A Cognitive Memory-Augmented Network for Visual Anomaly Detection
2021-06-18TianWangXingXuFuminShenandYangYangSenior
Tian Wang, Xing Xu,, Fumin Shen,, and Yang Yang, Senior
I. INTRODUCTION
ANOMALY detection in a video sequence is the process of identifying abnormal events which are unexpected to happen in the video, e.g., fighting, walking alone on the grass,and vehicles on the sidewalk. Visual anomaly detection is to apply anomaly detection on visual data, and its main purpose is to find abnormal data in visual data. It has attracted increasing attention in both the research and industrial communities, since it can solve many practical problems in life, e.g., security problems, automatic early warning of natural disasters, and analysis of traffic monitoring videos. For example, the application of intelligent robots with visual anomaly detection models on analyzing surveillance video data in public places can determine whether a fight has occurred and made an issue warning. Generally, visual anomaly detection is an extremely challenging problem for the following two reasons. Firstly, in the real world, the frequency of abnormal events is very low, so it is difficult to collect abnormal events. Secondly, the same event could produce a completely opposite result in different environments (e.g.,walking alone on the sidewalk or on the grass). Therefore,visual anomaly detection is naturally treated as an unsupervised learning problem in the literature, with the purpose of learning a model trained on normal data.
Generally, the existing methods [1]–[4] for solving visual anomaly detection adopt the reconstruction method and its diverse variant methods. At the training phase, a normal video clip is inputted into the proposed model. Then, the model takes an extracted feature representation to reconstruct the input video clip again. The reconstruction error between an input and a reconstruction could be used as a criterion for detecting whether an input is abnormal. Recently, deep neural networks (DNNs) have been widely used in the field of computer vision, and the reconstruction-based method has also benefited from them. The existing methods usually select an autoencoder (AE) [5], [6] based on convolutional neural networks (CNNs) as basic architecture, such as [3], [7]. AE includes an encoder obtaining a feature representation and a decoder decoding the feature representation back to the original image space. Thanks to the powerful feature representation capability of CNNs, the AE could be used to obtain the input’s feature representation in latent space.Generally, the feature representation from abnormal frames is supposed to be not reconstructed well by an AE, as the AE trains on normal data, which means that abnormal frames should have larger a reconstruction error than normal frames.However, it could be reconstructed well as the abnormal input contains a number of normal modes.
In order to solve the visual anomaly detection problem, a group of promising approaches [3], [6], [8]–[11] have been proposed. Specifically, a future frame predicting method [11]uses the reconstruction difference of predicted frames for visual anomaly detection. A memory method [3] introduces an extra storage space to remember the encoding of normal data,resulting in that an abnormal frame is reconstructed into a normal frame through the memory module. Some other methods, such as [6], [8]–[10], limit the latent space of the AE, with the purpose of restricting the normal data to a certain distribution. These methods do not focus on the visual anomaly detection problem itself, but regard it as a reconstruction problem, e.g., reconstructing the current or future frame of the video [3], [6], [11], [12]. The method [8]proposes to combine the auto-regressive network and AE into a unique framework to directly learn the data distribution to solve the above problems. It is noted that the method does not lessen the powerful representation ability of CNNs, resulting in relatively small reconstruction errors of abnormal frames.
In order to alleviate the problems of previous visual anomaly detection methods, we propose to devise a visual analysis system equipped with a memory module to help the collaborative robot to detect anomalies. The proposed memory module that is created by a contiguous memory area imitating human remember capabilities, is able to remember the normal feature and reconstruct the anomaly samples to normal samples. Generally, collaborative intelligent systems provide people with reference information, which is the underlying meaning of raw data, such as data distribution. Humans usually need to use the reference information provided by collaborative intelligent systems to complete the decision task.For example, when using collaborative robots to solve the visual inspection task, the data distribution is used as a judgment condition. Humans can combine multiple data information to easily distinguish whether an input is abnormal or not, even if only a few normal samples have been seen while abnormal samples have not been observed. It reflects the strong ability of the human brain to effectively use memory information, as shown in Fig. 1, while the robot does not have the ability. Moreover, when combining such a memory-based visual inspection ability with active robotic concepts, the proposed methodology may foster developments in the collaborative robotic domain.
In this paper, we propose a novel model termed cognitive memory-augmented network (CMAN) for visual anomaly detection based on an autoencoder network. Fig. 2 shows that our proposed CMAN method is based on an AE structure, an auto-regressive density estimator, and a memory module. The auto-regressive density estimator minimizes the novelty of their latent representation for normal samples, while the memory module maximizes memory ability for normal samples. The proposed memory module can enhance the memory ability of the previous reconstruction-based methods,and make the abnormal samples show higher reconstruction errors by remembering the normal samples. Following the prior method [8], we pick an estimation network to get a probability value of whether an input is abnormal by maximizing the likelihood of latent representations, and the network jointly minimizes the reconstruction error for optimization training.

Fig. 1. An illustration shows how humans make judgments whether a video contains an abnormal behavior based on previous memories. Human memory stores normal events that have been seen before. Here (a) is abnormal because the car does not appear in this scene in memory, while (b) is normal because there is a similar scene in the memory.
To reduce the problem of abnormal samples well represented by the memory module, the attention-based addressing operation with a threshold is used to obtain sparse memory encoding. Moreover, we propose a two-step training method. When the estimation network is well trained, we introduce the external memory module to remember normal samples by minimizing the reconstruction error and weight loss, which is optimized jointly with the estimation network.The two-step training method accelerates the convergence of the proposed CMAN model and makes the memory module and the density estimation network cooperate effectively to improve the performance of the proposed model for visual anomaly detection. Experimental results on standard benchmarks, including video dataset (UCSD Ped2 [13] and ShanghaiTech [4]), image dataset (MNIST [14] and CIFAR10[15]) and visual inspection dataset (MVTec [16]) show that our proposed CMAN method is superior and effective to the state-of-the-art methods.
In summary, our main contributions are as follows:
1) We propose a novel model termed cognitive memoryaugmented network (CMAN), which combines a memory module and an auto-regressive density estimation network to improve the model’s performance for visual anomaly detection, by remembering the feature representation and data distribution of normal input.
2) We propose a two-step training scheme, i.e., the memory module starts training after the estimation network has been trained, and is optimized by minimizing reconstruction error and maximizing the likelihood of latent representation, It can accelerate the convergence of the proposed CMAN model and effectively cooperate the memory module and the density estimation network.
3) We achieve competitive results for unsupervised anomaly detection on various visual datasets. We also provide comprehensive experimental results to demonstrate the effectiveness of our proposed method.
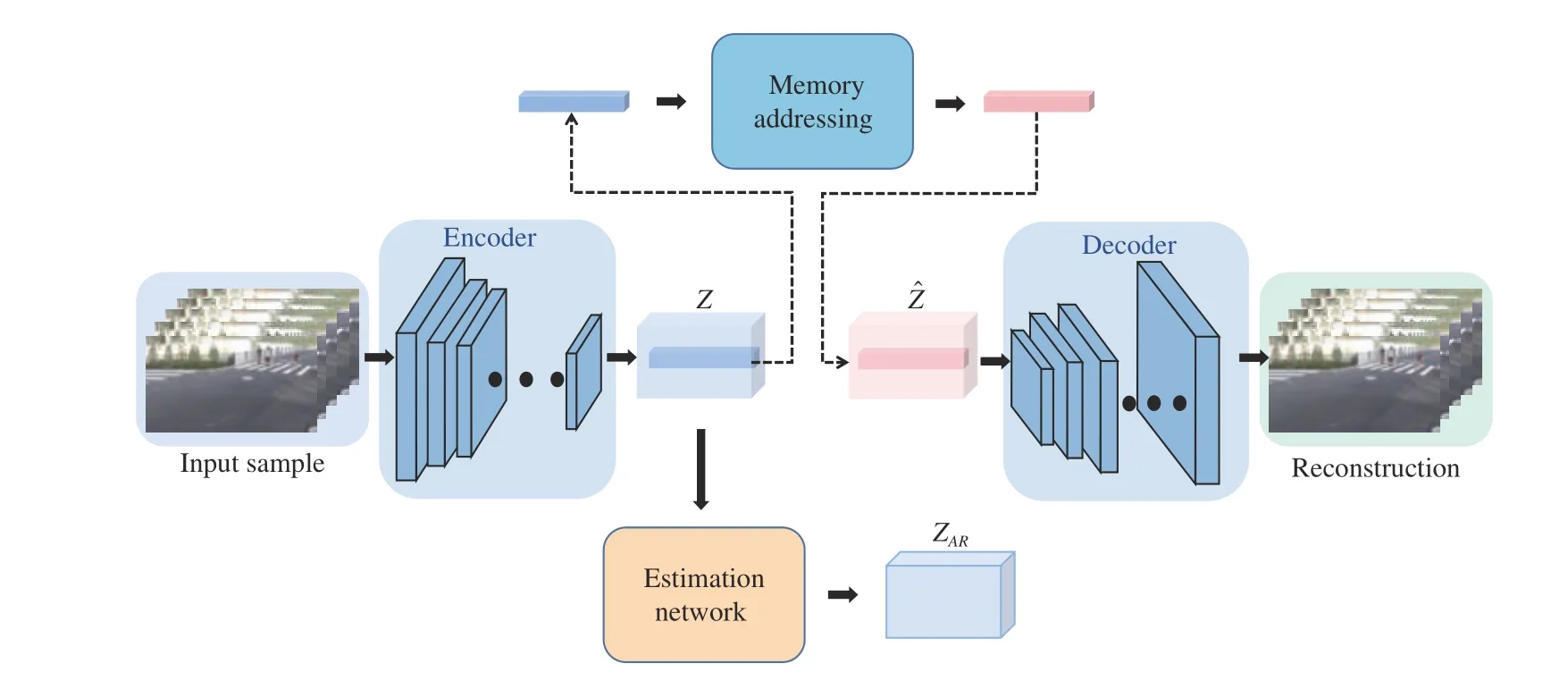
Fig. 2. The architecture of the proposed CMAN method. The overall framework consists of a deep autoencoder, a memory module with an attention-based addressing operation, and an estimation network based on auto-regressive layers. Note that when an abnormal sample is put into the network trained with only normal samples, the reconstruction error and the loss of the estimation network are larger than that of the normal input.
The remainder of this paper is organized as follows. In Section II, we introduce the works about cognitive computing and visual anomaly detection. Section III proposes a novel cognitive memory-augmented network (CMAN) for visual anomaly detection and shows how the proposed CMAN model works in detail. Then, the experimental details and results of the proposed CMAN compared with several stateof-the-art methods are presented in Section IV. In Section V,we summarize this paper.
II. RELATED WORK
A. Visual Anomaly Detection
Most methods [1]–[3], [8] treat the problem of visual anomaly detection as an unsupervised problem under the assumption that anomalies in the real world rarely occur and only normal data can be used for training. A natural method for solving the problem is to build a classification model, such as one-class support vector machine (SVM), which can seek the boundary between normal samples and abnormal samples to identify whether an input is abnormal. The unsupervised clustering methods calculate the distance between input and normal samples and select a threshold to identify whether an input is abnormal. However, traditional methods are difficult to process high-dimensional data. Recent methods [1]–[3], [8],[9], [11], [17] have begun to use deep learning to enhance the ability of processing data. Ionescuet al. [18] proposed to use preprocessing operations, that is, to rely on the object detection framework to extract higher-level semantic features,for visual anomaly detection. A complementary method for visual anomaly detection is to use probability models, which can model the distribution of normal data and predict whether an input is an abnormal sample. The probability model is mainly divided into non-parametric estimation and parametric estimation. The main problem faced by the probability model is how to estimate the density in high-dimensional data.Existing methods learn data distribution based on latent features of AE, such as Gaussian mixtures [19] and Gaussian classifiers [20]. Kernel density estimator (KDE) is proposed in[21] to model activations from an auxiliary object detection network. Kim and Grauman [22] introduced a novel mixture of probabilistic principal component analysis (MPPCA)method to model the features of optical flow. Mahadevanet al.[23] proposed a mixture of dynamic textures (MDT) method to model the video data. Recently, researchers have also begun to focus on generative models, such as variational autoencoder (VAE) [6] and one-class novelty detection with generative adversarial networks (OCGAN) [9]. However,these methods learned implicitly a density function, making it impossible to directly determine whether the input is abnormal. Therefore, a latent space autoregression estimator(AND) [8] method introduced an auto-regressive model to directly learn data distribution by the latent space of AE.
In recent research, reconstruction-based methods had also been well studied. Methods such as denoising AE (DAE) [12],VAE [6] and convolutional AE [1] used reconstruction errors as a criterion for visual anomaly detection. Luoet al. [4]introduced a stacked recurrent neural network (RNN) to detect anomalies in videos by iteratively updating the sparse coefficients. Zhaoet al. [24] detected the anomaly input with 3D convolution-based prediction and reconstruction. Liuet al.[11] incorporated different methods, including optical flow,adversarial framework, and gradient loss, resulting in learning a model that can predict the future frame. Gonget al. [3]proposed to use additional memory with the attention-based addressing operation to enhance the memory capacity of the AE. Parket al. [17] use a memory module to remember multiple prototypes of datasets based on the perspective of probability and introduce a real-time memory update method to solve the problem of visual anomaly detection. However,these reconstruction-based methods apply a proxy task to solve the problem of visual anomaly detection, instead of directly solving it. The proxy task utilizes the fact, that is the reconstruction error of normal samples is smaller than that of abnormal samples, to detect abnormalities.
B. Cognitive Computing
The definition of cognitive computing is to mimic the human thought process with computerized models, in order to solve problems in complex situations. Generally, cognitive computing systems are used as auxiliary information for humans to make judgments. IBM Watson for oncology, e.g.,had been used at Memorial Sloan Kettering Cancer Center to provide oncologists with evidence-based treatment options.Agarwalet al. [25] developed a cognitive computing system to assist humans to detect and classify fruit disease based on these technologies, including image segmentation, feature extraction, and the SVM algorithm. Vallejoet al. [26]proposed to identify unusual traffic behaviors based on a multi-agent system. Prescottet al. [27] built a multimodal memory system for the iCub humanoid robot by Gaussian process latent variable models. Dodd and Gutierrez [28]proposed to use a memory system that interacts with a machine emotion system, in order to produce intelligent decisions in a cognitive humanoid robot. In this paper, we propose a cognitive memory-augmented network (CMAN) for visual anomaly detection, which combines cognitive computing and neural networks. The proposed CMAN method is based on a memory module and a density estimator, which is to learn features from observed data and to model the data distribution. Compared with density estimation methods [8],[22], [23], the proposed method uses a memory module to store the feature of normal data. Compared with the memoryguided method [3], [17], the proposed method uses a density estimation network to learn the distribution of normal data,thereby assisting the memory to store advanced features.Moreover, we propose a two-step training method. When the estimation network is well trained, we introduce the external memory module to remember normal samples by minimizing the reconstruction error and weight loss, which is optimized jointly with the estimation network. The proposed method combines the advantages of the memory module and the density network to solve visual anomaly detection.
III. OUR PROPOSED MODEL
A. Overview
The proposed CMAN model contains three basic structures:1) an autoencoder (for reconstructing the samples and extracting the latent feature representations); 2) an estimation network module (for learning the distribution of latent space);and 3) a memory module (using a block of storage space and the read and write strategy).
As shown in Fig. 2, this is an overview of our framework.The autoencoder is divided into an encoder and a decoder,where the input of model is a normal video clip with some noise and the output of model is a reconstructed video clip.The encoder generates a latent codezto reconstruct the input by the decoder. The estimation network learns the density function of normal datap(x) by modeling an auxiliary random variablez, represented by the latent feature. By factorizing
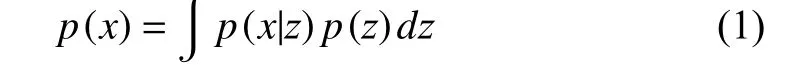
wherep(z) andp(x|z) denote the distribution of latent space and the conditional probability density function, respectively.We can use the estimation network to learn thep(z) by utilizing maximum likelihood estimation (MLE), andp(x|z) is modeled by using the decoder to reconstruct the input. By using a read operation based on attention, the memory module uses the encoded representationzto obtain a representation from the relevant memory items, which is fed into the decoder for reconstruction. From the above description, the network structure can be described as

where θenand θdedenote the parameters of the encoderfeand the decoderfd, respectively. The encoder extracts a latent feature representationzfrom an inputxbyfe(·), and the decoder uses the feature representationzˆ to obtain a reconstructionxˆ byfd(·). The memory module uses the latent feature representationzto address memory items to obtain a new feature representationzˆ, as below:
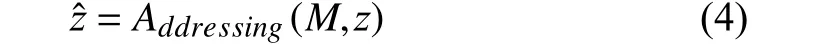
whereMandAddressing(·) denote the memory unit and the attention-based addressing operatiton, respectively. The estimation networkE(·) can estimate the density in the latent representationzwith autoregression layers, allowing to learn arbitrary data distribution without any restriction (i.e.,Gaussian distribution), as below:

where θEdenotes the parameters of the estimation networkE(·) andzARis the output probability.
During training phase, we use normal video as input by using an autoencoder with a memory module and an estimation network, which are proposed to reconstruct the input and model the data distribution of normal, respectively.Therefore, normal samples have low reconstruction error,while abnormal samples have high reconstruction error. The normal samples have a higher probability in the estimation network, while abnormal samples have a lower probability,which will be used as an evaluation criterion to detect abnormalities.
B. AutoEncoder
Following the previous methods, we choose an autoencoder model as the basic structure of the proposed CMAN model,which learns a feature representation from an input video clip and reconstructs the video clip from the feature representation.The autoencoder consists of an encoder and a decoder, which usually has an information bottleneck to obtain a compressed representation of the data. In our proposed model, the inputxis mapped to a latent codezby (2), and the inputx∈RH×W×C×Tand thez∈RT×feature_dim×Cdenote a video frame and a corresponding feature representation, respectively, whereH,W,C,Tandfeature_dimare height, width,the number of channels, time and the dimension of latent space, respectively. We map the latent representationzback to the original space by (3). For the original autoencoder, there iszˆ=z. However,zˆ is obtained by using an attention-based addressing operation in our proposed method. We perform the mentioned autoencoder model by minimizing the mean squared error (MSE) loss as below:


Fig. 3. The diagram of the estimation network: (a) The architecture of the auto-regressive layer which is decomposed into a dot product of a kernel and a mask; (b) Two types of masks and their differences are marked with red color.
wherexis the input video clip andxˆ is the reconstruction of the input. We use MSE loss as the evaluation standard for reconstruction quality and it is also used to detect whether an input is abnormal [3]. The autoencoder structure in our method is independent of the proposed model and can be selected according to specific applications.
C. Estimation Network
1) Auto-Regressive Density Estimation:Auto-regressive model is usually used to deal with modeling data distribution related to sequences, and the output depends on the previously observed values [29], [30]. In this paper, we adopt that method to learn the distribution of normal data in order to avoid setting a prior distribution [31], [32], which may damage the original distribution of data (i.e., variational autoencoder (VAE) and adversarial autoencoder (AAE)).Formally,p(x) is factorized as

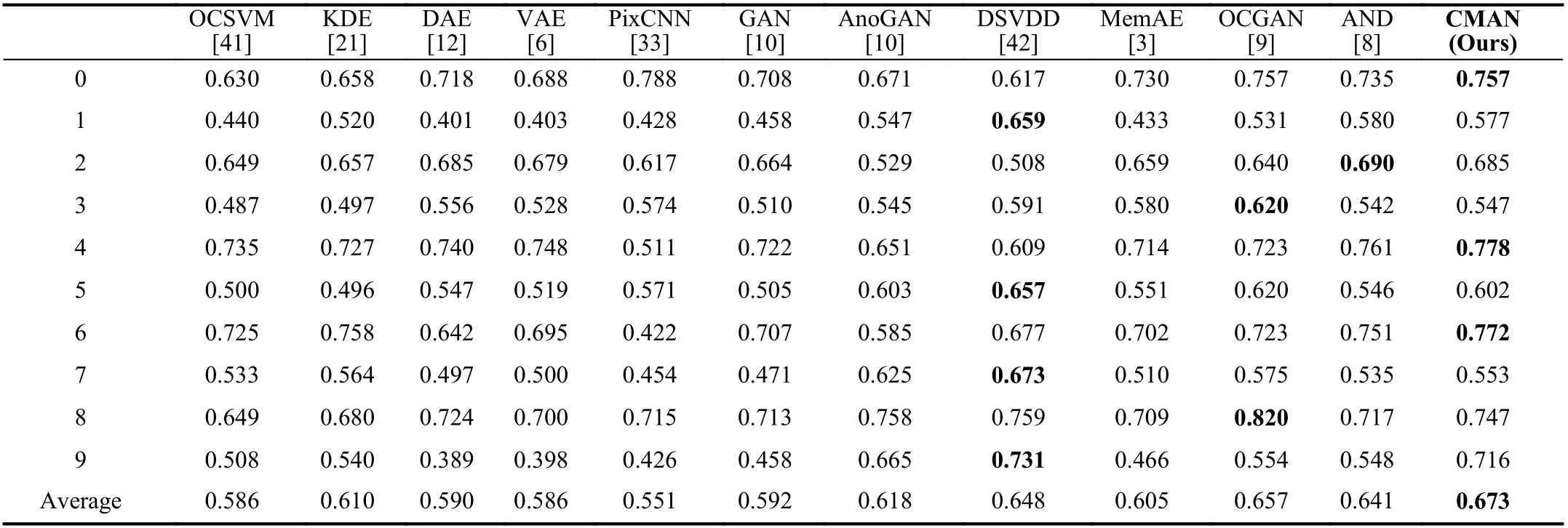
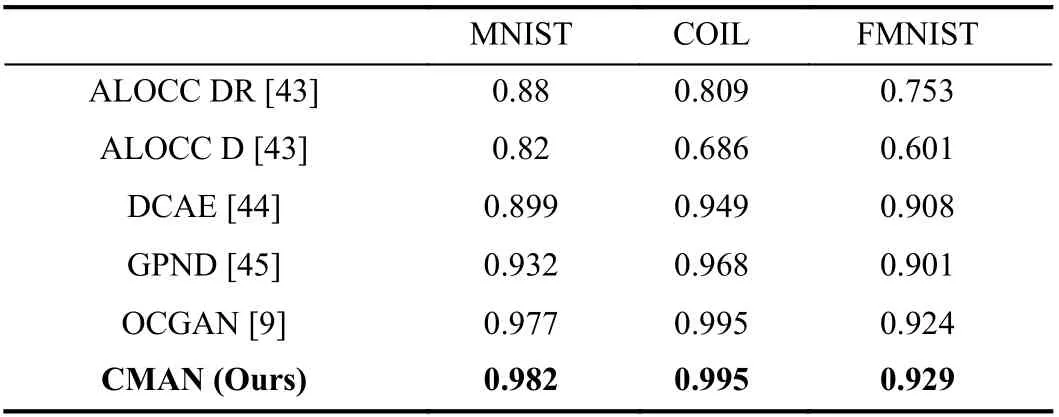
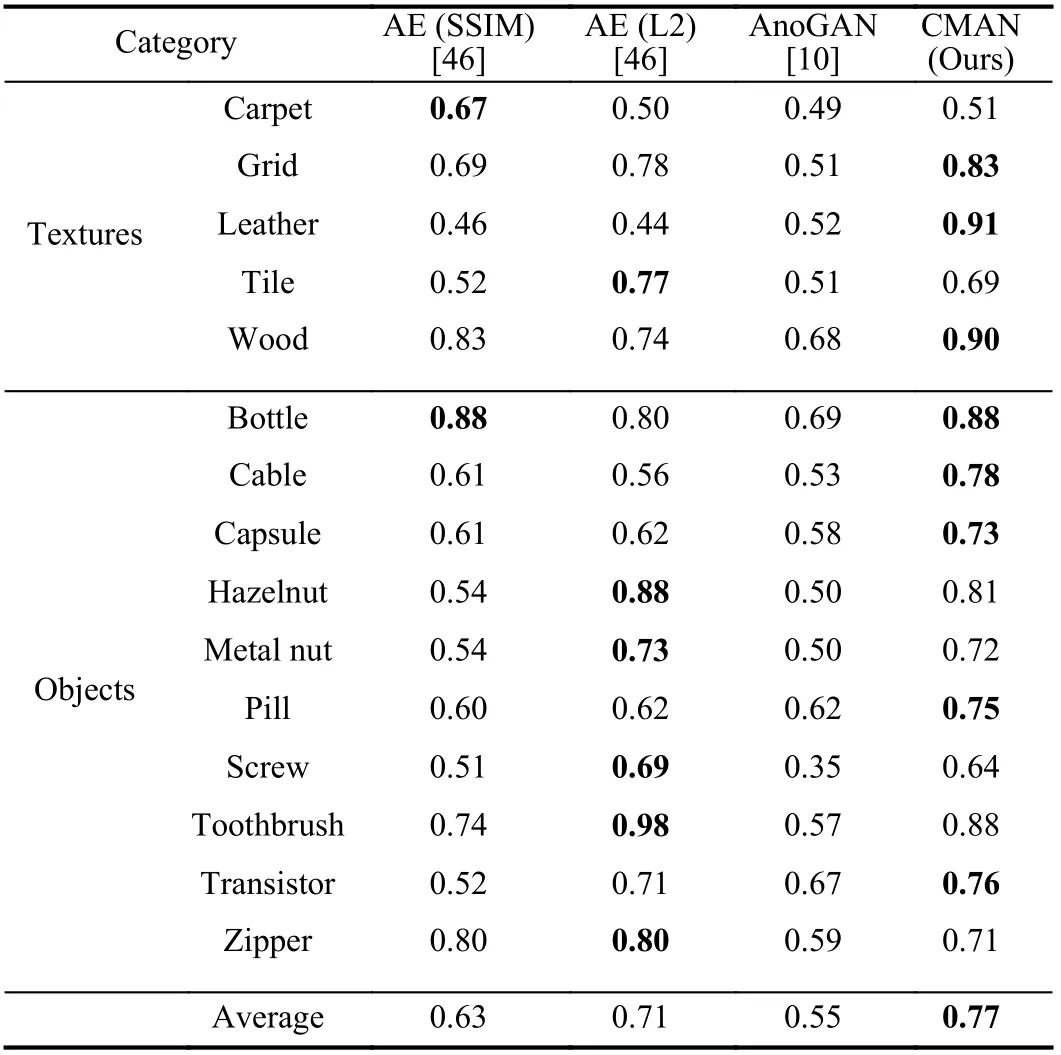
wherep(x) represents target distribution andp(xi|xj In order to solve the above problem, we only need to estimate each conditional probability density to achieve the goal of modeling the entire data distribution. In our proposed method, the auto-regressive layer can be represented as the formulap(xi|xj where θedenotes the parameters of the estimation networkE,which is divided into multiple auto-regressive layers. During testing phase, given a test sample to get its latent space representation, we use the estimation network to evaluate the probability of the test sample appearing in normal samples, which can be used as the criterion for visual anomaly detection. 2) Architecture of Auto-Regressive Layers:Following the previous article [8], [33], we select the method of [8] as our auto-regressive layer. As shown in Fig. 3(a), the latent codez∈RT×feature_dim×Cias input is delivered into the estimation network to obtain the outputzllk∈RT×feature_dim×Co, wherezis obtained by convolutional autoencoder, andCiandCodenote input dimension and output dimension, respectively. The autoregressive model is modeled in the time dimension ofz, where the output at timetcomes from the output at the previous time. For calculation convenience and easy implementation,the convolution and the mask methods are proposed to implement this process. Unlike PixelCNN [33], the size of kernelwselected here is 3×feature_dim, which avoids the blind spot problem caused by the receptive field. There are two types of kernels,AandB, as shown in Fig. 3(b), in which their outputs is related and unrelated to the input of current time, respectively. As below: wherei,jare the indices ofmaski,j∈R3×feature_dim,respectively, andt,dare the indices of time andfeature_dim,respectively. The convolution kernelwis dot-multiplied bymaski,jand finally we concatenate outputs as the input of the next layer together. The estimation network is composed of multiple auto-regressive layers, which are composed of multiple kernels of typesAandB. As shown in Fig. 4 , we set a continuous memory areaM∈RN×Kas external storage, whereNrepresents the memory size, andKisfeature_dimthat represents the size of each feature stored in the memory. The memory element is designed to store the feature representation of the normal sample, and the memory is a content addressable memory[34], [35] with an addressing scheme that computes attention weightswby calculating the similarity of the memory element and the queryz. In addition, the addressed latent codezˆ is calculated with the memory element and the latent codezby the similarity [34], [35], as below: Fig. 4. An illustration of the memory module with an attention-based addressing memory strategy and a threshold function to filter irrelevant memory units. wherezandzˆ denote the latent code and the addressed latent code, respectively.wiis attention weight by calculating the similarity of the latent codezand the memory elementmiandd(·)is cosine similarity. However, experiments show that attention weights obtained by calculating softmax can well locate the latent code of abnormal samples from the memory.We propose to limit attention weights with a threshold. The value of wight higher than a certain threshold will be retained and then be used to address in the memory through the normalized weight to obtainzˆ, as follows: where λ represents the threshold. The weights calculated by the above method can effectively alleviate the problem that abnormal samples can be also located. Formally, we adopt the entropy loss to optimize memory by using the gradient descent method as below: wherewidenotes the calculated weight by a threshold. During training phase, we update the memory units that represent the sparse representation of features by input normal samples. During testing phase, the values in the memory are sparse features of normal samples that achieve the ability to remember normal samples, and the sparse address operation effectively enhances the sparse representation of the memory to enhance the above-mentioned ability. 1) Loss Function:We use the previously mentioned loss,that is the loss of autoencoder, memory, and density estimation, as an objective function and formulate it into the following form: where λarand λmemdenote hyper-parameters for balancing the relation of loss. We propose a two-step scheme to train the proposed model, and the training procedure of the proposed CMAN method is described in Algorithm 1. As shown in Algorithm 1, we first build our proposed model and then input the training set into the proposed model. We propose to use the encoderfe(·) to obtain the latent space feature code, then use the decoderfd(·) to reconstruct input.Moreover, the density estimatorE(·) is trained on the latent space feature code. we run the procedure until the iteration reaches the set value. Then we fix the density estimatorE(·)and the encoderfe(·) to train the memory moduleM. Same as the previous step, we replace the input of the decoderfd(·)with the output of the memory moduleM. Finally, we have a trained model. 2) Anomaly Score:We assume that the proposed CMAN model learns the distribution of normal samples and remembers normal samples. Therefore, we can use the difference between reconstructionxˆ and inputxand probability from estimation network for visual anomaly detection. The anomaly score of the input is obtained by summing the reconstruction (mse) score and the estimation probability (ar) score as follows: where norm(·) resets score to [0, 1], andmseandarareLmseandLar, respectively. Then, we can identify whether an input is abnormal or not by setting a score threshold to distinguish as below: where τ is a predetermined threshold. Algorithm 1 The Training Procedure of the Proposed CMAN Method Input: Set of training videos; model parameters , , and memory parameters ;1: repeat fe(·)θen θde θE M 2: Compute latent code z by ;fd(·)3: Reconstruct input by ;zAR E(·)4: Compute by ;Lmse Lar 5: Compute and according to (6), (8);Lmse Lar θenθdeθE 6: Back-propagate , to optimize , , ;7: until Training iterations reach the preset value;8: repeat fe(·)9: Compute latent code z by ;ˆz 10: Compute new latent code with memory M by (4);ˆz fd(·)11: Reconstruct input with by ;zAR E(·)12: Compute by ;Lmse Lar Lmem 13: Compute , , according to (6), (8), (13);Lmse Lar Lmem θenθde θE 14: Back-propagate , , to optimize , , and memory M;15: until Training iterations reach the preset value;fe(·) fd(·) e(·)Output: Model , , and memory M. We demonstrate the effectiveness of the proposed CMAN method, compared with existing methods. We evaluate our method on two types of datasets: video and image data. For video data, UCSD Ped2 [13] and ShanghaiTech [4] datasets are often used to evaluate the performance of visual anomaly detection methods. We set thefeature_dimof latent code and the output’s channel of estimation network to 64 and 100,respectively. For UCSD Ped2 [13] dataset, we continuously sample 16 frames of video and then crop them into smaller patches (the size of 8×32×32). For ShanghaiTech [4]dataset, we preprocess the input clips of 16 frames with the size of 2 56×512 to remove the dependency on the scenario by calculating the foreground information of each frame through the mixture of Gaussians (MOG) method [36] (the background model based on mixture of Gaussians). We set the sizeNof memoryMand the threshold λ to 2000 and 0.002 on UCSD Ped2 dataset, while set to 1000 and 0.001 on ShanghaiTech [4] dataset. For image data, we select MNIST[14] and CIFAR10 [15] datasets as the main benchmark. We set the sizeNof memoryMand the threshold λ to 100 and 0.005 on MNIST dataset, while set to 500 and 0.002 on CIFAR10 dataset. We use the Adam optimizer [37] with a batch size 8 and 64 to video and image data, respectively. The epochs is set 20, 20,100, and 500 on UCSD Ped2 [13],ShanghaiTech [4], MNIST [14], and CIFAR10 [15],respectively. Unless otherwise specified, we set λarandλmemto 0.1 and 0.0025, respectively. 1) Evaluation Methodology:Visual anomaly detection can be viewed as a binary classification task, which often uses classification accuracy as evaluation criteria. However, when the data has a category imbalance (with very few abnormal data), the accuracy rate cannot be an available assessment of the performance of the model. Following previous works [3],[8], [9], a popular evaluation method, recommended as the evaluation metric, is to use area under the curve (AUC) of receiver operating characteristics (ROC). Better visual anomaly detection performance indicates a higher value of AUC. Furthermore, there are two types of protocols in the literature for visual anomaly detection performance on image datasets. Protocol 1:Select 80% of in-class as normal samples in training phase and the remaining 20% as normal samples in testing phase from training set. In testing phase, abnormal samples are sampled from out-class in testing set. Besides, the number of abnormal samples is consistent with that of normal samples. Protocol 2:Keep the division of the original dataset. The inclass of training set is to conduct training. The in-class of testing set is selected to be normal samples, and the out-class is abnormal samples during testing. Compared with the state-of-art methods, we use the corresponding protocol to evaluate the performance of our proposed CMAN method. 2) Datasets:As mentioned earlier, we compare the performance of our method on video and image datasets.Now, the dataset used in our experiment is listed below and Fig. 5 shows some examples. Fig. 5. Some examples of normal (top) and abnormal (bottom) frames in UCSD Ped2 and ShanghaiTech. Abnormal events are highlighted with a red rectangle, including a man riding a bicycle or a motorcycle, and fighting. UCSD Ped2:The UCSD Pedestrian 2 (Ped2) dataset consists of 16 training videos and 12 testing videos with 12 relevant abnormal events, including riding a bike and driving a vehicle, etc. ShanghaiTech:The ShanghaiTech dataset contains 13 scenes and various anomaly events, which is a very challenging dataset for visual anomaly detection. Totally, it includes 330 training videos and 107 testing videos with 130 relevant abnormal events. MNIST:The MNIST dataset is a widely used dataset, which consists of 0–9 hand-written characters with the size of 28×28. CIFAR10:The CIFAR10 dataset is a small object recognition dataset consisting of ten common objects with a 32×32resolution. COIL100 [38]:The COIL100 dataset is a multi-class object recognition dataset, composed of 100 categories taken from a different angle. FMNIST [39]:The FMNIST dataset is introduced to replace the MNIST dataset and consists of images of fashion apparels/accessories from 10 classes. 1) Results on Video Data:The anomaly detection of video data is mainly to analyze whether the frame in the video is contained in the abnormal event. Due to the characteristics of video data, the previous method [6], [19] cannot be effectively applied to video data. To show the effectiveness of our proposed method, we compare our CMAN method with several state-of-the-art methods on the UCSD Ped2 and ShanghaiTech datasets. The state-of-the-art methods can be plotted into three categories, namely prediction, reconstruction, and others. The prediction category reconstructs future frames, including a future frame prediction method (FFP), and a memory-guided normality model (Mem-guided). The reconstruction category reconstructs the current frames,including ConAE [1] method, a temporally-coherent sparse coding method (TSC) [4], a stacked recurrent neural network(Stacked RNN) [4], a memory-based network (MemAE) [3], a memory-guided normality model (Mem-guided) [17], a latent auto-regressive model (AND) [8]. In addition, there are other related methods, including a novel mixture of probabilistic PCA (MPPCA) method [22], a mixture of dynamic textures(MDT) method [23], and many visual anomaly detection baselines. As shown in Table I, there is a better performance of the proposed CMAN method compared with the state-of-the-art methods on the UCSD Ped2 and ShanghaiTech datasets.Moreover, we divide current methods into three categories,including reconstruction (Recon.), prediction (Pred.), and others. The proposed method is a reconstruction-based method, achieving superior results compared with prediction and other reconstruction methods on UCSD Ped2 dataset.Moreover, the results on ShanghaiTech dataset are competitive. Finally, the proposed CMAN method achieves the detection performance of 0.962 and 0.725 on UCSD Ped2 and ShanghaiTech datasets, respectively. TABLE I THE AUC OF DIFFERENT METHODS ON VIDEO DATASETS UCSD PED2 AND SHANGHAITECH From the table, the proposed CMAN method obtains stateof-the-art results on UCSD Ped2 dataset and competitive results on ShanghaiTech dataset compared with other methods, achieving the average AUC of 0.962 and 0.725,respectively. Compared to MemAE, we use a memory module and an estimation network together to achieve the best results,obtaining an increase of 0.055 and 0.028 on UCSD Ped2 and ShanghaiTech datasets, respectively. The proposed method achieves a small improvement on UCSD Ped2 dataset and competitive results on ShanghaiTech dataset compared with the AND method. Although the improvement is not much compared to the AND method, we introduce a memory module to achieve the improvement effect by remembering the distribution of normal samples, which is not sensitive to the memory size. For these memory-based methods, they detect abnormalities by remembering the distribution of normal samples. However, they lack the ability to model data distribution, which can effectively improve the ability to detect abnormalities. Although our method is as good as the FFP method on the ShanghaiTech dataset, the FFP method requires optical flow data, where extracting optical flow data is very time-consuming, and an adversarial learning framework, which has the problems of difficultly training and model collapses. Instead, the proposed method is simple and robust enough to accommodate multiple datasets. Fig. 6 shows the results of our method on some video segments. We can observe that the abnormal score value of the abnormal video segments (red rectangle) is larger than that of the normal video segments. Fig. 6. Some examples of score results were obtained by the proposed CMAN method on UCSD Ped2 and ShanghaiTech datasets. The area covered by a red rectangle indicates that an abnormal event has occurred. 2) Results on Image Data:We also evaluate the proposed CMAN method, compared with the state-of-the-art methods on image dataset with two different protocols, including MNIST, CIFAR10, COIL100, and FMNIST. The existing methods include one-class SVM (OCSVM) [41], a deep autoregressive generative model PixCNN [33], a deep variational autoencoder (VAE) [6], a kernel density estimator (KDE)[21], a generative adversarial network (GAN) [10], a memorybased network (MemAE) [3], a one-class novelty detection method (OCGAN) [9], a latent auto-regressive model (AND)[8] and others methods. For a fair comparison, we compare experimental results with the existing methods, using the corresponding protocol. However, we regard DAE as the basis of our method, on which we integrate a memory module with an auto-regressive network that efficiently improves the performance of DAE on visual anomaly detection. Compared with GAN, the training process of the proposed model is simple and the proposed model is more stable, which effectively models the data distribution. In addition, VAE and OCGAN are also proposed to model data distribution, by limiting the data to a Gaussian distribution. VAE is considered to replace GAN, because of its stable training and good generation effect. However, they do not learn the true data distribution, due to the limit of obeying a prior distribution.These memory-based methods propose to use additional storage space to store the features of normal samples to learnthe distribution of data. However, they have taken the reconstructed error as a criterion for judging whether an input is an abnormality, instead of explicitly modeling the distribution of data. Our method adopts an auto-regressive network in the same way as AND, which can effectively avoid the problems mentioned above and introduces a memory module to effectively enhance the capability of remembering. TABLE II THE AUC RESULTS OF DIFFERENT METHODS ON MNIST USING PROTOCOL 2 TABLE III THE AUC RESULTS OF DIFFERENT METHODS ON CIFAR10 USING PROTOCOL 2 As shown in Tables II and III , the results obtained by CMAN are superior to those of the state-of-the-art methods on the MNIST and CIFAR10 datasets, achieving the detection performance of 0.981 and 0.673, respectively. On MNIST dataset, the proposed CMAN method achieves better results on half of MINST dataset and competitive results on others,increasing from 0.975 to 0.981 in metric of average AUC. On CIFAR10 dataset, the proposed method achieves competitive results in most categories. Moreover, we increase the average AUC from 0.657 to 0.673. Table IV shows that the proposed method improves visual anomaly detection performance from 0.977 to 0.982 and 0.924 to 0.929 on MNIST and FMNIST,respectively, using protocol 1. Besides, our method obtains competitive results on COIL dataset. In conclusion, the CMAN method has achieved an excellent improvement on alldatasets compared with the previous methods, achieving a new state-of-the-art. TABLE IV THE AUC RESULTS OF ONE-CLASS NOVELTY DETECTION USING PROTOCOL 2 Fig. 7. The ROC curves of three different scores on UCSD Ped2, ShanghaiTech, MNIST and CIFAR10 dataset. Fig. 8. Experiments: (a) The AUC obtained by the one-step scheme and two-step scheme on four datasets; (b) The performance of our CMAN method with different values of λ. 1) The Effectiveness of Our CMAN Method:The proposed CMAN method combines auto-regressive models that model the data probability and memory modules, which are the sources of two types of abnormal scores. The scores consist of reconstruction scores between input and output and novelty scores obtained by estimation network and they can be used as a score alone to detect anomalies. Moreover, the memory modules enhance AE to get a better reconstruction score,named MSE, and the novelty score is denoted by AR. To further investigate the effectiveness of our method, we utilize the tool to plot the ROC curves of three different scores on UCSD Ped2, ShanghaiTech, MNIST, and CIFAR datasets.Fig. 7 shows the ROC curve of three different scores. We can observe that the proposed method is better than the other two methods, estimation network and autoencoder with memory modules, on most datasets. On ShanghaiTech dataset, the performance of the proposed method is very close to the performance of autoencoder with memory modules, mainly because the scale of the dataset is too huge, and it is not easy to obtain the distribution of normal samples. However, the proposed method still shows excellent performance that the proposed method achieves a higher AUC score on most datasets. 2) Effect of Two-Step Scheme:In order to investigate the effectiveness of the two-step scheme, we carried an ablation study using the MNIST, CIFAR10, UCSD Ped2, and ShanghaiTech datasets. As shown in Fig. 8(a), we observe that the AUC value achieved by the two-step scheme has already reached 0.981, 0.673, 0.962, and 0.725, respectively.Compared with the one-step scheme, the two-step scheme improves on four different datasets, which proves the effectiveness of the proposed method. When using the onestep scheme for training, the estimation network and memory module may have a mutual restriction relationship due to selecting gradient descent to optimize parameters, which leads to a lower performance than the two-step scheme. On contrary, the two-step scheme trains the memory module after the estimation network has been optimized, and then the two modules form a complementary relationship. 3) Sensitivity Analysis on the Memory Threshold:In this section, we also discuss the impact of the hyper-parameterλ in (12), which affects the read and update operations of the memory module. Therefore, it is directly related to whether the memory module achieves competitive results. In this experiment, Fig. 8(b) shows that the performance of our CMAN method under different values of λ that is in the range of [0.0005, 0.001, 0.0015, 0.002, 0.0025, 0.003]. We can notice that the proposed CMAN method is not very sensitive to the parameter λ, and the parameter value should not be too high or too low to achieve good results. Specifically, our CMAN method achieves the best performance withλ=0.002 and λ=0.001 on USCD Ped2 and ShanghaiTech datasets,respectively. Visual inspection task is a potential application of the proposed CMAN method, we finally conduct a visual inspection experiment on the MVTec [16] dataset, compared with state-of-the-art methods. The MVTec data set is proposed to detect the anomalous parts in an object, and it is divided into two categories, textures and objects, which consist of 15 specific categories. In order to verify the performance of the proposed method on the visual inspection task, we compared it with several state-of-the-art methods in experiments on the MVTec dataset, as shown in Table V.Table V shows that the proposed CMAN method has achieved improvement effects in both the textures and objects. In particular, the detection performance of the proposed method is increased from 0.52 to 0.91 on leather, from 0.83 to 0.90 onwood, from 0.61 to 0.78 on cable, and from 0.62 to 0.73 on capsule, respectively. In addition, the average indicator value in both the textures and objects is increased from 0.71 to 0.77.The proposed method achieves superior results in most categories and achieves competitive results in other categories. The sufficient experiments show that the proposed CMAN method can also be applied to visual inspection tasks,and has achieved superior results compared with previous existing state-of-the-art methods. TABLE V THE AUC OF DIFFERENT METHODS ON MVTEC DATASET In this paper, we are concerned that the application of robots for visual anomaly detection is a practical problem that needs to be solved. We have proposed a novel cognitive memoryaugmented network (CMAN), which simulates the remembering ability of humans who make a judgment based on previous cognition. We have developed a convolutional network based on AE with a memory module and a density estimation network, which are used to remember the seen data and model the data distribution, respectively. Then, the reconstruction error between input and output and the novelty score obtained by the density estimation network is used to be the criterion to distinguish abnormal data. We have conducted an experiment on various visual datasets, including UCSD Ped2, ShanghaiTech, MNIST, CIFAR10, and MVTec.Comprehensive experimental results demonstrate the effectiveness and prominence of the proposed CMAN method for visual anomaly detection.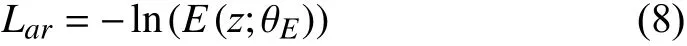

D. Memory Module


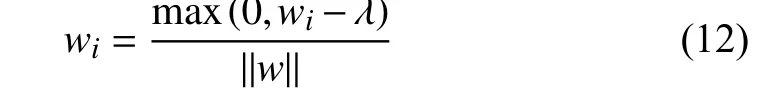

E. Training

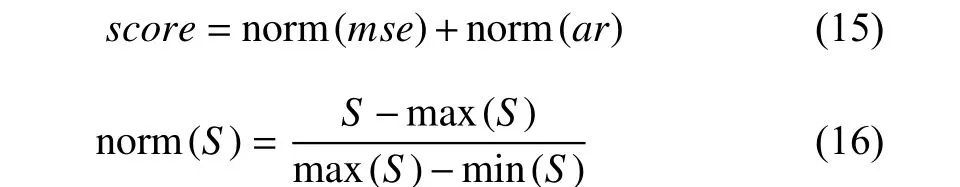


IV. EXPERIMENT
A. Implementation Details
B. Evaluation and Datasets

C. Experimental Results



D. Further Analysis


E. Results on Visual Inspection
V. CONCLUSIONS
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Remaining Useful Life Prediction for a Roller in a Hot Strip Mill Based on Deep Recurrent Neural Networks
- Disassembly Sequence Planning: A Survey
- Human-Swarm-Teaming Transparency and Trust Architecture
- Lightweight Image Super-Resolution via Weighted Multi-Scale Residual Network
- Towards Collaborative Robotics in Top View Surveillance: A Framework for Multiple Object Tracking by Detection Using Deep Learning
- Global-Attention-Based Neural Networks for Vision Language Intelligence