一种改进时序卷积网络的序列推荐方法
2021-07-08施浩杰刘学军肖庆华
施浩杰,刘学军,肖庆华
(南京工业大学 计算机科学与技术学院,南京 211816)
1 引 言
推荐系统的主要目的是根据用户的历史交互信息,来预测用户下一步的偏好行为[1].传统的协同过滤(Collaborative Filtering,CF)方法认为用户的偏好和项目属性都是静态的,主要利用用户信息(如个人资料、项目评分等)进行相似度计算,从而进行偏好分析,却忽略了用户的兴趣偏好是一种时序数据.用户的兴趣会随着时间的变化发生偏移,项目属性也会随时间而变化,如电影的受欢迎程度会随外部事件(如获得奥斯卡奖)而发生变化[2].同时,协同过滤方法使用未来的评分来评估当前喜好的做法也在一定程度上违背了统计分析中的因果关系.近年来,考虑用户历史行为的序列推荐方法,为问题的解决提供了新的思路.随着深度学习的蓬勃发展,循环神经网络(Recurrent Neural Networks,RNNs)由于其天然的序列结构,成为当前学术界对序列进行建模的主要工具.但RNN的决策要取决于所有过去的隐藏状态,无法在序列中充分利用并行计算,因此在训练和评估时的速度都受到限制.另外,在现实情况下,用户的兴趣可能并不是连续的.
如图1(a)所示,通常情况下,用户购买手机之后,会倾向于依次购买手机壳和充电宝,这个时候推荐系统可以依靠经验推荐数据线.但是实际会出现这样的情况,如图1(b)所示,用户在浏览了手机和充电宝之后,又突然搜索了并不相关的自行车,这时自行车的浏览就会成为推荐充电宝的干扰项,因此需要在推荐时考虑更为久远的项目,从而对推荐列表的生成产生影响.

图1 传统序列推荐方法存在的问题Fig.1 Problems in traditional sequential recommendation methods
为了解决上述问题,本文提出了一种基于改进的时序卷积网络的序列推荐方法(SETCNs),主要工作包括:1)使用时序卷积网络(Temporal Convolutional Network,TCN)取代传统的循环神经网络,作为捕捉序列信息的主要模型,通过结构空洞的扩张卷积扩大感受野,捕捉更为复杂的序列关系,从而加强了长期依赖;2)通过将残差连接和注意力机制结合,在TCN的基础上对压缩-激励网络[3](SENets)进行了改进.通过压缩激励模块,让TCN能够对层间的短时空间特征序列的权值进行重新标定,从而更好地利用序列特征,加强重点项目对推荐决策的影响,实现更好的推荐效果.
2 相关工作
传统的序列推荐研究主要有频繁模式挖掘(Frequent Pattern Mining,FPM)和马尔可夫链模型(Markov Chains,MCs).
频繁模式挖掘的基本思想是首先在序列数据上寻找频繁模式,通俗来说即项目A和项目B的共现性,然后利用挖掘出的模式来指导后续的推荐.Lu等[4]提出了一种移动应用程序顺序模式挖掘方法,考虑用户移动和应用启动,以发现顺序模式,用于通过预测用户的下一个使用的应用程序来解决上下文自适应的问题.频繁模式挖掘虽然简单直接,但会产生大量的冗余模式,增加不必要的开销.并且由于频率约束,会经常丢失那些出现频率低的模式和项目,这使得推荐结果被限制在那些流行的项目.
基于马尔可夫链的推荐方法,其主要学习的是状态转移概率,即用户点击物品A之后,下一次点击的物品是B的概率,并基于这个状态转移概率进行推荐.Khattar等[5]提出了一种基于项目的协同过滤的新方法,用于使用马尔科夫决策过程(Markov Decision Process,MDP)推荐新闻项目,最简单的MDP本质上是一阶马尔科夫链,其中可以基于项目之间的转移概率简单地计算下一个推荐.这类算法缺点是当试图包括用户所有可能选择的序列时,状态的数量会随问题维度扩大而指数增加,状态空间难以管理.因为随着物品的增加,建模所有可能的点击序列是十分困难的.另一方面,由于马尔可夫特性假设当前的交互仅取决于一个或最近的几个交互,因此只能捕获短期依赖而忽略了长期的依赖关系.He等[6]基于马尔可夫链提出了一种个性化的序列推荐模型,将矩阵分解和马尔可夫链方法结合起来,以同时适应长期和短期动态.
近年来,学术界也涌现出了利用深度学习方法来对序列推荐进行建模的热潮,其中一些解决方案代表了序列推荐研究领域的最新技术.Hidasi等[7]使用门控循环单元(Gated Recurrent Unit,GRU)来建模序列数据,直接从给定会话中的先前点击学习会话表示,并提供下一个动作的建议.这是首次尝试应用RNN来解决序列推荐问题,模型结果比传统方法有非常显著的提升.Tan等[8]进一步研究了RNN在基于序列推荐领域的应用,提出了一种数据增强技术,并改变输入数据的数据分布,用于改进模型的性能.Li等[9]提出一种基于RNN的编码器-解码器模型,它将来自RNN的最后隐藏状态作为序列行为,并使用先前点击的隐藏状态进行注意力计算,以捕获给定会话中的主要目的(一般兴趣).Jannach等[10]将循环方法和基于邻域的方法结合在一起,以混合顺序模式和共现信号.Tuan等[11]将会话点击与内容特征(如项目描述和项目类别)结合起来,通过使用三维卷积神经网络(Convolutional Neural Networks,CNNs)生成推荐.为了解决基本神经网络结构的局限性,一些高级模型通常与某种基本的神经网络结合,来应对特定的挑战.例如,注意力模型通常被用来在一个序列中强调那些真正重要的交互作用,同时淡化那些与下一次交互作用无关的交互.Liu等[12]提出了一个短期注意优先模型,通过采用简单的多层感知器(Multi-Layer Perceptron,MLP)和注意力网络来捕捉用户的一般兴趣和当前兴趣.总的来说,基于深度学习的序列推荐研究方兴未艾,主要涉及如何设计不同的网络结构以简便高效地捕获高阶动态.
近日,Bai等[13]对于序列问题提出了一种新的架构时序卷积网络,与传统的序列模型如LSTM或GRU相比,TCN具有更简单的结构和更高的效率.在此基础上,为了提取更完整的时间特征,本文在TCN的基础上引入了SENets进行增强,SENets是一种新的结构单元,其作用是通过对特征各个通道之间的相互依赖关系进行建模,增强重点通道的权重来提高网络表示的质量.在本文的方法中,我们对SENets进行了改进,通过使用压缩激励模块,将其组合入TCN,增强TCN在时间特征提取中的能力,通过注意力机制加强了重点项目对推荐结果的影响.模型利用扩张卷积增大感受野,捕获更多的序列关系,利用残差连接减小反向传播过程中的梯度消失问题.通过对用户和项目特征的融合,模型可以综合考虑用户的短期和长期偏好进行个性化推荐.
3 SETCNs方法
3.1 问题描述
序列推荐的主要任务是根据已获得的用户当前序列信息(包括用户的一系列历史交互行为)中发现用户的兴趣偏好,预测的用户下一步的点击行为,并由此进行项目推荐.

3.2 模型框架
图2为SETCNs模型的总体框架.首先,所有的项目先被嵌入成高维向量,再根据时间戳组成序列数据.项目的嵌入表示通过item2vec[14]生成,作为用户的短期偏好,用户的嵌入表示通过隐因子模型(Latent Factor Model,LFM)[15]生成,作为用户的长期偏好.模型的重点在于序列数据的建模,在TCN的基本框架下,通过扩张卷积,逐层扩大感受野,捕捉更多的序列关系.图2中的压缩-激励模块(Squeeze and Excitation Block,S-E Block)主要负责调整各维度之间的关系.各层之间通过残差连接,在最后将用户和项目获得的向量拼接,共同输入全连接层,获得推荐项目的概率值.

图2 SETCNs整体框架Fig.2 Framework of SETCNs
3.2.1 嵌入层

假设将所有用户的历史项目交互定义为语料库S,将某单一用户u的历史交互项目视为一个集合Su,且有Su∈S.通过学习所有用户历史记录中项目间的共现关系,获得该项目的词向量表示.具体的目标函数如公式(1)和公式(2):
(1)
(2)
其中,其中u∈Si,ν∈Sj,L为语料库集合长度,N为对于每个正样本负采样的个数.
另外,对用户的嵌入表示,采用LFM进行表示.其基本思想是:认为每个用户都有自己的偏好,同时每个项目也包含所有用户的偏好信息.而这个偏好信息即潜在因子,是潜在影响用户对项目评分的因素.某个用户u对某个项目i的感兴趣程度可以表示为公式(3):
(3)
pu表示用户u与K个潜在因子的关联关系,qi表示物品i与K个潜在因子的关联关系.以样本出现的次数作为权重,随机选择项目构建负样本集,保证正负样本平衡.通过将公式(4)作为损失函数,利用随机梯度下降(Stochastic Gradient Descent, SGD)算法在数据集上迭代更新,直至收敛.
(4)
将模型收敛后得到的用户潜在因子矩阵p作为对用户的嵌入表示.
3.2.2 扩张因果卷积
本文引入TCN,采用扩张因果卷积来提取特征.因果的思想是出于处理序列特征的要求,与传统卷积方法不同点在于,因果卷积是在时间序列上进行,具体如图3所示.每一层的输出都是由前一层对应未知的输入及其前一个位置的输入共同得到.
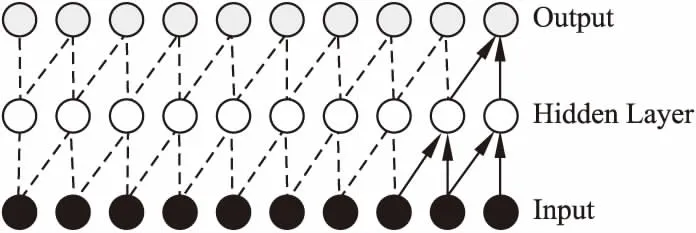
图3 因果卷积Fig.3 Casual convolution
其数学模型可表示为:y1,y2,…,yt-1,yt=f(x1,x2,…,xt),简单来说,即根据x1,x2,…,xt和y1,y2,…,yt-1去预测yt,使得yt接近于实际值.
但是标准滤波器只能与感受野线性地进行卷积,其深度会随着网络深度的增加而迅速增加.输入和输出距离越远,就越需考虑之前的输入参与运算的问题.在推荐系统中可以理解为,当前推荐项目的确定,需要更长时间段上的用户偏好信息.这带来大量需要训练的参数,因此难用以处理长期序列.扩张的基本思想是通过用零填充卷积滤波器,使其应用于大于其原始长度的场,具体如图4所示.通过扩张卷积,模型在层数不大的情况下可以获得更大的感受野,因此模型使用参数的较少.同时,扩张的卷积可以保留输入的空间尺寸,使得后期卷积层和残差结构的堆叠操作都变得更加容易.

图4 扩张卷积Fig.4 Dilated convolution
扩张卷积的计算如公式(5):
yt=(x*h)t=∑xt-dm·hm
(5)
其中*代表扩张卷积的计算符号,d是扩张率,通常设为2的指数形式(1,2,4,8,…,2i),h是卷积滤波器的参数.在实验中,为了更方便且直观的使用扩张卷积,需要对原始的数据进行一维变换操作,如图5所示,将大小为L×D二维矩阵E转换成大小为1×L×D的三维张量,E的每一行表示一个项目的嵌入表示,L表示序列的长度,D表示项目嵌入的维度,可以类比视为图像中的通道.

图5 原始数据进行一维变换Fig.5 One-dimensional transformation of the original data
3.2.3 压缩激励模块
卷积滤波器利用在一定感受野内融合空间和各通道间的信息达到特征提取的目的,一般通过使用不同大小的卷积核在同一特征图上进行滑动来学习提取图像的二维空间信息,获得不同大小的感受野输入神经网络,增强网络的表达能力,但是通常忽略了各个特征通道之间的关系.本文通过设计压缩-激励(Squeeze and Excitation)模块,采用了一种全新的特征重标定策略去建模各特征通道之间的相互依赖关系.通过网络学习自动获取各个通道在当前任务上的重要性,再根据学习到的通道权重,将注意力集中在关键的部分,提升有用特征权重,抑制对当前任务用处不大的特征,从而完成增强网络特征提取的作用.
压缩操作是对提取到的特征,在每个通道上执行全局平均池化(global average pooling).这将每个特征通道都压缩成一个代表全局感受野的实数,它表示该特征通道的全局响应,并且可以保持输出维度和输入的特征通道数一致.对于维度为D,长度为T的一串序列E=[ν1,ν2,…,ν|T|],所计算的维度描述为z=[z1,z2,…,z|T|],其中z是一个T×1维的向量,其中每一个元素的计算如公式(6):
(6)
其中vt(i)代表序列第t个元素的第i个维度,此时可以将zt作为t时刻特征的权重.
为了利用压缩操作的信息和利用通道间的信息依赖,接下来使用激励操作来完成特征的重标定,而且这个操作需要满足两个前提:第一,能够利用简单灵活的操作获得通道间的非线性关系;第二,学到的关系不一定是互斥的,因为需要加强多个通道特征,而不像one-hot编码方式,只加强了某一个通道的特征.按公式(7)采用门控机制进行激活.
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
(7)

(8)
Fscale(vt,st)表示标量st和特征图vt∈RT之间的乘法,其实质相当于把vt矩阵中的每个值都乘以对应的权重st,在通道维度上完成对特征权值的重新标定.
完整的压缩-激励操作可视为一次编码-反编码的过程,先将T × 1的序列压缩到r × 1获取全局感受野,再将其激励回新的T × 1序列.因为在每一步都加入了激励函数,所以在学习过程中,误差始终能够通过反向传播调整参数W1和W2[16].因为序列数据的结构并没有改变,因此TCN模型也不需要改变原本的结构,可以直接利用序列权值再调整后的特征进行训练.
3.2.4 残差连接
在序列特征抽取过程中,因果卷积层和扩张卷积层的叠加造成神经网络逐渐加深.为减少模型训练过程中,网络反向传播发生的梯度衰减和消失问题,需要在模型的输出层引入残差连接.残差学习的基本思想是将多个卷积层堆叠在一起作为一个块,然后采用跳跃连接的方法,将前一层的特征信息传递到后一层.将模型的输入被加权融合到卷积网络的输出中,输出被表述为输入本身和其一个非线性变换的线性叠加.其表达如公式(9):
Output=σ(X+F(X))
(9)
其中,X表示输入,F(X)表示前一层卷积层的输出,σ表示sigmoid激活函数.残差连接的概念已经在多种分类任务上取得了良好的应用,在提取高维卷积特征后,残差连接将大大提高模型的泛化能力,维护输入信息并扩大传播梯度,减小训练难度,使得模型成为深层网络和浅层网络的集成.
3.2.5 全连接层
为了捕捉用户的全局偏好,本文将用户的嵌入表示与时序卷积提取的特征拼接,再通过全连接的方式,得到预测项目出现的概率分布.对具有L层的TCN,最后一层的输出通过引入具有softmax激活函数的全连接层来实现序列分类.为减少在训练过程中的过拟合问题,在全连接层会采取Inverted dropout的方式随机关闭神经元的参数更新.与传统的dropout方法不同之处在于,Inverted dropout操作仅在训练阶段进行,省略了测试阶段的步骤.
3.3 网络训练
模型采用监督学习方式进行训练,以数据集中序列数据对应的下一个真实项目表示真实概率分布,将模型输出的项目概率分布作为预测值.实验使用二元交叉熵(binary cross entropy)作为目标函数,训练目标是最小化预测值与真实值之间的差异.为减少过拟合风险带来的模型泛化能力降低,目标函数引入了正则化.函数如公式(10):
(10)

4 实 验
本文提出的网络结构基于Tensorflow平台实现,该实验在CPU为Intel Xeon E5-2630v3,显卡为GTX 1080Ti(11G),内存为32G的服务器上运行,实验环境为Window10,Pycharm,Cuda9.0,Cudnn7.0.
4.1 数据集及实验设置
1.Movielens-1M数据集
Movielens1数据集是由美国明尼苏达大学GroupLens实验室提供的在推荐系统领域常用的数据集,有多个大小的版本.主要包括一系列用户对电影的评分,还附有这些用户的信息(如用户性别、职业)和电影的信息(如电影类别).
2.Gowalla数据集
Gowalla2是一个基于位置的社交网站,用户可以通过签到共享自己的位置,每一次的操作都带有时间戳.数据集中包括用户轨迹和社交群组.
实验遵循以下预处理程序:将评论或评分的存在视为用户与商品互动,从而将显性反馈的评分数据转换为隐性反馈的交互行为数据.使用时间戳确定序列的顺序,并丢弃ML-1M中互动次数低于5和Gowalla中互动次数低于15的部分.将处理后的数据集的80%作为训练集,同时将剩下的20%作为测试集.同时,将真实数据集中样本视为正样本,为增强数据集,在需要时通过随机采样生成负样本.处理完的实验数据集相关数据如表1所示.

表1 处理后数据情况说明Table 1 Description of the processed data
4.2 评价指标
本文使用召回率(Recall)和平均倒数排名(Mean Reciprocal Rank,MRR)作为评价指标,这两个指标也广泛用于评估其他推荐系统相关工作.
Recall@K:该指标表示用户真实点击的项目出现在推荐列表前K位的点击序列个数占测试集中序列总数的比例.只关心其是否出现在推荐列表而不考虑其顺序.这可以很好地模拟某些实际情况,绝对顺序无关紧要,而不会突出显示推荐.定义如公式(11):
(11)
其中N表示测试数据的总数量,nhit表示命中的项目数量.
MRR@K:该指标表示用户真实点击项目在推荐列表中位置序号的倒数平均值,具体定义如公式(12).若用户点击项目没有出现在推荐列表的前K位,MRR将结果为0.MRR在评价推荐列表质量时会考虑物品的次序,是一个顺序敏感的指标.
(12)
MRR是范围[0,1]的归一化分数,其值的增加反映了大多数“命中”将在推荐列表的排名位置中更高,表明相应推荐系统的性能更好.
4.3 参数设置
对于SETCNs模型,本文使用Adam优化器进行训练,每
个压缩-激励模块的增长率(growth rate)k设为12,模块的压缩率(compression rate)c设为0.5,学习率(learning rate)初始化为1e-4,批量大小(batch size)设为32,dropout概率p设置为0.5,扩张率(dilation rate)d设为[1,2,4].项目的嵌入维度分别设为[16,32,64,128],进行对比.
4.4 实验对比
为了探究本文提出的模型效果,模型将与3种传统推荐方法和3种基于循环神经网络的推荐方法分别在两个常用数据集上进行实验验证.其中,3种传统方法包括:POP、S-POP和FPMC[17];3种基于循环神经网络的模型包括GRU4Rec、GRU4Rec+和NARM[18].
POP和S-POP分别推荐训练集和当前会话中的前N个频繁项目.
FPMC是一种综合马尔可夫链和矩阵分解的序列预测方法.
GRU4Rec是首次使用RNN对用户序列进行建模的方法.
GRU4Rec+进一步提出了一种数据增强技术,通过改变输入数据的数据分布,改进模型的性能.
NARM采用引入注意力机制的RNN捕获用户的主要兴趣和序列行为.
实验首先观察项目嵌入维度参数的选取对本文方法的影响,如图6和图7所示,在两个数据集上,都可以发现项目的嵌入维度的增加会导致评价指标的上升,考虑其中的原因是

图6 不同嵌入维度在Movielens-1M数据集对实验结果的影响Fig.6 Effects of different embedding dimensions on experimental results in Movielens-1M dataset

图7 不同嵌入维度在Gowalla数据集对实验结果的影响Fig.7 Effects of different embedding dimensions on experimental results in Gowalla dataset
向量的维度过低表示能力不够,而更高的维度会带有更多的
1http://files.grouplens.org/datasets/movielens/ml-1m.zip
2http://snap.stanford.edu/data/loc-gowalla.html
隐含信息.通过S-E模块,模型在高维度的情况下可以更好地捕获其中的信息,但维度的增加也会带来相应的参数的增加和计算的开销,这是需要在实际应用中进行衡量的问题.
以下的实验结果以最终结果表现最佳的项目嵌入维度为128为准,具体的各项实验结果对比如表2所示.

表2 实验结果对比Table 2 Comparison of experimental results
从表2中可以得出结论,相对于传统的基于流行度的算法,基于神经网络的方法GRU4Rec,GRU4Rec+,NARM和SETCNs在各项指标上都有较为明显的提升,这是由于基于流行度的方法只考虑了个体的单独点击,忽略了用户的兴趣变化是一个时序相关的问题,没有考虑过往项目对未来偏好指示的问题.
同时,SETCNs表现也要优于FPMC方法,这表明传统的基于马尔可夫链的方法主要依赖的连续项目的独立性假设是不现实的,FPMC方法主要只捕捉一阶马尔可夫关系,但用户的偏好并非绝对连续,而是会受到各种因素的影响,产生间歇性的变化.
对比神经网络算法GRU4Rec和GRU4Rec+,SETCNs方法也有一定的提高,说明基于时序卷积网络的方法可以处理更长期的序列.与NARM方法相比,本文的方法提高不多,这是因为NARM方法同样采用注意力机制来捕获主要目的,但本文依旧在效果上依旧有所超越,这是由于时序卷积的结构决定了它可以获得更好地感受野,将更多的序列项目引入推荐的决策中.
另外,如图8所示,通过对比SETCNs方法和GRU4Rec+方法的损失函数曲线变化图发现,SETCNs的loss值下降到稳定值的速度比GRU4Rec+下降到稳定值的速度更快,收敛性较好,表明SETCNs相对于传统的循环神经网络,训练速度更快,且取得较好收敛效果.同时,与GRU4REC和NARM的对比也有类似的结论.因为在两个数据集上获取的结果类似,图中只展示针对Movielens-1M数据集的训练效果.
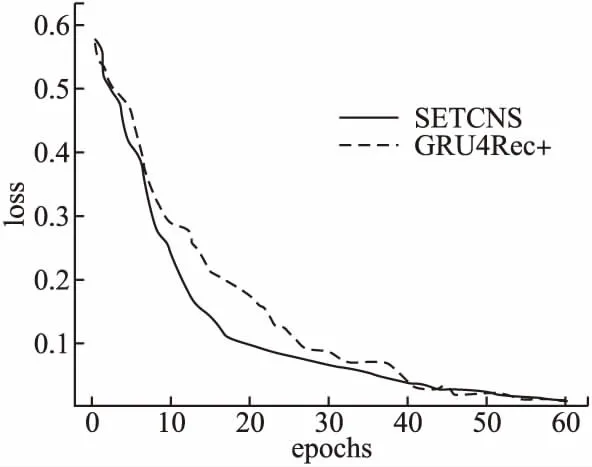
图8 SETCNs方法与GRU4Rec+方法训练损失下降曲线对比Fig.8 Comparison of SETCNs and GRU4Rec+ in loss decline curve
5 总 结
本文针对传统推荐算法无法表示用户兴趣的动态变化,基于循环神经网络的推荐方法无法捕捉复杂的序列关系,长期依赖差的问题,提出了一种针对序列推荐的SETCNs模型.在该模型中,通过嵌入压缩激励模块的改进时序卷积网络来对序列时空特征进行识别,利用注意力机制加强了重点项目对推荐决策的影响.模型通过对用户的兴趣随时间的演变进行序列建模,利用扩张卷积增大感受野,捕获更多的序列关系,利用残差连接减小反向传播过程中的梯度消失问题,并综合考虑了用户的长期和短期偏好,为用户提供个性化推荐.综合实验结果表明,所提出的算法优于基线算法,有效提升了推荐系统的精度.
