基于AIC准则的混频数据季度GDP预测实证研究
2021-07-21杨炜明胡瑞婷
刘 涛 杨炜明 胡瑞婷
(重庆工商大学 数学与统计学院,重庆 400067)
一、引言
党的十九大报告指出:“在我国经济发展进入新常态的背景下,宏观调控牢牢把握速度变化、结构优化、动能转换三大特征,不断调适理念、调适政策、调适方法强化经济形势监测预测和政策措施预研储备,加强宏观政策组合运用,更加注重市场行为和社会预测,宏观调控各项指标符合预测。”目前我国已进入新发展阶段,如何实现经济稳步发展成为国家当前面临的难题。这就需要对我国宏观经济指标进行短期预测,以此防范各种突发情况带来的不确定性。而在众多的宏观经济指标中又以GDP尤为重要,GDP反映一个国家或地区的综合经济实力和市场规模,是国民经济核算体系中的核心指标之一。因此对GDP进行预测,对于国家宏观调控以及政策引导都具有重要意义。
Clements和Galvao在2005年首次将MIDAS模型应用于宏观经济领域。Marcellino和Schumacher在2007年将因子分析模型引入到MIDAS模型中,并发现MIDAS模型在短期预测中的预测效果良好。Clements和Galvao在2008年基于季度GDP和月度非农就业总额,应用MIDAS-AR模型来预测下一季度GDP增长率,结果显示MIDAS-AR模型在宏观经济总量的短期预测相比传统计量模型更具优势。Hogrefe在2008年比较单频、混频以及插值法在美国GDP修订数据中的优劣,发现MIDAS模型在样本外的预测精度最好。刘金全、刘汉等在2010年探寻MIDAS模型对中国宏观经济的实证分析中提出遇到混频数据时,应优先考虑使用混频数据模型。刘汉、刘金全在2011年应用MIDAS模型对中国宏观经济总量进行实时预报和短期预测,发现MIDAS模型对中国宏观经济总量的短期预测精度较高,预测结果具有显著的可行性和时效性。张旭和刘晓星在应用MIDAS模型时,利用AIC信息准则选取最优模型,最终得出MIDAS在货币政策中的应用是有效的,能有效提高货币政策估计效果。
在近十年的混频数据模型研究中,大部分混频数据模型都是直接给定固定的滞后阶数或直接选取多项式权重函数来研究不同的经济问题,并没有讨论滞后阶数的最优值以及最优多项式权重函数的选取。本文选取2000年第一季度至2017年第四季度的宏观经济数据,选取2000年第一季度至2017年第二季度的数据构建MIDAS模型,应用混频数据抽样模型(MIDAS)预测中国2017年第三季度和第四季度GDP,在给定滞后阶数范围(k从3到10)并赋予高频解释变量不同的多项式权重函数来讨论混频数据模型的预测精度,在AIC信息准则下选取最优的MIDAS预测模型时发现:AIC值最小的模型预测精度并不是最优模型。故讨论在最优滞后阶数的情况下,对比AIC最小模型和其他多项式权重函数模型的预测精度,给出预测精度最好的模型并进行短期预测。
二、研究方法及模型简介
混频数据抽样模型(MIDAS)由Ghysels在2004年首次提出,加入高频解释变量后能有效提升时间序列的预测精度,并在2013年利用MIDAS模型来预测下一季度的GDP。MIDAS模型源于分布滞后模型,基本思想为:按变量出现的频率将变量归类为高频变量和低频变量,通过多项式权重函数对高频变量和低频变量建立回归模型,在非线性最小二乘法估计的情况下,对低频数据变量进行解释和预测。
本文先介绍单变量混频数据抽样模型,在单变量的基础上,衍生到多变量混频数据抽样模型。
(一)单变量混频数据抽样模型
单变量MIDAS模型是MIDAS模型中最简单的一种形式,该模型是针对一个高频数据变量和一个低频被解释变量之间使用多项式权重函数来建立回归模型,应用非线性最小二乘法对模型进行估计,从而实现高频数据变量对低频被解释变量的预测。
单变量MIDAS(m,k)模型基本表达式如下:


在目前的理论研究中,存在四种不同的参数化多项式函数,分别为Beta、Almon、指数Almon和步函数四种多项式函数。Ghysels曾在2007年给出以上四种权重多项式函数的形式,具体表达式如下:
1.Beta多项式:

2.Almon滞后多项式:

3.指数Almon滞后多项式:

4.步函数多项式:

(二)混频抽样自回归模型
由于经济系统中的指标数据往往存在惯性,并且时间序列中前一期数据和后一期数据也存在自相关关系,因此我们在混频数据抽样模型中加入自回归项。在MIDAS模型中引入一阶自回归项的h步预测的AR-MIDAS模型表达式如下:

(三)多元混频数据抽样(M(n)-MIDAS)模型
在单变量MIDAS模型基础之上,引入多个高频解释变量,扩展为多元MIDAS模型,表达式如下:

(四)多元混频数据抽样自回归(M(n)-MIDASAR)模型
当考虑到低频被解释变量可能存在自相关性时,那么在M(n)-MIDAS模型中引入自回归因子,则M(n)-MIDAS-AR模型表达式如下

其中,n为高频解释变量的数量,p为滞后阶数,对于解释变量xi(m)应单独设定其多项式函数形式和参数变量 θi来估计 β1i。
(五)MIDAS模型的估计方法
Ghysels在2004年提出混频数据模型时就尝试使用NLS(非线性最小二乘估计)方法估计单变量和多变量MIDAS模型中的参数,假定在参数变量为θ的情况下,通过NLS可以得出:

其中,xt-h(θ)=[1,W(L1/m;θ)xt-h(m)],β=(β0,β1)'在优化前需要给出约束条件:θ1≤300,θ2≤0,再通过给参数θ设定不同的取值来检验模型优化过程和初始取值之间相互独立。

(六)hah_test及AIC信息准则
hah_test是测试滞后项和权重函数对MIDAS回归系数的约束是否成立。给出MIDAS模型的约束:

检验以下约束成立的原假设为:θ=g(h,λ),h=0,1,…,K,K+1,…,m
AIC信息准则用于体现估计模型的复杂度和数据拟合的优良性,在当下研究中主要作为衡量统计模型拟合优度的一个标准。通常情况下:

K为参数变量的数量,L为模型的极大似然函数。AIC准则假设模型误差是服从独立正态分布,研究表明增加变量个数可以达到提高模型拟合精度的效果,AIC信息准则是在保证数据拟合良好的情况下尽量避免出现过度拟合的情况,所以优先考虑AIC值最小的模型。AIC信息准则是用来寻找最少的自由参数同时具有最优解释数据的模型。
三、实证分析
当下的宏观经济发展系统中,有众多影响季度GDP的指标。刘汉、刘金全2011年发表的中国宏观经济总量的实时预报与短期预测,李正辉、郑玉航2015年发表的基于混频数据模型的中国经济周期区制检测等研究文章,提出固定资产投资、出口额、社会消费品零售总额、规模以上工业增加值、税收总额、居民消费价格指数以及货币供应量等指标对季度GDP的影响效果最为显著。古典经济学认为GDP主要由投资、出口、消费“三驾马车”共同影响。根据国家统计局和中国经济信息网公布的信息,GDP按季度发布,而固定资产投资、出口、社会消费品零售总额等指标按月度发布。由于以上数据的频率不同并且公布时间也各不相同,导致无法对目前实际的GDP增长状态和未来的经济发展形势做出准确的预测和判断。因此,本文采用国家统计局最新公布的高频月度数据,应用Ghysels提出的MIDAS混频数据模型,并通过构建不同的滞后项多项式来实现对GDP总额的短期预测并对预测精度进行比较。
(一)数据来源及处理方法
本文选取季度GDP作为低频被解释变量,选取固定资产投资、社会消费品零售总额和出口额作为影响季度GDP总额的高频解释变量。使用2000年第一季度至2017年第四季度的实际GDPμ以及2000年1月至2017年12月的社会消费品零售总额x1,t、出口额x2,t和固定资产投资总额x3,t来构建混频数据模型。本文对所有数据进行了取对数、差分等平稳化处理。
本文首先采用单变量MIDAS(m,k)分别构建季度GDP,μ 与单个解释变量 xi,t(i=1,2,3) 的混频数据模型,选取2000年第一季度至2017年第二季度的数据构建MIDAS模型,预测2017年第三季度和第四季度的GDP,在AIC最小准则下确定最优滞后阶数K,再加入不同的多项式权重函数对数据进行预测并比较分析。其次,构建多变量 M(n)-MIDAS(m,K,h)模型,选取不同权重函数对模型进行预测并对比。最后,引入低频变量的自回归项,构建多变量的M(n)-MIDAS(m,K,h)-AR(p)模型,在 AIC准则下赋予高频解释变量最优的滞后阶数,对比不同多项式权重函数的情况下 M(n)-MIDAS(m,K,h)-AR(p)模型在当前数据内的预测精度。
(二)单变量MIDAS模型及预测
MIDAS模型在预测时须先确定高频解释变量的最优滞后阶数K和最优权重多项式函数。最新的理论研究表明,选择的滞后阶数越长越能体现信息的完整性,估计模型的显著性越高,预测的精度更好。但是高频解释变量的滞后阶数太长会导致数据的损失,长滞后阶数在高频金融数据中相对更具有可行性,但是宏观经济数据的滞后长度都较短,如果也取较长的滞后阶数,会导致用于MIDAS模型的样本数据减少,反而会影响到模型的估计值和预测精度。并且不同的权重多项式函数对模型的估计不同,Almon多项式函数在金融市场波动的预测中使用较多,指数Almon和Beta多项式函数在宏观经济分析和预测中应用较多,不同多项式函数的MIDAS模型预测的精度也各不相同。本文在选择高频解释变量的滞后阶数和权重多项式函数时,滞后阶数从3阶一直取到10阶,权重函数分别取 beta、Almon、指数 Almon,并通过 AIC信息准则,取出最优滞后阶数K和最优的多项式函数,并对比最优滞后阶数K下最优多项式和其余多项式函数模型的预测精度。
1.单变量MIDAS(m,k)模型的估计与预测
首先,本文分别建立季度GDPμ与单个解释变量xi,t(i=1,2,3)的混频数据模型,混频数据图形见图1。
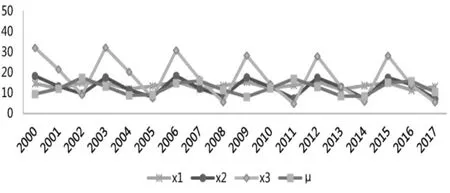
图1 MIDAS模型中的混频数据图形
然后列出所有模型的AIC.restricted、AIC.unrestricted、BIC.restricted、BIC.unrestricted以及hah_test等参数值,通过AIC.restricted曲线确定最小值,从而确定季度GDP和社会消费品零售总额、出口额和固定资产投资的最优滞后阶数和最优权重函数,图2为AIC趋势图。

图2 AIC趋势图
遵循AIC最小准则,我们筛选出单变量MIDAS对应的最优模型。

表2 AIC准则下的最优滞后阶数
社会消费品零售总额x1,t的最优滞后阶数K1=5,最优权重函数为指数almon函数。hah_test的值大于临界值 0.05,为 0.189,说明模型约束充分;出口额 x2,t的最优滞后阶数K2=5,最优权重函数为beta函数,hah_test值为0.380,大于临界值,表明模型约束充分;固定资产投资x3,t的最优滞后阶数K3=6,最优权重函数为指数almon函数,hah_test值为0.945,模型约束充分。
在最优滞后阶数确定的情况下,本文分别选取指数almon、almon以及beta等多项式权重函数对比预测精度,选取2000—2017年的数据进行样本内估计,对2017年的第三季度和第四季度GDP进行预测估计,再给出各自模型的预测值以及样本内样本外MASE和MAPE等参数,发现通过AIC信息准则确定的模型预测精度并不是最好的。单变量混频数据模型的估计结果如表3—表5所示,其中:EW表示基于特征值加权组合后的预测值;BICW:BIC信息准则加权后的预测值;MSFE:均方误差加权组合的预测值;DMSFE:基于MSFE组合的预测值。

表3 基于单变量MIDAS模型的预测值

表4 各自模型的EW、BICW、MSFE和DMSFE预测值

表5 单变量MIDAS模型样本内和样本外的MSE、MAP值
在AIC信息准则下,x1最优多项式权重函数为指数almon,根据表5可知,x1在指数almon多项式权重下样本外的均方误差(MSE)为12.154,平均绝对百分比误差(MAPE)为41.106%,而x1在多项式almon权重函数下,样本外的MSE值为10.522,MAPE为38.294,预测精度优于指数almon权重函数;x2在指数almon权重函数下,样本外MSE为9.665,MAPE为36.195,预测精度也优于通过AIC信息准则确定的beta权重函数;x3在almon权重函数中样本外MSE值为14.435,MAPE为44.802,也比指数almon权重函数的预测精度更好。并且单变量MIDAS的MAPE值都比较大,预测的精度并不理想,故下一步使用多变量MIDAS预测季度GDP,看预测精度会不会更优。
(三)多变量MIDAS模型估计及预测
在单变量MIDAS模型预测精度不理想的情况下,我们引入多变量MIDAS模型,将3个高频解释变量一起纳入混频数据模型中,再对我国季度GDP进行实证研究。本文为估计精度的需要,在AIC信息准则选取的最优模型基础上,还使用不同权重函数来估计多变量MIDAS模型的精度,模型估计、样本预测以及样本内外所需要的数据均与上述单变量MIDAS模型保持一致,下文不再赘述。
1.多变量M(n)-MIDAS模型估计结果及预测
在多变量的条件下,滞后阶数k是从3取到10,多项式函数取指数almon、almon和beta,故多变量模型一共存在6965种不同组合的模型,通过AIC最小准则,我们筛选出最优滞后阶数和权重函数分别为:社会消费品零售总额x1,t为滞后10阶的指数Almon权重函数;出口额x2,t为滞后5阶的beta权重函数;固定资产投资x3,t为滞后8阶的指数Almon权重函数,AIC值最小为398.305,模型的hah_test=0.9667,模型约束充分,然后对比最优模型和最优滞后阶数下其他模型的预测精度。因模型滞后阶数以及多项式函数选取的不同,本文选取具有代表性的五种组合模型,模型及估计结果如表6、表7、表8所示。

表6 多变量组合模型命名

表7 多变量MIDAS模型在h=1和h=2的预测值
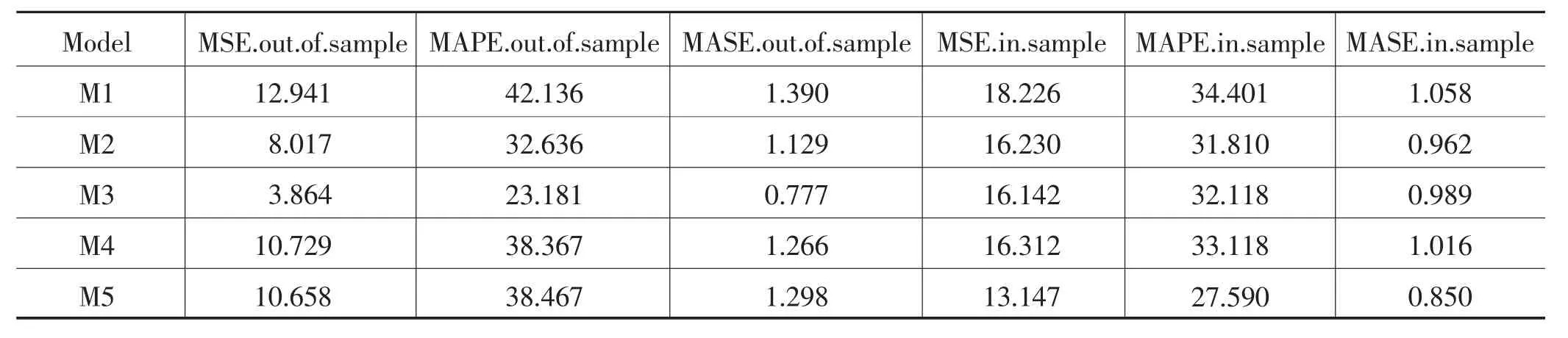
表8 多变量MIDAS模型样本外及样本内的MSE、MAPE值
在多变量MIDAS模型中,通过对比样本外的MSE和MAPE值可知,AIC最小的模型并不是预测精度最好的模型,在各自高频解释变量的最优滞后阶数下,当x1取almon加权函数,x2取almon加权函数,x3取beta加权函数时,模型在样本外的MSE值最小,为3.864,MAPE值为23.181%。相比单变量MIDAS模型,引入更多高频解释变量能有效提升模型的预测精度,但是模型的MAPE值还是较大,若能进一步降低MAPE的值,模型预测精度将进一步提升。
2.自回归多变量 MIDAS(AR-M(n)-MIDAS)模型估计及预测
由于宏观经济变量大多存在惯性,经济类数据大多是时间序列,具有自相关性,故我们在多向量MIDAS的基础上引入因变量的自回归项,构建AR-M(n)-MIDAS模型来检验能否进一步提升模型样本外的预测精度,模型及估计结果如表9、表10、表11所示:

表1 变量数据及来源

表9 加入自回归项的多变量组合模型命名

表10 AR-M(n)-MIDAS模型在不同步长值下的预测值

表11 AR-M(n)-MIDAS样本内外的MSE、MAPE值

图3 多变量MIDAS模型预测误差百分比趋势
通过上述预测精度趋势图可以看出,在没加入自回归项前,多变量MIDAS模型的MSE值和MAPE值都相对较大,通过预测2017年第3季度和第4季度GDP的预测误差来看,误差值都偏高,短期预测效果并不理想。再加入自回归项后,样本外的MSE和MAPE值都显著降低,说明模型的预测精度进一步提升。本次自回归多变量MIDAS模型共存在6848种不同组合的模型,通过AIC准则确定最优模型为:社会消费品零售总额x1,t为滞后10阶的指数Almon权重函数;出口额x2,t为滞后5阶的beta权重函数;固定资产投资x3,t为滞后6阶的指数 Almon权重函数,AIC值为 398.305,hah-test值为0.966,模型的约束良好,最优模型的MSE值为2.111,MAPE值为17.125%,模型的预测精度已经达到不错的水平,但是在社会消费品零售总额x1,t为滞后10阶的指数Almon权重函数,出口额x2,t为滞后5阶的almon权重函数,固定资产投资x3,t为滞后6阶的指数beta权重函数的M(n)-MIDAS-AR模型中,样本外的MSE值为0.646,MAPE值为8.581%,说明后者模型拟合和预测的效果更加良好。
四、结论及建议
在以往的文献中,混频数据模型的最优滞后阶数都是直接给出的,一般都是取 3,6,12,18,24,30 等具体数字,没有给出一个范围并讨论范围中的最优滞后阶数,对于学术研究而言,给出的滞后阶数并不能代表最优的滞后阶数,本文在选取滞后阶数时,先根据实际情况和经济意义给出滞后阶数的范围,然后通过AIC信息准则选取最优滞后阶数再来讨论模型的预测精度,力求研究的准确性。当下众多的研究中,很多文献并没有告知最优多项式如何选取,大部分多项式函数都是根据经验或者自己直接给定,并没有讨论高频解释变量会因多项式函数的不同而影响最终的预测精度。本文实证在AIC最优条件下的混频数据模型并不是预测精度最好的模型,AIC信息准则可以用来确定高频解释变量的最优滞后阶数,但不能选出最优的多项式函数。在最优滞后阶数的情况下,我们可以通过MSE、MAPE以及与预测误差等指标来确定最优多项式函数,从而确定预测精度最好的混频数据模型。对于目前的混频数据模型而言,可以尝试加入新的数理统计方法,如采用神经网络或者蒙德卡罗等方法来检验混频数据模型拟合优劣以及预测精度等。◆
