。因此跨模态检索针对每种模态学习一个转换函数:对于X模态,ui=f(xi;γX)∈Rd;对于Y模态,vj=f(yj;γY)∈Rd。其中,d为公共子空间的维度,γX与γY为两个模态数据的训练参数。转换函数将来自不同特征空间的数据xi与yj映射成为公共子空间中的特征向量ui与vj。使得来自不同模态的数据可以直接进行比较,并且在公共子空间中,相同类别的样本相似度大于不同类别的样本的相似度。
跨模态检索的目标是计算跨模态数据的相似性。例如,针对来自X模态的数据xa,利用上述转换函数将其映射到公共子空间ua=f(xa;γX)∈Rd,计算其与公共子空间中所有Y模态数据vj的相似度dj=sim(ua,vj),将相似度进行排序,最终得到Y模态中与xa相关联的数据的检索结果。
2 基于传统统计分析的技术
传统统计分析是常用的公共子空间技术的基础,其通过优化统计值来学习子空间的投影矩阵。主要有三种解决思路,分别是无监督学习、监督学习与半监督学习。其中无监督学习的训练数据均无标签标记,监督学习与之相反,对所有训练数据进行人工标注,通过利用数据的标签信息来关联数据的特征与语义,而半监督学习中仅有部分训练数据有标签标记。
2.1 无监督学习
Li 等人提出了最早的传统统计分析方法——跨模态因子分析法(cross-modal factor analysis,CFA)[7],通过最小化不同模态样本变量对之间的距离来学习投影子空间,进而探索模态间数据背后存在的潜在变量关系。最具代表性的方法是由Thompson提出的典型相关分析(canonical correlation analysis,CCA)[8],其通过从原数据变量中选取具有代表性的综合指标的相关关系反映原数据之间的相关关系,同时考虑了变量间与变量内特征的关联。不足之处在于CCA的目的是寻找变量之间投影后的综合指标之间的关系,但是无法通过该关系还原出原变量,即找不到原变量之间直接映射关系。此外Rosipal 等人提出偏最小二乘法(partial least squares,PLS)[9],利用潜在变量对观测变量集之间的关系,通过最大化不同变量集之间的协方差来创建潜在关系向量,在子空间的跨模态检索问题中,进一步加强了不同模态之间相关性分析。
在CCA 的基础上,Zhang 等人又提出了基于核的典型相关分析方法(kernel canonical correlation analysis,KCCA)[10],将核函数引入CCA,扩展到可以特征化两组多维变量的非线性关系,将原始特征数据映射到更高维的核函数特征空间。KCCA 的优化问题与CCA 相同,均希望找到最优系数,使得两组变量的相关性最大。由于KCCA 复杂的函数空间,使用足够的训练数据可以表示更高的相关性,且可以生成特征以提高分类器性能。但是KCCA 与CCA 均要求数据是成对对应的,当模式中的多个点簇对应于另一个点簇时,或者当成对模式被类标签补充时,KCCA与CCA 都不能直接使用。KCCA 方法虽然解决了数据的非线性问题,但是由于核函数选取的不可知性,使得训练开销增大且模型更为复杂,因此Andrew 提出深度典型相关分析(deep canonical correlation analysis,DCCA)[11]。神经网络在解决非线性问题时,是通过嵌入每个层次的非线性函数来解决的。DCCA 采用深度神经网络(deep neural networks,DNN)分别求出两个视图经过线性化的向量,并求出两个投影向量的最大相关性,最后获得新的投影向量,将其加入模型算法中进行学习。
2.2 监督学习
显然上述方法并未涉及高层语义的分析建模,语义特征的缺失使其无法达到令人满意的结果。因此许多学者提出基于监督算法的统计分析技术,利用不同模态数据的高层语义关系进一步关联底层的异构特征。
Jia 等人通过基于马尔科夫随机场的主题模型[12]对模态间的高层语义关系进行建模。基于CCA 方法,Rasiwasia 等人研究了文本和图像联合建模的问题,提出三种子空间学习模型[13],通过逻辑回归增加了语义层的判断。之后又提出了聚类相关性分析(cluster canonical correlation analysis,Cluster-CCA)[14],与CCA、KCCA 不同的是,其没有要求数据的标准成对关系,在Cluster-CCA 中,每个集合都被划分成多个簇或者类,其中的类标签定义了集合之间的对应关系。Cluster-CCA 能够在特征空间上学习最大化两个集合之间相关性的判别低维表示,同时在学习空间上分离不同的类。此外还提出了核扩展,核聚类典型相关分析(kernel cluster canonical correlation analysis,Cluster-KCCA)[14],扩展了Cluster-CCA 到高维空间的非线性投影来观察两个集合间的关系。Cluster-CCA改进了CCA 只能适用于所有数据必须成对对应的数据集的问题,即拓宽了应用范围。但是当应用于大规模数据集时,计算协方差的复杂度随着数据数量变化呈平方的关系增长。
此外,Ranjan等人基于CCA提出了多标签典型关联分析(multi-label canonical correlation analysis,ml-CCA)[15],用于学习共享子空间,以多标签注释的形式表示高层语义信息。对于多标签数据集,不同模态间存在自然的多对多对应关系,即来自一种模态的每个数据点与来自另一个模态的若干个其他数据点相关。与CCA 不同,ml-CCA 不依赖于模态之间数据的显示配对,而是使用多标签信息来建立模态间对应关系,产生了一个更适合跨模态检索任务的判别子空间。同时提出Fast ml-CCA[15],它是一个高效率版本ml-CCA,能够处理大规模数据集,且在学习子空间的同时能够有效地融合多标签信息。Gong等人还提出了三视角CCA(3view canonical correlation analysis,3view-CCA)[16],结合第三视角捕捉高层次语义,考虑文本与图像两种模态的同时,将高层语义视为一种模态,最大化三种模态两两间的相关性,证明了语义特征的加入使得检索准确率得到了极大的提高。模态数据点之间的对应关系如图3 所示,圆圈和方块表示两种模态的数据点,“+”“-”“*”表示类标签。在cluster-CCA 中,一种模态中的每个点与另一个模态中的所有相同的类点配对。在3view-CCA 中,第一个模态中的每个样本与来自第二模态的具有相同类标签的单个样本配对。在ml-CCA 中,一组样本可与第二组中的多个样本配对。

Fig.3 Correspondence of modal data points图3 模态数据点对应关系
2.3 半监督学习
基于未标记数据易于收集和不同模态之间的相关性的特性,Zhang等人提出了广义半监督结构子空间学习方法(generalized semi-supervised structured subspace learning,GSS-SL)[17],将标签图约束、标签链损失函数和正则化集成到联合最小化公式中,以学习有区别的公共子空间。
虽然现有的传统统计分析的技术比较容易实现,但是存在共同的缺点:欠缺对模态内数据局部结构和模态间数据结构匹配的考虑。实际上,与具有邻域关系的样本相对应的另一模态的样本数据也具有邻域关系。并且大多数统计分析方法学习到的都是非线性映射,因此在模态间高级语义建模方面无法取得有效的结果。同样,统计分析方法在处理大规模以及高维多模态数据的计算复杂度上也表现得不尽人意。
3 基于深度学习的技术
近年来,深度学习在单模态领域取得突破性进展,如自然语言处理领域、图像领域和语音识别领域,神经网络强大的抽象能力在不同的多媒体应用中展现出无穷的潜力,如对象识别[18]与文本生成[19],为其在跨模态检索的研究上奠定了理论基础和技术实践。
3.1 玻尔兹曼机
Ngiam 等人首次采用深度学习的方法处理多模态任务,提出将受限玻尔兹曼机(restricted Boltzmann machine,RBM)应用于公共子空间的学习[20],通过输入连续的音频和视频帧训练模型,来学习音频与视频的统一表示。此项工作展示了深度学习如何应用于发现多模态特征的挑战性任务,但是模型采用的是手工设计特定于任务的特征,既困难又耗时。基于之前的工作[20],考虑到探索关联数据的侧重点在于语义关联,Srivastava 等人提出基于深度玻尔兹曼机的多模态学习(deep Boltzmann machine,DBM)[21],将DBM 结构扩充到多模态领域,通过多模态DBM,学习联合概率分布。该方法对模态内数据的底层特征分别进行学习,利用不同模态之间的高层语义关系建立模态之间的关联。DBM 学习多模态表示的最大优点之一就是其生成特性,即它允许数据有丢失。即使整个模态丢失,模型也可以通过对它们的条件分布进行采样并填充来提取这种表示,进而很好地工作,因此该模型可以有效地利用大量未标记的数据。然而,由于RBM 的原因,仍旧没有解决耗时严重的问题,在当时计算能力不高的情况下,也严重限制了其实际的应用。并且使用传统手工特征技术,使得性能仍远远不能令人满意。
3.2 自编码器
为研究图像与文本之间的交叉检索,Feng等人提出了基于对应式自编码器模型(correspondence autoencoder,Corr-AE)[22]的方法,并提出了新的优化目标。通过使每种模态的表示学习误差和模态间的隐藏表示的相关学习误差的线性组合最小化,对模型进行训练。最小化相关学习误差迫使模型只学习不同模态隐藏的公共信息,最小化表示学习误差使得隐藏表示足以重构每种模态的输入。此模型将单模态的表示学习和多模态的相关性学习结合到一个过程中,从而将自编码代价和相关代价结合起来。基于此项工作,Zhang 等人提出独立组件多模态自动编码器(independent component multimodal autoencoder,ICMAE)[23]的深度体系结构,使用两个自编码器不断学习跨视觉和文本的共享高级表示,从而进行属性的自动发现。虽然自编码器的加入使得模型泛化能力得到加强,然而针对异常识别场景,得到的重构输出可能也会变成异常数据。
而现有的大多数跨模态检索方法,在整个训练过程中要使用到包含所有模态的数据,不同模态转换的最佳参数之间彼此依赖,并且当处理来自新模态的样本数据的时候,整个模型需要重新进行训练。因此,Hu 等人提出了可扩展的深度多模态学习方法(scalable deep multimodal learning,SDML)[24],设计预先定义一个公共子空间,使得类间差异最大、类内差异最小。针对每一种模态数据设计一个深度监督自编码器(deep supervised autoencoder,DSAE)将多模态数据转换到预定义的公共子空间,实现跨模态学习。与大多数现有方法不同的是,SDML 可以独立、并行地训练不同的特定模态的网络,可以有效地处理来自新模态的样本,只需要训练针对该模态的新网络即可。因此其是可以扩展模态数量的,是最先提出可以将不定数量的模态数据独立投影到预定义子空间中的方法之一,亦是提出将跨模态检索问题扩展到多个模态数量的实践之一,值得人们关注,这也是大多数现有方法所忽略的问题,亦是未来的挑战。
3.3 卷积神经网络
为了学习到更加具有判别性的表示,诸多学者提出了基于深度监督学习的跨模态检索方法。为加强对图像与文本之间的高级语义相关性表示的探索,Wang 等人提出了一种正则化的深度神经网络(regularized deep neural network,RE-DNN)[25],用于跨模态的语义映射。RE-DNN 通过结合卷积神经网络(convolutional neural networks,CNN)(处理图像)和语言神经网络(处理文本),将图像和文本数据映射到公共语义子空间,得到一个同时捕获模态内和模态间关系的联合模型,从而进行模态间数据的相似度度量。
也有一些想法将DNN 与CCA 相结合作为DCCA[11],其有很明显的缺点:对内存的过度占用,计算速度过慢以及过拟合现象的发生。因此使用DCCA 框架时,特征的高维性使得其在内存和复杂性方面提出了巨大的挑战。Yan 等人提出了一种基于DCCA 的端到端学习方法(end-to-end learning scheme based on deep canonical correlation analysis)[26]来对文本和图像进行检索,通过GPU 实现来解决这些问题,并提出处理过拟合的方法,以此来应对DCCA 框架的缺点。之前的工作[20-21]为不同模态数据创建一个具有共享层的网络,而DCCA 与之不同的是,其使用两个独立的子网络,并且通过控制代码层的相关约束性来最大化模态数据之间总体的相关性。
为解决带有一个或多个标签的图像文本跨模态检索问题,Wei等人提出了深度语义匹配(deep semantic matching,Deep-SM)[27]的方法,利用卷积神经网络对视觉特征的强大表示能力,完成文本和图像两种模态之间的检索,并验证了使用CNN 视觉特征表示的图像进行跨模态检索相比于其他方法更容易获得更好的结果。然而对于文本数据只是使用一个完全连接的神经网络来提取文本的语义特征,未来可以探索更合适的神经网络,以建立文本数据的底层特征和高级语义之间的关系。与此同时,为了从差异很大的模态数据之间学习到共享关联表示,Castrejon 等人提出了正则化跨模态卷积神经网络(regularized convolutional neural network,RE-CNN)[28]的方法,在给出仅使用场景标签注释的数据集前提下,从弱对齐数据中学习到具有强对齐的跨模态表示。
而为致力于图像与文本句子之间的检索,Zhang等人提出一种跨模态关系引导网络(cross-modal relation guided network,CRGN)[29],其将图像与文本嵌入到一个潜在的特征空间中。该模型使用门控循环单元(gated recurrent unit,GRU)提取文本特征,使用残差网络(residual network,ResNet)提取图像特征,并提出一种有效的多任务损失两阶段训练策略,用于优化网络。该方法虽然取得了很好的检索结果,但是仍具有很大的发展空间,为适应大规模的跨模态检索任务,可以将其与哈希网络相结合。
综上可知,CNN 可以保留领域的联系和空间的局部特点,且对于局部操作有很强的抽象表征能力。可以利用图像的二维结构和相邻像素之间的高度相关性,且引入池化操作在一定程度上保证了图像的平移不变性,使得模型不受位置变化的影响。池化操作同样使得网络拥有更大的感受野,使得网络在更深层学习到更加抽象的特征表示。因此,CNN特别适合于图像模态特征及语义的提取。尤其是近些年代表图像领域最高水平的ImageNet 视觉识别竞赛(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)[30]所涌现出来网络模型,如AlexNet[31]、VGG[32]、GoogLeNet[33]、ResNet[34]、DenseNet[35]、SeNet[36]等在图像特征提取、图像分类方面表现出绝佳性能的CNN网络模型,其判别能力甚至超过了人的水平,并且Wei 等人[27]也证明使用CNN 视觉特征相比于传统视觉特征(SIFT(scale-invariant feature transform)、BoVW(bag of visual words)以及LLC(locality-constrained linear coding)等)能给模型带来更加良好的效果。这对跨模态检索领域带来了巨大的推动力,大部分前人的工作也是基于这些网络模型所展开的。关于不同CNN 模型在实际应用中的重要指标的全面分析,读者可参考文献[37],此些模型的特征抽象以及表示能力均获得了卓越的成果。
3.4 循环神经网络
当前用于跨模态检索的算法通常提取全局特征,用于拉近相匹配的模态数据。在研究图像文本匹配时,考虑到全局特征包含较多的冗余信息,即关注图像中的显著区域、句子中的显著单词以及区域和单词之间的交互作用,过滤掉不相关的信息。Huang 等人提出一种基于选择性的多模态长短期记忆网络(selective multimodal long short-term memory network,sm-LSTM)[38]的动态模型,在每一个时间步上,利用基于上下文的注意力机制来选择不同模态数据之间描述相同语义的部分,从而进行计算得到局部相似性。最后,将经过多个时间步测量所得的局部相似性聚合为全局相似性。其使用的LSTM 模型以及提到的一种多模态的基于上下文的注意力机制,会对人们后续的工作带来极大的启发。然而使用全连接的循环神经网络(recurrent neural network,RNN)带来了不小的计算负担,增加了模型的运算复杂度,这方面表现得不如CNN 建模。
同样地,基于上述思想,Wang 等人提出跨模态自适应消息传递方法(cross-modal adaptive message passing,CAMP)[39],其由跨模态消息聚合模块和跨模态门控融合模块组成,使用自适应门控方案正确处理负对和无关信息。此外,代替传统的联合嵌入方法,基于融合后的特征来推断匹配分数,并且提出负二进制交叉熵损失进行训练。其很好地关注到模态数据间的重要信息并为跨模态匹配找到细粒度的线索,然而这种基于注意力的方法忽略了一个文本单词或者图像区域在不同的上下文中可能含有不同的语义的问题。同时考虑模态内和模态间上下文语境,并在适应各种上下文的情况下执行检索是更加有效的。针对上述工作[29-30]所存在的问题,Zhang等人提出上下文感知注意网络(context-aware attention network,CANN)[40],同时利用全局模态间和模态内相关关系来发现潜在的语义关系,从全局的角度基于给定的上下文来自适应地选择信息片段,包括单模态内的语义相关性以及模态间的可能的对齐方式,并使用基于语义的注意力捕获模态相关性、更细粒度的语义以及丰富的上下文信息,使得模型性能表现得更加优异。
RNN 是处理具有时序关系的数据相关任务最成功的多层神经网络模型,样本出现的时间顺序对于自然语言处理来说非常重要,针对其他网络无法对时间序列上的变化进行建模的问题,RNN 给予了很好的解决。很多现有模型对文本模态仅使用全连接层提取特征,忽略了文本的上下文信息以及丰富的语义信息,因此在跨模态检索中处理时间序列的文本、音频等模态的建模问题时,考虑使用RNN 进行特征提取表征,将会是一个很好的选择。
3.5 生成对抗网络
Goodfellow 等人提出的生成对抗网络(generative adversarial networks,GAN)[41]为跨模态检索的研究提供了很大的启发。Gu等人第一次提出同时利用GAN和强化学习(reinforcement learning,RL)实现跨模态检索[42]。将生成过程引入到传统的跨模态特征嵌入中,解决了传统跨模态检索方法在高层语义层面匹配良好,但在图片细节和句子单词层面缺乏良好匹配的问题,不仅可以学习到多模态数据的高层抽象表示,还能学习到模态数据的底层表示。但是其所生成图像的质量有待提高,且并未考虑如何共同提取和利用特定于模态以及模态之间共享的特征,即多模态数据之间的互补性与相关性的问题。
GAN 网络已显示出通过对抗学习来对数据分布进行建模的强大能力,使得跨模态检索有了很大的进展空间,针对其中有效地联合提取和利用互补性与相关性特征的问题,Wu 等人提出一种基于GAN 网络的方法MS2GAN(modality-specific and shared generative adversarial network)[43],其由两个学习特定于模态特征的子网和一个学习共享特征的公共子网组成,并使用生成模型预测产生的语义标签对相似性进行建模,判别模型用于对模态的特征进行分类,使得检索精度得到了极大的提升。然而该模型运算复杂度较高,且仅在公共数据集上进行测试,未来可以尝试与哈希方法结合以提高检索效率,并使用实际数据测试模型以提高模型稳健性,使得进一步应对实际应用。
GAN 网络模型充分体现了多层网络架构的强大性,并且最关键的是引入了无监督学习方式,使得模型的训练学习不再依赖大量的标记数据。针对无监督、半监督等场景,读者可以考虑利用GAN 进行模型训练。
深度学习具有丰富的表示能力和强大的计算能力,能更好地适用于大规模训练样本。但现有的基于深度学习的跨模态检索技术仍然有待完善,其主要挑战来自于不同模态数据特征的互异性,需要将不同模态的特征信息融合到一起,从而得到关于数据更好的理解以及应用。然而由于每种模态数据之间的表达方式、理解方式差异很大,现有的深度学习模型在抽取特征之后,再将其投影到一个公共的空间中,不同模态之间特征的相互融合以及相互对照仍然需要继续进一步地优化,不同模态内部数据的局部结构和模态间语义类结构关联缺乏关注和深入研究。因此跨模态检索在深度学习上的应用需要在特征融合、泛化能力、噪音对抗、语义特征缺失等方面继续进行长久的探索。
4 基于哈希学习的技术
传统统计分析技术与深度学习技术均基于提取到的特征值直接进行建模,从而实现跨模态检索,这对于大规模数据集非常耗时,并且需要大量的存储空间。哈希学习由于存储需求低且检索速度快,应对大规模数据具有很好的效果。该方法将原始特征空间中的数据点映射成公共汉明空间中的二进制编码,通过计算待查询数据的哈希编码和原始数据哈希编码之间的汉明距离进行相似度排序,从而得到检索结果,使得检索效率得到了极大的提高。并且以二进制编码代替原始数据存储,使得检索任务对存储量的需求极大地降低。
哈希学习的最初提出是为了加速检索过程,并广泛使用于各种检索任务中,但是它们大多数只涉及一种模态数据[44]。Zhang 等人提出了具有多个信息源的复合哈希(composite Hashing with multiple information sources,CHMIS)[45],将哈希学习技术引入多模态检索,其设计的哈希码尽可能保留了原空间中的近邻相似性,这也就是所谓的保留相似性,如图4 所示。具体来说,所有数据点都使用紧凑的二进制串编码,在原空间中相似的两个点被映射到哈希空间中时也应该具有相似性。同样在后续工作中,保留相似性是解决基于哈希方法的跨模态检索问题的关键原则[46]。

Fig.4 Keep similarity图4 保留相似性
4.1 基于手工特征的哈希学习
许多监督的多模态哈希方法(supervised multimodal Hashing,SMH)被提出,这些方法利用语义标签提高检索精度,然而大多数训练时间复杂度太高,无法扩展到大规模数据集。因此,Zhang等人提出了新的语义相关最大化方法(semantic correlation maximization,SCM)[47],将语义信息无缝地集成到大规模数据建模的哈希学习过程中,避免了显式地计算成对相似矩阵,利用所有监督信息进行线性时间复杂度的训练。提出了一种逐位学习哈希函数的顺序学习方法,每一位的散列函数的解都有一个闭式解,在SCM学习过程中,不需要任何超参数和停止条件,使得SCM 在精度和可扩展性方面都明显优于SMH 方法。
为了研究跨视图相似性搜索在多模态数据环境中学习哈希函数的问题,Ding等人提出了集体矩阵分解哈希(collective matrix factorization Hashing,CMFH)[48]方法,首次使用集体矩阵分解技术来学习交叉视图散列函数,其不仅支持跨视图检索,而且通过合并多个视图信息源提高了搜索精度。为了研究图像文本检索问题,Lin 等人提出了语义保持哈希(semanticspreserving Hashing,SePH)[49]方法,将数据的语义相似性作为监督信息。SePH 将待学习散列码之间所有的成对汉明距离转换为另一个概率分布,并通过最小化Kulback-Leibler 散度在汉明空间中学习的散列码来近似它。利用具有采样策略的核逻辑回归,学习从视图特征到散列码的非线性投影。
此外,当前跨模态哈希方法通常学习统一的或等长的哈希码来表示多模态的数据,使得不同模态的数据具有直观的可比性。然而,由于来自不同模态的数据可能不具有一对一的对应关系,这种统一的或等长的哈希表示会牺牲它们表示的可扩展性。Liu等人打破了相等散列长度表示的限制,提出了使用不等长的不同散列编码异构数据,并提出了一个通用灵活且高效的矩阵因子分解哈希(matrix tri-factorization Hashing,MTFH)[50]框架,其可以无缝地工作在各种检索任务中,包括成对或不成对的多模态数据,以及等长或者变长的哈希编码环境。MTFH 是首次提出尝试学习不同长度的散列码用于异构数据比较的方法,并且所学的特定模态的散列码对于跨模态检索来说在语义上更有意义,是一个高效的无松弛的离散优化算法,可以很好地减少哈希码学习过程中的量化误差。通过这个有效的实验,后续工作可以侧重于利用每个模态的最佳散列长度来执行跨模态检索任务,以及对小样本数据集的适应性和对更多模态的扩展。
为了综合利用不同模态之间的内在相关性,并同时充分利用监督信息进行高效的跨模态检索,Meng等人提出了一种新颖的跨模态哈希方法(asymmetric supervised consistent and specific Hashing,ASCSH)[51],并且提出了一种有效的多模态映射学习策略,将不同模态的映射矩阵分解为一致部分和特定于模态的部分。同时为了充分挖掘监督信息,构造了一种新颖的离散不对称学习结构,以联合利用成对相似性和语义标签。该模型给人们带来启发:联合探索一致和特定于模态的信息,有利于发现模态数据间的共享内在语义;引入非对称编码结构,有助于提高哈希码的区分能力,进而降低计算成本。该方法值得人们思考,其不仅可以产生优越的性能,而且在计算效率和检索性能之间也获得了良好的平衡,是应对目前部分跨模态检索相关方法的运算复杂度较高问题的方法之一。
早期还有很多类似于上述方法的工作,这些方法大多专注于模态间语义关系的发掘,而这些语义关系往往是通过某些浅层的结构提取出的基于手工制作的特性,而这些特性可能与哈希编码学习过程不兼容。这就使得特征提取与哈希码学习过程的分离,从而降低了紧凑哈希码的有效性。
4.2 基于深度学习的哈希学习
与上述传统的浅层结构提取手工特征相比,深度学习技术所提取的特征更加具有区分性和有效性。因此近些年来,大量的研究深度学习结合哈希学习(简称深度哈希)的工作陆续展开。
由于大多数跨模态哈希(cross-modal Hashing,CMH)方法基于手工制作的特性,导致其无法实现令人满意的性能。Jiang等人提出一种新的CMH方法——深度跨模态哈希(deep cross-modal Hashing,DCMH)[52],实现图像文本两种模态数据的互检索。DCMH 是集成特征学习与哈希学习的端到端框架,从端开始执行特征学习,一端提取图像特征,一端提取文本特征。自DCMH 首次提出将哈希与深度学习结合并证明了其可行性以来,诸多基于深度哈希的跨模态研究工作陆续展开。在DCMH 的基础上,Zhen 等人提出深度监督跨模态检索(deep supervised cross-modal retrieval,DSCMR)[53]方法,其目的是保持不同语义类别样本之间的区分度,同时消除跨模态差异。最小化样本在标签空间和公共表示空间中的判别损失,用以监督模型学习判别特征。同时最小化模态不变性损失,并使用权重共享策略来学习公共表示空间中的模态变量特征。这样的学习策略,使得成对标签信息和分类信息都被尽可能充分地利用,确保了所学习的表示在语义结构上是有区别的,弥合了不同模态之间的异构差距。
基于深度学习方法的成功,跨模态检索在近些年取得了显著的进展,但是仍然存在一个关键的瓶颈,即如何弥补不同模态之间的差异以进一步提高检索的准确性。因此,Li 等人提出了一种自监督的对抗式哈希方法(self-supervised adversarial Hashing,SSAH)[54],利用两个对抗网络来学习不同模态的高维特征及其对应哈希码,以最大化语义相关性和模态之间的特征分布的一致性。并且利用自监督语义网络以多标签标注的形式发现高级语义信息,将自监督语义学习与对抗学习相结合,能尽可能保证语义相关性和跨模态表示一致性。这些信息指导着特征学习的过程,并且在公共语义空间和汉明空间中也保持着模态之间的关系。
为加强对语义标签信息的利用,Lin 等人提出一种新的深度跨模态哈希方法——语义深度跨模态哈希(semantic deep cross-modal Hashing,SDCH)[55],生成更加具有区分性的哈希码。利用语义标签改进特征学习部分,可以保留学习到的特征的语义信息,并保持跨模态数据的不变性。此外,采用模态间成对损失、交叉熵损失和量化损失来保证所有相似实例对的排序相关性高于不同实例对的排序相关性。语义标签的加入使得可以利用其来为相互关联的跨模态数据学习更一致的哈希码,这能显著地减轻模态差距并提高检索性能。然而现实中的数据往往并不完全具有相关语义标签,无监督领域缺乏足够的探索,且由于DNN 的加入使得可以产生更多的语义相关特征和哈希码,并且能进一步提高检索性能,Su 等人提出了一种面向大规模的深度无监督联合语义重构哈希(deep joint-semantics reconstructing Hashing,DJSRH)[56]方法,其首次提出构造一种新颖的联合语义亲和矩阵,以学习保留原始数据邻域结构的哈希码,用于挖掘输入实例之间潜在的内在语义关系。通过提出的重构框架学习二进制码以最大限度地重构联合语义结构,一方面对原始相似度范围进行线性变换以调整更好的量化区域,使重构更加灵活;另一方面,重构了特定的相似度值,使得DJSRH 比前人[57]所使用的拉普拉斯约束更适合端到端的分批训练。
由于大多数现有的跨模态哈希方法在探索模态数据间的语义一致性方面有所欠缺,进而导致性能不理想,Xie等人提出了一种新颖的深度哈希方法CPAH(multi-task consistency-preserving adversarial Hashing)[58],其将多模态语义一致性学习和哈希学习无缝地结合在一个端到端的框架中。并且提出了一致性细化模块和多任务对抗性学习模块,分别用于分离模态表示与保留语义一致性信息,充分挖掘不同模态间的语义一致性和相关性,进而实现高效率的检索。
现有方法将哈希学习用于跨模态检索,使其具有存储需求小和检索速度快的优势。却存在一些问题,如将模态数据实值特征进行二值化转化过程中将原有数据的结构破坏,不可避免有精度损失,并且大部分没有考虑到模态内数据结构和模态间结构的匹配关联,对哈希进行优化计算比较复杂等。
5 验证与对比分析
在对相关研究总结综述的基础上,为了进一步加深对相关研究的认识和理解,评估与分析不同跨模态检索技术方法的特点,本文在传统统计分析、深度学习、哈希学习三大类技术中选取具有代表性的方法,在同一个数据集上进行跨模态检索实验,并根据实验结果进行分析和比较。
5.1 数据集准备
跨模态常用数据集有Wikipedia[13]数据集、Flickr8K数据集、Flickr30K[59]数据集、NUS-WIDE[60]数据集、XMedia[61]数据集、MIR Flickr[62]数据集、MSCOCO[63]数据集等。
为了统一,按照文献[64]选取NUS-WIDE 数据集中10 个最常见类别的图像进行实验,并且每一个图像以及相应的标签被视为具有唯一类别标签的图像文本对。最终有71 602 个图像文本对,其中训练集由42 941 对图像文本对组成,验证集由5 000 对图像文本对组成,测试集由23 661 对图像文本对组成。
为了控制其他因素干扰,对图像使用相同的CNN特征,这些CNN 特征是遵循文献[24]从具有4 096 个维度的19 层VGG Net[32]中的fc7 层提取出来的。300个维度的文本特征是通过预先训练好的Doc2Vec 模型[65]中提取出来的,对NUS-WIDE 数据集预处理结果如表1 所示。
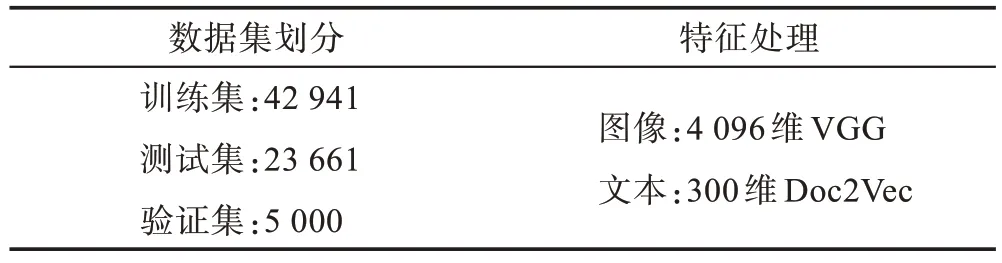
Table 1 Preprocessing results for NUS-WIDE data set表1 对数据集NUS-WIDE 预处理结果
5.2 实验过程
基于传统统计分析的跨模态检索技术选取了GSS-SL[17]方法,基于深度学习的跨模态技术选取了SDML[24]方法,基于哈希学习的跨模态技术选取了MTFH[50]方法。
三种检索方法分别在经过预处理之后的统一数据集NUS-WIDE上进行跨模态检索任务实验,即通过一种模态去查询另一种模态,这里通过文本检索图像(文本→图像)和通过图像检索文本(图像→文本)。
采用平均精度均值(mean average precision,mAP)作为评估指标对性能进行评估。其中MTFH 方法,选取在核逻辑回归中更优的k-means 方案[50],哈希长度依次调整16 bit、32 bit、64 bit、128 bit,记录其mAP结果。
5.3 实验结果
表2 列出了三种方法在NUS-WIDE 数据集上实验的mAP 结果。
从表2 中可以看出:SDML 方法性能最优,其次是MTFH 方法,最差的是GSS-SL 方法。且MTFH 方法性能并不是随着哈希码长度增加而持续提升,长度最适合的哈希码才能使其达到最高精度。

Table 2 mAP score comparison表2 mAP 分值比较
5.4 对比分析
从方法的理论基础和实验结果可以得出如下结论:基于传统统计分析的技术作为跨模态公共子空间建模方法的基本范例,这些方法对于训练来说是相对有效的,并且易于实施,但是由于其并没有考虑单一模态数据的局部结构与模态间的数据结构的匹配情况,且仅仅通过线性投影很难完全对真实世界中多模态数据的复杂相关性进行建模,导致在模态间高级语义建模方面无法取得有效的结果。其次其不仅针对如今大规模以及高维的数据来说训练时间较复杂,模型的运算复杂度较高以及检索效率较低,而且模型的易扩展性较差,大多模型仅限制两种媒体类型作为输入,扩展多模态检索需更加复杂的工作设计,因此与其他两类技术方法相比处于劣势。
基于深度学习的跨模态检索技术,具有更好的适应大数据样本的能力、超强计算能力和深度学习模型对特征的丰富表示能力等特点。深度学习的发展,很好地解决了传统统计分析方法难以提取数据之间非线性关系的难题,这对于跨模态检索领域来说是一个质的飞跃,因此其相比于传统统计分析方法能更好地提取多模态数据间语义信息,进而使得跨模态检索的性能得到了进一步的提高。然而大多数现有方法,存在同样的问题:模型过于复杂,大规模数据训练耗时较长,且运算复杂度过高;仅追求检索精度,而忽略了检索性能,使得模型虽然获得卓越的检索精度,然而具有巨大的检索延迟和效率低下的问题,难以在现实中应用;大多数方法仍然仅针对两种模态的检索问题,模型可扩展性依然较差,尽管有针对五种模态的工作[28],但仍是未来研究的重要挑战。
基于哈希学习技术的加入,很好地解决了前人大多数工作存在的实际检索时效率低下的问题,对于跨模态检索的实际应用起到了巨大的推动作用。其使用短的二进制哈希码,使得检索效率得到了极大的提高,且其还具有低存储的特性,降低了对存储的要求,使得检索在现实世界中大规模数据集上受益颇多,成为应对跨模态检索模型复杂度较高的主流解决手段。然而在将实值特征数据转化为二值哈希码的过程中,不得不将原有数据结构破坏,这就不可避免地造成了精度的损失。因此,其对多模态数据语义的提取以及对处理复杂交叉模态数据相关性的特征抽象能力没有深度学习表现得那样卓越。
因此,同时结合深度学习算法在表征学习中表现出来的良好性能以及哈希方法所表现出的高效率低存储的特性,有助于减少不同模态形式数据之间的异构性差距和语义差距,同时降低算法运算复杂度。适当结合深度学习算法与哈希学习(简称深度哈希)来为跨模态检索建模不同类型的数据是未来的趋势,不仅可以获得卓越的检索精度,在计算效率和检索性能之间也可获得良好的平衡。自2017 年,DCMH 方法首次提出将两者结合并证明了其可行性以来,已经有诸多学者进行实践,例如DSCMR[53]、SSAH[54]、SHCH[55]、DJSRH[56]、CPAH[58]等,使用集成的方式将高级特征学习与哈希学习结合起来,由此可以通过误差反向传播利用哈希码来优化特征表示[50],这将是未来研究的重点所在。除了少数方法[48],值得注意的是大多数已有的基于哈希技术的跨模态检索方法在可扩展性方面依然没有太多涉及,这将是未来将其应用于现实所面临的重要挑战。
6 展望
尽管跨模态检索领域已经取得了一些有前景的成果,但在最先进的方法和用户期望之间仍存在差距,这表明人们仍然需要在该问题上持续探索。当前大部分现有工作,存在以下共同问题,这也是未来研究的重要挑战。
(1)模型的可扩展性
模型大多从头开始训练,且大多现有工作仍限制于只有两种媒体类型作为输入,模型可扩展性较差,共同学习两个以上的媒体类型的公共子空间可以用来提高跨模态检索问题的灵活性,亦是未来研究的重要挑战。
(2)应对现实数据集的跨模态检索
像Facebook、YouTube、微博、微信等社交网络产生了大量的由人们所创建的多模态内容,然而这些数据大多是松散的,并且标签是有限的且含有噪声的,而大规模的多模态数据是很难进行标记的。现有大多数方法仅针对理想大规模样本以及含有语义标签的数据集设计,而对于现实中小样本、零样本、噪声样本场景以及弱监督、半监督、无监督方法较少涉及,因此在此情况下如何利用有限的且有噪声干扰的数据来学习多模态数据之间的语义相关性,是未来亟待解决的问题。
(3)大规模的具有多样性或噪声的数据集
近些年越来越复杂的算法模型涌现,然而缺乏进一步用于训练、测试以及评估模型的良好数据集。当前跨模态检索所共用的数据集,存在规模太小、类别合理性以及大多仅包含文本及图像两种模态缺乏多样性等问题,这些问题的存在使得多数数据集限制了模型评估的客观性。例如,Wikipedia[13]数据集太小,且仅仅包含两种模态数据类型。因此,包含多种模态样本以及含有噪声的大规模真实数据集,将是解决以上两个问题的关键,也将对未来的研究工作带来极大的帮助。近些年也出现了一些比较好的数据集,例如XMedia[61]数据集,其是第一个包含五种模态类型(图像、文本、视频、音频和3D 模型)、200 多个类别、10 万多个实例的数据集,这将有助于人们专注于算法设计,而不是耗时地比较模型与结果,极大促进跨模态检索的发展。
(4)检索效率的追求
大多数现有模型仅追求检索精度,却忽略了检索效率,导致了训练之后的模型具有巨大的检索延迟和效率低下的问题,使得无法在现实中应用。因此如何在保证检索精度的同时提高检索效率,是亟待解决亦必须解决的问题,是后续工作的重中之重,其中哈希方法的广泛应用为此问题的解决带来了巨大的推动力,近些年的文献也偏向于与哈希方法结合完成检索,进而降低运算的复杂度。
(5)语义鸿沟
如前面所说,深度哈希是将跨模态检索应用于现实所面临的重要挑战,然而尽管现有方法与很多方法相比表现出出色的性能,但仍然受到计算复杂性以及对模型最佳参数查找的穷举搜索的限制,并且不能很好地弥合哈希码的汉明距离与特征度量距离之间的语义差距。因此,结合深度学习与哈希学习来解决跨模态检索问题方面的研究很值得关注和期待,也是后续研究的重点。例如,使用CNN 建模图像模态,使用RNN 建模文本模态。需注意的是Self-Attention 机制[66]被广泛关注,其由于可以无视词之间的距离直接计算依赖关系,且能够解决RNN 出现的不能并行的问题,近些年被广泛用来配合RNN 与CNN 使用,甚至该机制可以代替RNN 并能取得更加优越的效果,已被成功应用于各种自然语言处理(natural language processing,NLP)以及计算机视觉(computational vision,CV)任务[67-69]。以及近些年被广泛关注的Transformer模型[66],旨在全部利用Attention方式替换RNN 的循环机制,进而能并行优化计算并实现提速,从而其在NLP 以及CV 任务上表现出卓越的性能,这使得在跨模态检索问题上具有很高的应用价值,也已经有学者对其进行了研究应用[70-71]。
(6)细粒度的语义关联以及丰富的上下文信息
跨模态检索的主要挑战仍是不同模态数据之间的“语义鸿沟”,大多数已有模型通常将不同模态数据映射到公共子空间,在其中比较不同模态数据。然而,由于不同的图像区域往往对应于不同的文本片段,直接映射到公共子空间显得太粗糙,考虑的粒度更精细可以更准确地对多模态语义进行关联建模。而且,模态之间的语义相关性往往与上下文信息有关,现有许多方法忽略了含有丰富语义关系的上下文,只考虑语义类别标签等作为训练信息,降低了检索的性能。因此,如何获取不同模态数据片段并找到其语义关联关系进而进行细粒度建模,以及更加关注含有丰富语义的上下文信息是未来需要解决的问题,这将对模型的精度提高带来助力。
7 结束语
本文深入分析了跨模态检索问题,针对公共子空间建模关键技术进行了研究,将其总结归纳为基于传统统计分析、基于深度学习和基于哈希学习三类技术;对三类技术相关研究的发展脉络、研究现状和进展进行了综述,从理论和实验两个角度进行了对比分析;对目前研究的各种不同方法的特点和不足进行了总结,并对未来研究重点进行了充分展望,为后续研究奠定了扎实基础。
