基于改进YOLOV3与贝叶斯分类器的手势识别方法研究
2021-07-08韩曼菲张莉莉吕佳琪
袁 帅,韩曼菲,张莉莉,吕佳琪,张 凤
(沈阳建筑大学 信息与控制工程学院,沈阳 110168)
1 引 言
手势识别[1]作为人机交互技术的一种重要方法已经在电子产品和智能设备中得到广泛关注与深入研究.例如聋哑人的手语翻译[2],手势控制的智能无人机,保时捷MissionE手势识别系统等已经有实际应用.手势识别的早期设备数据手套[3]因硬件设备造价昂贵,使用复杂,很难实现.目前基于深度学习的计算机视觉主流方法存在着泛化能力不强、结构过于复杂等不足,导致检测时间过长、精度不高等问题.因此,深入研究基于深度学习的手势识别方法对人机交互技术发展具有重要意义.
手势识别算法在传统方法方面通常依赖硬件设备或者基于视觉方法进行识别.Jayashree R.Pansare等[4]提出采用网络摄像机的实时手势识别,通过连通域提取和标记手势特征,能够可靠地识别单手手势,但在复杂背景下识别精度不高.因此,为了减少背景因素对于检测结果的影响,Singha J等[5]采用基于视觉的手势动态识别系统,该系统采用改良的Kanade-Lucas-Tomasi特征跟踪器用来跟踪手进而选择最优特征,确定手势区域,该方法减少了背景的影响,并且提高了识别精度,但是训练时间较长.为解决训练时间较长的问题,潘志庚等[6]提出了基于Kinect和肤色检测算法结合的手势识别系统,然后使用改进的凸分解算法和骨架匹配算法,算法效率有所提升,硬件设备影响较大.任彧等[7]提出将梯度方向直方图与支持向量机结合进行手势识别,减小了环境对识别任务的影响.并且谭台哲等[8]采用深度信息与肤色信息结合的方法,也减少了硬件设备的影响,并且具有更高的鲁棒性.此外,James Rwigema等[9]提出的一种差分进化方法来优化参数,训练速度与之前相比明显提高,但精度有所下降.以上通过自行设计建模方法进行手势识别的一系列方法,没有能够挖掘手势的深度特征,不能深度检测手势的深层信息,所以以上基于传统模型的识别方法有着许多的弊端.
随着近年来深度学习的发展,深度学习神经网络的学习算法得到迅速发展,并且广泛的应用,不少学者开始将深度卷积网络应用在手势识别的研究中.Alani A A等[10]提出一种自适应深度卷积网络的手势识别系统,来解决模型过拟合问题,提高了手势识别的性能但是训练时间较长.Bo Liao等[11]提出双通道CNN来融合颜色信息和深度信息,利用双通道的网络结构提高识别精度,并且通过深度信息对图像进行分割,以消除复杂背景和光照变化的影响.以上方法都存在网络结构复杂,系统参数数量过多,导致学习时间过长的问题,因此,Muneer Al-Hammadi等[12]提出了基于三维CNN卷积神经网络,该网络利用转移学习进行手势识别.另外,Rubin Bose S等[13]提出基于faster rcnn与Inception V_2结合的手势识别系统,获得了较好的查准率和召回率,较好地解决了进行识别任务时所用时间较长的问题.Sruthi C J等[14]提出了基于视觉的印度手语自主识别系统深度学习体系结构,提高了识别性能,但泛化能力不强.随着递归网络的发展,许多学者将其引入识别任务中.Lu Dongwei等[15]提出了利用CNN与时间递归神经网络结合构造的手势识别模型,该模型相对于一般的CNN有着更好的性能,并且泛化能力较强.Ji-Hae Kim等[16]提出了基于深度卷积和递归神经网络的手势识别算法,利用了4个卷积层处理数据,通过递归神经网络进行手势分类,但是由于神经元个数较多导致学习时间过长,收敛速度较慢.另外,吴晓凤等[17]采用Faster R-CNN进行手势识别,为适应不同的手势类别,先修改Faster R-CNN网络中的参数,再使用扰动交叠率算法,使训练过程中的对于数据过于严格的现象不再发生.Chi D等[18]提出了采用多卷积神经结构的手势识别系统,利用SSD结构和神经网络提取关键点特征,该方法在复杂环境下有较好鲁棒性,但是也存在收敛速度较慢的问题.为解决模型收敛速度的问题,Redmon J[19]等提出了YOLOV3算法,该算法很好的平衡了准确度与速度这两项指标,虽然该算法的一些表现良好,但是在手势检测领域还有待提高,例如相对小目标的手势图像存在着空间位置、尺寸范围变化影响检测效果等问题.
针对上述方法存在的诸如速度较慢、检测精度易受背景图像影响等问题,本文提出基于改进YOLOV3网络与贝叶斯分类器结合的手势识别模型.采用空间变换网络改进YOLOV3网络来对手势特征进行深层次提取,然后通过结合主成分分析(Principal Component Analysis,PCA)网络与贝叶斯分类器对特征维数进行降维并分类.最后本文在标准数据集与自制数据集上进行测试,验证了本算法的有效性.本算法增强了特征提取能力与特征分类的准确度,提升了目前手势识别方法检测效果.
2 相关工作
2.1 YOLOV3算法
YOLOV3网络的主要思想是将输入图像预处理至416×416大小,然后分成13×13个网格,如果ground truth中某个目标的中心坐标落在某个网格中,则由该网格预测目标,其中每个网格都会预测3个边界框.
首先通过特征提取网络Darknet53对输入图像进行特征提取,其中经过5次下采样,并且采用残差结构,目的是使网络结构在很深的情况下,仍然能够收敛并且继续训练下去,得到大小一定的特征图,具体检测方法是先对13×13的特征图进行卷积预测,得到第1个尺度下的检测结果;然后将13×13的特征图上采样得到 26×26 特征图,与网络下采样生成的 26×26特征图进行特征融合后进行卷积预测,得到第2个尺度下的结果;同理得到第3个尺度下的结果.每个尺度的特征图负责预测不同大小的目标.每个特征图对应3种大小不同的anchor负责预测目标.将3次检测结果进行非极大值抑制(Non Maximum Suppression,NMS)得到最终结果.
2.2 空间变换网络
卷积神经网络[20]由于最大池化操作,可在一定程度上实现平移不变形.但是当图像发生一定程度尺寸、角度和规模的变化时,会对最终识别结果产生影响.所以针对输入数据部分空间变化特性不敏感的问题,本文提出利用空间变换网络[21](Spatial Transformer Networks,STN)对输入图像进行空间变换操作,该网络能够依据自身的较强的空间不变性来降低输入数据在空间多样性上受到的影响,提高算法模型的识别检测和提取特征的能力.STN的输入特征图为U,输出特征图为V,其由定位网络(Localisation Network),网络生成器(Grid generator)和采样器(Sampler)3部分构成,网络结构图如图1所示.
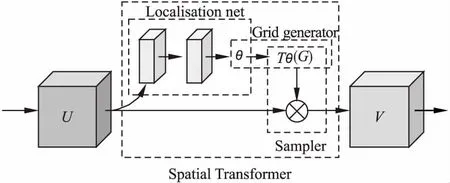
图1 STN网络结构图Fig.1 STN network structure diagram
1)定位网络的目标是生成学习空间变换参数θ.输入特征图维度为U∈RH×W×C,其中H为特征图的长,W为宽,C为通道数.通过卷积与全连接回归操作得到空间变换参数θ=floc(U),其中floc()代表定位网络.
2)网络生成器利用仿射变换将输入特征图进行对应的坐标变换.坐标转换的计算公式如式(1)所示:
(1)
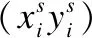
3)采样器利用采样网格和输入特征图同时作为输入产生输出,得到特征图经过变换之后的结果.由于在第2步计算出了V中每个点对应到U的坐标点,在这一步就可以直接根据V的坐标点取得对应到U中坐标点的像素值来进行填充,而不需要经过矩阵运算.此时计算出来的坐标可能是小数,使用双线性插值.输出的表达式如式(2)所示:
(2)

2.3 朴素贝叶斯分类器
朴素贝叶斯分类器[22]是以贝叶斯理论为基础的一种分类方法.该分类方法是基于样本的先验概率预测样本属于某一类别的概率,并选择其中的最大概率作为最终预测类别.具体的分类过程为:假设各个特征条件是独立的,根据给定的训练数据集,计算联合概率分布,用来生成分类器,然后根据训练生成的分类器,对输入的样本进行分类.
假设x=(a1,a2,…,am)为一个待分类项,其中每个a为x的一个特征属性,类别集合为C={y1,y2,…,yn}.现对样本进行分类,即计算P(y1|x),P(y2|x),…,P(yn|x).首先统计各类别下各个特征属性的条件概率,即P(a1|y1),P(a2|y1),…,P(am|y1);然后由于各个特征属性都是独立的,则根据贝叶斯定理:
(3)
其中分母对于所有类别都为常数,都是相同的,又因各特征属性是条件独立的,所以只需将分子最大化,则式(3)可写成式(4),选取最大的后验概率P(yi|x),作为待分类项x的类别.
(4)
最终选取最大的后验概率P(yi|x),作为待分类项x的类别.
3 YOLO算法模型改进
3.1 模型网络结构
基于改进的YOLOV3网络与贝叶斯分类器的手势识别方法的主要思想是先利用STN对输入图像进行特征提取与图像矫正,以此加强模型的特征提取能力和空间变换能力;然后通过Darknet-53网络中的一系列卷积与残差交替结构对输入数据进行下采样与特征提取操作,该部分将得到13×13、26×26和52×52这3种不同尺度的特征图;接着通过进一步的上采样与张量拼接等操作进行特征提取,最终输出经过网络提取出的手势特征.然后进入特征分类部分,由于经过神经网络提取出的手势特征维数特别多,影响识别效率,所以本文中先利用PCA进行降维,来减少特征的维数;然后融合贝叶斯分类器,对经过降维的特征进行分类,输出层有0-9共计10个类别,最终输出手势的分类类别.本文手势识别系统的网络结构图如图2所示.

图2 STN结合YOLOV3的手势识别系统网络结构图Fig.2 STN combined with YOLOV3 gesture recognition system network structure diagram
3.2 空间变换网络改进
手势相对于整张图像来说属于小目标,并且存在手势图像存在扭曲、拉伸或在图像中的位置差异等问题,将会影响最终的检测结果.因此,为了减小以上问题对于检测精度的不良影响,本文在YOLOV3网络框架的基础上结合了STN网络,该网络可以对数据进行空间变换操作,整合以后的结构仍旧可以进行端到端的训练.STN能自动获取感兴趣区域,因此通过卷积层与池化层交替设置来提取空间变换特征信息,然后通过全连接层输出学习得到的仿射变换矩阵,在测试样本上通过仿射变换进行空间变换,最后得到优化后的图像.优化后的输入图像能够将需要检测的关键区域即手势区域尽量分布到图像中间,以此来减少对检测结果产生的影响.通过STN与网络的结合,不但对图像进行自动校正,手势的空间位置,还通过仿射变换进一步对更高层次的手势特征进行处理,大大增加了网络的处理精度,并且能够增强算法的空间变换能力与特征提取能力.
3.3 手势识别分类器的改进
在高维数据的特征向量中,手势特征具有信息冗余的缺点.因此,需要采用降维去除高维数据中的冗余特征,同时将重要信息保留在降维之后的特征向量中.本文采用PCA降维,用来降低深度卷积神经网络特征的维数,降维能够减少数据在训练时所需的存储空间,能够训练算法使其速度加快,并且去除数据中的冗余特征和噪声.在应用贝叶斯分类器之前,根据零均值和单位方差对手势特征进行归一化处理,然后采用贝叶斯分类器进行分类.对于给定的图像,贝叶斯分类器能够在很多类别中找到属于该类的最大后验概率,从而使测试手势图像能够被正确地分类.
经过降维之后需要解决手势的识别分类问题,降维之后的特征数据明显减少,大大减少了运算量,并且本文手势识别属于分类问题,本文将融合贝叶斯分类器对手势进行分类.
利用贝叶斯公式对提取出的手势特征求出最大后验概率来进行手势的分类.手势特征的待分类项为X(x1,x2,…,xm),手势的类别集合为(y1,y2,…,yn),先计算在训练集中每个手势类别的条件概率如式(5)所示,再求解手势属性属于不同类别的后验概率如式(6)所示,最后将该手势归类为具有最大后验概率的手势类别.
P(X|yi)=P(x1,x2,…,xm|yi)
(5)
(6)
4 实验分析
实验主要配置:CPU为Intel(R) Xeon(R) CPU E5-2650 v3,GPU为AMD Radeon HD 7000 series,操作系统为Windows10,深度学习框架为TensorFlow.使用标准数据集与自制数据集进行对比实验,用来验证改进方法的有效性.
4.1 实验数据集
实验采用的数据集分为两部分,一部分是以美国标准手语0-9为标准的10种手势组成的数据集,如图3所示;另一部分是自制数据集,包含采用计算机摄像头进行采集的图像,并且运用图像标记软件labelImg对图像进行标记,如图4所示,均采用上下左右不同手势角度及不同光照强度的手势.每种手势包含314个样本,共3140个样本,随机选取其中90%的数据作为训练集,10%的数据作为测试集,测试集图片一共有314张.

图3 标准手势数据集示例Fig.3 Samples of standard hand gesture dataset

图4 自制手势数据集示例Fig.4 Samples of self-made hand gesture dataset
4.2 评价方法
为了更准确比较本文算法的检测性能,现采用以下性能指标来衡量算法性能:
1)平均精度AP(average precision):AP是针对单一类别的精度,表示为:
(7)
(8)

2)平均检测精度均值mAP(mean Average Precision):mAP为每一个类别的AP的均值,计算公式如式(9)所示,其中Q为识别目标的类别数.
(9)
4.3 实验结果分析
在YOLOV3网络进行多尺度检测时,对每一个尺度都产生3个边框的预测,将会导致同一检测目标被重复检测,产生重叠的检测框,对检测结果造成一定的影响,为避免这样的问题,采用非极大抑制的方法对检测结果进行处理来得到最终的检测结果.现选择不同的非极大抑制阈值(NMS thresh)对原YOLOV3和改进YOLOV3模型在测试集上进行测试.测试结果如表1所示.

表1 不同NMS阈值的平均检测精度均值Table 1 Mean average precision of different NMS thresholds
如表1所示,在NMS阈值为0.5时,原YOLOV3的mAP为93.99%,改进YOLOV3的mAP为96.73%,改进模型相比原模型的mAP提高了2.74%,并且总体上改进模型的mAP比原模型都要高.因此,改进模型的检测效果更好,并且选择NMS thresh为0.5作为改进模型的参数,具有更好的检测精度.
将原YOLOV3和改进YOLOV3模型在测试集上对不同的手势类别class 0-class 9进行检测结果如表2所示.原模型的AP值浮动较大,且精确度不高;改进模型的AP值较稳定,且均高于95%,相比原模型有着较大的改进.图5中横轴为手势类别,纵轴为AP值,将两模型进行柱状图对比,更形象地显示出了不同手势类别在测试集上的检测结果.
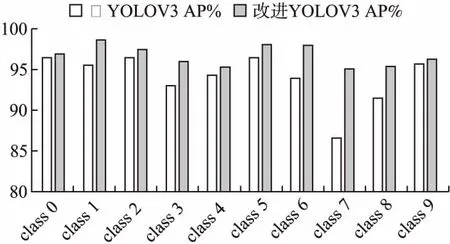
图5 不同手势类别在测试集上的检测结果Fig.5 Histogram of the detection result of different hand gesture categories on the test set
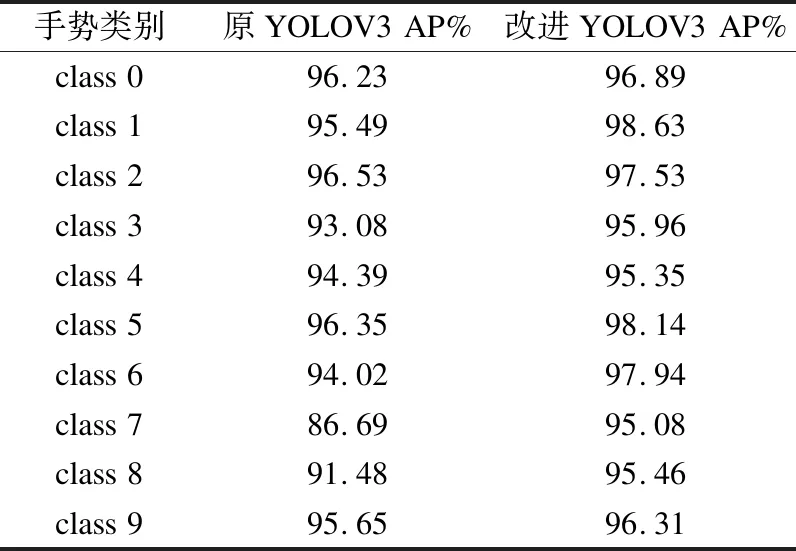
表2 不同手势类别在测试集上的检测结果Table 2 Detection result of different hand gesture categories on the test set
YOLOV3与改进YOLOV3网络的准确率指标对比曲线如图6所示.随着迭代次数的增加准确率逐渐提高,经过大约30000次迭代后,准确率变化趋于稳定,此时网络已经达到收敛状态.并且改进网络的准确率明显优于原网络,证实了改进算法的有效性.
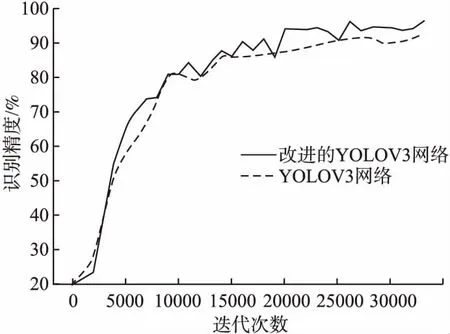
图6 迭代次数与准确率关系曲线Fig.6 Contrast curve between the YOLOV3 algorithm and the improved algorithm
由表3可知,采用传统方法HOG与SVM相结合的方法,识别准确率较低;采用深度学习中的Faster RCNN方法得到的结果虽然相比传统方法有着一些提升,但是结果并没有本文提出的方法好;并且对比改进的YOLOV3模型比原YOLOV3模型提高了2.74个百分点,由于改进模型中贝叶斯分类器方面的改进,大大减少了计算量,加快了检测速率,相比原模型检测时间减少了3.1%.
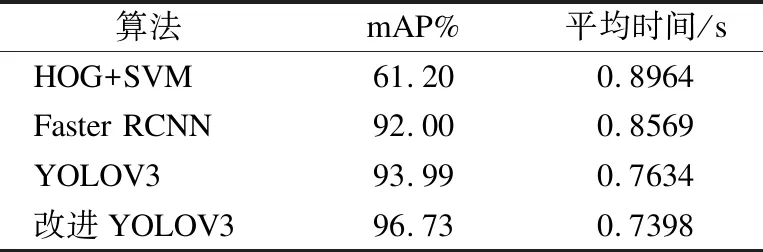
表3 改进模型与原模型性能对比Table 3 Performance comparison between the improved algorithm and the original algorithm
5 结 论
本文提出一种改进的YOLOV3手势识别网络,能够更快更准确地识别出手势目标.本文工作首先融入空间变换网络对训练数据进行空间校正与初步特征提取,降低了数据在空间多样性上受到的影响;使用YOLOV3网络进一步提取特征;然后采用PCA降维技术对提取出的特征向量中冗余特征进行降维操作,随后采用贝叶斯分类器对手势类别进行判定,提高了网络的检测效率.本文算法在保持网络深度特征的同时减少了运算量,控制了网络的参数数量.最后在公开数据集与自制数据集上进行对比实验,实验结果表明本文改进算法精度明显提高,检测时间有所缩减,证明了提出算法的有效性.
