基于域对抗学习的可泛化虚假人脸检测方法研究
2021-07-23翁泽佳陈静静姜育刚
翁泽佳 陈静静 姜育刚
(复旦大学计算机科学技术学院 上海 201203)
(上海市智能信息处理重点实验室(复旦大学计算机科学技术学院) 上海 200433)
近年来,随着以深度学习为代表的人工智能技术的发展,人工智能自动生成内容领域取得了显著的进步.基于生成式对抗网络(generative adver-sarial networks, GAN)[1]的图像、视频的生成技术已经开始被应用到社会生活的各个领域,如网络直播、影视创作、电商等.然而,科技是把“双刃剑”,技术的善用可以形成良性的影响,但是技术的滥用将对人类社会和现有的智能系统造成巨大威胁.伴随着互联网的飞速发展和广泛普及,使用深度学习技术生成虚假音频、图片、视频被广泛传播的情况层出不穷,如色情电影换脸、利用伪造生成技术实施诈骗、伪造虚假个人资料的照片用于国际间谍活动等.因此如何判断多媒体内容的真实性成为了一个亟待解决的问题.
相比于其他图像和视频内容生成,虚假人脸生成带来的潜在危害最大,也最容易造成社会的信任危机.因此针对虚假人脸鉴别的研究吸引了国内外学者的广泛关注,成为一个重要的研究方向.目前针对虚假人脸鉴别的研究主要围绕在如何设计一个较好二分类网络,尽可能提高虚假人脸鉴别的精度.现有工作在虚假人脸检测上能够取得一定效果,在训练集和测试集具有非常相近的数据分布的情况下可以达到高达90%以上的检测准确率[2-3].然而,基于传统二分类网络的检测方法的泛化性通常较弱,即当训练集和测试集由于人脸生成方法不同导致分布不一致时,该方法的性能将显著性下降.如图1所示,不同方法生成的虚假人脸图像的分布往往存在较大差异(即域差异),由于已有的方法不能有效学习到对域差异鲁棒的虚假人脸鉴别特征,因此在不同域之间的泛化性往往较差.考虑到在真实应用场景下,虚假图像的生成方法通常未知从而难以保证与训练样本分布一致,因此,为了提高虚假人脸鉴别效果,需要研究具有强泛化性的虚假人脸检测方法.
本文针对基于GAN生成的虚假人脸图像鉴别展开研究,旨在提高鉴别器在应对不同虚假人脸生成器上的泛化性.目前,已有少量工作针对虚假人脸鉴别器的泛化性进行研究.已有工作主要利用数据增强[4](如高斯模糊、JPEG压缩等方式)以及更优的深度鉴别网络设计等方式帮助鉴别器学习到更加鲁棒的特征[5],提高虚假人脸鉴别器性能.尽管这些工作一定程度上提高了鉴别模型的泛化性,然而并没有直接拉近不同GAN生成的虚假图像特征分布.

Fig. 1 Illustration of the generalization problem of fake face detection图1 虚假人脸检测泛化性问题
与上一段方法不同,本文直接从减小不同GAN生成的虚假图像特征分布差异的角度提高鉴别模型的泛化性.为了有效减小不同GAN生成的图像提取到的特征分布之间的差异,本文引入了迁移学习的思想,将不同GAN生成的图像看成不同的域,尽可能降低源域(训练集)特征与目标域(测试集)特征分布之间的差异,使得模型能尽可能学习到与域无关的通用鉴别特征,以此提升鉴别模型在不同生成方法上的迁移性.受无监督迁移学习算法——域对抗神经网络(domain adversarial neural networks, DANN)[6]启发,本文在鉴别模型特征学习的过程中,引入了域对抗模块,以防止鉴别模型过拟合到特定的GAN生成的图像上,从而导致模型泛化性能差.具体来说,本文方法在常规的假脸分类网络的基础上增加一个域分类器,域分类器与虚假图像鉴别器共享同一个特征提取网络.在训练的过程中,通过对虚假图像生成器分类层梯度进行反转,使得特征提取网络学习到与GAN生成方法无关的特征.通过对抗训练的方式弱化特征抽取模型对于特定生成模型非鲁棒性特征的提取,强化不同生成模型之间共同特征模式的抽取,而这样学习得到的分类网络将具有更强的泛化能力,面对新的生成方法产生的图像将会有更好的表现.
本文的主要贡献有3个方面:
1) 创新性地将域对抗思想引入鉴别生成对抗网络伪造图片的任务上,巧妙地利用额外监督信息来约束特征编码模块的训练,以此提升虚假人脸鉴别模型的泛化能力.
2) 鉴于目前没有合适的直接研究迁移性的虚假人脸数据集,本文在Yu等人[7]的研究工作基础上,构建了适合于迁移性探究的数据集.
3) 通过大量的实验,证明了所提出方法的有效性,即通过引入领域对抗训练,能够有效提升虚假人脸检测模型在训练不可见类别上的测试表现,且不会对可见类别的测试表现产生大的影响.
1 相关工作
鉴于虚假人脸生成的潜在危害性,目前已有部分学者对此展开了研究.目前针对虚假人脸鉴别方法主要分为2类:1)针对以深度伪造(DeepFake)为代表的换脸视频进行检测.该类换脸视频通常替换目标视频中人脸的局部区域,达到虚假人脸生成的目的.2)针对以生成对抗网络(GAN)为代表的虚假人脸进行鉴别.不同于换脸视频,生成对抗网络直接通过学习大量的人脸图像分布,直接对整张人脸图像进行生成.下面将针对这2类虚假人脸鉴别方法以及域自适应学习方法进行介绍.
1.1 换脸图像、视频鉴别
目前针对换脸图像、视频鉴别问题,现有工作主要集中于学习具有强鉴别能力的特征,然后以训练二分类器模型的方式实现换脸图像、视频鉴别.由于换脸图像、视频仅对人脸图像局部区域进行操作,因此现有方法通常注重挖掘局部的具有强鉴别能力的特征.例如Yang等人[8]提出提取头部姿势特征,并训练SVM分类器进行换脸鉴别;更近一步地,Agarwal等人[9]提出融合头部姿势面部特征提高换脸鉴别的效果;此外,脸部形变特征(face warping feature)[10]、介观特征(Mesoscopic feature)[11]、隐写分析特征(steganalysis feature)[12-13]等局部特征被提出用来进行换脸鉴别;除了上述特征外,眨眼频率[14]同样被用来挖掘换脸视频的视觉瑕疵,实现有效的换脸视频鉴别;此外,近期微软提出的Face X-Ray[15]通过寻找是否存在换脸边界来判断图像的真假,在多种新的换脸算法产物的鉴定上都取得很好的表现,具有极强的泛化性.然而,由于该方法依赖于换脸边界检测,因此并不适用于对GAN生成的整张人脸图像进行鉴别.
1.2 基于生成式对抗网络的虚假人脸的鉴别
相比于换脸鉴别,基于生成式对抗网络的虚假人脸鉴别工作相对较少.与换脸鉴别类似,已有工作同样是训练一个二分类器进行GAN生成的虚假人脸鉴别[2-5,16-18].例如Guo等人[2]提出了自适应残差提取网络对伪造人脸图像进行预处理,以便于特征学习网络更加注重于捕获视觉瑕疵,实现更加精准的虚假人脸鉴别效果;Afchar等人[11]提出了一个紧致的虚假人脸检测网络(MesoNet),仅需少量网络层数,就能够快速的有效的检测出伪造人脸视频;Bonettini等人[19]提出对多个检测网络进行集成,以提高虚假人脸生成视频检测的效果;此外,Hsu等人[3]提出利用成对学习的方式提高虚假人脸检测的精度.
由于GAN生成的是整张人脸,因此与换脸鉴别方法不同,针对GAN生成的虚假人脸检测并没有专注于局部特征设计.相反地,已有的针对GAN生成的虚假人脸检测模型通常直接采用深度学习网络学习的全局特征进行检测.例如Hsu等人[20]提出的DeepFD网络利用对比损失函数去挖掘人脸的全局特征进行虚假人脸检测;Bonettini等人[19]提出多网络集成假脸检测模型中,也是利用全局人脸特征进行检测.
GAN生成的假脸检测中一个挑战性问题是不同GAN生成的人脸图片分布通常不一致,导致假脸检测模型通用性差.因此,最近的工作开始关注于假脸检测模型在不同人脸生成模型生成的图像上的泛化性.现有的针对提高假脸检测模型泛化性的工作主要包括数据增强[4,21]、鉴别模型优化[5,20]、增量学习[17]等.基于数据增强的方法通过给训练集中数据添加扰动,例如高斯扰动等,帮助模型学习到更加鲁棒的特征,从而提高模型在没有见过的GAN生成的人脸图像上的鉴别性能.例如Wang等人[21]通过对训练数据进行高斯模糊与JPEG压缩等方式,有效地提高了模型在不同GAN生成的人脸图像上的泛化性.鉴别模型优化通常对网络结构或者损失函数进行优化,以提高鉴别模型的泛化能力. Liu等人[5]发现全局图像纹理信息对于虚假人脸图像鉴别至关重要,因此提出集成Gram block的Gram-Net以提取更加鲁棒的全局图像纹理特征,提高模型在不同生成方法上的鉴别性能.基于增量学习的虚假人脸鉴别模型[17]主要通过采用多任务学习的方式同时对虚假人脸进行鉴别与分类,以避免模型在学习新GAN生成的图像特征分布时忘记已有的GAN生成的图像特征分布.
不同于上述方法,本文所提出的方法引入迁移学习的思想,通过域对抗训练策略减小不同GAN生成的人脸图像的特征分布差异,使得特征学习模型能尽可能学习到与GAN生成方法无关的通用鉴别特征,以此提升鉴别模型在不同生成方法上的泛化性.
1.3 域自适应方法
实际应用中,训练集和测试集“分布不一致”导致模型性能变差的情况很多,而域自适应是一类能够很好地改善这种问题的方法.简单来说,域自适应方法的目的是利用带有标注的源域数据和无标注或少标注的目标域数据来训练模型,使得原始分布不同的数据在特征空间中尽量接近,从而提升模型在目标域测试数据上的迁移能力.目前,域自适应方法在物体分类、目标检测、行人重识别等任务上,都得到了很好的效果.
常见的域自适应方法可以分为2类:1)通过人工设计统计量距离函数来衡量并减小不同分布之间的距离;2)常见的域自适应策略则是基于领域对抗的思想构造域分类器,用以约束特征提取器的优化.
在基于人工设计统计量的域自适应学习方法中,最大平均差异(maxium mean discrepancy, MMD)距离是最常用的度量分布距离的函数,Tzeng等人[22]将MMD距离和深度神经网络技术进行结合,奠定MMD方法在域自适应任务中的重要地位;之后Long等人[23]引入多核多层的MMD方法,希望通过对齐更多的尾部特征层和多种核函数加权,达到更好的域自适应效果;Kang等人[24]则从类别细粒度的层面进行分布对齐,也达到了很好的效果.
方法1)需要人为精细地构造和验证统计量方法,因此最终的效果严重依赖于人工定义的统计量方法的好坏,而方法2)—基于域对抗思想构造的学习算法则很好地避免了这个问题,这类方法会引入域分类器对数据来源进行分类,然后让特征抽取模块和域分类器二者进行对抗学习,提升特征编码器提取域不变特征的能力,例如Tzeng等人[25]在特征层后增加域分类器,并通过任务分类器损失、域分类器训练损失和特征混淆损失对网络的不同部分进行迭代优化,从而实现不同域数据的特征既适合于目标任务又足够混淆;Ganin等人[6]则是创造了梯度反转层的概念,使得特征编码模块和域分类模块能够同时对抗优化.
本文所提出的方法借鉴了文献[6]中的思路.首先,本文将不同生成方法产生的数据分布视作不同的域,通过域对抗学习的方式让特征编码模型提取到的不同域数据的特征分布足够混淆,从而学习到生成方法无关的通用鉴别特征,提升模型泛化性.
2 基于域对抗学习的可泛化虚假人脸检测方法
本节主要对本文中涉及到的问题和核心方法进行详细描述,首先对所解决的问题进行形式化定义,然后对基于域对抗的训练过程进行详细阐述.
2.1 问题定义
本文研究的重点是如何提升虚假人脸检测器的泛化能力,让模型能够检测不同生成对抗网络生成的虚假人脸.对所解决的问题进行形式化定义.
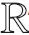
{p=f(x)|x∈X},
(1)
其中,总的人脸图片集合可以看作是真实人脸构成的集合XReal以及虚假人脸构成的集合XFake的并集,因此式(1)可以改写为
{p=f(x)|x∈XReal+XFake}.
(2)
进一步,假脸集合XFake可以根据训练过程中生成网络类型的可见与否划分为XSeenFake和XWildFake,其中XSeenFake表示多种已知的生成对抗网络生成的虚假人脸集合,而XWildFake包含未知方法生成的虚假人脸,故XFake能够表示为

(3)

真实场景中训练集不可能覆盖全部类型的假脸数据,而训练集之外的虚假图像的生成方法通常未知且与训练样本分布存在差异,本文设定的任务目标是通过部分已知类型的假脸数据学好一个强泛化性的虚假人脸检测方法,使之能够在判断XWildFake人脸集合真伪时达到高准确率.检测精度越高代表模型能够更好地检测不同来源的假脸,从而表明模型具有更强的泛化性能.

Fig. 2 The framework of the proposed approach图2 方法框架图
2.2 基于域对抗学习的假脸鉴别器训练方法
相关工作中提及了域自适应问题及其方法,不论是基于人工设计统计量的方法,还是基于域分类器构造辅助训练分支,本质都是在对齐来自不同域的特征分布,使得模型能够抽取不同域之间相同的模式,削弱模型对于过拟合到特定域特征的提取,从而减小跨域数据特征差异.
本文借鉴DANN方法,在训练时增加额外的训练分支,让模型能够学习属于不同“假脸域”的共同特征.在这里,“假脸域”的概念对应于不同的假脸生成方法所产生的数据的分布,本文定义一个类型的GAN产生的所有数据的分布将构成一种“域”,因此我们根据GAN类型的不同,将假脸数据划分为不同的数据域,划分为:设假脸图片集为X,对于一张输入图片x∈X,当它由第i种生成式对抗网络(GANi)生成时,我们定义这张图片属于第i个域(Domaini)中的数据.
本文利用“假脸图片属于何种假脸域”的信息构建假脸域分类器,并使用对抗训练的方式实现对特征抽取模块参数进行调整.这样做的目的是防止模型过拟合到特定假脸域的数据模式上,提升特征提取器提取通用鲁棒特征的能力,从而改善模型泛化能力差的问题.
具体的方法如图2所示,图2展示了一次输入的前向计算和后向梯度回传优化的具体细节.可以看到,图2的训练架构包含了上下2个分类器,处于上方的分类网络记为GY,参数为θY,处于下方的域分类网络记为GD,参数为θD,这2个分类器共享相同的特征提取模块GF,参数为θF,并分别完成真假脸分类任务和域分类任务.第1个分类器GY的任务是判断输入人脸是否属于假脸,而第2个分类器GD的任务是判断输入的伪造人脸由哪种类型的生成对抗网络产生,在优化过程中GD与GF将进行迭代式的对抗优化训练,其中GD的优化目标是让域分类器能够区分开虚假图片的来源类型,而GF的优化目标则是让特征提取器抽取到的特征尽量不包含虚假图像的生成来源信息.另外考虑上GY的优化目标:让整个模型能够区分开真脸和假脸图片,使得模型提取到的特征既能够区分真假脸、又不能区分假脸的来源生成网络.如果将不同的生成对抗模型视作不同的域,则这样优化的结果能够实现“类间差异大、域间差异小”的特点,使得特征提取网络学习到与GAN生成方法无关的特征,强化不同生成模型之间共同特征模式的提取,因而这样的模型能够具备更好的表现.
1) 训练阶段.在训练阶段,我们分别定义了2个损失函数:人脸真假的二分类损失函数LY以及域分类损失函数LD.下面将详细讲解这2个任务的损失函数及对抗优化过程.
针对人脸真伪的二分类器GY,本文使用二元交叉熵(binary cross entropy, BCE)损失函数衡量其分类损失,LY的形式化定义为
LY(x,y)=BCE(sigmoid[GY(GF(x))],y),
(4)
其中,BCE(p,y)=-(y×log(p)+(1-y)×log(1-p)),x表示输入图像,y∈{0,1}为真假标签,在二分类任务中采用sigmoid激活函数对GY的输出进行处理.
针对域分类器GD(即判断虚假人脸由何种GAN生成),本文使用交叉熵(cross entropy, CE)损失函数衡量分类损失,LD的形式化定义为
LD(x,d)=CE(softmax[GD(GF(x))],d),
(5)
其中,CE(p,d)=-log(pd),x表示输入虚假人脸图,d是域类别标签,它表示x由第d个生成模型产生.pd是预测x为类别d的概率,我们使用softmax激活函数将分类器输出转化为类别概率分布.
在优化过程中需要注意的是,由于存在GD域对抗分类过程,在优化过程中涉及到特征提取模块与域分类模块之间的对抗,因而在特征提取模块与域分类模块之间需要完成梯度反转操作,对应图2中展示的梯度反转层.对各部分模块的优化的梯度方向进行形式化描述:
对于人脸真伪分类器而言,优化的梯度方向为

(6)
对于域分类器而言,优化的梯度方向为

(7)
而对于特征提取器而言,域分类器与其衔接处完成一次梯度反转的过程,所以其优化的梯度方向为
(8)
其中,λ为手动可调的超参数.
式(6)~(8)分别描述了3个网络模块的梯度优化方向,而优化步长则由各自学习率进行调整.
本文认为防止特征表示过拟合到特定的某些生成对抗网络上对于增强虚假人脸检测网络的泛化能力至关重要,我们希望利用LY(x,y)监督项指导特征提取器通过训练数据学习到真实人脸和虚假人脸之间的特征差异,并利用LD(x,d)监督项指导特征提取器混淆不同生成方法之间的特征分布.通过这种学习策略抑制特征学习过拟合到特定的生成对抗网络上,使虚假人脸检测模型具备更强的泛化性和通用性.
2) 测试阶段.在测试阶段,给定测试图像x,我们仅使用GY分类器作为虚假人脸检测网络,对应的置信度输出:
p=f(x)=sigmoid[GY(GF(x))].
(9)
3 实验与结果
本节通过对比实验从多方面验证本文提出的方法的有效性.实验部分将按照数据集、衡量指标、实验结果与分析进行展开.
3.1 数据集
本文参考了Yu等人[7]的研究工作进行数据集构建.其中,真脸数据集来自CelebA人脸数据集[26],具体处理方式:首先对CelebA中的人脸图片做关键点对齐处理,然后利用剪裁方式得到分辨率为128×128的规范人脸图片得到最终使用的CelebA数据集. 而假脸数据集则由ProGAN[27],SNGAN[28],CramerGAN[29]和MMDGAN[30]这4种模型进行生成.这4种GAN模型都在经过对齐裁剪处理过后的CelebA真脸数据集上进行训练,保证模型训练数据源的一致性.另外所有图片数据存储格式为PNG格式,保证图片数据存储无损性.最终本文构建的数据集统计信息如表1所示,数据成分的部分展示如图3所示.
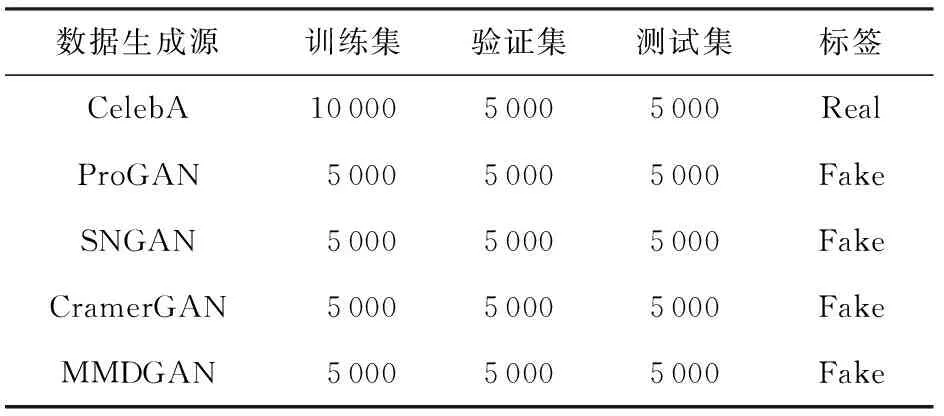
Table 1 Dataset Statistics表1 数据集构成成分与划分情况

Fig. 3 Image samples of the constructed dataset图3 数据集样本展示
实验过程中,我们会在ProGAN,SNGAN和CramerGAN这3种生成对抗模型中任意挑选2种模型生成的图像数据作为训练样本,剩余一种生成对抗网络产生的图像数据则作为未知类型的测试数据,用以验证模型的泛化性.为了保证训练过程中正负样本均衡,真脸数据集的训练样本数量设定为单种假脸训练数据量的2倍.在这种任务设定下3种生成对抗模型样本都可能被挑选成为未知的模型类别,因此后续将会进行3组对比实验来验证本文提出的方法的有效性.而MMDGAN数据集主要用于后续的测试集扩充与训练集扩充的实验中.
3.2 衡量指标
因为在测定全局性能时(1种真脸与3种假脸数据共同进行测试)会有正负样本不均衡的情况出现,所以本文采用了不容易受到正负样本不均衡影响的受试者工作特征曲线(receiver operating char-acteristic curve, ROC)下的面积(area under roc curve, AUC)作为评价指标.ROC描述的是随着分类阈值的变化真阳率(true positive rate,TPR)和假阳率(false positive rate,FPR)的变化情况,以反映模型的性能.真阳率TPR和假阳率FPR的计算为
(10)
(11)
其中,TP表示真阳性,FP表示假阳性;TN表示真阴性,而FN则表示假阴性.本文采用AUC数值来衡量模型的优劣.
3.3 实验结果与分析
本节将重点对实验结果进行展示和分析,主要包含3个部分:1)基线方法、他人方法以及本文提出的基于域对抗方法进行对比实验,并在其之上对伪造数据集进一步扩充,探究增加伪造方法种类对各类方法的影响;2)由于进行JPEG压缩后往往会对虚假人脸检测器造成负面影响,本文在前一个实验的基础上进一步对模型鲁棒性进行测试,并提出将域对抗方法同高斯模糊数据增强相结合,通过使用不同的JPEG压缩率处理测试图片来测试不同方法训练得到的模型针对图像扰动情况的泛化性;3)用TSNE[31]对特征进行可视化,展示改进前和改进后模型学到的特征性质的差异,从中分析本文方法取得提升的原因.
3.3.1 对比实验
我们将本文方法与基准模型以及Xuan等人[4]提出的2种增强模型泛化性的方法GN与GB进行比较.其中基准模型采用ResNet18[32]的骨干网络作为特征提取模块,在其之上使用单个全连接映射作为真假脸分类器.GN和GB分别使用高斯噪声与高斯模糊作为数据增强方法训练基准模型.我们根据原文的设定,随机在0~5之间选取高斯噪声的标准差,随机在1,3,5和7中选取高斯模糊的核大小.本文方法则是在基准模型之上增加辅助的域分类分支,其中域分类器由2层全连接层和ReLU激活函数组成.由于本文方法的核心是增加域对抗训练分支,因此以Adv(Adversarial)缩写代指本文方法.本节共包含5组实验,表2是数据集的质量分析结果,表3是方法对比的实验结果,表4是对Adv方法有效性的分析实验,表5和表6是Adv方法进一步的扩展实验.

Table 2 Calculate the FID Values of the GAN Dataset and the Real Face Dataset表2 计算GAN数据集和真实人脸数据集的FID值
表3记录了3组对比实验的实验结果,表中的数字是AUC测试分数.表3的第1列描述了训练集的组成成分,包括真脸图片来源和假脸图片来源情况;第2列记录方法名称;后面3列记录的是不同方法在不同的假脸数据类型上的测试分数(利用5 000张假脸图片与5 000张真脸图片计算得分);而在这3列中带有深色背景的单元格对应在训练时期未知的生成对抗网络类别;最后一列是将所有假脸和真脸进行汇总计算,即汇总5 000张真脸测试图片和3种生成模型共15 000张伪造测试图片计算AUC值.表3中展示的3组对比试验分别对应3种不同的生成对抗网络作为未知类型时的测试结果.

Table 3 Performance Comparison表3 不同方法的性能比较
通过表3中的第1组实验结果可以发现,使用CelebA+ProGAN+SNGAN训练集得到的虚假人脸检测模型在检测CramerGAN数据时,基准方法就具备非常好的迁移性,而另外2组基准实验中模型在检测未知类型假脸时则表现较差,本文尝试从伪造图像质量的角度对该实验现象进行分析解释.
一般来说,如果模型生成的图片的分布与真实样本分布越接近,我们会认为该模型产生的图像质量越高,鉴别难度越大.因此我们通过FID[33]指标衡量不同GAN产生的图片样本与真实人脸数据集之间的分布差异,从而对不同GAN产生的图片质量进行量化分析,以解释为何模型在CramerGAN上泛化性较强.实验值如表2所示.在计算FID指标计算时需要先用预训练网络抽取特征,然后再计算特征分布之间的差异,本文在计算FID时分别选择了预训练模型的2层特征进行FID计算,其特征维度大小分别是192和2 048.通过表2可以看出ProGAN和SNGAN对应的FID值接近且较低,而CramerGAN的FID值则高于其余2种GAN的FID值,证明CramerGAN产生的图像分布与真实人脸集之间差异更大,其生成的人脸质量最低.本文认为这是在测试过程中,CramerGAN数据作为未知人脸时检测模型泛化表现高的重要原因,即该方法产生的假脸质量较差,存在更多虚假伪造痕迹,因此更容易被模型捕获并识别.
即使第1组实验中基线模型已经具有较好的泛化性,但是本文方法仍然能够更进一步取得提升,相比于其他3种对比方法,本文提出的方案在各种GAN数据的鉴别得分都是最高.而在后2组实验中,基准方案在未知类型假脸的测试实验中表现较差,如第2组实验,基准方案在未知的SNGAN上初始方法仅取得0.829 2的分数,但是本文提出的基于域对抗的训练方法在SNGAN数据上的评测得分上升到0.866 4,提升接近4个百分点,在所有对比方法中得分最高;第3组对比实验也有类似的现象,在未知的ProGAN数据上基准模型仅取得0.794 2的分数,而使用了基于域对抗的新方法进行训练之后,同样的分类网络模型在ProGAN生成的人脸数据上检测指标上升到0.843 4,在所有对比方法中得分也是最高.通过与基准方案和2种增强泛化性的方法进行比较,证明了基于域对抗方法能够有效提升虚假人脸检测模型的泛化性能,提升模型检测未知生成方法的虚假人脸图像的准确率.另外通过表格还能发现,我们提出的算法对于训练中已知的生成网络类型也能够起到一定的提升作用,整体准确率的得分也最高,从另一个角度证明了域对抗方式能够防止模型发生过拟合,让模型学习到更鲁棒的特征.
另外,为了验证我们设计的方法使得模型提取到的特征不能区分假脸的来源,我们对域分类器也进行了测试,表4展示了我们设计的域分类器的分类表现,理想情况下域分类器应无法准确判断样本属于何种类别,即域分类器准确率应为0.5,域分类损失应为0.693 1.通过表4可以看出3组实验中的域分类器都无法准确分类假脸来源,其分类损失和分类准确率都很接近随机预测的分数.结合表3中的实验结果可以得出结论:我们的方法确实能够让模型提取到的特征既能区分真假脸,又不能区分假脸来源于何种生成网络.

Table 4 The Classification Loss and Accuracy of the Domain Classifier表4 域分类器的分类损失和分类精度
最后本文通过引入MMDGAN数据进行2组验证实验,分别验证在训练集不变的情况下我们的方法能够在更多虚假人脸类型上具有更强的泛化性表现,以及验证伪造训练集中GAN类型增加的情况下,我们的方法仍然表现最优.首先引入MMDGAN作为额外测试数据来做第1点验证,实验的过程为:选取表3中各实验组的模型及参数,在MMDGAN上进行性能测试.实验结果如表5所示.表5的第2~4列分别对应3组不同训练集的实验组,对应的分数为不同方法在MMDGAN伪造类型数据上的测试分数,可以看到,本文方法在多种测试组合下表现最好,进一步验证基于域对抗方法得到的模型能够在多种虚假人脸类型数据上有更强的泛化表现.其次,本文通过引入MMDGAN作为额外训练数据增加训练集中伪造类型的多样性以进行第2点验证.因为模型在SNGAN和ProGAN作为未知伪造类型的实验组中仍有较高提升空间,所以本文分别选定这2种伪造方法作为训练时未知的伪造类型,通过往训练集中额外增加MMDGAN产生的人脸数据,达到扩展训练集中伪造数据集种类的目的,实验结果如表6所示.在训练集中增加了MMDGAN类型数据后,所有对比方法的AUC分数都得到提升,说明包含更多GAN类型的训练数据有利于模型学习更为通用的检测特征;而本文提出的方法在扩展了伪造方法种类的情况下多项分数最高,尤其在未知伪造类型的泛化性测试和整体性能测试上都取得了最好的结果,证明了本文方法的可扩展性,能够在多种GAN方法的伪造训练数据集上提升检测模型的泛化性.
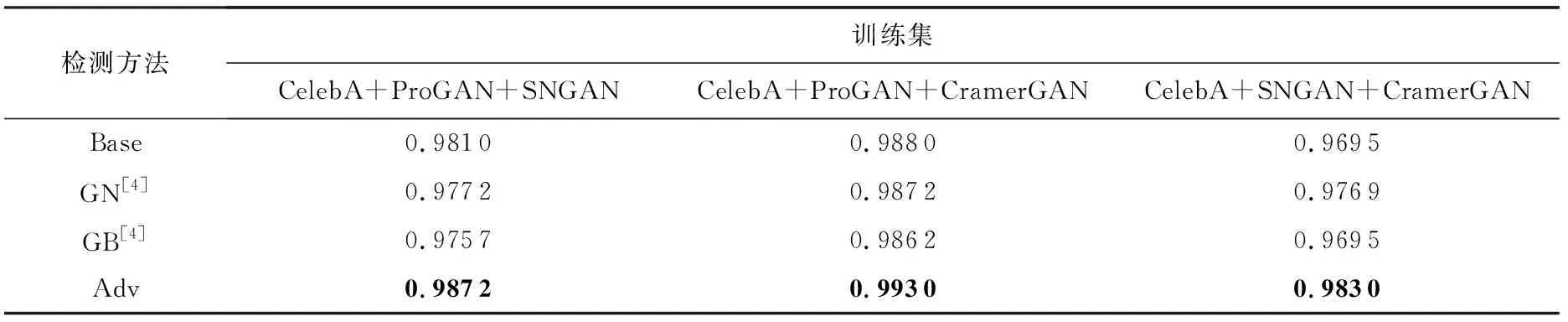
Table 5 Use the Models in Table 3 to Test Their Performance on MMDGAN Data表5 表3中的模型在MMDGAN数据上的检测表现
3.3.2 加入JPEG压缩后模型性能对比测试
JPEG图像压缩算法被广泛应用于互联网世界中.然而JPEG压缩会降低图像质量,很有可能对虚假人脸鉴别模型造成负面影响,因此本节在测试过程中引入JPEG压缩,更全面地测试和探究虚假人脸检测模型在实际场景中的表现.
具体来说,本文使用不同JPEG压缩率处理测试图片,在不同压缩质量下对比各种方法的表现,并分析方法之间得分的相对大小以及不同鉴别方法在不同JPEG压缩质量下的变化趋势.表7展示了完整的实验结果,而图4则是抽取了表7中第3组实验的全局分数,以折线图的形式直观表示,横轴表示JPEG压缩质量,从左到右压缩质量逐渐增大,当压缩质量增大至100时表示无损压缩,而纵轴表示AUC指标.图4中Base方法为最基础的对比算法,GN[4]和GB[4]对比算法,Adv为本文基于域对抗提出的方法,而Adv+GB则是将本文方法同高斯模糊数据增强进行结合.
通过表7可以明显看出,JPEG压缩对于虚假人脸检测模型的准确率有很大的负面影响,随着压缩质量不断降低,模型对于所有假脸类型的检测准确率也在持续降低,这是因为有损压缩让图片像素数值发生了一定的改变,破坏了虚假图片上原有的一些模式信息,而由于训练过程没有见过这样的压缩损失,所以模型在增加了扰动的测试集上的表现会随着压缩质量的降低不断下降.
本文首先着眼于3.3.1节中提到的4种方法的实验结果,也就是Base,GN,GB和Adv(本文提出的基于域对抗方法).通过表7可以分析得到3个重要信息:
1) 本文提出的方法在不同的干扰情况下取得的分数总是高于Base方法的分数,表明使用域对抗方法得到的虚假人脸检测模型在表现上稳定强于普通训练方法得到的虚假人脸检测模型.
2) 通过表7的测试分数可以发现GN方法与Base方法在分数上没有明显差异,因此本文认为高斯噪声并不能有效加强模型增强模型抵御JPEG压缩干扰的能力.
3) 相比于其他方法,GB方法(高斯模糊数据增强)受到JPEG压缩的干扰最小,图4非常直观地显示了这一点,图4使用折线图可视化了ProGAN作为未知假脸生成器实验组时不同压缩质量损失下各个方法的指标变化.图4中圆形图例折线表示GB方法,三角形折线表示本文提出的Adv方法,菱形图例和打叉图例分别代表GN方法和Base方法,可以看到从右往左随着压缩损失的增加,GB方法的AUC分数变化趋势最为平缓,并且在压缩质量降低到一定水平后,GB曲线与Adv方法的指标曲线出现交点,即在高压缩损失下GB方法的表现超过了Adv方法,证明使用高斯模糊数据增强能减小模型对JPEG压缩的敏感度.
因此本文将Adv方法与GB方法相结合,一方面Adv方法能够让模型提取到更能泛化到未知虚假类型的人脸上,另一方面GB方法能够让模型更好地抵御JPEG压缩攻击,所提出的结合算法记作Adv+GB.通过折线图中的正方形图例折线可以看出,增加了高斯模糊数据增强之后,所提出的Adv+GB方法对应的折线整体比Adv折线更加平缓,且在各种情况下均分数几乎都是最高.而表7的分数则更详细地给出了各类方法在不同实验组下的分数,可以看到在不同实验组、不同JPEG压缩质量的干扰测试结果中,本文所提出的Adv+GB方法能够取得更好的效果,证明了Adv+GB方法在JPEG压缩攻击下的有效性.
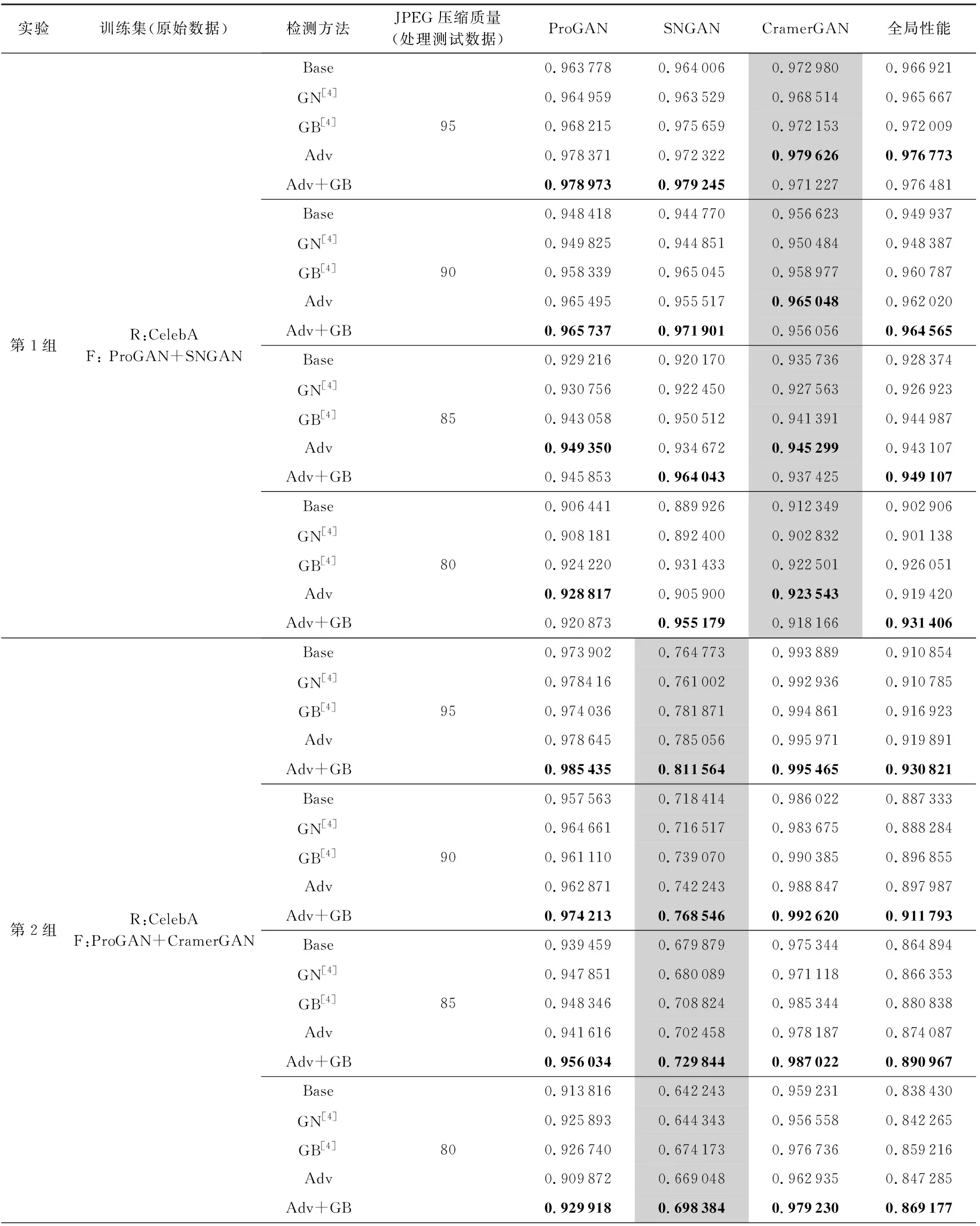
Table 7 Impact of Different JPEG Compression Ratios on the Scores表7 不同JPEG压缩比例对虚假图像检测性能的影响

续表7
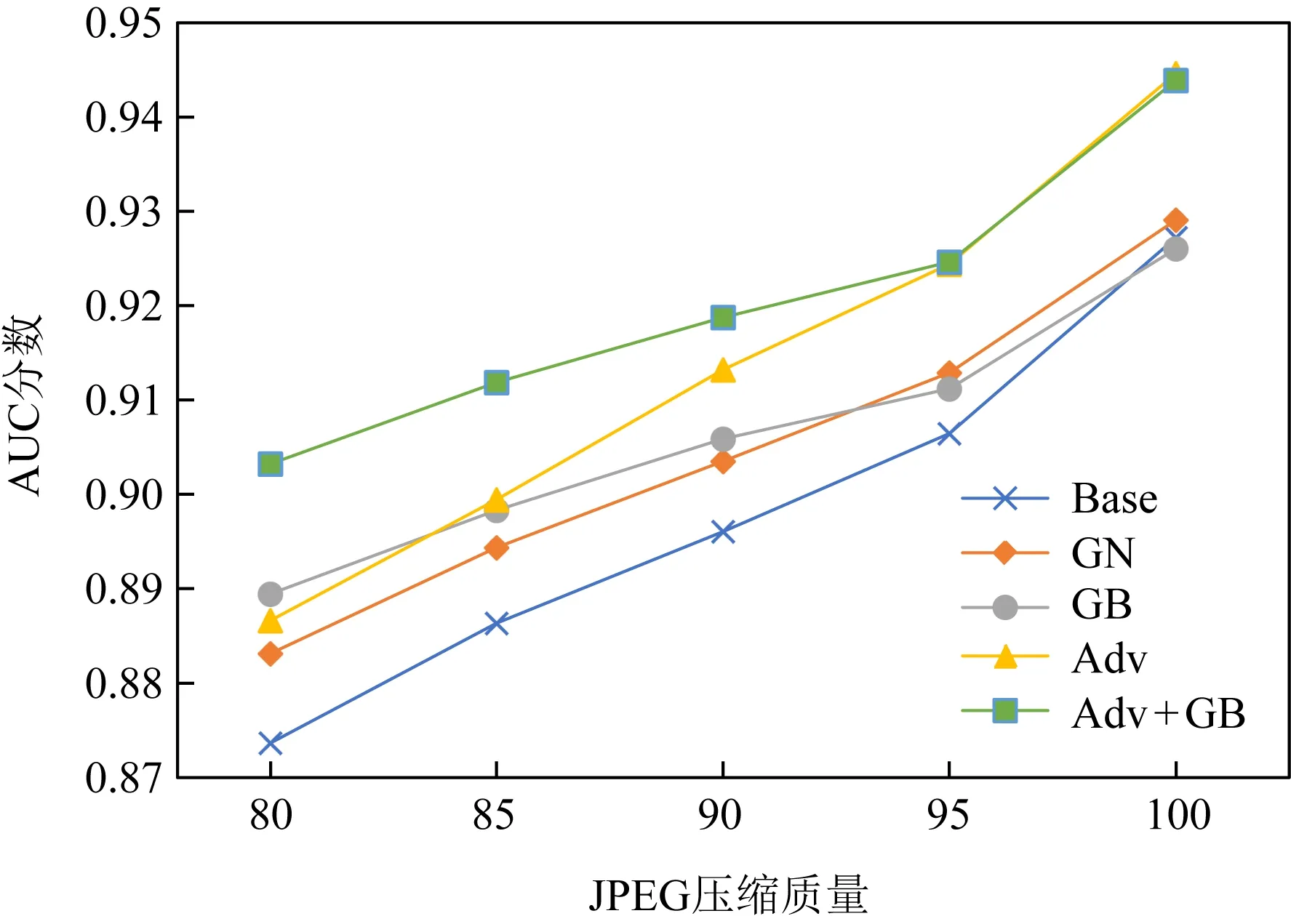
Fig. 4 Impact of different JPEG compression quality on the overall scores图4 不同JPEG压缩质量对虚假图像鉴别性能的影响
3.3.3 特征可视化
TSNE算法是最常用的特征可视化方法之一,我们使用TSNE算法对实验模型进行了特征可视化,利用可视化结果分析域对抗策略如何影响模型特征提取器.图5是一组TSNE可视化结果,这组可视化结果由2个模型生成:图5(a)为正常训练方式的模型的特征可视化结果,图5(b)为加入域对抗方法得到的模型的特征可视化结果.这里的2个模型均以CelebA,ProGAN和CramerGAN作为训练集,而SNGAN则扮演了未知的生成对抗网络的角色.
通过图5(a)可以发现,在最为基础的分类训练模式下,训练时可见的真脸类型(CelebA)和假脸类型(ProGAN,CramerGAN)在测试时期表现出良好的特征分布特性,能够在降维后的空间里存在较为清楚的分类边界.然而图中蓝色数据点,即对应SNGAN产生的人脸数据,在图5(a)中很大一部分与红色的真脸数据对应的特征分布混淆在一起,区分度不高,而与绿色和紫色的假脸特征数据分布存在较大差异,显然在这种情况下虚假人脸检测器容易误判.
图5(b)是做了域对抗方法之后模型的特征分布结果,可以看到域对抗分支的加入使得ProGAN图片数据和CramerGAN图片数据在特征空间中得到充分混淆,达到了我们预期的效果——尽可能消除特征中关于特定生成对抗模型的类别信息.而通过图中可以看出,真脸数据与已知的假脸类型数据之间也存在较为明显的分类边界,因而模型对已知类型的假脸具有良好的检测效果.
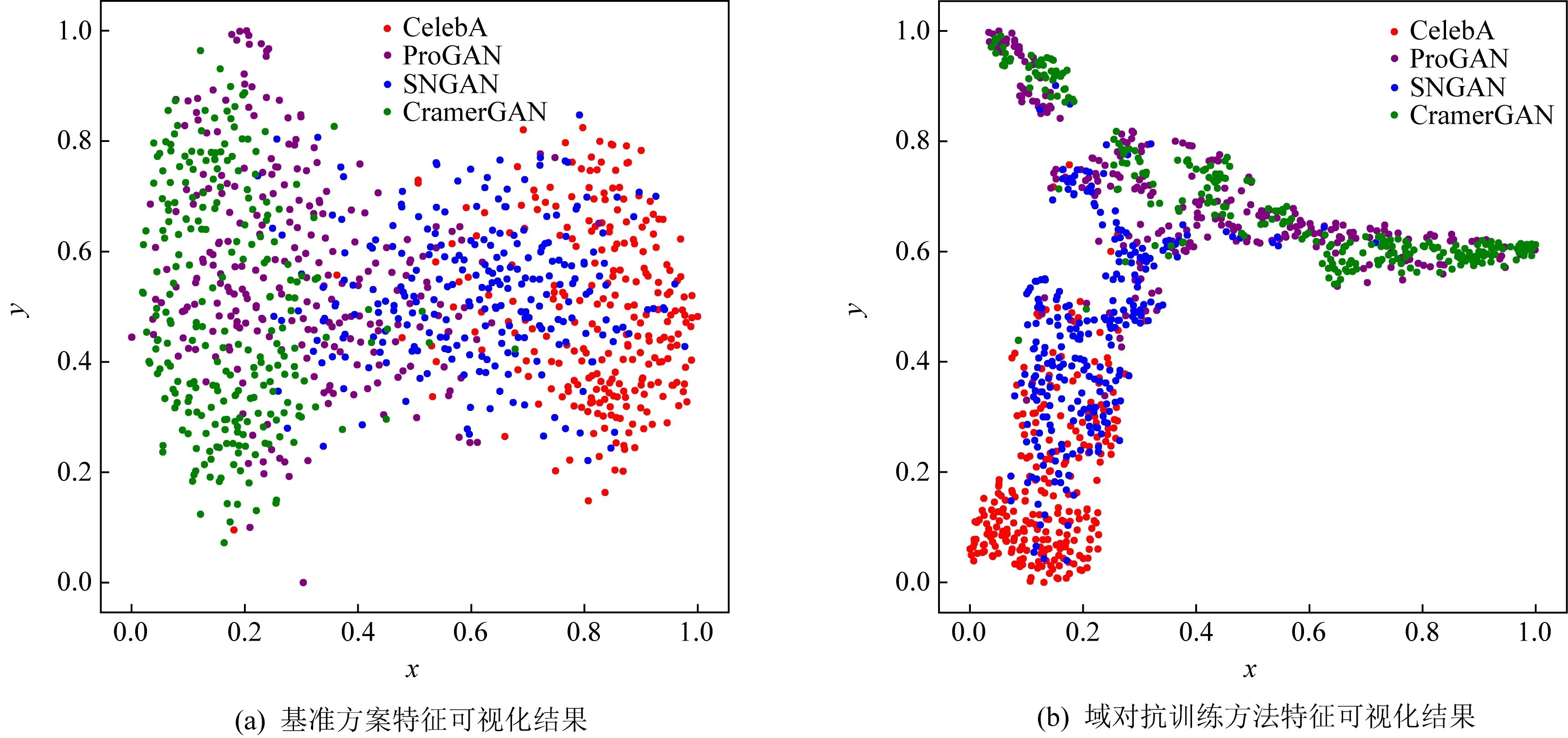
Fig. 5 Feature distribution visualization with TSNE图5 用TSNE算法可视化测试数据特征的分布
另外与图5(a)对比可以发现,代表着未知生成类型的蓝色点在图5(b)中与真脸数据有更为明显的分离,且与已知假脸数据的分布更为接近.通过这些可视化的现象成功验证了3点结论:1)域对抗成功将多种生成对抗方法的图片特征混淆,一定程度消除了特征中关于特定生成对抗模型的类别信息;2)使用域对抗方法的情况下,模型仍然能够学习到真脸数据和已知假脸数据的良好特征表示;3)域对抗过程有利于提升模型的泛化性能.
4 总 结
本文提出了一种基于域对抗学习的可泛化虚假人脸检测方法,通过引入域对抗的训练方式抑制模型过拟合到特定生成模型的数据上,强化特征提取模型能够抽取泛化性能更高的特征.实验结果表明:本文提出的方法能够有效地提升模型的泛化能力,提升模型在未知生成模型产生的虚假图像的表现.未来工作旨在将域对抗的训练方式引入到更加复杂的场景下,比如噪声严重的场景、换脸图像或视频的场景等,另外也希望能够在现有方法的基础上结合小样本相关的研究,在可见少量目标泛化类别的样本的情况下学习到更强的特征表示,提升目标类别的泛化性能.
