基于主题与情感联合预训练的虚假评论检测方法
2021-07-23张东杰黄龙涛林俊宇
张东杰 黄龙涛 张 荣 薛 晖 林俊宇 路 瑶
1(阿里巴巴集团 北京 100102)
2(中国科学院信息工程研究所 北京 100093)
3(廊坊职业技术学院 河北廊坊 065001)
随着互联网的发展,越来越多的线下销售行为被转移到线上.由于线上商品种类齐全、琳琅满目且处于虚拟环境,商品的评论信息已经成为用户决策过程中非常重要的影响因素.现实生活中许多商家出于盈利和打击竞品的目的,通常会雇佣一些专业写手来撰写虚假的商品评论[1].浏览了虚假评论的用户往往会对商品产生错误的预估,从而极大地影响用户的购物体验.
虚假评论检测任务由Liu等人[1]最先提出,现在已经成为了学术界的研究热点之一.虚假评论通常是由专门的作者通过仿照真实评论者的说话方式产生,在内容上有着较高的相似性,但通过深入研究后可以发现其与真实评论之间仍然存在着诸多差异.首先虚假评论往往由固定的一批人来创作,因为每个人的写作习惯和表达方式都相对固定,并且为了提高写作效率,专业写手往往会套用一些写作模板,每次撰写评论时只对文本细节进行小幅修改,这就造成了虚假评论在语义层面上往往内容的相似度较高,因此可以从语义层面上对评论文本进行建模来判定商品评论的真实性.
通常在撰写虚假评论时,作者往往具有很强的目的性,例如故意夸大或者贬低某件商品.我们通过观察发现含有比较绝对的话语和情感表达突出的商品评论往往更倾向于虚假信息[1-2].如图1所示,我们列举了一个公开虚假评论检测数据集[3]中的几个实例,它们分别是关于酒店Mike Ditka’s和Weber Grill的评论文本.从示例中我们可以看到,虚假评论中往往会存在一些明显的感情倾向(粗体的单词),而这些情感突出的表达方式也容易对用户产生误导使其不能对商品进行全面地考虑.因此评论的情感因素也是鉴别虚假评论信息的一种重要特征.

Fig. 1 Examples of fake and real reviews about restaurants of Mike Ditka’s and Weber Grill[3]图1 关于餐厅Mike Ditka’s和Weber Grill的虚假评论和真实评论实例[3]
在不久之前,许多预训练模型[4-7]被相继提出,并在包括情感分析在内的众多NLP任务中都取得了state-of-art的效果.预训练模型通过在大量未标注的语料上采用许多无监督的学习策略,包括mask机制[1]、后续单词预测[5]和排列机制[5]等,获得了强大的语义表示能力.其复杂的和多层的模型结构也能够让这些模型更方便地对复杂的下游任务进行建模,因此预训练模型在许多相关的自然语言处理任务中都有着出色的表现.
尽管预训练模型[4-7]在通用语义层面有着出色的表示能力,但在情感相关信息的表达上仍然有待进一步的改进.这些预训练模型大多采用基于单词序列预测的目标函数,尽管这种目标函数能够捕捉单词与句法之间的语义关系,但仍然缺乏在情感层面上的信息捕获能力.针对这一情况Hao等人[8]使用预定义的情感知识库对现有的预训练模型进行了改进,提出了一种全粒度的基于情感知识增强的预训练(sentiment knowledge enhanced pre-training, SKEP)模型.该模型在现有预训练模型的基础上,采用了一种情感mask策略,并将多种情感学习目标融合到预训练过程中,从而使得模型对情感信息更为敏感且能够同时适用于多种情感分析任务.
基于虚假评论在语义和情感层面上的特点,我们提出了一种联合预训练模型来检测商品的虚假评论.鉴于预训练模型在语义和情感信息捕获上的优势,我们设置了语义和情感2种预训练编码器来分别获取评论语义和情感的上下文信息.基于2种编码器学习到的情感和语义的表达,我们设计了一种联合训练框架来识别虚假评论.我们在多个公开数据集上进行了虚假评论检测实验,结果表明:我们的模型要明显优于目前主要的传统模型和预训练模型基线,并且在跨领域和跨任务的实验中表现出了最好的泛化能力和鲁棒性.
本文的主要贡献有3个方面:
1) 首次提出在虚假评论检测中引入情感预训练模型,通过情感编码器捕获全粒度情感信息来帮助识别虚假评论;
2) 设计了一种能够同时结合语义和情感信息的联合训预训练方法,通过联合学习的方式同时整合情感和语义信息到一个模型之中;
3) 在多个公开数据集和多个不同任务上的实验结果表明,我们提出的联合模型在虚假评论检测与情感极性分析任务上都取得了目前最好的效果且具有更强的泛化能力.
1 相关工作
自从虚假商品评论的任务提出后,针对虚假评论检测的相关研究不断展开.Ott等人[9]从心理学的角度发现了评论文本的情感信息能够帮助虚假评论的识别.针对这一发现,结合情感分析的虚假评论检测方法逐渐成为了研究热点.Peng等人[10]提出通过语法分析的方式对文本语法的依赖关系进行建模来分析评论的情感极性,并结合语言模型和序列模型来识别虚假评论.Deng等人[11]提出了一种基于主题情感极性的虚假评论识别方法.他们通过观察发现绝对正面或者负面的评论大概率是虚假评论.基于这个假设他们给每一条评论定义了环境、口味、服务等主题,并单独计算各个主题的情感极性.若所有主题的极性都是一致的则为虚假评论,反之为真实评论.实验结果表明该方法具有良好的领域适应性,但准确率有待进一步提高.文献[12]提出了一种基于语言结构和情感极性的虚假评论识别方法,首先利用自然语言处理方法抽取评论文本的情感特征,然后通过遗传算法来选择最优特征,从而提高虚假评论检测的准确率;Zhao等人[13]提出了一种融合情感极性和逻辑回归的虚假评论检测方法,模型通过建模评论文本情感极性及其与大众情感的偏离程度来识别虚假评论信息,实验表明该方法效果优于仅考虑评论本身情感极性的模型.
目前的主流预训练模型有很多种,Bert[4]和RoBerta[14]是其中比较有代表性的2种.Bert通过自监督方法训练多层多Transformer编码器[15]来动态表示文本的语义特征.与传统的语言模型不同,Bert提出了一种新型的自监督训练目标被称为Masked Language Model(MLM).在训练过程中MLM方法首先随机选择15%的单词进行mask,对于这部分单词,其中80%的词被替换为[mask]标记进行屏蔽,10%的单词被随机替换为其他单词,另外10%的单词保持不变.基于MLM的学习方式和大量的无标签数据,Bert可以更好地学习文本中的语义信息.在实际应用中Bert模型采用了一种迁移学习的策略,即把训练任务分为2个步骤Pretrain和Finetune.在Pretrain过程中,Bert通过自监督的MLM方法学习通用的文本语义表达,并在特定的任务中基于标注数据做有监督的微调.通过这种方式Bert可以省去许多不必要的预训练过程,同时具有更好的可扩展性.RoBerta是Bert模型的一种改进版本,其在不改变模型结构的前提下,通过动态mask机制等多种优化方式改进Bert的训练算法,并且成为了目前最佳的预训练模型之一.在本文中我们也采用RoBerta作为语义编码器和对比基线之一.
情感分析与其他自然语言处理处理任务存在许多不同,其主要用来处理新闻文本意外的用户评论信息.情感分析涉及到不同的粒度和层面的知识,包括情感词抽取、属性词抽取、情感—属性词对抽取、不同粒度的情感极性判别等.这些情感知识被广泛应用在句子级[16-18]、评价对象级[19-20]和单词级别的情感分析[21-23]等任务中.基于以上考虑,Hao等人[8]提出将情感知识融入到预训练模型之中,从而使得模型在预训练学习过程中学习到的文本表征更加适用于情感分析任务.相对于传统的预训练模型,他们首先基于启发式的方法挖掘出了文本总的情感词、属性词和情感极性信息,在预训练过程中对这些情感信息进行mask,并将多种粒度的情感分析学习目标应用在了模型的预训练过程中,通过在这种基于情感知识增强的学习方式,该模型可以获得一种统一的多任务情感表示,从而在多种公开的情感分析任务评测集上取得了最佳的效果.在本文中,我们同样采用该模型作为情感编码器,并设置其作为对比基线之一.
2 虚假评论检测方法
本节我们主要介绍虚假评论检测的联合预训练框架,在检测过程中,模型仅利用评论的文本的内容进行虚假评论的判定.模型首先通过语义和情感编码器获得评论的上下文表示向量,然后通过联合训练的方式得到分类结果.
2.1 问题定义
虚假信息检测任务可以看做自然语言处理领域中的一项基础问题即文本二元分类问题.假设给定训练集合:
D={(Xi,Yi),i=1,2,…,n}
(1)
其中,Xi为第i条评论文本的输入序列,Yi为该评论的标签且
Yi∈{0,1} ∀i∈{1,2,…,n}
(2)
其中,当Yi=0时,表示评论为真实评论,当Yi=1时表示该评论为虚假评论.虚假评论检测的目标是学习一个映射函数
f:X→Y
(3)
使得映射函数f能够把评论文本X映射到正确的评论标签Y上面,这个过程可以形式化为
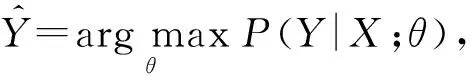
(4)
其中,θ为模型参数.
如图2所示,本文提出的虚假评论识别模型主要包括3个模块:语义编码器、情感编码器和联合训练模块.语义编码器通过对输入序列进行编码产生语义向量Cm,情感识别模块通过编码输入序列产生情感向量Cs,联合训练模块在训练时同时结合语义向量Cm和情感向量Cs计算模型输出,并将误差同时传递给语义编码器和情感编码器.
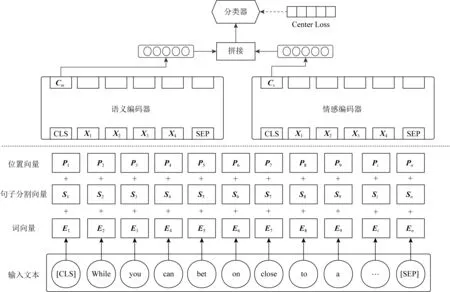
Fig. 2 Structure of our joint pre-training model图2 联合预训练模型结构
2.2 语义编码器
预训练模型拥有更加复杂的结构和更多的层数,并通过利用大量无监督数据进行自监督训练,因此它们具有强大的语义特征表示能力,相对于浅层模型预训练模型更适合对语义进行建模.Bert是最具有代表性的预训练模型之一,它使用一种随机的mask机制来训练多层双向的Transform来达到捕获文本语义特征的目的,并在很多NLP任务中显示出卓越的表现.RoBerta是对Bert模型的进一步优化,是目前最佳的预训练模型之一,在此我们选择RoBerta作为我们的语义编码器.对于给定的输入文本序列:
x={x1,x2,…,xn},
(5)
xi表示输入序列中的第i个字符.我们分别获取序列中每个字符的字符向量Ei和位置向量Pi.其中Ei为字符xi的嵌入表示向量,通过词嵌入方式获得.位置向量Pi的计算为
Pi=concat([P(i,1),P(i,2),…,P(i,dmodel)]),
(6)
P(i,2j)=sin(j/10002j/dmodel),
(7)
P(i,2j+1)=cos(j/10002j/dmodel).
(8)
另外Si为分割向量,考虑到虚假信息识别是一个单句分类任务,这里我们将所有分割向量Si置为0向量.除此之外,我们在输入序列首尾增加“[CLS]”和“[SEP]”标志位用来标记输入开始和结束.我们分别将每个字的3种向量进行求和,作为最终的输入向量
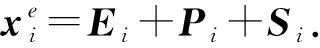
(9)
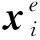
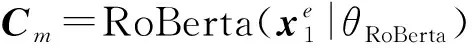
(10)
其中,θRoBerta为RoBerta模型的参数,我们采用公开的RoBerta预训练模型的参数对齐进行初始化.
2.3 情感编码器
使用情感编码器旨在获取评论的全粒度情感极性信息,并将其以情感上下文向量的形式提供给整个模型.在这里我们采用预训练的SKEP全粒度情感分析模型作为情感编码器.虽然SKEP模型和RoBerta模型一样属于预训练模型,不同的是SKEP在预训练过程中被mask的词主要为情感词和属性词,并且除了语言模型的损失函数之外,SKEP模型设计了多种情感任务的损失函数Lm,包括情感词损失函数Lsw、情感极性损失函数Lwp和情感—属性词对的损失函数Lap:
Lm=Lsw+Lwp+Lap,
(11)
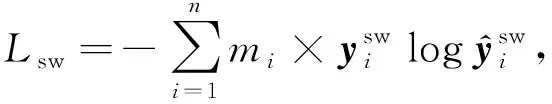
(12)
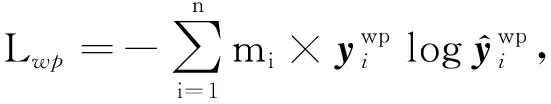
(13)
(14)
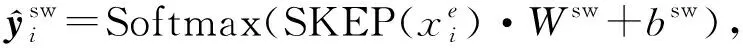
(15)
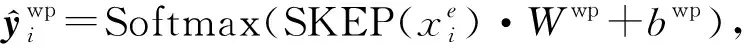
(16)

(17)
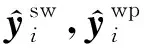
通过情感词mask和多种情感损失函数机制,可以使得SKEP在预训练的过程中更加专注于捕获情感信息.从而获取到全粒度的情感上下文向量.在我们的情感编码器中,与RoBerta相似,对于给定文本序列:
x={x1,x2,…,xn}.
(18)
我们以同样的方式得到每一个词的字符向量Ei和位置向量Pi以及分割向量Si,同时通过预训练的SKEP模型进行参数初始化,取SKEP模型的第1步出作为情感上下文向量.
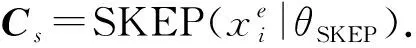
(19)
2.4 联合训练
联合训练的目标是同时整合语义信息和情感信息来综合帮助模型更好地识别出虚假的评论.在联合训练过程中,我们分别初始化语义编码器和情感编码器的变量,并尝试了多种方式来整合语义向量和情感向量,最终选择直接拼接语义和情感上下文向量作为最终的上下文向量表示
C=concat({Cm;Cs}).
(20)
模型的分类器包括2层全连接层和一层Softmax层,最终的模型输出可以表示为
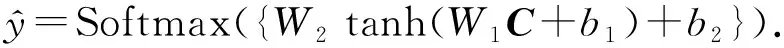
(21)
2.5 辅助损失函数
在实际中,虚假评论的数量会远远小于真实评论的数量,这就造成了在虚假评论中存在严重的类别不平衡现象.另外在跨领域的任务中类别边界越近往往会越难以区分跨领域的数据,因此我们在训练过程中需要尽可能地增加类别间决策边界距离,从而提升模型的鲁棒性.在训练过程中我们使用Center Loss作为辅助损失函数来增大模型不同类别之间的决策边界,从而使模型拥有更好的鲁棒性.我们定义模型最终的损失函数L为
L=Ls+Lc,
(22)
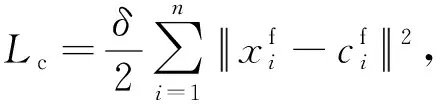
(23)
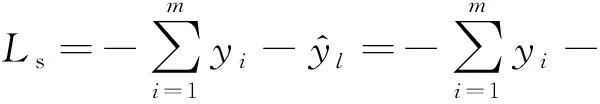
(24)
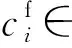
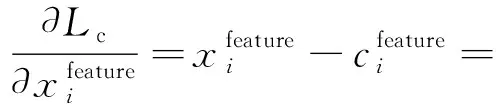
(25)
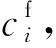
3 实验与结果
本节我们将本文提出的联合预训练方法和现有的传统虚假评论检测模型以及预训练模型基线进行对比,并分别在多个公开数据集和虚假评论识别和情感极性分析2个任务上展开可相关实现.
3.1 评价指标
我们采用文献[2,9,24]中所采用的4种指标来衡量我们模型在虚假评论检测任务上的效果,其分别是:虚假评论检测的F1值、精确率(Precision)、召回率(Recall)、和准确率(Accuracy),针对虚假评论检测问题,这个4种指标的计算方法为
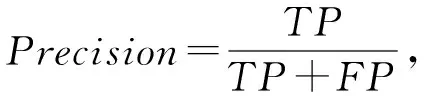
(26)
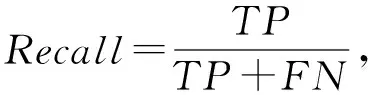
(27)
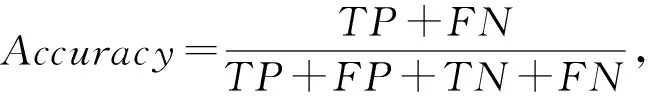
(28)
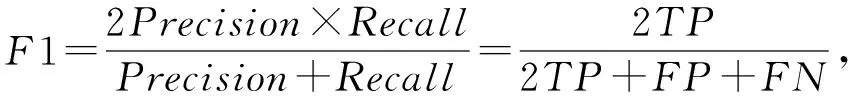
(29)
其中,TP为正确识别的虚假评论数,TN为错误识别的虚假评论数,FP为错误识别的正常评论数,FN为正确识别的正常评论数.这4种指标都是在分类任务中最常用的评价指标,不仅可以从不同角度来评价模型的效果,也方便和之前的工作进行对比.
3.2 数据集
本文在实验过程中使用文献[3,9]中发布的3个虚假评论数据集来验证模型效果,这3个数据集分别涉及旅馆(Restaurant)、酒店(Hotel)和医疗(Doctor)领域的评论数据,数据分布如表1所示:
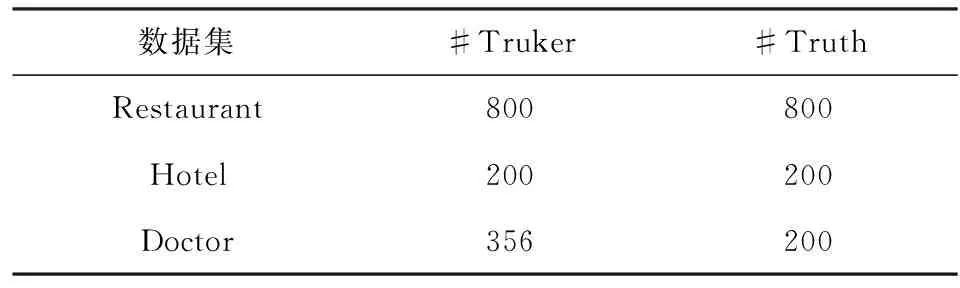
Table 1 Dataset and Its Statistics表1 数据集及其分布
数据集中主要包括2种类别Turker和Truth,其中Turker数据为虚假评论,由Li等人[3]和Ott等人[9]在亚马逊的众包平台“MTurk”上进行人为收集,这些评论的编写者为雇佣而来的专业写手.Truth数据是由真实用户产生的数据,通过筛选在线平台中可信度高的用户获取.除此之外在旅馆数据集中存在少量专家数据“Professional”,这些数据由具备专业知识的领域专家所创作,仍属于虚假评论.在数据处理过程中,我们和文献[24]保持一致并没有采用此部分数据.在实验过程中我们采用5-fold交叉验证的方式来划分训练集和测试集,每次取其中一个fold的数据作为测试集其他数据作为训练集,最终结果取每个fold的平均表现.
3.3 实验设置和基线
在实验过程中我们大多数参数采用RoBerta和SKEP模型的默认参数配置,少数参数遵循设置:
迭代次数epoch=10,样本批次大小batch_size=8,学习率learning_rate=0.3×10-5,Transformer层数num_hidden_layers=24,隐藏层神经元数hidden_size=1024,最大序列长度max_length=512.在整个实验过程中,对于RoBerta和SKEP模型我们保持这些参数均为相同的配置.
SAGE(sparse additive generative model)[3]是一种贝叶斯生成模型,最早由Eisenstein等人[25]引入,可以看作是主题模型和广义加性模型的组合,根据语言特征来判定评论的类别归属,是一种被广泛使用的特征模型.
SWNN[26]模型是一种基于神经网络的文档表示模型,模型分别从句子和文档2个层面学习对应的文本表示和权重向量,并对其进行整合得到文档的表示向量,进而基于文档的表示向量来判定虚假品论,在领域内实验中,SWNN取得了很好的效果,在跨领域实验中,SWNN也表现出了很好的鲁棒性.
ABME(attention based muti-layer encoder)[24]模型是一种基于注意力机制的多层编码器模型.ABME基于评论首尾部分表达情感更加强烈等特点,将评论拆分为首、中、尾3部分并对其分别进行编码,在整合3种编码时文献[23]作者提高了首尾部分的权重借此来强调首尾句对模型结果的影响,结果表明ABME能取得比传统模型更好的效果Bert(large)[4]和RoBerta(large)[17]是目前比较流行的预训练语言模型,有着强大的语义捕捉能力,并且在大多数的自然语言处理领域都保持着最好的效果.RoBerta模型是对Bert的改进版本,其使用了动态mask策略和更加精细化的训练方式,使其成为了目前效果最好的预训练模型之一.
SKEP(sentiment knowledge enhanced pre-training)[11]是一种全粒度情感分析的预训练模型,SKEP与RoBerta结构类似但在预训练过程中SKEP采用采用了一种情感知识驱动的mask策略和多种情感损失函数,使其在情感分析任务上具有非常突出的表现.
3.4 领域内实验结果
在实验过程中采用5-fold交叉验证的方式来划分训练集和测试集,每次取其中一个fold的数据作为测试集其他数据作为训练集,最终结果取每个fold的平均表现,实验结果如表2所示,其中SAGE,SWNN和ABME模型的结果直接从相关论文拷贝得到.
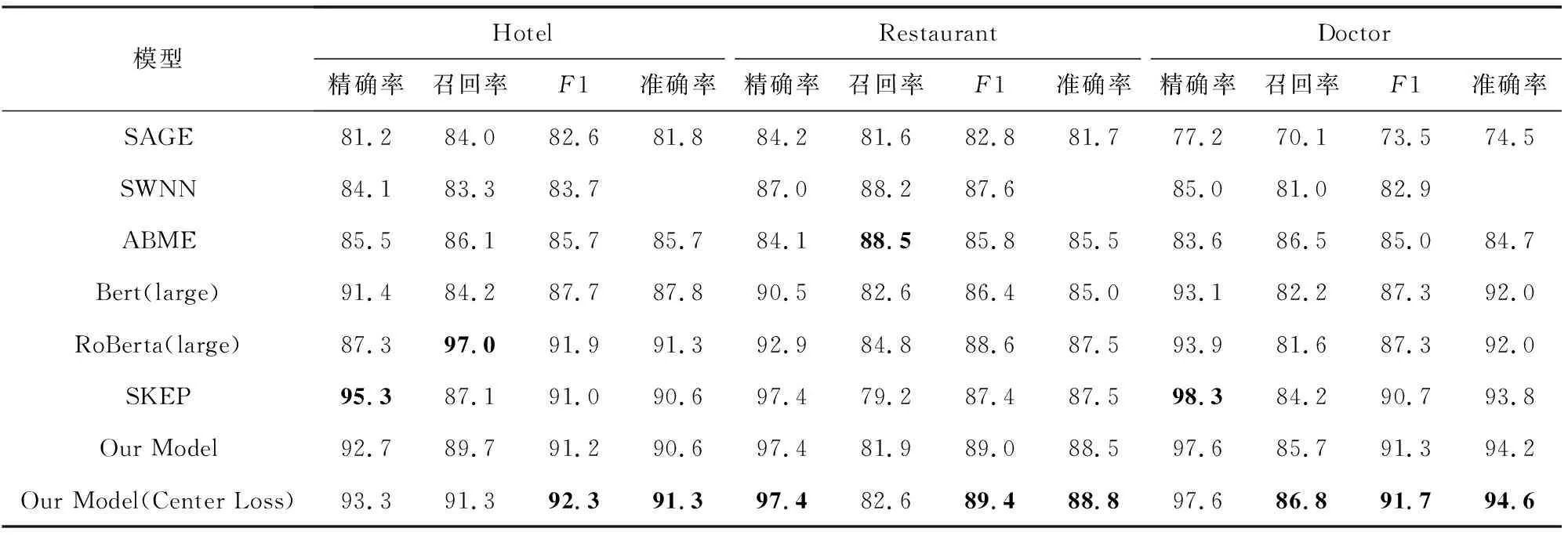
Table 2 Main Domain Results of Spam Review Detection表2 领域内虚假评论检测实验结果对比
实验结果表明,我们提出的联合预训练模型在所有数据集上的准确率(Accuracy)和F1值上都取得了目前最好的水平,这充分证明了我们的联合训练方法在同时整合语义和情感信息上的优势,也说明了在虚假评论识别任务中引入情感信息可以帮助提升虚假评论检测的效果.从整体来看,预训练模型相对与浅层神经网络和特征模型都有较为明显的优势,这也证明了预训练模型具有更加强大的语义分析能力,更加适用于虚假评论检测任务.在预训练模型中,基于全粒度情感分析的预训练模型SKEP相对于基于语义的预训练模型Bert和RoBerta,具有更高的精确率(Precision),因此联合模型可以利用其这一特点来弥补语义模型缺失情感信息的问题从而提高结果的准确率.
3.5 跨领域实验结果
跨领域实验的目的是为了测试模型的鲁棒性和泛化能力.领域内实验的训练集和测试集均来自同一个领域,跨领域实验的训练集和测试集则分别来自不同领域.在我们的实验中,我们将旅馆(Restaurant)领域数据作为训练集,并且分别将酒店(Hotel)和医疗(Doctor)领域的数据作为测试集进行了跨领域的实验,实验结果如表3所示,其中SAGE,SWNN和ABME模型的结果参考相关论文[24].
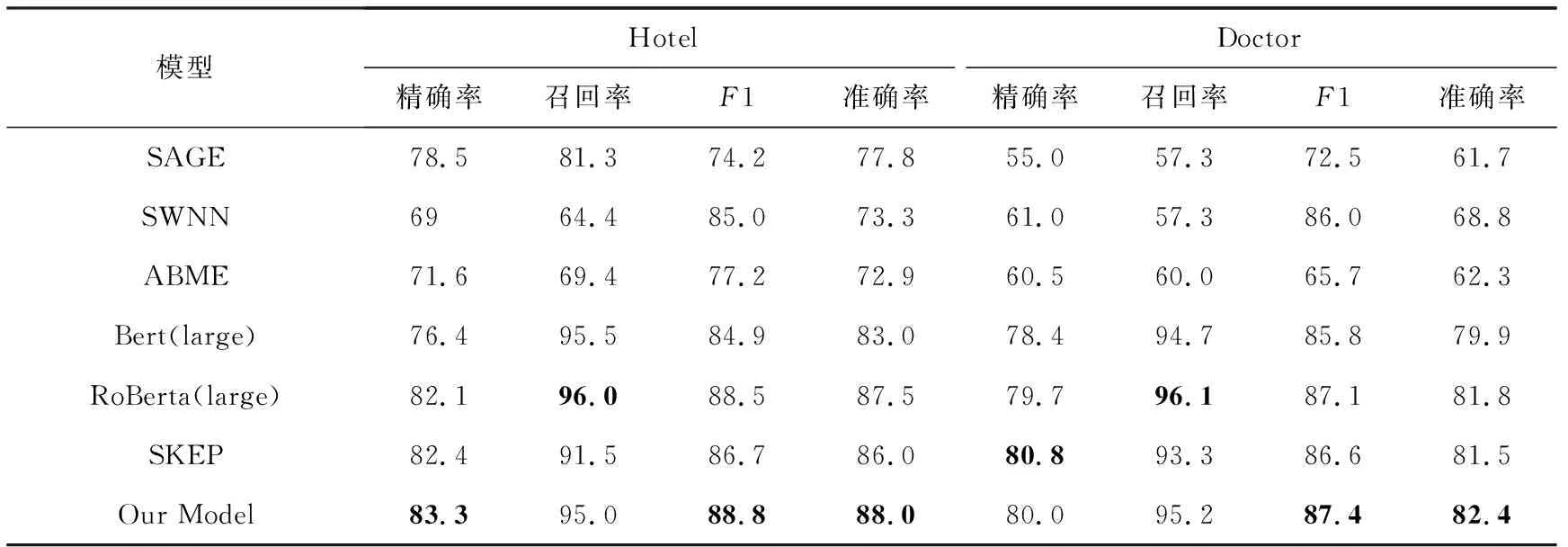
Table 3 Comparative Experimental Results of Cross Domain on Spam Review Detection表3 跨领域虚假评论检测实验结果对比
结果表明我们的联合学习模型在跨领域任务中依然取得了最好的效果.除此之外,预训练模型的结果都要明显优于其他模型,因为预训练模型本身就是一种迁移学习方法,所以能够更好地适应不同领域的虚假评论识别任务.另一方面,我们采用的Center Loss同样可以提高模型的鲁棒性和泛化能力,这也是我们的模型在跨领域任务上要明显优于传统模型的原因之一.
3.6 情感分析实验
为了进一步验证联合模型对情感语义的捕获能力,我们基于旅馆(Restaurant)数据集进行了情感分析实验.数据集中的情感标注仍然来自于Li等人[3],我们将数据集中的虚假评论标签换为情感极性标签并保持模型的其他设置不变重新进行了实验,实验结果如表4所示:
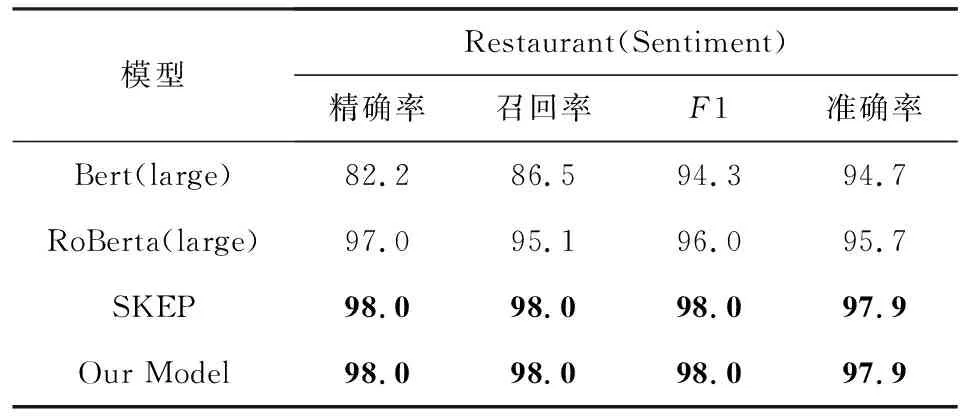
Table 4 Experimental Results of Sentiment Analysis表4 情感分析实验结果对比
从实验结果中可以看出,SKEP模型和我们的联合训练模型同时取得了目前最好的结果,这也说明了我们的联合模型拥有较强的情感信息捕获能力并且可以扩展运用在情感分析的相关任务上.至于SKEP和我们的联合模型结果相同的问题,经过我们的观察发现结果中的负例数量非常少,对于个别的疑难案例增加语义信息仍然不能很好地区分它们,且受限于数据集的规模.因此考虑到数据本身的原因和语义特征的限制导致联合模型的学习上限和情感模型SKEP是一致的,我们在未来的工作中会通过更大规模的数据进一步验证联合训练模型对情感信息的捕获能力.
4 总 结
本文提出了一种同时整合语义和情感信息的联合预训练学习方法来进行虚假评论检测任务.我们分别采用了预训练的语义模型和情感模型作为编码器分别抽取评论中的语义和情感信息,并通过一种联合训练框架对抽取的信息进行整合和泛化,在多个公开数据集和不同任务上的实验结果表明,我们提出的联合模型在虚假评论检测与情感极性分析任务上都取得了目前最好的效果且具有更强的泛化能力.
作者贡献声明:张东杰,负责论文主要撰写,方法设计及实验验证;黄龙涛,负责方法设计,论文整体内容修改;张荣,对实验设计提出指导意见;薛晖,为实验环境提供支持;林俊宇,稿件整体算法方案和实验设计把关,对相关工作对比提出具体指导意见;路瑶,稿件整体算法方案和实验设计把关,提供实验数据支持.其中,路瑶和林俊宇为本论文的共同通信作者.
