基于LNRE模型的硕士研究生毕业论文词汇丰富度研究
2021-06-03李森
李森
(北方工业大学图书馆,北京 100144)
近年来,随着研究生教育的不断深入,硕士教育水平逐渐上升。毕业论文作为衡量在校生学术规范意识的培养、研究方法的掌握与语言表达能力的积累和训练等方面内容的综合手段,为国内外绝大多数培养单位采用。同前两个方面相比,表达能力也许是最容易被忽视的,但实际上其表现并不乐观[1]。学生毕业后,其进一步选择主要包括继续在国内深造、直接工作和出国留学。如将考察对象只集中于词汇的使用,在前两种选择中,学生均会继续使用本民族语言进行产出性语言行为,二者只是在词汇的使用范畴上存在一定差别,却未产生本质性差异[2-3];虽然学生出国后会较少使用本民族语言,但与学业技能发展关系最为紧密的“认知/学业语言能力”可为双语者在不同语言中共享,且具有可迁移性[4],因为本民族语言的提升能在其他语言的使用上得到体现,所以学生在校期间汉语能力的培养对今后的工作与深造均具有积极作用。因此仅通过对毕业论文的用词情况来探究硕士的语言能力、进而衡量在校生的学习积累和对比不同专业间研究生培养效果的研究可以得到理论上的支持,且具有较高的应用价值。在可见的文献中,研究生语言能力的研究基本集中于外语水平的比较,且多数仅通过人工测试或语料库的简单统计[5-6]。这些方法虽能表现部分语言使用者的语言情况,却无法反映研究对象的语言能力,因此还需将这种表现“外推(extrapolation)”至能够代表其语言能力和个人或群体特征的语言总体(population)或某个总体子集,但通过此类认识与研究手段进行的、专门针对某一群体汉语能力的研究尚未被作者发现,因此如能填补这一空白将会有较高的理论与实践价值。
基于研究开展的便利性,本研究采用词作为计量单位,通过词汇丰富度(lexical richness)探究文献作者群体的语言能力。由于传统测量词汇丰富度的各种统计量在语料规模不断增长的情况下不遵守大数定律,所以就无法从此角度估计总体大小[7],需要诉诸于其他方法。立足于人类语言的大量罕见事件(Large Number of Rare Events,LNRE) 性质,Baayen将已有的多种模型引入语言学[8]。后经Evert 与Baroni 的研究认为其中仅有广义逆高斯—泊松(Generalized Inverse Gau-Poisson,GIGP) 模型具有较好的解释与预测能力[9],且Evert 提出的齐普夫曼德尔布罗特(Zipf-Mandelbrot,ZM)模型与有限齐普夫曼德尔布罗特(finite Zipf-Mandelbrot,fZM)模型[10]也具有较好的拟合与外推效果,并基于这3 种模型开发了zipfR 程序包[11-12]。他们所做的工作为该研究的开展提供了方法论支持的同时带来了工具使用上的便利。
1 研究语料简介与模型拟合
为使用定量的方法考察不同研究群体的汉语语言能力,需要收集能够充分代表群体特征的语料,因此在语料库建立阶段应充分考虑文献所代表总体的共性与个性。同时在基于语料获取便利性,笔者收集了北方工业大学2018 届及2019 届经济管理、法律、计算机与机械工程4 个专业的部分硕士研究生的毕业论文作为语料来源。由于该研究仅针对汉语,所以对论文语料进行分词(分词采用R 语言中jiebaR 程序包,版本号0.11,用户词典采用搜狗输入法中与研究专业相关的词库。)后去掉了标点与非汉字符号,按不同专业组成语料库,每个语料库词例(token)数约84.3 万左右,词型(type)数排序为法律(26 838)、经管(24 108)、机械(22 438)和计算机(18 069)。
通过zipfR (计算使用的程序包版本号为0.6-66,拟合效果按默认设置最好,因此该研究均采用默认参数。)可以方便地拟合上述3 种模型,所得χ2与P 值如表1 所示。其中多元卡方检验的原假设为实际值与模型期望值间无显著性差异,显著性水平为0.05,若P 值大于此值,则接受原假设,表示该模型可以较好地描述总体,且卡方值χ2越小,描述效果越好(见表1)。
结果中GIGP 表现最好,即使最小的P 值(0.049)也非常接近0.05,且同一语料的结果中该模型的χ2最小;fZM 次之,但P 值除计算机类语料外均小于0.05,且χ2大于GIGP;ZM 的表现最差。可见除GIGP 外,ZM 与fZM 的表现并不理想。
2 拟合结果分析
产生两种模型拟合不佳的两个可能的因素分别为:模型不遵守LNRE 的球罐模型(urn model)假设和该假设同语言事实不符。
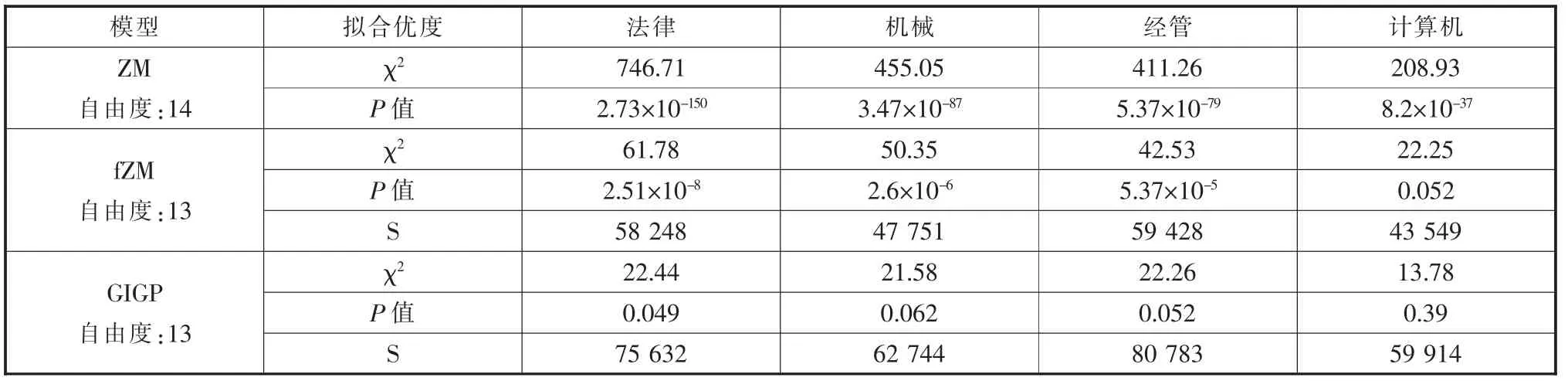
表1 模型的拟合优度与S 近似值
为证实第一种情况,Baayen 曾提出过基于大规模语料数据,对比语料二项式内插值(binomial interpolation)与模型内插值的方法。每种语料结果均表现相似,这里仅以经管为例,图1 绘制了两种内插值的频谱(frequency spectrum)数据与词汇增长曲线(Vocabulary Growth Curves,VGC)。前者的频谱数,后者包括全体词汇V 增长曲线(较粗部分)与独频词(hapax legomena)V1 增长曲线(较细部分)两部分。作者很难从视觉上分辨出二者间差异,之后设置原假设为每种语料中的两种内插值均不存在显著性差异,通过柯尔莫可洛夫-斯米洛夫检验(Kolmogorov—Smirnov test)得出的P 值均接近1,证实了视觉判断的正确性,说明每种模型都较好地遵守了球罐假设。
第二种情况的检验需将模型的内插值与实际数据予以对比,图1 同样分别绘制了频谱数据与VGC的实际值。相较实际值,模型的期望值确实存在一定程度的偏差。具体表现为在频谱图中,3 种模型会产生明显的高估或低估的现象,其中在m=1 时ZM 的高估最为显著,而fZM 与GIGP 则表现为低估;当m=2 或3 时,情况正好相反,但实际偏差远小于在m=1 时ZM 高估所带来的差值; 随着m 值的逐渐增大,偏差逐渐减小,但这种现象仍然存在。在VGC中,模型高估现象较为明显,二项式内插值同三种模型内插值的中前段基本重合,但ZM 在语料大小N的整个增长过程中均保持对V 和V1 的高估,而其他曲线则在语料邻近结束时基本保持了同实际值的一致。通过以上分析可以认为球罐模型在描述语言事实方面确实需要进一步改善,但fZM 与GIGP 可以较为准确地反映实际词汇的增长趋势,且与频谱变化差别较小,因此可以作为语言总体大小大致或趋势估计的主要依据。ZM 拟合结果较差的原因应该源自其总体无限大的模型假设,这是同语言事实不符的,因此不予采用。
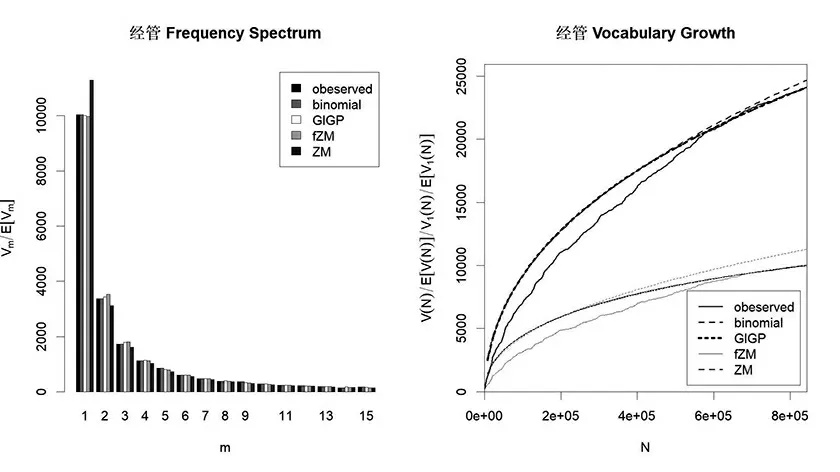
图1 经管语料的频谱图与VGC
表1 中同样展示了fZM 与GIGP 模型预测的不同语料总体近似值S。由于Baayen 认为内插阶段的高估会引起外推阶段的低估,且这一看法在其他文献中均得到证实[9-13],所以该值也仅为总体实际规模的下限。因此可以通过对比S 值同VGC 中V 与V1来评价各语言群体的词汇量下限和词汇丰富度。由此可知各语言群体在论文撰写过程中,经管类毕业生的汉语词汇量下限最高,其次为法律、机械和计算机,其中非工科毕业生同工科生之间的差距较大,但工科专业间的差距较小。
fZM 与GIGP 在内插阶段几乎重合,因此图2 仅提取了图1 中各类V 与V1 的VGC 实际值与fZM内插值,二者基本保持增长趋势的一致。结合频谱图中的低频数据实际值可以认为在现有语料中,法律专业学生的汉语词汇丰富度最高,之后依次为经管、机械与计算机。在词汇使用上,现有模型较为准确地预测了工科毕业生低于非工科生的情况,但最终预测的汉语总体词汇量却不完全与语料中词汇丰富情况吻合,如VGC 实际值与内插值均存在法律类高于经济类的情况,但表1 中S 值却正好相反,因此可以预期在未收集到的语料中后者的词汇增长率更高;两类工科论文的VGC 中V 的实际值或内插值之间差距大于模型预测的S 差值,因此在未收集的语料中同样存在词汇增长率有较大变化的可能性。

图2 V 与V1 的VGC 实际值与fZM 内插值
虽然现有模型仍有可改善空间,但仍可得出结论:通过模型预测和语料事实,非工科研究生的词汇量与词汇丰富程度确实高于工科生,这体现了不同专业硕士研究生群体的语言能力。论文写作是论文撰写者在着重使用产出性学术词汇开展的语言行为,不同专业领域的学术词汇量固然存在差异,但其并不能作为实际语言能力高低的判别标准[14]。产生的可能源自不同专业学生在撰写论文过程中,同其他领域结合时对非该专业词汇的引入程度差异。虽词汇的丰富性在研究生培养与论文撰写上常被忽视,但相关培养单位或导师如能在硕士生培养、选题与论文撰写方面多关注该专业同其他相关学科与领域的结合和应用,为学生带来的好处恐怕不仅是语言能力的提升。
3 不足与展望
该研究虽完成了对语料的拟合与内插分析,但以上结论仅基于fZM 与GIGP 模型拟合结果展开,内插曲线的高估现象使得可信度仍有可以讨论的余地,且不同专业学生的词汇量同VGC 之间也存在部分需进一步解释之处。为解决这些问题需要通过外推等技术开展进一步研究,但由于外推过程可能存在低估现象,所以需要将探索高估的成因放在首位。对模型的评价也仅局限于拟合优度,存在较大过拟合风险,缺乏更为丰富和全面的评价手段与改善拟合结果的解决方案。所用语料类型较为单一,缺乏通过多类型语料考察模型的适用性、开展非同质性研究的过程。另外Baayen 最初的分析基本只集中于部分欧洲语言,该论文限于篇幅所限并未展示其结论在汉语中的适用性。这些都是该研究的不足之处。在后续研究中,笔者认为应将精力主要集中在模型外推与模型内插阶段高估原因探索两个方面。针对前者除了采用更为适合的评价手段外,应充分利用交叉验证之类的技术,通过训练语料与测试语料选择适当的模型,避免过拟合风险;对于后者,应专门针对句法与词汇层面分别展开分析,更应将关注点放在语料库建立或所用模型的改善上; 另外展示并分析传统测量词汇丰富度方法在汉语中的情况也应考虑在内。
4 结语
该文首先介绍了该研究的意义与所用语料的详细情况,之后使用3 种LNRE 模型对所用语料进行了拟合。通过对拟合结果的分析得出结论:GIGP 和fZM 模型优于ZM 模型,可以认为经管和法律专业学生在论文撰写阶段所用的汉语词汇量与词汇丰富度最高,机械与计算机专业较低,并在分析原因后给出了建议。最后该文分析了研究的不足之处与后续方向,为下一步的研究指明了努力方向。
