Global-Attention-Based Neural Networks for Vision Language Intelligence
2021-06-18PeiLiuYingjieZhouDezhongPengandDapengWu
Pei Liu, Yingjie Zhou,, Dezhong Peng,, and Dapeng Wu,
I. INTRODUCTION
IMAGE captioning aims at giving a natural language description for a given image automatically by computer[1], [2], which lies at the intersection of computer vision (CV)and natural language processing (NLP). Practical applications of automatic caption generation include leveraging descriptions for image indexing and retrieval and helping those with visual impairments by transforming visual signals into information that can be communicated via test-to-speech technology. Most of the current approaches employed the encoder-decoder framework, in which encoder usually consists of convolutional neural networks (CNNs), in order to obtain a fixed length of feature vectors from input image as visual representation; while the decoder adopts recurrent neural networks (RNNs) [1], [3]–[6] or attention-based neural network (such like Transformer) [7]–[9], [10], [11] to decode image visual features into flexible length captions.
Recently, many captioning approaches tend to take region proposal features as their input features inspired by the progress made in the CV [12]–[14]. Region proposal features refer to a set of visual features extracted for each region proposal through an object detection model. Compared to a fixed single vector, the object features are stored separately and integrally, therefore this kind of representation method could provide more accurate and complete visual information.However, there are some challenges when taking region proposal features as inputs in the captioning task, because the intrinsic gap naturally exists between the tasks of object detection and image captioning, and further cause a result that the region proposal features obtained from the former task may not serve well for the latter directly. Specifically, only a small portion of region proposals are essential for captioning at each step of word generation, which means that there are many noises and distractions to mislead the decoder, and it is difficult to let the decoder keep attention on these correct areas when “looking for” the needed visual information in the process of caption generation.
In order to address the above-discussed challenges, many works adopted various attention mechanisms [15] and more complicated sequence generation networks. The attention mechanism was introduced in captioning tasks to leverage the above problem by helping the decoder only pay attention to most related areas. Meanwhile, with the recent successes in NLP [7], [16], [17], the self-attention mechanism is powered by assigning different weights to previously got words, and the Transformer proposed in [7] has the ability to summarize the “past” (previously obtained words) much more accurately.Most of captioning approaches only try to “ look inside”,including already got words, state of the model, etc., in order to extract the needed visual information from region proposal features, but ignores the external latent contribution (i.e., the degree of the inherent importance of region proposal for captioning task) that actually inherently existed in the image and could affect the result of caption generation.
To overcome this gap, our motivation aims at exploring the latent contributions for region proposals and utilize these clues in the decoder to help visual feature extract. The latent contribution could provide external guidance for the language module so that the decoder could better attend on these critical proposals and less chance to be misled. This inherent characteristic hints that these areas with high latent contribution would have a higher chance to be attended and mentioned, while the chance of the rests are relatively much lower. An example is given in Fig. 1 . The areas in blue bounding boxes, i.e., tagged “fireplace”, “stocking” and“chair”, are easier attended by us to take as caption contents,while the areas in orange bounding boxes, i.e., tagged“flower”, “clock”, “lamp” and “door” might be ignored,which is also verified in the ground-truth captions of this image in the MS-COCO dataset. This phenomenon illustrates the situation that region proposals have inherent different degree impacts for image captioning. We human beings could get these latent contributions of region proposals at the first glimpse of the input image.

Fig. 1. An example shows that local regions with different probabilities being mentioned in caption text, in which blue boxes are easier being mentioned than blue boxes.
In our work, we proposed a novel global-attention-based neural networks (GANN) to incorporate the latent contributions in decoder. First, we extract such a global caption feature by taking region proposal features as input in encoder, which could used for predicating the caption objects(i.e., the objects mentioned or will be mentioned in captions)directly; after that, the final weights in attention module of each decoder layer is obtained by combining latent contributions (global weights) and local weights, in which the former reflect the importance of each region proposal“globally” by taking feature caption feature as query vector,while the latter reflects the importance of each region proposal“locally” by taking hidden state vector as query vector at each specific time step of word generation.
The main contributions are summarized as follows:
1) We proposed a global-attention-based neural network for image captioning, in which we could incorporate the latent contributions of region proposals into the attention module of decoder so that the decoder can better attend on correct and related region proposals in the process of caption generation.
2) We proposed a novel method for global caption feature extraction, which is treated as a multi-class multi-label classification problem and jointly trained with the caption model.
3) We perform comprehensive evaluations on image captioning dataset MS-COCO, demonstrating that the proposed method outperforms several current state-of-the-art approaches in most metrics, and the proposed GANN could improve previous approaches.
The rest of the paper is organized as follows: Section II introduces related works; Section III describes the global caption feature extraction and presents the GANN;implementation details and experiments are described in Section IV; finally, Section V concludes the paper.
II. RELATED WORKS
1) RNN vs. Transformer:Most of previous captioning approaches are built based on recurrent neural networks(RNNs) or Transform neural networks [7]. a) For the first category, approaches usually take a fixed length feature vector extracted from pre-trained convolutional neural networks(CNNs). For example, the works [6], [18] first employ RNNs and long short term memory (LSTM) as their language model in image captioning respectively, and the work [19] consider the training images as the references and proposed a reference based long short term memory (R-LSTM) model. b) For the second category, Transformer based model could achieve better performance in many sequence-to-sequence tasks through the multi-head self-attention mechanism, like reported in many machine translation works [20], [21]. For example,the work [22] built its model based on transformer to explore the intra-modal interactions, and the work [23] tries to incorporate the geometric clues for image captioning. The results from these recent works illustrate that transformer based model could give more accurate captions.
2) Attention Mechanism:The attention mechanism [7], [15],[24] now is often adopted to help the decoder to extract needed visual information. We can understand these attention modules in captioning approaches from two aspects, i.e., the query vector, and multiple attentions fusion method. a) for the query vector, most of models [4], [25]–[27] adopt the hidden state as the query vector in attention module at each step of caption generation for given image or video, the works [11]propose a two layers attention approach, in which the top layer takes the output of bottom layer as query vector to generate the information vector and attention gate. b) for the fusion method of multiple attention, the work [28] compute the temporal attention on frames and spatial attention on image regions both using hidden state as query vector, and fuse these two kinds of attention in an adaptive way, and the work [23] fuse the position attention and self-attention in encoder in order to get geometry information involved. In our work, multiple attention weights are computed by taking hidden output of previous layer and global caption vector as query vector respectively, and fuse these two kinds of attention for involving the latent contributions in each step of visual information extraction.

Fig. 2. An example shows that local regions with different probabilities being mentioned in caption text, in which blue boxes are easier being mentioned than blue boxes.
3) Semantic Clues:Another approach [3], [29]–[31]considers incorporating semantic clues. The usage and extraction method for semantic clues vary in there approaches.a) for semantic clue extraction, the work [29], [32] tries to extract scene vector independently with caption model, while the work [33] and our work extract the semantic clues simultaneously along with the captioning model. b) for the usage of semantic clues, the work [33] uses a semantic embedding network layer to accept semantic clues as input and feed its output for decoder, the work [29] utilize the tag vector as semantic clues to guide the ensemble of parameters in language model, however, in our work, we take the semantic clues to calculate the global attention weights, which is hoped to help the encoder focus on the correct areas as knowledge priors.
III. GLOBAL-ATTENTION-BASED NEURAL NETWORK
In this section, the implement details and intuition of our proposed global-attention-based neural network (GANN) will be described and discussed. Fig. 2 shows the structure of our proposed approach. In the encoding phrase, region proposal features are extracted from the input image through the pretrained Faster-RCNN model, then feed into the encoder as well as an inserted empty vector (same role of “sos” embedding vector in BERT). After that, the encoder outputs the encoded features and the global caption feature, which are followed by additional classification layers for caption objects predication as a multi-class multi-label problem. In decoding phrase, the global caption features would be employed to explore the latent contribution for each encoded region proposal feature in multi-head global attention layer, to help the decoder better attend on these most related region proposal. The word embedding layer and position embedding layer in decoder are ignored in the above figure to avoid ugly layout. The arrangement of the section is as follows: first in Section III-A, we will introduce the extraction of global caption feature; and then we will depict a standard Transformer neural networks structure in Section III-B; after that, the Section III-C will focus on introducing the details of the GANN, finally, the objective functions will be given in the Section III-D.
A. Global Caption Feature Extraction
In this subsection, we will introduce the extraction of the global caption feature in encoder which is illustrated in top of Fig. 2. Our encoder takes the work [23] as bias and takes the region proposal features as inputs, which is extracted through a pre-trained Faster-RCNN [13] (identical to the work [4]),and output the global caption feature as well as the encoded region proposal features. Additional FFN networks is following the encoder to predicate the caption objects by taking the global caption feature as input. In this way, the global caption feature is endowed the caption object information which by give the region proposal occurring caption object to be more chance noticed in the caption generation process.
We will first introduce the selection of caption object labels and then create the caption object label vector as ground truth for each image in training set. After the caption vocabulary is obtained using all ground-truth captions from training set, we select these noun words from this vocabulary with the occurrence is higher than 100, here we get 359 caption object labels for the dataset MS-COCO. In order to eliminate duplicate words and ambiguities, we re-category these words into different classes, including combining singular and plural forms, removing gender attribute, for example, we cast the words “he”, “him”, “she”, “her” into the same class, saying“people”. After this process, we get 220 unique caption object labels. In each position of caption object label vector, we set its value as 1 if corresponding caption object appear in given captions, otherwise, set its value as 0. The obtained labels in training data will be used to guide the global caption feature extraction for predicating the caption objects through auxiliary classification layers.
When predicting the caption object labels for a given image.Motivated by [29], we treat this problem as multi-class multilabel classification problem. Here, we will define a loss function for this task, and the corresponding network structure could be found in Fig. 2. Suppose there are an input image in training set, andl=[l1,...,lK]∈{0,1}Kis its label vector,Kis the dimension of caption object label vector, thenlk=1 if the image is annotated with the labelk, otherwiselk=0. we denote the input image representation for encoder asR=[r0,r1,r2,...,rn], in which we inject a special empty featurer0(zero vector) into region proposal featuresri,i∈1,2,...,n, andnis the number of region proposal. Ther0is the embedding of placeholder token for extracting global caption feature, playing the same role of “ 〈 s os 〉” embedding vector in NLP model, like BERT [16]. For convenient, we denotetheoutputsofencoder asY¯=[y0,y1,...,yn],andY=Yˆ−{y0}isencodedfeatures,wherey0is the corresponding output in position ofr0. FFN means feed forward networks following the encoder which is used for projecting the global caption feature into label distribution. We give following equations:

B. Standard Transformer
In this section, we will introduce the architecture of the standard Transformer network given by work [7], which is the based model for our work. We adopt the same approach to build our the word embedding layer and the position embedding layer as the transformer [7] work which has been ignored in Fig. 2 for page courtesy.
The encoder and decoder in Transformer both consist a stack of layers (we set to 6 in our model), and each layer is composing by a multi-head self-attention layer, and a multihead attention layer, pulsing a FFN layer, where the first two layers both are composed by 8 identical heads with independent parameters and the network structure is the same as [7]. The network structure of head is shown on the right side of Fig. 3. Inspired by previous work, such like [23] in captioning task, we adopt the similar configuration as used in transformer. In each head of self-attention, the inputs are provided by the output of previous outputs (except the first layer take the sum of masked word embedding layer and position layer as input), however in multi-head attention layer of decoder, the inputs of each head provided by the encoded region proposal featuresYand the output of previous layerXat the same time.
For convenience, we denoteA∈{X,Y}, in whichXis the output of previous layer, andYis encoded features from encoder. We take thatAequalsXfor these attention head in multi-head attention layer of encoder, otherwiseAequalsY.At the attention calculation process in each head, the queryQ,keyK, and valueVwill be calculated first for each of input tokens using the following linear projections:
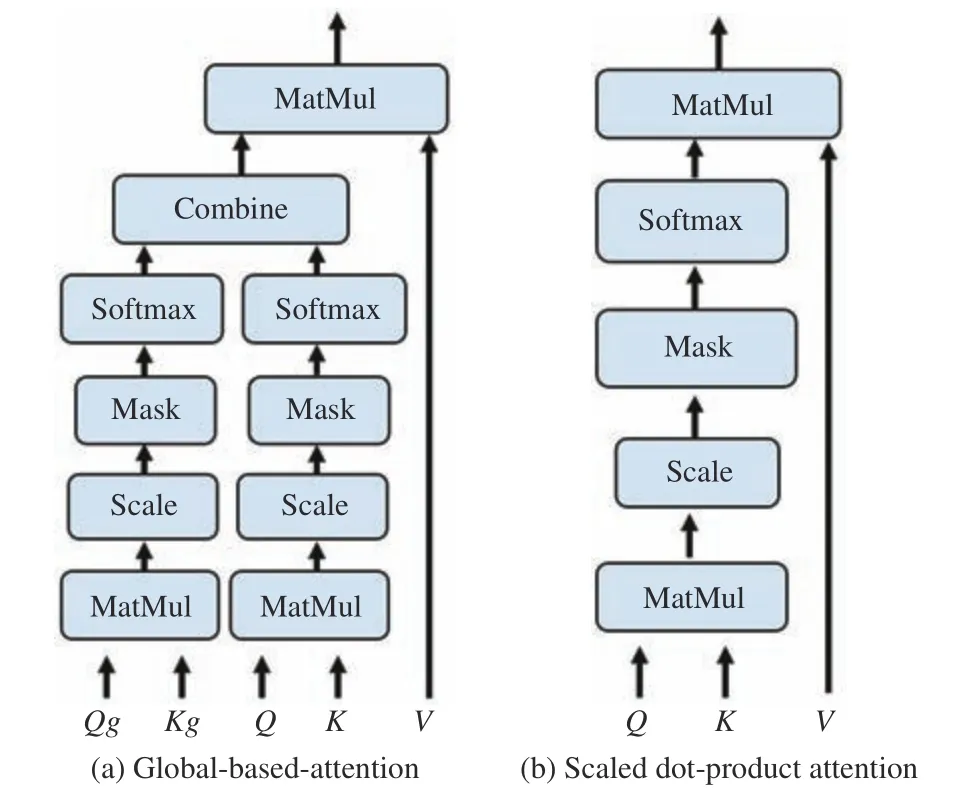
Fig. 3. The architecture of proposed global-based attention neural network(GANN) compared the scaled dot-product attention. Compared to (b), our proposed neural networks (a) incorporate external latent contributions of region proposals into attention calculation process.
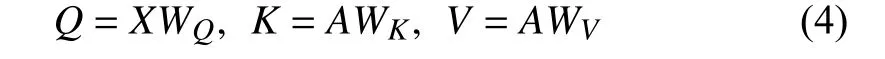
whereX∈RN×nmodel,WQ,WK,WA∈Rdmodel×nmodelare learned matrices for getting the query, key and value respectively, anddmodelis the dimension of internal vector in each head.
We will introduces the process of the attention weight calculation in each head as follows:



Equations (4) to (6) are calculated independently in each head. The final output of each layer is got by concatenating the output of all heads to one single vector, whose dimension is 512, and then multiplied with a learned projection matrixWOas the final output of this attention layer, i.e.,

The next component of in each encoder and decoder layers is the point-wise F FN , which is applied to each outputxof the attention layer.
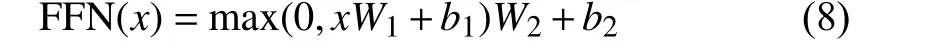
whereW1,b1, andW2,b2are the weights and biases of two fully connect linear projection layers. In addition, skipconnections and layer-norm are applied to the outputs of the self-attention and the feed-forward layers.
C. Global-Attention-Based Neural Network
At this section, we will introduce the proposed GANN and give some intuition explanations about the reason why the global attention mechanism works. First, The global caption feature obtained from the encoder carries the caption object information, which could offer some help for the model to attend the most related region proposals and therefore benefit for caption generation. We let the extracted global caption feature get involved in the attention weight calculation process in each head of every decoder layer, because we believe that the attention could be affected not only by the “internal”factors, like current state and memory of model, also by the“external” latent contribution of each region proposals. We compute these two kinds of attention weight separately, and then try to combine two weights together using the method used in (12).
We will depict the definition of the GANN here. Supposed that we got global feature vector from encoder annotated byy0for input image, i.e., the corresponding output for the ejected empty inputs of encoder, and we denoteYis the encoded region proposal features though encoder, i.e., the set of the output from encoder exclude the global feature vectory0. We define the global attention weight as follows:


At the same time, we use hidden output at current time step by the multi-head self-attention module in each decoder layer,i.e., the content information, to obtain the local attention weight matrix using the equations from (4) to (5), like most of models do at the decoder module, the weight is calculated in following equation:

whereWijmeans the element of the final attention weight matrixW. As for decoder structure, we employ the similar neural network structure as transformer [7], each layer is constructed by a self-attention layer, and a GANN followed by a feed-forward layer, the corresponding neural network structure is shown in Fig. 2. and the outputV¯ of the head is then calculated as
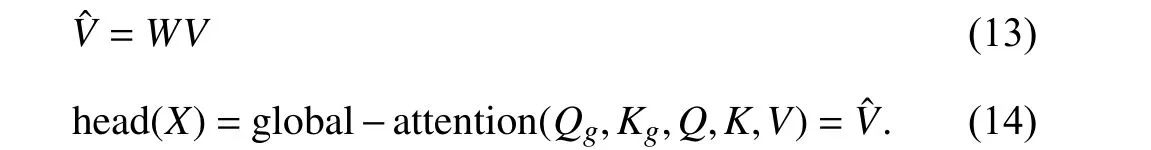
The global attention encoding diagram shown in Fig. 2 shows the multi-head global attention layer of GANN, which would be repeatedly applied in each layer of decoder in the same way as the work [7].
D. Training and Objectives

For fair comparisons with the works trained using selfcritical sequence training (SCST) [34], we also report the results optimized for CIDEr [35]. Initializing from the corssentropy trained model, we seek to minimize the negative expected score

IV. EXPERIMENTAL EVALUATION
We conducted our experiments on the benchmark dataset for image captioning, and quantitatively and qualitatively compare the results with some state-of-the-art approaches in Sections IV-C and IV-D, respectively. Also, we conduct some ablative analysis about the effect encoder structure for global caption feature extraction, the effect of GANN on decoder,and the effect of the value of trade-off factor λ.
A. Dataset and Metrics
Our experiments are conducted on the Microsoft COCO(MS-COCO) 2015 Captions dataset [36], which totally includes 123 287 images. All of our experiments result on the Karpathy validation and test splits [37] that are widelyadopted in other image captioning approaches. There are 5 K images in Karpathy test and validation sets respectively. The final caption results are evaluated using the CIDEr-D [35],SPICE [39], BLEU [40], METEOR [41], ROUGE-L [42]metrics.

TABLE I COMPARATIVE ANALYSIS TO EXISTING STATE-OF-THE-ART APPROACHES. WE COMPARE THE ORIGINAL MODEL WITH THESE MODELS WITH THE PROPOSED GANN. TWO KINDS OF RESULTS ARE PRESENTED, I.E., SINGLE MODEL AND ENSEMBLE METHOD. ALL RESULTS ARE OBTAINED ON MS-COCO “KARPATHY” TEST SPLIT, WHERE M, R, C AND S ARE SHORT OF METEOR, ROUGE-L, CIDER-D AND SPICE SCORES. ALL VALUES ARE REPORTED AS PERCENTAGE (%)
B. Implementation Details
Our algorithms was developed in PyTorch taking the implementation in [23] as our basis. We conduct experiments on NVIDIA Tesla V100 GPU. The ADAM optimizer with learning rate is initialized by 2×10–4and annealed by 0.95 every 3 epochs. We increase the scheduled sampling probability by 0.05 every 5 epochs [43]. We adopted the same warm up method as the work in [23], and set our batch size to 16. Before starting training the decoder, we took a pre-training procedure on encoder separately using the caption object prediction loss function defined in Section III-A in first 10 epochs. After that, we jointly trained the encoder and decoder in future epochs usingLXEjoint. We also trained another version model with self-critical reinforcement learning method (SCST) [34] using the objectives defined in 19 for CIDEr-D score when the loss score on the validation split does not improve for some training steps. In the cross entropy training and CIDEr-D score optimization method, early stop mechanism is adopted in all phrase of training.
C. Quantitative Analysis
In this subsection, we will show our experiment results,which demonstrate that the proposed global attention method can enhance the performance for the task of image captioning.First, we select three most representative state-of-the-art methods, which include both the regular image captioning decoder and Transformer based decoders. The comparison methods are briefly described as follows: 1) Up-Down [4], in which a separate LSTM is used to encode the “past” word in accumulate way, and an attention mechanism is utilized at each step of word generation; 2) RFNet [38], which tries to fuse encoded features from multiple CNN models; 3) GCNLSTM [26], which predicates visual relationship clues in each entity pairs and encodes this information into feature vectors through message passing mechanism; 4) Att2all [7], which maximum reserves the structure from the Transformer design for machine translation; 5) AoANet [11], which proposes an“attention on attention” module to determine the relevance between attention results and queries; 6) ObjRel [23], the geometric is involved in encoder for a purpose of exploring the spatial relationships among region proposals.
For fair comparison, the models in Fig. 1 are trained in the same method using first trained XE loss and then optimized for CIDEr-D score, and two kinds of results, i.e., single model and ensemble models, are shown in Table I. In this table, we can see that our single model achieves the highest scores on BLEU-1, BLEU-4, CIDEr-D, and SPICE metrics, and on all metrics in ensemble models. As for the result using CIDER-D optimization, we achieve the best performance on BLEU-1,BLEU-4, ROUGE-L, SPICE in single model, and get 39.1 score on BLEU-4 score in ensemble models, which illustrates that our proposed GANN could enhance the performance for captioning task.
D. Qualitative Analysis
In Fig. 4 shows a few examples with images and captions generated by comparison models and compared results with our proposed GANN. We derive the captions using the same setting and training method, i.e., SCST optimization [34].From these examples, we find that these “base” models areless accurate for the image content, while our method could give relatively better captions. More specifically, our proposed global attention method is superior in the following two aspects: 1) our proposed GANN could help language model correctly focus on the caption objects. For example, our proposed method could help the model attend on the “flight”in the first example, and “tv” on the second example in Fig. 4,while the other models choose to ignore them. 2) our proposed GANN could help the language model count objects of the same kind more accurately. For example, there are two benches and two motorcycles in the third and fourth image in Fig. 4, but the comparison models only give one in their captions. However, our proposed model only tend to recognize concrete objects while ignores the relatively abstract concept compared to the ground truth captions, such as in the fourth image, our model could not give “autumn”, “fall” these season words, this limitation of understanding higher concepts will be our next research target in future work.

TABLE II THE EXPERIMENT RESULTS OF MODELS COMPOSED BY DIFFERENT METHODS OF GLOBAL CAPTION FEATURE EXTRACTION AND DECODERS ON MS-COCO “KARPATHY” TEST SPLIT. ALL OF THESE EXPERIMENTS ARE TRAINING IN THE SAME METHOD USING XE-LOSS. ALL VALUES ARE REPORTED AS PERCENTAGE (%)

Fig. 4. Examples of captions generated by the comparison approaches and our proposed approach along with their ground truth captions.
In Fig. 5, we visualize region proposal with the highest attention weight in each time step of caption generation process. We select [7] as the “base” model and “base” +GANN as comparison, and training process are exactly the same using XE-loss which has been discussed above subsection. Observing the attended image region in Fig. 5, we find that the “base” model was attracted by the car behind the motorcycle, and the caption decoder generate the caption directly based on the attention result, therefore the corresponding caption is about that car. In contrast, the “base”+ GANN caption model could correctly focus on the “man”and “motorcycle” with the help of global caption feature and the proposed GANN, because it plays a role of reminder for language module at each time step of word predication.
E. Ablative Analysis
We conducted additional experiments to study three kinds of impacts for the caption generation results: 1) the method of global caption feature extraction, 2) the effect of GANN on decoder, 3) trade-off factor λ in the joint training process. All the results are obtained using the XE-loss and the same training method.
1) Method of Global Caption Feature Extraction:We choose two additional kinds of methods besides our method mentioned in Section III-A to extract the global caption feature. More specifically, the mean method and CNN-based network are adopted, whose network architecture are shown in Fig. 6. In the experiments, we use Up_Down [4], LSTM and transformer [7] as decoder for comparison. The result presented in the Table II, we can see that the global caption feature extracted through Transformer based encoder could obtain a better result compared to another two kinds of encoder network structure on almost all metrics. For example,the model [7] with Transformer based encoder obtained 6.2 and 3.1 higher score on metric of CIDEr-D compared to the models with Mean and CNN based encoder respectively.

Fig. 5. Visualization of attention regions in 6th layer of decoder for the “baseline” model and “baseline” with GANN. The “baseline” model can be easily misled by irrelevant attention while “baseline” with GANN is less like so.

TABLE III THE EXPERIMENT RESULTS OF SEVERAL “BASE” MODELS AND “BASE” MODELS WITH GANN ON MS-COCO “KARPATHY” TEST SPLIT.ALL OF THESE EXPERIMENTS ARE TRAINING IN THE SAME METHOD USING XE-LOSS. ALL VALUES ARE REPORTED AS PERCENTAGE (%)

Fig. 6. Two neural network structure of encoder for global caption feature extraction, i.e., the mean operation and convolutional neural networks, are adopted to obtain the global caption feature respectively in above figure.
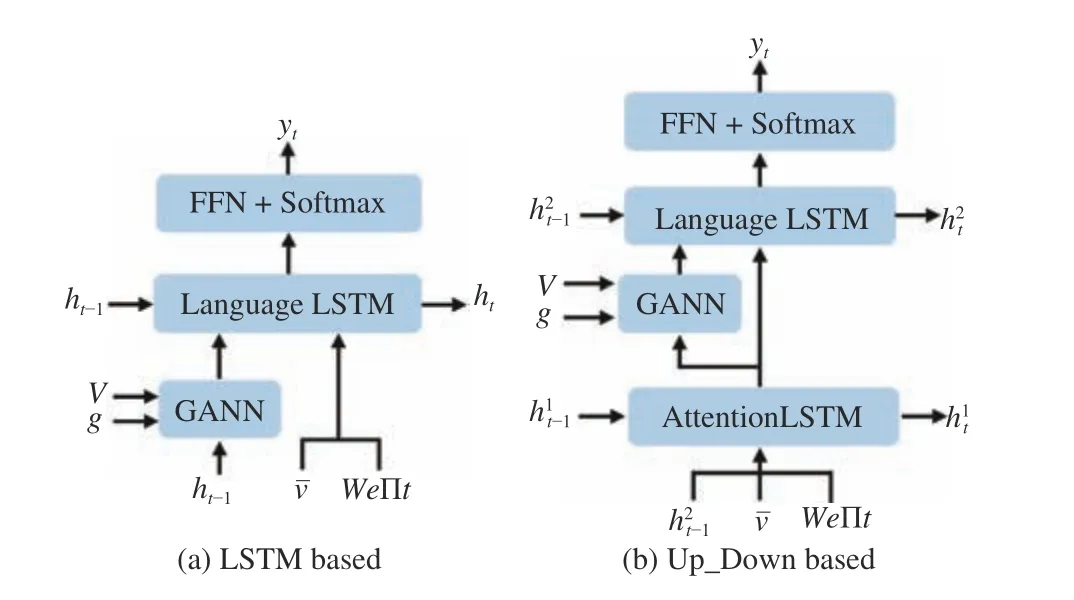
Fig. 7. Two neural network structure of decoder, i.e., the LSTM based decoder and and UP_Down based decoder, are adopted respectively in above figure in order to study the effect of GANN on decoder.
2) Effect of GANN on Decoder:Besides our Transformerbased decoder, we choose another two kinds of network structures as language module as comparison to explore the effect of GANN on decoder. The another two kinds of decoders are LSTM and Up_Down, which is shown in Fig. 7.In all experiments, the global caption feature extraction method is the same, i.e., the Transformer based encoder. We compare these three “base” model with “base” + GANN model, and the results are shown in the Table III. We find that our proposed the GANN could improve the performance compared to original caption models. For example, our model(the last line of Table III) achieves 1.3 and 2.3 increment over the metrics of METOR and CIDEr-D respectively.

Fig. 8. The performance affected by the trade-off factor of λ. In above we show 4 main metrics curve obtained by different value of λ sampled from 0.1 to 0.5,and 0.05 as separation distance.
3) Effect on the Trade-off Factorλ:We also study the effect of λ on final performance, i.e., the trade-off factor between the loss for caption objects predication and XE-loss for caption generation, which is defined in Section III-D. The result is shown in the Fig. 8, in which the value of λ is chosen from the from 0 .1 to 0.5 and 0 .05 as separation distance. From the result, we can see that the λ value actually affects the final performance of our model, and it is also hard to get such a value for λ that all metrics could be optimized to maximum score. We take BLEU-4 as our bias, and select the λ to 0.2 in our experiments, in which we can obtain the BLEU-4 score 37.8, and corresponding results are shown in Table I.
V. CONCLUSION
In this paper, we proposed a global-attention-based neural network (GANN) for the captioning task, which enhances conventional attention mechanisms. GANN explores the latent contributions of region proposals and helps the resulting model correctly focus on the most relevant areas, which further improves the performance of the captioning model.Extensive experiments conducted on the MS-COCO dataset demonstrate the effectiveness of our proposed method.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Remaining Useful Life Prediction for a Roller in a Hot Strip Mill Based on Deep Recurrent Neural Networks
- Disassembly Sequence Planning: A Survey
- A Cognitive Memory-Augmented Network for Visual Anomaly Detection
- Human-Swarm-Teaming Transparency and Trust Architecture
- Lightweight Image Super-Resolution via Weighted Multi-Scale Residual Network
- Towards Collaborative Robotics in Top View Surveillance: A Framework for Multiple Object Tracking by Detection Using Deep Learning