基于时空关注区域的视频行人重识别
2021-06-18胡晓强王子阳沈江霖任洪娟
胡晓强,魏 丹,王子阳,沈江霖,任洪娟
(上海工程技术大学 机械与汽车工程学院,上海 201620)
0 概述
行人重识别是判断图像或视频序列中是否存在特定行人的关键技术,被认为是图像检索的子问题,可为犯人追踪、视频数据处理等问题提供智能化解决方案,具有重要的理论意义和实际应用价值[1]。由于行人外观易受穿着、遮挡、姿态和视角等因素的影响,使得行人重识别成为计算机视觉领域中一项具有挑战性的研究课题。
行人重识别的关键问题是寻找一个最具鲁棒性的特征表示。在现有模式识别研究中,涉及区域特征[2]和特征融合[3]的研究较多。文献[4]提出一种端到端比较注意网络(Comparative Attention Network,CAN)模型。该模型在学习几张行人图像后有选择地关注显著的部分,采用比较注意元件生成关注区域,基于LSTM生成注意力图,利用CAN 模型模拟人类的感知过程,验证两幅图像是否为同一行人。文献[5]提出基于局部卷积基准(Part-based Convolutional Baseline,PCB)网络和精确局部池化(Refined Part Pooling,RPP)方法提取局部特征。利用PCB网络将特征图水平划分为六等分并进行平均池化和降维,同时利用RPP 方法将异常值重新分配生成具有内部一致性的精确局部特征,但这种处理方式会产生区域异常值。文献[6]提出一种基于视频的全局深度表示学习方法,以软注意力模块学习局部特征,在视频范围内聚合局部特征。该方法作为对3D卷积神经网络(Convolutional Neural Network,CNN)层的补充,能够捕获视频中的外观信息和运动信息,进一步增加3D 局部对齐方式。网络经过端到端训练,能够自动学习更具判别性的局部区域,从而减少背景等因素造成的影响,但是行人姿势会随着时间的推移而发生改变,显著区域会被佩戴物品遮挡,同时也会造成大量空间信息的丢失。
进行视频行人重识别时需要考虑时间信息的影响,对此的解决方法主要有3D CNN、递归循坏网络(Recurrent Neural Network,RNN)、光流和时间聚合[7]。文献[8-9]在采用CNN 提取空间特征的同时利用RNN 提取时序特征,针对单帧图像信息不足的问题,采用多帧序列图像信息进行弥补,对图像区域的质量进行评估,将来自其他采样帧的高质量区域补偿到低质量区域[10]。文献[11]采用CNN 提取步态序列的空间特征,利用LSTM 从步态序列中提取时间特征,最终得到时空信息融合的特征表示。文献[12]提出利用改善循环单元(Refining Recurrent Unit,RRU)进行帧间特征的升级。不同于LSTM,RRU 不直接利用每帧特征提取时间信息,而是根据历史视频帧的外观和上下文恢复当前帧缺失的部分。文献[13]将RNN 单元输出的平均值作为最终的特征表示并直接采用最后一个隐藏层的输出作为时间聚合的特征表示。本文对局部特征序列进行权重分配并加权平均,在空间特征的基础上融入时间信息,这种权重分配的方式优于文献[13]的全局平均和最后隐藏层输出的方法。以上行人重识别方法着重考虑关注区域,丢弃了全局特征的大量信息,同时也没有将空间信息与时间信息进行充分融合。
本文提出一种基于时空关注区域的行人重识别方法,将空间信息与时序信息进行深度融合,以解决行人姿势变换[14]和遮挡等问题,并通过快慢网络[15]提取全局特征和关注区域特征。快慢网络以不同的速度处理时间信息,用以捕获视频帧快速变化的动作信息,两个路径分别提取关注区域特征和全局特征。同时,提出一种融合模型替代快慢网络中的横向连接,采用亲和度矩阵和定位参数融合局部特征和全局特征,从而形成凸显关注区域的全局特征。
1 基于时空关注区域的行人重识别
1.1 网络框架
视频V被分割成连续的非重叠视频片段{Am}m∊[1,M],每个视频片段包含T帧,将视频片段的首尾两帧P={Ja|a=1,2}作为慢路径的输入,对视频片段按梯度采样6 帧Q={In|n=1,2,…,6}作为快路径的输入,采样帧P和Q均来自同一视频片段。如图1所示,本文方法框架由快慢网络的基础架构改进,其中,慢路径是全局特征X的提取流程,快路径是局部关注区域生成和特征聚合的流程,跨帧的关注区域特征被时间聚合后生成fk=[f1,f2,f3,f4],融合模块将全局特征X和局部特征fk融合成最终的全局时空特征表示F。
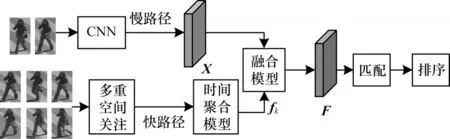
图1 基于时空关注区域的行人重识别框架Fig.1 Person re-identification framework based on spatio-temporal attention region
慢路径采样帧稀疏,低帧率运行,时间分辨率低,用于提取优良的空间特征,获得完整的语义信息;快路径采样帧数是慢路径的γ倍,高帧率运行,时间分辨率高,用于捕捉快速变化的动作信息。快路径的通道数是慢路径的1/γ倍,便于网络的快速运行。2 个路径的输入帧尺寸均为240×240,慢路径提取的全局特征尺寸为30×30,快路径则进行关注区域特征的获取与聚合。在本文中,慢路径视频片段采样2 帧,取γ=3,快路径视频片段采样6 帧,通道数是慢路径的1/3。
1.2 时空关注模型
1.2.1 多重空间关注
多重空间关注模型基于文献[16]的多样性正则化实现,用于发现具有判别性的身体区域,减小遮挡、视角等因素对识别结果的影响。
如图2 所示,时空关注模型采用ResNet-50 的conv1 到res5c 作为特征提取器,每个图像In由8×8 网格的特征向量{un,l},l∊[1,L]表示,L=30 是网格单元的数量,利用conv 网络和softmax 函数生成输入图像的多个空间注意区域和相应的感受野。
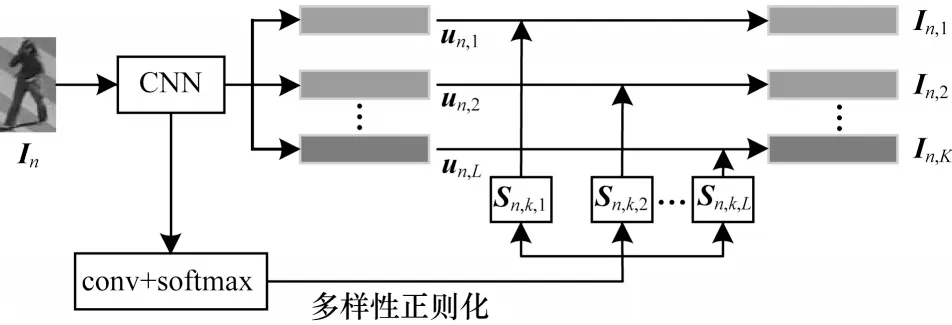
图2 多重空间关注模型Fig.2 Multiple spatial attention model
以Sn,k=[Sn,k,1,Sn,k,2,…,Sn,k,L]表示第n个采样帧第k个空间关注区域的感受野,每个感受野是概率质量分数,即=1。对于每个图像In,使用注意加权平均生成K个关注区域视觉特征:

其中,每个视觉特征表示图像的显著区域。为约束空间关注模型学习到不同的显著区域,文献[16]设计一个惩罚项衡量感受野之间的重叠,基于Hellinger 距离度量关注区域之间的相似性:

为抑制关注区域之间的重叠,Sn,i和Sn,j之间的距离应尽可能大,即1-H2(Sn,i,Sn,j)应尽可能小。在快路径中,每个视频片段存在6张采样帧,每张采样帧确定4个关注区域,即K=4,网络通过预训练和约束训练自动学习每个行人的脸部、手臂、膝盖、脚,产生24个关注区域特征(共6组,每组4个):{In,k|n∊[1,2,…,6],k∊[1,2,3,4]} 。
1.2.2 时间聚合模型
在1.2.1 节中,每个采样帧都由4 个关注区域的集合表示,即{In,k}=[In,1,In,2,In,3,In,4],本文采用图3 所示的时间聚合模型,在局部特征的基础上融入时间信息,计算所有采样帧相同部位的特征权重Cn,k,=1,k∊[1,2,3,4],由此形成时空关注的局部特征表示。
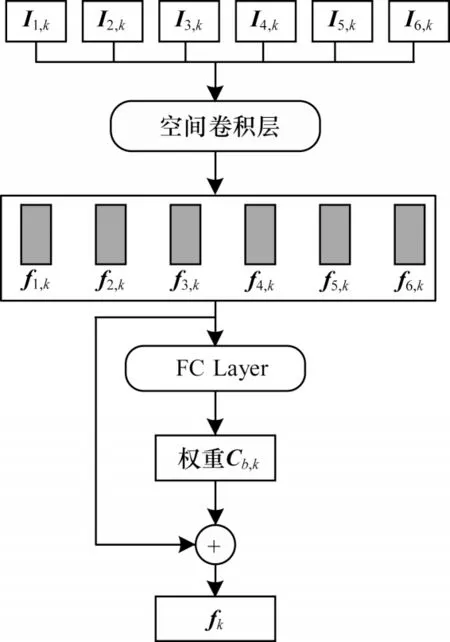
图3 时间聚合模型Fig.3 Temporal aggregation model
时间聚合模型由空间卷积层(输入通道数为1 024,输出通道数为D)和全连接层(输入通道数为D,输出通道数为1)组成,采用采样帧相同部位的关注区域特征作为输入,空间卷积层对关注区域的特征表示做进一步卷积操作,生成6 个采样帧相同部位的特征表示{f1,k,f2,k,f3,k,f4,k,f5,k,f6,k},经全连接层输出每个特征表示的权重Cn,k,然后对跨帧的局部特征表示进行加权聚合:

其中,k∊[1,2,3,4],fk为连续帧相同部位具有时空特性的特征表示。
1.3 融合模型
快慢网络中的横向连接存在融合过程复杂和单向连接等不足。本文提出一种融合模型代替快慢网络中的横向连接。该模型将局部关注特征fk与全局特征X融合,形成关注区域凸显且不丢失全局信息的全局特征表示,其融合过程简单,且不受单向连接的限制。模型中包括亲和度函数H和定位函数G,具体细节如图4 所示。

图4 融合模型Fig.4 Fusion model
1.3.1 亲和度函数
亲和度函数H用于表示局部特征fk与特征X之间的相似性,函数表达式为H(X,fk)=Hk,RD×30×30×,其中,D是特征向量维数,e×e是关注区域特征尺寸。亲和度函数计算嵌入特征之间的点积,fk与X之间的相似性度量矩阵为:

其中,X(m)表示特征X中空间网格m的特征,fk(n)表示fk中网格n的特征。对于每个fk(n),利用亲和度函数H(m,n)在fk(n)的空间维度上进行softmax 归一化。
1.3.2 定位函数
定位函数G由2 个卷积层和1 个线性层组成,将亲和度函数H(m,n)作为输入,在特征X中寻找与关注区域特征fk最相似的区域,并输出该区域的定位参数θk,定位参数为双线性采样网格的4 个参数[17],定位函数的表达式为:

定位参数θk=[a,b,c,d]用于映射局部关注特征fk和全局特征X坐标位置之间的关系:
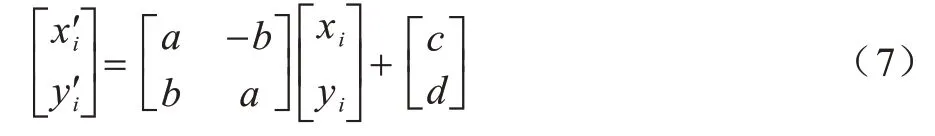
其中,(xi,yi)表示关注区域特征fk的坐标位置,()表示在全局特征X中与关注特征fk相对应的区域坐标位置,参数θk=[a,b,c,d]表达坐标位置之间的平移和旋转关系。
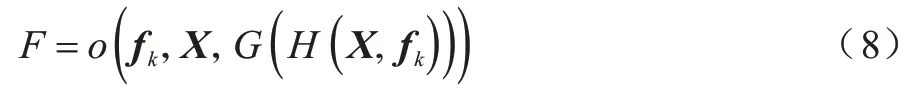
函数o(˙)根据定位参数将局部特征fk融合到全局特征X中,最终获得凸显局部特征且不丢失整体细节的全局特征表示F。
1.4 损失函数
本文采用融合损失函数和三重损失函数进行网络训练,融合损失函数基于局部关注特征fk与其在全局特征中相对应区域之间的平均欧氏距离对识别结果进行判定:
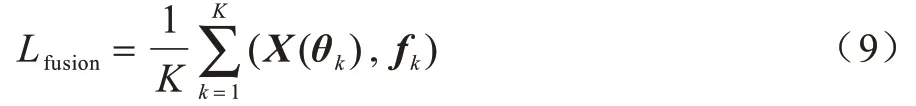
其中,X(θk) 表示与fk相对应的关注区域特征,表示fk与X(θk)的欧氏距离的和,Lfusion即为平均欧式距离,采用端到端的方式训练网络,直到Lfusion趋于最优值。
三重损失函数[18]在一个批次中将待检测样本、一个正样本和一个负样本构成三元组,该批次由P个待检测样本和每个检测样本的A个视频片段组成,每个视频片段有T帧,该批次共有P×A个视频片段,利用本文网络架构在该批次中识别出最优正样本和最差负样本,构成三重度量损失,表达式如下:
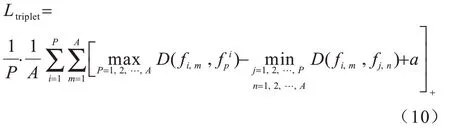
其中,a是设定的阈值参数。总损失等于两个损失函数的和,表示为:

融合损失和三重度量损失都是基于特征表示的,彼此之间存在内在联系,因此,可将融合损失作为融合阶段的经验指导和纠正匹配错误。
2 实验与结果分析
基于iLIDS-VID、PRID-2011 和MARS 视频数据集对本文方法进行性能评估。
2.1 实验细节
首先在ImageNet 数据集上对Resnet-50 进行预训练,然后在3 个数据集上进行微调。在训练阶段,输入图像的大小为240 像素×240 像素。为方便实验对比,训练包含不同关注区域数量的空间关注模型。在时间聚合模型和融合模型训练过程中,假设T=6,K=4,采用随机梯度下降算法对网络学习进行更新,初始学习率设置为0.1,逐渐降至0.01。在测试阶段,在3 个视频数据集上分别计算平均精度(mAP)和Rank-1、Rank-5 的准确率作为对模型行人重识别性能的评价指标。
2.2 结果分析
2.2.1 空间关注模型数量
首先研究空间关注模型的数量K对识别效果的影响。随着空间关注模型数量的增加,网络能够发现更多的显著区域。由于受到多样性正则化的约束,随着K的增大,关注区域的尺寸不断缩小。如表1 所示,当K=2 时,关注区域往往会包含多个身体部位和背景,识别性能较低,经实验验证,本文模型在K=4 时网络的识别性能达到最优。如果K再持续增大,识别效果反而降低,这是因为在多样性正则化约束的情况下,空间关注模型的数量过多会导致关注区域尺寸过小或者特征判别性降低,最终使识别准确率下降。笔者在iLIDS-VID 数据集上进行实验时发现,K=6 时识别效果最佳,这与数据集的特性有关,因为iLIDS-VID 数据集具有复杂的背景和严重的遮挡。增加关注区域的数量可以减少背景和遮挡对识别结果的影响,在不同数据集中关注区域的尺寸对识别准确率有很大影响,下文将对此做进一步讨论。
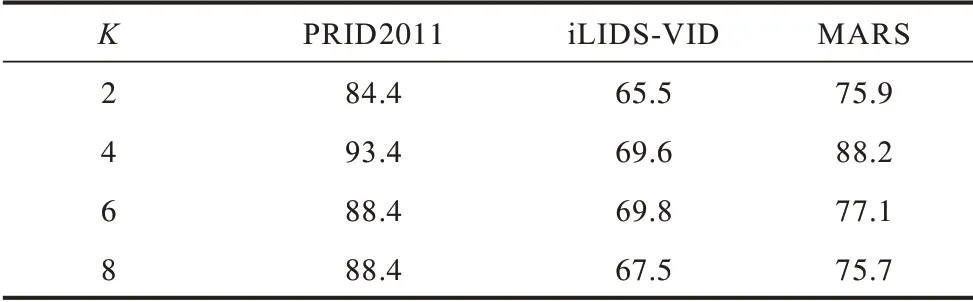
表1 多重空间关注模型的Rank-1 准确率Table 1 Rank-1 accuracy of multiple spatial attention model %
2.2.2 关注区域尺寸
在上述实验中,设置每个相同部位的关注区域尺寸是相同的,目的是便于进行时间聚合,在此基础上进行关注部位区域尺寸的讨论,并记录最优的区域尺寸和识别准确率。首先进行单一关注区域尺寸的讨论。以膝盖为例,分别设定不同尺寸的膝盖区域,记录识别准确率,然后以所有关注区域的尺寸最优值为约束条件,最终得到识别准确率。
表2 的上半部分为单一区域尺寸的实验结果。可以看出,在原始图像中,膝盖区域尺寸为48×48时Rank-1准确率最高,达到80.4%,由实验数据可以发现,识别准确率会随着设定区域的扩大而不断减小,这是由于背景逐渐增多造成的影响。表2 的下半部分为关注区域尺寸全部为最优值的实验结果。可以看出,在MARS数据集上Rank-1 准确率达到88.2%,在对单一区域尺寸进行单独讨论时,Rank-1 准确率都略低于88.2%,这是因为其他关注部位的区域尺寸不是最优值。
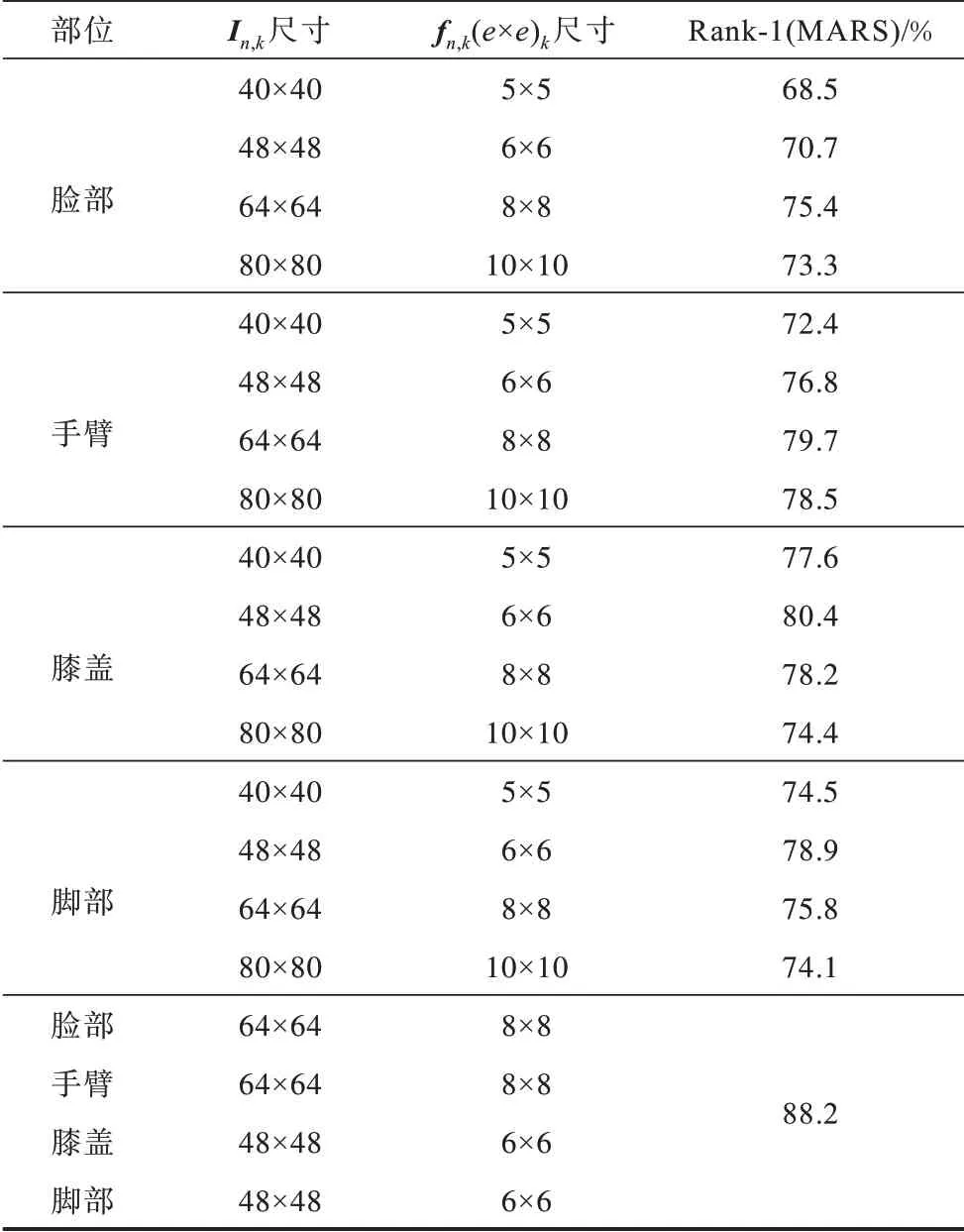
表2 不同部位的关注区域尺寸Table 2 Size of attention region in different parts
2.2.3 横向连接与融合模型
设置一系列对比实验验证融合模型的性能,首先是单一路径实验,分为慢网络和快网络进行双路径快慢网络结合的实验验证。快慢网络横向连接存在3 种形式,即时间到通道、时间跨度采样和时间跨度卷积[15]。横向连接需要匹配特征的大小,慢网络的特征参数为{T,S2,C},快网络的特征参数为{γT,S2,τC},其中,T为时间长度,S为特征表示的高度和宽度,C为通道数,γ为快慢路径采样帧数量之比,τ为快慢路径通道数之比,且τ=。时间到通道表示将所有γ 帧打包到一帧的通道中,即将特征{γT,S2,τC}转换为{T,S2,λτC};时间跨度采样表示在每 个γ帧中采样一次,即将特 征{γT,S2,τC}转换为{T,S2,τC};时间跨度卷积采用5×12、2τC输出通道、步长等于γ的3D 卷积核进行卷积。本文对每一种横向连接形式都进行实验对比,进一步验证融合模型的优越性。空间关注模型数量和关注区域尺寸均采用上述实验最优值。
首先对单一路径与双路径的对比,由表3 可以看出,在PRID 2011 和MARS 数据集上,双路径的识别性能更优越。对于快慢网络横向连接的3 种形式[15],实验结果表明:在PRID 2011 数据集上显示时间跨度卷积的横向连接性能最好,Rank-1 准确率达到78.2%,本文方法Rank-1 准确率达到93.4%,相较于时间跨度卷积提高15.2%;在MARS 数据集上本文方法Rank-1 准确率较时间跨度卷积提高13.6%。由实验结果可得出,本文方法识别准确率远高于单一路径方法。
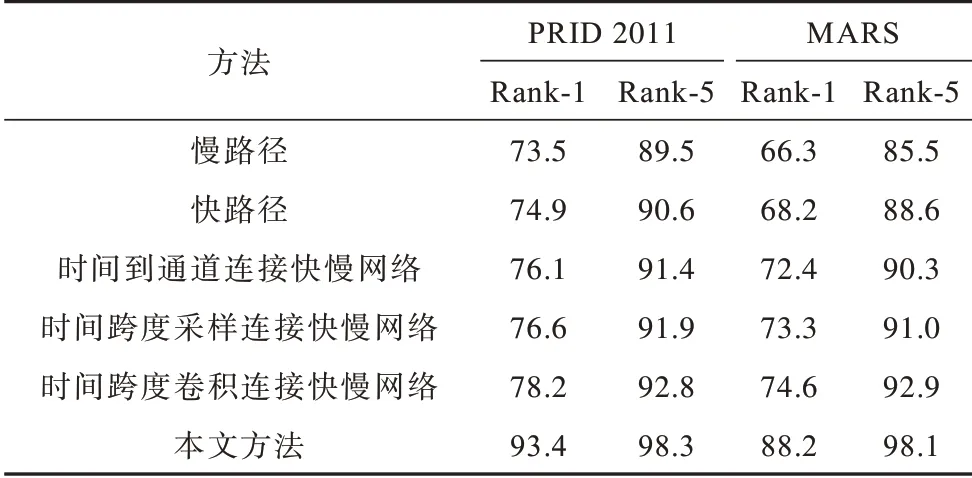
表3 在PRID 2011 和MARS 数据集上不同融合方法的准确率对比Table 3 Comparison of different fusion methods on PRID 2011 and MARS datasets %
2.3 识别性能对比
本文方法 与SeeForest[19]、ASTPN[20]、RQEN[11]、MARS[21]、AMOC+EpicFLOW[22]、DRSTA[16]和STMP[13]方法的识别准确率对比如表4 所示。可以看出,在3 个数据集上,本文方法的Rank-1 准确率均能达到最优。与STMP 方法相比,本文方法在MARS 数据集上的Rank-1识别准确率提高了3.8%,在iLIDS-VID数据集上Rank-1 准确率提高了2%。MARS 是最具有挑战性的视频行人重识别数据集,其中存在干扰视频片段,图5显示,本文方法在MARS 上的的平均精度达到79.5%,较DRSTA 提高13.7%,较STMP 提高6.8%。这一结果表明,在关注区域的基础上融合时空特性对再识别性能的提升有很大帮助。
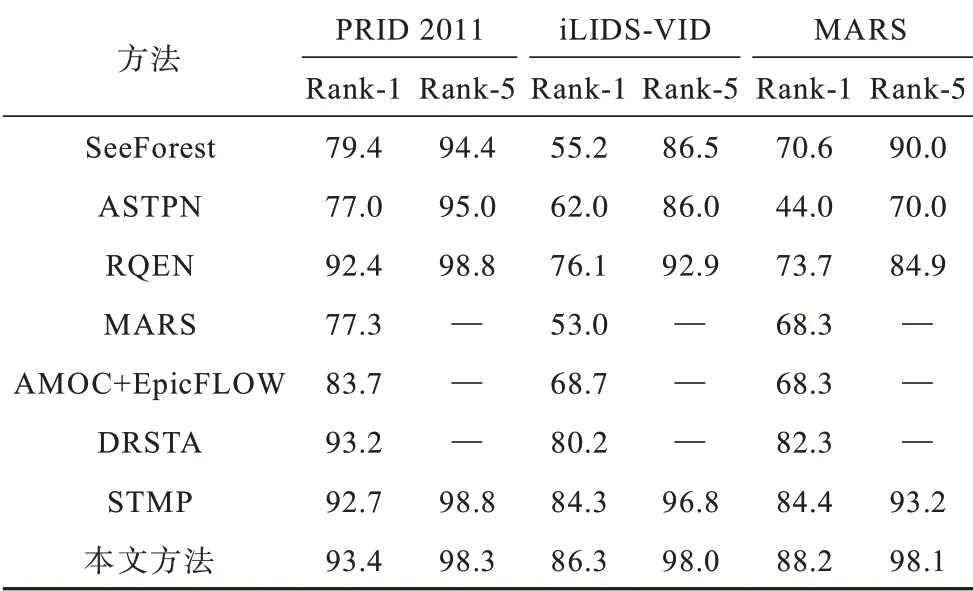
表4 不同方法的准确率比较Table 4 Accuracy comparison between different methods %

图5 MARS 数据集上不同方法的mAP 对比Fig.5 mAP comparison between different methods on MARS dataset
3 结束语
本文通过融合局部特征和全局特征,提出一种新的视频行人重识别方法。在提取局部特征的同时,利用时间关注模型将视频序列中同一关注部位的局部特征进行跨帧聚合,以形成视频级关注区域特征表示,并通过融合模型将关注区域特征与全局特征融合,以形成具有全局空间细节和局部关注区域的视频级特征表示。基于视频级特征表示计算特征距离,使用特征距离进行识别排序,在PRID2011、iLIDS-VID 和MARS 数据集上进行实验验证。实验结果表明,本文方法能够有效提升Rank-1 和mAP 指标,具有较高的识别准确率。后续将依据行人动作变化建立关注区域之间的结构关系,提取对姿势变化更具有鲁棒性的特征,进一步提升行人重识别性能。
