融合改进Stacking与规则的文本情感分析
2021-07-08宛艳萍谷佳真
宛艳萍,谷佳真,张 芳
(河北工业大学 人工智能与数据科学学院,天津 300401)
1 引 言
文本情感分析是通过对文本的观点、情感或者极性进行挖掘的一种计算机技术,是对用户在互联网中发布的带有情感的文本进行整合和信息提取.相较于英文文本,中文文本因其句式、语法和分词等方面更加复杂而分析更加困难,成为了研究者们进行情感分析的焦点.
现阶段的中文文本情感分析技术大体分为两种方法:基于规则的文本情感分析和基于机器学习的文本情感分析.基于规则的文本情感分析方法在处理跨领域文本时,其情感分析结果未达到应有效果;基于机器学习的文本情感分析方法包括传统机器学习算法和深度学习算法,其训练结果依赖于训练集的设置,并且单一的传统机器学习方法在处理不同文本时各有利弊.由于单一机器学习方法并不能满足研究者们对文本情感分析的准确度要求,便将集成机器学习方法应用在该领域.
常见的集成学习方法有:Boosting、Bagging和Stacking等.其中Stacking算法集成了多个传统机器学习算法,融合其各自优点,具有泛化能力强、比任何一种单一的机器学习效果好等优点.然而随着人工智能的发展,可供Stacking集成的算法越来越多,而Stacking算法并不是随着集成的分类器数量越多效果越好,对于文本情感分类领域,如何选择集成的分类器种类也是一个有待解决的问题.
为了解决上述问题,本文拟实现一种基于融合改进Stacking与规则的文本情感分析方法:
1)建立基于文本规则的方法模型,计算文本情感倾向值,从而得到类标签.
2)在传统Stacking集成算法的基础上进行改进.改进基学习器与元学习器的输入用以提高分类器的准确度.
3)将基于文本规则的情感分析方法与Stacking算法融合,得到新的文本情感分类模型Stacking-I.
4)对比本文方法各种配置的分类情况,得出对于评论文本情感分析的最佳Stacking-I配置.
为验证该方法的效果,研究将在不同的网络评论文本上进行实验.
2 相关工作
文本情感分析的主要工作就是提取文本中的特征,并利用该文本特征来分析文本的情感.
基于文本规则的情感分析方法在文本情感分析领域发挥着重要的作用.该方法需要首先通过对文本集的分析建立情感词典,再将文本中的词语与情感词典中的词语进行对照获得词语极性,根据中文文本规则等建立计算整体文本情感倾向值的数学模型,最终获得该文本的情感极性.朱建平等人[1]根据文本中正向词和负向词的数量来决定文本的情感词的极性;肖江等人[2]将情感词、否定词、程度副词、缩写词和表情符号赋予权值,并用加权求和的方式来计算文本情感倾向值,得到文本的情感极性.基于文本规则的情感分析方法过于依赖情感词典,对未登录词的情感倾向分析有较大的偏差,因此在跨领域情感分析中效果不理想.
基于机器学习的情感分析方法通过提取可能影响文本情感分析的特征值,利用监督学习的方法,采用传统机器学习或深度学习算法,将文本进行情感分类,最终得到情感分析结果.2002年Pang等人[3]初次将机器学习应用在情感分类问题上;Kouloumis等人[4]将表情和缩写加入情感分析的特征当中;李明等人[5]提出了一种基于SVM结合PMI的细粒度商品评论情感分析方法.深度学习也同样被应用在文本情感分析当中:谭旭等人[6]通过构造中文文本词向量解析模型和RAE深度学习模型来实现文本信息的高层特征提取和情感分类;周锦峰等人[7]提出一种多窗口多池化层的卷积神经网络模型.传统机器学习方法对于不同的文本分析各有优缺点,且其得到的情感分析效果不能达到预期,因此研究者们提出了融合多种机器学习的方法.高欢等人[8]结合情感词典构造文本特征,利用逻辑回归、Light GBM等机器学习方法进行在线评论情感分类;Liu P等人[9]将条件随机场与最大熵模型相结合进行情感分析;黄伟等人[10]利用了一种基于多个分类器投票集成的半监督方法进行情感分类;李寿山等人[11]采用一种基于Stacking集成分类方法来进行中文文本情感分析研究.基于机器学习的方法过于依赖训练集的设定,其缺少对上下文的分析,且对于特征的选取和拓展不够灵活,而深度学习适合处理大量数据,对于处理网络评论这种的数据量较少的数据集表现不能达到预期.
Stacking集成算法是指用一个模型来组合其他各个模型,具有很强的泛化能力,可以综合各个传统机器学习的优点,且对时间、空间复杂度的影响较少.而基于学习器和元学习器的算法选择即Stacking算法的配置则也是研究者们的一个重要课题.Kai等人[12]实证表明多响应线性回归MLR作为元学习器可以很好的学习效果;GzVeroski等人[13]的研究中用多响应模型树代替多响应线性回归来提高分类性能;Webb等人[14]则将AdaBoost算法作为Stacking的基分类器.其他研究者基于Stacking也做了相应的研究[15-18].然而对于不同的领域,最优的Stacking配置并不相同,因而需要对文本情感分析领域的最优Stacking配置进行探索.
本文针对于上述所提两种方法的优缺点,提出了一种融合改进Stacking与规则的中文文本情感分析方法,该方法不仅利用了基于文本规则方法的灵活性和对上下文的考量等优点,还利用了Stacking算法的泛化能力和集合多种单一的机器学习算法优点等优势以提高对网络评论文本的情感分析准确率.
3 算法基本实现
图1为本文提出的基于融合改进Stacking与规则的中文文本情感分析框架图,该模型分为以下4个部分:
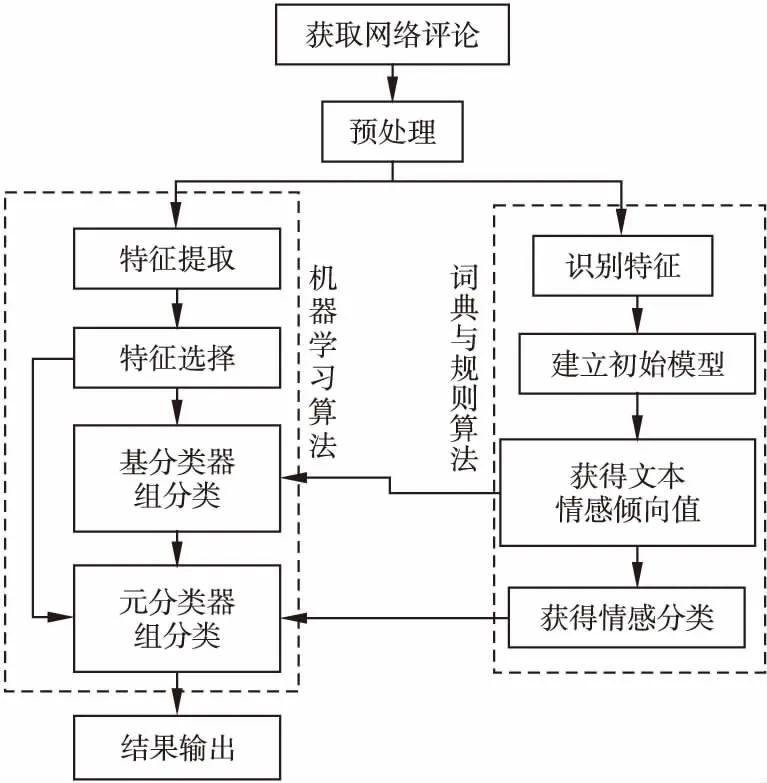
图1 融合改进Stacking与规则的方法总框架Fig.1 Framework of the model based on the integration of improved Stacking and text rule
1)网络评论文本预处理.该部分的主要任务就是将从网络中爬取的评论文本进行分词以及去停用词等预处理,使得文本可以更好的在所提出的模型中进行处理分类.
2)基于文本规则的情感分析.该部分的主要内容为构建情感词典,利用情感词典将文本中的特征与之对照,根据所建立的情感分析模型计算评论文本情感倾向值,并根据文本情感倾向值进行文本情感分类.该部分所得到的文本情感倾向值与分类结果放入改进的Stacking算法中辅助该算法进行最终的情感分类.
3)基于改进Stacking的情感分析.该部分利用文本中提取并选择的特征将原有的Stacking算法改进,利用Stacking算法的泛化优点来对网络评论文本进行情感分析
4)将两种方法融合得到最终的文本情感倾向.将基于文本规则的方法的分析结果放入基于改进Stacking的方法中,从而得到文本情感分析的结果.
下文将从以上4个部分进行深入介绍.
3.1 预处理
通常文本预处理包括去重、降噪、分词和去停用词等过程.对于网络评论文本,其中的#话题#、@用户和URL等不包含用户的情感信息,应在分词前将其去掉.由于网络评论文本有不规范等特征,文本集中可能出现乱码、错字以及重复文本等情况,应将文本进行规范和筛选.本文使用的分词系统为Jieba分词系统,将文本进行分词后,再通过自建停用词表,将文本进行去停用词处理.
3.2 基于文本规则的情感分析
基于文本规则的情感分析方法首先建立针对文本集的词典,该词典包括情感词典、否定词典、程度副词词典等一系列可以影响情感分析的词典.再将文本中的词与词典中的词进行对照,获取其权值.通过词语权重值以及语句规则来建立情感分析模型,并利用模型对每个文本进行情感分析.下面我们将从基于文本规则的两个重要部分进行介绍.
3.2.1 构建词典
由于不同的词语对文本的情感倾向影响程度不同,本文采用投票制,通过采纳100名志愿者对词汇的理解,构建了情感词典、否定词典、程度副词典、词组词典、连词词典、标点表六个词典,并给词典中的每个词汇赋予权值,下面对每一个词典的具体内容进行详细介绍.
1)情感词典
本文的情感词典分为两个部分,一个是正向情感词典,另一个是负向情感词典.而构建的情感词典包括:HowNet中文情感词典、网络情感词典以及通过分析语料自建的领域情感词典.其中网络情感词典通过百度搜索引擎的网络新词中获取,经过去重和权值赋予等过程构建出如表1和表2所示的情感词典,其中包含负向情感词汇4450个,和正向情感词汇4554个.

表1 部分正向情感词Table 1 Part of the positive emotion words

表2 部分负向情感词Table 2 Part of the negative emotion words
2)否定词典
句子中否定词的出现可以改变句子的情感极性,因此分清句子情感极性倾向,则要将句子中的否定词考虑在内,因此我们收集了一些可以影响句子极性的否定词并构造如表3中的否定词典,本文将用到24个否定词.

表3 部分否定词Table 3 Part of the denial
3)程度副词典
程度副词修饰情感词,并对文本情感极性有所影响,其影响有时是增强有时是减弱,而每个词汇对文本的情感增强或减弱的程度不同,因此本文将根据每个程度副词对情感极性的影响,赋予了对应的权重.本文将用到98个程度副词,表4列出了部分程度副词.

表4 部分程度副词Table 4 Part of the adverb
4)词组词典
由于行文的复杂性,中文文本存在很多不包含情感词却依旧含有情感极性的词组,我们通过总结语料,得到了正向以及负向词组词典,将该词组赋予权值,其中正数为正向,负数为负向,得到了本文所需要的词组词典.该词典中包括37个词组,表5列出部分词组及其权值.

表5 部分词组Table 5 Part of the phrases
5)连词词典
中文文本中经常为了语义的连贯性而出现连词,一部分的连词同样可以突显出该文本中所跟分句的情感极性,因此文本建立连词词典,并为其赋权.表6列出了部分连词及其权重.

表6 部分连词Table 6 Part of the conjunction
6)标点表
除以上词表可以影响文本情感极性外,文本中出现的表情符号有时也会影响文本的情感分析结果,例如“??”等符号通常代表文本对某件事情的消极态度的增强.因此文本中还根据标点规定了各个标点的权值用以情感分析.部分符号以及对应权值如表7所示.

表7 部分标点符号Table 7 Part of the punctuation
3.2.2 建立方法模型
基于文本规则的方法主要是要建立方法模型用于计算该文本的情感倾向值,通过计算得到的文本倾向值来确定该文本的情感极性.
本文首先将微博的评论文本,通过标点符号进行分句,并对单个分句进行情感分析.而分句中又存在影响该分句情感倾向的词组,该词组一般是由情感词、程度副词和否定词组成,因此将分句中的词语与情感词典中的词语进行比较,获得其相对应的权值,每一个情感词作为该分句中的一个情感词组.计算该情感词组的情感倾向值SW如式(1)所示:
SW=WvWdS
(1)
其中SW为该情感词组的情感倾向值,Wv为初始为1的情感词前后3个窗口出现的程度副词的权重,Wd为情感词前后3个窗口出现的否定词的权重,其初始为1,S为该情感词的权值.
分句中除情感词组会影响该分句的情感倾向值外,其中的连词、标点以及某些动词名词词组也会影响情感倾向值,于是计算该分句的情感倾向Ss如式(2)所示:
SS=WpWc(∑Swi+Wph)
(2)
其中Wp为该分句中出现标点的权重,Wc为该分句中出现连词的权重,Swi为该分句中第i个情感词组的情感倾向值,Wph该分句中出现动名词词组的权重.
除以上情况外,分句的位置也会对评论文本的情感倾向产生影响,其中首句和尾句的情感倾向对整个评论文本的倾向影响较大,因此分句的情感倾向值可再通过式(3)进行处理,得到加权的第i个分句情感倾向值Si:
Si=WdSsi
(3)
其中Wd为句子权重,当该分句为首句或尾句时,其值为2;当该句在其他位置时,其值为1.而Ssi则为之前计算的该分句的情感倾向值.
根据以上的计算,整个评论文本的情感倾向值如式(4)所示:
(4)
其中Score为该评论文本的情感倾向值,Si为第i个分句的情感倾向值,n为整个评论的分句数.
根据情感倾向值的计算,本文通过对情感倾向值的分析,可以确定该评论文本的情感极性,如式(5)所示:

(5)
其中,当sentiment为0时,该评论的情感为负向的,反之,评论的情感为正向的.
3.3 基于改进Stacking算法
3.3.1 Stacking集成算法
集成算法的基本思想就是集成分类器.Stacking算法的集成方式为:集成不同基分类器,再将基分类器的输出作为第2层元分类器的输入进行再次分类.该分类方法可以中和传统机器学习方法的优缺,其分类结果比其集成的任意单一分类器的分类结果都要好,因此本文考虑在Stacking集成分类方法的基础上进行改良,从而有效对网络评论文本进行情感分析.
传统的Stacking集成方法中,将基分类器分类后的类标签,即本文中的情感正向和负向作为元分类器的输入.Wolpert[19]研究表明新数据的属性表示对Stacking集成的泛化性能影响很大,因此本文将类标签用类概率替代.类概率不仅仅包含了基分类器的预测结果,还包含了基分类器的置信程度和各个基分类器之间的差异性等信息,因此使其分类结果更能结合基分类器的优缺点,提高泛化能力.传统Stacking算法框架如图2所示.
图2中ti为n个文本中每个网络评论文本经过向量化处理后的表示,m为基分类器的个数,fm为基分类器对应的机器学习算法,且其互不相同,ti′为文本经过基分类器分类后所得的分类概率向量,其中Pij+为第i个评论文本通过第j个基分类器分类后结果为正向的概率,Pij-为第i个评论文本通过第j个基分类器分类后结果为负向的概率,F则为元分类器的机器学习算法.

图2 Stacking集成算法Fig.2 Stacking integration algorithm
3.3.2 改进Stacking集成算法
然而只在元分类器层输入基分类器的分类类概率,效果虽有提高但并不能满足本文要求的准确率,其原因为分类后的类概率所携带的原始数据信息不足,导致元分类器的分类结果不理想.因此本文将元分类器的输入进行改进,输入向量在类概率的基础上添加原始数据经过特征提取等工作所得的特征向量以提高整个集成分类器的分类准确率,具体结构如图3所示.本文使用CBOW实现词语向量化,并通过χ检验进行特征提取.其中xiq为n个评论文本内第i个评论文本进行向量化后的第q个特征值.
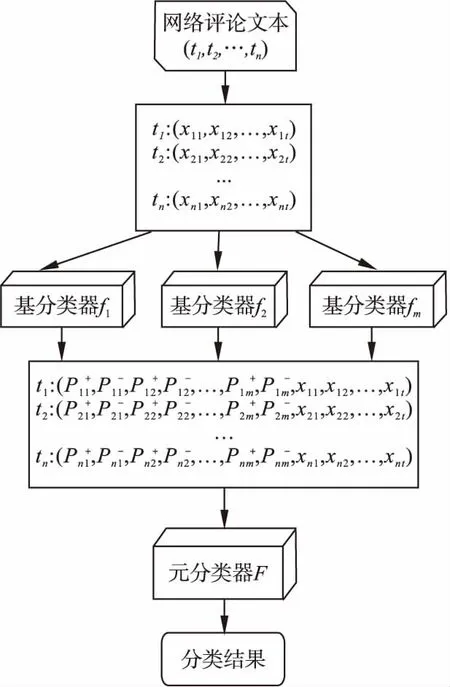
图3 改进Stacking算法Fig.3 Improved Stacking algorithm
此外,传统的Stacking算法对于基分类器与元分类器算法的选择只局限于传统机器学习方法.随着机器学习的发展,更多的集成机器学习算法出现,其分类是性能比传统的机器学习好.已知Stacking算法的准确率一定比其集成的机器学习方法准确率高,因此本文将其他集成算法以及深度学习学习算法加入基分类器与元分类器算法的选择中,进而提高其分类准确率.
3.4 融合集成与情感词典
前文已经提到,文本规则法和机器学习法各有优缺,本文将结合两种方法,中和两种方法的优缺,得到一个新的文本情感分析模型.该模型将基于文本规则方法的输出,作为改进Stacking算法的输入,该输入不仅仅局限于类标签,还包括文本情感倾向值,其输入不仅作为基分类器的一部分,还将影响元分类器.
研究者们在之前的研究中,已经将基于文本规则的方法与基于机器学习的方法进行了简单的融合,即已经出现将基于文本规则方法分析所得的情感倾向值作为传统机器学习输入特征的一部分,以此来弥补传统机器学习方法未考虑上下文关系的缺陷,提高文本情感分析的准确率.与之不同的是,本文将基于文本规则方法所得文本倾向值进行归一化处理后再放入分类器中,以此来统一输入向量中的特征量,其具体的归一化处理如式(6)所示:
score′=(score-s.min)/(s.max-s.min)
(6)
其中,score为该文本计算所得的情感倾向值,s.min为最小情感倾向值,s.max为最大情感倾向值.
此外,Stacking集成算法的基本思想就是融合各种分类方法,并将这些分类方法所得结果放入第2层分类器中,以此来解决各分类方法优缺不一的情况.
对于文本情感分析,分类方法则不局限于各种机器学习方法,还包括文本规则情感分析法,因此本文将基于文本规则的情感分析方法也作为Stacking集成算法中的一个基分类器,将基于文本规则的情感分析方法所得的类标签作为元分类器输入的一部分进行再次分类.具体本文模型如图4所示,其中Scorei为基于文本规则方法所得的归一化后的文本情感倾向值,sentimenti为该方法最后得到的类标签.
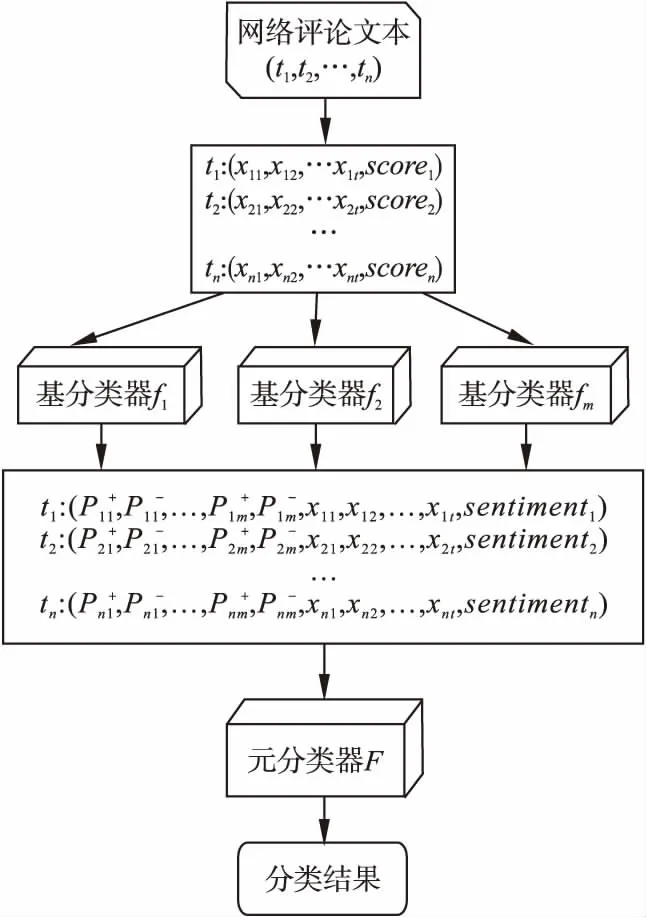
图4 融合两种方法框架Fig.4 Framework for merging the two approaches
4 实 验
该节将分析本文提出的算法Stacking-I在具体的网络文本评论情感分析中的表现.
4.1 实验设置
本文将从网络上爬取某外卖app评论,通过去重降噪等处理,人工标注得到内有2500、4000、5000条数据的3组数据集,其中正负向评论比为1∶1.在研究者们的研究中表明Stacking集成算法中,训练集与测试集的比例为4∶1时的效果最好.因此本文在2000条数据集A中设置2000条作为训练集,500条作为测试集;在4000条数据集B中设置3200条作为训练集,800条作为测试集;在5000条数据集C中设置4000条作为训练集,1000条作为测试集.其中每个训练集与测试集正负向数据分布平均.
本次实验结果使用准确率作为评估值,且通过Python语言实现,部分传统机器学习方法应用Scikit-learn框架实现,深度学习方法应用keras框架实现.
4.2 实验验证
4.2.1 对比实验
实验结果如表8所示.本文将基于融合改进Stacking与规则的文本情感分析方法(Stacking-I)与传统机器学习、其他集成算法以及深度学习算法进行比较,意在证实本文提出的算法模型stacking-I可以有效提高文本情感分类的准确率.

表8 与各类方法的比较Table 8 Comparison with traditional machine learning methods
表8中TCNN中有3个中间层,每个中间层有16个人隐藏单元;Stacking-I(A)的配置为:AdaBoost、RandomForest、Bagging和GradientBoosting作为基分类器,Logistic作为元分类器;Stacking-I(B)的配置为:RandomForest、ExtraTree、KNN和TCNN为基分类器,Logistic作为元分类器.由实验数据可以看出,本文提出的基于融合改进Stacking与规则的中文文本情感分析方法(Stacking-I)比传统机器学习模型对该数据集的情感分析准确率有明显提高,对比其他的集成算法及深度学习算法,Stacking-I也有很大的提高.
针对文本数据集A,传统机器学习算法中,准确率最高可以到89.4%,而Stacking-I(A)所得分类准确率比其高1%;Stacking-I(A)与传统Stacking算法相比提高了1%;在其他集成算法中准确率最高为88.8%,Stacking-I(A)比其高1.6%;与深度学习TCNN相比,Stacking-I比其高3.6%.
对于数据B,传统机器学习算法中,准确率最高可以到85.125%,而Stacking-I(A)和Stacking-I(B)比该算法所得分类准确率提高2.2%和2.7%;Stacking-I(A)和Stacking-I(B)与传统Stacking算法相比提高了3.6%和4.1%;在其他集成算法中,AdaBoost算法的准确率最高为85.75%,Stacking-I(A)和Stacking-I(B)分别比其高1.5%和2.0%;与深度学习TCNN相比,Stacking-I(A)和Stacking-I(B)分别比其高0.8%和1.3%.
对于数据C,传统机器学习算法中,准确率最高可以到87.6%,而Stacking-I(A)和Stacking-I(B)比该算法所得分类准确率高3.7%和3.9%;Stacking-I(A)和Stacking-I(B)与传统Stacking算法相比分别提高了2%和2.2%;在其他集成算法中,AdaBoost准确率最高为85.8%,Stacking-I(A)和Stacking-I(B)分别比其高5.5%和5.7%;与深度学习TCNN相比,Stacking-I(A)和Stacking-I(B)分别比其高2.3%和2.5%.
通过对比可以看出,融合改进Stacking与规则的中文文本情感分析方法(Stacking-I)有更好的性能,且比传统机器学习方法、其他集成算法和深度学习方法的准确率都要高,有效提高了文本情感分析的准确率.
4.2.2 获取最优配置
本部分将从Stacking算法的配置讨论,通过对时间复杂度与准确率两方面进行考虑,选出最适合本文数据集的一组Stacking配置.
1)元分类器
研究者们对于Stacking算法配置的研究中,线性分类器作为元分类器时,准确率较高,本文固定基分类器,将Logistic、TCNN、BiLSTM作为元分类器在3组数据上实验,其中BiLSTM为双向单层LSTM,得到实验结果如表9所示.可以看出,当Logistic作为元分类器时的文本情感分类效果最优.
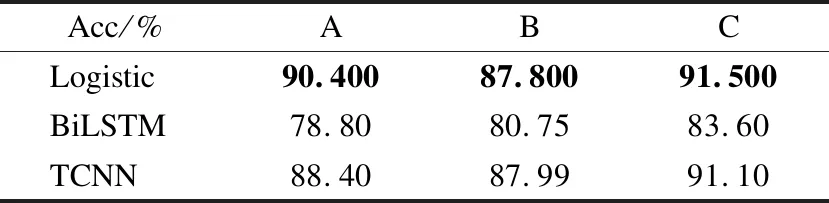
表9 不同元分类器对比Table 9 Comparison with different meta-classifiers
2)基分类器
对于基分类器的选择,本文将从两个方面进行探究.
对于基分类器的数量问题,若分类器的数量过多会导致算法的时间复杂度过大.因此本文通过控制基分类器数量在数据集C上进行全排列组合实验,获得了图5,从而分析得到最优的分类器数量.由图可见,基分类器数量为4时效果最优.
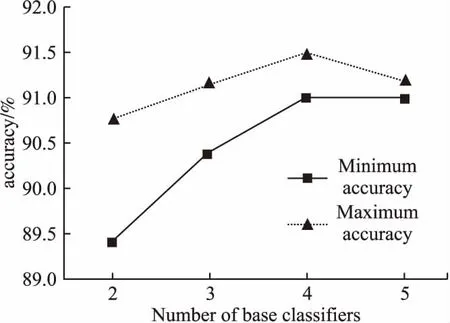
图5 基分类器个数与分类准确率的关系Fig.5 Relationship between the number of base classifiers and classification accuracy
对于基分类器选择的问题,本文经过大量的实验对比,将基分类器的组成分为3组:基分类器只包含传统机器学习方法和集成方法,基分类器包含一种深度学习方法以及基分类器包含两种深度学习方法.最终在3大组中实验得到了3种准确率组内最高Stacking-I基分类器配置,分别为AdaBoost、RandomForest、Bagging和GradientBoosting的组合(Stacking-I(A)),RandomForest、ExtraTree、KNN和TCNN的组合(Stacking-I(B))以及RandomForest、ExtraTree、BILSTM和TCNN的组合(Stacking-I(C)),其具体文本情感分类准确率如表10所示.
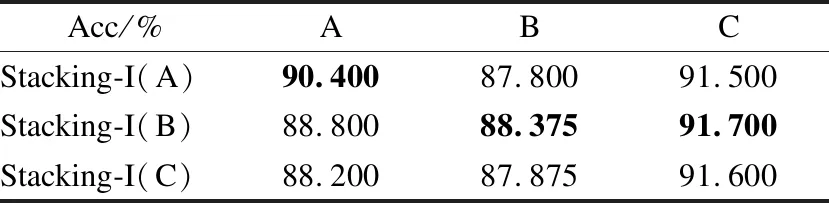
表10 不同基分类器对比Table 10 Comparison with different base-classifiers
对于数据量少的数据集,Stacking-I(A)的配置在文本分类时表现更好,而当数据量变大时,Stacking-I(B)的配置在文本分类时表现更好.Stacking-I(C)的表现与Stacking-I(B)的相差不多,但因为集成了两个深度学习算法,其时间复杂度相较于Stacking-I(B)更大.因此在数据量小时,Stacking-I(A)的配置,即AdaBoost、RandomForest、Bagging和GradientBoosting作为基分类器的效果更好;而当数据量大时,Stacking-I(B)的配置,即RandomForest、ExtraTree、KNN和TCNN作为基分类器的效果更好.
4.2.3 分析算法时间复杂度
该部分将从算法的时间复杂度上进行分析,将本文所提算法Stacking-I的两种不同配置与其他机器学习算法、深度学习算法TCNN在数据集C上的运行时间对比,其结果如表11所示.

表11 算法运行时间对比Table 11 Comparison of algorithm′s running time
通过对比可知,本文所提出的Stacking-I(A)和Stacking-I(A)的时间复杂度比传统机器学习算法、集成算法要高,且Stacking-I(A)其比运行时间最长的GrandiantBoost算法运行时间增加了60%.而Stacking-I(A)与深度学习TCNN相比,其运行时间更短,运行时间缩短了55.7%.Stacking-I(B)与深度学习TCNN相比,其运行增加了25%.
因此Stacking-I(A)的时间复杂度虽然与其他机器学习方法相比有所增加,但其复杂度远远低于深度学习TCNN算法的时间复杂度,且其分类准确率与其他算法相比表现更加优秀.而 Stacking-I(B)虽在时间复杂度上有所增加,但其分类准确率远远高于其他算法,因此本文认为Stacking-I算法在对时间复杂度影响较小的前提下,提高了文本情感分析的准确率.
以上实验证明了本文提出的融合改进Stacking与规则的文本情感分析方法Stacking-I相较于基于传统机器学习、集成学习以及深度学习的文本情感分析方法有着更高的分类准确率,最高可达91.70%.且通过大量实验,在不同数据量的情况下,本文得出了最佳的Stacking-I的配置.
5 总 结
本文提出了一种融合改进Stacking与规则的中文文本情感分析方法Stacking-I:
1)建立基于文本规则的方法模型,计算文本情感倾向值,从而得到类标签.
2)在Stacking集成算法的基础上进行改进,改进元学习器的输入用以提高分类器的准确度.
3)将基于文本规则的情感分析方法与Stacking算法融合.
4)对比该模型各种配置的分类情况,得出针对不同数据量的最佳文本情感分析Stacking-I配置.
通过实验可知,相比于传统机器学习方法、其他集成算法以及深度学习方法,本文所提模型Stacking-I在情感分析在对时间复杂度影响不大的情况下,其准确率有了明显地提高,最高可达91.7%.并且本文确定了当,Logistic作为元分类器时效果最佳,而对于基分类器的选择,当数据量小时其配置为:AdaBoost、RandomForest、Bagging和GradientBoosting作为基分类器效果最佳,当数据量相对较大时,RandomForest、ExtraTree、KNN和TCNN作为基分类器的效果最好.
Stacking-I算法弥补了基于文本规则和基于机器学习方法的文本情感分析的不足,融合了两方法的优点,并在对时间复杂度影响不大的情况下,提高了文本情感分析的泛化能力和准确率.
