基于姿态表示的航空影像旋转目标检测网络
2021-07-27张国生
张国生,冯 广,李 东
(广东工业大学 自动化学院,广东 广州 510006)
目标检测是计算机视觉研究中的一项基础性任务,随着近些年遥感技术和无人机巡航技术的快速发展,航空影像中的目标检测也逐渐成为一项特定且极具挑战的任务。由于复杂多变的视角,航空影像中的目标通常呈现出拥挤、聚集及旋转等特点,对比于普通场景具有更高的检测复杂度。相关研究[1]表明,用水平边框来表示密集的旋转目标,通常会覆盖过多的背景或相邻的目标区域,如图1(a)和图1(b)所示。然而,传统目标检测旨在检测目标的水平边框,并不能契合航空影像中的旋转目标,因此面向航空影像的旋转目标检测也成为一个研究热点。
传统目标检测方法可分为单阶段和双阶段方法,双阶段方法能实现更高的检测性能但需要更大的计算复杂度,而单阶段方法虽然性能次之,但检测速度更快,易于实现实时检测。双阶段方法可以总结为RCNN(Regions with CNN Features)系列,第一阶段生成一系列区域提案(Region Proposal),然后送入第二阶段的分类和回归网络。例如,Fast RCNN[2]在特征图上提取RoI (Region of Interest)来减小计算量;Faster RCNN[3]提出区域提案网络(Region Proposal Network,RPN)和锚框(Anchor)机制进一步提高检测效率和性能;Mask RCNN[4]用RoIAlign替换RoIPooling来解决边框的量化误差。不同于双阶段方法,单阶段方法省略第一阶段的提案网络,直接进行区域的分类和回归。经典的单阶段方法包括有YOLO算法[5],将检测问题直接转化为分类和回归问题,实现单阶段实时检测并得以实际应用[6],但由于其稀疏监督,对小目标检测并不友好;RetinaNet算法[7]提出Focal Loss来解决单阶段训练过程中正负样本不平衡问题,在样本极端不平衡情况下,依然有所局限。最近单阶段方法尝试利用检测关键点的策略来实现目标检测,并实现了能与双阶段方法媲美的检测性能,如CenterNet[8]通过检测目标的中心点,然后进一步在中心点处回归边框来实现单阶段无锚框检测,得益于其思路简单与对小目标检测友好等特点,逐渐成为一个热点研究。
受益于传统目标检测算法,航空影像旋转目标检测也得到了相应的研究进展。Ding等[9]在Faster RCNN基础上提出RoI Transformer来回归水平RoI和旋转RoI的偏移,实现旋转目标检测;SCRDet[10]利用多维注意力机制(像素注意力和通道注意力)来应对航空影像的复杂背景,并设计了IoU损失函数来进一步提升旋转目标检测的性能;Xu等[11]在水平边框检测基础上,提出Gliding vertex的方法,通过回归顶点在边框方向的偏移比例实现旋转目标检测。虽然以上方法能实现不错的性能,但是它们都是基于双阶段网络的方法,需要更大计算代价,不利于实际应用。为此,单阶段的方法开始尝试。RSDet提出了旋转敏感度误差(Rotation Sensitivity Error,RSE)的概念,针对性地设计了调制旋转损失函数,有效缓解角度所带来的旋转敏感度误差问题[12];R3Net提出了可旋转的区域提案网络,通过在特征图上裁剪旋转边框区域来生成旋转的RoI[13],以上2个单阶段的方法基于单阶段RetinaNet方法,依赖于对锚框的设计,在密集的小目标检测问题上效果欠佳。DRN尝试无锚框的检测网络的设计,在CenterNet的基础上额外增加一个角度变量进行回归,然而忽略了角度的周期性特点[14]。综上所述,以上方法的不足可以总结为2点。(1) 在基于锚框的方法中,额外的角度变量意味着需要设计不同角度、尺度和宽长比的锚框,极大增加了锚框数量,提高模型计算复杂度,对于单阶段方法,更多锚框则会带来更严重的正负样本不平衡问题。(2) 如图1(c)所示,角度θ为矩形框长边与水平的夹角,(x,y)为矩形框中心点坐标,h和w分别为矩形框的高和宽,角度变量具有周期性。在周期临界点0和π 具有相似的几何外观,但回归变量却发生突变,临界点的突变导致代价函数不连续[14],网络训练不稳定。
针对以上问题,本文提出了旋转目标,基于关键点检测的方法设计了单阶段无锚框的旋转目标检测网络。如图1(d)所示,该网络将旋转目标表示为中心点和4个角点构成的姿态,通过检测目标的中心点位置及回归4个角点相对坐标来实现旋转目标的检测。基于关键点的单阶段无锚框网络有效降低模型计算复杂度,而旋转目标的姿态表示则巧妙避开周期性角度变量RSE[12]问题。为了进一步提高网络性能和训练效率,提出了选择性采样来平衡训练样本前景和背景的比例,缓解正负样本不平衡问题。本文提出基于姿态表示的航空影像旋转目标检测网络,主要贡献如下。

图1 旋转目标的表示方法Fig.1 Representation of oriented object
(1) 提出姿态表示的方法,将旋转目标表示为中心点和4个顶点构成的不同姿态,有效避免周期性角度变量回归问题,且能实现无锚框检测。
(2) 使用了改进的自适应融合的特征金字塔网络(Adaptive Feature Pyramid Network,AFPN),利用可学习权重对不同尺度特征进行加权融合,以数据驱动的方式使网络自动选择更具判别性的尺度特征。
(3) 针对高分辨率的航空影像,提出选择性采样(Selective Sample,SS)策略,有效提高网络的训练效率,同时缓解了训练过程中正负样本不平衡问题,提高了模型的整体性能。
1 本文方法
1.1 整体结构
本文提出的旋转目标检测网络整体结构如图2所示,首先利用HRNet[15]多路并行的高低分辨率分支网络对图像进行多尺度特征提取,相较于高-低-高的特征网络能避免低-高上采样过程空间信息的损失,保留更完整的空间信息,这将有效提高下游网络对目标中心的定位的精度。然后设计了自适应融合的特征金字塔网络,自底向上对高层语义特征不断进行加权融合,得到了自适应融合特征。最后2个分支网络是本文提出的姿态表示的旋转目标检测网络,上分支用于目标中心的定位,下分支根据上分支定位中心进行回归顶点偏移,从而实现旋转目标的检测。
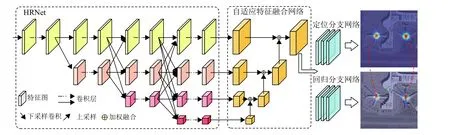
图2 本文网络整体结构Fig.2 The overview of proposed network
1.2 旋转目标的姿态表示
如图1(c)所示,基于水平边框和额外角度变量表示的方法会带来周期临界点混淆问题,即角度变量θ在0和π 具有相似的几何外观,但却要求回归不一致的角度值,所以难以直接进行线性回归。本文提出利用绝对的中心坐标加相对的4个顶点坐标构造的姿态图来表示旋转目标,巧妙避开了周期性角度变量。给定旋转目标顶点的绝对像素坐标{ (xi,yi)|i=1,2,···,k},k为目标顶点数量。当目标为四边形时k=4。为了统一表示旋转目标绝对位置坐标,本方法额外计算目标的中心点,根据外接水平矩形的中心点来表示姿态的绝对位置,并以此作为每个旋转目标顶点的参考坐标系原点,计算为

因此,如图1(d)所示,根据中心点坐标,可以得到每个顶点的相对坐标,旋转目标的姿态表示为pose=(v1,v2,v3,v4,p) ,其中vi=(xi-px,yi-py)。
如图2所示,本文设计的姿态表示的旋转目标检测网络包括中心点定位分支网络和偏移回归分支网络,前者输出每个类别0~1分布的热图估计值Yˆ ∈[0,1]WHC,其中W,H,C分别表示热图的宽、高和类别数量。Yxyc=1表 示对应位置为目标中心,Yxyc=0表示背景。定位分支网络利用训练标签得到的标签热图Y∈[0,1]W×H×C进行监督训练,使定位分支网络实现中心的定位预测,其中标签热图中的每个点由二维高斯图和标签中心计算得到,如式(2)、(3)所示。

其中 σ2p是与目标尺寸相关的标准差,Yxyc为Y的分量,同时原素图像坐标会根据网络的下采样率d进行相应缩放。最后利用改进的Focal Loss进行定位分支网络的训练,代价函数Lcenter为
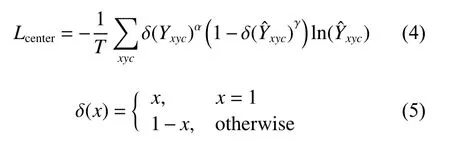
其中γ 为Focal Loss的超参数,Yˆxyc为Yˆ的分量,超参数α用于控制中心点附近的惩罚力度,T为目标总数量,本文实验采用和CenterNet相同的设置, α =4,γ=2。Lregress为


最终本方法将2个分支网络代价函数进行加权得到整体网络的代价函数L为
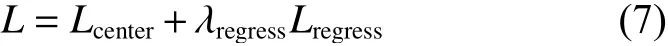
其中 λregress回归分支网络代价函数的权重超参数,本文实验中设置 λregress=0.1。旋转目标检测网络的2个分支网络均由3 ×3的卷积层和ReLu函数构成。
1.3 自适应融合特征金字塔网络
本方法利用HRNet作为特征提取网络,输出多个不同分辨率且不同尺度的特征 {Fi|i=1,2,···,k},其中HRNet中k=4。深度网络学习过程中,不同网络深度的特征具有不同的感受野,浅层高分辨率特征偏向于学习低层次的纹理特征,而深层高宽度特征偏向于学习高层次语义特征,所以应对尺度不一的目标检测任务一般需要进行多尺度特征融合。传统的特征金字塔网络FPN[16]对低分辨率特征进行上采样然后直接进行一致性相加融合。区别于一致性相加融合,本文提出假设,认为不同尺度特征对融合特征具有不同的贡献度,因此采用数据驱动的方式,使网络在学习过程中利用可学习权重 βi∈[0,1]动态地学习不同尺度特征的重要性,自底向上对不同尺度特征进行加权融合,融合策略如式(8)。

其中U(·)表 示双线性插值的上采样操作,Mi为第i个融合特征,C onv(·)为卷积1×1操作。值得注意的是,当将可学习权重设置为常数0.5时,本文提出的自适应特征金字塔网络可以退化为一般形式的特征金字塔网络,可见本文提出的自适应融合的特征金字塔网络具有一般化特点。
1.4 选择性采样



为了推导采样总数与上限重叠度m的关系,已知

将式(11)代入式(9)可得


图3 滑动窗口均匀采样Fig.3 Evenly sampling by sliding window
由此可见,这样的滑动窗口均匀采样策略会给网络训练带来2个问题。
(1) 如图4所示,当滑动步长很小 (上限重叠度很大)时,滑动窗口采样会得到大量的图像块,且其中大多数不包含任何目标,降低了网络训练效率。
(2) 均匀样策略生成大量包含极少目标的图像块,这些图像块大部分像素为背景,这会给前景背景分类网络训练带来正负样本不平衡问题。
虽然本方法采用了Focal Loss来解决前景背景网络正负样本不均衡问题,但若训练样本正负比例严重不平衡时效果也是有限的。因此,本文从原始训练数据的采样策略着手,创新性地设计了选择性采样策略,根据训练样本提供的标签来提供选择依据。具体算法流程如图5所示,给定输入参数,首先同样采用滑动窗口的形式生成一系列采样候选区域,然后根据采样候选区域中的标签边框总面积来为每个采样候选区域设定分数,最后根据给定的分数对所有采样候选区域进行非极大值抑制(Non-Maximum Suppression,NMS),选取高分数的采样候选区域作为最终的训练图像块。为了定量衡量采样结果,定义了采样区域的目标占有率 ρ来刻画训练正负样本比例,即采样区域前景所占有像素面积的比例为

图5 选择性采样算法流程图Fig.5 Flow chart of selective sampling

其中D为采样图像块的总数,Di为 第i个采样图像块Pi内标签边框数量,Bj为 第j个边框,a rea(·)为计算给定区域像素面积函数。如图4所示,滑动窗口均匀采样策略无论采样密度(滑动步长或上限重叠度)多大,采样区域目标占有率几乎不变,这是因为均匀采样等价于随机抽样过程,所以采样区域目标占有率会等于原图像的目标占有率。相反,选择性采样策略根据样本的真实标签进行选择性采样,可以通过调节采样上限重叠度,得到更高的目标占有率,从而有效缓解训练样本正负比例不均衡问题。
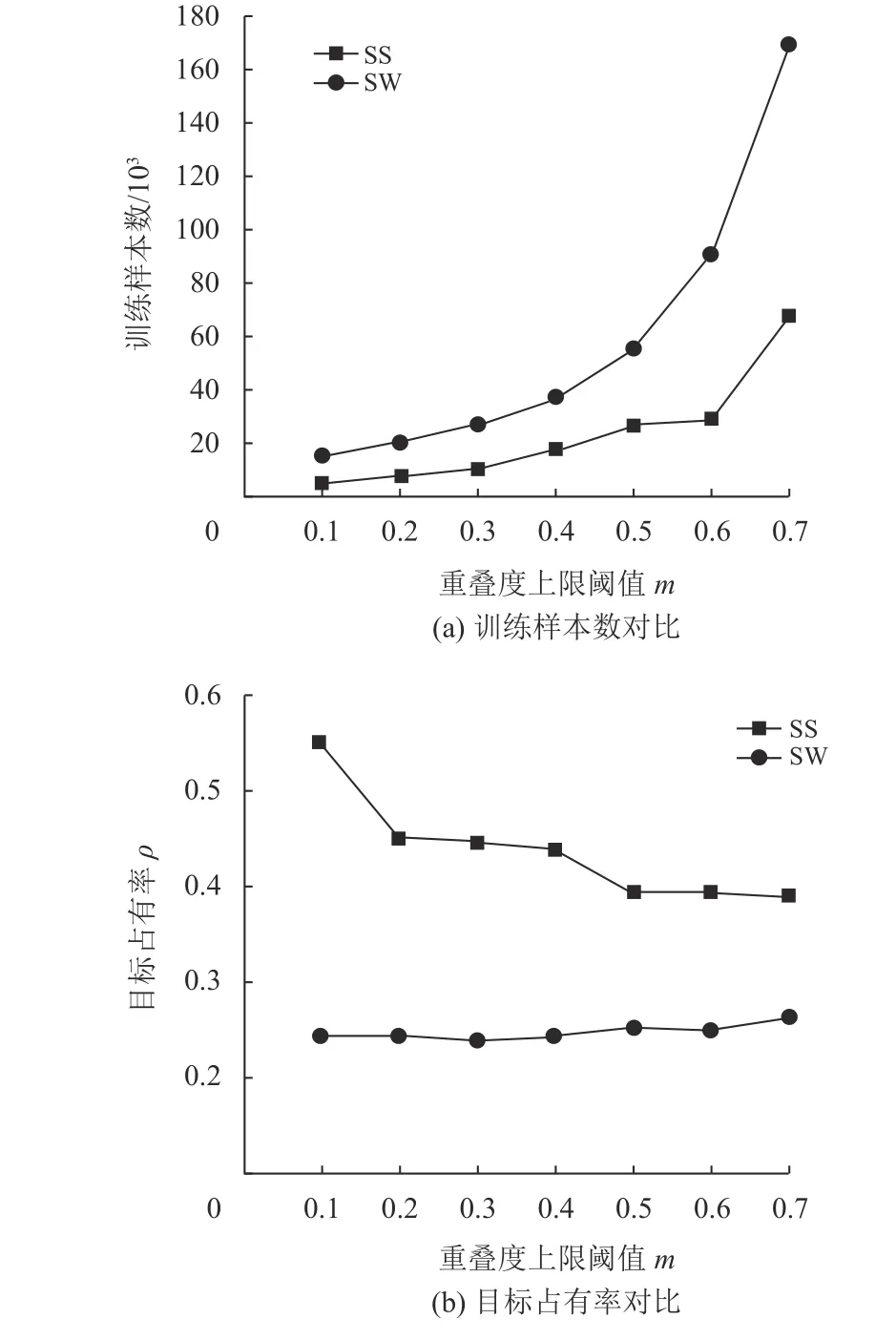
图4 采样方法对比Fig.4 Comparison of sampling methods
2 实验分析
2.1 数据集与实验设置
为了充分验证方法的有效性,本文选用了2个航空影像数据集:遥感图像数据集DOTA[1]和无人机航拍数据集VisDrone[17]进行实验。
DOTA是航空影像目标检测的基准数据集,包括有2 806张高分辨率遥感图像(训练集有1 409张,验证集548张,测试集有942张),高分辨率最大可达5 000 ×12 000。数据集有15个目标类别(类别简称对应:飞机-PL,棒球场-BD,田径场-GTF,小型车-SV,大型车-LV,船舶-SH,网球场-TC,篮球场-BC,存储罐-ST,足球场-SBF,环形路-RA,港口-HA,泳池-SP,直升机-HC),总共有188 282个标注实例,每个标注实例均为旋转的四边形。之前非姿态表示的方法均为假设四边形为矩形,这个近似假设也会带来精度损失。使用了选择性采样策略之后,在上限重叠度0.36下总共得到12 964个1 024 ×1 024图像块作为训练样本。另外数据集的度量标准是采用经典通用目标检测数据集PASCAL VOC[18]一样的度量标准。
VisDrone是一个大型的无人机航拍数据集,包括有10 209张航拍图像(训练集6 471张,验证集548张,测试集3 190张),航拍图像目标高度拥挤和密集,总共包括有约46万标注实例,甚至超过通用目标检测基准数据集MS COCO数据集[19]。标注类别包括有行人车辆等10类。度量标准采用了MS COCO数据集计算平均精度(mean Average Precision, mAP)的标准,同时计算重叠阈值分别为50和75的精度(Average Precision, AP)AP50和AP75。
本文实验的实现配置包括Python编程语言、PyTorch深度学习框架、单块NVIDIA Tesla V100 32 GB GPU。对于采样区域尺寸,DOTA(VisDrone)数据集图像裁剪成1 024 ×1 024 (1 024 ×768)的图像块,网络训练和测试时,为了减小计算量,进一步下采样到768 ×768 (1 024× 768)大小。由于测试集没有标签,所以本文采用了512步长的滑动窗口均匀采样的策略,最后将每个图像块的检测结果合并到原来图像上。网络训练使用的数据增强包括随机裁剪、随机翻转、随机旋转以及随机对比度增强。本文骨架网络HRNet加载了ImageNet预训练的权重,优化器选择了Adam优化器,且总共迭代了8万次,学习率开始设置为10-4,在4万次迭代之后下降为原来的10%。最后本文将测试集检测结果提交到数据集官方评测服务器进行评测,得到最终实验结果。
2.2 对比实验分析
本节将对所提方法在2个航空影像数据集的实验结果进行对比分析,通过与现有方法对比发现,所提的选择目标检测网络实现了优异性能。
表1展示了在DOTA数据集检测的各类别详细结果,本文方法平均精度达到74.9%,超过了现有大部分一阶段方法及部分二阶段的方法。同时可以发现本文方法在拥挤、聚集的类别上,如车辆、船舶等取得最佳检测效果,这充分说明本文设计的基于关键点无锚框的方法能有效避免因锚框分布密度不足导致密集小目标漏检的问题,证明了本方法对拥挤、聚集小目标检测的友好性。值得强调的是,在直升机类别检测中,虽然其样本数量在整个训练样本中最少,即处于严重类别不平衡情况,但本文方法依然能取得最好的检测精度,说明其能很好应对类别不平衡问题。

表1 DOTA 数据集检测结果Table 1 Detection results on DOTA dataset %
如表2所示,在VisDrone数据集检测中,本文方法在验证集上平均精度达到33.81% 。本文实验将VisDrone数据集标签水平边框视为特殊的旋转四边形(旋转角均为0°),实验结果也充分说明了本文方法在通用的航拍影像中也能实现极佳的检测效果。图6展示了在拥挤、旋转等复杂场景下的检测效果。

图6 检测结果可视化Fig.6 Visualization of Detection results

表2 VisDrone 数据集检测结果Table 2 Detection results on VisDrone dataset %
2.3 消融实验分析
为了验证本文每个技术策略,在DOTA验证集上做的一系列消融实验,如表3所示,打勾代表使用了该方法,实验结果证明了每个方法的有效性。

表3 消融分析实验结果Table 3 Results of ablation studies
(1) 自适应融合特征金字塔网络(AFPN)。本文通过增加可学习的权重,将传统的特征金字塔网络改进为一般化形式,利用可学习权重,使融合网络能够动态地学习不同尺度特征的重要性。同时,融合特征在进行1× 1卷积之前根据式(3)进行归一化。为了对比分析,先使用传统金字塔特征网络作为基准模型进行使用,然后再使用改进的自适应特征图融合网络进行实验,如表3所示,mAP从71.57% 提升到72.87%。为了进一步验证,本文将自适应特征融合网络的学习权重重置为0.5,实验发现性能有严重下降,这说明了不同尺度的特征对融合特征具有不同的贡献度,学习到的权重能自动引导融合网络选择更具判别性的尺度特征。
(2) 选择性采样(Selective Sample)。本文选用滑动窗口均匀采样策略作为对比基准,如表3所示,在使用选择性采样策略之后,网络的整体检测平均精度提升2.07%,结合自适应特征融合网络后,最终在验证集上平均精度达到75.17%。同时,为了进一步验证方法的有效性,本文通过开源代码复现了R3Det的方法,在仅增加选择性采样策略之后,网络检测的平均精度提高了0.80%,说明选择性采样策略能无代价提升模型性能。
3 结语
本文提出了一种单阶段无锚框的航空影像旋转目标检测网络。为了解决周期性旋转角度难以表示问题,提出了旋转目标姿态表示的方法,将旋转目标视为一个中心点和4个顶点构成的不同姿态。同时,本文创新性地使用了自适应特征融合网络,能够自动地选择更具判别性的尺度特征。为了进一步提升网络的训练效率和性能,提出了选择性采样策略。对比实验证明了本文方法能有效实现良好的检测效果。但在实验中发现本方法在大尺度目标检测上效果欠佳,通过分析认为是由于缺少锚框提供先验信息,对顶点偏移的回归存在较大误差,特别是对大目标的回归,因此在未来工作中,将进一步思考能否结合关键点和锚框来提升大尺度目标的检测效果。
