一种基于多关系传播树的谣言检测方法
2021-07-23卫玲蔚淮晓永韩冀中虎嵩林
胡 斗 卫玲蔚 周 薇 淮晓永 韩冀中 虎嵩林
1(华北计算机系统工程研究所 北京 100083)
2(中国科学院信息工程研究所 北京 100093)
3(中国科学院大学网络空间安全学院 北京 100049)
随着社交媒体的快速发展,用户生产内容(user generated content, UGC)以此为载体可以迅速得到广泛传播、获取大量受众,大大加速人们信息交流的速度与深度.然而,在获取便利的同时,社交媒体也滋生许多网络谣言,成为造谣、传谣的主要领地,谣言依附新的媒介,呈现出爆发式的增长和泛滥传播[1].谣言前所未有的迅猛之势对人类社会产生着巨大的影响,极大程度上扰乱了正常的社会秩序[2-3].检测网络中的谣言不仅能够促进清朗的网络空间建设,还能帮助人们迅速甄别有效信息,对社会的稳定快速发展具有重大的现实意义.
谣言(rumor),是指一种从一个人传到另一个人的故事[4],其真实性一开始都是未经证实的,而其中一些后来被证明是真的(即真谣言)或被发现是假的(即假谣言),还有一些始终未被证实(即未经证实的谣言)[5].谣言检测(rumor detection)任务旨在确定谣言的真实性[6].与主要关注于新闻(news)文章的虚假新闻检测(fake news detection)[7]任务不同,谣言检测任务涉及的话题更广,同时是一个更加细粒度的分类任务.
谣言检测的早期研究基于博文内容[8-12]展开.但是,随着谣言检测技术的不断升级,谣言的伪装能力也在动态变化.例如,谣言的发布者常常会学习真实信息的写作特点和风格,故意模仿、伪造真实信息来逃避检测[13].因此,单纯基于博文内容检测方法,并不能有效地识别谣言.与博文内容相比,谣言的传播模式往往与真实信息的传播存在较大差异,且这类差异很难被隐藏.基于此,对信息传播结构的分析和探索成为了当下谣言检测研究的热点之一.
为了探究谣言的传播特征,一些谣言检测方法主要通过统计传播规律,人为构建特征[14-17],利用传统的机器学习方法识别谣言.此类方法依赖于繁重的特征工程,十分耗时,需要大量人力资源,并且人为构建的特征主观性较强,缺乏高阶的特征表示.近期,研究学者利用深度学习模型,提出很多有效的谣言检测方法[6,18-25].近期,基于图模型的方法[26-28]利用图神经网络建模传播树结构特征,将谣言检测任务转化为图分类任务,也取得了一定的成果.然而,这些方法仅关注了传播过程中博文之间的显式交互关系,如转发(或评论)关系,难以捕捉到复杂多样的传播结构特征,限制了谣言检测的性能.
在现实的信息传播过程中,用户是否转发(或评论)某条源博文,不仅取决于该条博文内容的影响,还可能会受到已转发(或评论)过该条博文的其他博文的影响.如图1所示,社交网络用户通过转发(或评论)行为传播谣言源内容,形成谣言的多级传播结构[29].本文发现,该谣言传播结构中包含2种不同类型的依赖关系,分别是层间依赖关系和层内依赖关系.1)层间依赖关系是指在相邻层级之间,父节点与其子节点之间的依赖关系,反映了谣言传播过程中,转发(或评论)博文与被转发(或被评论)博文之间的直接影响.2)层内依赖关系是指在同一层级下,同一父节点的孩子节点之间的依赖关系,反映了层级内的某条博文受到其他同级传播内容的潜在影响.这种层内依赖表现2个方面的特征:①局部的时序性特征,即先发布的博文对后发布博文产生一定的影响;②对同一博文的转发(或评论)内容越相似,更有可能形成这种层内依赖关系.现有的大多数研究仅仅考虑父子节点之间显式的层间依赖关系,而忽略了潜在的兄弟节点之间的层内依赖关系,难以捕捉到丰富的传播结构特征,限制了谣言检测的性能.

Fig. 1 Multi-relational dependences in a rumor propagation structure图1 谣言传播结构中的多种依赖关系
本文提出一种基于多关系传播树的谣言检测方法,共同建模传播树中父子节点之间的层间依赖关系和兄弟节点之间的层内依赖关系.该方法基于博文文本内容和传播树结构信息,先构建自顶向下传播方向和自底向上扩散方向的异构图,然后利用多关系图卷积网络建模复杂的传播结构特征,并通过聚合2个方向的节点特征生成最终的特征向量表示,用于谣言检测.
在谣言传播过程中,谣言源博文往往包含更丰富的信息内容,其他转发(或评论)博文与谣言源博文之间存在密切的关系.此外,除了谣言发布者,一些关键传播用户通过调动用户分享信息的积极性,在整个谣言传播的过程中也起着重要的中介作用.Soroush等人[1]分析Twitter平台的谣言传播模式发现,与真实消息相比,谣言传播的影响范围更广,真实消息在任意一个层级上参与转发的最多人数达到1 000以上,而谣言的最大转发数最多可达万级.本文认为,源博文和关键传播博文均对谣言的传播有着广泛的影响.然而,现有研究[30]仅仅考虑谣言源博文在传播过程中的重要影响.为了充分考虑这2类重要博文在传播过程中的潜在影响,本文提出一种关键节点增强的策略,利用传播树中根节点和当前路径最大转发节点,增强传播树中节点的特征向量表示,扩大重要博文的影响力,从而提升谣言检测性能.
本文的贡献主要包含4个方面:
1) 首次探究博文在传播过程中的多种交互关系,以挖掘更准确的谣言传播规律,而现有研究仅考虑显式的转发(或评论)交互关系;
2) 提出一种基于传播树的多关系图卷积网络模型,共同建模传播树中父子节点之间的层间依赖关系和兄弟节点之间的层内依赖关系,以捕获丰富的传播结构特征;
3) 提出一种关键节点增强的策略,利用传播树中的关键节点建模源博文和关键传播博文在信息传播中的潜在影响力;
4) 在3个社交网络数据集上评估模型,实验结果表明,本文方法具有比其他基线方法更高的谣言检测性能,并且在早期传播阶段也可有效地识别谣言.
1 相关工作
已有的谣言检测方法大致可分为:1)以博文内容和用户信息为主要特征的谣言检测方法;2)以传播结构信息为主要特征的谣言检测方法.
1.1 基于博文内容和用户信息的谣言检测方法
谣言检测的早期研究[6,11-12,30-31]基于博文内容构建人工特征,利用机器学习分类模型实现谣言检测.例如,Chua等人[8]通过分析文本内容的可理解性、情感、写作风格、主题等6类特征,通过逻辑回归分类器识别谣言;Castillo等人[9]基于人工构建的文本特征,研究信息可信度,利用决策树模型完成谣言的分类任务;刘政等人[25]通过卷积神经网络(convolu-tional neural network, CNN)自动挖掘文本深层的特征.除了文本特征,一些研究也基于博文的图像或音频等内容构建统计特征[7]、内容特征[32],用于检测社交媒体中的谣言.
但是,Sharma等人[13]指出,谣言发布者常常故意模仿、伪造真实信息来逃避检测,单纯基于博文内容的检测方法,并不能有效地识别谣言.一些研究[9-10,33-36]考虑引入用户信息辅助博文内容进行谣言检测.廖祥文等人[23]利用带有注意力机制的双向门控循环单元(gated recurrent unit, GRU)模块,提取文本潜在特征和局部用户特征,用于谣言检测.Shu等人[37]引入用户画像特征,利用多个机器学习模型识别谣言,检测性能得到一定的提升.
1.2 基于传播结构的谣言检测方法
基于传播结构的谣言检测方法通常分析博文转发(评论)等形成的传播路径或网络以识别谣言.早期方法主要基于传统的特征工程人工提取特征来完成谣言的分类[11,14-15,17,38].例如,Ma等人[16]利用时序特征建模社交上下文特征,从而识别社交网络中的谣言信息;Ma等人[17]提出基于内核的传播树方法,通过评估传播树之间的相似性来识别谣言;Wu等人[29]提出基于核的谣言检测模型;蔡国永等人[39]提出基于随机通路图核和RBF核的混合核方法,利用支持向量机(support vector machine, SVM)进行谣言检测;刘彻等人[40]提出一种改进的IMPA算法,以提升检测谣言源的性能.但是,这些方法依赖于繁重的特征工程,同时缺乏高阶的特征表示.
之后,研究学者利用深度学习模型建模传播结构,提出很多有效的谣言检测方法[19-20,28,41-48].例如,Ma等人[6]使用循环神经网络(recurrent neural network, RNN)对传播结构进行建模.Liu等人[49]使用RNN对传播路径建模,完成早期阶段的谣言检测任务;Ma等人[18]使用递归神经网络分别建模传播树自顶向下的传播方向和自底向上的扩散方向;随后,Chen等人[21]将CNN与注意力残差网络模型相结合,提高模型捕获长距离依赖的能力;Chen等人[22]利用CNN来提取分散在输入序列中的关键特征,有助于模型有效地识别谣言,尤其是在早期阶段的谣言检测中;Muhammad等人[41]也尝试结合CNN和LSTM的优点,学习更丰富的特征表示,用于识别虚假信息中的立场类别;李力钊等人[50]结合CNN和GRU的优点,学习微博事件的特征表示用于谣言事件检测.
近年来,图卷积网络(graph convolutional network, GCN)[51]模型由于其强大的表示能力,在图像处理[52-53]、自然语言处理[54-56]等领域受到广泛关注.谣言检测任务中,研究者们尝试将传播树构建为图结构,从而将谣言检测问题转化为图分类问题,取得了不错的进展[26-28].Bian等人[26]利用图卷积网络模型,基于自顶向下和自底向上2个方向挖掘传播树的传播结构特征;Yang等人[27]在图结构上引入了对抗训练方法来提高对谣言传播的图表示学习能力.然而,这些方法仅关注了传播过程中博文之间的显式交互关系,如转发(或评论)关系,难以捕捉到复杂多样的传播结构特征,限制了谣言检测的性能.
本文探究谣言传播过程中的多种传播路径,提出一种基于多关系传播树的谣言检测方法,共同建模父子节点之间的层间依赖关系和兄弟节点之间的层内依赖关系,为每个节点学习更准确的特征向量表示.此外,考虑到传播过程中关键节点的重要影响,本文提出基于关键节点增强的策略,建模源博文和关键传播博文在传播过程中的潜在影响力,学习更全面的谣言特征向量表示,用于提升谣言检测性能.
2 问题定义
本节简述谣言和传播树的定义,并描述谣言检测任务的形式化定义.
定义1.谣言(rumor)[4].谣言是一种从一个人传到另一个人的故事,其中的真相未经证实或值得怀疑.谣言通常出现在模棱两可或有威胁的事件中.
定义2.信息传播树(information propagation tree)[29].一条信息对应的发布博文和其后续所有的转发(评论)博文,生成的传播路径是一个树状结构,通常被称为信息传播树,简称传播树.其中,根节点表示信息发布博文(源博文),其他节点表示后续的转发(或评论)博文.
给定样本包含源博文和其后续转发(或评论)博文的文本信息以及对应的传播结构信息,谣言检测(rumor detection)的目标是学习一个分类器,预测其类别概率分布.
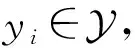
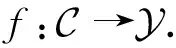
(1)
3 基于多关系传播树的谣言检测方法
本节详细介绍本文提出的基于多关系传播树的谣言检测方法RumorGCN.为简化描述,在本节及后续章节,统一用“转发博文”代替“转发(或评论)博文”,用“被转发博文”代替“被转发(或被评论)博文”.
3.1 总体架构
本文提出的谣言检测方法RumorGCN的总体架构如图2所示,包含多关系异构图构建、关键节点增强的多关系图卷积网络以及谣言分类器3个部分.

Fig. 2 The overall architecture of the proposed model (take the forwarding relations)图2 基于多关系传播树的谣言检测方法总体框架(以转发关系为例)
首先,基于给定样本中的博文文本内容和传播树结构信息,同时构建自顶向下传播方向和自底向上扩散方向的多关系异构图.
其次,利用多关系图卷积网络,共同建模传播树中父子节点之间的层间依赖关系和兄弟节点之间的层内依赖关系,以捕获丰富的信息传播结构特征.接着,利用传播树中的根节点和当前路径最大转发节点增强传播树中当前节点的特征表示,建模重要博文在信息传播中的潜在影响力.
最后,融合传播树传播方向和扩散方向的特征向量表示,生成样本的特征向量表示.基于此,预测样本属于不同类别的概率,输出类别标签.
3.2 多关系异构图构建
对于每个样本c={r,x1,x2,…,xn-1,S},基于博文文本和传播树结构,同时构建自底向上(bottom-up, BU)信息扩散方向上的多关系异构图GBU和自顶向下(top-down, TD)信息传播方向上的多关系异构图GTD.
图GTD包含2种类型的边,即父节点与子节点之间形成的层间依赖关系边以及兄弟节点之间形成的层内依赖关系边,分别代表了社交网络中转发博文与被转发博文之间的关系以及转发同一博文的多个转发博文之间的关系.对于第1种类型边,根据传播过程中的转发关系进行构建,即博文与其转发的博文之间形成一条边.对于第2种类型边,转发同一博文的转发博文之间构成了兄弟关系.
社交网络中,先转发的博文可能会对后转发的博文产生一定的传播影响,并且,转发同一博文且时间相邻的2条博文之间更有可能存在这种关系,因此,先基于转发的时间先后顺序,在每条博文的转发博文对应的节点之间构建候选的有向时序边.计算每条时序边相邻的2个节点特征向量xi,xj的余弦相似度,记为score(xi,xj),如果相似度得分大于预设的阈值T,即score(xi,xj)>T,这条候选的有向时序边保留作为第2种类型边,否则去掉该候选边.
形式化地,对于每种类型边,定义如下:Ek={ek,pq|p,q=0,…,n-1},k∈{inter,intra},其中,inter和intra分别表示信息传播方向对应的传播树STD中层间依赖关系与层内依赖关系.邻接矩阵用Ak表示:
(2)
例如,如图2所示,节点2和节点3相继转发了节点1,对于传播树中的第1种类型边,节点1和节点2、节点1和节点3之间构建1条有向边,即einter,01和einter,02;对于第2种类型边,节点2和节点3均转发了节点1,并且节点2转发节点1早于节点3,则构建1条节点2指向节点3的有向边,即eintra,12.
为缓解图卷积网络中存在的过拟合问题,Rong等人[58]提出DropEdge方法.该方法的思想是基于一定的概率随机失活输入图中的边,从而达到缓解过拟合的目的.给定邻接矩阵A以及失活概率η,Ne表示原图中边的数量,在给定图的边集合中随机采样Ne×η条边,形成Adrop,处理后的邻接矩阵为
A′=A-Adrop.
(3)

3.3 关键节点增强的多关系图卷积网络模型
3.3.1 基于层间-层内依赖关系学习节点表示
图卷积网络(graph convolutional network, GCN)[51]模型的基本思想是通过节点间的信息传播更新节点的特征表示,定义一个卷积层操作,描述信息传递过程,通过迭代地聚合边的信息和节点的信息,生成新的节点表示.
为了更好地建模博文之间的多种交互关系,本文采用多关系图卷积网络[59]融合不同关系下节点的邻居信息,学习传播树的信息传播结构特征.具体地,为了共同建模传播过程中的层内依赖和层间依赖,本文聚合不同关系类型下的邻居节点信息,并进行归一化操作,生成节点的隐藏特征向量表示.为了确保节点自身第l层到第l+1层之间的信息传递,为每个节点增加自连接,即αvv=1.
给定节点的初始化特征向量表示X= [xr,x1,…,xn-1]T,第1层的信息传递:
∀v∈V,
(4)

在第2层图卷积网络中,基于第1层图卷积网络的输出,聚合邻居节点的信息:
∀v∈V,
(5)

通过2层不同的图卷积操作,可以有效累积在不同依赖关系下的局部邻域特征.最终,基于传播方向的异构图GTD和扩散方向的异构图GBU,分别学习到传播树中的各个节点特征表示,记为

3.3.2 基于关键节点增强特征向量表示
在谣言传播的过程中,许多用户发布的内容起到了推波助澜的作用.以转发关系为例,为了探究源博文和关键传播博文在信息传播中的潜在作用,本文利用传播树中的2类关键节点对当前节点的特征进行增强.对于传播树中的任一节点,对应的2个关键节点分别为其根节点和当前路径最大转发节点.
1) 根节点.根节点代表源博文,包含了丰富的谣言源信息,有助于帮助学习更准确的节点表示.给定当前节点xi,该节点对应的根节点记为xi,root,即xi,root=r.利用根节点增强特征向量表示,xi,root对应的特征向量表示记为hroot.

(6)
其中,ODinter(xj)表示节点xj基于层间依赖关系的出度.例如,图2中,节点9对应的当前路径最大转发节点为节点3.xi,mod对应的特征向量,表示记为hmod.

(7)
(8)
3.4 谣言分类器
分别聚合自顶向下传播方向和自底向上扩散方向中各个节点的特征向量表示,得到传播树在传播方向和扩散方向的特征向量表示:
(9)
(10)
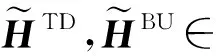
最后,拼接自顶向下方向的特征向量表示和自底向上方向的特征向量表示作为该样本最终的特征向量表示:
C=concate(CTD,CBU),
(11)
其中,concate表示向量操作.
本文将谣言检测任务转化为图分类问题.基于谣言特征向量表示,通过线性层和softmax函数计算该谣言属于每个类别的概率:
(12)
其中,Wc和bc是需要学习的参数.
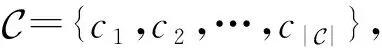
(13)
其中,yi是表示第i个样本的真实标签向量表示,β是超参数,表示L2正则化的大小,Θ是模型需要学习的所有参数.
4 实验设置
本节详细阐述本文的实验设置,4.1节介绍本文实验所用到的3个真实评测数据集,Twitter 15[17],Twitter 16[17]和PHEME[5].4.2节简要地描述本文所选取的基线方法.4.3节描述实验评估指标.4.4节记录实验的主要参数设置.
4.1 数据集
本文将在Twitter 15,Twitter 16和PHEME三个公开数据集上测试本文提出的方法.数据统计特征如表1所示.
1) Twitter15数据集和Twitter16数据集(1)https://www.dropbox.com/s/7ewzdrbelpmrnxu/rumdetect 2017.zip?dl=0是由Ma等人[17]创建,收集了不同时刻来自国外著名社交网络平台Twitter网站上的谣言信息,分别包含1 490和818条样本.参考Zubiaga等人[5]和Ma等人[17],根据辟谣网站(如snopes.com,Emergent.info等)中文章的真实性标签,每个样本被标注为4种标签之一,即真谣言(true rumor, TR)、假谣言(false rumor, FR)、未经证实的谣言(unverified rumor, UR)、非谣言(non-rumor, NR).Twitter15和Twitter16数据集的划分方式参考现有研究[11,18,22],采用5折交叉验证的方式进行实验.
2) PHEME数据集(2)https://figshare.com/articles/dataset/PHEME_dataset_for_ Rumour_Detection_and_Veracity_Classification/6392078是由Zubiaga等人[5]创建,围绕9个事件共收集了2 402条谣言,被标记为3个类别,分别是真谣言(true rumor, TR)、假谣言(false rumor, FR)、未经证实的谣言(unverified rumor, UR).该数据集划分方式参考基线方法[20,28],采用留一法(leave-one-event-out)交叉验证的方式进行实验,这使得谣言检测任务更加困难,但是更接近于现实场景下未知事件的谣言检测.参考前人的训练方式[20],本文将标签分布较为平均的Charlie Hebdo事件中的样本作为验证集,以选择模型的最优参数.
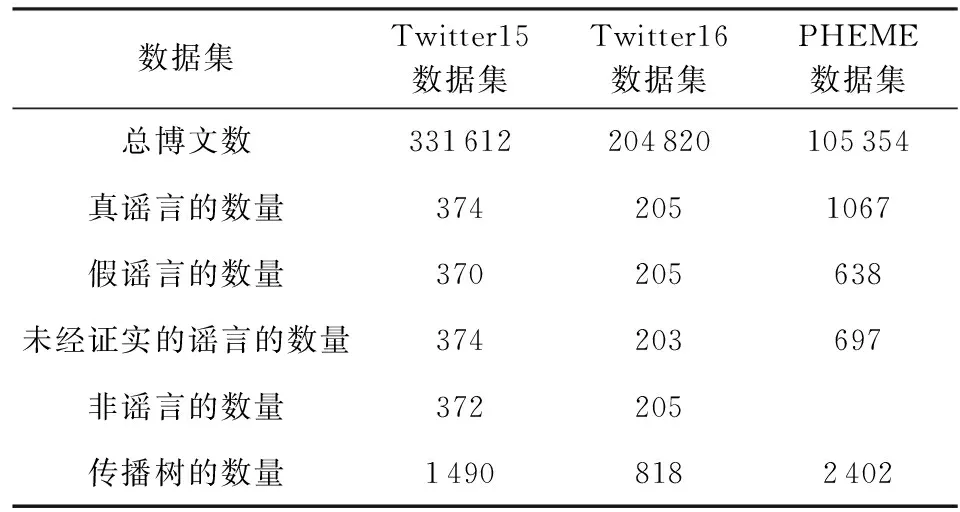
Table 1 Statistics of the Datasets表1 谣言检测数据集统计信息
4.2 实验对比方法
本文选取基于特征工程的谣言检测方法、基于核函数的谣言检测方法以及基于深度学习模型的谣言检测方法作为基线方法,与本文提出的方法RumorGCN进行对比.
Twitter15和Twitter16数据集的基线方法包括:
1) DTC.Castillo等人[9]基于人工设计的全局统计特征,构建决策树分类器获取信息可信度;
2) SVM-RBF.Yang等人[10]基于博文内容人工构建统计特征,构建基于RBF核函数的支持向量机分类器识别谣言;
3) SVM-TS.Ma等人[16]基于时序上下文特征构建线性支持向量机分类器对谣言进行分类;
4) SVM-TK.Ma等人[17]采用基于传播树的核函数提取结构特征,利用支持向量机分类器完成分类;
5) GRU-RNN.Ma等人[6]基于递归神经网络,通过建模相关帖子的序列结构学习谣言的特征向量表示.
6) RvNN.Ma等人[18]利用2个循环神经网络模型分别对传播方向和扩散方向进行建模,学习传播树的特征向量表示;
7) StA-PLAN.Khoo等人[19]采用Transformer模型挖掘传播过程中的博文之间长距离的交互特征,学习谣言的特征向量表示,基于该特征向量表示完成分类任务;
8) Bi-GCN.Bian等人[26]基于传播树的传播方向和扩散方向构建图卷积网络模型,将谣言分类任务转化为图分类任务.
对于PHEME数据集,本文与目前性能较好的5个具有代表性的基线方法进行对比:
1) NileTMRG.Enayet等人[12]提出的基于词袋模型获取博文的向量表示,利用支持向量机分类器完成分类;
2) RvNN.Ma等人[18]提出的基于RNN的谣言检测模型;
3) branchLSTM.Kochkina等人[20]利用序列模型LSTM检测谣言,并采用多任务学习方式,联合训练谣言检测和立场识别任务;
4) Hierarchical GCN-RNN.Wei等人[28]利用GCN建模传播过程中的结构特征,并利用多任务学习同时建模谣言分类任务和立场检测任务;
5) Bi-GCN.Bian等人[26]提出的基于图的谣言检测方法.
为了保证公平性,对于基于多任务方法(branch-LSTM和Hierarchical GCN-RNN),本文仅考虑其在谣言分类单一任务下的性能.此外,参考Hierar-chical GCN-RNN采用skip-gram语言模型[60]提取博文的文本特征,本文也采用相同的方式对Bi-GCN和RumorGCN的文本特征编码部分进行改进,分别记为Bi-GCN(SKP),RumorGCN(SKP).
4.3 评估方法
本文所研究的谣言检测问题本质上是一个分类问题,为此,本文选用基于分类的评价指标来评测谣言检测性能.
对于Twitter15和Twitter16数据集,本文选用准确率(accuracy,Acc)和各个类别的F1值作为评价指标:
(14)
其中,TP(true positive)是真正例,指被模型预测正确的正样本;FP(false positive)是假正例,指被模型预测正确的负样本;FN(false negative)是假负例,指被模型预测错误的正样本;TN(true negative)是真负例,指被模型预测错误的负样本.
对于PHEME数据集,参考基线方法[20,28],本文选用准确率、宏平均F1值(macro-averagingF1,macro-F1).macro-F1即先对每一个类统计指标值,然后在对所有类求算术平均值,计算方法为
(15)
其中,n表示预测类别的个数.考虑该数据集中各个类别样本不平衡,本文还比较了加权平均F1值(weighted-averagingF1,weighted-F1) ,先对每一个类统计指标值,然后在对所有类别求加权平均值,计算方法为
(16)
其中,权重γi为各个类别在样本中所占的比例.
4.4 参数设置
参考基线方法的参数设置[18,26],提取博文文本信息的TF-IDF特征,初始化节点的输入向量表示,其维度d0=5 000.采用2层的图卷积网络模型进行训练,每1层中节点的隐向量维度为64,即d1=d2=64.模型各层的dropout=0.5.采用Adam算法训练模型,迭代次数设为200,并设置提前结束(early stopping),即当验证集的损失函数在10个迭代内不再下降时,提前终止训练.本文提出的模型基于PyTorch(3)http://pytorch.org/开源工具实现,采用Tesla M40 24 GB的GPU训练模型.
对于Twitter15和Twitter16数据集,学习率(learning rate)设置为0.000 5.DropEdge的失活概率η=0.2.相似度阈值T分别为0.8和0.6.
对于PHEME数据集,学习率设置为0.02,DropEdge的失活概率η=0,相似度阈值T=0.7.参考文献[28], Bi-GCN(SKP)和RumorGCN(SKP)中skip-gram语言模型的特征维度设置为200.
5 实验结果与分析
本节描述实验结果并进行分析.5.1节对本文提出RumorGCN和基线方法在谣言检测任务的性能进行对比分析;5.2节探究建模传播树中不同依赖的影响;5.3节探究了传播树中不同关键节点的影响;5.4节对比分析不同相似度阈值对谣言检测结果的影响;5.5节评估本文提出方法RumorGCN和对比的基线方法在早期谣言检测任务中的性能.
5.1 谣言检测实验结果与分析
5.1.1 Twitter15和Twitter16数据集的实验结果分析
Twitter15和Twitter16数据集的实验结果如表2和表3所示.其中,本文使用文献[26]提供的开源代码在相同环境进行实现,得到了Bi-GCN模型在2个数据集的实验结果.其他基线方法的结果均参考文献[18-19].
由表2和表3可知,本文提出的RumorGCN在Twitter15和Twitter16数据集上均优于对比的基线方法.对于Twitter15数据集,相比于最优的基线方法,RumorGCN在准确率指标上提升1个百分点,F1值指标上最大提升了1.8个百分点;对于Twitter16数据集,RumorGCN在准确率指标上提升了2个百分点,F1值指标上最大提升了3.7个百分点.这些结果表明本文提出的方法具有比其他基线方法更高的谣言检测性能.
基于表2和表3中的实验结果,具体分析为:
1) 所有基于深度学习的方法(GRU-RNN,RumorGCN,Bi-GCN,StA-PLAN以及RvNN)的谣言检测性能均优于基于人工构建特征的谣言检测方法(DTC,SVM-RBF,SVM-TS,SVM-TK).该现象证实了深度学习模型在谣言检测任务中的优越性,主要优势在于深度学习模型可以学习谣言潜在的特征向量表示.DTC,SVM-RBF,SVM-TS和SVM-TK利用人工构建特征的方法识别谣言,提取的特征具有较强的主观性,缺少谣言潜在的特征表示,不能较好地识别社交网络中的谣言.

Table 2 Rumor Detection Results on Twitter15 Dataset表2 谣言检测实验结果(Twitter15) %

Table 3 Rumor Detection Results on Twitter16 Dataset表3 谣言检测实验结果(Twitter16) %
2) RvNN通过使用递归神经网络模型对传播树进行建模,但是难以捕获序列中长距离的依赖关系,因此,谣言检测的性能受到了制约.StA-PLAN利用Transformer结构,可以有效缓解长距离依赖问题,因此,获得了优于RvNN的检测性能.与RvNN和StA-PLAN相比,基于图的谣言检测方法(RumorGCN和Bi-GCN)在所有深度学习模型方法中表现最佳,这也表明图模型具有捕获复杂依赖关系的能力.
3) 与最优的基线方法Bi-GCN相比,RumorGCN在2个Twitter数据集中均有更优的表现,说明RumorGCN在谣言检测任务中的有效性.本文认为性能提升的原因主要源于2个方面:
1) 在对谣言树中的依赖关系建模时,Bi-GCN仅仅考虑传播树中父子节点之间形成的层间依赖关系,而RumorGCN共同显式建模层间依赖关系和兄弟节点之间形成的层内依赖关系,聚合不同依赖关系下的局部邻域信息,可以学习到更准确、更丰富的传播结构特征.由此说明,传播树中的层内依赖关系同样可以为谣言检测提供有效信息.在社交媒体中,用户转发某条源博文,不仅受到源博文的影响,同时还可能受到转发过该源博文的其他博文的影响,从而形成复杂的多种传播路径.
2) Bi-GCN中通过利用根节点特征辅助学习节点特征表示,忽略了传播过程中的另一类关键节点的重要影响.RumorGCN同时考虑根节点和当前路径最大转发节点,增强传播树中的节点特征表示,充分建模关键节点对信息传播的潜在影响力,从而提升模型的检测性能.
5.1.2 PHEME数据集的实验结果分析
表4记录了本文提出方法和对比的基线方法在PHEME数据集上的实验结果,其中,NileTMRG和BranchLSTM的结果参考文献[20],RvNN和Hierarchical GCN-RNN的结果参考文献[28].本文基于Bi-GCN的开源代码进行实验,得到Bi-GCN在PHEME数据集上的实验结果.从结果可知,与最优的基线方法相比,RumorGCN在准确率指标上提升了17个百分点,宏平均F1值提升了7.9个百分点,加权平均F1值指标上提升了10.3个百分点.
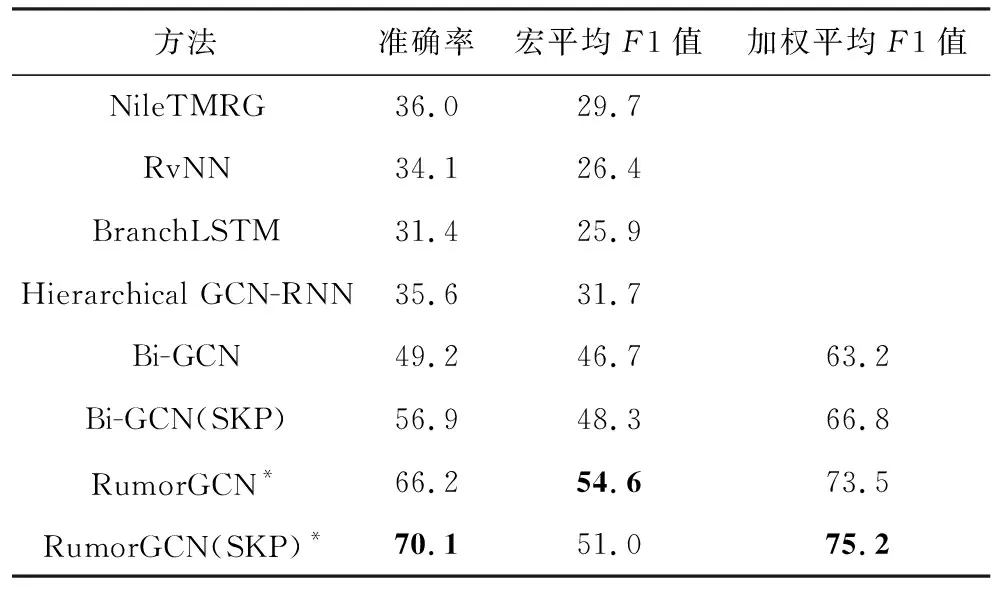
Table 4 Rumor Detection Results on PHEME Dataset表4 谣言检测实验结果(PHEME) %
基于表4的实验结果,具体分析为:
1) 与基线方法相比,RumorGCN在PHEME数据集上取得了较优的谣言检测结果,再次说明RumorGCN建模多关系传播路径和关键节点增强的有效性. Hierarchical GCN-RNN虽然也利用图卷积网络建模了谣言的传播结构,但是该方法仅考虑建模传播方向的结构特征,忽略了扩散方向上的传播规律.相较之下,Bi-GCN和RumorGCN共同建模传播树在传播方向和扩散方向的规律,可学习更丰富的特征表示向量,更有助于识别谣言信息.
2) 与利用skip-gram语言模型提取博文文本特征的基线方法Hierarchical GCN-RNN和Bi-GCN(SKP)对比,在采用相同文本特征提取方式的前提下,本文提出方法的变体RumorGCN(SKP)在3个指标均取得最好的检测性能,这说明本文方法在不同文本特征提取方式下的有效性.
3) 采用skip-gram语言模型提取文本词向量特征的Bi-GCN(SKP) 和RumorGCN(SKP),相比对应的基于TF-IDF统计特征的Bi-GCN和RumorGCN,取得更高的准确率和加权平均F1值,这说明skip-gram语言模型可以更充分地挖掘博文的语义特征,有助于模型识别更多的谣言.注意到RumorGCN(SKP)的宏平均F1值优于RumorGCN,该结果的原因是PHEME数据集中类别标签分布不平衡导致,宏平均F1值会受到稀有类别的影响.
5.2 传播树中不同依赖的影响分析
为了探究在传播过程中博文之间的多种交互关系,本节对传播树中层间依赖和层内依赖的建模方式进行了一系列消融实验.基于这2种依赖关系的类型特性,本节设置了RumorGCN的4种相关变体,具体为:
1) GCN(Inter-Intra)指利用传统的GCN模型共同建模传播树中的层间依赖和层内依赖;
2) RumorGCN(Non-Seq)指在建模层内依赖时,没有引入层内节点之间的时序边,而是在层内节点之间构建全连接边,如图2中,对于第2种类型边,在节点4、节点5和节点8之间均构建一条边;
3) RumorGCN(Intra-Level)指仅建模传播树中的兄弟节点之间的层内依赖,而不考虑层间依赖;
4) RumorGCN(Inter-Level)指仅建模传播树中的父子节点之间的层间依赖,而不考虑层内依赖.
在3个数据集上的消融实验结果如表5~表7所示,结果分析为:
Table 5 Results of Ablation Study with Different Dependencies in the Propagation Tree on Twitter15 Dataset表5 传播树中不同依赖的消融实验结果(Twitter15) %
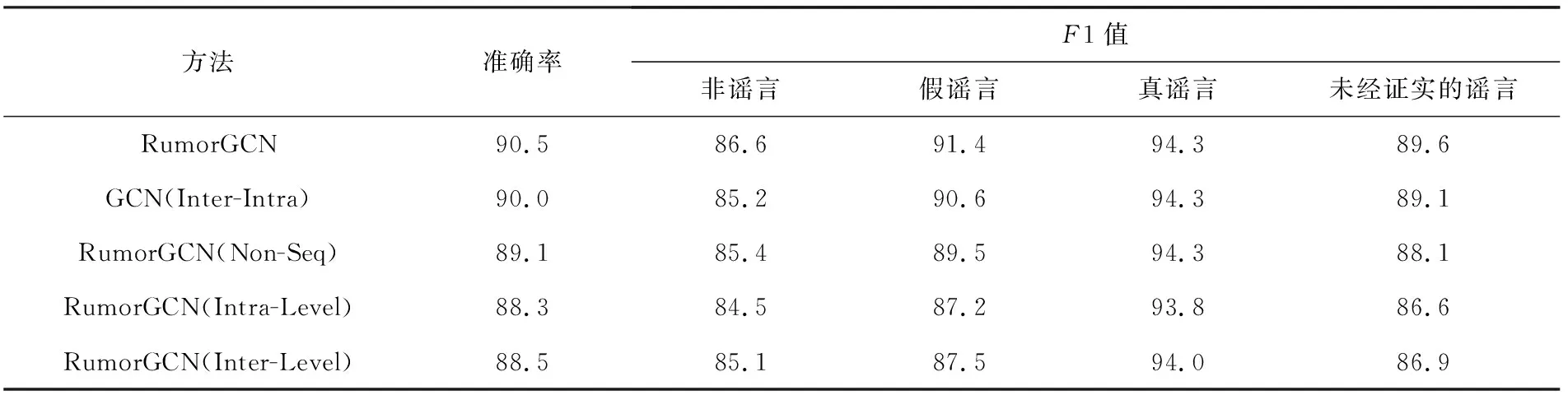
Table 6 Results of Ablation Study with Different Dependencies in the Propagation Tree on Twitter16 Dataset表6 传播树中不同依赖的消融实验结果(Twitter16) %

Table 7 Results of Ablation Study with Different Dependencies in the Propagation Tree on PHEME Dataset表7 传播树中不同依赖的消融实验结果(PHEME) %
1) GCN(Inter-Intra)变体方法基于同构图结构建模传播树中的依赖关系,在3个数据集上性能均有一定的下降.这说明利用多关系图卷积模型的异构图结构能更好地捕捉节点之间不同类型的关系.这也间接说明在传播过程中,博文之间的显式和隐式交互形式具有不同的特性.
2) 与同时建模2种依赖的RumorGCN方法相比,仅建模层内或层间单一依赖的变体方法RumorGCN(Intra-Level)和RumorGCN(Inter-Level)的检测性能均有明显的下降.这说明了建模传播树中的层内依赖和层间依赖的有效性.对于RumorGCN方法,同时考虑传播过程中博文之间的多种交互关系,可以捕捉到更丰富的传播结构特征,进而得到更高的谣言检测性能.
3) 建模传播树中的层内依赖时,考虑时序边的RumorGCN的检测性能明显高于考虑全连接边的RumorGCN(Non-Seq)变体方法.这表明了建模层内依赖的局部时序性特征的有效性.这也说明了在谣言传播过程中,较早转发该谣言的博文对后续浏览的部分用户确实具有一定影响,这也为谣言的防治提供了新思路.
5.3 传播树中不同关键节点的影响分析
为了探究源博文和关键传播博文这2类重要博文在信息传播中的潜在影响,本节基于不同方向的传播树,对2类关键节点的增强策略进行了详细的消融实验.
通过考虑不同方向的传播树,可得到4种传播树建模方案,以及对应RumorGCN的4种变体.这4种传播树结构包括UD,BU,TD和BU+TD.其中,UD(undirected)表示无向的传播树结构,TD(top-down)指仅考虑自顶向下的传播方向,BU(bottom-up)指仅考虑自底向上的扩散方向,BU+TD指同时考虑传播和扩散2个方向.
在这4种传播树结构下,为了探究根节点和当前路径最大转发节点的增强作用,本节设置了4种不同的对比策略.记ROOT和MOD分别为根节点和当前路径最大转发节点,则4种策略具体如下:
1) w/o ROOT & w/o MOD.指不使用任何关键节点增强节点的特征表示;
2) w ROOT & w/o MOD.指仅利用根节点进行特征增强;
3) w/o ROOT & w MOD.指仅利用当前路径最大转发节点进行特征增强;
4) w ROOT & w MOD.指同时利用根节点和当前路径最大转发节点进行特征增强.
实验结果如图3所示,结果分析为:

Fig. 3 Results of ablation study for different key nodes in the propagation tree图3 传播树中不同关键节点的消融实验结果
1) w/o ROOT & w/o MOD变体方法未考虑任何关键节点的增强影响,在4种传播树结构下均获得了较差的检测性能.
2) w ROOT & w/o MOD和w/o ROOT & w MOD两种变体方法在4种传播树结构下均获得了较好的性能表现,表明基于根节点和当前路径最大转发节点的这2种特征增强策略的有效性.同时,仅利用当前路径最大转发节点与仅利用根节点进行特征增强的效果相当.这表明,除了源博文,关键传播博文也有着巨大的影响力,在信息传播过程中发挥着关键的桥梁作用.
3) w ROOT & w MOD变体方法同时考虑了这2类关键节点的增强作用,在4种传播树结构下均获得了最优的谣言检测性能,同时这也是本文方法RumorGCN所采取的节点增强策略.该结果表明同时考虑这2种关键节点的增强策略在该任务上的有效性.同时,也说明了源博文和关键传播博文在信息传播中均有着不可忽视的潜在影响力,对于谣言的发现和识别均有一定的积极作用.
4) 在相同的节点增强策略下,对于基于不同方向的传播树结构得到的4种变体,检测性能从低到高排序为:UD变体方法、BU或TD变体方法、BU+TD变体方法.由此可见,同时建模传播和扩散2个方向的传播树结构,有助于挖掘更丰富的传播结构特征,更好地识别社交网络中的谣言信息.
5.4 相似度阈值的影响分析
本节对比不同相似度阈值对谣言检测结果的影响.该阈值越高,表明2个博文之间内容越相似.选取了[0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]共11种阈值进行实验,结果如图4所示.横轴为相似度阈值大小,纵轴为准确率.Twitter15,Twitter16,PHEME数据集的最优阈值分别为0.8,0.6,0.7.
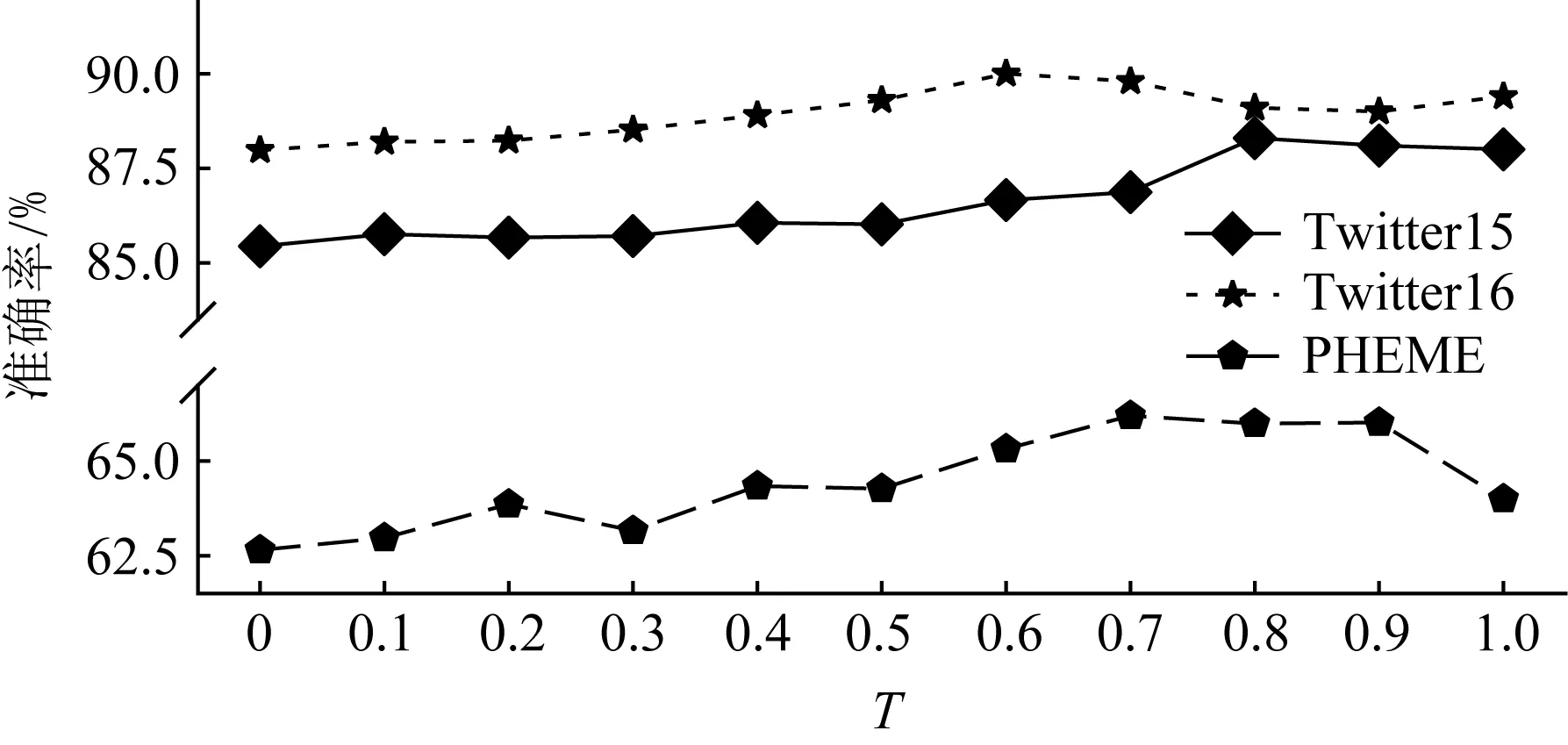
Fig. 4 Results against different thresholds T图4 不同相似度阈值T的谣言检测结果
实验结果如图4所示,结果分析为:
1) 过大的相似度阈值或者过小的相似度阈值均会限制模型识别谣言的性能.当阈值设置过小时,可能会引入一些噪声边,相似度较小的2个博文之间可能并不存在影响;当阈值设置过大时,使得转发过同个博文的节点之间无法构建边,不能很好地建模层内依赖关系,从而限制了模型的检测能力,这也再次说明了建模层内依赖关系对于谣言检测任务的重要性.
2) 最优阈值在3个数据集上均不相同,这可能是因为谣言所针对的事件不同,同时,在数据集中,也存在一定的噪音现象.在实际应用过程中,该参数的选择可参考本文在PHEME数据集上的选择方法,即将类别标签分布较为平均的某个谣言事件数据集作为验证集,以选择最优相似度阈值.
5.5 早期谣言检测实验结果与分析
谣言的早期检测要求模型在谣言传播的早期阶段识别谣言,便于及时进行干预,以将谣言产生的危害降低到最小.谣言的早期阶段通常是指谣言转发数较少或者刚产生的几小时.参考文献[18,26],本节分别通过限制源博文的转发数和其发布后的经过时间2种延时策略,来评估本文提出方法和其他基线方法的早期谣言检测能力.实验结果如图5和图6所示:
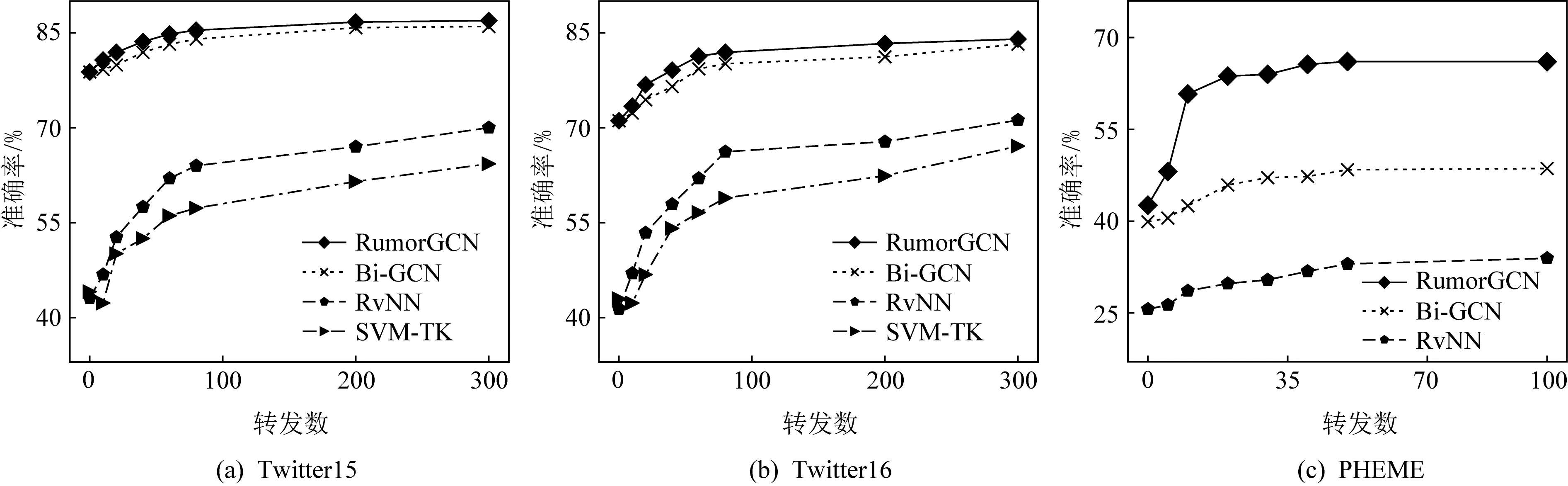
Fig. 5 Results of early rumor detection against the comment forwarding dimension图5 基于不同转发数的早期谣言检测结果
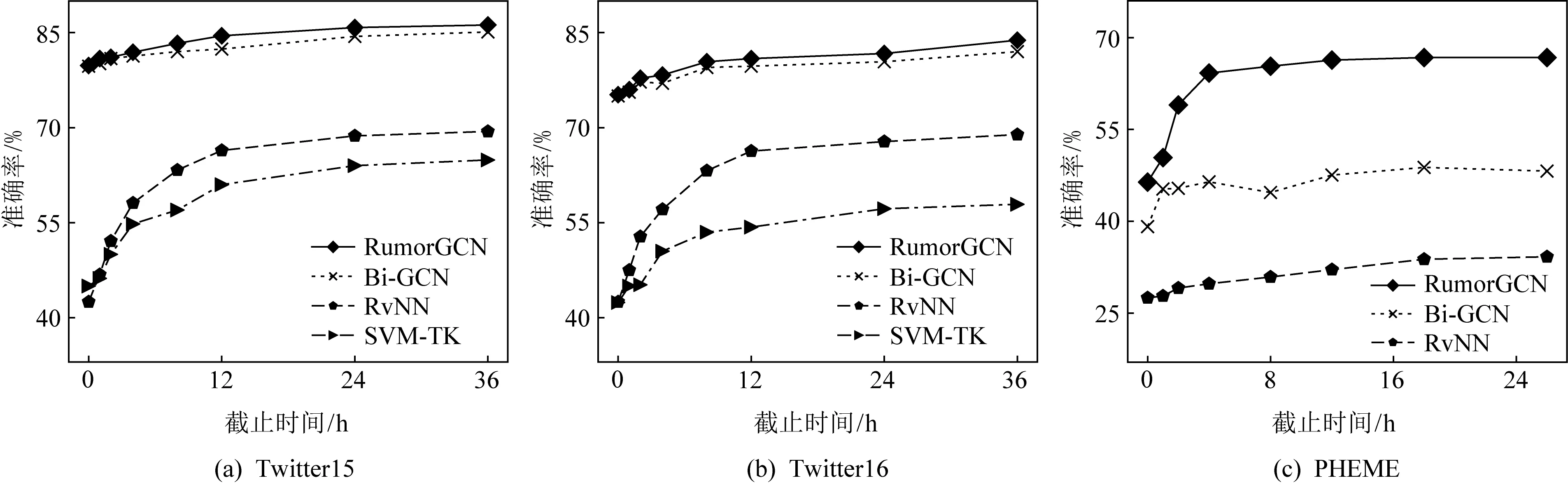
Fig. 6 Results of early rumor detection against deadline time图6 基于不同截止时间的早期谣言检测结果
5.5.1 有限转发数下的早期谣言检测
通过控制自源博文发布以来用户转发的数量,计算不同时期谣言检测的准确率,评估模型的性能.实验结果如图5所示,横轴代表用户转发的博文数量.随着转发次数的增加而增加,不同方法的谣言检测性能逐渐上升.RumorGCN和Bi-GCN在谣言源进行初始广播后的很早期就达到了较高的准确率.这说明,图卷积网络可以有效聚合邻居节点信息,学习准确的节点特征向量表示用于提升模型的早期检测谣言的能力.在PHEME数据集上,RumorGCN使用不到10条博文时优于Bi-GCN使用所有数据的性能.这一优势可归因于RumorGCN对于转发同一博文的多个转发博文之间形成的层内依赖关系的探索,表明本文提出的方法可以有效地同时建模层间依赖和层内依赖,获得更准确的谣言检测结果.
5.5.2 有限时间内的早期谣言检测
通过控制源博文发布以来的截止时间,计算不同时期谣言检测的准确率,评估模型的性能.实验结果如图6所示,横轴代表截止时间,单位为小时(h).时间维度的效果与转发维度的趋势保持一致,随着时间的推移,不同谣言检测方法均有一定的提升,这说明信息传播过程中显现的结构特征会越来越丰富.同时,在信息传播的早期阶段,基于图的模型可以捕获更全面的有限传播结构特征,从而具有比其他对比模型更优的检测性能.尤其是在PHEME数据集上,RumorGCN在使用前2 h数据的谣言检测性能已优于基线方法使用所有数据的谣言检测性能.这也再次说明博文之间多种交互关系的重要性和本文提出方法的有效性.
6 总 结
本文研究了基于文本内容和传播结构信息的谣言检测任务,提出一种基于多关系传播树的谣言检测方法.该方法通过多关系图卷积网络建模了传播树中父子节点之间形成的层间依赖关系和兄弟节点之间形成的层内依赖关系,以捕获复杂的传播结构特征.同时,利用关键节点增强传播树中节点的特征向量表示,有效建模了源博文和关键传播博文在谣言传播过程中的潜在影响力,学习更准确的谣言特征向量表示.在3个公开数据集上的广泛实验表明,本文提出的方法具有比其他基线方法更高的谣言检测性能,并且在谣言的早期传播阶段,也具有良好的检测效果.该方法进一步探索了谣言的深层传播规律,对迅速甄别社交媒体中的谣言、建设清朗的网络空间有重大的现实意义.
