改进遗传算法求解基于MPN混流制造车间调度问题
2021-07-27王美林曾俊杰成克强陈晓航
王美林,曾俊杰,成克强,陈晓航
(广东工业大学 信息工程学院,广东 广州 510006)
混流制造(Hybrid Flow Shop,HFS)是一种常用且主流的大批量定制生产(Mass Customization Production,MCP)组织模式,可以通过定制阶段并行机上的工艺参数满足客户多样化的产品需求。HFS本质上是一个NP-Hard难题[1],而其系统规模大、资源约束多的特性,导致了解空间过大难以求解的问题。
国内外很多研究团队对混流制造的调度问题进行了深入的研究。何军红等[2]针对在MES系统(Manufacturing Execution System,MES)生产调度模块的柔性作业车间问题,提出了3个阶段的优化调度算法,对具有10个库所、6个工件的HFS问题进行求解。王秀萍[3]针对柔性车间提出一种具有优先级的启发式算法,能够对10个库所、10个工件的问题求解。而何涛[4]针对智能制造柔性车间采用了改进过的遗传算法,将机器的选择与工件的顺序进行分段,对6个库所、4个工件的加工问题进行求解。在求解调度问题中,研究人员尝试了各类智能算法。如黄亚平[5]在基于汽轮机的智能调度系统上采用改进的蚁群算法解决生产调度问题,在调度任务发生变化时快速地根据上次调度结果进行重调度。又如田松龄[6]针对柔性车间,采用异步仿真时钟的蚁群并行搜索算法,减低资源共享型系统的运算成本。白俊峰[7]针对车间调度问题采用包含了精英保留策略与逆转变异机制的遗传算法,其在求解7个工件、5台机器的案例中能够有较好的效果。余璇[8]针对柔性调度问题提出一种混合遗传禁忌搜索算法,对问题模型进行优化并能够在10×10的案例中获得不错的效果。吴大立和田海霖等[9-10]针对Petri网建模的车间作业调度问题,采用数学的方法对染色体编码并提出基于GA(Genetic Algorithm)算法的优化求解。但是以上算法多是针对特定场景较小规模问题进行求解,在面临大规模问题时都无法避免地形成巨大的解空间或陷入局部解。
本文针对HFS大规模HFS系统的调度难题,使用MPN(Manufacturing Petri Net)[11]建模方式进行模型压缩,采用2段编码方式重塑染色体限定搜索范围,用包含粒子群机制(Particle Swarm Optimization,PSO)交叉子、模拟退火机制(Simulated Annealing Algorithm,SAA)变异子与邻域搜索机制的改进遗传算法来改进解搜索方向以优化大规模HFS问题的求解。
1 问题描述
混合流水车间问题可以描述为:一共有n个待加工工件,它们需要经过s道工序进行加工,每道工序会存在Mi台 并行机器(Mi≥1;i=1,2,···,s);同一工序上不同类型的机器加工同一工件的加工时间会有所不同;而且每个工件都要经过每一道工序进行加工;当工件被排产到第i道工序时可以被该工序中的Mi台并行机中的任意一台机器加工;而且车间中的所有机器都是非抢占式。
以图1为例,图1描述了一个包括了2个阶段工序的HFS系统。工序1有M型并行机2台和N型并行机2台,共4台,工序2有H型并行机2台和G型并行机2台一个共4台。对图1中的HFS系统采用MPN模型进行同类并行机压缩建模后,可以将一个4×2的HFS模型压缩成一个 2 ×2的HFS MPN模型,其中资源约束相同的同型设备被建模成MPN中的一个place节点。在MPN模型中,HFS作业的调度问题转换为在制品工件Token,在目标函数监督下,全部从库所p0转移到pl的路径搜索问题。

图1 混合流水车间案例Fig.1 Case of hybrid flow workshop
2 模型构建
2.1 模型建立
本文针对以上基于MPN的HFS调度,为了适应改进GA算法压缩解搜索空间的需求,在MPN的Petri模型基础上,加入用于描述工件加工可选路径的约束和生成作业集约束,避免算法运行时的盲目搜索。模型案例如图2所示。

图2 基于案例的MPN模型Fig.2 Case-based MPN model
本文的MPN模型定义如下[11]:
(1)P={p1,p2,···,pl}是模型中库所的有限集合,表示生产车间中的同类型并行机集合。
(2)E={t1,t2,···,tl}是有限的集合,用于生产状态变化的触发器。
(3)I,O分别表示工件离开库所和进入库所的路径。
(4)S是MPN模型中所有库所令牌的状态向量,Sτ(pi)表 示库所pi在时间τ 时 的所有令牌数量。S0表示MPN的初始状态,Sl表示MPN的结束状态。
(5)K(pi) 是 一个函数表示库所pi内并行机的数量也就是库所的容量。
(6) Θ (θ)={Φ}是工件类型函数,能够计算得出工件 θ的 类 型 集 合Φ ,Φ 表 示 工 件 类 型 的 集 合 即Φ ∈{c1,c2,···,cµ}。
(7)D是各种不同类型的工件在库所中进行加工的时间矩阵。
(8)W(M)是 MPN模型中从库所p0到pl的加工路径所组成的向量集合。r为路径向量的索引。W(M)r表示W(M) 中的第r条路径。如图2所示,其W(M)={
( 9 )Q(θ,pi)={(θ,pi)|θ ∈Order,pi∈P,(θ,pi)∈θ×W(M)r},是表示工件θ 选择了路径W(M)r完成所有操作所产生的作业集合。如工件1选择了2号路径(W(M)2 )则其作业集为{Q(1,p1),Q(1,p4)}。
(10)s((θ,pi))、c((θ,pi)) 分别表示工件θ 在库所pi上的进入时间与离开时间。且s((θ,pi))-c((θ,pi))≥D(Θ(θ),pi)。
(11) Order是进入MPN的一个加工订单,包含了一定数量不同类型工件token集合。
2.2 优化目标

2.3 基于MPN模型的染色体编码
目前处理柔性加工问题的染色体结构有两种,将作业的选择与安排混合考虑[12]或分开考虑[13]。本文采用后者,将一个完整的染色体分为:路径选择段,作业安排段。选择段为染色体的第一段genestring0用于描述约束(式(2))。其余部分为每个工序阶段对应一个安排段,描述每个阶段所有加工作业的优先约束(式(3))和资源约束(式(4))。

以图2的Petri网为例。假定place容量设置为{K(pi)}T={(2,2,2,2)|(i∈[1,4])},Order由4个不同类型的工件组成,表示为 {θ1,θ2,θ3,θ4}、 Φ 分别为{c1,c2,c3,c4}。图3为算法1生成的一个用染色体编码方案。genestring0记录了Order中4个工件分别选择了1,4,4,4号路径,形成了p1作 业的作业集合{Q(1,p1)}、p2作业的作业集合{Q(2,p2),Q(3,p2),Q(4,p2)}、p3作业的作业集合{Q(1,p3)}、p4作业的作业集合{Q(2,p4),Q(3,p4),Q(4,p4) }。g enestring1记 录了工序1库所p1和p2的 工件处理顺序:p1只 有工件1,p2工件处理顺序为2、4、3。
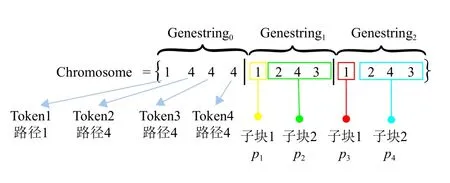
图3 染色体编码结果Fig.3 Chromosome coding results
由染色体的编码算法1,可看出染色体将具体的调度方案分成了选择段与安排段。选择段确定了工件要以经过哪条加工路线的库所完成加工,即每个库所pi会接收到什么作业,而安排段记录库所pi内接收作业的处理顺序。当给出一个D矩阵时,图3中的染色体便能够获得该编码在MPN模型下所有作业的s((θ,pi))、c((θ,pi)),并可以将它们记录在一个schedule中。
3 染色体约束与优化
很多使用染色体对车间问题进行求解时都会采用调整算法去掉部分的无用解[14-15],但由于调整方法简单且无法压缩解空间,所以对本文的大规模HFS问题不适用。在此本文设计了染色体安排段优化算法对染色体(解空间)的编码过程进行补充。
染色体安排段优化算法是在算法1编码的基础上,对pi内接收作业(即其对应安排段)的处理顺序进行有限次数有反馈的调整。反馈机制是寻找拖慢调度的起始作业操作,并调整下次迭代中工序1的相应操作顺序来优化该操作。由于该算法通过反馈解决了调整方向的问题,而且该算法对相同选择段的染色体,执行一定次数迭代调整后,获得唯一最优的染色体安排段。
染色体安排段优化算法2:

4 算法设计
为了探索本文所研究的MPN模型下的HFS问题的优解,提出了一种改进的遗传算法(Improved Genetic Algorithm,IGA)。目前很多的遗传算法都会为其交叉变异添加新的机制[16],但是无法处理大规模问题。本算法结合了3种方法从3个方面解决了遗传算法在求解问题中所遇到的难题。(1) 本文会使用如图4的方式将染色体选择段与适应度进行关联,让遗传算法(IGA)把搜索的精力集中在搜寻最优的染色体选择段上,压缩可行解空间。(2) 本文的算法所使用的交叉子将采用粒子群优化(PSO)机制,而变异子将采用模拟退火算法(SAA)机制,这样的组合有利于改善遗传算法过早收敛的问题。(3) 算法还会对每次迭代的最优个体(Optimal Individual,OI)进行邻域搜索挖掘该个体的“潜力”。
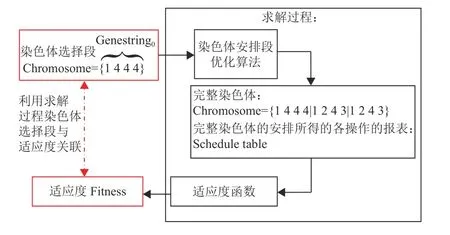
图4 以染色体选择段代替完整染色体与适应度进行关联Fig.4 Using chromosome selection segments to connect with fitness
4.1 以染色体选择段代替完整染色体与适应度进行关联
交叉、变异、邻域搜索的运算只需要使用选择段即可,当需要进行染色体间比较时,染色体能够通过

Cmax为schedule table中最大的值(最后一个作业的完成时间)。
4.2 粒子群算法与模拟退火法在遗传算法上的结合运用
4.2.1 交叉算子
为了提高算法收敛性,本文引入PSO机制(其中GI1表 示guided individual、P I1表示 parent individual1、PI2表示 parent individual2、O I1表示Offspring individual1、 OI2表示Offspring individual2)。它们使用了特殊的交叉方式 (GI1+PI1+PI2→OI1&OI2),从群内个体两两交叉生成两个子代,变为群外一个( GI1)与群内两个( PI1& P I2)个体交叉获得两个子代,保证了后代个体 OI1、 O I2有明确的优化方向,使种群的收敛性提高。
然后为交叉引入k1、k2、L三个变量,k1表示从GI1个 体中学习的学习率,k2表示从另一个父代个体中学习的学习率,L表示选择段的长度。具体交叉方式为(如图5):使用当前迭代所得的最优个体作为引导个体 ( GI1) 并随机抽出两个父代个体(P I1& P I2)。后代 OI1以P I1为 基 础(O I2以P I2为 基 础),并 学 习(L/2)×k1个 GI1的基因,学习方式为直接将选中的基因覆盖在 PI1( PI2)上如图5的黄色基因,然后再学习(L/2)×k2个P I2(P I1)的基因,学习方式为直接将选中的基因覆盖在 PI1(P I2) 上,但不可以选之前在G I1中选中的位置,如图5的蓝色基因。
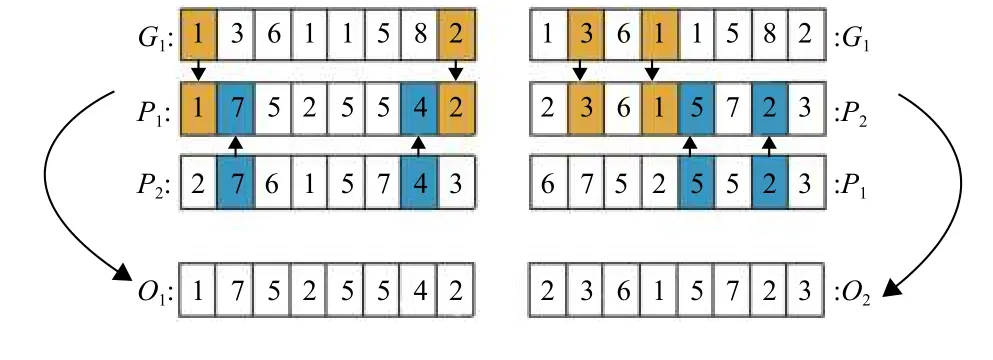
图5 交叉算子Fig.5 Crossover operator
由于PSO机制的添加,引导个体(本群内最优染色体)参与群内交叉能够引导染色体的生产方向,提高收敛性。
4.2.2 变异算子
为了避免遗传算法过早收敛的弊端,本文改进了变异算子,引入新的模拟退火(SAA)机制,使用接收概率实现变异结果的条件接受,使用变异倾向函数实现变异的方向性指导,从而提高未出现基因序列的出现概率。两者组合可以帮助算法跳出局部最优解。
在本节中,变异算子设计如下:
Step1: 在个体中随机选择一个位置。
Step2: 在选择的位置上,通过突变趋势函数(式(6))和(式(7))所得出的可选基因元素(路径)的概率分布,从中按概率选取一个基因值(路径)替换原基因。
Step3:通过模拟退火法的接受概率判断是否接受该变异所得的染色体。
Step4:当代总群中的所有个体都执行过变异后,按照模拟退火中Ta=Ta×K的规则执行退火(Ta为当前温度,K为退火常数),改变温度,影响下一次算法迭代的接受率。
其中,突变趋势函数将对每次迭代后出现在个体上每个位置的值进行计数,并获得在每个位置突变为不同值的相应概率,从而影响个体变异的倾向。

其中 θ ∈{Token},rn∈{Path},N∈|Path|,G为当前的种群代数,G0是开始的种群代数。fs(rn,θ,g)表示在第g代中的所有个体在某个位置(工件θ)上选择了某个基因值(路径rn)的频率。
4.3 邻域搜索摸索最优个体
由于Petri网模型的拓扑结构的原因,Chromosome个体的细微差别,会导致适应度存在巨大差异。为了能够激发当前系统发现的最优个体(OI),在遗传算法执行过交叉与变异后都会进行最优个体邻域搜索。
邻域搜索算法:

其中基本邻域搜索函数是一个输入为最优个体选择段,输出为其邻域(只有一个位置的值与genestring0不同)内的最优染色体选择段。如果邻域内有多个适应度相同的染色体则选择每个工件完成时间的总和最小的个体。
4.4 IGA算法框架
综合上述的算法模块,改进遗传算法的算法流程如图6所示。
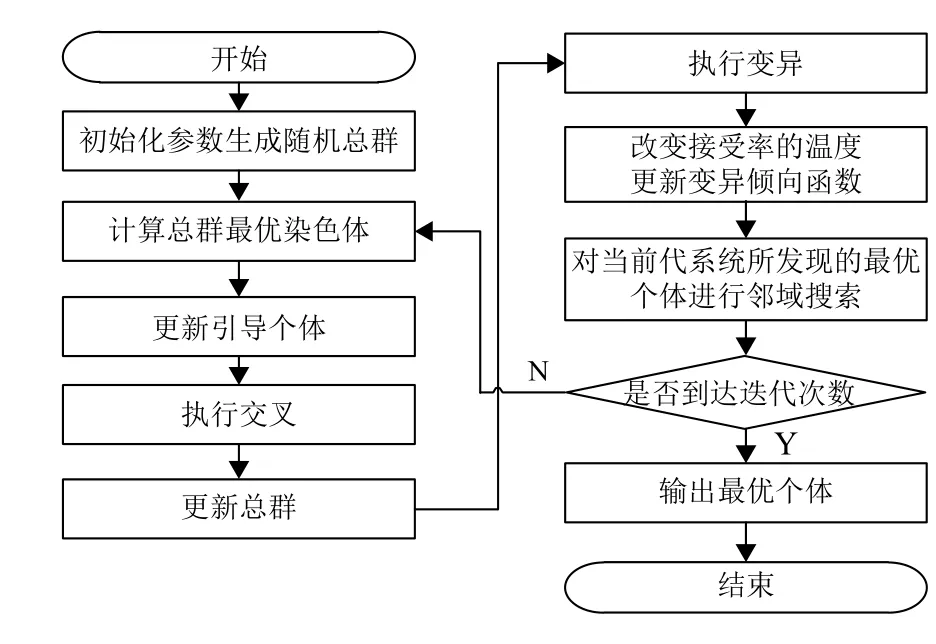
图6 算法流程图Fig.6 Algorithm flowchart
5 实例分析
采用本团队所研究的基于覆铜板层压厂混流加工环境所构建的Petri 网模型为基础[11],并用同样的订单对本文的算法与所采用的模型的论文所提出的算法进行比较。该案例为某覆铜板生产车间案例。
Petri网模型中每个库所的容量参数:

每个种类在库所中的加工时间矩阵D见图7,订单加工内容见表1,其中矩阵行为工件专利,列为库所p0到pl。
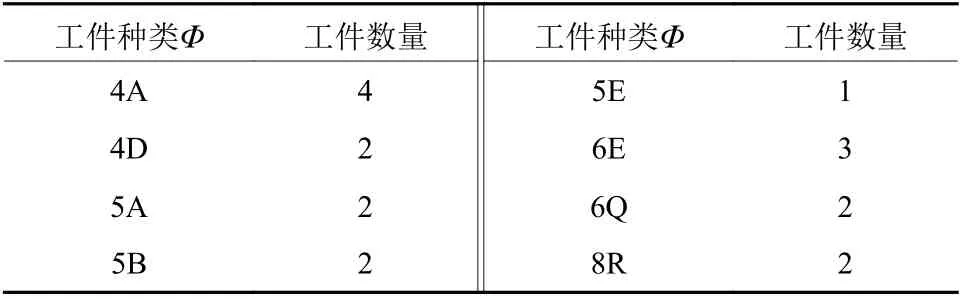
表1 加工订单案例Table 1 Case of processing orders
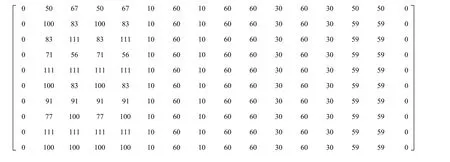
图7 加工时间矩阵DFig.7 Processing time matrix D
5.1 参数设置
可设置的参数一共有7个:交叉率pc,学习因子k1、k2,初始温度T0, 降温次数tn,最优适应度保持不变的最大忍耐迭代数tc,染色体安排段优化算法的参数DN 。最优参数的测试一共分为两组,前6个(pc,k1,k2,T0,tc,tn) 与最后一个参数D N 。前6个参数在D N固定的前提下采用田口实验获得最优的参数。参数 DN在使用之前获得的最优6组参数后采用控制变量测出。
前6个参数的实验范围如表2所示,分别为:pc∈[0.6,1] ,k1∈[0.1,0.5] ,k2∈[0.1,0.5] ,T0∈[50,250],tc∈[5,25],tn∈[5,25] 。水平划分:前6个参数(pc,k1,k2,T0,tc,tn) ,在种群数ps为100,最大迭代数Gmax为250,DN=2的参数前提下按水平划分进行分组测试,不同实验组每组10次实验,并取对应指标的平均值。

表2 前6个参数的实验范围Table 2 The experimental range of the first 6 parameters
从表3得知RA>RE>RB>RD>RF>RC,RA、RB、RC、RD、RE、RF它们分别代表表中ABCDEF列相应因素的级差,级差越大影响越明显(7.8>6.6>6.3>6.1>4.7>3.9) ,所以参数为:pc=0.9,k1=0.5,k2=0.2,T0=50,tc=25,tn=20。

表3 田口实验Table 3 Taguchi experiment
从图8可以获得最终的参数pc=0.9 ,k1=0.5,k2=0.2 ,T0=50 ,tc=25 ,tn=20 , D N=3 , p s=100,Gmax=250。
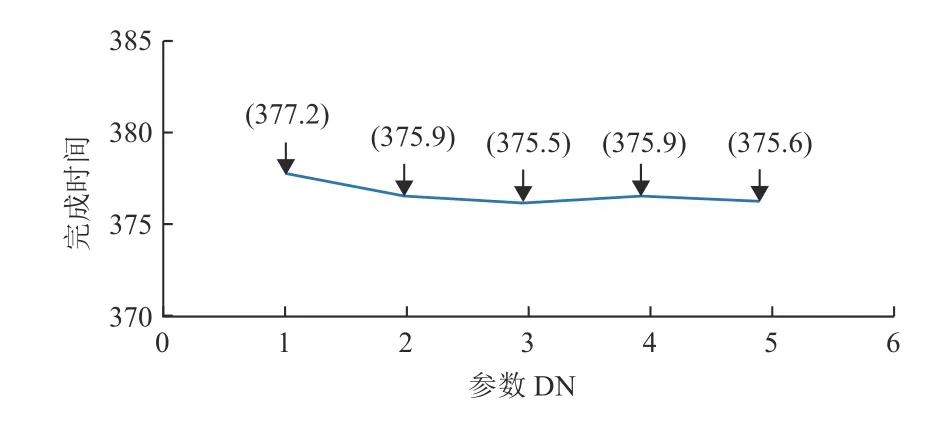
图8 参数DN在之前所获得的最优的参数的基础上对其进行讨论Fig.8 Parameters discussion on the basis of the optimal parameters obtained before
5.2 最优结果
图9中,蓝色曲线所代表的遗传算法使用了具备粒子群优化(PSO)机制的交叉子,而棕色曲线则代表使用了普通交叉子的遗传算法。从图9可知,改进后的交叉子对遗传算法的收敛性有所改善。其曲线所代表的种群内各个体的Cmax值(适应度的绝对值)的均值在大约140代收敛于最优值,收敛性明显提高。普通的交叉子由于HFS问题的巨大规模再加上其轮赌式的交叉规则,使在个体产生细微变化就会导致适应度大幅变化的环境下,却实行无方向式的概率交配。通过给改进遗传算法添加改进的交叉算子,提高了总群后代继承前代优秀基因片段的能力,让算法达到更好的收敛效果。

图9 在250次迭代过程中,种群内个体的均值变化曲线对比Fig.9 Comparison of mean change curves of individuals in the population during 250 iterations
图10代表当前迭代次数出现过的最优个体的Cmax。蓝色曲线代表添加了最优个体邻域搜索,而且使用了具备模拟退火算法(SAA)机制变异子的改进遗传算法,而棕色曲线则代表普通遗传算法。从图10可知,添加了最优个体邻域搜索,而且使用改进的变异子对遗传算法的搜索能力有所提高。对比普通的遗传算法,可以看出蓝色曲线的最优Cmax值为373在大约第77代获得,而棕色曲线的最优Cmax值为390在第87代获得,算法的搜索能力有明显的提高。通过给改进遗传算法添加改进的变异算子,提高了群内个体探索新基因组合的能力;通过给改进遗传算法添加邻域搜索,提高了最优个体主动探索的能力,让算法达到更好的搜索效果。

图10 在250次迭代过程中,最优解的变化过程对比。Fig.10 Comparison of the change process of the optimal solution during 250 iterations.
5.3 效果对比
表4为相同MPN模型下相同案例中,采用文献[11]中的蚁群优化算法、标准遗传算法和采用本文的改进遗传算法进行对比所得的结果。采用改进遗传算法所得出的最优解373明显优于文献[11]蚁群算法中所得出的最优解393与标准遗传算法的523,而且达到最优的次数在100次中出现了83次,优化结果稳

表4 效果对比Table 4 Effect comparison
定。而文献[11]中的蚁群优化达到最优的次数有79次,虽然较为稳定但最优解却只有393。标准遗传算法因为无法适应大规模的混流车间问题,在最优解上只得到了523,到达的次数也只有25次。从中可以看出改进遗传算法相比于蚁群优化算法与标准遗传算法能够获得相对更优的优化结果且达到最优解更为稳定。如图11为案例最优结果甘特图。
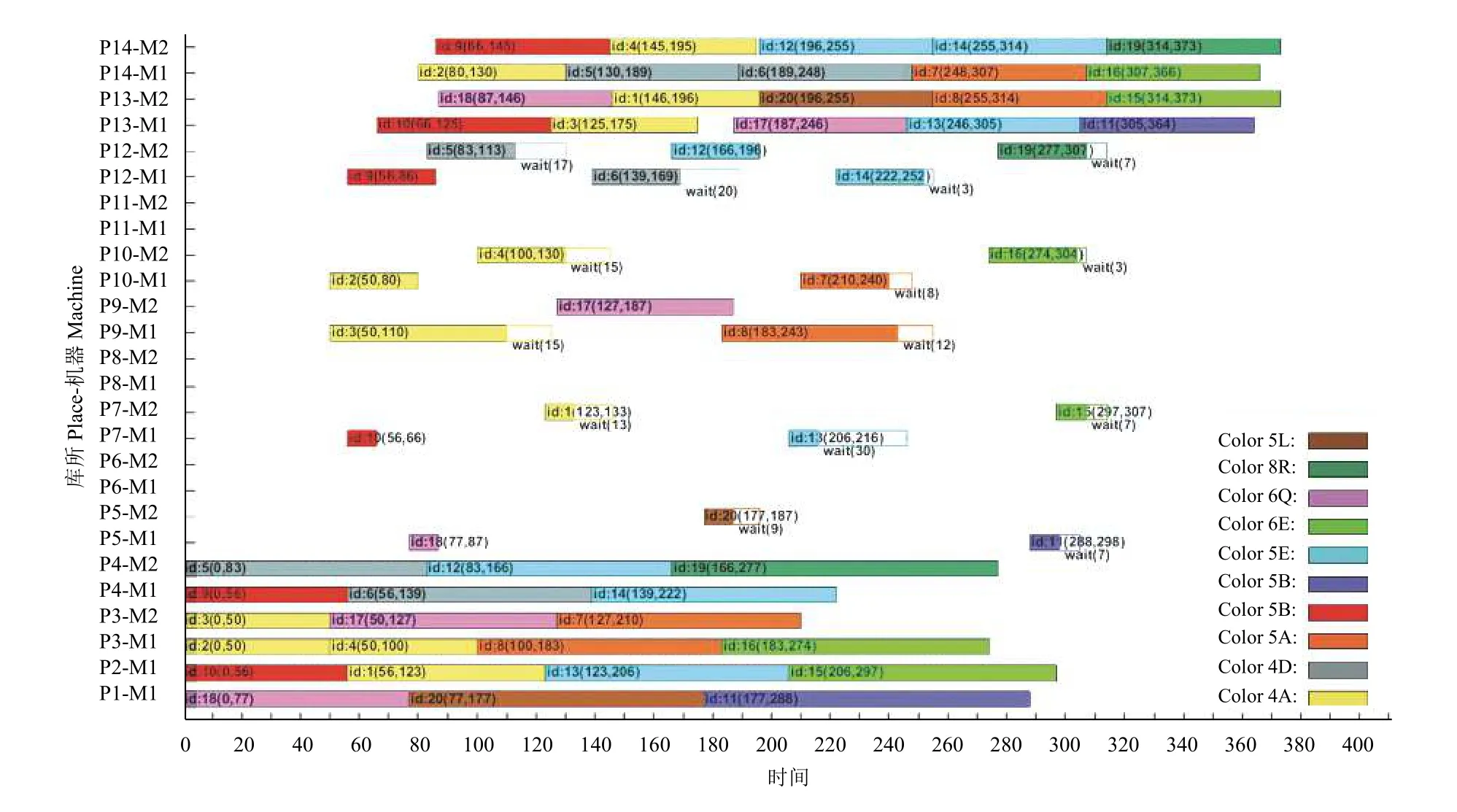
图11 实验结果甘特图Fig.11 Gantt chart of experimental results
6 结论
为了解决基于MPN模型下的混流车间问题,本文采用了一种改进的遗传算法对优化的目标进行求解,并通过实验证明其有效性。最后获得的结论如下。
(1) 在每个染色体进行编码时,利用染色体安排段优化算法对染色体进行补全,并采用固定的求解过程让染色体的选择段与适应度进行绑定,可以有效压缩遗传算法的搜索空间,为HFS大规模问题的求解提供一个缩减后的解空间。
(2) 改进式遗传算法通过染色体进行交叉与变异时,分别使用粒子群与模拟退火的机制,可以提高遗传算法的搜索效率,为求解大规模HFS问题提供优质个体。
(3) 改进式遗传算法通邻域搜索让当前代所得的最优染色体(优质染色体)主动对自己进行优化,实现求解大规模HFS问题的精确搜索。
(责任编辑:杨耀辉)
