Towards Collaborative Robotics in Top View Surveillance: A Framework for Multiple Object Tracking by Detection Using Deep Learning
2021-06-18ImranAhmedSadiaDinGwanggilJeonFrancescoPiccialliandGiancarloFortino
Imran Ahmed,, Sadia Din, Gwanggil Jeon,, Francesco Piccialli,, and Giancarlo Fortino,
Abstract—Collaborative Robotics is one of the high-interest research topics in the area of academia and industry. It has been progressively utilized in numerous applications, particularly in intelligent surveillance systems. It allows the deployment of smart cameras or optical sensors with computer vision techniques,which may serve in several object detection and tracking tasks.These tasks have been considered challenging and high-level perceptual problems, frequently dominated by relative information about the environment, where main concerns such as occlusion, illumination, background, object deformation, and object class variations are commonplace. In order to show the importance of top view surveillance, a collaborative robotics framework has been presented. It can assist in the detection and tracking of multiple objects in top view surveillance. The framework consists of a smart robotic camera embedded with the visual processing unit. The existing pre-trained deep learning models named SSD and YOLO has been adopted for object detection and localization. The detection models are further combined with different tracking algorithms, including GOTURN, MEDIANFLOW, TLD, KCF, MIL, and BOOSTING.These algorithms, along with detection models, help to track and predict the trajectories of detected objects. The pre-trained models are employed; therefore, the generalization performance is also investigated through testing the models on various sequences of top view data set. The detection models achieved maximum True Detection Rate 93% to 90% with a maximum 0.6% False Detection Rate. The tracking results of different algorithms are nearly identical, with tracking accuracy ranging from 90% to 94%. Furthermore, a discussion has been carried out on output results along with future guidelines.
I. INTRODUCTION
COLLABORATIVE robotics has been gaining the attention of researchers and emerging as a key technology in different areas such as industry, manufacturing, transport,domestic task handling, entertainment, healthcare services,navigation, localization, and most prominently in intelligent video surveillance. The need for intelligent surveillance systems has been increasing day by day. Several optical devices (cameras and sensors) have been installed in public places for security and monitoring purposes. The majority of surveillance systems consist of a centralized monitoring structure (a single room where multiple camera recording videos have been observed/monitored by human operators).Monitoring multiple video streams, however, may be a tedious task for the security operators/officials. Therefore, it is desirable to use collaborative robotics and provide such an intelligent automated surveillance system that monitors and analyzes multiple video streams and helps human operators as much as possible. Collaborative robotics helps to expand the surveillance system’s potential by utilizing smart camera devices and visual processing technology. The primary objectives of such collaborative robotics-based surveillance systems are to provide useful information about different activities in a specific environment or scene. It provides information that may help in behavior analysis, events and activity analysis, managing and protecting people in crowded environments, movement pattern detection, and tracking objects. These are considered as important with wide range of real-life applications, e.g., security analysis, [1], [2]autonomous or self-driving vehicles, [3], face recognition [4],human-computer interaction (HCI) robotics [5]–[7], and [8]location and navigation. These applications may suffer from several factors, including variations in object appearances,(sizes, body orientations, poses), different backgrounds,illumination conditions, cluttered scenes and camera viewpoints, abrupt variations in motion, and close interaction of objects and most importantly occlusion.
A number of deep learning, machine learning and computer vision based methods have been presented to cope with these challenges by providing robust and efficient solutions [9],[10]. Majority of the developed approaches are primarily based on traditional handcrafted features [11]–[16] along with different machine learning classifiers [17]. Recent advancement in deep learning models makes object detection[18]–[24], and object tracking [25]–[28] and [29] methods more robust, efficient in terms of computation speed and accuracy. The key advantages of these models are automatic selection of most salient features of objects and having stronger classification probability as compared to laborious handcrafted features which requires extra training of images[30]. Furthermore, these models usually have more discriminative power in terms of multi class object classification regardless of their scale, size, pose, location,appearance with respect to the camera position, illumination,background condition and occlusion.
Majority of techniques either feature-based or deep learning-based, generally developed for normal, horizontal, or frontal view object detection and tracking, without utilizing collaborative robotics setup. Mostly researchers developed different object tracking methods, e.g., [25], [26], [28], [29],commonly based on frontal or asymmetric camera perspective as shown in Fig. 1. These methods have their robustness,detection, and tracking reliability for different applications,but still suffered from occlusion challenges as highlighted in Fig. 1.

Fig. 1. Frontal view object detection and tracking: sample images taken from [31]–[35] showing variation in object appearance (scale, size, pose) also highlighting occlusion problem.
In contrast, with the frontal view, if a similar object is captured and viewed from a top perspective, occlusion problems may be reduced. Likewise, using the top view perspective provide more visibility of the scene, and the object is more visible to the camera Fig. 2. In order to minimize occlusion problem, some researchers [36]–[38] suggested and utilized top view images or video sequences for object detection and tracking. Ahmadet al.[44 ] suggested that replacing multiple frontal view cameras with a single top view camera may overcome power consumption, human resource,and installation expenses. The perspective change in camera position also causes significant variation in the object's appearance in terms of posture, size, body articulations, and visibility, as highlighted in Fig. 2.

Fig. 2. Top view object detection and tracking: sample images taken from[37]–[43], showing variation in object appearance (scale, size, pose) in top view perspective also handle occlusion problem.
This work introduces a collaborative robotics-based framework for top view intelligent surveillance system,capable of detecting and tracking multiple objects. A smart robotic camera is used with a processing unit that can facilitate human operators during surveillance and suitable for real-world applications. For object detection existing deep learning models, you only look once (YOLO) [22] and single shot detector (SSD) [23], trained on frontal view data sets have been practiced. The top view data set, containing video sequences of multiple objects against various backgrounds,has been used for testing purposes. Object detection models are further combined with six different algorithms, including GOTURN, MEDIANFLOW, TLD, KCF, MIL, and BOOSTING, to track the objects in top view scenes. This paper mainly focused on the following:
1) A framework is introduced for top view collaborative surveillance that can assist human operators in multiple object tracking and detection tasks. The structure consists of a smart robotic camera with a visual processing unit that used deep learning-based pre-trained object detection models.
2) Generalization performance of frontal view pre-trained object detection models has been investigated by testing on completely different data set, i.e., top view data set. It contains video sequences of multiple objects recorded from top view with various sizes, poses, body orientations, shapes, and camera resolutions in different background and illumination conditions.
3) Top view object tracking is performed by combining deep learning object detection models with different tracking algorithms. A comparison of six tracking algorithms, along with object detection models, have also been made.
4) The importance of top view multi-class multi-object detection and tracking over a traditional or frontal view,specifically in video surveillance, is explored with possible future direction.
The work presented in this paper is ordered in the subsequent sections. The summary of the present work used for object tracking and detection tasks is provided in Section II.The recorded top view data set is explained in Section III.Deep learning-based object detection models employed for top view data set and different tracking algorithms have been elaborated in Section IV. Section V provides a detailed explanation of output results, performance evaluation of object detection models, and comparison results of different tracking techniques. The conclusion of the paper with possible future directions is presented in Section VI.
II. LITERATURE REVIEW
A summary of different object tracking and detection approaches has been presented in this section. The developed methods are mainly categorized in traditional generic,features, deep, and machine learning-based models. A comprehensive study of various tracking and detection techniques is also found in [9], [10], [45], and [46].
A. Feature Based Methods
Early object detection techniques are based upon handcrafted features. Researchers designed sophisticated feature based methods such as color histograms [47],attributes [48]–[50], traditional handcrafted features including histogram of oriented gradient (HOG) [14], [51], local binary patterns (LBP) [13], Haar-like features [12], [52], scale invariant feature transforms (SFIT) [15], and shape based features. These methods mainly extract most prominent object features, which are further utilized for training and testing of machine learning algorithms, e.g., support vector machine(SVM) [53], boosting [52], random forest [54], Hough forest[55], and structural learning [52], [56]. Besides with object detection, traditional object tracking methods are categorized into frame differencing, optical flow, and feature-based methods. The traditional tracking algorithms focused on the target position in video sequences and prediction using filterbased methods, e.g., Particle and Kalman filter.
Some researchers used appearance features like shape,color, and texture to track different objects across the frame[57]. Other researchers used a template-based [58] and sparse representation [58] based methods for object tracking by concentrating on searching region, similar to the tracked target. To differentiate the background and foreground, some researchers developed discriminative feature learning [59]based algorithms. Many of them used object features similar to object detection methods. Reference [60] presented a method for object tracking, combining multiple detection features with the probabilistic segmentation technique. Most of the developed detection and tracking techniques are based on data sets recorded from frontal view, that might suffers from the occlusion problem, as discussed in the Section I. To overcome this problem many researchers [36], [61]–[65] used and suggested top view camera perspective. In [66], authors provide a top view feature-based method for person detection in an industrial and indoor environment. In another work [67],developed a feature-based method for tracking people in the top view industrial environment. Reference [68] used blob based method and provided a rotation-invariant person tracking solution for top view surveillance. The authors in[69] used an efficient rotated HOG based method along with SVM classifier for overhead view person detection.
B. Deep Learning-Based Methods
Recent growth in deep learning-based models, capable of learning high-level image/video frame features, object detection, and tracking methods, start evolving with unprecedented speed. Deep learning models are characterized by two-stage and one-stage detection frameworks. The first detection framework is developed by [70] by proposing Regions with CNN features. In [70], each region proposal is scaled into the fixed-sized image and fed into the training CNN model. Reference [71] proposed a two-stage object detection model using a particular pyramid pooling network for object identification. The model consists of CNN layers,which enable the generation of fixed-length representation features regardless of the image’s rescaling. Another twostage object detection method is proposed by [20], which enables to train bounding box regressor and detector simultaneously at the same network using the Pascal VOC data set. Reference [72] developed first real-time end to end model for target detection. In Faster-RCNN, the authors move individual blocks of region proposal detection, bounding box regression, and feature extraction at the end to end integrated network, making it fast compared to former models. The COCO [73] has been employed for training and testing of the developed model. Another two-stage object detection model has been developed by [74] based on [72] and gives the advantage to classify objects with a wide range of scale variations. Redmonet al.[22] presented a one-stage object detection model named YOLO, a single neural network is employed on the whole image that extracts regions and predicts bounding box and probabilities for each region proposal. The improvement has been made by [75] and [76],which further enhanced the detection accuracy of the previous model. Another one stage detection model is proposed by Liuet al.[23] named as single shot multibox detector (SSD). It introduces a multi-resolution and multi-reference detection framework. [18], [21], and [24] also used deep learning models which show their robustness, efficiency and accuracy in different object detection applications.
The researchers also developed deep learning-based object tracking methods [25], [26], [28] and [29]. The deep learning tracking frameworks detect the object and store it in the form of features information, which is further used for tracking purposes. Numerous method [60], [77]–[82] have been proposed that used the neural network architecture for object tracking. Reference [83] developed a feature-based visual object tracking method that mainly used a pre-trained detection hierarchical network. Likewise, taking advantage of the region proposal network [84] used a recurrent convolution network model for object tracking. Reference [85] developed a neural network-based online object tracking technique using the frontal view data set. Reference [77] used a pre-trained network of deep layers for human tracking via frontal view images. Furthermore, [82] developed a generic feature-based object tracking method robust against several object appearance variations. Other CNN based object tracking methods were developed by [31], [86], similar as [21], using proposal information to track pets. Reference [81] adopted the CNN model and produced discriminative saliency maps,which were further combined with SVM to track the object from the frontal view. For object feature extraction they adopted DLT [82] and CNNSVM [81] classifier. Cuiet al.[87] proposed RNN based object tracking method using the correlation filter. References [86] and [88] also developed CNN based trackers.
Majority of the developed deep learning models used frontal view images. Some of the researcher performed object detection and tracking tasks using aerial and satellite images[42], [89]–[92]. Some researchers used deep learning for top view object detection and tracking, but their work was mainly for a single class object, person [42], [93], and [94]. Ahmedet al.[43] applied two-stage detection models for top view multi-class object detection. In [43] used Mask-RCNN and Faster-RCNN for top view object segmentation.
III. DATA SET
Video sequences used in this work are recorded in the real world, uncontrolled environment, having variation in illumination conditions and backgrounds in different indoor and outdoor environments. The movement of the objects is also not restricted within the scene. Two top view scenarios are considered, in the first scenario (symmetric top view) the object is observed under the camera from a specific camera height. The newly recorded data set provides better visibility and wide coverage of the scene. The appearance of a different object in the symmetric top view is different from the frontal view, as shown in the sample frames of the experimental results section. In the second scenario (asymmetric top view),the object is observed at a different location from the centrally mounted camera. The appearance of the object is significantly varied with respect to the camera. Multiple objects are considered during the recording, such as motorbikes, cars,trucks, buses, and most prominently persons. The distribution of different objects in indoor and outdoor environments are variable. The number of object classes varies but mainly focuses on a person as it is counted as one of the important objects in video surveillance [43] and [69]; therefore, the large portion of our data set comprises person video sequences in outdoor and indoor environments. The sample frames of the experimental results section highlighted the change in the object appearance cause by changing the camera perspective.The data set provides variation in object appearance (size,scale, poses, and orientation) with respect to the camera position. Mainly, it is recorded in surveillance environments in different day timings covering different views. Different camera devices have been practiced. The detail of the data set is elaborated in Table I.
IV. SYSTEM OVERVIEW
In this work, we have introduced a top view collaborative video surveillance framework, as described in Fig. 3. The overall framework is comprised of a top view smart robotic camera source and a visual processing unit. The top view robotic camera is used for recording video sequences in different indoor and outdoor environments. The visual processing unit is embedded with a smart camera responsiblefor observing the scene and performing multiple object detection and tracking tasks. The visual processing unit results are sent to the surveillance monitoring room/maintenance room, where it assists/helps human operators to control and monitor surveillance systems. The framework helps human operators with multiple surveillance applications highlighted in Fig. 3.

TABLE I DATA SET
The detail of the visual processing unit is presented in Fig. 4.The visual processing unit is the combination of two modules:one for object detection and other for tracking. The detection module aims to localize and detect the object in top view video sequences. While the tracking module helps in tracking the object in the top view scene. The video sequences after conversion into subsequent frames are fed into the object detection module. For top view object detection, existing deep learning models YOLO [22] and SSD [23] have been adopted.The frontal view data set [73] was utilized for the pre-training of both models. The models produce a detected bounding box,class label, and identified object confidence score at outputs.This information is stored in the list, which further helps in object tracking. A tracker is initialized, which assigned tracking ID to each detected object. Six different pre-built trackers are used for tracking purposes, including GOTURN,MEDIANFLOW, TLD, KCF, MIL, and BOOSTING. All of these tracking algorithms are developed for the frontal view data set. In this work, trackers used the detected output bounding box information to track the object from a top view.The following subsections provide a detailed explanation of the different tracking algorithms and deep learning-based object detection models.
A. Object Detection Using Deep Learning Models

Fig. 3. A collaborative framework for top view video surveillance. The visual processing unit is embedded with smart robot camera so that the object detection and tracking are performed that may assist/facilitate human operators in top view surveillance applications.

Fig. 4. The flow diagram of the top view multiple object detection and tracking.
1) YOLO Based Object Detection:This section briefly discusses the first deep learning model YOLO [22] applied for top view multiple object detection. It is faster and more generalized than other regional proposal architectures (twostage detection models) discussed in Section II, which involves various object detection steps. It localizes the object along with its predicted class using a single network structure.As it used the same integrated network, therefore forcing the classifier to extract specific region proposals that exactly contain the object. It also helps in reducing false positives present in background areas. The model is quite useful in terms of accuracy and computation. Because of these characteristics, we adopted this as the first model for top view object detection—for top view object tracking, the detection model is further embedded with tracking algorithms. The general structure of the model is described in Fig. 5. It simply takes the input image, passes it over convolutional layers, and gives a vector of bounding boxes with object confidence value and class label prediction. The YOLO model [22] was trained using the frontal view COCO data set [73]. It has an additional batch normalization layer, which makes network convergence faster. The model can randomly adjust the input image size during training, improving the detection results during testing of multi-scale images. The YOLO model’s general structure for top view multiple object detection, demonstrated in Fig. 5 is explained in the following steps:
i) The model is composed of Darknet architecture and convolutional layers. The pre-trained model composes of 2 phases. Firstly, the classifier network was trained like VGG-16. The fully connected (FC) layers for the object detection using the PASCAL VOC data set convolution neural network were evaluated. Initial convolutional layers are used to extract features, and connected layers are used to predict output probabilities along with bounding box’s coordinates. The original model used twenty-four convolutions layers.

Fig. 5. YOLO [22] based object detection using top view.
ii) Unlike two-stage detectors or region based approaches,i.e., (Faster RCNN, Fast-RCNN, and RCNN), which uses the local area for detection, YOLO model used entire image features. The model firstly divides the image into associated(S×S) size grid cells, as shown in Fig. 6(a). For individual grid cell,
– The model predicts boundary boxesBwith a confidence score.
– Only one object is detected despite the number of detected boxesB.
–Cconditional class probabilities are predicted (one for per class object probability).
The center of each object present in the image falls within the grid cell; then, it predicts random bounding boxes for objects. As depicted in Fig. 6(c), instead of predicted different bounding boxes for one object in the whole image, the model predicts five different bounding boxes.
(2)分析:63版棱柱教材的结构体系:概念—(基本)性质—表示—分类—直棱柱的性质、正棱柱的性质;平行六面体及其分类(斜、直)与性质—长方体—立方体,长方体的性质(对角线定理);棱柱的截面;直棱柱的画法.这是一个典型的公理化体系,大致按照“概念—表示—分类—性质”的路径,从一般到特殊(逐步增加条件)展开研究.几何体的内容放在点、直线、平面的位置关系之后,逻辑严谨,研究的内容非常丰富.内容选择做到重点突出.一如既往地,直接呈现结论,没有任何“闲言碎语”.
iii) The predicted bounding box has five components: width,height,w, andhandx,ycoordinates, and confidence value.The coordinate information illustrates the center of the bounding box, as shown with a green dot. Thewandhrepresents the dimension (width & height) of the bounding box (Fig. 6(d)).
iv) Fig. 6 depicts that the model predicts individual objects only if it falls within the grid cell; else, the grid cell value becomes zero. The coordinate dimensionsx,y,w,h, and confidence value is calculated for each bounding box. When the bounding box is detected, the class prediction has been made in the next step, which classifies the object to its labeled class. From Fig. 6(d), each bounding box class is assigned to a particular object, e.g., person and car. Finally, an objective function is calculated as a combination of conditional class probabilities and localization (x,ycoordinates, andw,hinformation). Both values are calculated as the sum of squared errors [22].
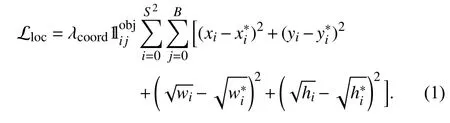

Fig. 6. Overall top view deep learning-based object detection process using[22]. The video frame is divided into S×S cells (a), bounding boxes are predicted for each cell (b) as an object has an arbitrary shape so different anchor box is predicted for one object (c) finally, the bounding box is predicted for an object in (d) the blue is the predicted bounding box for object and green dot represents anchor region.
In the above equations λcoordis the scale parameters used for bounding box coordinates predictions.x,yare the predicted positions, whilex∗,y∗are the actual positions of bounding box. The above equation calculates the loss function related to the predicted bounding box having coordinates valuex,y. The term λ is constant, the above function calculates sum over each bounding box, using (j=0 toB) as predictor for each grid cell (i=0 toS2). The function is defined as [22]:
–If the target object is present in thejth bounding box andith grid cell, then function is equal to 1 otherwise it becomes 0.
Now, moving to the second part of loss function related to the object class probability and confidence value given as [22].


Fig. 7. SSD based [23] object detection using top view.


2) SSD Based Object Detection:The second model used for top multiple object detection is SSD [23]. This section briefly explains the general architecture of SSD, which shows excellent results for generic object detection. It uses convolutional neural networks as pyramidal feature hierarchy for the detection of various sized objects. The general architecture of the SSD model used for object detection using a top view is represented in Fig. 7 is explained in the following steps:
i) The model used the VGG-16 pre-trained network for useful feature extraction. Further, it adds several additional convolution layers as features extraction layers with decreasing sizes can be seen in Fig. 7. These layers are called pyramid representations of different scales of images. On each pyramid layer, object detection happens for several size objects.
ii) Unlike the above discussed model (YOLO), the image is not split into arbitrary size grid cells [95]. It usually predicts the predefined bounding box for all spatial locations of the feature map, which is further responsible for one particular scale of the object, as shown in Fig. 7. In Fig. 8, a higher-level feature map is used for the detection of a large object while the lower-level feature map is used for small-sized object detection. It typically estimates four default bounding boxes or corners, particularly for every location, with different scales and aspect ratios, as seen in Fig. 8. Thus, confidence scores and shape offsets are predicted at each location for each object category, Fig. 8.
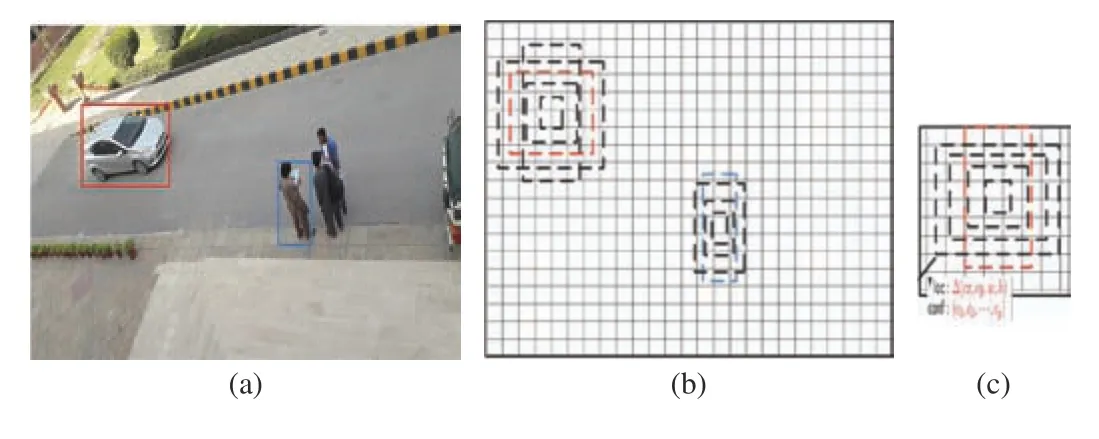
Fig. 8. Two types of feature maps (coarse-grained and fine-grained) are used for small and large object detection.
iii) Each bounding box is either preserved as positives or negative boxes. The loss function is calculated using ground truth and the default bounding box information; it only predicts positive values and ignores the negative ones. Similar to the previous model, the loss function is calculated as a combination of two functions: localization and classification loss. The loss function is given as [23].

The second loss shown in (4) is the localization loss [23]calculated as

B. Object Tracking Algorithms
In Fig. 4, it can be visualized that for tracking purposes, the output of each detection model is stored in the form of the list.A tracker is initialized using different tracking methods. After the initialization of the tracker, we manually select the tracking algorithm. The tracking algorithm checks for object information in the list and starts tracking it from the top view.In the object tracking module, if the detected object’s value in the list is greater than 0, the tracker is continuously updated,and the object is tracked. In this work for top view multiple object tracking, we used six different tracking algorithms:GOTURN, MEDIANFLOW, TLD, MIL, KCF, and BOOSTING implemented in OpenCV. These algorithms are originally proposed for frontal view object tracking. The detected bounding box information extracted from object detection models is utilized to create a tracker list. The tracker list stores this information and tracks the multiple objects in the top view data set. The visualization results of tracking algorithms are elaborated in the experimental results section.Tracking algorithms used in this work are discussed as follows:
1)BOOSTING Tracker:A robust and real-time tracking technique is developed by [96] using 20 fps (frame per second). The limitation of this technique is that it considered tracking an object as a binary classification problem(background and object). For tracking, it considers the most discriminating features. The algorithm is similar to Haar cascades (e.g., Haar-like wavelets, local binary patterns,orientation histograms). It is slow and does not work well as compared to others.
2)MIL Tracker:Babenkoet al.[97] developed a method for object tracking known as multiple instance learning (MIL),that solves the problem of adaptive appearance model learning. It employs a discriminative classifier to classify the object from the background. It permits to update the appearance model utilizing image patches without knowing which image patch is responsible for capturing the object of interest. The accuracy is better in comparison with the BOOSTING tracking algorithm but suffers during reporting failure.
3)KCF Tracker:To overcome the computation burden of the discriminative classifier, Henriqueset al.[98] developed a fast learning and detection model using a fast Fourier transform. Reference [98] used a space kernel machine with linear classifiers. The model analyzed consequences using dense sampling in tracking. It is faster than the above two but does not handle occlusion and suffers from failure when there is variation in the size and position of an object.
4)TLD Tracker:In [99], authors examined long-term tracking algorithm for different objects in video sequences.The developed framework for tracking, learning, and detection (TLD) decomposes the long-term tracking task. The tracker localizes all observed appearance of the object in video sequences and each frame. It immensely suffers from false-positives.
5)MEDIANFLOW Tracker:Kalalet al.in [100] developed a method based on Forward-Backward error. In [100], the authors measured forward and backward differences between two trajectories of the target. The proposed algorithm detects the faults and helps in the discovery of tracking failures and the selection of tracking paths. It is suitable for reporting failures but runs out whenever there is a massive jump or variation in motion, a sudden change in appearance, and fast motion.
6)GOTURN Tracker:The generic object tracking using regression networks (GOTURN) [101] based on CNN layers.The architecture is primarily trained (mainly frontal view video sequences) on thousands of crop frames. The algorithm provides excellent results and handles several variations, e.g.,(viewpoint, lighting changes, and deformation) during tracking, but it does not manage occlusion very well.
The overall algorithm for the top view, multiple object detection, and tracking framework shown in Fig. 4 is explained in Algorithm 1. The pre-trained deep learning models are applied on top view video sequences. The pretrained models’ output has learned features, which are used for detecting objects along with the bounding box and confidence score value. The detected bounding box information is stored in the form of a list. The list contains coordinate information of each detected object (x,y,w,h), its class label (e.g., either a person or other object) and its confidence value. In the tracking module, a tracking algorithm is manually selected and initialized for each detected object.The tracker assigns a tracking ID to each identified object in the list and starts tracking it.
V. EXPERIMENTAL RESULTS AND DISCUSSION
The experimental results of deep learning models used for object detection in top view video surveillance have been elaborated in this section. Deep learning-based models, along with tracking algorithms, are implemented in OpenCV. The section is split up into subsections. The first section mainly discussed the testing results for multiple object detection and tracking using pre-trained deep learning models, in different scenes with a variety of backgrounds, heights, poses, and illumination conditions angle, cameras resolution and aspect ratio. In the second section, the results of tracking algorithms have been elaborated. The evaluation performance of object detection models and tracking algorithms are carried out in the last s ubsection.

Algorithm 1 Top View Multiple Object Detection and Tracking 1: for each frame in input video sequence do Fi Vi 2: convert it into RGB frames 3: if framework = YOLO then 4: test the model shown in Figs. 4 and 5:Fi th S×S 5: divide input into i grid cells .6: for each grid cell do 7: detect the object as .>Oi 8: if confidence threshold: then Bi x,y,w,h 9: detect bounding box with ( )10: end if 11: end for 12: else 13: framework = SSD 14: use the MobilenetSSD-deploy.caffemodel.15: test model shown in Figs. 4 and 7:16: for each detection value in feature map. do>17: if confidence threshold: then 18: detect the object with bounding box Oi Bi 19: assign class ID to each detected Bi x,y,w,h 20: assign bounding box with ( )21: end if 22: end for Oi Bi 23: for each detection with : i = 0 do 24: assign class number to each detected object.25: if object is present in detected list: then 26: i = i + 1▷27: Skip background 28: else 29: object is not detected list.30: end if 31: end for Bi 32: for each object bounding box do 33: initialize tracker▷Ti 34: manually select the tracking algorithm▷35: (i = 0 to 5) for 6 tracking algorithms 36:Oi Bi 37: start tracking with e.g/ GOTURN tracker Fi 38: for i = 10 in do 39: track the object with Bi>0 Oi>0 Oi Bi 40: if and then▷41: tracking threshold 10 42:≥43: Continue tracking the 44: Update the tracker list.45: else 46: Stop tracking.47: end if 48: end for 49: end for 50: end if 51: end for Oi
A. Detection Results of Multiple Objects Using Top View
Figs. 9 and 10 show the learning models’ output results for top view person detection. In both scenes, video sequences are recorded from a completely top view (symmetric view). The first scene is captured in an outdoor environment, while the second is captured in indoor environments. From Figs. 9 and 10, it can be viewed that the appearance of the person is varying, but still, the deep learning models give good detection results. In Fig. 9, the person’s appearance changes throughout the video sequence, depending upon its radial distance from the camera position. The radial distance causes a change in the person’s scale and size, but the deep learning model still detects the accurate bounding box for each size and scale variation.

Fig. 9. Testing results of some sample frames using deep learning-based model (YOLO) for top view outdoor symmetric environment. The person appearance is significantly changing with respect to its radial distance from the camera.

Fig. 10. Testing results of some sample frames using deep learning object detection model (SSD) for top view indoor symmetric environment. The detected bounding box automatically adjusted depending upon scale and size of the person.
Similarly, in Fig. 10 , the detected bounding box is automatically adjusted for different sizes and scales. The person in the sample frames moves exactly below the camera,which causes variations in appearance in the person’s body.The person’s size looks increasing with the movement of the person away from the camera. The detected bounding box,class label (person) along with the confidence score, can be seen in sample frames. We also tested the discussed deep learning models for multiple persons, as seen in Fig. 11. It can be determined from the Fig. 11 , that the models detect multiple people and assign an ID to each person. It can be seen from the sample frames that the person in the red shirt is assigned by ID 0, which is the same throughout the video sequences. The sample frames are captured in an outdoor environment where the person is going down from the stairs,which causes variation in the size of the person from camera height. The detection results show that the model effectively detects and classifies the person without any false detection.

Fig. 12. Testing results of some sample frames using YOLOv2 for top view multiple object detection covering both symmetric and asymmetric overhead view. (a)–(c) is symmetric overhead view while (d)–(f) asymmetric top view.

Fig. 11. Testing results of some sample frames using deep learning-based detection model (SSD) for top view multiple persons in outdoor symmetric environment. The unique ID is assigned to each detected person which helps in tracking of the detected objects.
The deep learning object detection models are also tested using asymmetric top view in outdoor and indoor environments. In video surveillance, the main focus is detection and tracking of the person/multiple persons; therefore, in almost all scenes, they are considered as the main region of interest.The other scene covered multiple objects from the symmetric top view in outdoor environments. The last scene is comprised of sample frames of multiple objects from an asymmetric overhead view. All of the scenes are captured in different backgrounds with different illumination conditions. The YOLO model results for top view multiple object detection,using different backgrounds and scenes are examined in the Fig. 12. It can be visualized from the sample frames that from the top view, there is significant variation in size, orientation,and scale and appearance of objects, but still, the pre-trained deep learning model efficiently detects the object from an overhead view. In Fig. 12(a) , the persons from the top perspective are efficiently identified even they are too close to each other.
Similarly, in Figs. 12(b), 12(c), and 12(d), the person in an indoor environment is detected using a pre-trained deep learning model. In sample frames, Figs. 12(e) and 12(f), the person and other objects, including car, bus, and truck, are accurately detected from the top view. The confidence score for different objects is also depicted in Fig. 12. The detected bounding box shows three values for each object, i.e., the object class label, the object class ID, and its confidence score. For example, in sample image Fig. 12(d) , the two objects with different class labels are detected, one is the bench, and one is a person. Some false detections are also highlighted in Fig. 12 ; for example, the person’s feet are detected as a skateboard. Likewise, in Fig. 12(b), the two people from the overhead view are not identified by the model, which are marked with red crosses, while one in Fig. 12(e).Furthermore, in Fig. 12(c), two people are detected in the same bounding box, which is referred to as miss-detection.We concluded from the results that the YOLO model efficiently detected the object from an overhead view without any additional training. Although there are also some false detections, it can be reduced if the model is trained using the same top view data set.
Likewise, for the second deep learning model SSD, the visual results of testing using top view frames are depicted in Fig. 13. Same as the YOLO model, the SSD also shows beneficial results for top view object detection. The SSD model also gives miss-detection as shown in Fig. 13(a), where multiple persons are detected in a single bounding box.Similarly, in Fig. 13(b) , like YOLO, the SSD model also produced not detected results highlighted with red crosses.Same in Fig. 12(d), the only person is detected while the bench is not detected. However, overall, the results are good compared to the traditional feature-based method, which requires bulky training of background samples. Like the first deep learning object detection model, the second model also detects the object in a bounding box with three values for each object, i.e., the object class label, the object class ID,and its confidence score. For example, in the sample frame Fig. 13(b), each detected person has a class label, class ID,and a confidence score. For the SSD model, the confidence values of objects are different; for example, in sample image Figs. 12(a) and 13(a), the person in red color cloth is detected with different confidence score 0.96 and 0.83, respectively.Similarly, in Fig. 13(d), the identified person has a different confidence score of 0.78 and 0.72, respectively. The detected bounding box information from the above models are further applied for tracking purposes. In the following section, the tracking results for top view multiple object detection has been discussed.

Fig. 13. Testing results of some sample frames using SSD for top view multiple object detection covering both symmetric (a)–(c) and asymmetric(d)–(f) top view.
B. Tracking Results of Multiple Objects Using Top View
In Fig. 14, the tracking results of the top view data set for different scenes can be visualized. It can also be analyzed from sample frames of different video sequences, that the object appearance, size, scale, and orientation changes with respect to the camera location in comparison with a frontal view. However, the tracking algorithms developed for frontal view data sets, still give good results. The YOLO and SSD models, pre-trained on frontal view images, accurately classify the object in top view video frames. The detected object (person) with the confidence score can be seen in Fig. 14 with a green color bounding box.
The results of different tracking algorithms for multiple top view object detection are good, but, in some instances, it suffers from failure. The BOOSTING and MEDIANFLOW trackers are good but suffer when there is an abrupt change in object size; it shows failure. Likewise, the MIL fails sometimes during the sequence due to the variation in the person’s body size and change in motion direction. The results of the KCF algorithm are quite well as compared to other trackers. The TLD algorithm also gives miss rate and suffers from failure, but that failure is not consistent. The median flow tracker gives false detection results and experiences failure when there is a sudden variation in the person’s direction and gesture.
To avoid unnecessary repetition, we explain the tracking results of one best tracker, i.e., GOTURN. The first column of Fig. 14 the tracking results using the YOLO model, while in the second column, the tracking results using SSD are depicted. In Fig. 14 , to avoid confusion in tracking trajectories, we show the outcomes for simple video sequences. As discussed earlier, in video surveillance, where the primary interest is to track persons’ trajectories, in this section, we also focus on tracking individuals’ trajectories. In Figs. 14(a) and 14(b) , the tracking trajectories for an individual with an asymmetric top view can be seen. It can be seen that person in the scene is moving across the scene. The GOTURN tracker shows good results along with the deep learning models.
Likewise, in Figs. 14(c) and 14(d), the tracking results for symmetric top view person video sequences are depicted. The individual in the scene moves freely, as seen from trajectories results of the Figs. 14(c) and 14(d). Similarly, in the next video sequence where the two people are moving nearer to each other in the same direction, the algorithm efficiently tracks each person with some miss rate. Figs. 14(g) and 14(h)show result for outdoor video sequences that are captured from the asymmetric top view, in which the car is moving in straight direction also two persons are moving freely in the scene. The tracking trajectories of all objects are depicted in Figs. 14(g) and 14(h). The trajectories for the different objects are indicated with different color dotted lines.
Similarly, results for another scene in which there are two objects; a bus and a person are depicted Figs. 14(i) and 14(l).One object is stationary, while other object is freely moving in the scene. In Figs. 14(i) and 14(l) the person trajectories are presented with a yellow color dotted lines. Same in the case of Figs. 14(m) and 14(n) where the person is continuously moving in the scene. That video sequence contains person and bus from the asymmetric top view. The person is efficiently tracked by tracking algorithm using deep learning-based detection models.
C. Performance Evaluation
In this section, different parameters utilized for the evaluation of different tracking algorithms, and both object detection models have been discussed. The evaluation method is adopted from [67]. The parameters are further categorized into two categories listed as follows:
i) False detection rate (FDR) and true detection rate (TDR):These two parameters are applied to evaluate both deep learning-based multiple top view object, detection models.
ii) Tracking accuracy (TA): It is utilized for the evaluation of different tracking algorithms.
1) Detection Results:The detection results for top view multiple objects using deep learning-based models are demonstrated in Figs. 15 and 16 and elaborated in Tabel. II. It can be determined that both models produced good results.For top view, multiple object detection both models perform well without any extra background training. The performance of SSD is slightly better in comparison to the YOLO model.In case if a preference is given to speed over accuracy, then YOLO performance is better. For sample video frames containing person, the YOLO model achieves TDR of 92%,while for other objects, TDR ranges from 90% to 92%.Likewise, for the SSD model, the TDR for multiple top view objects ranging from 90% to 93% while for persons, it presents good results by achieving TDR of 92%.

Fig. 14. Tracking results of some sample frames for top view multiple object detection covering both symmetric and asymmetric top views. Column 1 shows results of tracking using YOLO detection model while column 2 shows tracking results for SSD model, the sub-figures (a), (b), (g), (h), (i), (l), (m), and (n)asymmetric top view while (c), (d), (e), (f) is showing symmetric top view.

Fig. 15. TDR of deep learning models for multiple objects.

Fig. 16. FDR of deep learning models for multiple objects.
The TDR for both models in different symmetric and asymmetric top view scenarios for different objects are plotted in Figs. 15 and 16. From both figures, the robustness of the deep learning models can be analyzed. Similarly, FDR for both models is depicted in Fig. 16 for symmetric and asymmetric top views. From FDR, we concluded that instead,the method shows high FDR because they were not trained on top view data set; it turns over minimal values of almost less than 0.7%. It indicates that the deep learning models are better than traditional handcrafted features, which requires additional background training to improve the TDR. From the results of FDR, we conclude that the results may be further improved if the same models are trained for top view images.
2) Tracking Results:In Fig. 17, the performance measure of six different tracking algorithms, for indoor and outdoor top view scenarios in symmetric and asymmetric view against each object are depicted. It is clearly examined that accuracy of tracking algorithms is changing for different target objects.It shows that changing the camera perspective significantly influences the shape, appearance of the object. The TA of different tracking algorithms is also presented in Tables IIIand IV. With YOLO model the tracking algorithm achieves tracking accuracy ranges from 90% to 93% for the person shown in Fig. 17(a) , While the SSD model, the tracking accuracy for a person is ranging from 94% to 90%. Fig. 17 reflects that using multiple top views scenes, the tracking accuracy of algorithms for multiple objects may be effectively improved. From Fig. 17, all tracking models, along with both detection modules, achieve good accuracy results. The GOTURN performance is excellent in comparison to other tracking algorithms by making tracking accuracy of 94%. The tracking accuracy of different tracking algorithms with each detection model is also elaborated in Tables III and IV.

TABLE II TOP VIEW MULTIPLE OBJECT DETECTION RESULTS USING DEEP LEARNING MODELS
VI. CONCLUSION
Collaborative robotics plays a crucial function in video surveillance by providing an autonomous solution for many real-life applications. In this work, a robotic framework is presented for top view surveillance system. The overall framework consists of a visual processing unit embedded with a smart robotic camera. The visual processing unit performs object detection and tracking in top view surveillance and assists human operators to manage and control different surveillance applications. For object detection existing pretrained deep learning models, i.e., SSD and YOLO, already trained on frontal data sets are practiced against a top view data set. Different tracking algorithms are investigated for multiple objects, along with detection, for tracking objects from the top view. However, due to the perspective change of the camera, there is a significant variation in the object’s appearance, even though deep learning-based models show promising results. Overall, TDR of 93% with FDR of 0.6% is achieved for person images, and for other objects, the TDR is ranging from 92% to 90% in the case of YOLO. For SSD model top view person sample frames, TPR is 93% with FDRof 0.5% and for other objects TPR up to 90% with 0.6% FDR.

TABLE III RESULTS OF DIFFERENT TRACKING ALGORITHMS FOR EACH OBJECT USING YOLO DETECTION MODEL
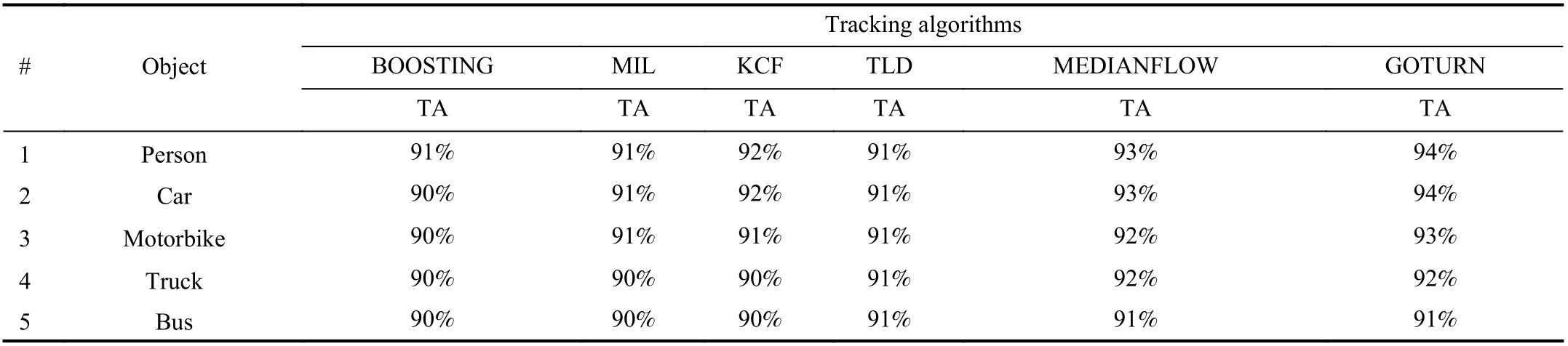
TABLE IV RESULTS OF DIFFERENT TRACKING ALGORITHMS FOR EACH OBJECT USING SSD DETECTION MODEL
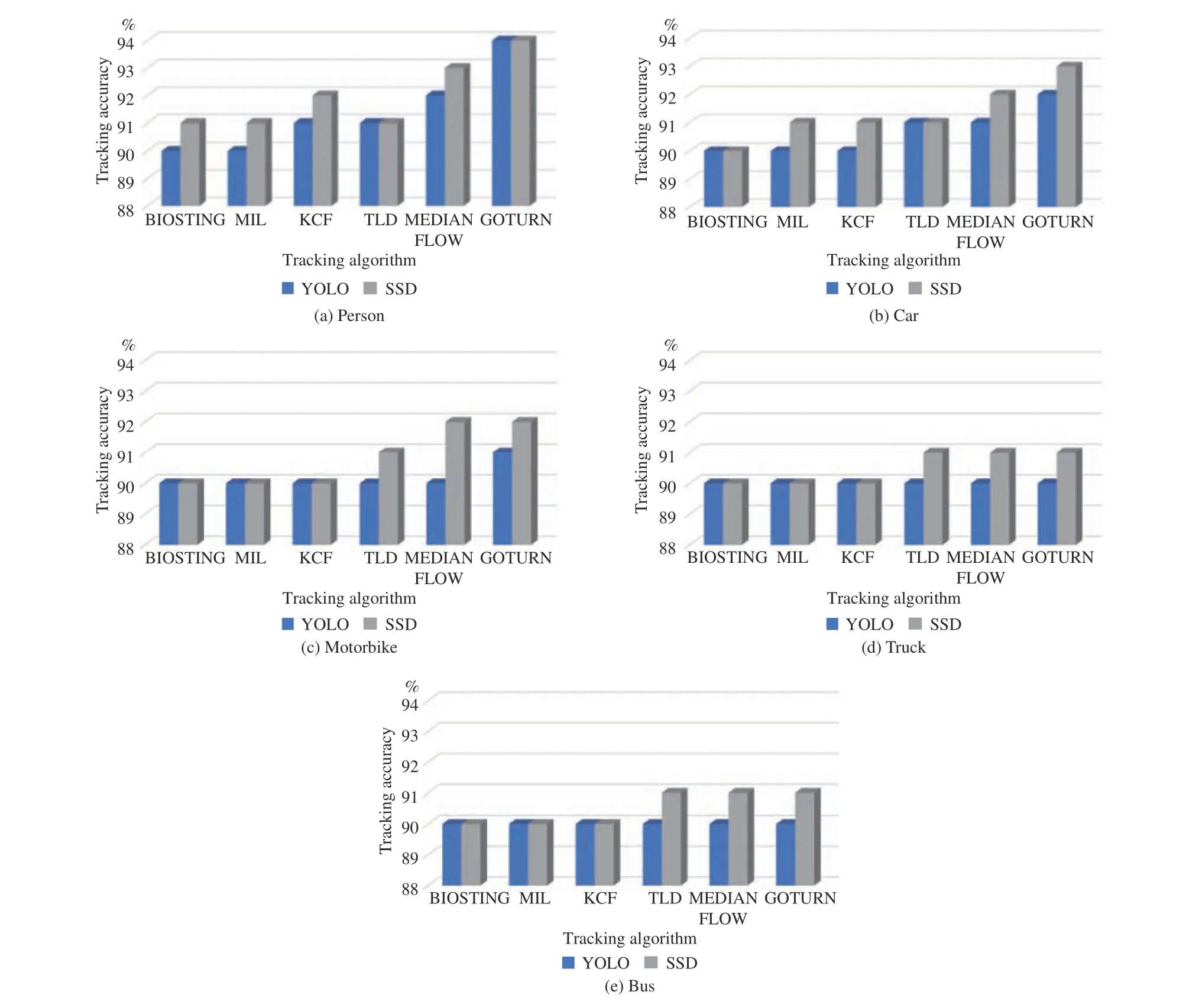
Fig. 17. Comparison results of different tracking algorithms for each object using YOLO and SSD detection model.
Furthermore, while using different tracking algorithms for multiple object tracking, all tracking algorithms almost achieved tracking accuracy ranges from 94% to 90% with both detection models. To the best of our knowledge, this work is considered the first attempt in top view collaborative surveillance systems and generic models in relation to object detection and tracking. In the future, this work is intended to be explored for other deep learning models for a variety of top view objects. The models trained and tested on top view data set may boost detection and tracking performance. The collaborative robotics in top view surveillance may further be enhanced by incorporating different modules, e.g., behavior analysis, activity recognition, and event detection.
猜你喜欢
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Remaining Useful Life Prediction for a Roller in a Hot Strip Mill Based on Deep Recurrent Neural Networks
- Disassembly Sequence Planning: A Survey
- A Cognitive Memory-Augmented Network for Visual Anomaly Detection
- Human-Swarm-Teaming Transparency and Trust Architecture
- Lightweight Image Super-Resolution via Weighted Multi-Scale Residual Network
- Global-Attention-Based Neural Networks for Vision Language Intelligence