联合图嵌入与特征加权的无监督特征选择
2021-07-27张圳彬
张 巍,张圳彬
(广东工业大学 计算机学院,广东 广州 510006)
伴随着信息科技的飞快发展,在许多热点研究领域, 如图像、声音、文本、视频和基因工程等,人们通常需要面对体量庞大的高维度数据[1-2]。为此,降维方法中的特征选择(Feature Selection)是处理此类数据的常规方法。根据某些指标,在不改变数据原始表示的前提下,特征选择从高维数据中挑选信息量最为丰富的维度构成特征子集,该过程各特征原始物理意义将得到维持[3],因此降维结果具备很好的解释性。在大部分情形下对全部特征进行采集将会是极其耗时耗力高开销的或者是不可能的[4-5],特征选择只针对选择的特征进行采集,故特征选择能减少待处理的数据量,有助于进一步分析处理数据。
依据标签信息是否可用,特征选择方法可分类为:无监督(Unsupervised)、半监督(Semi-supervised)和有监督(Supervised)方法[6]。因为现实大部分数据缺乏标签,对数据添加标签费力费时[7]。标签信息的缺乏使无监督学习难于其他两者。无监督特征选择可进一步分为3类:过滤式(Filter)、包裹式(Wrapper)和嵌入式(Embedding)[8]。此处主要介绍嵌入式。嵌入式方法将数据分布先验等数据属性纳入考虑,因此大多数情况下可以获得较优的特征信息。由于无监督特征选择具备捕获数据隐藏结构如局部流形结构和全局结构等的能力[9-10],因此捕捉学习前者结构的嵌入式无监督特征选择通常能得到良好的效果[11]。
目前特征选择方法大多数采用嵌入式无监督的方式构建模型,但其中有些方法使得降维后的低维子空间特征判别性不强且存在冗余,导致选择的特征不具有较强的代表性,影响模型的性能。本文通过将自适应图嵌入学习获得的聚类指示矩阵在回归中进行拟合,并对低维的投影子空间施加正交约束,以此选择出判别性强且非冗余的特征,并通过一个表征特征重要程度的特征权重对角矩阵,进行特征选择并形成特征子集,进行后续任务处理。
1 国内外研究现状
国内外学者对于无监督特征选择方法进行了各种各样的探索。Cai等[12]提出多簇特征选择(Multi-Cluster Feature Selection, MCFS),使用l1范数正则化来维持数据的自然聚类的多簇结构;Qian等[13]提出鲁棒无监督特征选择(Robust Unsupervised Feature Selection, RUFS),在无监督聚类标签学习和特征学习过程同时利用最小化l2,1范数达到特征选择的目的;Hou等[3]提出了联合嵌入学习稀疏回归(Joint Embedding Learning and Sparse Regression, JELSR),使用谱聚类进行数据聚类结构学习,并使用系数回归在同一过程完成特征选择;Li等[14]提出了非负判别特征选择(Nonnegative Discriminative Feature Selection, NDFS),通过联合非负谱分析和稀疏回归统一学习以得到预想特征子集。
相较于以往方法,上述方法效果得到提升,但在降维过程中没有考虑对学习的投影子空间施加正交约束,以减少冗余特征的影响,提高选择特征的判别性。因此本文通过图嵌入局部结构学习,对数据间的相似图进行自适应调节,并将学习到的聚类指示矩阵作正交回归拟合,最后通过权重矩阵选择出判别性特征,该过程统一局部结构学习和特征选择在一个无监督框架中同时进行。
2 相关技术

2.1 图嵌入局部结构学习
根据局部距离,图嵌入局部结构学习为各个数据点自适应分配最优近邻,以此来学习相似度矩阵,并挖掘潜在几何结构。
本文采用欧氏距离作为距离度量,默认向量为列向量。已知数据集X=[x1,x2,···xn]T∈Rn×d,其中n,d分别表示样本数和特征维度;S∈Rn×n表示相似度矩阵,其元素sij表示xi,xj之间的相似度,si∈Rn表示xi与全体样本的相似度;DS表示关∑于S的度矩阵(Degree Matrix),其第i个对角元素为j(si j+sji)/2,LS=DS-(S+ST)/2 表 示关于S的拉普拉斯矩阵(Laplacian Matrix)。

由于S与LS,DS直接相关,式(1)中的秩约束难以求解。Nie等[15]根据r ank(LS)=n-c,等价于理想情况下LS具 有前小c个 和为0 的 特征值,记σv(LS)表 示LS前小v个特征值,并由樊畿定理(Ky Fan's Theorem),得式(2)。
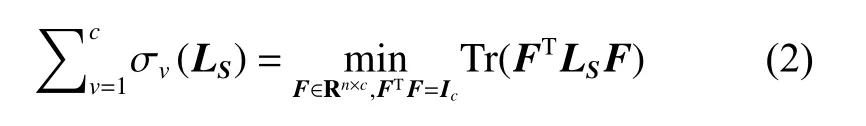
其中,Ic为 单位矩阵,规格为Rc×c,F表示样本的低维嵌入,将式(2)迹约束替代式(1)秩约束,以便于求解,最终如式(3)所示,其中α ,β均为正则化参数。

2.2 特征加权正交回归
为了在投影子空间中保留关于数据样本更多的判别信息[16]并避免平凡解[17],对最小二乘回归(Least Square Regression, LSR)模型中的投影矩阵施加正交约束,得到正交回归模型(Orthogonal Regression)。对于该模型,W∈Rd×c表示投影矩阵,b∈Rc表示偏置向量,Y∈Rc×n表示数据样本标签矩阵,如式(4)所示。

3 JGEFW模型
3.1 模型构建
将式(3)与式(5)联立,得到本文的目标函数,参见式(6)。式(6)将图嵌入局部结构学习与特征加权正交回归结合起来,获得一个统一的目标函数。其中:第一、二部分为图嵌入局部结构学习,自适应学习局部流形结构,即数据样本间的相似度矩阵;第三部分约束学习到的数据之结构图的连通分量个数与自然聚类的簇个数完全相等,以学习到更好的数据样本图结构;第四部分将局部流形结构学习得到的聚类指示矩阵在正交回归中拟合并获得权重矩阵。
进行联合学习是为了保留更多的判别信息并得到表征各个特征重要性的权重矩阵。整体框架模型参见式(6)。
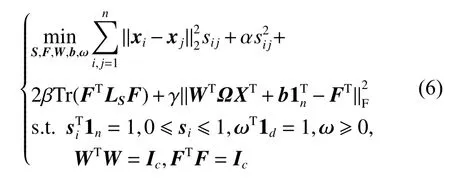
3.2 模型求解
根据变量b的极值条件,有b=(1/n)(FT1n-WTΩXT1n) ,其中H=In-(1/n)1n1Tn∈Rn×n为中心化矩阵,故目标函数可简化为

原问题转换为

其中, d iag(ϱ) 表示以向量ϱ 的元素为对角元素的方阵。由增广拉格朗日乘子法[18](Augmented Lagrangian Multiplier Method, ALM),可求解得ω 。

重复步骤①~③直到收敛。
基于上述算法,交替更新F,S,W,ω,直到收敛。
4 实验
为验证本文提出的JGEFW的有效性,根据文献[21]将JGEFW与几种常见的无监督特征选择算法,包括拉普拉斯分数(Laplacian Score, LS)、多簇特征选择(MCFS)、无监督判别特征选择(Unsupervised Discriminative Feature Selection, UDFS)、双自表示和流形正则化的鲁棒无监督特征选择(Dual Selfrepresentation and Manifold Regularization, DSRMR)以及包含所有特征的基线模型(Baseline)进行对比。
根据文献[21]选择在4个公开数据集YALE、TOX、ISOLET和COIL上进行比较,且设定选择特征数范围均为{ 20, 30, 40, 50, 60, 70, 80, 90, 100}。对于不同的选择特征数均采用30次k均值(k-means)聚类取平均值以减少随机效应的影响,并记录各评估指标的最优结果来表征对所选择的特征的评估。实验设备具体配置为Core(TM) i9-9900K CPU@3.60GHz,RAM 32GB。
4.1 评估指标
实验评估指标包括聚类准确率(Accuracy, ACC)和标准化互信息(Normalized Mutual Information,NMI)。这两者取值范围均为[ 0,1],且数值越大代表聚类效果越好。

4.2 数据集介绍
实验采用的4个公开数据集简介,如表1所示。

表1 数据集简要信息Table 1 Brief information of datasets
YALE数据集属于人脸图像数据集,其包含15个人共165张的灰度图像,每个人包含11张不同面部表情和环境的图像,包括中心光、左光、右光、快乐、正常、悲伤、困倦、惊讶、戴眼镜和眨眼[23]。
TOX数据集属于生物数据集,共包含4个类别的171个样本,每个样本维度为5 748维。
ISOLET数据集是从30个测试者每人读出两次全部英文字母收集而来,样本共1 560个,维度为617。
COIL数据集包含1 440张图像,共20类物品,每个物品有72张图像,其来源于相机以固定间隔5°的角度拍摄得到每类物品的图像,裁剪大小为32×32像素,故维度为1 024维。
4.3 各算法参数设置


4.4 实验结果与分析
4.4.1 评估指标最优结果
表2~3分别展示几种无监督特征选择算法在各数据集上,经参数搜索后选取最优参数且选取各特征选择数情况下的最佳聚类结果及相应的标准差,同时表2~3最后一行为各个算法在全部数据集上的平均聚类效果。表中加粗项表示在该数据集效果最优,下划线项表示在该数据集上效果次优,对比算法结果均由文献[21]给出。

表2 几种无监督特征选择算法在各数据集聚类准确率(%)± 标准差(%)比较Table 2 Results on clustering evaluation metric of ACC(%)± std(%) of all compared unsupervised feature selection methods on all datasets
由表2可知,本方法在各数据集和平均聚类准确率上效果均为最优,同时在YALE、ISOLET、COIL和平均聚类准确率与次优效果相比均有较大的提升。由表3可知,本方法在YALE上效果为最优,且与次优效果相比有较大的提升,而在TOX、ISOLET和平均标准化互信息为次优,由于Baseline模型对全部特征进行利用而不加以选择,因此对于某些包含噪声和冗余特征较少的数据集而言,该做法有时也能获得较好的效果,但并无包含降维操作。

表3 几种无监督特征选择算法在各数据集标准化互信息(%)± 标准差(%)比较Table 3 Results on clustering evaluation metric of NMI(%)± std(%) of all compared unsupervised feature selection methods on all datasets
4.4.2 评估指标随各特征选择数的变化
图1~2分别表示在不同聚类指标下几种不同的特征选择算法在各数据集上选择不同特征数时的聚类效果。图中横坐标表示不同的选择选择数,纵坐标分别表示以聚类准确率(ACC,%)和标准化互信息(NMI,%)作为聚类指标时的值。由于文献[21]并无给出对比算法在各选择特征数的实际数值,故该部分数据是根据该论文设置,实际运行代码获得的,得到的各对比算法实际最优效果允许与表2~3存在差距。
由图1可知,本方法在YALE上聚类准确率变动较为波动,与其他对比算法情况相似,且在大多数选择特征数范围优于其他对比算法;在TOX上聚类准确率大致呈整体上升趋势,且在大多数选择特征数范围效果均优于LS、MCFS和DSRMR;在ISOLET上随着选择特征数增加,效果大致呈上升趋势,与大多数对比算法变化趋势一致,且在选择特征数为 90时聚类准确率为所有对比算法下的最优;在COIL上随着选择特征数增加,聚类准确率在多数选择特征数范围均优于其他对比算法,且在选择特征数为 70时聚类准确率为所有对比算法下的最优。

图1 各数据集几种算法不同特征选择数的聚类准确率(%)比较Fig.1 Results on clustering evaluation metric of ACC (%) of different numbers of selected features of all compared unsupervised feature selection methods on all datasets
由图2可知,本方法在YALE上标准化互信息变动较为波动,与其他对比算法情况相似,但在选择特征数为30时标准化互信息为所有对比算法下的最优,表明JGEFW在选择特征数较小时便能选择出判别性强的信息;在TOX上标准化互信息大致呈上升趋势,与其他对比算法趋势完全不同,且当选择特征数在大于70的范围内,标准化互信息均为所有对比算法下的最优;在ISOLET上随着选择特征数增加,标准化互信息大致呈提升趋势,与其他绝大多数对比算法变化趋势相同,且在选择特征数为100时标准化互信息优于Baseline的效果;在COIL上随着选择特征数增加,标准化互信息在Baseline算法上下波动,表明本算法能有效学习到数据间的潜在几何结构,并对判别力强的特征加以选择。
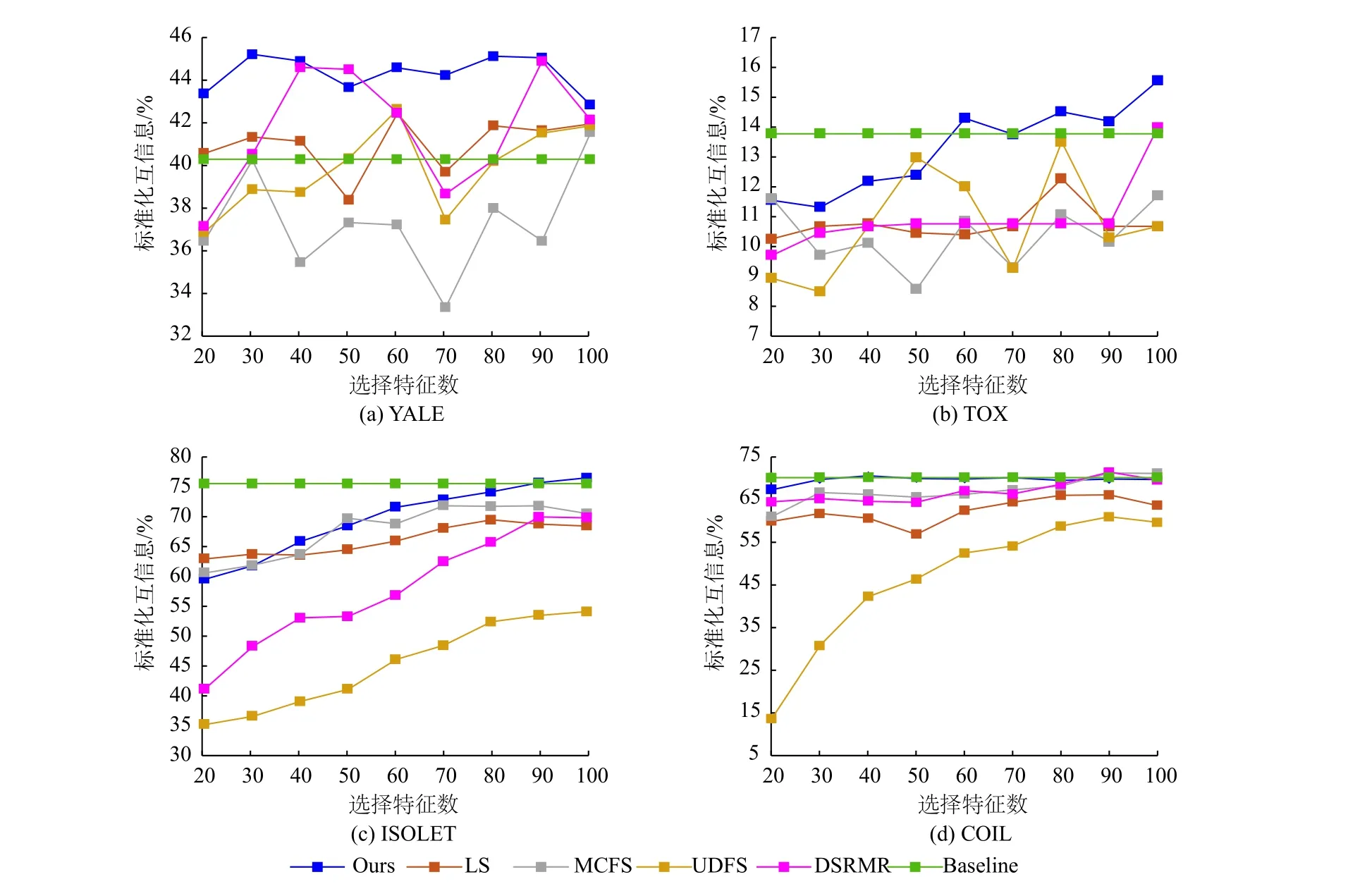
图2 各数据集几种算法不同特征选择数的标准化互信息(%)比较Fig.2 Results on clustering evaluation metric of NMI (%) of different numbers of selected features of all compared unsupervised feature selection methods on all datasets
4.4.3 参数敏感性分析
为探究算法的性能,进行参数敏感性分析实验(Parameter Sensitivity),以考虑各参数变动对模型的影响。此处以COIL数据集为例,在最优聚类准确率效果中先固定 β=10, 变化γ,观察算法的聚类准确率变化,再固定γ =0.1, 变化 β,观察算法的聚类准确率变化;在最优标准化互信息效果中先固定 β=103,变化γ ,观察算法的标准化互信息变化,再固定γ =105,变化 β,观察算法的标准化互信息变化。
由图3可知,JGEFW的聚类准确率随着选择特征数、 β 和γ 的改变略有波动,而JGEFW的标准化互信息则随着选择特征数、 β 和γ 的改变总体上较为平稳,具有一定的鲁棒性。

图3 本方法在COIL的参数敏感性分析实验结果Fig.3 Parameters sensitivity analysis about clustering evaluation metric of the proposed method on COIL dataset
4.4.4 收敛性实验证明
此处以COIL数据集为例,其他数据集上的收敛情况与此相似,目标函数值的收敛曲线如图4所示。由图4可知,随着迭代次数逐渐增加,目标函数值不断减少,最后趋于一个稳定值,表明该算法是收敛的。

图4 本方法在COIL数据集上的收敛结果示意Fig.4 Result of convergence experiments of the proposed method on COIL dataset
5 结束语
本文给出了一种改进的无监督特征选择算法,称为JGEFW。通过局部结构学习自适应地调节数据的相似图,使其满足自然聚类的簇的要求,提高图构造的准确度。并通过加权特征回归的方法,使图构造的聚类指示矩阵在正交回归中拟合以学习权重矩阵,并挑选出权重值大的判别特征和非冗余特征形成特征子集。实验结果表明,JGEFW的性能在平均情况下优于其他对比的特征选择方法。未来工作将尝试提高模型的聚类性能和迭代速度。
