基于Xgboost的心血管疾病预测模型和指标分析研究
2021-07-29陈洞天周文丹
陈洞天 单 杰 周文丹
心血管疾病是一种严重威胁人类,特别是50岁以上中老年人健康的常见病,具有高患病率、高致残率和高死亡率的特点,即使应用目前最先进、完善的治疗手段,仍有相当比例的心血管意外幸存者生活不能完全自理,全世界每年死于心脑血管疾病的人数居各种疾病死因的首位。随着国民生活方式的转变以及我国人口老龄化进程的加速,中国心血管病危险因素流行趋势明显,导致以心血管疾病为代表的慢性病发病人数持续增加,发病年龄不断前移[1]。面对心血管病的发病风险不断提高,提高防治水平仍是最有效的方向。
现阶段临床常用的心血管风险评估工具都是基于回归模型制作的风险评估量表,例如在Framingham[2]心血管风险评分量表和GRACE危险评分量表[3]。这些传统的量表虽然具有较好的预测评估效果,但是也存在模型相对固化的问题:①指标固定,无法纳入新的指标;②很多指标在不同地域与时代表达出不同的影响效果,量表难以及时更新。与传统的回归模型量表相比,机器学习算法可以支持新指标的引入,并根据当地最新病例数据进行模型训练,从而得到相对更为精准的预测模型。此外,通过可解释性研究,可以发掘各指标的影响规律,为临床诊疗提供知识支撑。
1 材料与方法
1.1 数据来源
选取诊断为冠心病、心肌梗塞等心血管疾病的的病例和未诊断为心血管疾病的患者,合计1 000病例数据患者作为研究对象。其中包含507名确诊病例,493名未确诊病例。对于所有病例,选取3类共计11个指标作为数据集特征,见表1。
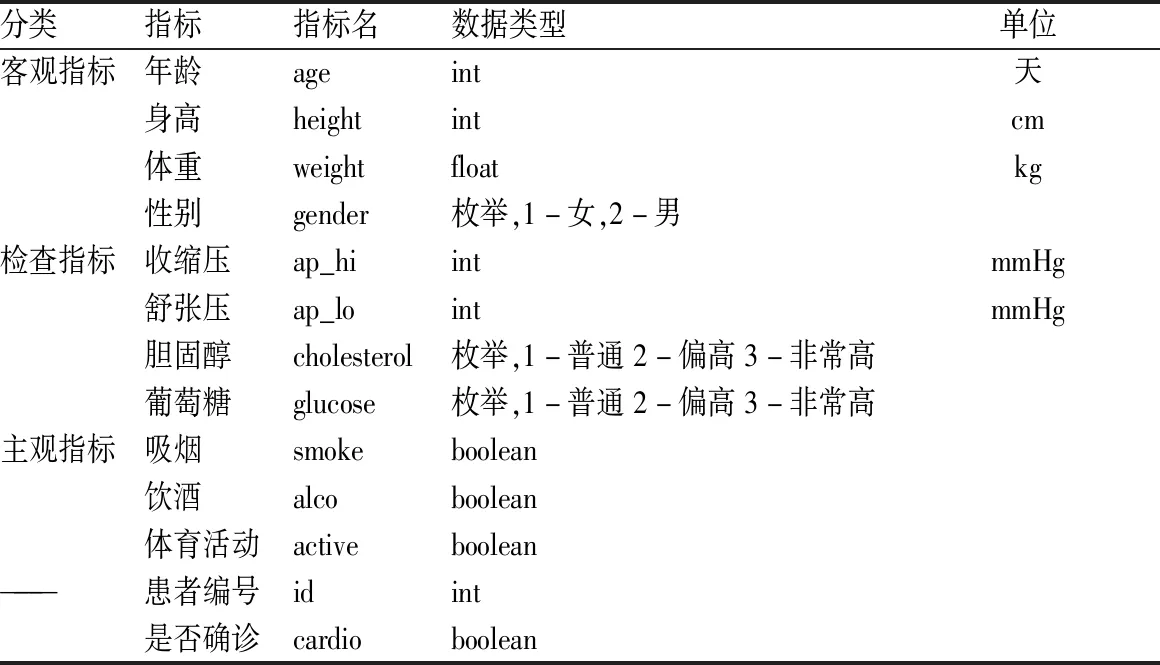
表1 指标列表
1.2 数据探索与预处理
数据探索和预处理是拿到实验数据集的第一个环节,也是影响后续实验效果最重要的一个环节。其中,数据预处理能改善数据集的完整性,降低冗余性和相关性,有效提升算法模型质量[4],应格外重视。本研究采用pandas[5]数据模型工具对数据集进行结构化处理。部分样本数据见表2。

表2 部分样本数据
1.3 研究方法
1.3.1 模型训练方法 XGBoost[6]是一种改进的梯度提升算法,它采用二阶导数优化目标函数,将多个弱分类器进行融合从而演化成强分类器。XGBoost具有计算复杂度低,运行速度快、准确度高的优点。按照表3对XGBoost算法进行配置:将数据集按照4 ∶1的比例分割为训练数据集和测试数据集,即800名病例的指标数据作为训练数据集,200名患者的指标数据作为测试数据集。在训练数据集上完成模型训练后,使用该模型在测试数据集上进行测试,验证模型的性能指标。

表3 XGBoost主要参数配置
1.3.2 指标分析方法 除了获得一个具有较好性能的预测模型之外,我们还希望能了解其内部工作机制,从而为临床诊疗提供经验知识。通过算法训练出的模型往往被看作成黑盒子,严重阻碍了机器学习在某些特定领域的使用,譬如医学、金融等领域[7]。为了能了解各个指标在模型中的重要程度,我们采用SHAP值[8]方法对该模型进行解释。
SHAP值方法是博弈论中解决多人合作博弈成本分摊或利益分配的方法,该方法通过考虑联盟成员对联盟的边际贡献将利益或成本进行合理分配[9]。Shap值体现了每个数据点的每个特征参数的对于总体收益的贡献值,SHAP值的符号代表该特征的影响方向,绝对值大小代表该特征的影响大小。
SHAP值的原理可以描述为:假设第i个样本为xi,第i个样本的第j个特征为xij,模型对该样本的预测值为yi,整个模型的基线(通常是所有样本的目标变量的均值)为ybase,那么SHAP值服从以下等式:
yi=ybase+f(xi1)+f(xi2)+…+(xik)
其中f(xij)为(xij)的SHAP值。直观上看,f(xi1)就是第i个样本中第1个特征对最终预测值yi的贡献值,当f(xi1)>0,说明该特征提升了预测值,也正向作用;反之,说明该特征使得预测值降低,有反作用。
本文使用Python的shap[10]工具包对上文所述的心血管疾病风险预测模型中各指标的影响力进行分析,该工具包是Scott Lundberg对SHAP值法的Python实现,是一种模型无关(model-agnostic)的机器学习可解释性方法,兼容所有主流的机器学习模型。基于SHAP值法,我们对训练集中的患者的样本数据进行计算,得到每名患者的所有指标的SHAP值数据。
2 结果
2.1 模型表现
在测试数据集上进行验证的结果见表4。可见,该模型的整体准确率(Accuracy)为76.50%,并且在精度(Precision)、敏感度(Sensitivity)、特异度(Specificity)、准确率(Accuracy)四个指标均表现尚可,可以认为该模型的性能能够有效地通过患者常规检验指标预测其罹患心血管疾病的风险。

表4 模型验证结果(混淆矩阵)
2.2 指标分析结果
完成SHAP值的计算后,随机输出其中一例患者的SHAP值,结果见图1。该患者的模型预测结果为阳性,实际结果为确诊,与预测结果一致。图1中,Base value为模型基准值,即样本整体平均值。模型输出值(Model output value)为4.13,是该患者各项指标输入模型后得到的最终结果,高于0.5则会预测为阳性。模型的输出结果和基准值之间存在差异,这个差异是各个特征参数的共同作用导致的,而每个特征的SHAP值大小就是该特征参数对这个差异的贡献大小。

图1 某患者的Shap值结果
图中红色部分为对预测结果产生正向影响的指标,蓝色部分为产生负向影响的指标。其中影响力最大的3个指标分别为ap_hi(收缩压)=170 mmHg,cholesterol(胆固醇)=严重偏高,BMI=28.04。可以看出:该患者收缩压远高于健康范围(<120 mmHg)导致心血管疾病风险大大增加;其次是胆固醇严重偏高和BMI过高,都导致心血管疾病风险激增。
SHAP值的绝对值代表该特征的重要性。对各特征的SHAP值重要性数据进行汇总,输出排名前20的特征,结果见图2。其中前面3个最重要的指标分别为:收缩压、年龄和BMI。将每个样本数据点的SHAP值按照指标进行统计,可以输出SHAP值相对于指标值的变化趋势。以收缩压和年龄为例,其SHAP值的变化趋势见图3~4。
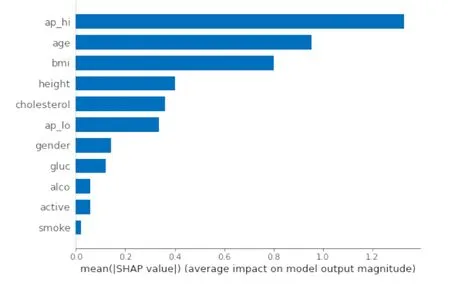
图2 基于Shap值的模型特征重要性(前20)

图3 收缩压的SHAP值趋势图
分析收缩压和年龄的SHAP值趋势图,可以总结如下经验规律:①收缩压在135 mmHg以下时,心血管疾病风险降低,并且收缩压越低风险越低;超过136 mmHg时,心血管疾病风险急剧上升;②年龄在46岁以下时,心血管疾病风险降低,并且年龄越低风险越低;超过46岁开始出现心血管疾病风险,但是并不规律,可能需要综合性别等因素综合考虑。这一点与Framingham量表的年龄指标评分标准接近:年龄在44岁以下时,心血管疾病风险降低,并且年龄越低风险越低。
3 讨论
以2014年为例,我国居民死因构成显示,城市和农村的心血管疾病病死率均超过40%,平均为43%,居疾病死亡构或首位[11],并且围手术期死亡率较高[12],如能早期发现则可以有效提高患者生存率。并且,随着医院信息化程度提高和业务数据越来越多,需要有效利用这些数据为临床医护人员日常工作提供有力支持[13]。利用信息系统的一些常规指标数据,进行基于Xgboost机器学习算法训练,可以获得具有参考价值的疾病风险预测模型;完成模型训练后,通过可解释性方法对模型指标进行量化分析,可以总结归纳各指标的影响规律。此外,通用风险评估工具可能由于心血管疾病谱、危险因素流行情况等的差异,无法适应本地人群,因此基于本地人群的临床数据构建定制化的风险预测模型有重要的现实意义和应用价值[14]。
可以预见,随着机器学习技术发展的深入和引用的普及,各类基于机器学习使用临床数据训练得到的疾病风险预测模型将越来越常见。机器学习模型的可解释性可以使预测模型透明化并发掘其中经验规律和临床知识[15],从而有力推动人工智能领域研究的发展并应用到各个传统领域中。

图4 年龄的SHAP值趋势图
