基于长短期记忆网络的装配工艺语义识别方法
2021-06-29陈治宇鲍劲松郑小虎丁司懿刘天元
陈治宇,鲍劲松,郑小虎,丁司懿,刘天元
(东华大学 机械工程学院,上海 201620)
0 引言
目前,航空发动机装配车间的工艺文档管理主要为产品数据管理(Product Data Management, PDM)系统[1]中的电子化管理,管理水平较低。在评估工艺可执行性和指导装配作业时,依赖人工识别的方式使用电子工艺文档中的工艺语义信息,效率低下,难以适应单件、小批量生产模式下对企业装配效率与应变能力的要求。因此,考虑抽取装配工艺文档语义要素,建立装配工艺语义信息的知识化描述,以提高装配工艺信息在评估装配工艺可执行性与指导装配作业时的使用效率。该过程主要存在两个难点:①装配工艺文档无标准或规范约束,以自然文本存在,具有非结构化特点,难以从中提取装配语义要素;②装配语义信息通常由多种装配关系复合而成,结构复杂,难以用一种固定的模式组织,无法形成知识化描述便于使用。
关于装配语义要素的提取,属于工艺信息提取的一种。目前工艺信息提取的研究主要集中在CAD模型的几何与非几何信息提取[2-3],以及对电子工艺文件的浏览和读取[4-5]。例如,Pushkar Vyas[3]等基于CAD/CAM组件,实现从STEP文件提取工艺信息;赵浩然[4]等提出一种数字孪生车间的三维可视化实时监控方法,在车间实时数据管理中对电子工艺文件进行可视化。本文的工艺信息提取旨在通过自然语言处理(Natural Language Processing,NLP)自动从装配工艺文档获取装配语义,并建立装配工艺知识化描述。NLP从统计或计算的角度对自然语言进行理解,基本算法包括基于统计学习和基于深度学习两类[6]。基于统计学习算法有条件随机场(Conditional Random Field, CRF)[7]、隐马尔科夫模型(Hidden Markov Model, HMM)[8]等,它们的训练在非常高维、稀疏、依赖手写的特征上进行,耗费时间且不完整;基于深度学习算法有循环神经网络(Recurrent Neural Network, RNN)[9]、长短期记忆网络(Long Short Term Memory, LSTM)[10]、卷积神经网络(Convolutional Neural Network, CNN)[11]等,它们不依赖手写特征且泛化能力更强。NLP可处理分词、词性标注、实体识别、文本聚类等任务。例如,LIU等[12]提出一种融合神经网络与字典信息的中文分词方法,用于训练数据不足时的分词任务;ZHANG等[13]提出一种Seq2Seq神经模型,同时用于中文分词与词性标注;ZHAO等[14]基于双向长短期记忆网络(Bi-Long Short Term Memory, Bi-LSTM)与CNN提出一种联合解码算法用于实体识别;杨开平[15]基于词语相似度和文本长度构造文本间相似度,并用于文本聚类。
而对于装配语义信息的知识化描述,本质为装配工艺信息建模,建模方法可分为面向对象建模[16-18]、基于可扩展标记语言(eXtensible Markup Language, XML)建模[19-21]、基于Petri网建模[22-24]和基于本体论建模[25-27]。面向对象模型[16-18]具有抽象、稳定、可重用的特点,但缺乏结构化的描述机制,不能满足异构系统间的互操作要求。基于XML建模[19-21]可解决异构系统间的互操作问题,但只是对工艺文档的结构进行定义,不利于表达工艺中的语义关系。基于Petri网[22-24]的装配信息模型,实质为面向对象建模,具有与面向对象模型类似的缺点。本体思想[25-27]有利于装配工艺的语义表达与定性描述,且本体语言(Ontology Web Language, OWL)有利于本体模型的表达及信息在异构系统间的交互,但其作为数据模型仅对装配工艺信息进行抽象,并不算知识化的描述形式。而知识图谱将信息以“实体—关系—实体”、“实体—属性—值”的方式组织起来,是一种结构化的语义知识库[28]。例如,DUBEY等[29]基于知识图谱将问答场景抽象为“实体—关系—实体”模型;ZHOU等[30]提出一种基于常识知识图谱的对话模型,用于理解对话中的语义信息。
综上所述,本文装配工艺语义识别的具体对象为装配工艺过程卡或装配工序卡,它们具有形式规则、描述非结构化的特点。装配工艺过程卡或装配工序卡均为表格形式,使得信息间的宏观语义可通过统计方法获取,如工序组成、工步顺序等;而装配工艺过程卡或装配工序卡内部以自然语言描述装配工艺,具有非结构化的特点,故结合NLP方法来获取微观语义,例如操作对象、工序动作等。在语义识别的基础上形成装配语义的知识化描述,首先基于本体论定义装配语义数据模型,然后设计知识图谱的描述形式,最后得到某对象的装配工艺知识图谱。
1 装配语义定义与描述
1.1 装配语义定义
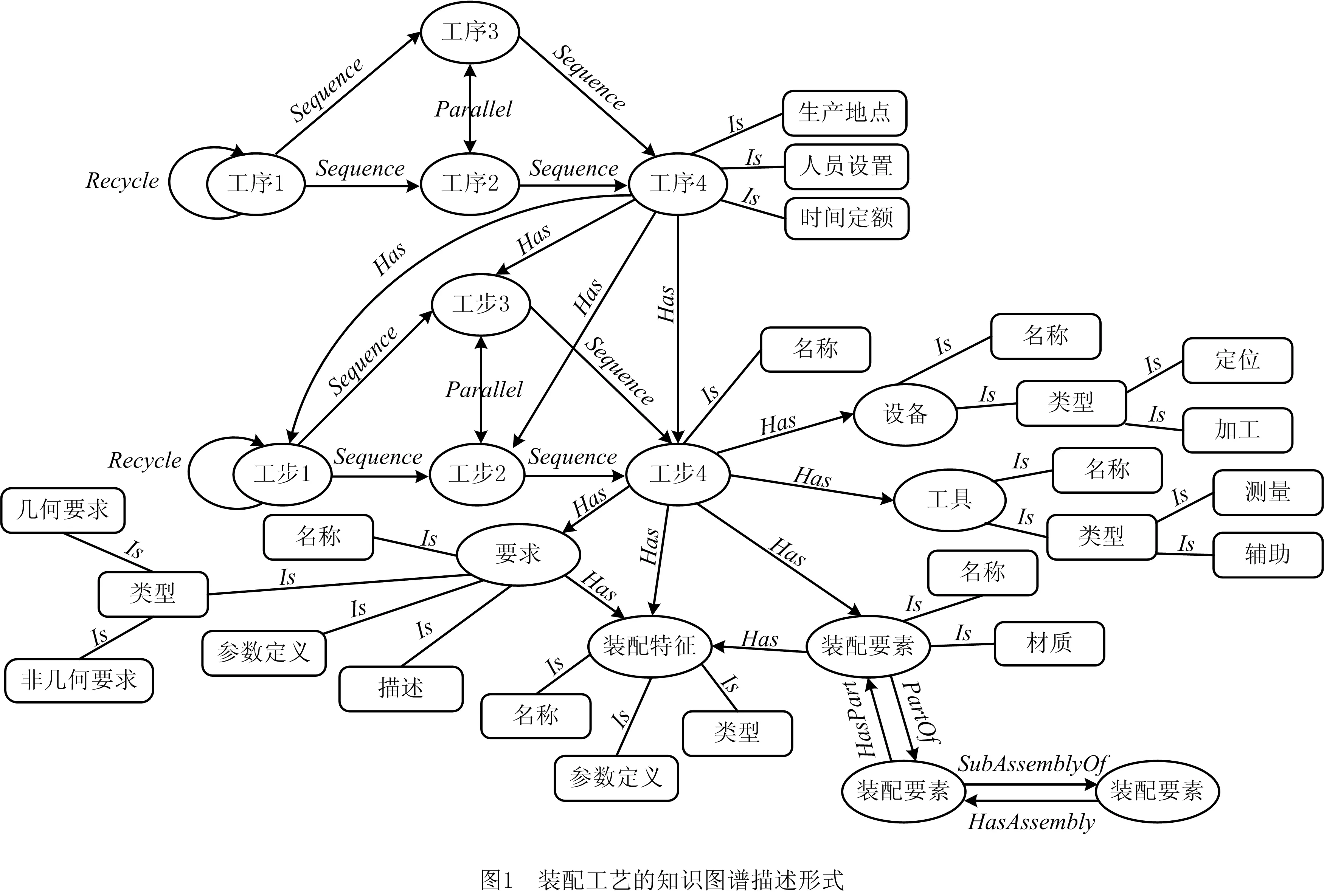
装配工艺文档描述了装配工序与装配工步的作业过程和工艺要求,包含装配要素(E)信息、装配特征(F)信息、工具(T)信息、设备(D)信息、要求(R)信息和操作(O)信息,将装配语义(S)定义为操作(O,包括装配工序、装配工步)与装配要素(E)、装配特征(F)、工具(T)、设备(D)、要求(R)之间的结构关系以及操作(O,包括装配工序、装配工步)之间的序列关系,如式(1)所示。其中,结构关系包括Has、HasPart、PartOf、HasAssembly、SubAssemblyOf,序列关系包括Sequence、Parallel、Recycle,各关系的详细说明如表1所示,以上语义关系相互组合可构成装配工艺复杂的语义信息。
(1)

表1 结构关系与序列关系说明表
1.2 装配语义描述方式
将装配工艺的装配工序、装配工步、装配要素、装配特征、工具、设备、要求抽象为实体,表1定义的结构关系与序列关系抽象为关系,以“实体—关系—实体”、“实体—属性—值”的方式组织装配工艺语义信息,建立装配工艺知识图谱,如图1所示。图中“Is”连接实体的属性,而“Has、HasPart、PartOf、HasAssembly、SubAssemblyOf、Sequence、Parallel、Recycle”为实体与实体间的关系,对每个实体的说明如下。
(1)装配要素实体 描述零件或子装配体,包括“名称”与“材质”属性,特征信息通过“Has”与装配特征实体建立结构关系。装配要素实体之间通过“HasPart”、“PartOf”、“HasAssembly”、“SubAssemblyOf”建立结构关系。
(2)装配特征实体 描述装配特征,包括“名称”、“类型”与“参数定义”属性,“类型”属性取值为装配特征或组合特征。
(3)工步实体 描述两装配要素间的装配操作,包括“名称”属性,设备信息、装配要素信息、装配特征信息、要求信息通过“Has”与设备实体、装配要素实体、装配特征实体、要求实体建立结构关系。工步实体之间通过“Sequence”、“Parallel”、“Recycle”建立序列关系。
(4)工序实体 描述一系列工步组成的装配操作,包括“生产地点”、“人员设置”、“时间定额”属性,工步信息、工具信息、设备信息通过“Has”与工步实体、工具实体、设备实体建立结构关系。
(5)要求实体 描述装配工艺的几何要求或非几何要求,包含“名称”、“类型”、“描述”与“参数定义”属性,“类型”属性取值为几何要求或非几何要求,特征信息通过“Has”与装配特征实体建立结构关系。
(6)设备实体 描述装配工艺所采用的工艺设备,包含“名称”、“类型”属性,“类型”属性取值为定位类型或加工类型。
(7)工具实体 描述装配工艺所采用的工具,包含“名称”、“类型”属性,“类型”属性取值为测量类型或辅助类型。
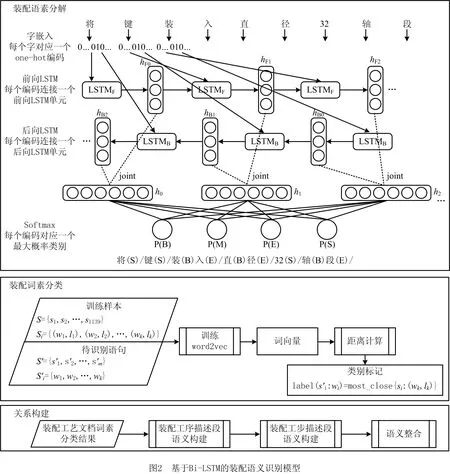
2 基于Bi-LSTM的装配语义识别模型
装配工艺包含的装配要素属性信息、装配特征信息来自于CAD系统,通过软件接口获取。本文的装配语义识别指从装配工艺文档中识别装配语义关系,然后与装配要素、装配特征建立联系,以形成装配工艺知识图谱。如图2所示为基于Bi-LSTM的装配语义识别模型,包括装配语素分解、装配词素分类与关系构建。装配语素分解将连续的装配工艺语句分解为非连续的词序列;装配词素分类对非连续词序列进行类别识别,从而判断出“工具设备名称”、“装配对象名称”、“装配动作词”、“装配特征词”、“装配序列语义词”、“装配结构语义词”与“量词”;关系构建将装配词素分类结果与装配要素属性信息、装配特征信息建立关联。
2.1 装配语素分解
装配语素分解的输入为连续的装配工艺语句,输出为非连续的词序列,通过字标注的方式实现。标注“S、B、M、E”标签,“S”表示单汉字词、“B”表示词的首汉字、“M”表示词的中间汉字、“E”表示词的末尾汉字。例如,输入装配工艺语句“将键装入直径32轴段”,输出结果为“将(S)/键(S)/装(B)入(E)/直(B)径(E)/32(S)/轴(B)段(E)”,详细流程如图2所示。首先,通过字嵌入将汉字转换为可计算的数字编码。具体过程为:将句子拆分成字的集合,然后根据字的出现频率由大到小编号,得到每个字的one-hot编码,该编码即为字嵌入结果。
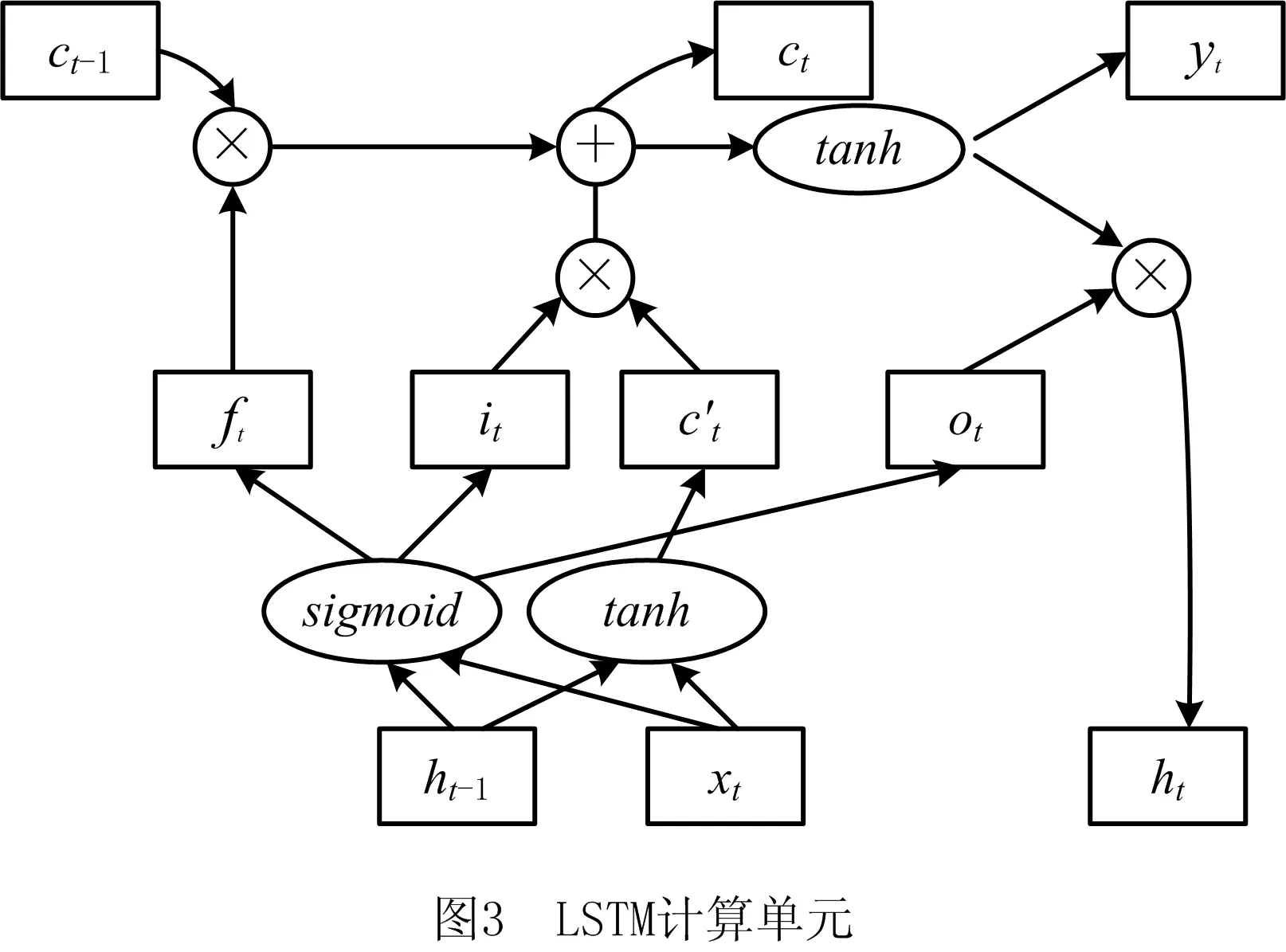
然后,将字嵌入结果输入Bi-LSTM。Bi-LSTM由前向LSTM与后向LSTM组成,基本组成单元为LSTM。如图3所示,ft为遗忘门、it为记忆门、
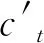
ft=σ(wf×[ht-1,xt]+bf);
(2)
it=σ(wi×[ht-1,xt]+bi);
(3)
(4)
(5)
ot=σ(wo×[ht-1,xt]+bo);
(6)
ht=ot×tanh(ct);
(7)
(8)
式中:y为期望输出,a为实际输出。
2.2 装配词素分类
装配词素分类用于对非连续词序列进行类别识别。如图2所示,首先使用word2vec[31]得到词向量,然后计算词向量间的空间距离得到词与词的相似度,将与待识别词距离最小的训练样本词的类别作为待识别词类别。在计算词向量间的空间距离时,需要考虑向量方向与绝对距离大小,因此将词向量间的空间距离定义为式(9)。
(9)
式中,w1、w2表示两个词向量,n为词向量维度,w1i表示第1个词的第i维,w2i表示第2个词的第i维。
2.3 关系构建
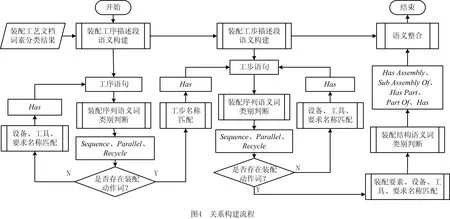
关系构建将装配工艺文档词素分类结果与装配要素属性信息、装配特征信息建立关联。如图4所示,包括装配工序描述段语义构建、装配工步描述段语义构建和语义整合。从工序语句开始扫描,判断装配序列语义词类别,建立装配工序之间的“Sequence”、“Parallel”或“Recycle”序列关系;然后进行装配动作词判断,当不存在装配动作词时,表明这不是一个配合工序,因此进行设备、工具、要求名称匹配,建立装配工序与设备、工具、要求之间的“Has”结构关系;然后扫描下一句工序语句,当存在装配动作词时,表明这是一个配合工序,与装配工艺文档中的工步名称匹配,建立装配工序与装配工步之间的“Has”结构关系并进入对应工步。扫描工步语句,判断工步语句中装配序列语义词类别,建立装配工步之间的“Sequence”、“Parallel”或“Recycle”序列关系;然后进行装配动作词判断,当不存在装配动作词时,表明这不是一个配合工步,因此进行设备、工具、要求名称匹配,建立装配工步与设备、工具、要求之间的“Has”结构关系;然后扫描下一句工步语句,当存在装配动作词时,表明这是一个配合工步,与装配要素、装配特征、设备、工具、要求名称匹配,然后进行装配结构语义词类别判断、确定它们之间的“Has”、“HasPart”、“PartOf”、“HasAssembly”、“SubAssemblyOf”结构关系。如此递归扫描所有装配工序语句与装配工步语句。
3 装配语义识别模型的训练
3.1 数据集说明
以某航发企业压气机机匣、静子部件、主轴传动部件的装配工艺文档为原始数据构造数据集。首先为每条装配工艺语句标注“S、B、M、E”字标签,得到装配语素分解数据集。例如,“按记号装上5根长拉紧螺栓和5根短拉紧螺栓”标注为“按/s记/b号/e装/b上/e5/s根/s长/b拉/m紧/m螺/m栓/e和/s5/s根/s短/b拉/m紧/m螺/m栓/e”。然后标注每个词的类别,包括“工具设备名称”、“装配对象名称”、“装配动作词”、“装配特征词”、“装配序列语义词”、“装配结构语义词”、“量词”,无类别词用字符‘x’占位,得到装配词素分类数据集。例如,“按记号装上5根长拉紧螺栓和5根短拉紧螺栓”标注为“按/装配动作词记号/装配特征词装上/装配动作词5/量词根/x长拉紧螺栓/装配对象名称和/装配结构语义词5/量词根/x短拉紧螺栓/装配对象名称”。数据集的说明如表2所示。
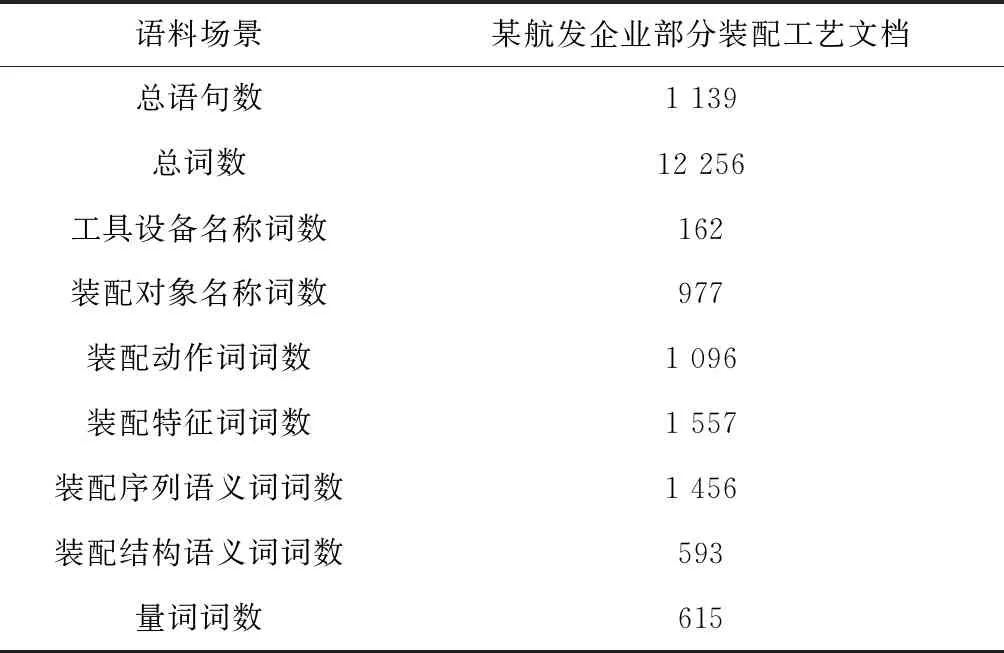
表2 数据集说明
3.2 装配语素分解模块训练
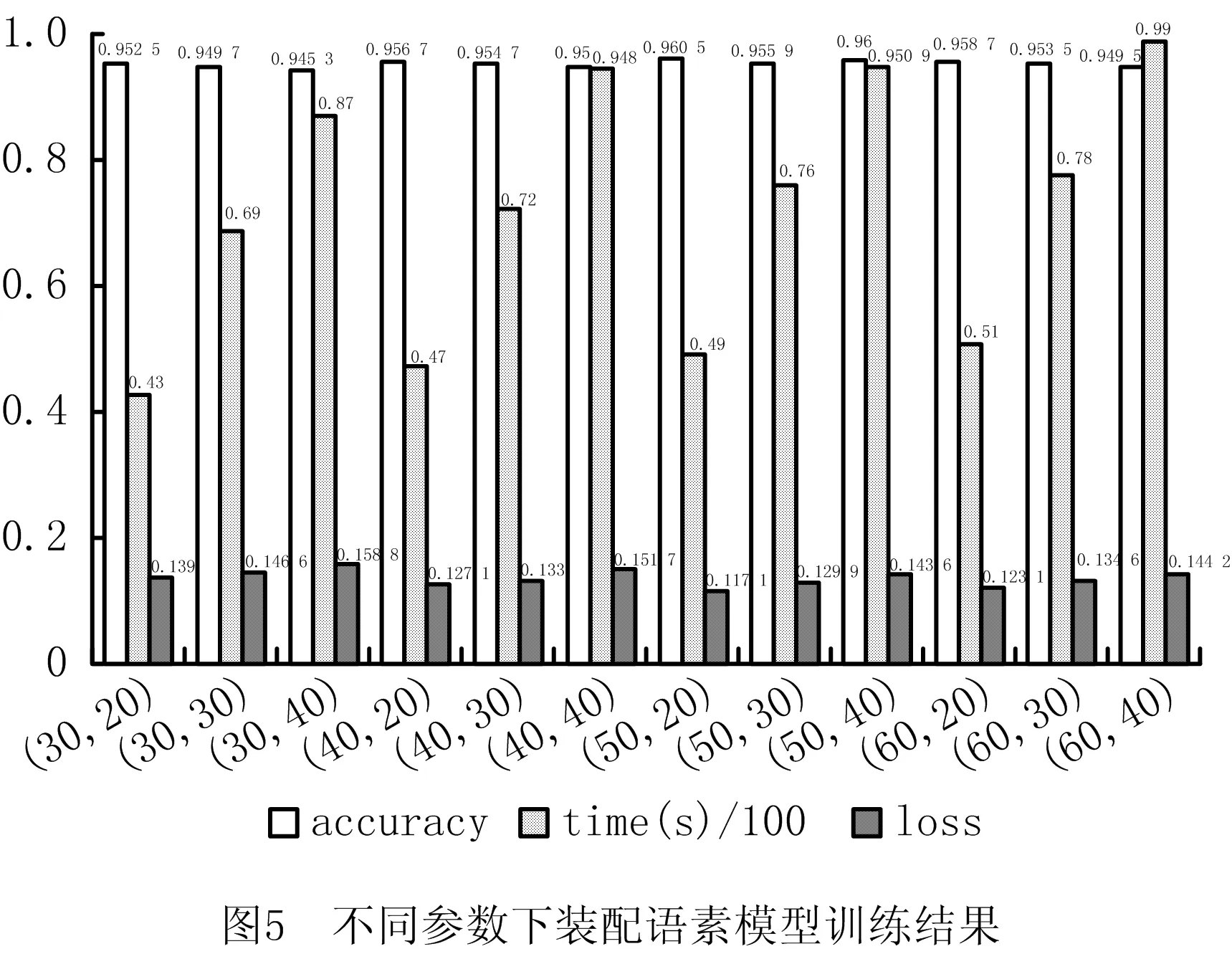
在不同字维数与句子长度下对装配语素分解模块进行训练。其中,字维数会影响模型的训练时间和性能,维数大,则训练时间长、适合数据量大的情况。根据数据集规模,试验字维数为30、40、50、60。句子长度会影响上下文的关联情况。数据集以15~40字的句子居多,试验句子长度为20、30、40。装配语素分解模块输入每个字对应的30、40、50或60维向量,句子长度为20、30或40,batch size选为句子长度的32倍。在CPU为Intel Xeon E5-2630、显卡NVIDIA GTX1080 8G的电脑上迭代训练20次得到各参数下的准确度(accuracy)、时长(time)和损失(loss),如图5所示。由图可知,字维数从30增加到50时,accuracy增加,time较稳定;字维数从50到60时,accuracy降低。故确定最佳字维数应位于50与60之间、且句子长度为20时accuracy表现较好。因此,将字维数50、句子长度20、batch size=20×32作为参数,迭代训练约100次至收敛,总耗时约81 min。
将该语素分解模块与经典的CRF++分词模型[32]和LSTM分词模型[33]比较,均使用本文构造的训练数据集,考查常用的精确率P、召回率R和F值,得到如图6所示的模型训练loss曲线。表3为3种分词模型的评测指标,可得出基于Bi-LSTM的装配语素分解模块相较于其他方法loss最低,且P、R、F值更优。
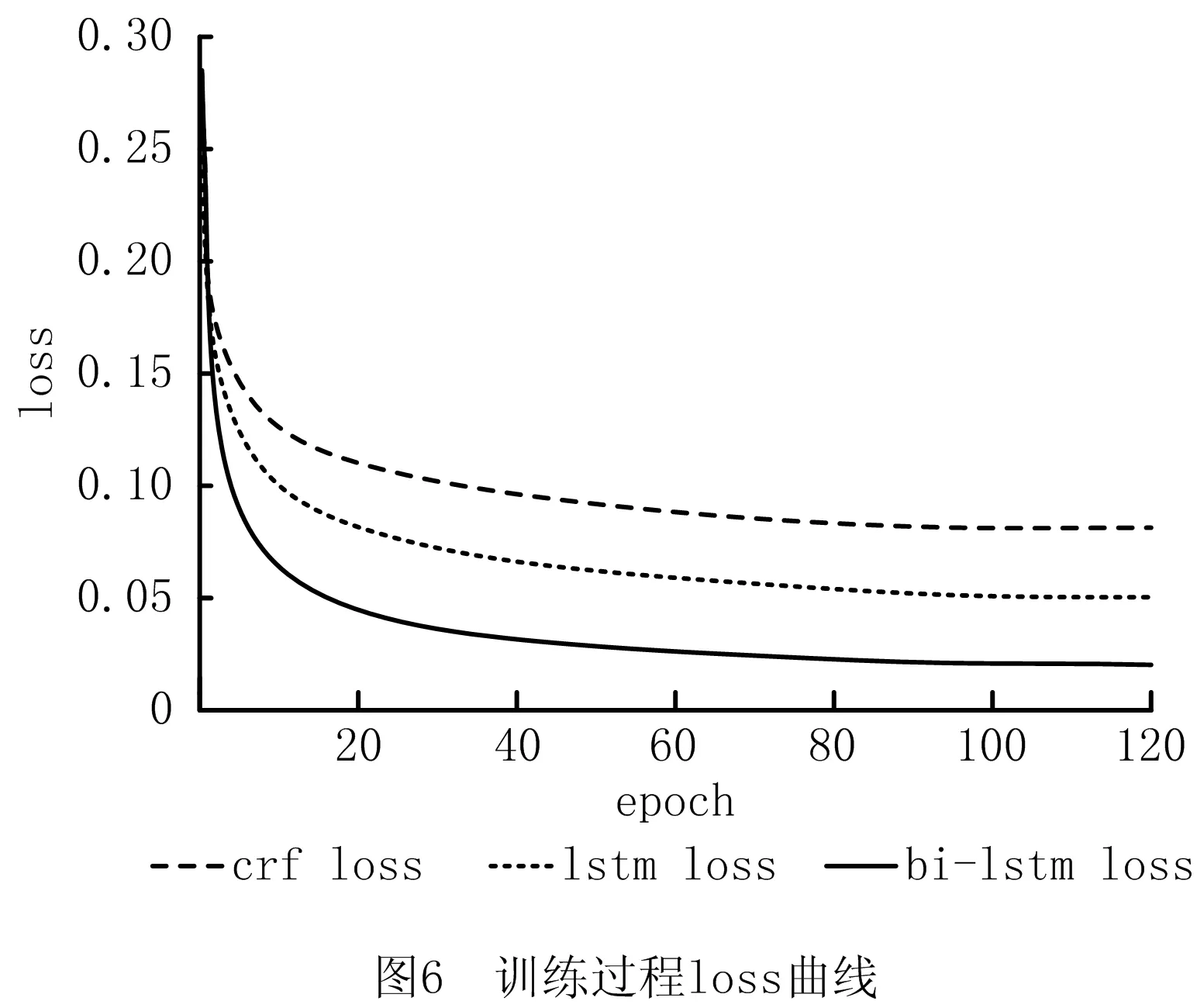
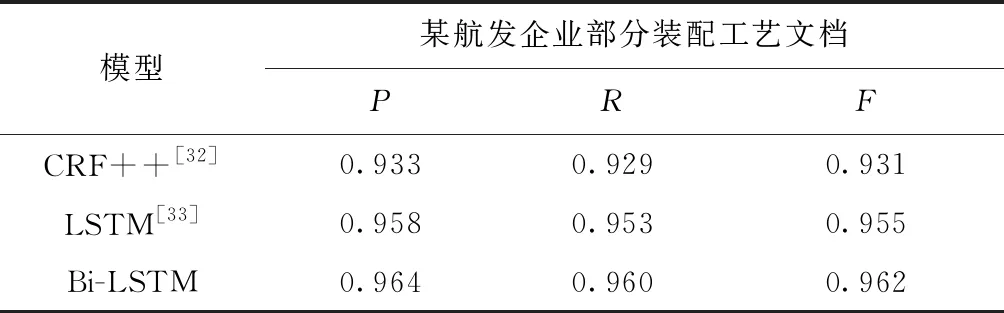
表3 分词性能评测指标对比
3.3 装配词素分类模块训练
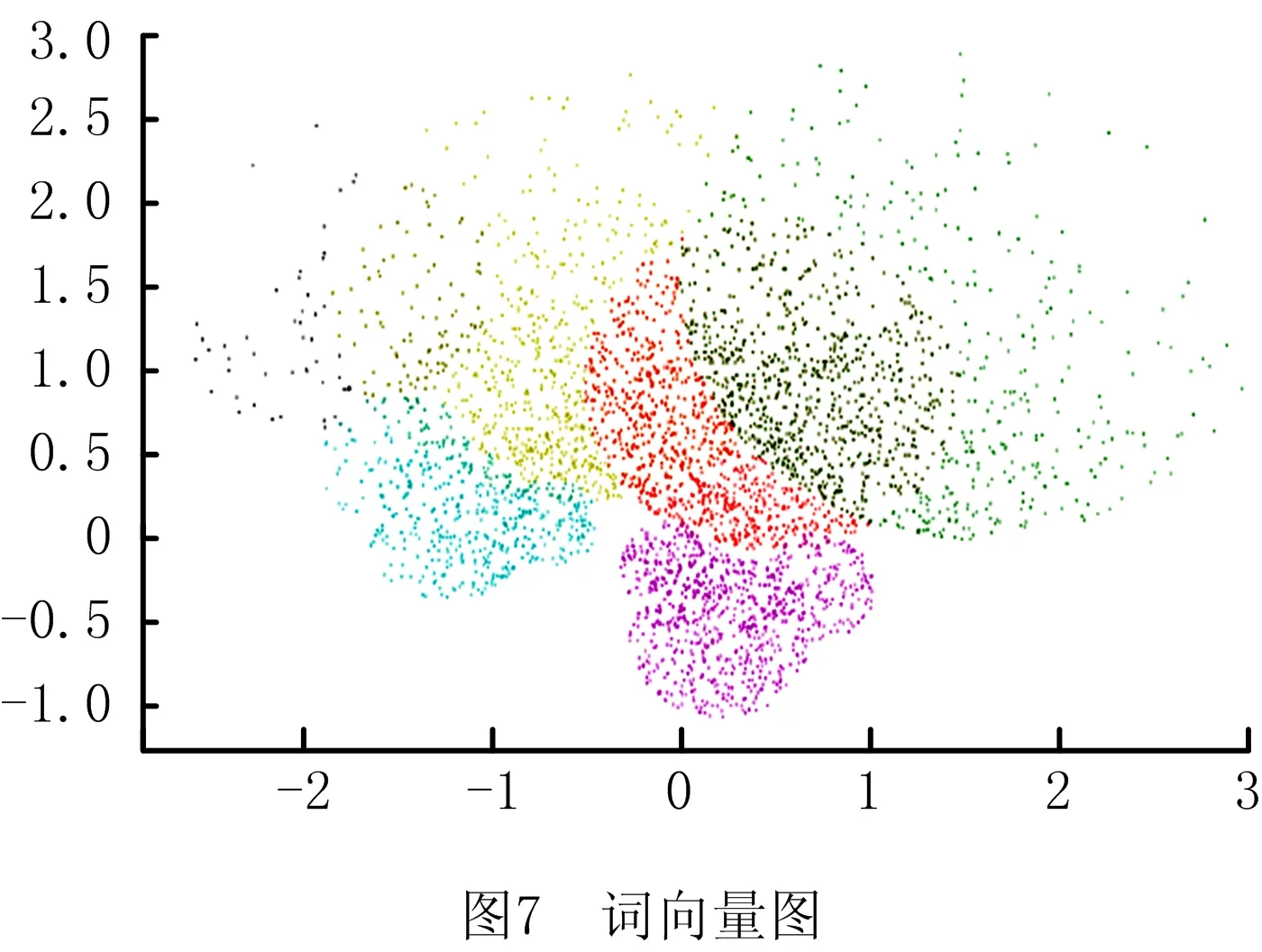
使用前文所述数据集,训练Google开源项目word2vec(选择Skip-gram),得到词向量。指定输出词向量的维数为128,训练窗口大小为5,学习率为0.001,最低频率为3,其余参数使用默认值。如图7所示为将高维词向量降维至二维空间所得的词向量图,黑色表示工具设备名称、黄色表示装配对象名称、红色表示装配动作词、深绿色表示装配特征词、蓝色表示装配序列语义词、紫色表示装配结构语义词、浅绿色表示量词。训练得到词向量后,采用增量学习方式得到测试数据集的词向量,根据式(9)计算词之间的相似度并分配类标签,分类正确率Q由式(10)定义,测试结果如表4所示。

(10)
4 实例分析
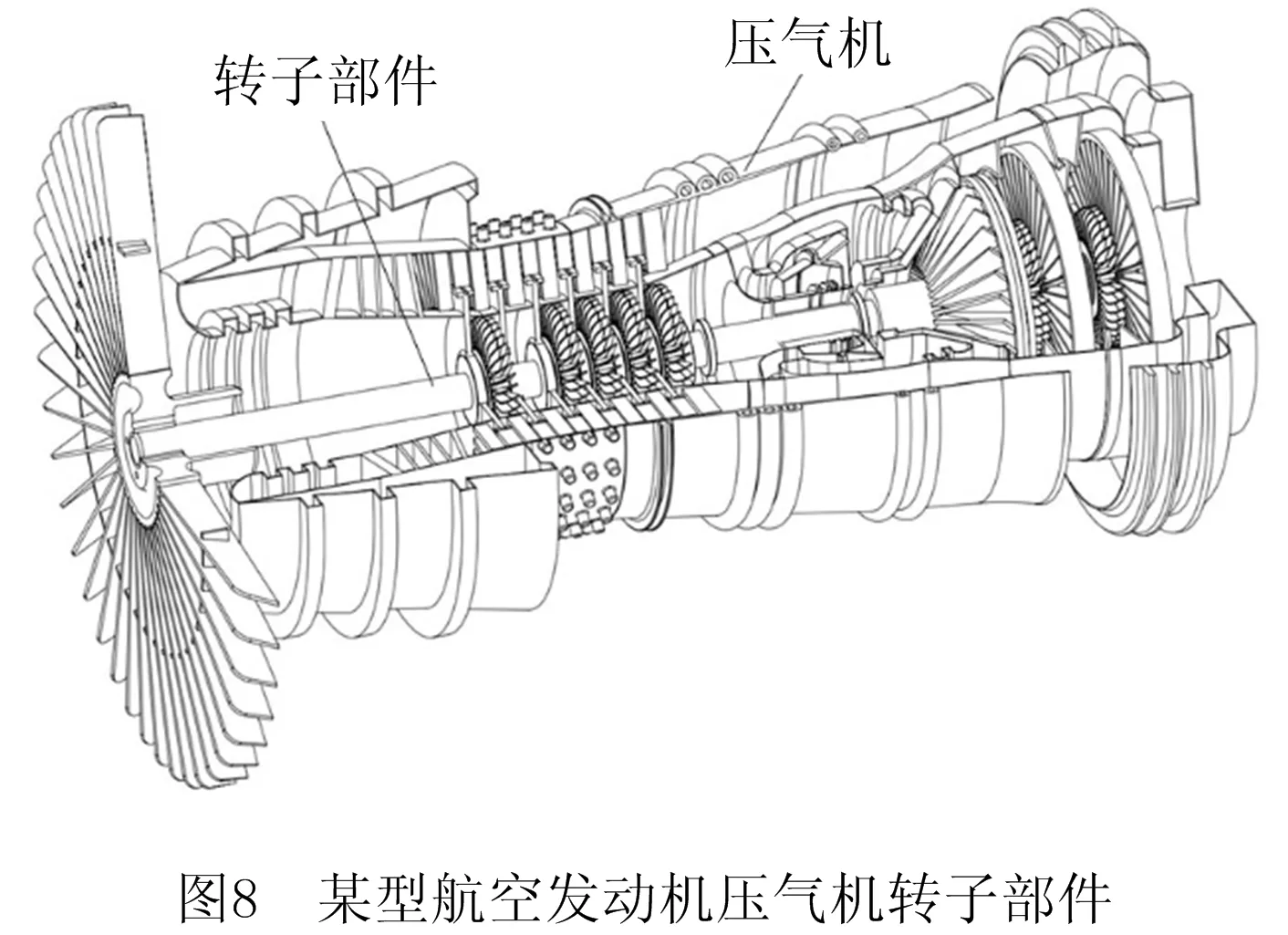
某型航空发动机压气机转子部件由轮盘、轴、叶片等零件组成,如图8所示。以其装配工艺文档为实例,验证基于Bi-LSTM装配语义识别方法的有效性,如图9所示。首先从CAD系统获取装配要素、装配特征、装配结构信息,然后在Python 3.6.2的环境下,利用训练好的装配语素分解模型与装配词素分类模型,并按照关系构建流程,完成装配工艺过程卡、装配工序卡的语义识别。具体步骤如下。
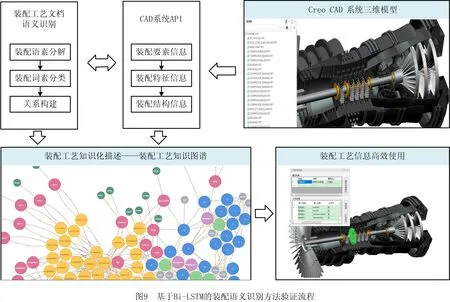
步骤1装配工艺过程卡与装配工序卡存储。
步骤2装配语素分解处理。将装配工艺过程卡、装配工序卡输入训练好的装配语素分解模型,得到语素分解结果,语素间用空格隔开。
步骤3装配词素分类处理。将语素分解结果作为增量训练数据,输入word2vec模型,得到每个词素对应的词向量,计算其与标记类别词之间的空间距离,完成装配词素分类,得到“词/类别”文件。
步骤4关系构建。依据关系构建流程,扫描装配工艺过程卡、装配工序卡的“词/类别”文件,建立装配工序序列关系、装配工步序列关系与装配结构关系。
步骤5语义整合。按序存储装配工序序列关系、装配工步序列关系及装配结构关系的构建结果。
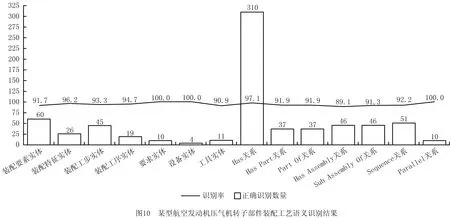
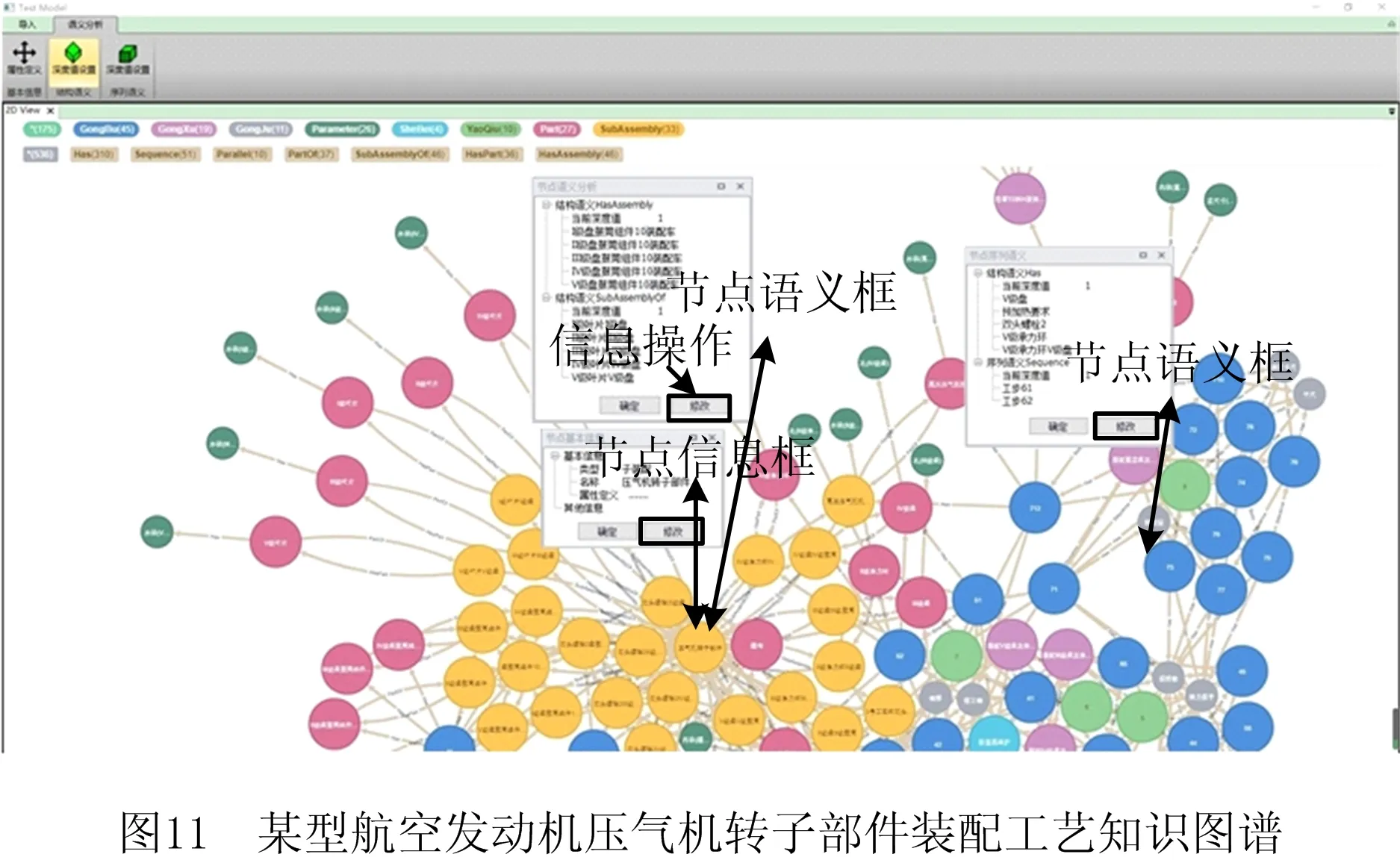
完成装配工艺语义识别,结果如图10所示。装配要素实体的语义识别率为91.7%,未识别实体均为漏识别;装配特征实体的语义识别率为96.2%,未识别实体为漏识别与误识别;装配工步实体与装配工序实体的语义识别率均为100%,说明关系构建流程对装配工艺文档的宏观语义识别效果较好;要求实体的语义识别率为94.7%,未识别实体均为漏识别;设备实体的语义识别率为100%;工具实体的语义识别率为90.9%,未识别实体为漏识别与误识别;Has关系的语义识别率为97.1%,未识别关系均为漏识别,由部分装配要素实体、装配特征实体、要求实体、工具实体未识别造成;HasPart、PartOf关系的语义识别率为91.9%,未识别关系均为漏识别,由部分装配要素实体未识别造成;HasAssembly、SubAssemblyOf关系的语义识别率为91.3%,未识别关系均为漏识别,由部分装配要素实体未识别造成;Sequence关系的语义识别率为92.2%,未识别关系均为漏识别,为装配语素分解阶段导致的错误。综上所述,装配实体与装配关系存在漏识别或误识别现象,且装配实体的语义识别率会影响装配关系的语义识别率,而装配实体的漏识别或误识别主要是装配语素分解、装配词素分类模块由非完全数据集训练,案例中装配工艺文档存在训练集未包含的词素造成。依据装配工艺文档扫描顺序建立“实体—关系—实体”、“实体—属性—值”结构,得到该型航空发动机压气机转子部件的装配工艺知识图谱,其对装配实体和装配关系表达正确率达93%以上,仅遗漏少数的装配要素实体、装配特征实体、要求实体、设备实体、工具实体与装配关系,满足车间使用要求,如图11所示。其中,蓝色实体表示工步、紫色实体表示工序、灰色实体表示工具、深绿色实体表示装配特征、浅蓝色实体表示设备、绿色实体表示要求、红色实体表示零件、黄色实体表示子装配体。实体间的边表示关系,该装配工艺知识图谱的关系包括Has、HasPart、PartOf、HasAssembly、SubAssemblyOf、Sequence。
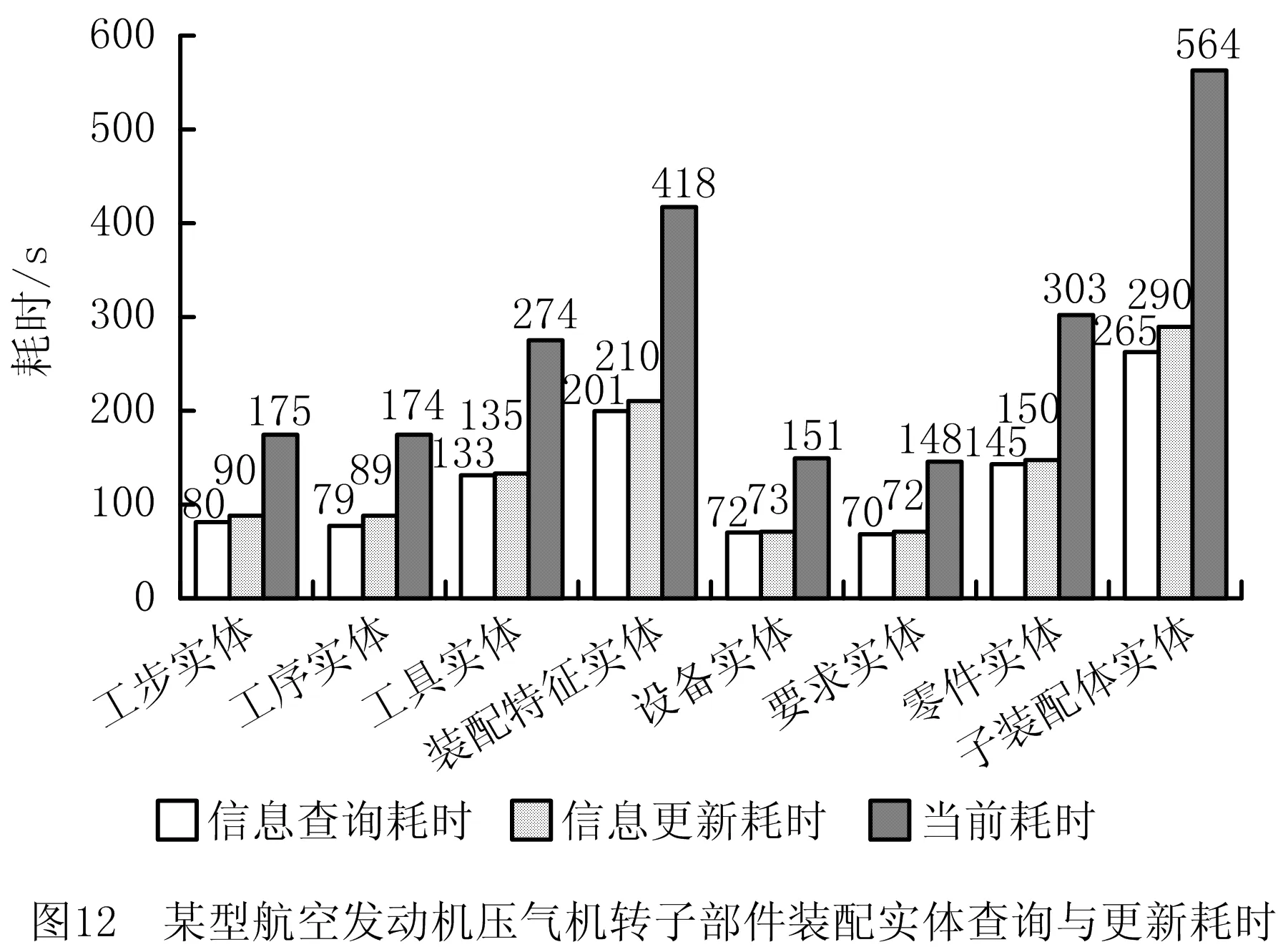
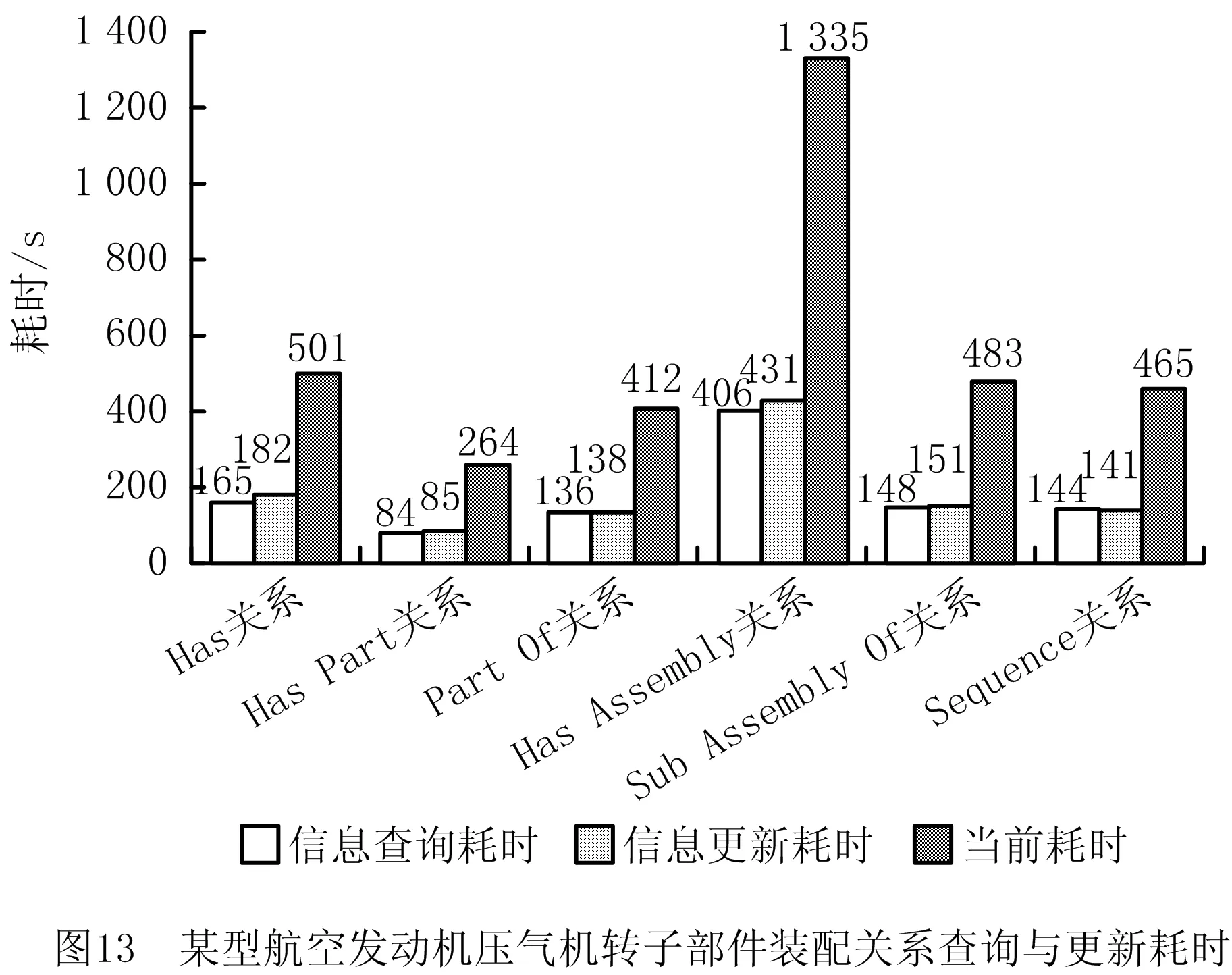
基于前述方法对装配工艺文档完成语义识别,并建立装配工艺知识图谱,可将装配工艺语义查询效率与更新效率提高至秒级。因此,装配工艺可执行评估与装配工艺指导过程的信息交互将主要消耗在装配工艺语义识别阶段。将每个装配实体或装配关系的识别耗时记为Tc,装配实体信息查询耗时记为Tnq,装配实体信息更新耗时记为Tnu,装配关系查询耗时记为Trq,装配关系更新耗时记为Tru。装配实体或装配关系的总查询与更新耗时按式(11)~式(13)计算,与目前该航发企业中节点的属性信息与语义信息的平均更新耗时相比较,得到图12与图13。
装配实体查询总耗时=Tc+Tnq;
(11)
装配实体更新总耗时=Tc+Tnu;
(12)
装配关系查询总耗时=Tc+Trq;
(13)
装配关系更新总耗时=Tc+Tru。
(14)
由图12和图13可得,对某型航空发动机压气机转子部件装配属性信息的查询速率和更新速率比当前方法提高1倍以上,而装配语义信息的查询速率和更新速率比当前方法提高2倍以上。因此,基于长短期记忆网络的语义识别方法对装配实体与装配关系的识别率较高,有利于装配工艺的知识化描述,从而提高装配工艺可执行评估与装配工艺指导过程的信息交互效率。
5 结束语
本文提出一种基于长短期记忆网络的装配语义识别方法,实现装配工艺文档的语义自动识别,并形成知识化描述,有利于提高装配工艺可执行评估与装配工艺指导过程的信息交互效率。以某型航空发动机压气机转子部件的装配工艺文档为输入,识别其装配实体与装配关系,得到装配工艺知识图谱。进行装配实体、装配关系的查询与更新耗时分析,证明了基于长短期记忆网络的装配语义识别方法的有效性。
未来工作需要扩大训练数据集的语料量,提高装配实体与装配关系的语义识别率,保证装配工艺知识图谱的表达正确率,并将其用于自动构建某车间的装配工艺知识图谱数据库,进一步研究基于工艺知识图谱的装配工艺规划方法,提高工艺设计阶段的智能化水平。
