面向非平衡数据集的金融欺诈账户检测研究
2021-06-18汤丰赫黄俊恒王佰玲
吕 芳,汤丰赫,黄俊恒,王佰玲
(1.哈尔滨工业大学(威海)计算机科学与技术学院,山东 威海 264209;2.哈尔滨工业大学(威海)网络空间安全研究院,山东 威海 264209)
0 概述
欺诈可以定义为导致金钱或个人利益损失的不正当或刑事欺骗行为。近年来,欺诈活动的形式和规模随着跨银行交易而变得越来越复杂和庞大,普华永道(PwC)[1]2018 年的全球经济犯罪调查结果显示,有49%的公司在过去两年经历过金融欺诈行为,2016 年的这一数据仅为36%。面对海量、多样的欺诈手段,基于专家知识、侦查经验的传统欺诈账户识别方法已经难以满足当前金融安全保障的需求。如何从海量金融数据中自动识别少数欺诈账户逐渐成为侦查部门及大数据研究人员关注的问题。
金融欺诈账户检测是一项难度较高的任务,许多学者使用不同方法从多个角度研究检测模型。文献[2]采用广义的定性相应模型(EGB2)来预测企业管理层进行的欺诈活动,文献[3]提出一种成本敏感的决策树欺诈检测方法,文献[4]对比了利用支持向量机(SVM)、逻辑回归和随机森林构建模型对欺诈检测的性能,文献[5]通过比较金融欺诈检测中机器学习算法的性能,得出随机森林算法是最佳的金融欺诈检测技术。在真实的交易数据中,欺诈账户的数据量相对整个数据集来说比例极少,且其具有欺诈倾向的行为活动被淹没在海量、常规的金融交易活动中。若直接采用上述分类模型,由于常规交易(多数类样本)数量多,欺诈交易(少数类样本)数量少,会导致欺诈检测模型在学习分类边界时无法充分捕捉少数类样本的类别特征,从而影响对欺诈账户的检测性能。因此,解决数据集在类间的非平衡问题对提升账户分类模型的检测性能具有重要意义。文献[6]发现不平衡性通常会导致少数类内部形成小杂项(间断和分离),导致其在决策时易被错误地学习,从而降低欺诈检测性能,造成该现象的主要原因是一些典型的少数类样本在少数类中分布稀疏,数量较少。可见,解决小杂项引起的类内不平衡问题也同样值得关注。
目前,解决数据集不平衡问题的方法主要分为两类。一类从数据层面入手,通过改变数据样本的分布来降低数据的非平衡性,常用方法有欠采样和过采样技术,它们分别对应少数类样本的增加和多数类样本的减少。另一类从算法层面入手,通过调整算法来适应分类不平衡问题,如代价敏感学习、集成学习等。在过采样技术的研究中,文献[7]提出用于不平衡学习的自适应合成采样方法(ADASYN),该方法使用密度分布作为准则为少数类样本分配权重,从而自适应地生成少数类的合成数据样本,以减少由不平衡数据分布引起的偏差。对于处于多数类高密度分布区域内的少数类样本,ADASYN 会将该样本作为“较难学习”的样本,赋予其高权重并为其生成更多的合成样本。虽然使用ADASYN 会面临跨决策区域合成样本的风险,但作为一种新的学习方法,其基于密度分布自适应地给予样本权重并进行样本合成的思想,可以用于处理不同情况下的不平衡学习问题。除了采用分类模型进行少数类检测,有研究人员将“异常”定义为“离群点”,进而提出众多“异常”检测方法,如基于密度、测量和iForest方法。其中,iForest是由文献[8]提出的基于孤立概念的无监督异常检测方法,其将“异常”定义为“容易被孤立的离群点”。在特征空间中,分布在稀疏区域的点表示某事件在稀疏区域发生的概率很低,iForest 认为落在这些区域中的点是“异常”的,因此,通过iForest可以快速高效地检测数据集中分布稀疏且离密度高群体较远的异常点。
欺诈账户交易行为的隐蔽性导致正常账户和欺诈账户的类别边界模糊,严重影响了分类器的检测性能。因此,有必要针对金融账户模糊的类别边界进行分析。模糊边界中的节点集合主要分为少数类的异常点和多数类的异常点。其中,多数类的异常点作为存在于少数类内部或决策边界的冗余样本,是导致决策边界混乱的重要原因;少数类的异常点作为少数类内部的稀疏样本会导致小杂项的产生,是引发类内不平衡问题的重要原因。
本文借鉴iForest 检测异常点的算法思想以及ADASYN 决策边界样本合成方法,设计一种样本均衡策略。提出一种基于iForest解决分类不平衡问题的金融欺诈账户检测框架(iForest-SMOTE),框架主要包括特征抽取、数据集均衡、欺诈账户检测三个部分。样本的分类特征提取是影响分类器性能的一个关键因素,金融数据同时具有网络、流式数据的特点。因此,为了全面描述账户的交易行为,本文分别从静态交易信息、交易关系和交易周期性三个维度进行特征抽取。具体地,本文分别从交易资金、交易网络和交易周期三个维度设计银行账户的交易行为特征抽取方法。为了解决类别样本不均衡问题,提出一种基于iForest 解决非平衡数据集的方法。该方法通过iForest对数据集进行检测以获取预处理样本子集,根据类别不同对其采用不同的调整策略,从而提升欺诈检测的性能,具体地,负采样多数类样本,减轻决策边界的混乱程度,重采样少数类样本,减少内部小杂项的产生,结合ADASYN 将决策边界向具有决策影响力的少数类异常点附近移动。在分类器的选择上,结合金融数据分类特征复杂、类间不均衡的特点,本文采用随机森林分类器模型[9]检测金融欺诈账户。
1 相关工作
1.1 iForest 异常检测技术
iForest 是文献[8]基于样本集中异常样本是稀疏且异于正常样本的两个假设而提出的一种基于孤立点的无监督异常检测方法,该方法使用二值树结构(iTree)将每个实体转化为树结构中的孤立节点。基于异常点对孤立划分更敏感的理论,通过子采样使得异常点相对正常点距离iTree 的root节点路径更近。iForest有效解决了异常检测中的淹没效应(异常点和正常点的距离很小)和掩蔽效应(异常点增多,导致其密度增大),因此,iForest可以快速高效地检测离群点。随后,为将iForest扩展到分类、在线异常检测和高维数据中,研究人员进行了一系列探索。文献[10]将iForest扩展到类别数据集上,对用户日志中体现出的用户行为模式进行异常检测。文献[11]改进iForest 中的约束条件,实现对多类别正常数据中局部聚集异常数据集合的检测,文献[12]根据iForest中异常分数的热图提出扩展隔离森林(EIF),ELF 可以稳定高效地对高维数据进行异常检测。此外,文献[13]基于iForest 提出一种自适应方法,实现对网络管理系统的快速异常检测,文献[14]通过iForest 对软件进行缺陷预测。
针对金融账户数据,由于正常和欺诈账户在金融交易模式上具有一定的相似性,在特征空间中表现为分布在决策区域附近的样本密度集中且分布混乱,导致iForest 在样本密集区域中检测少数类样本的效率较低,不能直接用于金融欺诈账户检测任务。但是,由于iForest 检测出的异常点具有孤立的特性,使得该点在不同类别的决策中具有重要作用,因此iForest 的异常点可用于样本均衡。
1.2 类别均衡方法
改善数据集类别不均衡问题的方法分为数据级别和算法级别两类。其中,数据级算法主要包括对数据集进行欠采样和过采样。在欠采样方面,文献[15]将聚类与实例选择相结合对不均衡数据集进行欠采样。上述方法加速了分类过程,但对数据进行过度欠抽样时将导致提升分类器性能的样本信息被消除。文献[16]通过欠采样技术去除决策边界的嘈杂和冗余多数类实例,以减少分类器对分类不平衡的敏感度。在银行账户数据集中,一部分多数类样本会成为嘈声存在于少数类内部或决策边界,因此,选择有效的欠采样技术有助于排除降低决策的多数类样本。过采样通过增加少数类样本以达到数据集平衡,若随机复制样本有可能降低样本的泛化能力、加剧少数类中噪音数据对模型的影响。为此,研究人员通过插值生成人工样本,扩大少数类的泛化空间。文献[17]提出SMOTE 技术,插入彼此接近的少数类样本以合成新的少数类样本,保证新增少数类样本的质量。然而,SMOTE 为所有实例赋予相同的权重,忽略了决策区附近实例对分类的重要性。据此,文献[18]提出了borderline-SMOTE1 和borderline-SMOTE2 两种改进方法,然而这两种方法均只为决策边界附近的少数类样本分配高采样权重。文献[19]提出一种混合采样的方法,该方法将过采样技术SMOTE 与从多数类中消除歧义样本的欠采样技术相结合,通过进行样本均衡来解决数据集的不平衡问题。另外,文献[6]提出用于不平衡学习的基于密度分布的自适应合成采样方法ADASYN,其将分布在高密度多数类中的少数类样本定义为较难学习的样本,设计参数调节较难学习的样本的采样权重,从而自定义地合成更多样本。ADASYN 在改善数据集非平衡问题的同时还可以将分类的决策边界自适应地转移到教难学习的样本上。但是,当有大量较难学习样本存在于多数类内部时,ADASYN 会在合成少数类样本时跨越决策区域,加剧决策区域的混乱程度。总体而言,ADASYN 算法具有较强的泛化能力,通过修改和扩展,可用于解决不同场景下的类别不平衡问题。
由于ADASYN 根据多数类的密度分布准则对少数类进行权重分配,当少数类样本分布在多数类内部时,合成样本会面临跨决策边界合成的风险。金融数据的复杂性导致其类别边界模糊,直接使用ADASYN 会加剧决策边界的混乱程度。金融数据中不同类别的异常点具有不同的特性,难以确定其能否对决策产生正面影响。为了提高欺诈检测性能,本文对不同类别的异常点实施不同的策略:一方面,将属于多数类的异常点(多数类异常样本)作为嘈杂样本,对该样本和其附近的多数类样本进行筛除,以降低决策边界和少数类内部的混乱程度;另一方面,对于属于少数类的异常点(少数类异常样本),借鉴ADASYN 的思想进行样本合成,以在样本均衡的同时减少出现小杂项的风险,并将少数类的决策边界调整到具有典型性的少数类样本附近。
1.3 随机森林分类模型
随机森林[8]是一种由多棵决策树组成的集成学习模型,随机森林在多种分类任务中相对其他机器学习算法具有明显优势,因此受到数据分析、知识管理、模式识别等众多领域研究人员的广泛关注[20]。在异常检测方面,文献[21]使用两种不同的随机森林算法分别训练正常和欺诈交易的行为特征,检测信用卡欺诈行为;文献[22]提出一种采用交易时间序列中固有模式对文件进行汇总的欺诈检测方法,从而评估支持向量机、随机森林等多种分类模型,验证了随机森林具有高效的检测性能。
随机森林在金融数据分类任务中具有明显优势,但非平衡数据集引发的数据稀缺、噪声等问题会大幅降低分类准确性。因此,本文提出iForest-SMOTE 框架,对金融数据集进行样本均衡后使用随机森林分类器模型实现欺诈账户检测。
2 iForest-SMOTE 框架
iForest-SMOTE 框架如图1 所示。首先,在银行账户交易数据集中抽取分类特征,包括交易资金、交易网络、交易周期、有监督交易行为等特征,从而构建样本特征数据集;其次,为解决样本不均衡问题,利用iForest 进行特征数据集均衡预处理,得到异常样本数据集,并针对其中的多数类异常样本、少数类异常样本分别设计去采样、过采样数据均衡策略,实现样本自适应合成以达到类别数据均衡的目的;最后,采用随机森林分类器对类别均衡特征数据集进行欺诈检测。
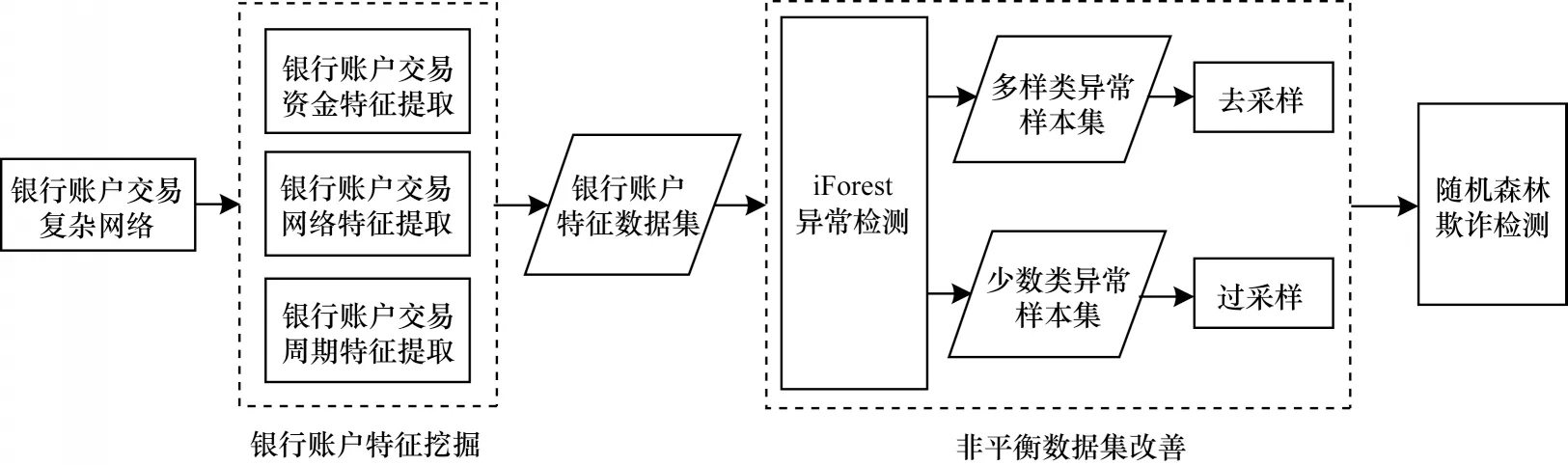
图1 iForest-SMOTE 框架Fig.1 The framework of iForest-SMOTE
2.1 基本定义
在详细描述iForest-SMOTE 欺诈账户检测框架之前,本文先给出一些基本的问题说明和定义。
定义1(银行账户数据集)一个银行账户数据集表示为D⊆C×B,其中,C={c1,c2,…,cn}为银行账户数据集信息,ci为账户i的数据,集合B={T,F}作为欺诈账户检测的标记集,T和F分别代表欺诈标记和正常标记,代表账户i的标记。在数据集D中,少数类记为P={p1,p2,…,ppnum},P⊆D,且=T,多数类记为N={n1,n2,…,nnnum},N⊆D,且=F。
定义2(分类特征集)设集合C={c1,c2,…,cn}是符合定义1 的银行账户数据集,ci的m维分类特征依次定义为交易行为特征值向量(a=1,2,…,lμ)、交易网络特征值向量(b=lμ+1,lμ+2,…,lν)、交易周期特征值向量(c=lν+1,lν+2,…,lξ)、有监督交易行为特征值向量(d=lξ+1,lξ+2,…,m),由所有ci的交易统计特征向量构成的集合记为银行账户分类特征集。
定义3(iForest 异常标记)给定银行账户数据集D,其分类特征集为Cxα,采用iForest 对D进行异常检测的模型可表示为:
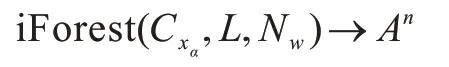
其中,L为iForest 中要选择 的iTree 数量,Nw为采样大小,A={Tspecial,Fspecial}为iForest 对账户的标记集,Tspecial和Fspecial分别代表异常和正常标记,表示iForest 对ci的标记。
定义4(样本预处理)给定标记集A,Dspecial⊆C为C中属于异常标记的预处理样本子集,其中,Dspecial满足如下条件:

定义5(异常样本集)给定Dspecial,其中,属于少数类的样本组成少数类异常样本集Pspecial,属于多数类的样本组成多数类异常样本集Nspecial,则Pspecial和Nspecial的数学定义如下(P、N详见定义1):

2.2 数据均衡策略
受到iForest 检测出的异常样本在不同类别中具有不同特性的启发,本文设计一种样本均衡策略。
多数类异常点指远离多数类的离群点。文献[23]采用去采样多数类(记为x∊Smaj)的方法减弱噪声数据对分类器的影响。去采样的核心是确定要筛除的多数类样本。远离多数类的离群点会成为噪声数据,致使分类器依据错误的样本学习。因此,本文将多数类异常点作为噪声源点,并将多数类异常点近邻的多数类样本构成的集合作为噪声簇,将多数类异常点和其对应的噪声簇从多数类中去除。
少数类异常点指在特征空间中分布稀疏、数量较少的离群点。过采样技术通过对少数类(记为Smin)进行人工合成数据,以解决小样本数据不均衡问题。过采样算法的核心[7]是确定每个少数类样本x∊Smin的合成样本数量k。ADASYN 首先计算∀xi∊Smin在Smaj中的密度分布,并 将作为权重衡量准则来确定xi的过采样次数ki。可见,值正比于集合S=Si-near⌒Smaj的大小,其中,Si-near为xi的KNN邻近样本集,高值样本分布在多数类高密度区域,该样本在分类器中难以被学习,因此,ADASYN 根据值赋予该类样本更多的过采样次数,使分类器更加关注难以学习的样本。
从上述分析可以看出,过采样通过对少数类进行样本合成从而使分类器充分地对少数类进行学习,进而提升决策性能,去采样因筛除了噪声数据而提升决策性能,过采样改善了数据集的不平衡性问题。然而,ADASYN 在处理S集合过大或决策边界混合严重的问题时,会面临跨决策区域合成数据的风险。欺诈账户的隐蔽性导致金融账户数据集中存在一定数量的少数类样本分布在决策边界和多数类内部,使用多数类的密度分布计算并合成样本会使多数类内部和决策边界出现大量的少数类合成数据,提高了分类器模型错误地学习样本的几率并加剧了决策边界的混乱程度。
为解决上述问题,本文利用异常点在特征空间的密度改进ADASYN 中的权重衡量准则ri,以提升分类器的欺诈检测性能。
2.3 特征抽取
在分类框架设计时需要考虑如何表示样本的类别特征以及避免特征集合冗杂等问题。根据定义2,银行账户的交易行为可量化为资金特征、网络特征、周期特征以及有监督的交易特征。
2.3.1 交易资金特征
将账户视为单一个体,其历史交易数据视为静态时序数据,可从统计角度表示其交易资金特征,则定义2 中的(a=1,2,…,lμ)具体表示为账号i收入和支出两种交易类型分别对应的资金相关统计项,如交易金额、交易次数等,交易资金特征如表1所示。

表1 交易资金特征汇总Table 1 Summary of transaction capital characteristics
2.3.2 交易网络特征
账户与其直接交易账户集合之间的资金流动构成了自我中心金融关系网络,据此,将账户的交易行为转化为一个局部中心网络,该网络的属性特征可视为账户的交易特征,则定义2中的(b=lμ+1,lμ+2,…,lν)为账户i的一阶关系网络特征,具体特征项如表2 所示。

表2 交易网络特征汇总Table 2 Summary of transaction network characteristics
如表2 所示,(b=lμ+1,lμ+2,…,lν)包括账户i的交易入度din、出度dout、根据进出交易对比得到的账户i的黑洞(账户转账远大于出账)和白洞(账户出账远大于转账)节点标记、根据网络计算出的LeaderRank 值[24]和对流边[25]账户之间的频繁交易等特征。
2.3.3 交易行为周期特征
账户的交易行为反映了持卡者的社会经济活动,则社会活动的周期性、规律性也会体现在交易数据上。以一个月为一个活动周期单位,分析账户交易的周期波动,则账户i的交易周期特征(c=lν+1,lν+2,…,lξ)如表3 所示。
2.3.4 有监督的交易特征
在异常检测任务中,若将已知的专家知识量化为分类特征,对优化分类器具有重要作用。这类特征与具体的欺诈类型相关,金融欺诈的实施方式、欺诈团伙的牟利模式、欺诈组织的运营方式等,均直接影响有监督交易特征的定义和量化。本文以传销欺诈组织为例,对此类特征进行说明。传销组织的资金流通方式多呈现金字塔形式,会员费(本文称为申购资金)自底向上流经固定的申购账户汇集到顶层账户;提成(本文称为返利资金)按比例从顶层经由返利账户下发给各会员。针对涉及传销的账户i,其(d=lξ+1,lξ+2,…,m)的各特征分量如表4 所示。

表4 有监督的交易特征汇总Table 4 Summary of supervised transaction characteristics
需要指出的是,本文提出的特征为串联关系,因此,若异常检测任务缺乏背景知识则特征值向量可忽略此类特征。
2.4 基于iForest 的数据均衡预处理
如上文所述,金融交易数据中正常账户、欺诈账户样本的不均衡问题,严重影响欺诈账户检测模型的性能。为此,本文提出一种基于iForest 改善非平衡数据集的策略。采用iForest 进行异常子集筛选,以获取银行账户特征数据集中的异常样本集,进而将其划分成多数类异常样本和少数类异常样本,分别对上述两类样本采用欠采样和自适应生成合成样本的方式实现类别均衡。
2.4.1 基于iForest 的异常子集筛选
本文首先对所构建的银行账户特征数据集进行iForest 异常检测,为每个账户样本分配一个异常账户检测标记,其次根据样本的异常检测标记对样本进行预处理,最后根据预处理样本子集中样本的欺诈标记对样本进行筛选,以获取少数类异常样本集和多数类异常样本集。具体过程如下:
1)通过iForest 对特征数据集Cxα进行检测并得到每个特征样本的标记集:
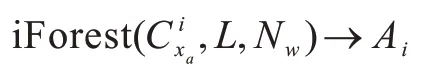
2)将标记集An中标记为Tspecial的样本加入到Dspecial中,对于∀ci∊C,如果=Tspecial,则Dspecial=Dspecial‿ci。
3)对预处理样本子集的样本进行筛选:对于∀cj∊Dspecial,如 果∃cj∊N,则Nspecial=Nspecial‿cj,如 果∃cj∊P,则Nspecial=Nspecial‿cj。
在具体实现过程中,分别表示银行账户特征数据集、iTree 的数量、数据采样大小,N、P是符合定义1 的多数类和少数类,是符合定义3 中ci样本的异常标记,Dspecial是符合定义4 的预处理样本子集,Nspecial和Pspecial分别为符合定义5 的多数类异常样本集和少数类异常样本集。
2.4.2 多数类样本去采样
本节将对2.4.1 节筛选的多数类异常样本进行欠采样处理,以减少嘈声样本对决策的影响,具体过程如下:
1)对于每一个多数类异常样本ci∊Nspecial,计算距离ci最近并且属于多数类的K1个邻近样本ci-near,将ci-near构成ci的噪声簇:
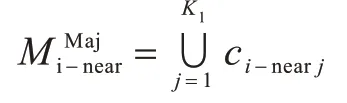
2)将每一个多数类异常样本ci∊Nspecial和ci对应的噪声簇从多数类N中去除:
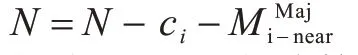
样本之间距离计算采用欧几里得距离:
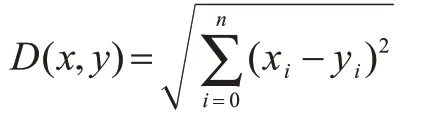
其中,x、y为空间中的任意两个样本,xi和yi为对应的i维度的数值。
2.4.3 少数类样本过采样
1)计算需要生成的合成数据数量G:

其中,θ∊[0,1]为用户定义参数,用于指定生成合成数据的水平,当θ=1 时将得到完全平衡的样本集。
2)计算针对每个少数类样本pi∊P需要合成的数据数量gi,计算过程如下:
对于∀pi∊P,首先计算距离pi最近的K2个近邻样本构成的近邻样本集Di-near,其次计算Di-near中少数类异常样本cj∊Pspecial所占的比重ri:

3)对少数类样本进行样本合成。对于每一个少数类样本pi,进行gi次样本合成,在合成人工数据时,本文选择近似SMOTE[17]中的数据合成方法,具体过程如下:
对每个少数类样本pi进行gi次循环,每次循环步骤为:
步骤1计算距离pi最近的K3个属于少数类的近邻样本并构成近邻样本集
步骤2在中随机选择一个少数类样本pzi。
步骤3根据pzi和pi的特征进行人工数据合成,合成公式如下:

其中,sxi是合成样本的特征,pxi和pxzi分别是少数类样本pi和pzi符合定义2 对应的特征向量,(pxzi-pxi)为n维空间中特征的差失量,λ是随机数,λ∊[0,1]。
步骤4赋予合成的特征向量少数类标签Bsi=T,并将对应的样本si加入少数类中,P=P‿si。
结束循环。
本文通过赋予少数类异常点和其临近样本更高的权重来调整合成样本的数量,不仅实现了样本均衡还降低了跨区域合成的风险,同时合成的样本会提高少数类异常样本附近的少数类密度,降低内部小杂项出现的概率,通过合成样本能够转移少数类的决策边界。
2.5 欺诈账户检测模型
iForest-SMOTE 首先通过对银行账户数据进行特征抽取并生成特征数据集,再通过银行特征数据集实现类别均衡,得到样本均衡数据集Dbalance,随后采用随机森林分类模型检测欺诈样本,分类器的输入为Dbalance中样本平衡特征数据集,输出为分类模型对每个样本的分类结果。
3 实验与结果分析
3.1 实验环境与数据集
本文实验的硬件环境为Inter®CoreTMi7-7700HQ,内存(RAM)为16 GB。软件环境为Python 语言,Windows 10 操作系统。实验数据为由经侦部门提供的脱敏资金交易数据,其中包括正常金融账户和欺诈账户四年内产生的银行交易数据,每条交易数据包括交易双方账户、交易方向、交易时间、交易金额等属性,共涉及账户15 633 个,传销账户为1 303 个。数据集含有总账户交易数据227 179 条,传销账户交易数据64 630 条。实验将数据转化为7 859 条银行账户数据,其中属于少数类的账户数据共778 条,属于多数类的账户数据共7 081 条,多数类和少数类节点比为10∶1。随机抽取数据集中70%的数据作为训练集,其余30%的数据作为测试集。
3.2 分类效果衡量指标
随机森林是用于分类和预测的组合分类器,分类效果是评价分类器性能的典型指标。本文使用混淆矩阵作为分类器的性能衡量指标,混淆矩阵详见表5。

表5 混淆矩阵Table 5 Confusion matrix
其中,TP 表示真实值和分类结果均为欺诈,FN 表示真实值为欺诈而分类结果为正常,FP 表示真实值为正常而分类结果为欺诈,TN 表示真实值和分类结果均为正常。
本文采用准确率、召回率、精确率、F-value 值评价模型的分类效果。准确率Accuracy 为分类模型所有判断正确的样本数占样本总数的比例;召回率Recall 为在模型预测为欺诈的样本集合中,真实值也为欺诈的样本数占所有真正为欺诈的样本总数的比例;精确率Precision 为在被模型预测为欺诈的所有样本集合中,真正为欺诈的样本比例;F-value 值从少数类的角度综合评价随机森林的性能,它是召回率和精确率的组合。
3.3 实验结果
3.3.1 采样均衡策略评估
在非平衡数据欺诈检测问题中,由于欺诈类别属于少数类,因此少数类的分类准确率对于评价分类模型更有意义,本文采用召回率Recall、精确率Precision、F-value 值等指标在少数类上的平均得分来评价不同欺诈检测模型的性能。为了验证本文iForest-SMOTE 框架对不均衡数据集的优化效果,统一对不同算法处理后的特征数据集采用随机森林进行欺诈检测。特征数据集包括分别经过随机过采样算法(RamdonOverSampler)、ADASYN 算法、SMOTE算法、iForest-SMOTE 框架处理后的数据集以及只进行特征提取的数据集。随机森林对不同特征数据集的检测效果如表6 所示。其中,使用下划线标出每项指标的最佳取值,并加粗显示本文算法(iForest-SMOTE)的各项指标取值。
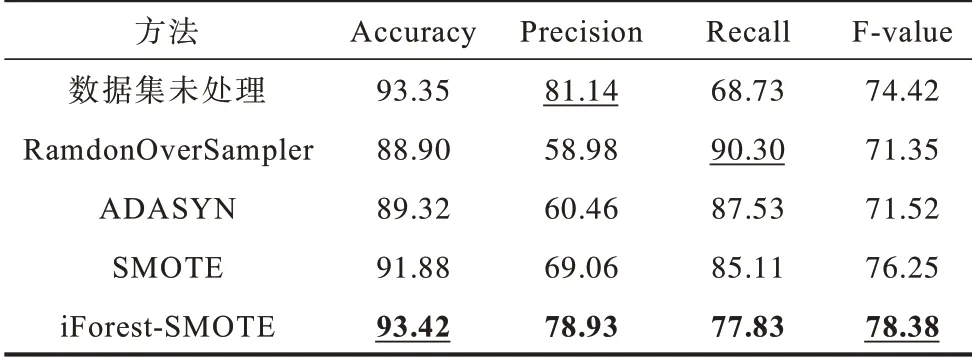
表6 不同方法的性能比较结果Table 6 Performance comparison results of different methods %
由表6 可知,尽管某些算法(如ADASYN)的召回率Recall 指标具有较高水平,但其他指标大多处于较低的水平,导致综合指标F-value 值偏低。ADASYN 的F-value 值较低说明其存在跨区域合成样本的风险,不适合用来解决金融数据集的非平衡问题。与其他算法相比,本文iForest-SMOTE 模型在召回率和准确率方面都处于较高的水平,F-value 相比对比算法至少提升2.13 个百分点。综合各项指标得出,iForest-SMOTE 框架能够为检测模型提供更好的特征集合筛选功能,可以明显提高分类器的欺诈账户检测能力。
ROC 曲线可以描述分类器的性能,是针对不平衡技术的重要判断依据,ROC 曲线越靠近左上角表示非平衡技术越能提升分类器的性能。图2 所示为金融账户数据集的ROC 曲线。
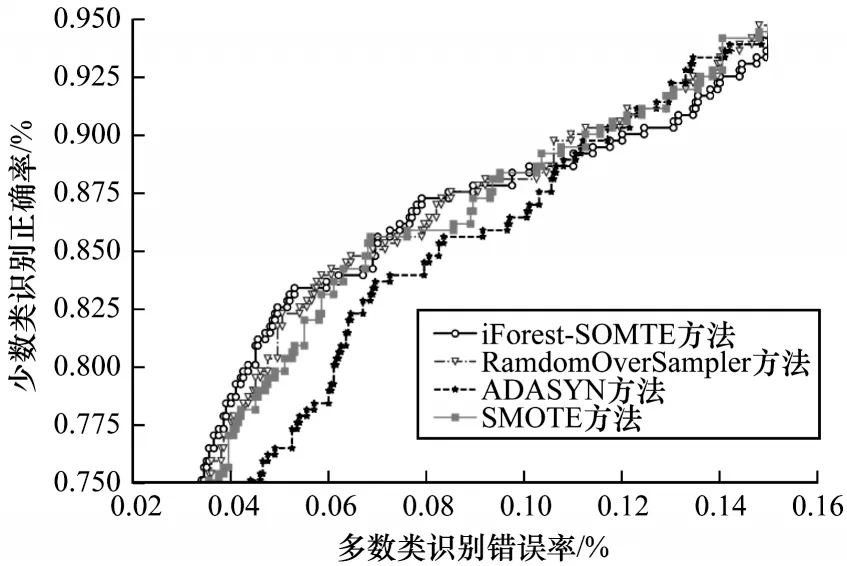
图2 不同分类方法的ROC 曲线Fig.2 ROC curves of different classification methods
从图2 可以看出,各个方法的分类性能较为接近,其中,iForest-SOMTE 具有相对较高的少数类识别正确率。ROC 曲线下的面积可以用来度量非平衡分类模型的功效,通常将该度量值称为AUC,AUC 值介于0 和1 之间,其中,0.5 为随机猜测值。在非平衡数据集中,AUC 值更加能够体现两个类别的正确性。不同方法的AUC 值如表7 所示。

表7 不同方法的AUC 值Table 7 AUC values of different methods %
由表7 可知,iForest-SMOTE 具有较高的AUC 值,表明其对金融不平衡数据集具有更好的处理效果。
3.3.2 分类特征重要性评估
通过随机森林对特征重要性的评估,可以了解每种特征在构建决策模型时的重要性,这为后续的特征筛选提供了一定支撑,有利于提高模型的鲁棒性。本节对提取的每维分类特征在决策中的重要性进行评估。
随机森林特征重要性评估的思想为:比较每个特征在随机森林的所有决策树上分类贡献的平均值,然后比较特征之间的贡献值大小。本文采用基尼指数评估重要性,对于特征xj,计算在随机森林的每一颗决策树中由特征xj形成的分支节点的基尼指数Gini(p)下降程度之和(基尼不纯度下降程度)。其中,基尼指数Gini(p)为:
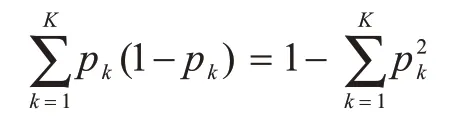
其中,K代表类别个数
特征xj的重要性评估过程具体如下:
1)计算特征xj在决策树中节点m处的下降程度
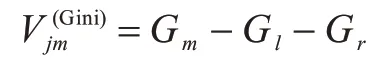
其中,Gl和Gr表示在决策树中节点m分支前后两个新节点的Gini 指数。
2)计算特征xj在决策树i上的特征重要性:
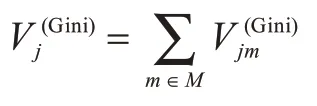
其中,m为特征xj在决策树i中出现的节点,M为节点m的集合。
3)计算特征xj在随机森林中的分类重要性:

其中,n为随机森林中的决策树数量。
4)对所有特征的重要性评分进行归一化处理,特征xj的重要性评分为:

其中,c为特征的总数量。
根据上述方法,本文提取的金融账户分类特征集合中每维特征的重要性如图3 所示,其中,银行账户特征中LeaderRank 值(编号14)、入度(编号12)、出度(编号13)等特征的贡献占比较高,由此可知,这三个特征对辨识欺诈账户尤为关键,表示交易网络特征(编号7~编号14)对欺诈账户检测具有重要作用。此外,银行账户交易资金特征(编号1~编号6)的特征贡献度总体相对较低,但体现账户交易敏感资金和交易敏感次数的申购返利特征(编号29~编号40)具有较高的贡献占比,说明在传销账户识别中,账户的申购和返利交易能有效区分欺诈账户和正常账户,即有监督交易特征在提升欺诈账户检测性能中具有重要作用。

图3 分类特征的重要性程度Fig.3 Importance degree of classification features
4 结束语
本文设计一种欺诈账户检测框架iForest-SMOTE。针对实际数据中欺诈样本不均衡的问题,结合iForest 对异常边界的识别能力与ADASYN 对决策边界的样本合成思想,改善分类器的训练数据集。分析样本在交易的时序、关系、周期及有监督异常行为方面体现出的判别特征,进而组合生成分类特征数据集。iForest-SMOTE 中的随机森林分类模型用于提高分类准确性并实现对各分类特征的重要性评估。在真实含有传销欺诈账户的数据集上进行实验,结果表明,iForest-SMOTE 在严重不均衡数据集中仍能取得较高的识别准确率。下一步将在无监督的数据集上实现异常边界调整,以改进无标签非平衡数据的异常检测效果。
