融合卡方统计和TF-IWF算法的特征提取和短文本分类方法
2021-06-10李昌兵段祺俊纪聪辉张婷婷
李昌兵,段祺俊,纪聪辉,张婷婷
(重庆邮电大学 a.经济管理学院;b.计算机科学与技术学院,重庆 400065)
随着社交网络以及电子商务的兴起,产生了海量的短文本数据。这些短文本直接反映出人们对不同事件的情感和看法,对短文本信息的挖掘和对短文本的分类成为了热点话题。对短文本的分类研究是自然语言处理的一个重要分支,在搜索引擎、自动问答、舆情分析和情感分析等方面有重要意义[1]。
由于短文本内容短小、口语化严重且噪声大的问题,导致在情感分类的过程中特征极性不显著[2],对短文本内容精准分类的关键是对短文本重要内容的提取。一般通过引入外部语料库和文本自身的内容特征等方式实现。通过外部语料库拓展方法的有效性严重依赖于语料库的质量,计算缓慢、效率低下[3]。而基于短文本自身内容特征的方式是充分挖掘文本语义、词频等关键信息来获取文本的重要特征,对文本特征提取有较高要求。
本文提出了一种融合卡方统计和TF-IWF算法的特征提取和短文本分类方法,旨在解决TFIDF算法计算特征值权重范围小的问题,提升短文本分类的准确率。
1 研究现状
相比较于长文本,短文本的内容稀疏、信息单元难以准确采集,将传统的文本分类方法如支持向量机、朴素贝叶斯分类等直接应用于短文本分类难以取得好的效果[4-5]。针对此问题,研究者提出了一系列对短文本进行特征提取的办法,由此达到提升短文本分类精准率的目的。一部分研究者通过引入外部语料库来弥补短文本语料集信息密度低的缺点,另一部分研究者通过创造、改进提取短文本关键信息的方法使提取的短文本特征更具代表性。
1.1 引入外部语料库实现特征拓展
外部语料库通常指维基百科、知网等含有大量文本内容及语言材料的知识库,这些外部语料库可以给予短文本集信息补充,从而增加信息量。范云杰等[6]结合统计学知识和类别信息,通过外部知识库维基百科来建立语义集合。Hu Xia等[7]把短文本特征种子词融入建立的层次结构模型,再借助外部语料库来拓展获取基于种子词特征的语义信息。丁连红等[8]通过知识图谱计算推理短文本拓展信息,并将其运用于短文本特征。王盛等[9]通过外部数据库计算短文本中词语的上下位关系,再把这种关系利用于待测文本的特征,由此提升分类效果。基于外部语料库的短文本内容拓展方法非常依赖外部语料库的质量。对于一些涉及专业领域、用词前卫的文本内容难以起到好的作用,由此考虑借助短文本自身的特征挖掘方法。
1.2 基于短文本自身的特征挖掘方法
在不借用外部语料库的前提下,分析短文本内容、挖掘短文本潜在的语义关系来构建基于文本的特征集,如何精确的构建这种特征集合是目前研究的热点。张群等[10]基于Word2Vec训练词向量从粒度层面对短文本进行建模,再训练LDA主题模型完成特征提取的过程。郭东亮等[11]使用Word2vec的Skip-gram模型获得短文特征,接着送入CNNs中进一步提取高层次特征,最后通过K-max池化操作后放入Softmax分类器得出分类模型。于政[12]综合现有词向量模型,提出了基于编码isA关系的词向量模型,再将其推广到长文本领域,构建了短文本集长文本的语义向量表示法。TF-IDF算法[13]计算训练文本词语的权重,将权重最大的若干词语作为特征词,再通过其权重构建短文本特征组。TF-IDF的优点是算法简单易实施,但是存在特征词提取不准确、特征词权重方差较小,导致文本之间区分度低、分类效果不佳的问题。因此,本文对原有算法进行改进,提出融合卡方统计和TF-IWF算法的特征提取和短文本分类方法来解决上述问题。TF-IWF算法在计算文本词条权重时更加注重特征词之间的数量差异引起的特征词权重的差异。
2 短文本分类模型
2.1 卡方统计方法
卡方统计方法(CHI Square,CHI)通常是计算数据的分布和假设分布之间的差异,在此用作衡量某个词条和其所在类别之间的关联程度。如果卡方值越大,词条与类别的关联程度越大,词条体现类别的能力越强;卡方值越小,则二者关联程度越小,词条体现类别的能力越小[14]。特征词与类别关系如表1所示。

表1 特征词与类别关系
基于特征词t的计算方法如式(1)~(4)所示:
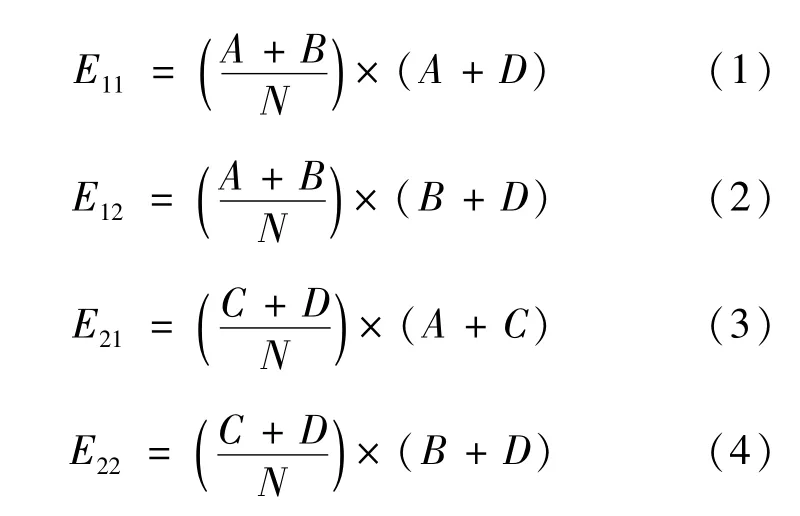
根据卡方检测公式计算特征词t与类别的关联度如式(5)所示:
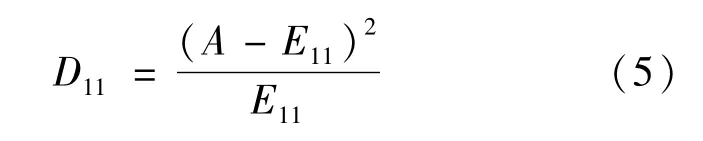
同理求出D12、D21、D22,代入并求解特征词t和ci的χ2值如式(6)所示:
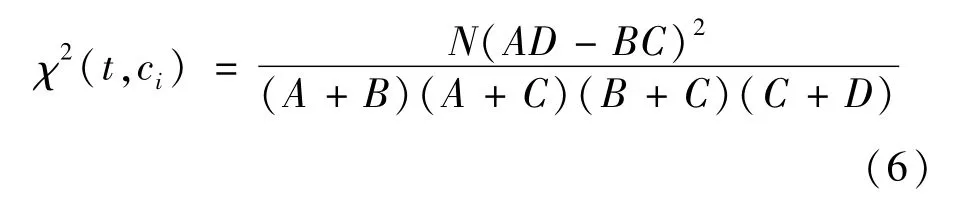
由式(6)可知,词语t与类别ci具有较低相关性时,χ2值越接近0。特征词t与ci类别具有较强相关性时,χ2值越大。
卡方统计方选取特征词步骤:
①在ci类 别 中 列 出 所 有 词 语ti,1、ti,2、ti,3、…、ti,j。
②计算每个词语tk与类别ci的Ai,k、Bi,k、Ci,k、Di,k。
③计算词语tk和类别ci的χ2(tk,ci)值。
④取χ2值最大的m个词语作为特征词。
2.2 TF-IWF算法
2.2.1 TF-IDF算法
TF-IDF(term frequency-inverse document frequency)是用来衡量一个词条能体现其所在文本多大的程度的算法。
词频(term frequency,TF)是衡量某个词ti在文档dj中出现的频繁与否指标,出现的越频繁则词频值越高,如式(7)所示:
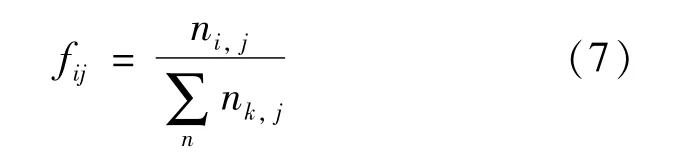
式中:ni,j表示此ti在文档dj中出现的次数;表示文档dj中所有k个词条出现的总数。
逆文档频率(inverse document frequency,IDF)是指包含词ti的文档数占文档总数D的比重的对数。IDF的作用是避免高频但对文档作用小的词汇获得较高的权重。如式(8)所示:
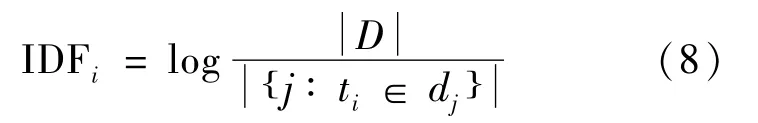
TF-IDF值由tfij值和IDFi值相乘得到,用si,j表示,其计算公式为
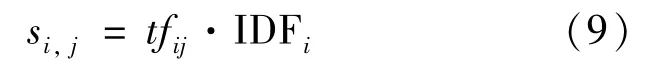
2.2.2 改进的TF-IDF算法——TF-IWF介绍
逆文档频率(inverse document frequency,IDF)只关注了文档个数之间的差异,忽视了词条在不同文档中数量的差异导致的词条逆文档频率权重的差异。
TF-IWF(term frequency-inverse word frequency)是用来评估一个词能体现出所在语料多大程度的算法。
词频(term frequency,TF)是衡量某个词ti在文档dj中出现的频繁与否指标,出现的越频繁则词频值越高,如式(10)所示:
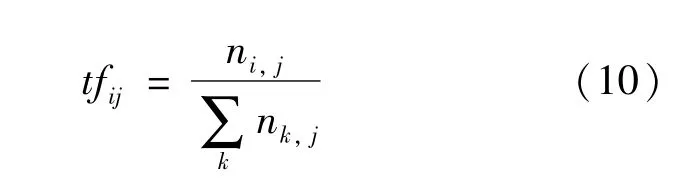
式中:ni,j表示词条ti在文档dj中出现的次数;表示文本dj中所有词条出现的总次数。
逆特征频率(inverse word frequency,IWF)是指词的总数占总文档数D的比重的倒数。IWF的作用是避免高频但对文档作用小的词汇获得较高的权重。如式(11)所示:
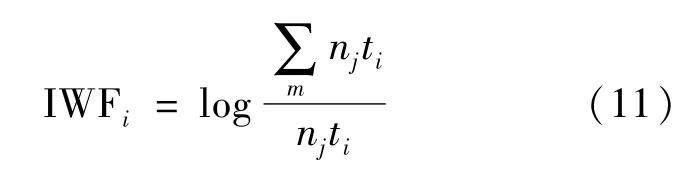
TF-IWF值由tfij值和IWFi值相乘得到,用wi,j表示,如式(12)所示:
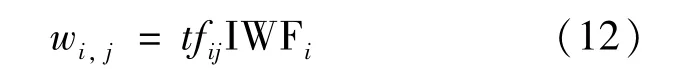
TF-IWF用来过滤常见的词条,给更能体现语料的词条赋予更大的权重。如果一个文本内部的高频词条在文本集合中呈现低频状态,则该词条的TF-IWF值有高的权重值。
2.3 短文本分类流程
本文特征提取和短文本分类的流程如图1所示。
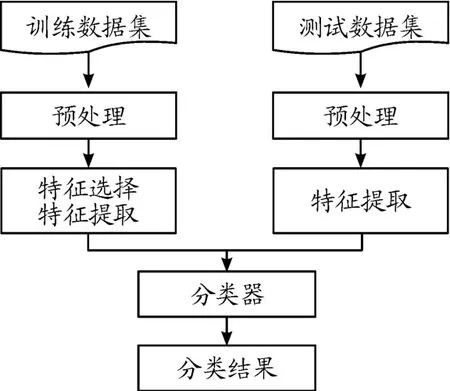
图1 融合卡方统计和TF-IWF算法的特征提取和短文本分类流程
首先进行数据清洗,对待训练文本进行预处理,包括分词、去停用词等。接着提取特征,计算所有出现在文本中的词条和其所在类别的卡方值,根据卡方值的大小按顺序排列各类中的词条。下一步是计算特征词的权重,按照上文描述的TFIWF算法分类计算已经提取的特征词条的权重。最后进入分类器分类,与其他分类系统相比,SVM是一类根据监督学习的方式来实现数据二分类的线性分类器[15-17],故选择SVM分类器作为分类模型。由短文本特征向量及其类别的标签训练SVM分类器。测试过程中对待测文本进行特征提取,再通过训练完毕的分类器预测待测试文本的所属类别。
3 实验
3.1 数据平台及数据集
1)实验平台
硬件平台基于Windows 7操作系统,内存为8 GB。算法部分均使用Python3.6语言进行编写,使用的Python模块包括自然语言处理库:Gensim 3.6.0;机器学习库:Sklearn 0.20.2;数学计算库:Numpy 1.15.4;进度处理库tqdm4.43.0。
2)实验数据集
收集了飞猪网上的酒店评论数据共10 000条,其中好评7 000条,差评3 000条。各类别80%的文本用于训练,20%的数据用于测试。训练集与测试集中的数据相互独立且不存在重复文本。所有数据经过预处理:去除英文文本、去表情符号、去重、去停用词等,并用结巴分词对数据进行分词处理。实验所使用数据集如表2所示。

表2 实验数据集
3.2 实验参数设置
1)基于卡方统计的特征选择模型参数设置
通过Python模拟不同的由卡方统计所得到特征数与文本分类效果的关系如图2所示,因此选择准确率收敛于最大值时的特征数400作为卡方统计得到的特征个数。
2)SVM文本分类器参数设置
SVM分类器参数设置如表3所示。
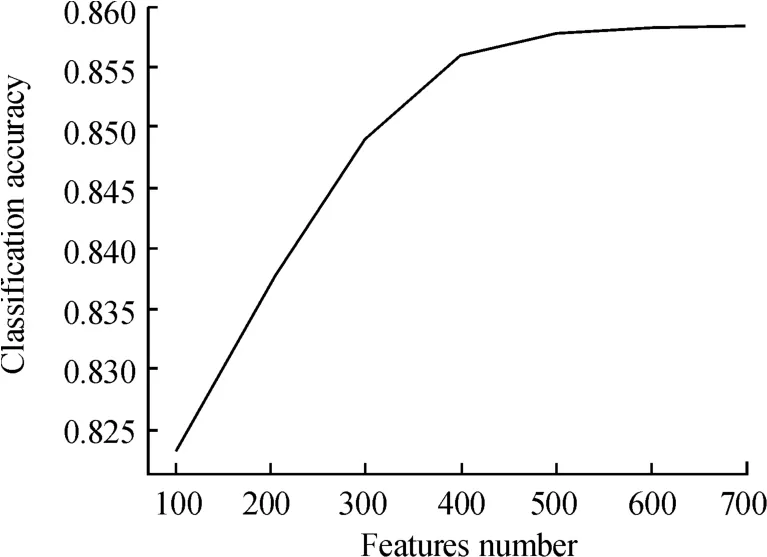
图2 特征数与测试集准确率的关系曲线
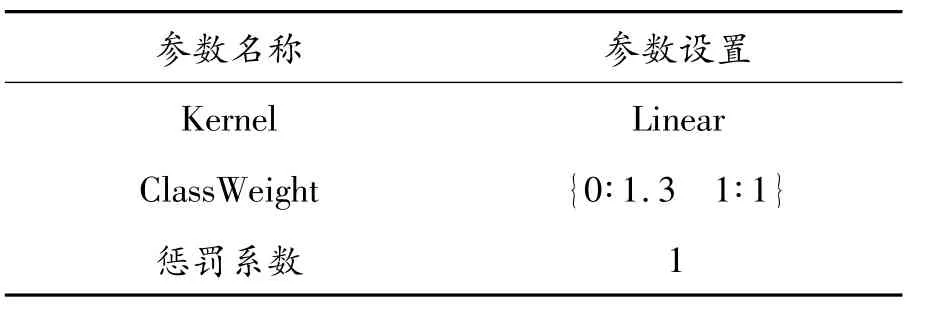
表3 SVM分类器参数
3.3 实验评估
准确率(precision)、召回率(recall)、和F1评分3项评价指标是分类实验中常用的指标。其中TP表示属于正类、预测也为正类的样本数量;FN表示属于正类、预测为反类的样本数量;FP表示属于反类、预测为正类的样本数量;TN表示属于反类、预测也为反类的样本数量。
准确率是指分类结果中被分类正确的样本数量占所有分类样本数的比例,如式(13)所示。
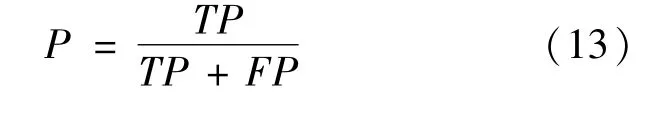
召回率是指分类结果中被正确分类的样本数量与该类的实际文本数的比例,如式(14)所示。
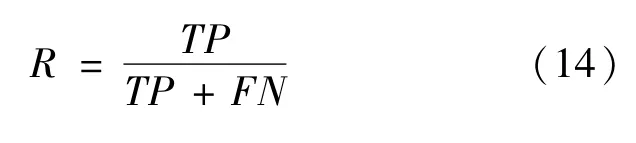
F1评分是融合准确率和召回率的一种综合性的评价标准,如式(15)所示。

3.4 实验结果及分析
3.4.1 基于特征选择的有效性验证
为验证基于卡方统计的特征选择的有效性,共设置2组实验:第一组实验使用融合卡方统计和TF-IDF特征提取的短文本分类方法,第二组基于TF-IDF特征提取的短文本分类方法,2组实验均使用SVM模型进行分类,结果如表4所示。
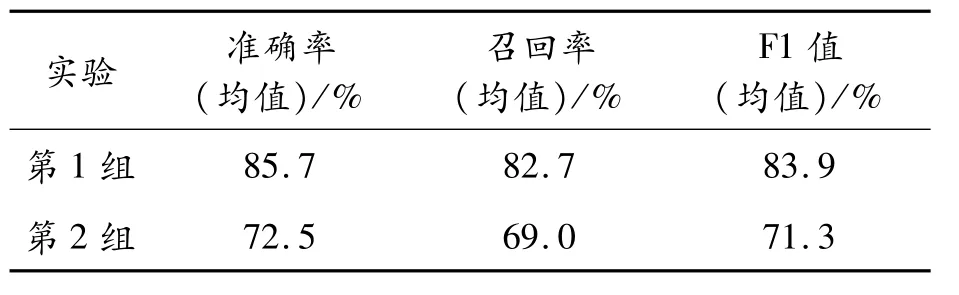
表4 基于特征选择的对比验证
融合卡方统计与TF-IDF的特征提取算法与基于TF-IDF的特征提取算法相比,实验各项指标明显提升。说明卡方统计提取特征词更加精准,卡方特征选择相比于TF-IDF进行特征选择是一种更好的特征选择方法。
3.4.2 基于特征提取的有效性验证
为验证融合卡方统计和TF-IWF算法的特征提取的有效性,共进行3组实验:第1组实验使用Word2vec方法进行特征提取;第2组实验使用融合卡方统计和TF-IDF算法的特征提取与短文本分类方法;第3组实验使用融合卡方统计和TFIWF算法的特征提取及短文本分类方法。3组实验均使用SVM分类器模型进行分类,结果如表5所示。
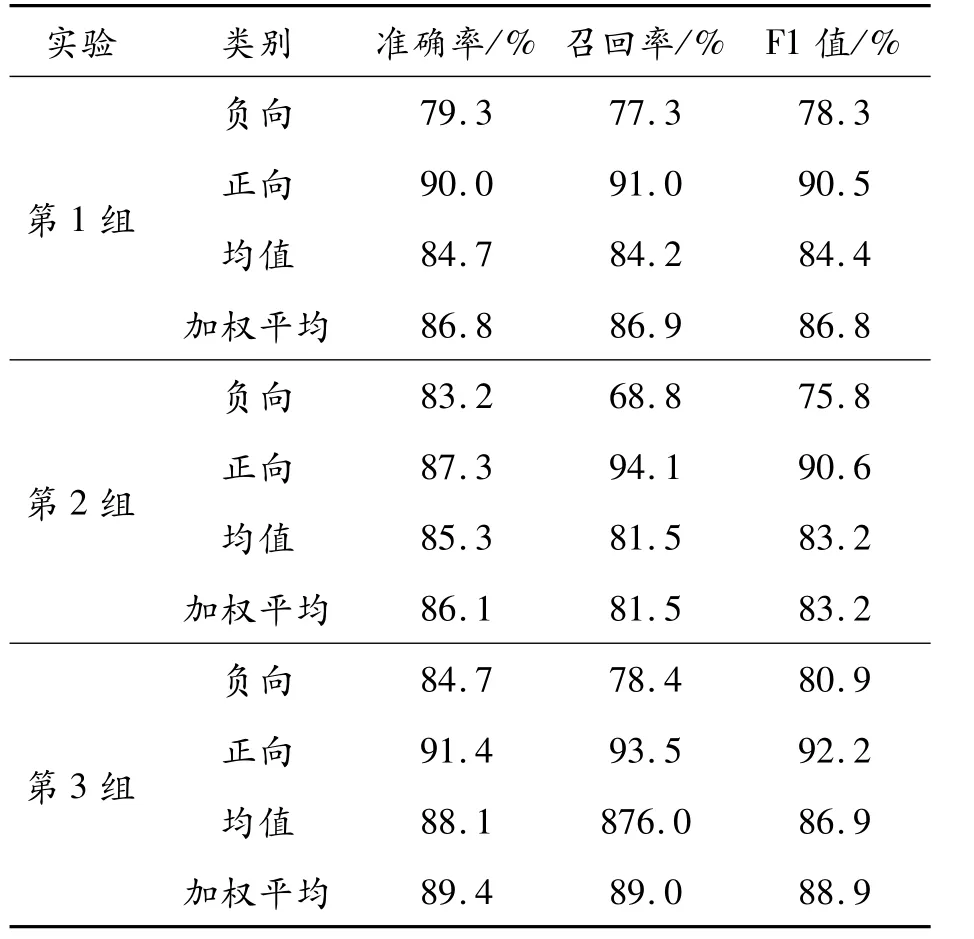
表5 基于特征提取的对比验证
实验结果显示,与基于未进行任何改进的TFIDF模型的文本分类方法相比,融合卡方统计和TF-IWF模型在正向文本的召回率上下降0.6%;其他分类指标:平均准确率提升2.8%、平均召回率提升4.5%、平均F1值提升3.7%;融合卡方统计和TF-IWF模型相比于Word2vector模型在各类分类指标下均有提升。说明融合卡方统计和TFIWF的模型在短文本特征的选择上更具有代表性,特征权重的计算更接近真实比重,提高了提取文本关键特征的能力。
3.4.3 基于TF-IWF算法的特征提取与短文本分类方法与其他分类方法对比
为对融合卡方统计和TF-IWF算法的特征提取与短文本分类方法的分类效果做出综合判断,将该方法与其他文本分类方法进行对比。向量空间模型(vector space model,VSM)作为传统的文本向量表征方法把文本内容简化为向量运算;支持向量机(support vector machine,SVM)是经典的按监督学习的方式对数据进行二项分类的分类器;而K近邻分类算法(K-nearest neighbor,KNN)[18]作为经典的机器学习分类算法具有操作简单、可解释性强的特性。因此,使用SVM分类器对VSM模型[19]所表征的文本向量进行分类,实验结果如表6所示。
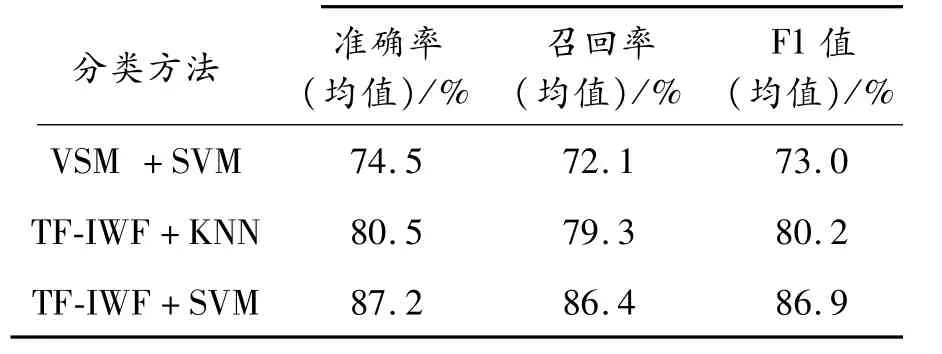
表6 基于分类方法的有效性验证
由表6可知,融合卡方统计和TF-IWF算法的特征提取与短文本分类方法相对于基于VSM模型的短文本分类方法在分类各项传统指标上均有较大程度的提升。
4 结论
针对文本分类中传统的特征提取算法得到特征表征的能力不强的问题,提出了融合卡方统计和TF-IWF的特征提取算法,该算法在一定程度上解决了TF-IDF权值分布集中导致文本区分度低的问题,并构建了融合卡方统计和TF-IWF算法的短文本分类模型,实验结果表明:该模型文本特征提取的能力有所增强,分类准确率得到提升。
