改进Mask RCNN 算法及其在行人实例分割中的应用
2021-06-18陈雪云贝学宇
音 松,陈雪云,贝学宇
(广西大学 电气工程学院,南宁 530004)
0 概述
行人实例分割[1-3]技术目前已被广泛应用于车辆自动驾驶、视频监控[4]和机器人等领域,然而在实际应用场景中,行人姿态、背景、遮挡、光照等因素都会对检测精度产生较大影响。因此,行人的实例分割成为一项具有挑战性的研究课题。
目标检测[5]是检测图像中目标的位置框,语义分割是识别图像中每个像素点对应的物体语义信息,实例分割则将两者相结合,即识别检测出位置框中每个像素点的类别归属。现有基于深度学习的目标检测算法主要可分为基于候选区域和基于端到端两类。基于候选区域的算法分两阶段来完成检测,例如:RCNN[6]先通过选择性搜索产生候选框,再通过支持向量机(Support Vector Machine,SVM)进行分类;Fast RCNN[7]先通过选择性搜索产生候选框,利用VGGNet[8]进行特征提取并引入RoI Pooling 层,从而消除对输入图像的尺寸限制,再通过softmax 进行分类;Faster RCNN[9]通过区域候选网络(Region Proposal Network,RPN)产生候选框,使检测精度和速度得到提高。基于端到端的算法只需要一个阶段即可完成检测,如YOLO[10]、YOLO 9000[11]、YOLO V3[12]等。这些算法将骨干网络 从GoogLeNet[13]换为DarkNet,利用回归的思想来完成目标检测,其对于输入的一张完整图像直接得出目标位置和类别概率。得益于卷积网络的发展,语义分割研究近年来也取得了极大的突破,例如:DeepLab V1[14]利用空洞卷积并通过条件随机场(Conditional Random Field,CRF)做后处理;DeepLab V2[15]利用空洞金字塔池化,对不同分支采用不同的空洞率来获得不同尺度的图像特征;DeepLab V3[16]优化了空洞金字塔池化并增加了BN 层,取消了CRF 的后处理过程;DeepLab V3+[17]将Xception 结构用于语义分割任务,进一步提高了模型的速度和性能。行人实例分割是行人检测与行人分割的合并,其结合了目标检测和语义分割技术。
本文以Mask RCNN[18]为基础,通过增加串联特征金字塔网络(Concatenated Feature Pyramid Network,CFPN)模块优化Mask RCNN 网络分支,以提高算法的检测精确率,并利用COCO 数据集和自建数据集中的行人图像进行网络训练和评估。在本文提出的改进算法中,用于RPN 和检测的特征仍然由卷积网络和特征金字塔网络(FPN)[19]生成,用于Mask 分支的卷积网络生成的多层特征,经过上采样后不再与上一层特征进行相加,而是先进行融合,再合并融合后的多组特征生成Mask,从而更充分地利用不同特征层的语义信息。
1 Mask RCNN 网络
Mask RCNN 通过ResNet[20]或ResNeXt[21]提 取特征并通过FPN 构成骨干网络,生成的特征图为共享卷积层,特征金字塔对提取的阶段特征进行不同的组合,一方面通过RPN 判断前景和背景进行二值分类并生成候选框,另一方面将生成的候选框通过RoI Align 操作与特征图中的像素对应。之后,将一个分支用于分类和回归,将另一个分支用于分割生成Mask。
Mask RCNN 定义了一个多任务的损失函数,如式(1)所示:

在上式中,Lcls和Lbox为分类误差和检测误差,计算公式如下:
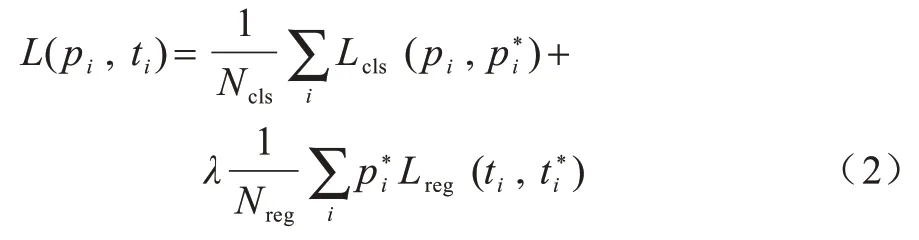
Lmask是语义分割分支的损失,输入Mask 分支的每个特征图经过一系列卷积和转置卷积操作后,输出k×m×m的特征图,其中,k表示输出的维度即总的类别数,每一个维度对应一个类别可以有效规避类间竞争,m×m表示特征图的大小。Lmask为平均二值交叉熵函数,其对每一个像素进行分类,对每一个维度利用sigmoid函数进行二分类,判断是否为此类别。
2 改进的Mask RCNN 网络模型
本文针对行人实例分割任务对Mask RCNN 网络进行改进。首先依据生活中的场景新建一个行人数据集,更有效地弥补COCO 数据集用于行人实例分割时的不足,然后新增一个CFPN 模块和分支,通过对特征提取骨干网络的重新设计,使得上下文语义信息得到更充分的运用。
2.1 网络整体架构
引入CFPN 的改进Mask RCNN 网络结构如图1所示,其中,ResNet 分5 个阶段依次提取特征。与原始网络不同的是,FPN 处理后的特征组通过RPN 生成候选框,经RoI Align 操作后仅用于分类和回归,而通过CFPN 融合的特征组与候选框经RoI Align 操作后只进入Mask 分支用于分割任务。FPN 和CFPN都是对特征进行处理,且重组后的特征大小相同、维度相同,因此,即使分别经RoI Align 操作,处理后的候选框仍然一一对应。
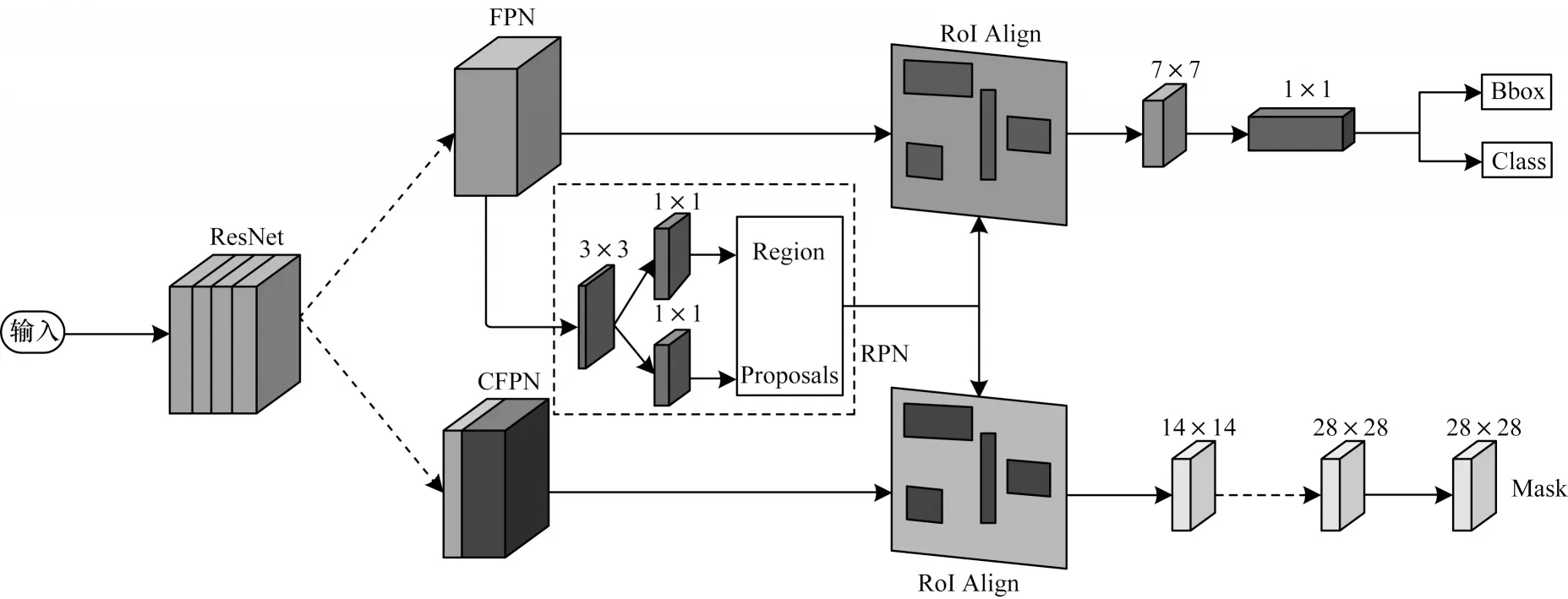
图1 改进Mask RCNN 网络结构Fig.1 Network structure of improved Mask RCNN
2.2 CFPN 模块
在深度神经网络中,低层特征包含更多的细节信息,而高层特征则更关注于语义信息。由于FPN自上而下通过上采样与横向特征相加得到的新的特征层包含了不同层的特征,因此具有更丰富的信息,这对于目标检测尤其是小目标检测具有重要意义。由于多维特征直接相加的操作不利于后续全卷积的分割任务,因此本文设计改进的CFPN 模块(如图2 所示)用于Mask 分支,从而更充分地利用不同层的语义信息提高网络性能。
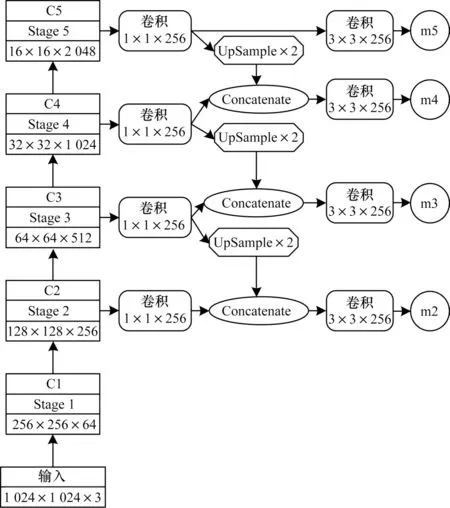
图2 CFPN 模块Fig.2 CFPN module
将ResNet 提取的特征记为C1~C5,每一层的特征经过1×1 卷积核的卷积,在保持特征图大小不变的同时降低了维度,C3~C5 卷积后进行上采样处理,目的是将特征图扩大一倍与低层特征相融合。对每一个融合后的特征进行3×3 卷积核的卷积,从而消除上采样后的混叠效应并实现降维。在图2 中,m5 由C5 直接上采样后卷积得到,m2~m4 则是由高层特征上采样分别和低层特征融合所得,形成的特征组[m2,m3,m4,m5]将用于Mask 分支。
3 改进Mask RCNN 算法流程
改进后的Mask RCNN 算法流程如图3 所示,该算法通过ResNet 网络对输入图像分5 个阶段提取特征,分别记为C1~C5,之后再分别进入后续两个分支。
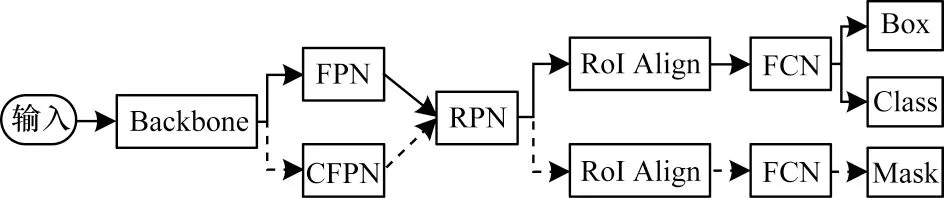
图3 改进Mask RCNN 算法流程Fig.3 Procedure of improved Mask RCNN algorithm
FPN 将高层特征经过上采样后分别与低层的特征相加形成新的特征组合P2~P5,C5 经过上采样后直接得到特征层P6,RPN 利用特征组[P2,P3,P4,P5,P6]产生候选框,生成的候选框先通过RoI Align 操作,再经过卷积核大小为7×7、通道个数为1 024 和卷积核大小为1×1、通道个数为1 024 的卷积操作后,通过全连接层和softmax 得到分类类别,经全连接层和Reshape 操作获得每个候选框的位置偏移量,用于回归目标候选框。
CFPN 将提取的阶段特征通过上采样与低层特征相融合形成[m2,m3,m4,m5],并结合候选框,通过RoI Align 操作用于Mask 分支,先进行连续的卷积核大小为3×3、通道数为256 的卷积操作,再经过一个2×2 的转置卷积将特征面积扩大一倍,最终输出候选框中对应类别的像素分割结果。虽然这一系列的操作都是语义分割,但由于每一个候选框中只有一个类别,因此相当于进行实例分割。
4 实验
4.1 实验数据集
COCO 数据集是微软团队提供的一个可用于图像分割和目标检测的数据集,主要为从日常复杂场景中选取的图像,包括80 类目标,超过33 万张图片。该数据集中的图像主要以物体检测、关键点检测、实例分割、全景分割、图像标注5 种类型标注,以json文件存储。本次实验使用的是COCO 2014 数据集,共分为训练集、测试集和验证集,其中训练集含82 783 张图像,测试集含40 755 张图片,验证集含40 504 张图像,本次实验在该数据集上进行预训练。
虽然COCO 数据集包含大量数据,但是数据种类众多,范围宽广。为更好地完成行人实例分割的任务,笔者仿照COCO 数据库自建了一个行人实例分割数据集(如图4 所示)用于数据增强。从街道、商场、海滩、公园、公路、车站等复杂日常生活场景中拍摄夜晚、清晨等弱光照条件下包含骑车、嬉闹、遮挡等各异姿态和背景的1 000 张图片,这些高分辨率图像有近景也有远景的行人,最后使用labelme 软件对所有的图像进行实例标定并生成对应的json 文件,用于训练和测试。自建的行人数据集相对COCO 数据集更接近生活且更复杂,这对网络性能检测更具挑战性。

图4 自建数据集标定图Fig.4 Calibration images of self-constructed dataset
4.2 网络训练
本实验在Ubuntu 16.04 系统中完成,实验框架为keras 和tensorflow,处理器为AMD R5 2600,内存为16 GB,显卡为NVIDIA 1060Ti。为适配硬件和统一图像尺寸,训练前将图像大小归一化为448 像素×448 像素,利用Python 图像增强库imgaug 随机选取50% 训练集进行数据增强。对不同骨干网络的Mask RCNN 和改进后的Mask RCNN 算法分别进行训练,训练共分为4 个阶段,前三个阶段在COCO 数据集中进行预训练,最后一个阶段在自建的数据集中进行。前两个阶段学习率为0.001,每个迭代(epoch)1 000 次,每个阶段训练40 个epoch;后两个阶段学习率为0.000 1,训练次数与前两个阶段相同。一个完整的训练过程共16 万次训练。
训练过程中的损失包含了RPN 网络和两个分支的损失,如图5 所示。可以看出,在第120 个epoch 后损失下降明显,是因为前120 个epoch 是在COCO 数据集上预训练,而后40 个epoch 在自建的数据集中进行。正因为自建数据集作为增强训练且容量有限,所以只进行了40 000 次迭代后损失已经趋于稳定。

图5 网络训练损失Fig.5 Network training loss
4.3 实验数据分析
4.3.1 精确率
精确率(Precision)是评价网络性能的一个重要指标,其为正确识别的物体个数占总识别出的物体个数的百分比,计算公式如下:

其中,XTP表示正确识别的物体个数,XFP表示错识识别出的物体个数。
本实验以AP50(IoU=0.50)和mAP(IoU=0.50︰0.05︰0.95)两个指标来分析实验结果并与原网络进行对比。
为避免测试准确率偶然性对实验结果的影响,对AP50 和mAP 两个指标各进行100 次测量,实验结果如图6 所示(彩色效果见《计算机工程》官网HTML版),其中,4个子图的算法骨干网络分别是ResNet50/101和ResNeXt50/101,原网络结果用FPN 表示为蓝色,改进后的网络结果用CFPN 表示为红色,实线和虚线分别为AP50 和mAP 的值。从图6 可以看出,在4 种不同的骨干网络中,改进的Mask RCNN 算法在AP50 和mAP 上都较原算法有较大提高,网络越深,提升越明显。
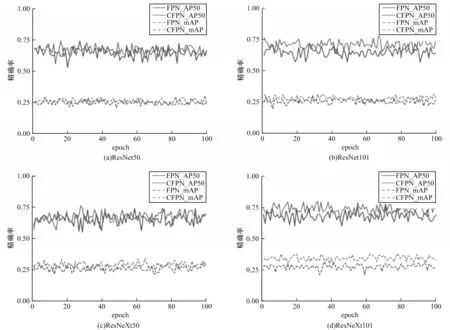
图6 不同骨干网络的精确率对比Fig.6 Precision comparison of different backbone networks
表1 和表2 显示了100 次测量结果的平均值,其中,ResNet50_FPN 代表骨干网络为ResNet50 的原网络,ResNet50_CFPN 代表骨干网络为ResNet50 的改进网络,以此类推。可以看出,改进网络性能较原网络得到了很大提升,同时,相同深度的ResNeXt 网络较ResNet 网络精确率更高,且网络越深,实验结果越理想。
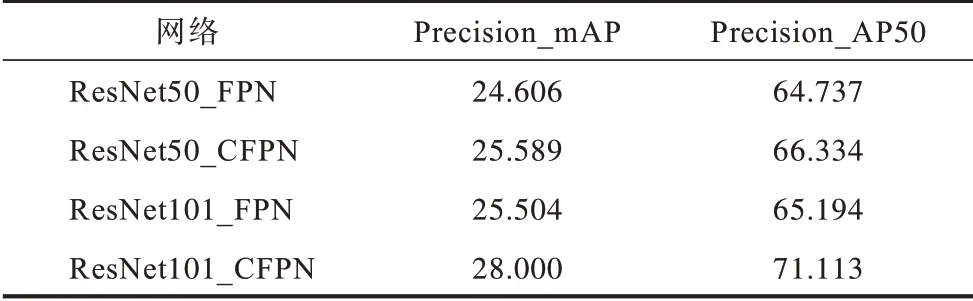
表1 改进前后精确率对比(ResNet 骨干网络)Table 1 Precision comparison before and after improvement(ResNet backbone network) %
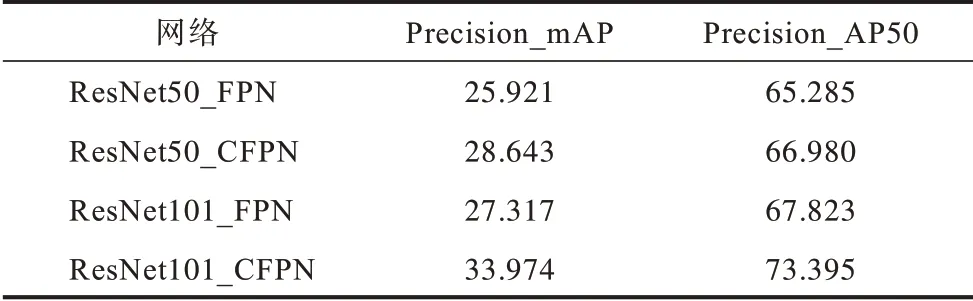
表2 改进前后精确率对比(ResNeXt 骨干网络)Table 2 Precision comparison before and after improvement(ResNeXt backbone network) %
4.3.2 网络预测时间
在网络训练结束后,对网络改进前后的每次精确率测试所花费的时间进行统计,以此来对比网络预测时间的差异。表3 和表4 显示了不同的骨干网络改进前后精确率每测试一次所需要的时间。可以看出,计算mAP 所需要的时间往往比AP50 要多,在同样层数情况下,ResNeXt 网络比ResNet 耗费时间多,而同样的网络改进后虽然参数量有所增加,但是测试所需要的时间整体上变化不明显,因此,改进后的算法并没有影响原算法在实时性上的表现。

表3 改进前后测试时间对比(ResNet 骨干网络)Table 3 Test time comparison before and after improvement(ResNet backbone network) s
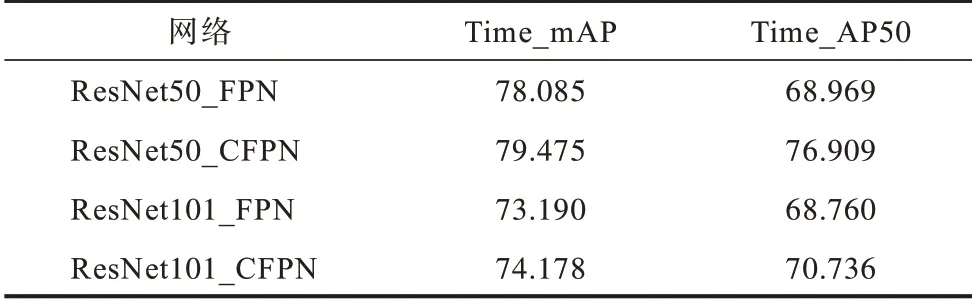
表4 改进前后测试时间对比(ResNeXt 骨干网络)Table 4 Test time comparison before and after improvement(ResNeXt backbone network) s
4.3.3 分割结果
基于生活场景图的训练结果进行测试,实验结果如图7 所示。可以看出,在应对不同的光照、姿态、背景时,本文改进算法都有很好的表现。但是在测试的过程中也发现,行人个例分割的边沿并不理想,仍然存在较大的误差。

图7 改进Mask RCNN 算法行人实例分割结果Fig.7 Pedestrian instance segmentation results of improved Mask RCNN algorithm
5 结束语
本文提出一种改进的Mask RCNN 算法用于行人实例分割任务。通过在Mask 分支中设计CFPN 模块,更充分地利用不同层特征的语义信息。仿照COCO数据集自建包含1 000张图片的行人数据集,对改进前后的网络进行定量和定性分析。实验结果表明,改进算法在不同的骨干网络中测试结果都得到了提升,增强了网络性能。但是该算法所得行人个例分割的边沿仍然存在较大的误差,下一步将对此进行改进。此外,还将研究如何减少网络参数并提高小目标下的实例分割精度。
