融合源信息和门控图神经网络的谣言检测研究
2021-07-23杨延杰王宇航
杨延杰 王 莉 王宇航
(太原理工大学大数据学院 山西晋中 030600)
随着互联网的飞速发展,社交媒体已经成为用户获取信息、交流意见的主要平台,根据Kantar Media在2019年发布的一份报告,全球40%的人使用社交媒体[1],而且这一数字还在不断地增加,这就极大地促进了谣言的快速滋生和广泛传播,对社会稳定造成巨大的威胁.例如据BuzzFeed News报道[2],在2016年美国总统大选期间,谣言的传播在网络上造成了不小的负面影响.2020年COVID -19疫情爆发期间,有些人在社交平台上散布一些有关疫情传播的谣言,引发了人们的不安.谣言的迅速传播,已经开始从各个方面影响人们的正常生活,因此,谣言检测是一个亟待解决的关键问题.
然而,谣言检测是一项非常有挑战性的任务,主要体现为3个方面:1)谣言具有强迷惑性和误导性,使得单独从谣言文本内容本身检测谣言存在困难.因此除了从谣言本身的内容信息出发,我们还应该探索和利用其他信息,如社交媒体上的用户信息以及社会上下文信息.2)早期检测的需求.社交媒体上的用户较为活跃,使得谣言能够在短时间内广泛传播,谣言造成的负面影响随之剧增,使得早期检测尤为重要.3)谣言的传播过程复杂多样[3],数据流动没有固定的规律,谣言内容涵盖的方面非常大,使得数据的处理和使用成为一大困难.
为了有效检测谣言,人们已经做了大量的研究,常见的方法利用文本内容进行谣言检测,研究人员从文本内容中提取一些低级特征如n-gram,TF-IDF,bag-of-word[4-6]和一些高级的特征如文体特征、事实主观性、写作风格一致性[6-8]等,然后将这些特征应用于机器学习算法进行谣言检测.这些方法基于手工构建的特征,特征提取类别较为单一,无法很好的应对复杂多变的真实环境.深度学习不依赖于手工特征的构建,而且还能提取得到高层次的特征表示.近年来,研究者开始利用深度学习方法建模文本语言[9-11]、文本结构[12-14]等,取得了非常好的效果.这一类方法需要较长的文本才能够训练得到好的特征表示以提高检测效果.但是社交媒体上,人们发表见解的帖子通常是较短的文本[15],这就可能影响基于内容的方法的检测性能.此外,还有方法利用参与社交媒体的用户信息来检测谣言[16-17],这些方法受到现实场景的限制,出于隐私考虑,用户的真实信息往往难以获得.研究者们开始关注于利用社交网络上的传播信息进行谣言检测,一些研究利用传播路径构建传播树,然后利用长短期记忆(long short-term memory, LSTM)网络、门控递归单元(gated recurrent unit, GRU)来学习传播过程中的序列特征[18-19],但是传播的序列特征无法反映传播内部的结构信息,此类方法有一定的局限.图卷积网络(graph convolutional network, GCN)[12]的诞生,为我们提供了很好的思路,最近的一些研究使用GCN解决谣言检测问题[20-21]并取得了较好的效果.
受上述研究启发,社交媒体上的消息转发可以建模为图结构,图1(a)展示了来自公共数据集Fake-NewsNet的一条“凯瑟琳生下第3个孩子后5个小时就出现在伦敦一家医院外”(1)https://twitter.com/CNN/status/988463960159608833的谣言以及它的转发路径,根据图1(a)的转发关系可以得到如图1(b)所示的转发图.消息转发图中某一帖子的上游信息和下游信息对于研究当前帖子都非常重要,我们认为这样的转发图中蕴含着丰富的结构关系可以为谣言检测提供帮助.另外,转发过程是一种信息逐步扩展的过程,源帖表达出最原始且最重要的信息,更好地利用源帖的信息对于谣言检测至关重要.
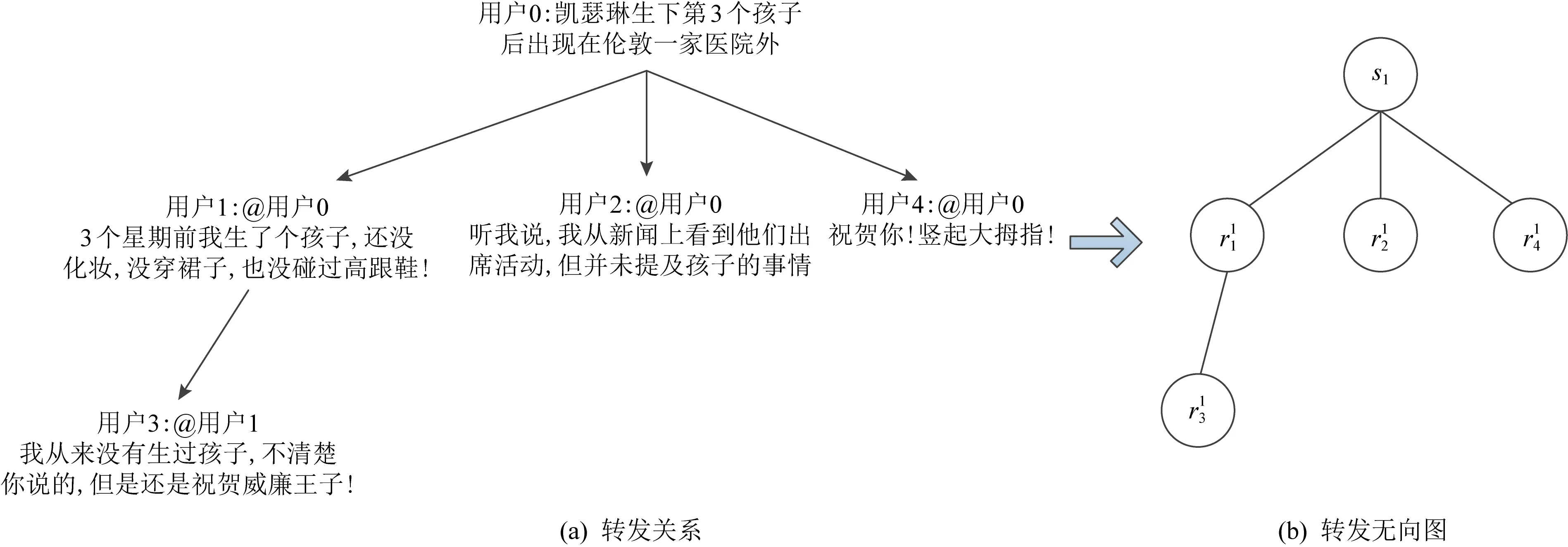
Fig. 1 Construction of forwarding graph in social media environment图1 社交媒体场景下的转发图的构造方法
本文主要研究:1)如何有效地利用转发图来整合复杂的转发结构信息用于分类;2)如何更好地利用源帖的信息以提高谣言检测的性能.为了解决这2个问题,提出了一种谣言检测模型GUCNH.首先,我们利用社交网络中帖子的转发关系构造转发图,然后提出了一种融合门控的图卷积网络模块用于捕获转发图中的各节点之间的结构信息,融合门控的目的是对图卷积之前的特征表示和之后的特征表示进行选择与组合,以得到更加可靠的表示.为了更好地利用源帖信息,我们在源帖对应节点的原始表征和通过融合门控的图卷积网络模块之后得到的表示之间进行选择与组合,将选择后的结果与每个节点的表征拼接.最后将所有节点表征取平均用于分类.本文工作的主要贡献可以概括为3个方面:
1) 提出了一种融合门控的图卷积网络模块GUCN,该模块通过门控单元来对图卷积之前的特征表示和之后的特征表示进行选择与组合,以得到更加可靠的表示.通过该模块来捕获转发图节点之间的结构关系,并结合多头自注意力模块来考虑任意节点之间可能存在的影响,最终生成节点表示.
2) 源贴信息往往最为重要,为了充分利用源贴信息,在生成节点表示之后,模型将经过选择的源贴特征表示与转发图中生成的所有节点表示拼接起来,以加强源帖的重要性.
3) 在3个真实的数据集进行了一系列的实验.实验结果表明:本模型在谣言分类和早期检测任务方面都取得了优于现有模型的结果.
1 相关工作
谣言检测的目标是根据用户发布在社交媒体平台上的相关信息(如文本内容、用户配置文件、评论、传播模式等)来检测谣言的真假.根据研究对象的不同,相关工作可以大致的分为3类:1)基于内容的方法;2)基于用户的方法;3)基于传播的方法.
1) 基于内容的方法.基于内容的方法主要依赖于文本的内容信息来检测谣言,这些研究通常面向于长文本数据.一部分研究者从机器学习的角度进行谣言检测,Pérez-Rosas等人[22]从新闻中提取手工特征建立组合特征集训练线性支持向量机SVM模型用于谣言检测;Popat等人[7]通过研究文本内容的语言风格来进行谣言检测;Takahashi等人[23]通过应用命名实体和线索关键字来训练分类器进行谣言检测,这类方法均基于机器学习,需要人工设计特征并进行提取,在通用性和扩展性上存在一定的缺陷.近年来,深度学习的发展为谣言检测提供了很多新的方法,Ma等人[18]利用递归神经网络(recurrent neural network, RNN)从文本内容中提取隐藏的向量表示用于分类;Ahn等人[10]将预训练的BERT模型用于谣言检测任务,取得了非常好的效果;Vaibhav等人[13]提出了一种用于虚假新闻检测的图神经网络模型,该模型对新闻中所有句子对之间的语义关系进行建模,从而进行谣言检测;Wang等人[14]依赖文本内容,提出了SemSeq4FD模型来检测虚假信息,该模型同时考虑了新闻中句子之间的全局语义关系和局部上下文顺序特征,取得了很好的效果.本节介绍的基于文本内容的方法局限性是它们更适用于长文本,基于机器学习的方法需要长文本才能提取到所需要的特征进行分类,基于深度学习的方法也需要较长的文本才能够训练得到好的特征表示以提高检测效果,而社交媒体上的帖子大多是短文本,造成数据稀疏问题从而影响该类方法的检测性能.
2) 基于用户的方法.基于用户的方法主要针对参与社交媒体的用户进行建模.其中用户的特征信息是从用户配置文件中收集的,如描述、性别、关注者、朋友、位置和验证类型等.Yang等人[16]提取用户特征进行分类,如性别、地理位置和追随者数量;Castillo等人[4]利用Twitter上的用户特征来检测假新闻,这些特征包括关注者数量、好友数量、注册年龄等;Shu等人[24]充分研究了用户配置文件在虚假信息检测中的作用,他们的工作为深入探索社交媒体的用户特征提供了基础;Liu等人[17]结合RNN和卷积神经网络(convolutional neural network, CNN)来捕获基于时间序列的用户特征;Lu等人[20]将参与社交的所有用户构建为一个完全连通的图以辅助检测谣言.这类方法的局限性主要表现在由于隐私问题,许多用户会隐藏自己的信息或使用虚假的个人信息,这使得获取真实的用户信息变得非常困难.
3) 基于传播的方法.与基于内容和基于用户的2种方法不同,基于传播的方法主要侧重于真假信息传播特征的差异,现有的研究根据建模类型的不同主要可以分为3种:基于传播链的方法、基于传播树的方法、基于传播图的方法.①基于传播链的方法主要将信息传播按照时间顺序看为一个时间链来检测谣言.Kwon等人[25]确定了真假新闻在传播中存在语言差异,从时间、内容等方面分析了谣言的传播特征,并根据这些特征,利用决策树、随机森林和支持向量机来检测谣言;Ma等人[26]提出了一系列基于谣言生命周期的时间序列特征,将这些特征用于分类,一定程度上提高了谣言的检测效果.②基于传播树的方法主要将信息的传播建模为一棵消息传播树,通过对消息传播树中的传播链进行一系列操作以检测谣言.Wu等人[27]提出了一种随机游走的核来建模消息的传播树,以提高谣言的检测能力;Ma等人[19]建立了树结构递归神经网络(RvNN),从传播结构和文本内容中捕捉各节点的隐藏表示,取得了不错的效果.然而,这些方法通常只关注于从传播树上学习序列化特征,忽略了社交网络上帖子之间的全局转发关系.③最近的一些研究将信息的传播建模为一个传播图,利用图神经网络技术解决谣言检测问题,Wei等人[28]针对谣言检测问题,提出了一种多深度M-GCN模型,该模型能够捕获多尺度的邻居信息;Wu等人[29]对于传播图迭代的使用图神经网络直到收敛,将收敛之后的节点表示用于分类;最近,Bian等人[21]提出了一种用于谣言检测的双向BiGCN模型.通过双向图卷积网络学习消息转发的结构特征,取得了良好的效果.这些现有的基于传播图的方法虽然已经开始注意使用消息传播结构信息,但是他们过分依赖于GNN,GCN等单一模型的处理结果,同时源帖子的重要性并没有得到充分利用.
本文的研究主要是根据文本内容和转发结构进行谣言检测,与本研究最相关的是基于文本内容的方法和基于传播的方法.本文工作的贡献在于:考虑到帖子之间的转发结构信息、融合门控单元和图卷积网络进行建模、充分利用源帖的信息.
2 问题定义
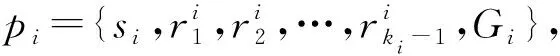
3 模 型
本文提出一种谣言检测模型——GUCNH,如图2所示,主要分为4个模块:转发图构建、节点表示、选择性增强根节点表示、谣言分类.
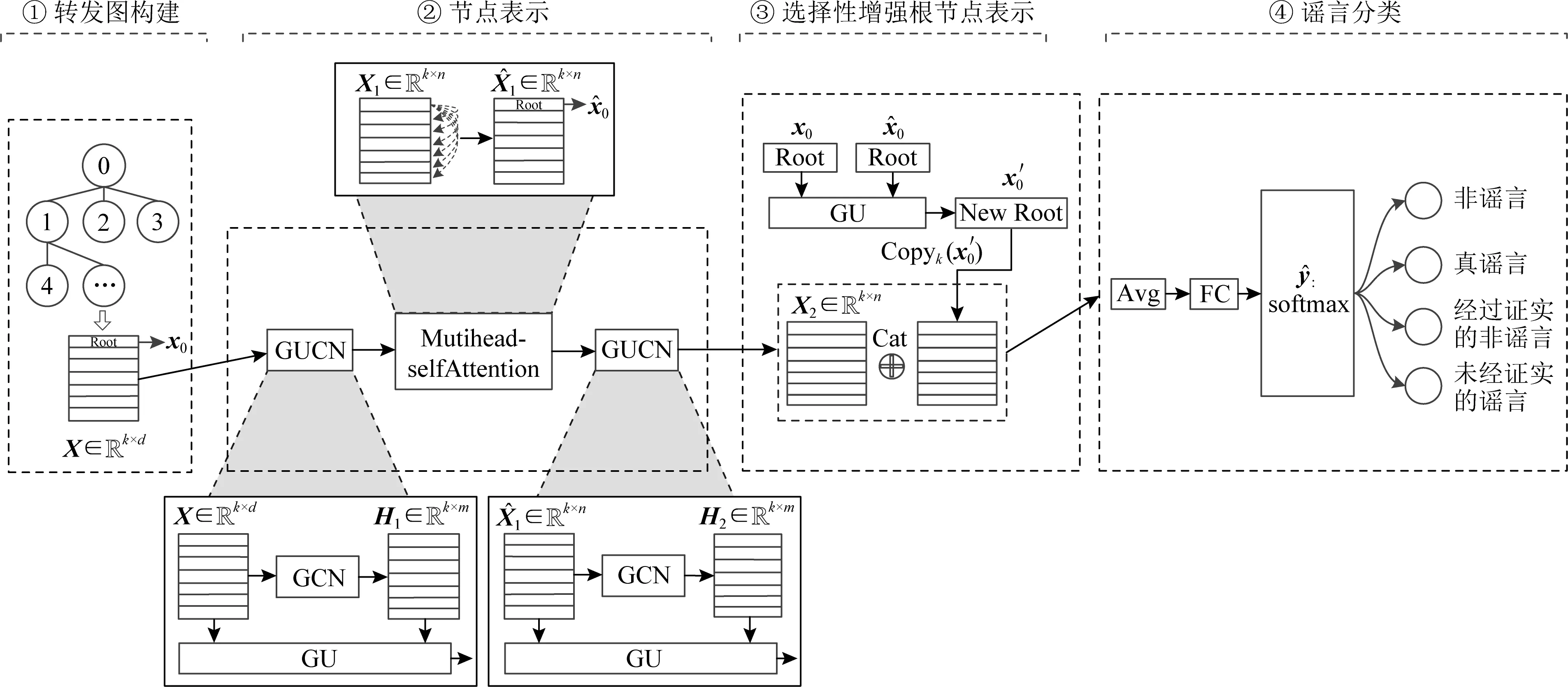
Fig. 2 Four modules in GUCNH model图2 GUCNH模型的4个模块
3.1 构建转发图
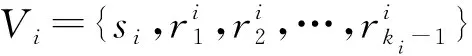
(1)
借鉴Bian等人[21]的方法,本文引入了一种DropEdge[31]的方法以减少GCN过拟合,在训练的每个阶段,随机的将输入图中的一部分边去掉,增加了输入数据的随机性和多样性,能够有效地防止过拟合.本文模型中,随机删除边的比率设定为q,通过DropEdge之后,邻接矩阵变为
(2)
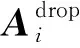
3.2 节点表示
构建好转发图之后,通过融合门控的图卷积网络模块GUCN和多头自注意力模块来得到包含转发结构信息的节点表示,前者利用图卷积网络聚合一定的邻居信息,融合门控机制来获取更好的中间表示,后者主要通过注意力机制来捕获任意节点之间的多方面影响,具体介绍如下:
1) 融合门控的图卷积网络模块GUCN
为了充分利用转发图中的转发结构信息,使转发图中的各个节点能很好地融合邻居信息以获得更好的特征表示,引入了融合门控的图卷积网络模块GUCN,图卷积网络[12]能够依据结构信息对图中的节点进行融合,得到聚合邻居信息后的特征表示.但是GCN依靠聚合邻居信息来提升自己的表示,有些聚合可能带来噪声.受文献[32]的启发,本文提出了一种名为GU的门控单元,实现从不同的数据组合中找到合适的中间表示.门控单元GU的结构如图3所示:
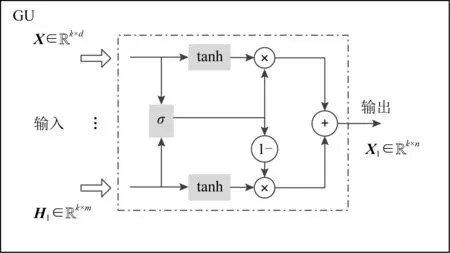
Fig. 3 GU network structure diagram图3 GU网络结构图
为了提高表示的质量,门控单元对图卷积之前的特征表示和之后的特征表示进行选择与组合,最终通过堆叠GUCN模块得到融合邻居信息的节点高级特征表示:
X1=GUCN(X),
(3)
X2=GUCN(X1),
(4)
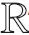
(5)
H1=tanh(W1XT),
(6)
(7)
Z=σ(W3[H1,S1]T),
(8)
X1=ZH1+(1-Z)S1,
(9)
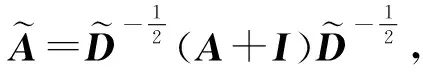
2) 多头自注意力模块
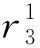
(10)
(11)
(12)
MutiHeadAttention(Q,K,V)=
Concat(Head1,Head2,…,Headh)WO,
(13)
(14)
3.3 选择性增强根节点表示
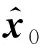
(15)
(16)
z=σ(W6[h1,s1]T),
(17)
(18)
(19)
(20)
3.4 谣言分类
本节主要讨论如何使用得到的节点表示Xlast进行分类,我们认为基于转发图的谣言检测可以看作是一个图分类任务,所以需要一个单独的向量作为整图的特征表示用于分类.具体的,首先通过选择性增强根节点表示模块得到了转发图中每个节点的表示,然后通过平均这些节点表示得到整个转发图的向量表示,将该向量表示作为全连接神经网络的输入,得到预测结果,计算过程为
(21)
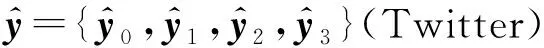
最后,将模型的损失函数定义为预测结果与真实标签之间的交叉熵:
(22)
其中,r为分类的类别数,θ为整个模型的参数,yi∈{0,1,2,3}(Twitter),yi∈{0,1}(Weibo)为真实标签值.
3.5 时空复杂度分析
对所提GUCNH模型的时间复杂度和空间复杂度进行分析.对于端到端的深度学习算法而言,相比训练的时间复杂度,实际应用中,更关注其预测时间复杂度,因此,在进行时间复杂度分析的时候,我们只分析所提模型预测一个谣言需要的时间.在进行空间复杂度分析的时候,我们则更关注于训练参数的个数.分2个方面进行分析:
1) 时间复杂度分析.对于本文提出的方法,当来自邻居的信息根据式(3)进行GCN运算的时候,时间复杂度与转发图中节点的个数k以及平均入度β有关,所以式(3)的时间复杂度为O(βkd2),其中d为节点表示维度.式(6)~(9)的时间复杂度为O(kd2),所以GUCN模块的总体时间复杂度为O((β+1)kd2).多头自注意力模块的时间复杂度除了与节点个数k相关,还与头的个数相关,文章中使用了4个,所以该模块的时间复杂度为O(4k2d2),综合可得在节点表示模块,时间复杂度为O(4k2d2+2(β+1)kd2).根节点选择性增强模块的时间复杂度为O(d2).谣言分类阶段的时间复杂度则为O(rkd2),其中r为最终分类的类别数.

4 实 验
将通过实验回答3个问题:
1) 问题1.与现有的谣言检测方法相比,本模型GUCNH是否能够获得较好的谣言检测性能?
2) 问题2.GUCNH的每个模块对于谣言检测的性能是否有贡献?
3) 问题3.与现有的谣言检测方法相比,GUCNH是否具有优秀的早期检测性能?
4.1 实验数据和设置
1) 实验数据
我们在3个真实数据集上评估了我们提出方法的有效性:Twitter15[30], Twitter16[30]和Weibo[18].Twitter15,Twitter16数据集均包含4个标签类别,分别是非谣言(N)、经过验证的非谣言(F)、真谣言(T)、未经证实的谣言(U).而Weibo数据集包含2个标签类别,分别是谣言(T)和非谣言(F).数据集中的每个事件标签都是根据辟谣网站上文章的真实性标签来标注的,这3个数据集的详细统计情况如表1所示:
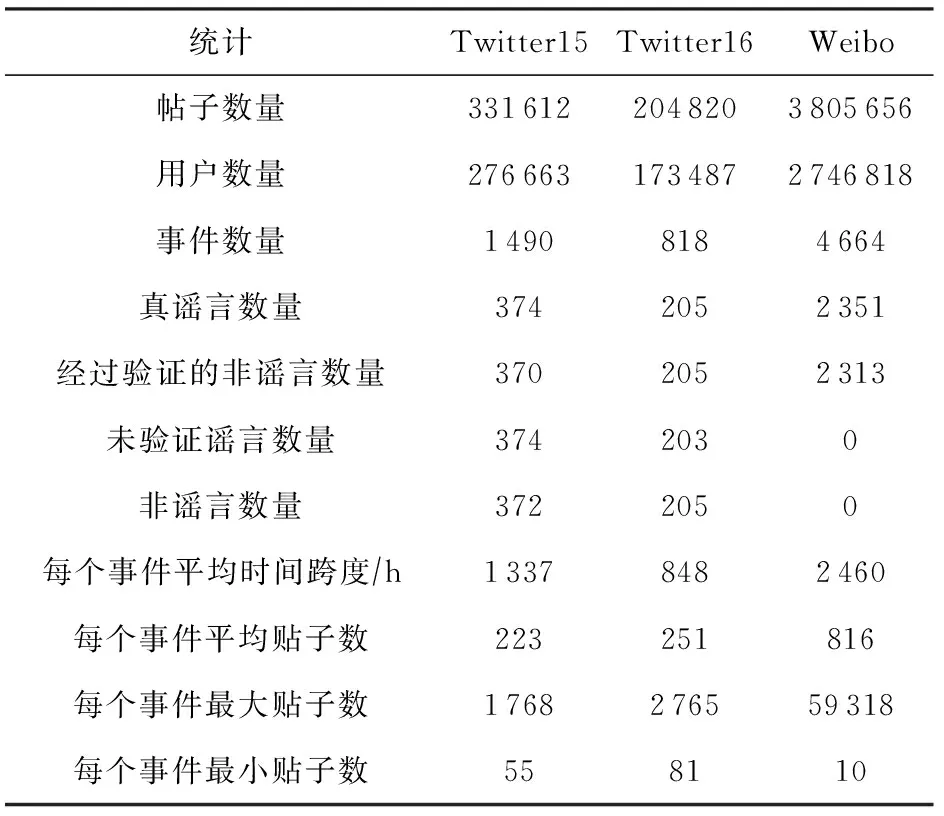
Table 1 Dataset Statistics表1 数据集统计
2) 对比方法
为了验证我们的模型,我们将提出的方法和一些最先进的基线方法进行了比较,这些方法大致可以分为基于机器学习的方法、基于传播链和传播树的方法、基于传播图的方法:
① 基于机器学习的方法
Ⅰ DTC[4]:使用基于人工设计的各种统计特征进行分类的决策树分类模型.
Ⅱ SVM-RBF[16]:一种基于支持向量机的RBF核模型,利用手工制作的特征对帖子进行总体统计.
② 基于传播链和传播树的方法
Ⅰ BU-RvNN[19]: 基于递归网络的自底向上树状结构的谣言检测模型.
Ⅱ TD-RvNN[19]: 基于递归神经网络的自顶向下树状结构的谣言检测模型.
Ⅲ PPC_RNN+CNN[17]:一种结合递归神经网络和卷积神经网络的模型,通过谣言传播链中的用户特征来进行谣言检测.
Ⅳ CED(0.975)[34]:一种基于谣言转发序列的可信度检测模型,该模型通过寻找一个时间点来做出可信的预测,其中0.975为预测阈值.
③ 基于传播图的方法
BiGCN[21]:利用信息传播时的双向传播结构使用图卷积网络进行谣言检测的模型.
3) 实现细节和评价指标
首先,本文所有实验的机器配置以及环境为:Intel i7 2.20 GHz(处理器),8.0 GB(内存),GTX-1050 ti(GPU),所有代码都是用Python(3.7.6)实现,scikit-learn(0.22.1),Theano(1.0.4),Pytorch(1.4.0).
① 基于机器学习的方法:
使用scikit-learn实现基于机器学习的对比方法DTC和SVM-RBF,对于特征的选择与提取,完全按照原文描述基于我们的数据集提取了有效特征(主要包括:转发数、粉丝数、发布设备类型、好友数量、用户所在地、是否认证、发帖数、性别、评论数等).
② 基于传播链和传播树的方法:
使用Theano实现了基于传播链的方法BU-RvNN和TD-RvNN(2)https://github.com/majingCUHK/Rumor_RvNN,使用pytorh实现了基于用户传播链的方法PPC_RNN+CNN(3)https://github.com/yumere/early-fakenews-detection.在BU-RvNN和TD-RvNN中,所有模型的参数通过Adam[35]算法更新,模型参数的初始化使用均匀分布,词汇大小设置为5000,隐层单元大小设置为100.在PPC_RNN+CNN中,我们设置epoch=200,早停机制轮数设置为10,GRU输出维度设置为32,CNN窗口大小设置为3,dropout率设置为0.5.对于CED方法,由于可复现性问题,我们仅在Weibo数据集上得到了结果(结果来自原文).
③ 基于传播图的方法:
使用Pytorch实现了基于传播图的方法BiGCN(4)https://github.com/TianBian95/BiGCN以我们提出的模型GUCNH.其中BiGCN的复现代码由原作者提供,每个节点的隐层特征向量维度设置为64,随机删除边的比率q设置为0.2,dropout率设置为0.5,epoch设置为200,其余参数设置严格按照原文设定.
我们所提模型中的参数由Adam[35]算法更新, 学习率初始化为1E-4,在训练过程中逐渐降低.我们利用TF-IDF值提取前d个单词构建词袋模型作为文本的初始表征,设置d=5 000,模型中图卷积网络输出表征的维度m和门控单元输出表征的维度n均设置为64,多头自注意力模块头的个数h=4.对于原始的转发图,我们设置随机的删除边的比率q=0.2,即随机删除20%的边.实验的batchsize=128,epoch=100,为了防止过拟合,模型中用到了dorpout机制,其比率为0.3,我们将数据集随机分成5部分进行5折交叉验证以获得结果,除此之外还应用了早停机制[36].
我们采用了与先前工作中相同评估指标[20,37],即准确度、F1分数、召回率和精准率进行评估.为了公平比较,我们的方法和对比方法在所有数据集上的结果都是在5次实验的结果上取平均.
4.2 实验结果分析
为了回答问题1,通过实验得到分类的总体准确率Acc和各类别的F1值来验证本文模型的谣言检测性能.表2~4分别展示了本文模型以及所有比较方法在3个数据集上的性能.显然,我们提出的模型优于选定的对比模型.对实验结果进行分析:
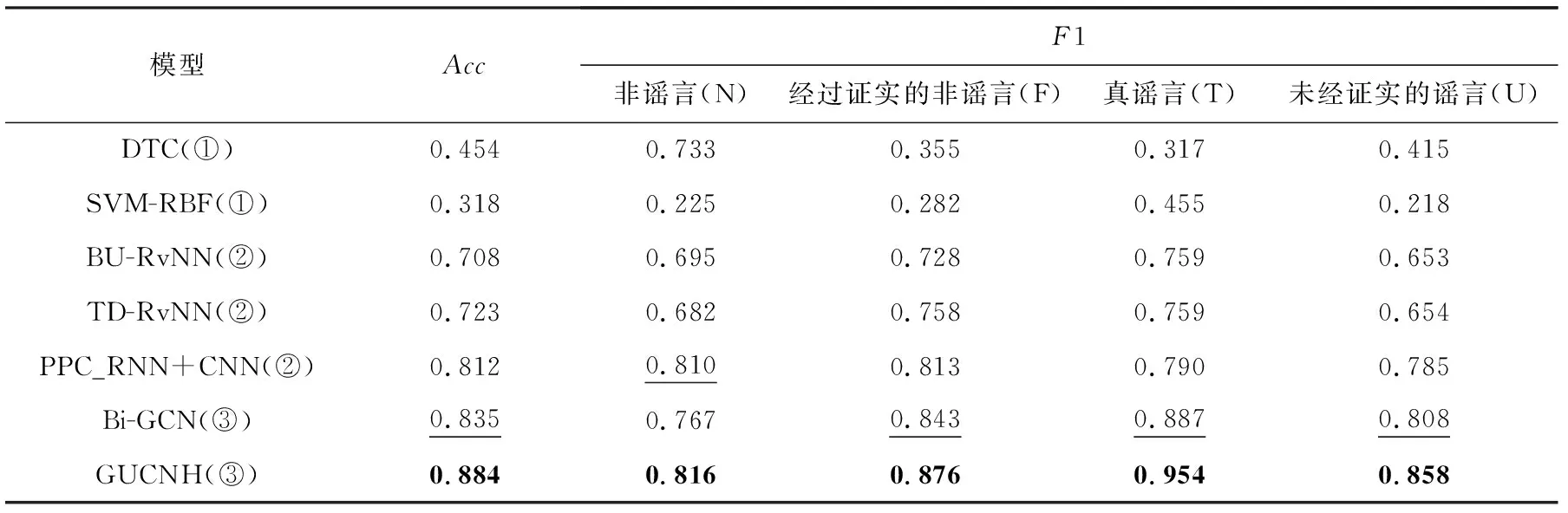
Table 2 Experimental Results on Twitter15 Dataset表2 Twitter15数据集上的实验结果

Table 3 Experimental Results on Twitter16 Dataset表3 Twitter16数据集上的实验结果
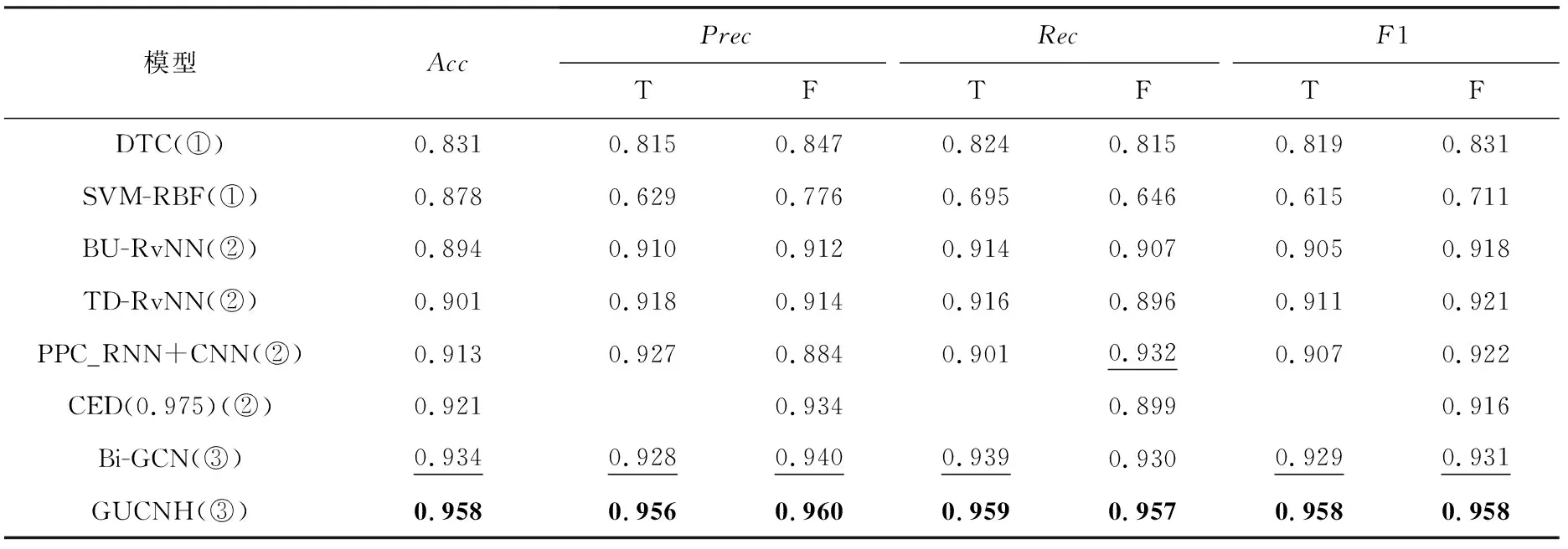
Table 4 Experimental Results on Weibo Dataset表4 Weibo数据集上的实验结果
1) 可以观察到深度学习方法的性能要明显地优于机器学习方法,理由是因为深度学习方法可以捕捉到更有价值的高层特征,而机器学习的方法需要手工提取特征,检测能力较为局限.这进一步说明了研究深度学习方法在谣言检测中的重要性和必要性.
2) 可以观察到我们提出的GUCNH模型在Twitter15数据集上的结果要比BU-RvNN和TD-RvNN模型分别高17.6个百分点和16.1个百分点,在Twitter16数据集上的结果比BU-RvNN和TD-RvNN模型分别高16.8个百分点和14.9个百分点,在Weibo数据集上的结果比BU-RvNN和TD-RvNN模型分别高7.1个百分点和6.3个百分点.实验结果表明传播结构中包含很多重要信息,捕获这部分结构信息有助于谣言检测任务,将任务建模为传播图以捕获全局结构信息的方法要优于通过建模为传播树捕获局部序列特征的方法.
3) 相比于PPC_RNN+CNN,我们提出的模型结果更好.一方面,PPC_RNN+CNN仅仅使用传播链上的用户信息进行建模,单一使用用户的一些特征来检测谣言有一定的片面性;另一方面,PPC_RNN+CNN并没有考虑到实际的转发结构.我们提出的模型根据实际的转发结构充分了利用了每个帖子的内容信息,从而取得了更好的结果,由此可见实际的转发结构在检测谣言中的重要性.相较于CED(0.975),我们的模型在Weibo数据集上的准确率要高4个百分点,这进一步说明了利用全局传播结构的优势.
4) 本文模型的实验结果要优于BiGCN,BiGCN虽然使用了双向的GCN对于转发图结构进行了建模,同时还在2次GCN之间融入了一定的源节点信息,但是仅仅使用GCN聚合得到节点表示的方法太过于依赖GCN的表现,这一点本文模型通过引入门控单元来弥补.此外,本文模型引入了多头自注意力模块来考虑任意节点之间的多方面影响,可以有效弥补有限次GCN不能很好地捕获任意节点信息的缺陷.
4.3 消融实验
为了回答问题2,证明我们提出模型各模块的有效性,进行了一系列的消融实验.主要包括4部分:
1) w/o Matt.移除多头自注意力模块,在节点表示模块,只使用2次GUCN的堆叠,其余部分不变.
2) w/o 1GUCN.移除一个GUCN模块,主要用于验证GUCN模块堆叠的有效性,将多头自注意力模块输出的结果作为节点表示模块的输出,然后拼接源帖表示进行分类.
3) w/o Head.移除选择性增强根节点表示模块,主要用于验证增强源帖信息对于该场景分类的有效性.
4) w/o GU.移除每个GUCN模块中的GU门控单元,只保留图卷积操作,用于验证我们引入的门控网络与图卷积网络融合的有效性.
如图4为消融实验的结果,其中ALL为不做任何消融的原始模型GUCNH,根据表中的实验结果,可以得到结论为:
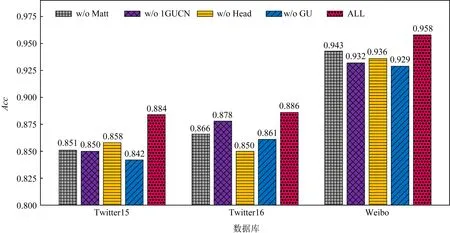
Fig. 4 The ablation experiment result of the GUCNH on three datasets图4 GUCNH在3个数据集上的消融实验结果
首先研究多头自注意力模块带来的影响,根据实验结果可以看到,删除多头自注意力模块会影响我们的模型在3个数据集上的结果,其中GUCNH在消融多头自注意力模块后,Twitter15和Twitter16数据集上的结果分别下降了3.3个百分点和2.0个百分点,Weibo数据集上的结果下降了1.5个百分点.多头自注意力模块可以捕获任意节点之间的影响,而不仅仅限于具有邻接关系的节点之间,使得在进行下一次节点信息融合之前所有节点的信息尽可能的全面,对于结果的提升有很大的帮助.结果同样可以证明我们引入该模块的动机,并非具有直接转发关系的帖子之间会相互影响,任意的帖子之间也会存在相互影响,而使用多头注意力模块能够很好地考虑到这些影响,取得较好的结果.
随后我们评估了GUCN模块堆叠的有效性.GCN的适当堆叠有助于节点聚合高阶邻居的信息,所以我们的模型采用了融合门控的图卷积网络模块堆叠的方式.一方面使得节点能够聚合到更远节点上的信息;另一方面为了在多头注意力机制之后重新让节点数据考虑到结构信息.为了验证GUCN模块堆叠的有效性,我们进行了w/o 1GUCN消融实验,根据实验结果可以看到,不进行GUCN模块堆叠会影响我们所提模型在3个数据集上的结果,GUCNH在不堆叠GUCN模块的实验中,Twitter15和Twitter16数据集上的结果分别下降了3.4个百分点和0.8个百分点,Weibo数据集上的结果下降了2.6个百分点.结果表明,对融合门控的图卷积网络模块GUCN进行堆叠使用可以使得节点更好地融合邻居节点甚至更远节点的信息,同时对于多头自注意力模块有可能造成的结构信息破坏问题有一定的解决,所以取得比单一使用该模块更好的结果.
谣言事件的源帖总是有着最丰富且重要的信息,所以我们的模型包含选择性增强根节点模块,作用就是额外的为每个节点增加源帖的信息.为了证明设计的有效性,进行了该模块的消融实验.根据实验结果可以看到,不增强头节点的信息会影响我们所提模型在3个数据集上的结果. GUCNH在没有选择性增强头节点模块的实验中,Twitter15和Twitter16数据集上的结果分别下降了2.6个百分点和3.6个百分点,Weibo数据集上的结果下降了2.2个百分点.结果表明,源帖有着非常重要且原始的信息,为每个节点额外的增加源节点对应的信息,能够有效地提高该场景下的检测能力.
最后研究了引入融合门控的图卷积网络的有效性,实验过程是将原模型中所有融合门控的图卷积网络模块GUCN换为单一的图卷积网络模块GCN进行实验,根据实验结果可以看到,使用单一的GCN会影响我们所提模型在3个数据集上的结果, GUCNH在使用单一GCN的实验中,Twitter15和Twitter16数据集上的结果分别下降了4.2个百分点和2.5个百分点,Weibo数据集上的结果下降了2.9个百分点.结果表明,引入门控单元GU能够对进行图卷积之前的特征表示和之后的特征表示进行选择与组合,从而得到更好的表示使得分类结果有了一定的提升.
4.4 早期检测研究
在谣言检测任务中,最关键的目标之一是尽早发现谣言,以便及时进行干预[38].为了回答问题3,验证我们提出的模型具有优秀的早期检测性能,我们在Twitter15和Twitter16这2个数据集上设计了早期检测实验,具体的方法是设置检测截止时间节点,即仅使用在发布时间到检测截止时间节点之间的帖子内容来评估模型检测的性能.通过改变检测截止时间节点(我们设置节点分别是源帖发布后4 h,8 h,12 h,24 h,36 h),分别得出了2个数据集上的早期检测结果,如图5和图6分别为2个数据集上进行早期检测的结果.可以看到,在源帖发布的最早期,也就是图5、图6中4 h时,我们提出模型的在Twitter15数据集和Twitter16数据上分别取得了82.1%和84.1%的结果,可以看出这些结果比其余对比方法的结果好,这表明我们提出的模型具有良好的早期检测性能.当检测截止时间节点逐渐增大时,我们模型的性能仍然呈上升趋势,这一点与BiGCN等模型不同,随着时间节点的变大,转发结构更加复杂,言论种类也逐渐增多,我们的模型仍然可以保持很好的结果,说明我们的模型对复杂的数据不敏感,具有较好的稳定性和鲁棒性.
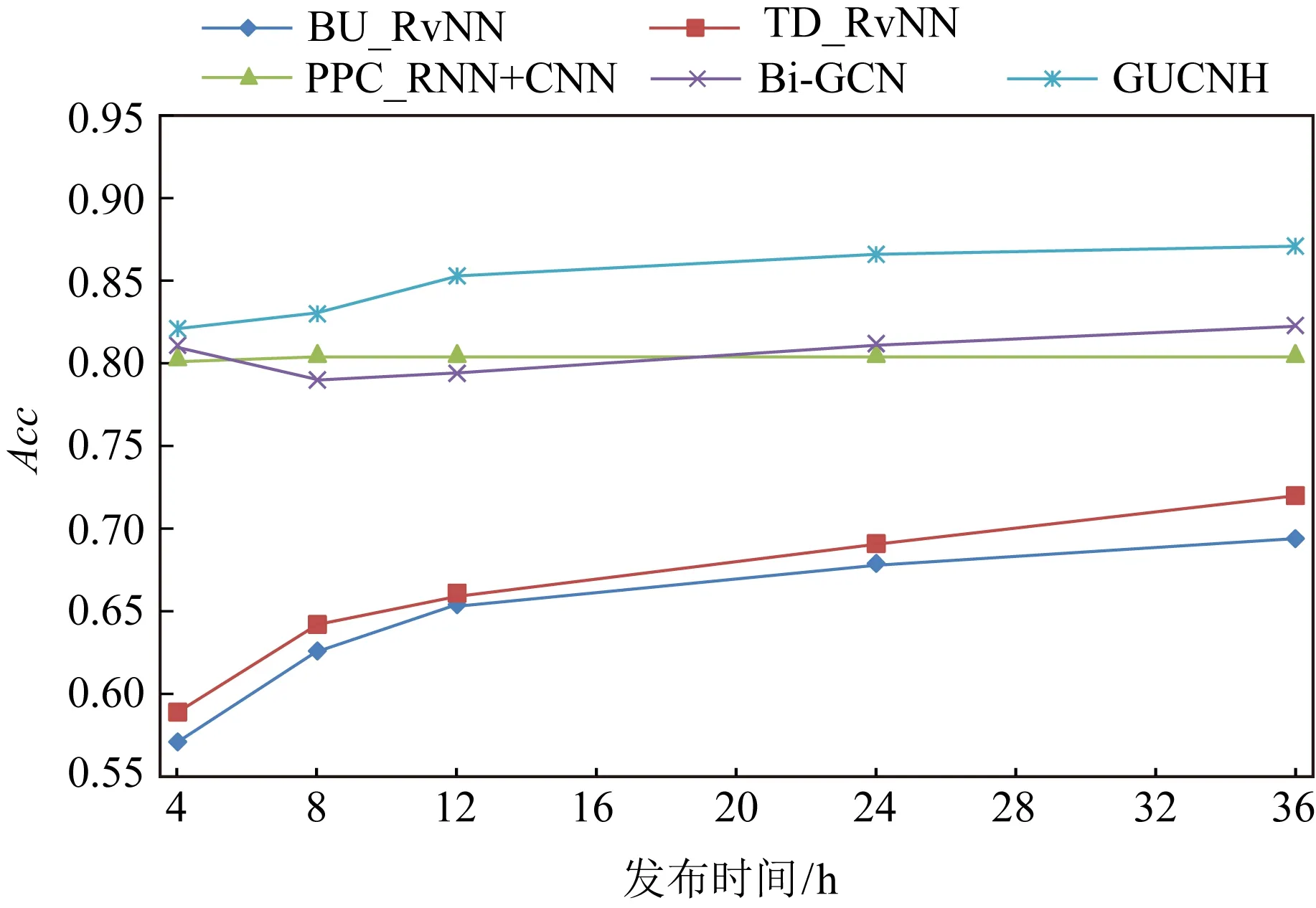
Fig. 5 Experimental results of early detection on Twitter15 dataset图5 Twitter15 数据集上早期检测实验结果
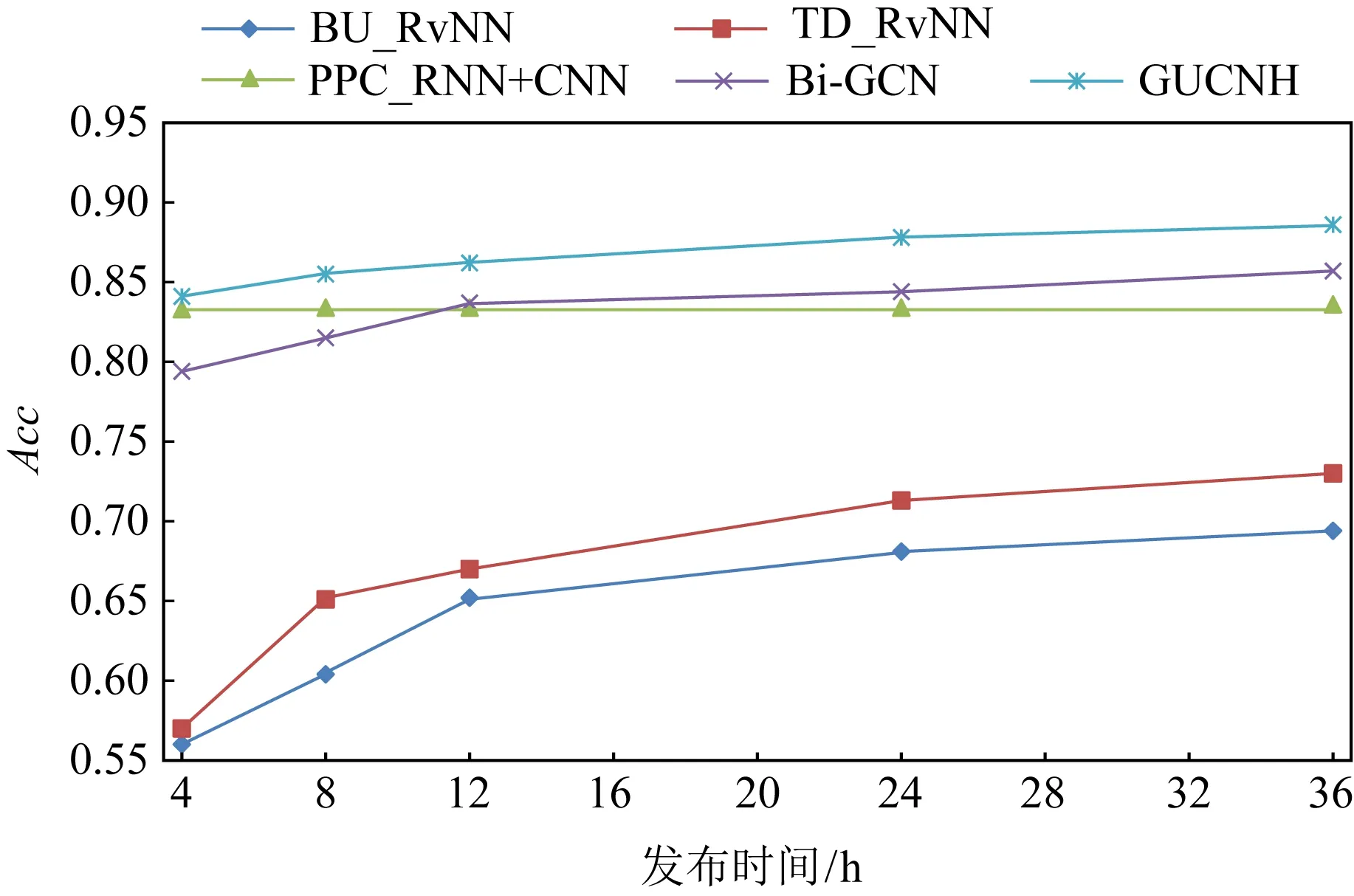
Fig. 6 Experimental results of early detection on Twitter16 dataset图6 Twitter16 数据集上早期检测实验结果
5 总结与展望
本文提出了一个融合门控的传播图卷积网络模型GUCNH,该模型首先通过融合门控的图卷积网络模块GUCN来根据实际转发结构聚合邻居信息以生成节点的表示,即门控机制用来对进入图卷积网络之前的特征表示和经过图卷积网络之后的特征表示进行选择与组合得到质量更高的特征表示,同时在2个融合门控的图卷积模块之间引入了多头自注意力模块来考虑任意节点之间的影响,使得节点信息在进入下一次融合之前包含尽可能全面的信息.在生成节点的高级特征表示之后,我们选择性的增强了源节点的信息,理由是往往转发源的信息最为丰富.为了确保增强的源节点信息的质量,同样加入门控单元对于源节点的信息进行了选择与组合,最终将选择后的源节点特征表示与所有节点的特征表示拼接用于分类.在3个真实数据集上的实验结果表明,我们提出的方法优于最先进的方法.
在未来的研究中,我们将主要从2个方面继续深入工作:1)在转发图的构建方面,寻找更加合适的建模方法(如加入用户构建异构图),以提高检测性能.2)一般来说,完整的社交帖子不仅只有文本内容,同样还会包含图像或视频等信息,在接下来的研究中,我们还将考虑利用多模态信息来解决谣言检测问题.
