基于AOD-Net和SSD的雾天车辆和行人检测
2021-06-10陈琼红种一帆宫铭钱
陈琼红,冀 杰,种一帆,宫铭钱
(西南大学 工程技术学院,重庆 400715)
车辆和行人检测是实现智能交通以及自动驾驶的必经之路。在雾霾天气下,通过相机拍摄的图片对比度下降、可辨识度较低[1],严重影响城市道路上车辆和行人的检测。因此,利用雾天环境下的车辆和行人检测,精确感知道路前方的交通信息,对降低交通事故的发生率和保障驾乘人员的人身安全有重要意义。
雾天环境下的车辆与行人检测分为2个阶段,去雾阶段和车辆与行人检测阶段[2]。目前,雾天图片的去雾处理主要分为图像增强[3]和图像复原[4-8]两大类。He等[4]提出基于暗通道先验知识统计的去雾算法,该方法往往高估雾气浓度,导致去雾过度;Tang等[9]利用随机森林法对雾天图片中的特征进行学习,从而得到最优传播图;Cai等[10]提出DehazeNet,利用卷积网络[11-12]提取图片特征并得到图片传输图。该方法在某些特殊场景,会造成该环境下的传播图估计不准确,导致去雾效果不理想。综上所述,目前的去雾算法主要是根据大气散射模型原理,分别对传输图和全局大气光值进行估计,最终得到恢复的真实图片。本文选用AOD-Net(All-in-One Dehazing Network)算法[13],利用卷积网络对全局大气光值和传输图进行联合估计,从而得到恢复的真实场景图片,使得重建误差更小[14]。
在图像目标检测领域,利用深度学习进行目标检测的算法主要分为双阶段[15-17]和单阶段[18-19]两大类。“双阶段”是指先对图片生成建议候选区域,再进行预测识别,以Girshick R等提出的R-CNN系列为代表,其中Faster R-CNN对目标检测的影响较为深远;“单阶段”则不需要生成建议区域,直接进行预测识别,以Redmon J提出的YOLO系列和Liu W等提出的SSD(Single Shot MultiBox Detector)[19]为代表。其中,SSD网络延续了YOLOv1网络直接对检测对象回归出预测框和分类概率的特点,又借鉴了Faster R-CNN网络中利用RPN层产生大量的anchor的特点。除此之外,SSD的网络训练框架相对简洁,因此SSD与Faster R-CNN相比检测速度更快且检测精度与Faster R-CNN相媲美;SSD框架与YOLOv1框架相比,其检测精度和检测速度更高。本文选用SSD网络实现车辆和行人检测,其流程如图1所示。

图1 算法流程框图
1 雾天图片处理
在雾霾天气下,导致相机拍摄到的图片质量降低有2个方面,一方面是大气中悬浮粒子对入射光的散射作用,造成入射光从景物点传播到成像设备观测点的过程中出现削弱衰减现象;另一方面是大气中的大气微粒偏离原来的传播方向融入到成像光路中,并与目标物体的反射光一起参与成像。
McCartney提出大气散射模型理论[20]揭示雾天图片颜色衰退以及对比度下降的原因。大气散射模型由入射光衰减模型和大气光成像模型两部分组成。其中,入射光衰减模型描述场景反射光线传播到观测点的能量变化;大气光主要由同样直射光、天空散射光和地面反射光组成,因此传播距离越大,大气光在成像模型中的影响越大。
根据大气散射模型理论,得到雾天图像退化模型的公式如下所示。
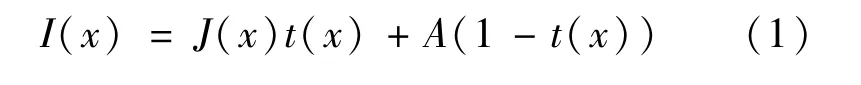
式中:I(x)为带雾图片;J(x)为恢复的真实场景图片;A为全局大气光值,表示观测方向上大气环境中其他光路在观测方向上的影响,一般为全局常量;t(x)为透射率,即传输图,描述光线对雾气的穿透能力,一般取值0~1之间。
当大气同质时,透射率可以表示为

式中:β为散射率,当大气均匀时,在一定时刻对于整幅图像来说β是一个定值;d(x)为场景对象到传感器的距离,即场景深度。
对式(1)进行整理,得到恢复的真实场景图片表达式为
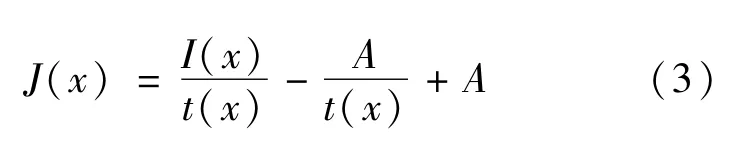
AOD-Net算法由K值估计模型和清晰图片生成模型2个部分组成,AOD-Net算法的模型如图2所示。
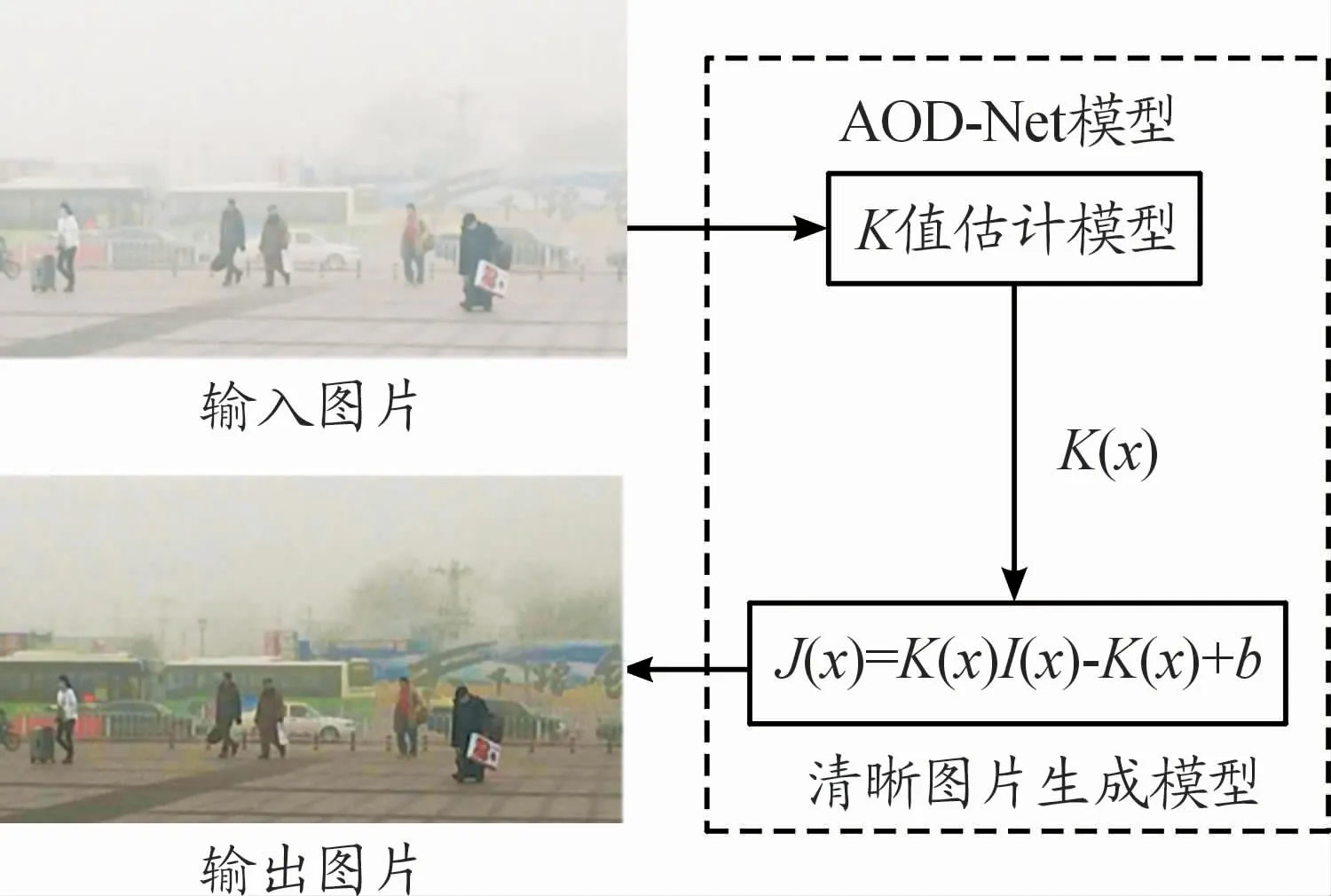
图2 AOD-Net模型
K值估计模型对输入图片的传输图和全局大气光值进行联合估计,如式(4)所示。
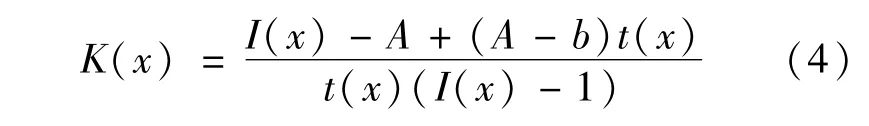
式中,b为常数偏置,默认值为1。
从式(4)可以看出,K(x)除了与透射率t(x)和全局大气光值A有关,还与输入图像I(x)有关,K(x)随着输入图像I(x)变化而变化,从而建立了一个输入自适应模型。通过最小化输出图像J(x)与清晰图像之间的重构误差来训练模型,使输出J(x)与清晰图像的误差最小,从而输出恢复的真实场景图片J(x)。
K值估计模型的结构如图3所示,由5个卷积层和3个连接层组成。卷积层分别采用不同大小的卷积核来提取不同尺度的特征,且每个卷积层仅使用3个卷积核。为了将不同卷积层提取到的特征相结合,在卷积层之间加入Concat层。其中Concat1将Conv1和Conv2提取到的特征连接在一起;Concat2将Conv2和Conv3提取到的特征连接在一起;Concat3将Conv1、Conv2、Conv3和Conv4提取到的特征连接在一起。利用Concat层既可以结合多种特征,实现从低层特征到高层特征的平滑转换;又可以补偿在卷积过程中的信息损失。

图3 K值估计模型
根据大气散射模型原理,将估计得到的K(x)代入式(3),得到清晰图片生成模型的公式如下。
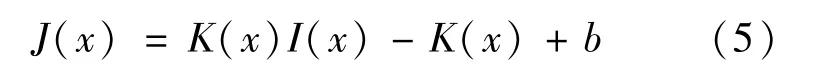
利用AOD-Net算法对图片的透射率t(x)和全局大气光值A进行联合估算,得到恢复的真实场景图片J(x),为后续SSD网络的模型训练奠定基础。
2 车辆和行人检测
本文采用SSD算法作为雾天车辆和行人的检测网络。在SSD网络中将提取到的多级特征图作为车辆和行人分类及其预测框回归的依据,在SSD网络中,靠前的卷积层提取到的特征图(大特征图)用于检测图片中远处的车辆和行人以及近处的小目标行人;靠后卷积层提取到的特征图(小特征图)用于检测近处的车辆和行人,从而达到多尺度特征的检测效果。SSD网络框架由基础网络层和辅助网络层2个部分组成,如图4所示。
1)基础网络层:本文选取VGG16作为车辆和行人检测的基础网络,将原VGG16中的FC6和FC7 2个全连接层分别改为卷积层Conv6和Conv7,然后去掉dropout层和FC8层。其中Conv6采用空洞卷积,使得网络在不增加参数及模型复杂度的情况下卷积视野指数级扩大。
2)辅助网络层:由位于基础网络层之后的4个卷积层组成,分别提取不同的特征图用于车辆和行人检测的分类和预测框回归。
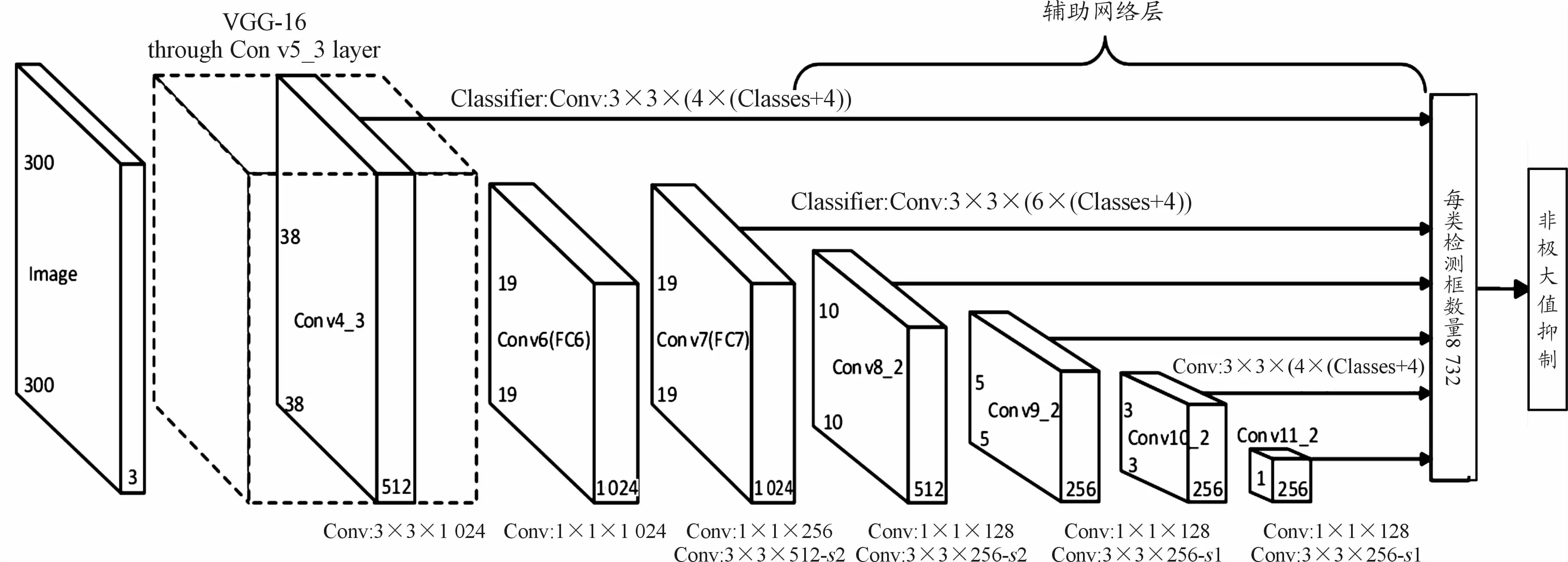
图4 SSD网络结构图
由图4可知,最后用于车辆和行人目标分类及预测框坐标回归的特征图由Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2和Conv11_2等提供,利用不同的特征图进行分类回归能够提升模型对车辆和行人的检测精度,且在每一层特征图上的每一个单元产生先验框的过程如下。
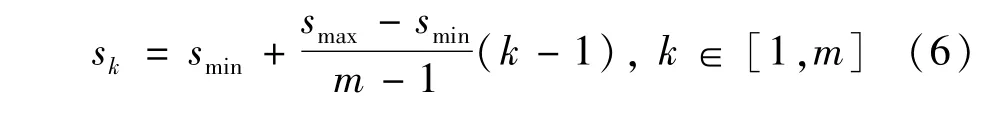
式中:m为特征图个数;sk为第k个特征图的尺度;smin为先验框的最小值,smin=0.2;smax为先验框的最大值,smax=0.9。
Conv4_3、Conv10_2、Conv11_2等卷积层提取特征图的每一个单元产生4个先验框,其高宽比ar1有2种尺寸,一般取ar1={1,2,1/2};对于Conv7、Conv8_2、Conv9_2等卷积层则产生6个先验框,其高宽比ar2有3种尺寸,一般取ar2={1,2,3,1/2,1/3}。
在形成先验框时,针对特定卷积层的特定高宽比,得到先验框的宽和高计算公式如下:

式中:ari取ar1或ar2内的数值。
当高宽比ari=1时,除了特定尺寸sk的先验框外,还会另设一个先验框,其尺寸为:
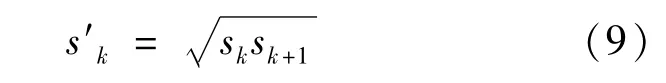
图片中生成的每个先验框都会预测一个边界框,因此一张图片共产生8 732个边界框。遵循一个先验框只能与一个真实框匹配,一个真实框可以与多个先验框匹配的原则。首先对雾天城市道路图片中每一个车辆和行人的真实框找到与其交并比(IOU)最大的先验框进行匹配;对于未匹配的先验框,若存在真实框与某个先验框的交并比大于0.5,则该先验框与真实框匹配。若一个先验框与多个真实框的交并比均大于0.5,则选择交并比最大的那个真实框与先验框进行匹配。其中与真实框进行匹配的先验框为正样本,反之为负样本。为了保证正负样本相对均衡,故对负样本进行抽样,并按照置信度误差进行降序排列,选取损失最大的前k个作为训练负样本,使得正负样本比例约为1∶3。根据SSD网络的匹配原则,训练得到车辆和行人检测模型的总损失(L)为位置损失(Lloc)和置信度损失(Lconf)的加权和,如式(10)所示。
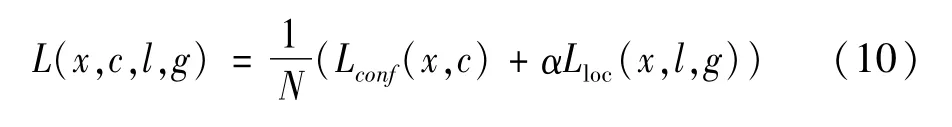
式中:α为权重系数,设置为1;N为边界框的数量,当N=0时,总损失为零。
车辆和行人检测的位置损失是预测框l和真实框g参数之间的Smooth L1损失,如式(11)所示。
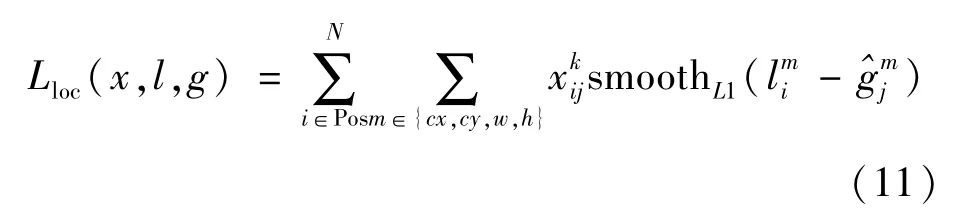
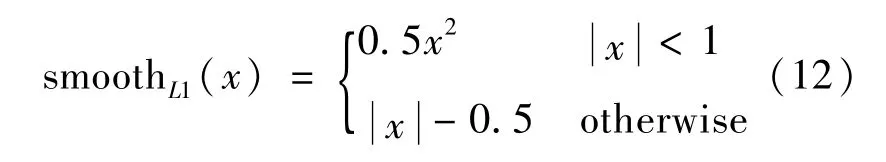
真实预测值是先验框d的中心(cx,cy)、宽度w和高度h相对于真实框的转换值,如下所示。

车辆和行人检测模型的置信度损失为Softmax Loss,其定义如式(17)。
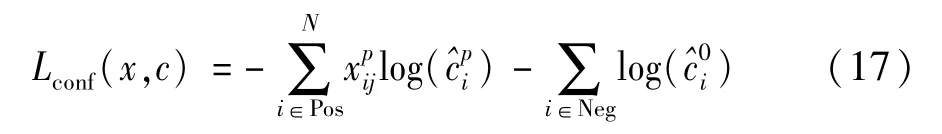
3 实验与结果分析
3.1 实验配置
本文实验的操作系统为Ubuntu 18.04.2,运行内存为64 GB,双NVIDIA RTX 2080Ti型GPU,Intel®Xeon(R)Gold 6242 CPU@2.80GHz处理器,并行计算框架版本为CUDA 10.1,深度神经网络加速库为CUDNNv 7.6.1.34。采用Python编程语言在Pytorch 1.1.0深度学习框架上完成模型的训练与测试过程。
3.2 去雾处理的结果分析
本文利用NYU2数据集[21]对AOD-Net网络进行训练,其中训练参数学习率为0.000 1,权重衰减为0.000 1,batch_size为8,epoch为10。利用训练好的去雾模型对真实场景下的雾天图片数据集RTTS[22]进行去雾处理,得到不同雾气浓度下,去雾处理前后的图片对比结果,如图5~7所示,其中(a)为原始带雾图片,(b)为去雾处理后的图片。

图5 薄雾的处理结果

图6 中雾的处理结果

图7 浓雾的处理结果
对图5~7中不同程度雾气浓度的处理结果进行对比分析知,雾天复杂交通环境下,经过去雾处理后的图片中被雾气遮挡的车辆和行人轮廓能够凸显,细节信息都更为丰富,颜色更加饱和,目标的可辨识度、对比度更高。
采用平均峰值信噪比(PSNR)和平均结构相似度(SSIM)对去雾处理前后的图片质量进行评价。其中PSNR为基于对应像素点间的误差,即基于误差敏感的图像质量评价,对一张H×W的图片,其公式如下所示。
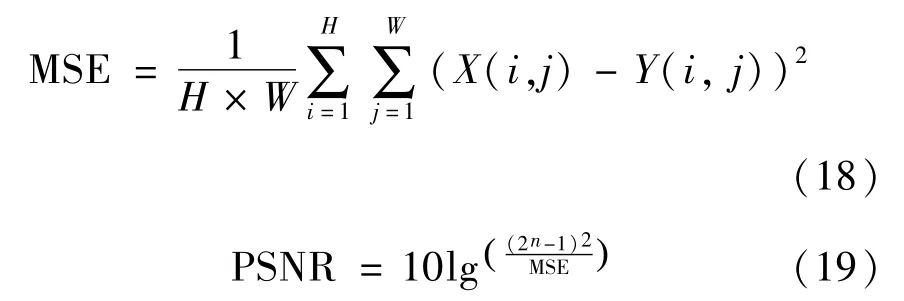
平均结构相似度分别从亮度、对比度、结构3个方面度量图像的相似性,其表达式如下:
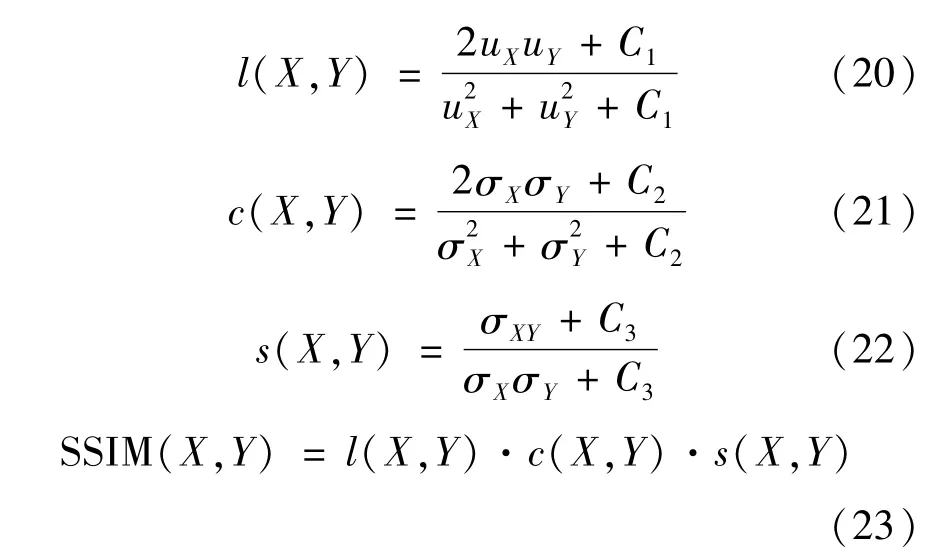
式中:uX、uY为图像X和Y的均值;σX、σY分别为图像X和Y的方差;σXY表示图像X和Y的的协方差;C1、C2、C3为常数项。
PNSR和SSIM值越大,表示图像失真越小。RTTS数据集去雾处理前后的PSNR和SSIM对比如表1所示。

表1 去雾处理前后的客观评价
通过表1可知,经过去雾处理后,图片的平均峰值信噪比和平均结构相似度分别提高了0.325 5、0.020 2。因此,去雾处理后的图片失真更小,噪音更少,对比度更高,图像更加明亮且目标物体的边缘信息更加丰富。
3.3 SSD网络训练
由于同时获取雾天图片和与之相对应的清晰图片在现实生活中较难,故在以往的去雾算法中均采用人工合成雾天图片进行模型训练。一般情况下,人工合成雾天图片的雾气浓度较低且分布相对均匀,与真实场景下的雾天图片有较大差距,因此利用人工合成雾天图片训练出的模型在真实雾天场景下的泛化能力和鲁棒性较差,因此本文采用真实场景下的雾天城市道路数据集RTTS进行模型训练。该数据集包含了不同场景和不同雾气浓度下丰富的车辆和行人图片,对RTTS数据集进行修改,将图片随机分为训练集、验证集和测试集3个部分,且训练集、验证集和测试集的比值为6∶1∶1,得到训练集图片共3 242张,验证集和测试集图片分别540张。对训练集中的图片分别进行水平翻转、旋转、拉伸、明暗变化以及添加高斯噪声等操作,得到更加丰富的数据集。训练的目标有“汽车”“自行车”“摩托车”和“行人”4种,数据集的示例如图8所示。

图8 RTTS数据集图片
为了验证将AOD-Net和SSD算法结合起来的优越性,利用RTTS数据集的原始带雾图片和经过AOD-Net去雾处理后的图片训练了2种不同的模型[2]分别用于车辆和行人检测。2种模型的基本训练参数均一致,batch_size设为64,学习率设为10-4,权重衰减设为5×10-4,betas设为(0.9,0.99),共训练560个epoch。采用Adam梯度优化器使2种模型的总损失快速收敛,具体训练过程如下。
模型1:将RTTS训练集的带雾图片进行AOD-Net去雾处理,然后将经过去雾处理后的图片作为目标检测网络SSD的输入,并依据上述的模型训练参数进行训练,得到车辆和行人的检测模型1,训练过程中的损失曲线如图9所示。
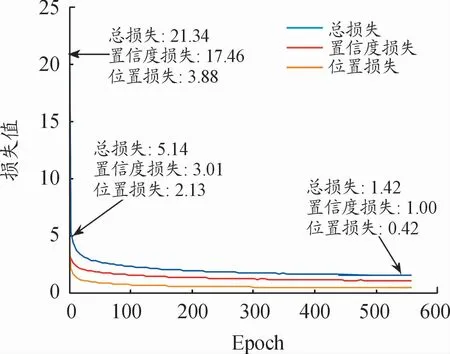
图9 模型1的训练损失曲线
模型2:将RTTS训练集的带雾图片直接作为目标检测网络SSD的输入图片。并根据上述的训练模型参数进行训练,得到车辆和行人的检测模型2,其训练过程中的损失曲线如图10所示。
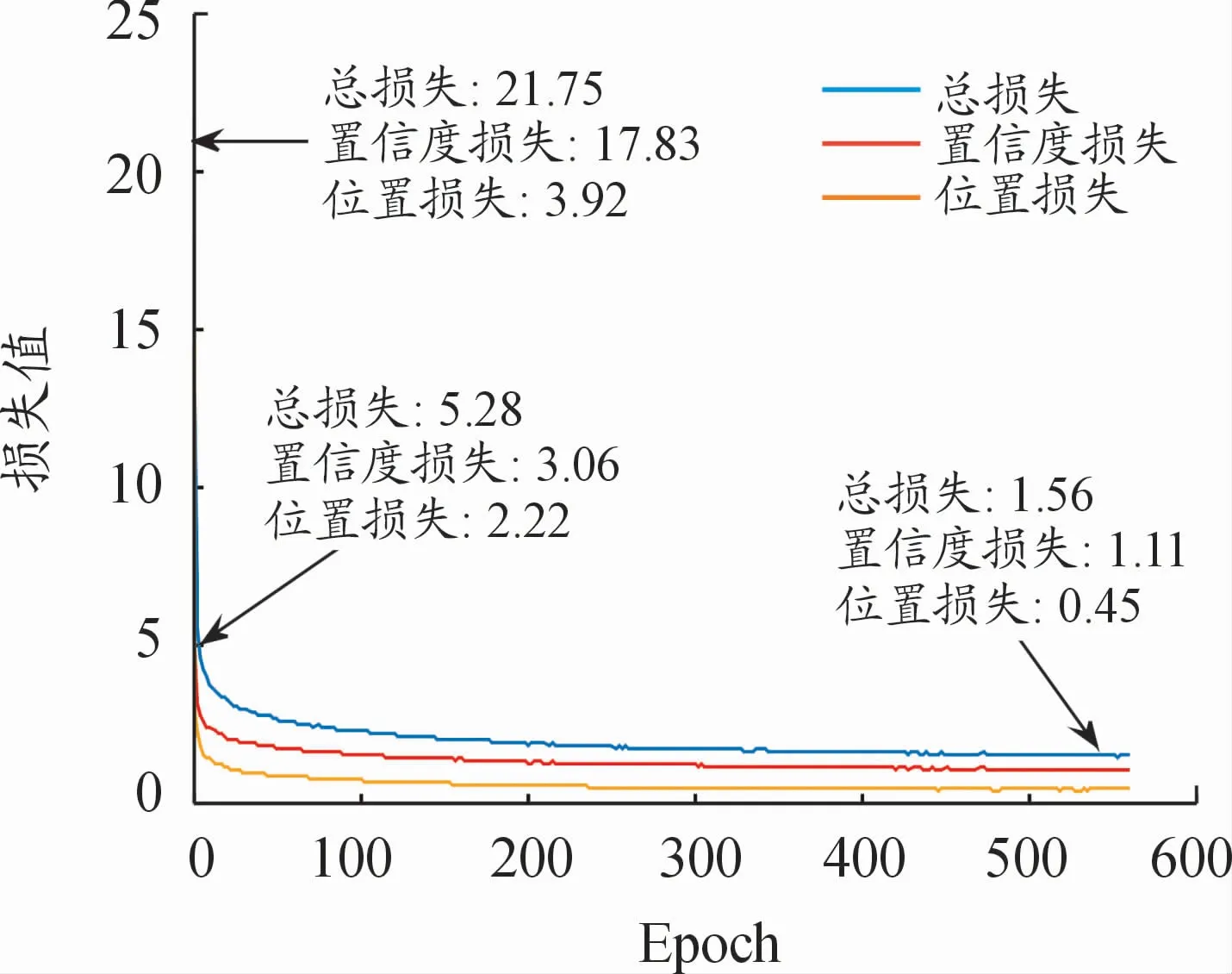
图10 模型2的训练损失曲线
由图分析可知,模型1和模型2的总损失值分别由最初的21.34、21.75下降至1.42、1.56;置信度损失分别由最初的17.46、17.83下降至1.00、1.11;位置损失由最初的3.88、3.92下降至0.42、0.45。因此模型1和模型2的训练过程收敛均较好。
3.4 模型评估
目前,主流的目标检测模型评价指标有交并比(IOU)、精确率(precision)、召回率(recall)、AP(Average Precision)值和mAP(Mean Average Precision)值,其中精确率和召回率的公式如下。
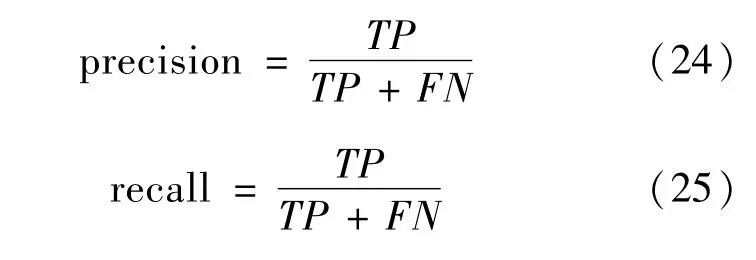
式中:TP为正样本被识别为正样本;FP为负样本被错误识别为正样本;FN为正样本被识别为负样本。
AP值为PR曲线(即以precision和recall分别作为横坐标和纵坐标的二维曲线)下的面积,利用AP值可以对训练的模型在某个目标类别上的检测结果进行评价。mAP值则表示训练的模型对所有目标类别上的检测结果进行评价,即所有类别对应AP值的均值,其表达式如下。

式中,N为目标种类数。
本文采用交并比、召回率、AP值和mAP值对训练得到的2个模型进行全面评价。将RTTS测试集的带雾图片分别在模型1和模型2上测试,得到模型1和模型2的交并比、召回率、AP值及mAP值如表2~4所示。
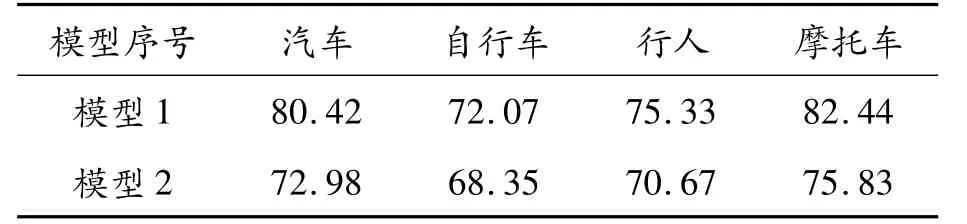
表2 模型1和模型2的交并比 %
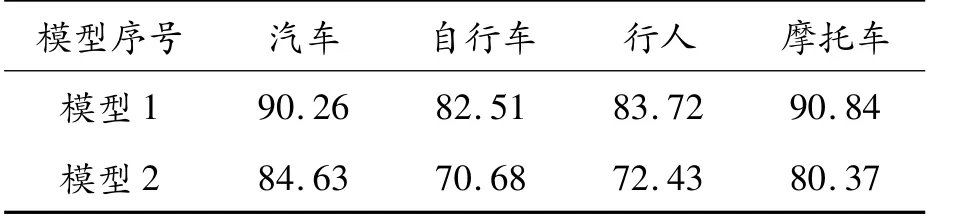
表3 模型1和模型2的召回率 %
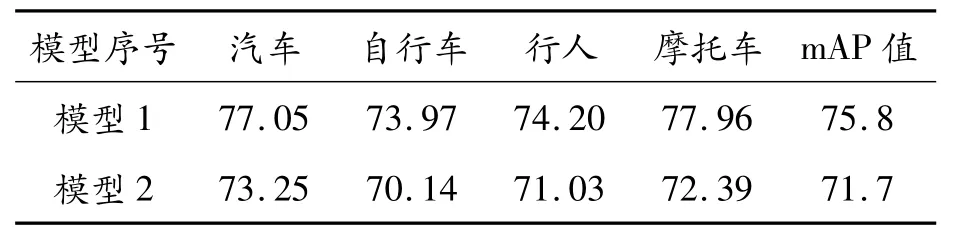
表4 模型1和模型2的AP值及mAP值 %
由表2可知,模型1的交并比高于模型2,表明模型1的目标框和标定框相似度高于模型2,各类目标的交并比分别高7.44%、3.72%、4.66%和6.61%。由表3可知,模型1的召回率高于模型2,各类目标检测的召回率分别高5.63%、11.83%、11.29%和10.47%,即模型1中被正确检测识别的目标高于模型2。由表4可知,模型1的mAP值比模型2高4.1%;在单个目标检测中,模型1中汽车的AP值比模型2高3.8%;自行车的AP值相比模型2高3.83%;行人的AP值相比模型2高3.17%;摩托车的AP值比模型2高5.57%。综上所述,加入去雾处理的模型1对车辆和行人的检测精度比模型2更高。
3.5 检测结果分析
利用数据集RTTS测试集的带雾图片,分别在模型1和模型2上进行测试,选取薄雾、中雾和浓雾3种不同等级的雾气浓度图片进行车辆和行人的检测精度分析,每个雾气浓度等级选取4张作为示例,如图11~13。

图11 薄雾环境下的检测结果

图12 中雾环境下的检测结果

图13 浓雾环境下检测结果
由图11~13知,在薄雾、中雾及浓雾3种不同等级的雾浓度下,模型1对目标漏检及误检的情况明显低于模型2;对车辆和行人的定位精度相比模型2较高且检测到的目标置信度更高。
将本文的雾天车辆和行人检测算法与MSCNN+Faster R-CNN、DehazeNet+Faster R-CNN和DCP+Faster R-CNN等雾天目标检测算法进行比较,得到各类算法的mAP值如表5所示,表中“F”表示Faster R-CNN。
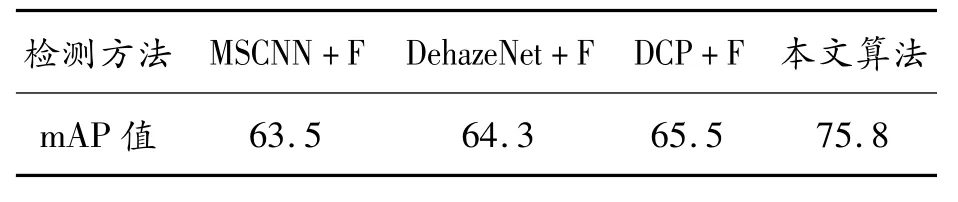
表5 各种雾天检测算法的mAP值 %
从表5中得出,与其他算法相比,本文算法在雾天环境下检测的mAP值最高,比MSCNN+F算法高12.3%;比DehazeNet+F算法高11.5%;比DCP+F算法高10.3%;综上所述,AOD-Net网络与SSD网络相结合有效地提高了训练模型的mAP值,改善了雾天车辆和行人的检测精度;除此之外,由于训练的数据集为真实雾天图片,故本文的模型在真实雾天场景中相比其他算法泛化能力更好。
4 结论
本文将AOD-Net去雾算法和SSD目标检测算法进行结合,针对城市道路下,雾天的车辆和行人进行检测。该方法在真实带雾图片上进行车辆和行人检测的mAP值可达75.8%,相比其他算法,提高了雾天环境下的目标检测精度。当雾天环境下的雾浓度发生变化时,仍然能很好地对车辆和行人进行检测,使得其泛化能力更好。由于本文的数据集图片数量相对Pascal voc、COCO等大型数据集而言较少,学习到的雾天场景下车辆和行人的特征有限,下一步将继续增加数据集的图片数量和不同的雾天场景,从而为未来自动驾驶和智能辅助驾驶感知雾天环境下的车辆和行人奠定环境感知基础。
