典型危险事故特征的自动驾驶测试场景构建
2021-07-09陈吉清舒孝雄兰凤崇王俊峰
陈吉清 舒孝雄 兰凤崇† 王俊峰
(1.华南理工大学 机械与汽车工程学院,广东 广州510640; 2.广东省汽车工程重点实验室,广东 广州510640)
道路交通安全问题是世界性问题,而自动驾驶汽车无疑对减少交通事故的发生具有重要意义。随着无人驾驶技术等级的提高,面向传统汽车的测试工具与测试方法已不能满足自动驾驶汽车测试的需要,基于场景的自动驾驶系统(ADSs)车辆测试及评估相关的仿真框架和标准已成为当前的研究热点[1- 2]。自动驾驶汽车场景化测试的核心在于定向构建高测试需求场景,而自动驾驶汽车的驾驶场景主要来源有标准法规、自然驾驶数据、交通事故数据、模拟数据[2- 3]。自然驾驶数据场景不能充分验证自动驾驶汽车在危险场景下的安全性,而交通事故场景具有真实危险场景的特征,能够补充自动驾驶汽车的高风险场景。
国外基于交通事故数据的自动驾驶或高级驾驶辅助系统(ADAS)的测试场景研究较多[4- 6],而国内在基于自然驾驶数据或交通事故数据构建测试场景方面主要集中在研究汽车-两轮车(TWS)场景、汽车-行人场景[7- 9],很少考虑道路路段类型的测试场景研究[10]。由于国情的差异,中国的交通环境具有独特交通特征,有别于欧美等国家。有研究指出欧盟的车辆事故发生在交叉路口的事故数占1/3,在十字路口的致命伤害和严重伤害比例最高,约为43.9%和43.2%[11];而中国的车辆交通事故多发生在普通路段(包括无交叉路口的直路和曲率较小的弯道),死亡人数占总死亡人数的76.25%,其次是交叉路口(包括三枝分叉口、四枝分叉口、多分枝交叉口和环形交叉),占17.5%[12]。城市道路中,普通路段和交叉路口路段人流密集、交通工具多样和交通环境复杂是事故发生的主要原因。在城市道路上,自动驾驶汽车或智能网联汽车主要应用在物流、共享出行和公共交通等领域的应用场景,而且目前针对行人的AEB测试场景研究和法规较为成熟[10,13],因此相比人-车事故的场景研究,更需要对城镇道路上包含乘用车与驾乘交通工具的道路使用者的测试场景进行研究。
文中基于641例涉及道路路段类型的真实事故数据,选择了合理的场景要素和聚类变量,通过对聚类变量的独热编码和聚类分析,结合天气、第1碰撞点位置、车辆速度和事故发生前车辆具体运动类型4个危险事故特征构建了自动驾驶测试场景。
1 场景数据来源
国家车辆事故深度调查体系(NAIS)数据库是一个采集较为严重车辆交通事故的数据库,是中国起步最早、最详细的交通事故数据库之一。道路类型一般可分为公路和城市道路,公路可分为高速公路、一级公路等。在NAIS数据库中,道路按路段信息可分为普通路段、三枝分叉口、四枝分叉口、多分枝交叉口、环形交叉、高架路段、匝道口、隧道和其他特殊路段等路段。
为了保证数据的代表性和典型性,对NAIS数据库中1 909例事故数据进行统计分析后,再确定场景数据。在数据中共有1 130例事故数据(在参与方总数为2的事故中占70.7%),包含了所有路段的数据,如表1所示。根据表1的数据分布,最后将641例全部的普通路段和路口路段(包括T型路口和X型路口)事故案例作为场景数据,其中经过事故重建的事故数据有134例,占21%,满足下一步分析危险事故特征的需要。
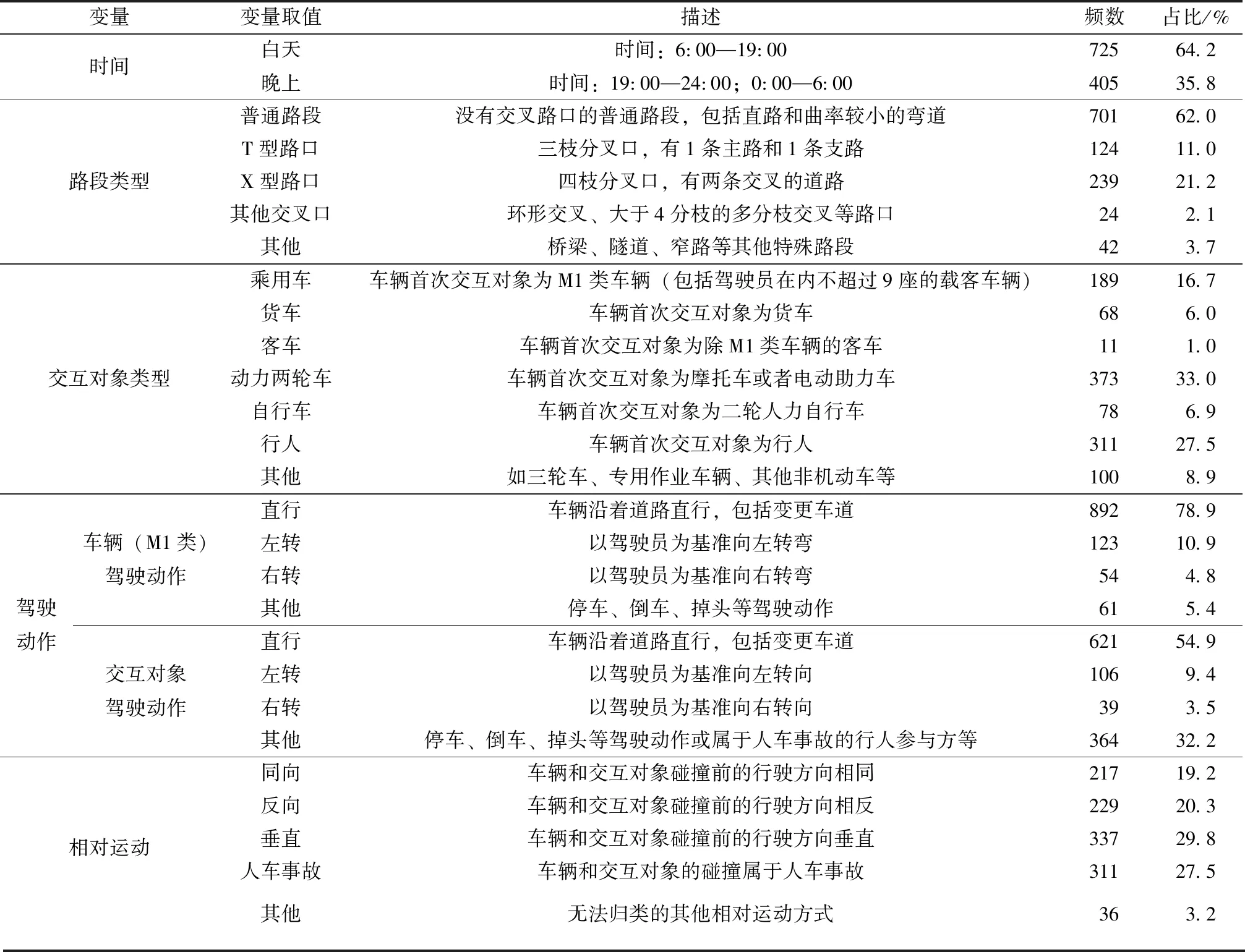
表1 数据分布Table 1 Distribution of data
2 典型车辆碰撞危险场景聚类分析
2.1 聚类方法和变量编码
文中选择采用汉明距离(Hamming Distance)和K-Medoids聚类算法中常见的PAM算法[9,11],并利用R语言进行实现。为解决同一名义尺度变量多属性取值的问题,采取对名义变量进行了独热编码的数据前处理,这与国内场景研究[7- 8,10]的解决方案相比更具有灵活处理非连续型数值特征的优势,同时也在一定程度上进行了特征扩充。
(1)汉明距离
假设{A1,A2,…,Am}是一个样本的属性特征序列,对象X和Y由唯一的{A1,A2,…,Am}描述,X由{x1,x2,…xm}描述,Y由{y1,y2,…,ym}描述,则定义d(X,Y)是向量X=(x1,x2,…,xm)与向量Y=(y1,y2,…,ym)之间对应元素不相等的个数和[14]。
(1)

(2)
(2)独热编码
独热编码又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有独立的寄存器位,并且在任意时候,其中只有一位有效[15]。
(3)PAM算法和聚类质量评价
PAM算法适用于样本数量较小的聚类分析,它分为构建和交换两个步骤[11]。对聚类质量的评价和簇数k的选择上,选择平均轮廓系数(ASW)为K-Medoids算法聚类质量的评价指标是合理的[11]。ASW比较均衡地体现了簇内的聚合度和簇间的分离度,ASW值的取值范围为[-1,1],一般来说ASW值越高,聚类质量越好。
2.2 场景要素和聚类变量选择
自动驾驶系统面临的主要挑战是复杂的城市环境、临时工作区域和恶劣天气条件下的能见度差,而路面特征、道路线形和照明被认为是次要影响因素[11]。因此,针对复杂的城市环境这一影响要素,结合交通环境要素和测试车辆基础信息两大测试场景要素,以及对场景可量化、可复现和高保真的要求[2],进行了场景要素的确定,并以此为基础进行聚类变量的选择。目前对场景要素的种类和具体内容还有待研究[2],所以将车辆速度和交互对象速度作为危险事故特征来描述场景。进一步结合事故数据分布选择的场景要素如图1所示。
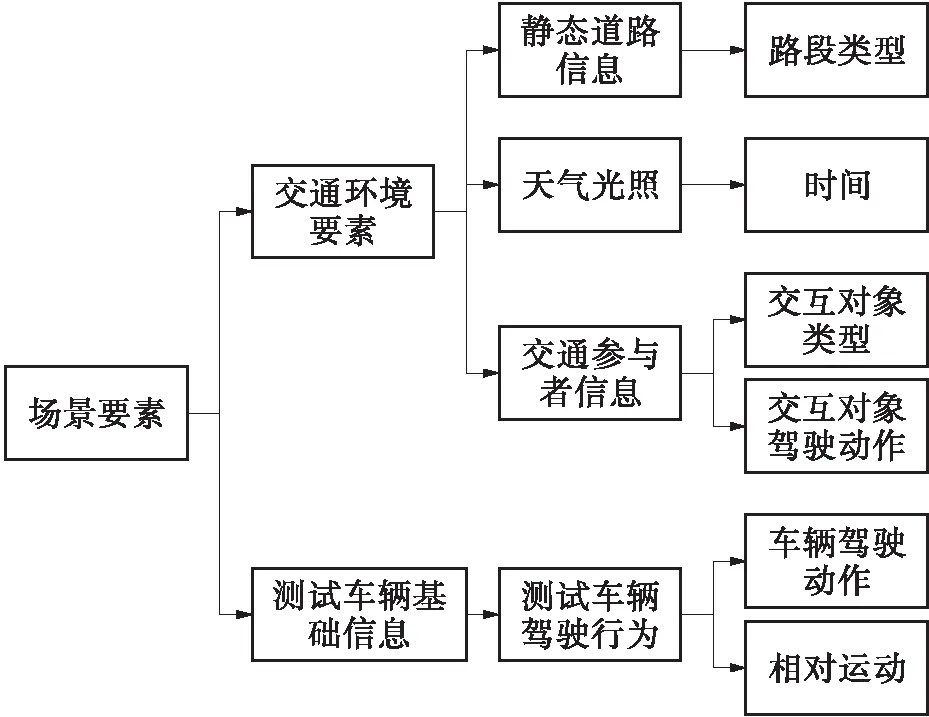
图1 场景要素
通过对1 130例事故数据的初步统计分析,将641例场景数据按照路口类型分为两类分别进行聚类分析比较合理:第1类是无路口的普通路段(376例),第2类是路口路段(265例)。考虑到车辆的驾驶动作和相对运动可以较大程度地描述事故双方的运动情况,结合事故双方的碰撞部位和交通法规可以确定交互对象的驾驶动作和起始方位,而且在实际交通环境中,交互对象驾驶动作往往具有复杂性和多样性,所以不将交互对象驾驶动作作为聚类变量。综上,选择时间、路段类型、交互对象类型、车辆驾驶动作和相对运动5个场景要素作为聚类变量。
2.3 相关性分析
使用Cramer’s V统计量来衡量两个分类变量对之间的关联强度,接近1的值显示强关联,接近0的值显示弱关联或无关联[9]。
对第1类事故数据和第2类事故数据进行相关性分析,以普通路段数据为例,相关分析结果如表2 所示。从表中可以看出,Cramer’s V接近于0,变量之间都为弱关联,总体上相关性对聚类结果无实质影响。
2.4 聚类分析
一般来说,簇的数量越高,轮廓系数就越高,较高数量的簇可能是过拟合,较低数量的簇可能是欠拟合[11]。根据簇数大小和簇有效性之间折衷的思想选择最佳的族数(k),限于篇幅限制,文中以普通路段数据为例,对最佳簇数做出选择。
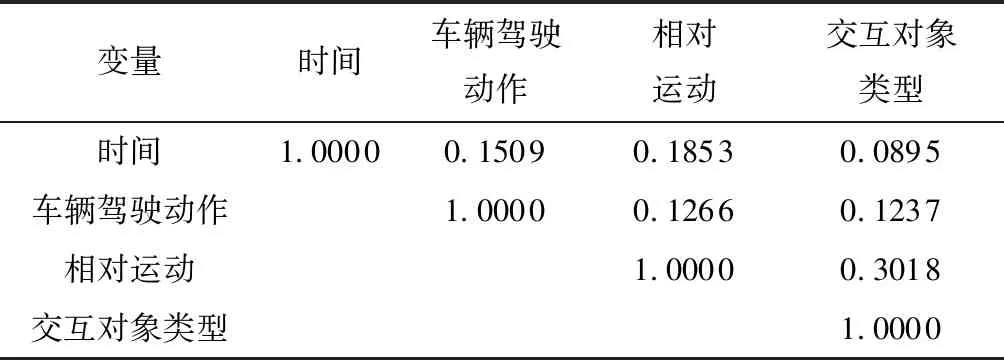
表2 普通路段数据相关性分析Table 2 Correlation analysis of common sections data
结合ASW值和不同簇数的最小簇样本数来确定最佳簇数[9]。最佳簇数确定规则:一是最小簇样本数占总样本的比例须大于等于某一比例,而该比例根据ASW值及其变化情况确定;二是在具有较高最小簇样本数下选择具有较高ASW值的簇数;三是具有较高ASW值时,为减小错误聚类的可能,选择总体负轮廓系数较小的簇数。
如图2所示,对于9个或更多的簇数,每个簇中的最小样本数减少到小于等于23个(占总样本的6.1%),因样本量过小且6到8个簇数的ASW值较高(在0.4以上),所以不进行选择。图2中6个簇数、7个簇数和8个簇数具有较高的ASW值且有相同的最小簇样本数,其ASW值分别为0.415、0.442和0.464。对比6个簇数轮廓系数图(如图3所示)、7个簇数轮廓系数图和8个簇数轮廓系数图可知,6个簇数的轮廓系数图出现负轮廓系数的样本明显较少,即被放置在错误聚类中的样本较少,所以选择6为最佳簇数。

图2 普通路段不同簇数ASW值和最小簇样本数
对于普通路段数据,选择簇数为6的情况下得到的聚类结果如表3所示,表中加粗的频数代表了聚类中心点的聚类变量取值。定义各个簇中心点的聚类变量取值为每一个簇的典型场景的属性,典型的车辆碰撞危险场景为C1-C6,如场景C1描述为:在白天,普通路段,直行的乘用车碰撞垂直方向上行驶的动力两轮车。对于路口数据,通过聚类分析,判断确定最佳簇数为9,并进行相应的场景分析。

图3 普通路段6个簇数的轮廓系数图
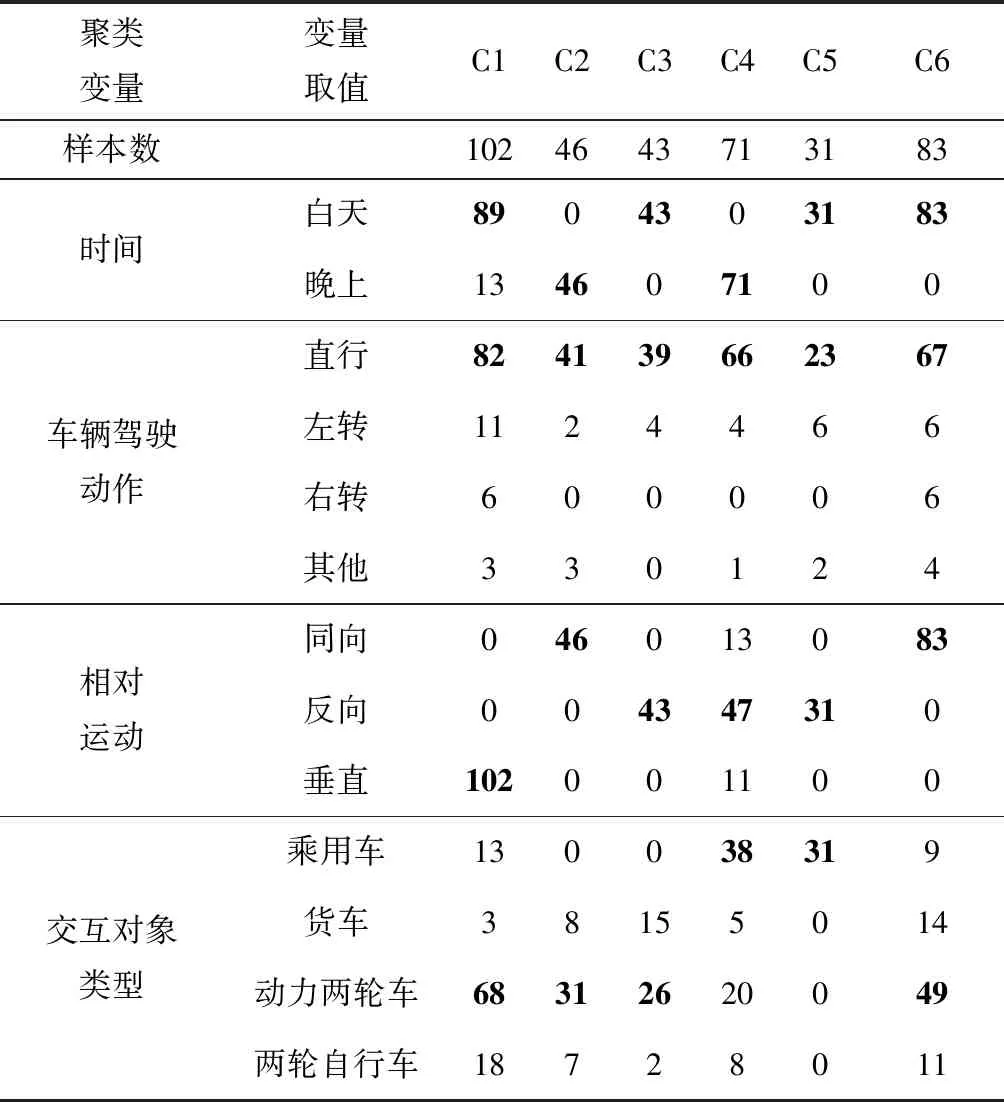
表3 普通路段每簇聚类结果频数表Table 3 Frequency of clustering variables in each cluster for common sections data
3 自动驾驶测试场景的提取和分析
3.1 危险事故特征分析
为进一步描述和分析危险场景并提取测试场景,对典型的车辆碰撞危险场景中具体描述场景的危险事故特征进行研究。结合典型的车辆碰撞危险场景定义如下8个因素为危险事故特征:天气、第1 碰撞点位置、车辆速度、交互对象速度、碰撞点相对于路口的距离、碰撞最终位置与碰撞点的方位距离、碰撞前平均减速度和事故发生前车辆具体运动类型。由于部分特征数据难以获得或者丢失严重,所以只对天气、第1碰撞点位置、车辆速度和事故发生前车辆具体运动类型4个特征进行统计分析。
(1)天气
考虑到自动驾驶汽车主要是通过雷达、相机等传感器来感知环境,且易受到恶劣天气的影响,所以对天气中晴、阴、雨和其他4个取值进行统计分析,分析可得天气特征在6个场景中分布基本一致,占比最大的是晴天(占60%以上)。
(2)第1碰撞点位置
如图4所示,除C6场景外,车辆碰撞位置在前侧的比例占75%以上。
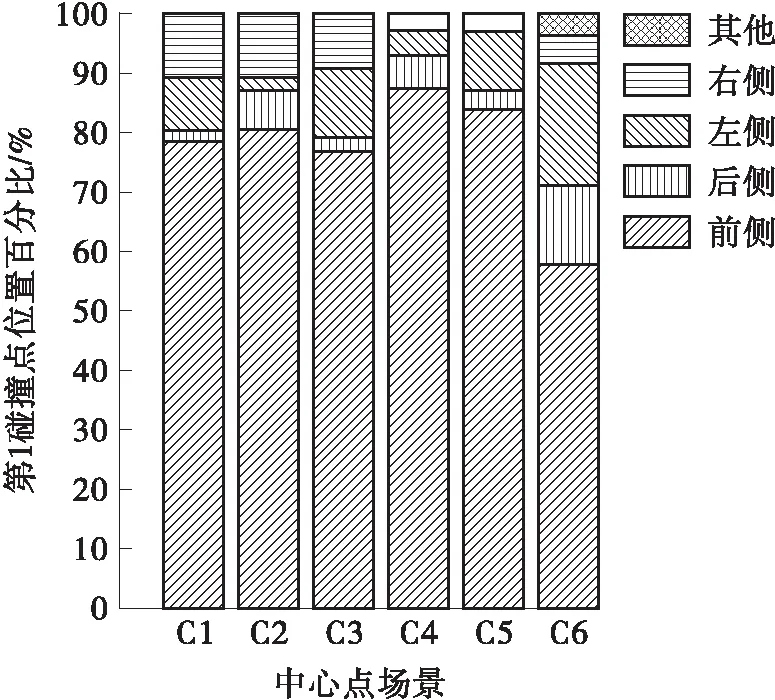
图4 普通路段车辆第1碰撞点位置的分布
如图5所示,6个场景的交互对象的第1碰撞点位置分布不同。交互对象中,C2场景碰撞位置在后侧最多(占58.7%),其次是前侧,可推测该场景为交互对象被乘用车追尾;C3场景交互对象碰撞位置在前侧的占比最大,可推测C3场景中乘用车与交互对象正面碰撞;C4和C5场景交互对象碰撞位置在前侧的占比大,且交互对象都为乘用车;C6场景的交互对象的碰撞位置在后侧(占33.7%)和右侧(占19.3%)相对其他类占比较大,这与C6场景中乘用车前侧和左侧占比大相对应,可以推测参与方在向右变道时与乘用车发生碰撞。
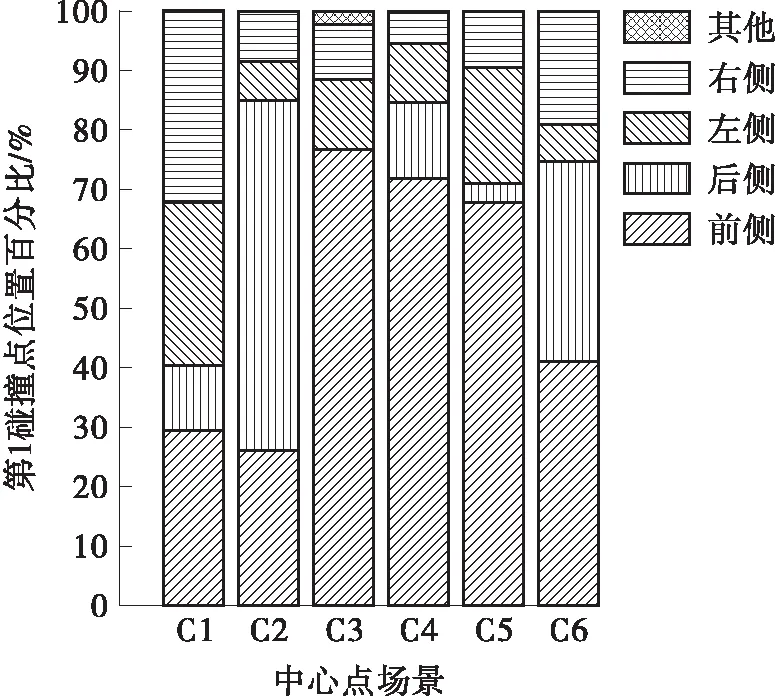
图5 普通路段交互对象第1碰撞点位置分布
(3)事故发生前车辆具体运动类型
如图6所示,全部场景中的车辆具体运动类型为匀速直行占比最大,右转、向左变道和向右变道等具体车辆运动类型占比较小。

图6 普通路段事故发生前车辆具体运动类型分布
(4)车辆速度
经过事故重建的数据在各类典型车辆碰撞危险场景数据中约占22%,所以车辆速度的置信度较高,较好地贴近了事故案列的真实速度分布。如表4 所示,C2、C3和C4场景碰撞前的车速较高,C5场景的平均车速最低,C2场景的平均车速最高。对车辆速度的统计分析可以为测试场景的测试车速提供依据。为便于测试场景进行测试,根据50百分位车速确定测试车车速。如C1场景,以靠近50百分位车速和5的倍数确定基准测试车速为40 km/h。
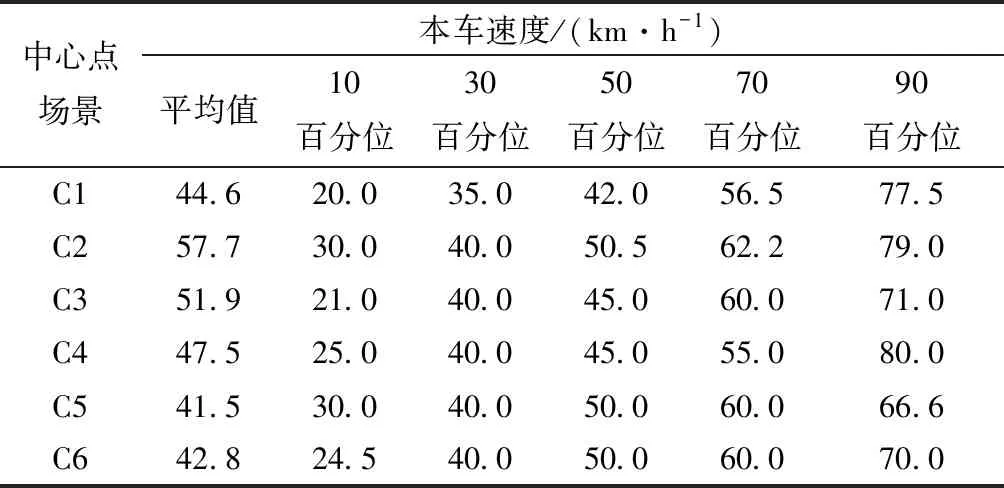
表4 普通路段乘用车速度分布Table 4 Velocity distribution of host vehicles in different core scenarios for common sections
3.2 测试场景的构建和分析
通过聚类分析得到了15个典型车辆碰撞危险场景,结合第1碰撞点位置特征,确定了交互对象的起始方位和驾驶动作,进一步结合其他危险事故特征,以车辆为测试车,以交互对象为目标车,构建了15个自动驾驶测试场景,包括6个普通路段的测试场景和9个路口路段的测试场景,测试场景描述和部分场景示意图分别如表5和图7所示。
对比表5中场景描述可知,车辆的第1碰撞点位置集中在车前侧,其次为左侧;在普通路段的场景车速普遍比路口场景的车速高;测试场景中目标车40.0%涉及M1类乘用车;测试场景中关于PTW(包括摩托车和电动助力车)的测试场景占15个测试场景的53.3%,占6个普通路段测试场景的66.6%。为了便于与相似的车辆测试场景研究[9- 10]进行讨论,将测试场景以目标车类型分类,将典型车辆测试场景分为9个关于TWS的场景和6个关于乘用车的场景。

表5 自动驾驶汽车测试场景Table 5 Test scenarios of autonomous vehicles


图7 部分测试场景示意图
关于TWS的测试场景中,场景C1、J3、J4和J9与文献[9]的场景1描述基本一致,场景J6与文献[9]的场景4描述基本一致。研究的场景得到了文献[9]的验证,且具有更详细的场景描述,如将文献[9]的场景4具体到X型路口的J6场景。总体来看,得到的关于TWS的测试场景与文献[9]有一定差异,因为本文研究的数据是NAIS数据库,更倾向于严重程度较高的事故,而文献[9]研究的数据是中国深度事故数据库(CIDAS),具有更全面的事故类型。但相比文献[9]的研究本文有3个优势:一是场景描述更具体,特别是在较高比例事故重建的基础上分析了碰撞车速的分布;二是考虑了路段类型,对场景的位置环境有更明确的描述;三是场景更具有事故严重性和危险性。
文献[10]使用不同年份的NAIS数据库,选取了499例路口事故数据,研究得到了8个关于路口路段的场景。文献[10]的场景3和文中场景J4描述基本一致,场景5和文中场景J8描述基本一致,且场景J8与Euro-NCAP最新发布的规程中推荐2020年引入的AEB十字路口场景基本描述相符[10]。本文与文献[10]相比没有区分事故案例中主动碰撞方和被动碰撞方,并没有把天气、信号灯类型和车速等作为聚类变量,所以提取到的场景与文献[9]研究得到的测试场景有明显的目标车车型的差异。但本文的研究对象更具有针对性,其将目标车类型具体为乘用车、货车、PTW和自行车,并提出了危险事故特征,描述了测试车和目标车的第1碰撞点位置,采用更有优势的独热编码进行数据前处理。综上,研究得到的测试场景是对事故数据另一角度的合理描述。
4 结论
(1)针对中国交通事故较多发生在普通路段和路口路段的独特交通环境特征,考虑了道路路段类型,对乘用车与驾乘交通工具的道路使用者的自动驾驶汽车测试场景进行了研究,得到了15个涉及道路路段类型的自动驾驶汽车测试场景,测试场景包括6个关于普通路段的场景和9个关于路口路段的场景,其中9个是关于乘用车-TWS的场景,6个是关于乘用车-乘用车的场景。
(2)自动驾驶汽车测试场景中测试车碰撞的目标车是M1类乘用车、动力两轮车和自行车;测试场景中关于动力两轮车的测试场景占总测试场景的53.3%,占普通路段测试场景的66.6%,相比其他测试场景是最可能发生的测试场景。
(3)提出的天气、第1碰撞点位置、车辆速度等危险事故特征能够更好地描述和明确测试场景;结合独热编码的数据前处理方法具有灵活处理非连续型数值特征的优势,同时在一定程度上进行了特征扩充。
