港口拖轮调度模糊规划优化模型及算法
2021-05-31李伯棠王智利周海英任阳军
李伯棠,王智利,周海英,任阳军
(1.广州航海学院 港口与航运管理学院,广东 广州 510725;2.上海海事大学 经济管理学院,上海 201306)
0 引言
近年来,随着船舶的大型化发展,大型船舶进出港口靠离码头、在港内不同码头和泊位之间货物装卸、系离浮筒和临时抛锚等辅助作业都需要拖轮协助完成。由于不同船舶(如散货船、集装箱船和邮轮等)的操纵性能及其尺寸存在差异,船舶靠离的区域、所需拖轮数量和作业时间均不相同。同时,随着港口吞吐量的上升,进出港口的船舶数量不断增加,港口会建设多个拖轮停泊基地来实施拖轮作业管理,拖轮往往被调派到不同的基地开展辅助作业,使得拖轮调度成为一个更加复杂的问题。传统的拖轮调度主要依靠调度人员的经验,随着辅助作业量和停泊基地数量的增加,该方法不再适用。因此,寻找科学高效的拖轮调度计划成为解决问题的关键。
本文研究拖轮的分配问题,其在某种程度上与经典分配问题有关[1]。Kuhn等[2]为多种变形的分配问题提供了新的解决方法;Zhang等[3]提出一种基于阈值的最优分配策略,将批量到达的作业分配给异构服务器,并给出了计算阈值的显式公式;Pisinger[4]将载货驳船分配给有能力的拖轮,类似于多重背包问题,该问题可以归结为将n项任务分配给m个拖轮的背包问题;Laalaoui等[5]考虑一台机器在某些时期无法使用的准时作业调度问题,建立了一个基于二进制的多背包问题模型;Dimitrov等[6]研究了单个仓库分配卡车到各个项目的决策问题;Kataoka等[7]设计了一种多项式时间算法求解多背包分配模型。在海上运输研究领域,学者们对船舶的泊位分配的优化问题进行了广泛研究[8-9],但是很少有针对船舶拖轮调度优化的研究。
目前,国内外学者对拖轮调度优化的研究不多,鲜有针对不确定情况的拖轮调度优化进行研究,而且对拖轮调度的求解大多都采用启发式算法。刘志雄等[10-12]采用基于进化策略的混合算法对所建立的拖轮调度模型进行求解;董良才等[13]采用基于动态遗传算子的改进粒子群优化算法求解以“拖轮马力溢出”及船舶等待拖轮的时间最小为目标函数的拖轮调度问题;王巍等[14]针对多停泊基地和不同作业模式下的拖轮调度,以最大完工时间和总作业油耗最小化为目标,建立了拖轮调度多目标优化模型,并提出一种基于轮盘赌概率分配的编码和解码求解算法;徐奇等[15]构建了以拖轮总作业时间最小化为目标函数、考虑多停泊基地条件下的一体化调度优化模型,并设计了混合模拟退火算法进行求解;徐奇等[16]建立了对多停泊基地不同作业模式下考虑靠泊与停泊两阶段的拖轮调度优化模型,并设计了启发式规则与模拟退火相结合的混合算法求解模型;郑红星等[17]基于复式航道的特点,给出基于Arena的仿真模型,并嵌入了以拖轮耗油总成本最小为目标的作业调度优化模型,最后设计了嵌入启发式规则的遗传算法(Genetic Algorithm, GA)用于模型求解;Zhen等[18]研究了一个位于河口的港口拖船调度问题,建立了一种混合整数规划模型,并提出一种基于分支定价法的求解方法。总体上,上述文献同样考虑多停泊基地的拖轮调度问题,但其所建立的可求解的线性规划模型均未考虑拖轮可停靠任意停泊基地的情况。在现实的码头作业中,拖轮完成一项辅助作业后必须停靠在任意一个合理的停泊基地,在此基础上,本文针对多停泊基地对多拖轮和不确定的情况建立一个混合整数线性规划模型。
综上,本文根据传统调度模型,提出多停泊基地的港口拖轮调度优化模型,在此基础上考虑不确定性,运用模糊规划理论,建立相应的模糊港口拖轮调度模型,同时设计一种基于调度计划编码的鲸鱼—遗传混合算法(Whale Optimization-Genetic hybrid Algorithms based on Scheduling Plan coding, SPWOGA)进行求解。
1 问题描述
首先明确5个定义:
(1)任务 在拖轮开始作业前,港口通过顾客申请接收船舶的作业需求来安排当天的作业计划。因此,可以预先获知单个船舶作业的服务内容、所需拖轮数量和功率、开始和结束时间以及开始和结束地点,本文将这4个方面的信息定义为任务。
(2)拖轮作业 拖轮完成一项任务后行驶至某个基地停靠并等待下一项任务。
(3)预处理 为了避免港口拥堵,根据任务和拖轮作业的定义,首先按照开始时间对任务按排序,如果一项任务的结束时间和下一项任务的开始时间接近,则可将前后两项任务合并为一项新任务,其开始时间和地点为前项任务的开始时间和地点,结束时间和地点为后项任务的结束时间和地点,作业时间为前后两项任务作业时间与前后两项任务衔接时间之和。如果前后两项任务需要的拖轮数量不同,例如前项需要2艘拖轮,后项需要3艘拖轮,则将后项任务分解为一项任务需要2艘拖轮、另一项需要1艘拖轮,并将需要2艘拖轮的任务和前项任务合并,将需要1艘拖轮的任务作为新增的任务,对于前项所需拖轮数多于后项任务的情况同理。另外,将两项最大功率作为新任务的拖轮功率。
(4)初始状态 指前一天任务完成后,拖轮所停靠的基地。
(5)调度计划 指结合各拖轮的初始状态,根据当天的任务集合为每项任务安排拖轮服务。
本文所研究的多停泊基地的港口拖轮调度问题是多停泊基地、多拖轮和多任务之间的调度分配问题,拖轮可停靠在任意一个停泊基地,其须从某个基地出发,完成一项任务后回到某个基地后再等待后续任务(不一定是紧接的任务)。如图1所示,弯曲的港口岸线上有4个停泊基地,每个基地上有一定数量的拖轮(初始状态),应用预处理将任务按时间顺序排序,任务通过单向进港航道依次进入港口,任务的形状大小表示任务所需拖轮的数量,例如任务1需要两个拖轮,调度员分别从停在基地3和4的拖轮各抽调一艘拖轮完成任务1,作业完成后从基地3出发的拖轮前往基地2,从基地4出发的拖轮前往基地1等待后续任务。
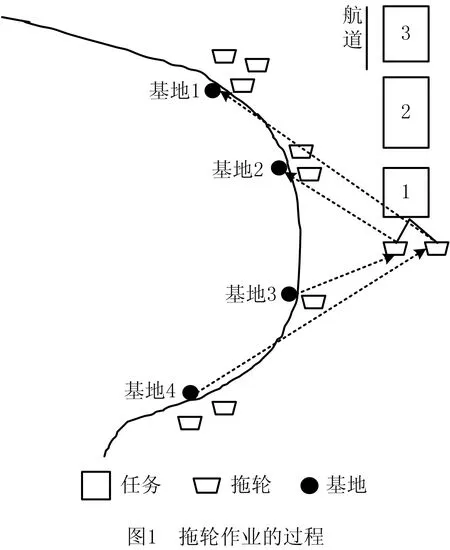
拖轮服务按拖轮作业艘次计费,任务确定后收费总额也确定,调度计划的优劣取决于作业成本的高低,作业成本以燃油成本为主。因此,本文目标是最小化燃油成本,其由从基地到任务开始地点和从任务结束地点到基地的行驶燃油成本(按距离计算),以及完成任务的作业燃油成本(按时间计算)组成。
在实际生产作业中,受不确定因素的干扰,调度人员不能准确掌握港口环境和作业变化。因此,本文设定某些参数具有不确定性,参数的变化用对称的三角模糊数表示。
基于以上描述,本文针对不确定的情况,以行驶燃油成本和作业燃油成本之和的总成本最小化为目标,利用模糊规划方法建立拖轮调度模糊规划模型,研究拖轮分配计划问题。
2 模型建立
2.1 模型假设与符号说明
本文提出以下假设条件:①调度计划期为1天;②港口的进出航道为单行,且船舶不能并行进入;③拖轮在当天所有任务开始前都停靠于基地;④不考虑基地外泊位和内泊位的区别;⑤拖轮备车的时间短,其靠离基地泊位的时间忽略不计;⑥不同拖轮有各自固定的速度(最佳经济航速);⑦每个基地可停泊的拖轮数量不限。
定义如下符号:
(1)集合J,J′为任务的集合,j∈J={1,2,…,NJ},j′∈J′={0,1,2,…,NJ};0表示当天任务开始前的0时刻任务(即初始状态);I为拖轮的集合,i∈I={1,2,…,NI};K为基地的集合,k∈K={1,2,…,NK}。
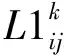
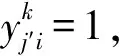
2.2 目标函数与约束条件
本文研究的港口拖轮调度问题含有模糊参数,因此建立一种基于可信性的模糊规划模型[19-20],将期望值方法(用于目标函数)和机会约束规划方法(用于约束条件)结合进行建模,得到基于可信性的模糊机会约束规划模型M1:
(1)
(2)
(3)
Pi≥Mjxij,∀i∈I,j∈J;
(4)
(5)
(6)
(7)
(8)
(9)
(10)
(11)
其中:目标函数式(1)的第1部分表示拖轮从基地出发到达任务开始地点所用的燃油成本,第2部分表示拖轮从任务开始地点到结束地点作业所用的燃油成本,第3部分表示拖轮从任务结束地点到基地所用的燃油成本;式(2)表示满足任务所需拖轮数需求的可信性不能小于α∈[0,1];式(3)表示拖轮当天初始停泊基地的位置;式(4)表示执行任务的拖轮功率必须大于任务所需功率;式(5)表示执行第1个任务的拖轮必须在第1个任务开始前到达任务开始地点的可信性不能小于α∈[0,1];式(6)表示拖轮必须执行完上一个任务回到某一基地,再从该基地出发,在下一个任务开始前到达任务开始地点的可信性不能小于α∈[0,1];式(7)表示拖轮必须执行完上一个任务回到某一基地才能执行下一个任务;式(8)表示某一个基地的拖轮总量不能少于执行任务的拖轮总量;式(9)表示一个拖轮只能停泊在一个基地;式(10)表示任意拖轮如果不执行当前任务,则继承上一个任务所停靠的基地位置;式(11)表示变量为0-1变量。
由于模型中存在两类变量相乘而造成的非线性部分,下面对非线性部分进行线性化处理:
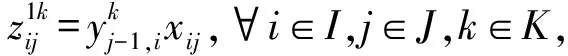
(12)
(13)
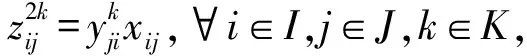
(14)
(15)
则式(1)、式(5)和式(6)分别变为式(16)、式(17)和式(18):
(16)
(17)
(18)
3 模型的处理
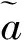
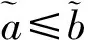
(19)
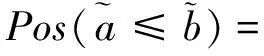
模糊排序公式(19)可以根据可信度度量重新表述为
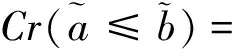
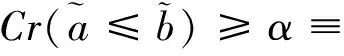
ac+(2α-1)wa≤bc+(1-2α)wb,∀α∈[0,1]。
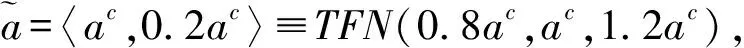
(0.8+0.4α)ac≤(1.2-0.4α)bc,
∀α∈[0,1]。
(20)
由式(20)和梯形模糊数的期望值,可以将式(2)、式(16)和式(17)变为式(21)~式(24):
(21)
(22)
(23)
∀i∈I,j∈{2,3,…,NJ}。
(24)
综上所述,本文建立以式(22)为目标函数,以式(3)、式(4)、式(7)~式(15)、式(21)、式(23)和式(24)为约束条件的港口拖轮调度模糊规划模型M2。
4 解决方法
模型M2在求解小规模问题时可采用成熟的商业求解器(如CPLEX,Xpress, CAMS)求解,然而对于大规模问题,现存求解器的求解效率变低。GA是一种通过模拟自然进化过程搜索最优解的方法,但其存在易早熟和局部收敛等问题[22-23]。鲸鱼优化算法(Whale Optimization Algorithm, WOA)具有操作简单、调整参数少、全局部搜索能力强等特点[24-25],已被成功应用于工业设计[26]、最优控制[27]、流水作业调度问题[28]等领域,但其局部搜索能力较差。本文利用WOA的全局优化优势和GA的局部收敛特点,提出SPWOGA对模型进行求解,算法流程如图2所示。
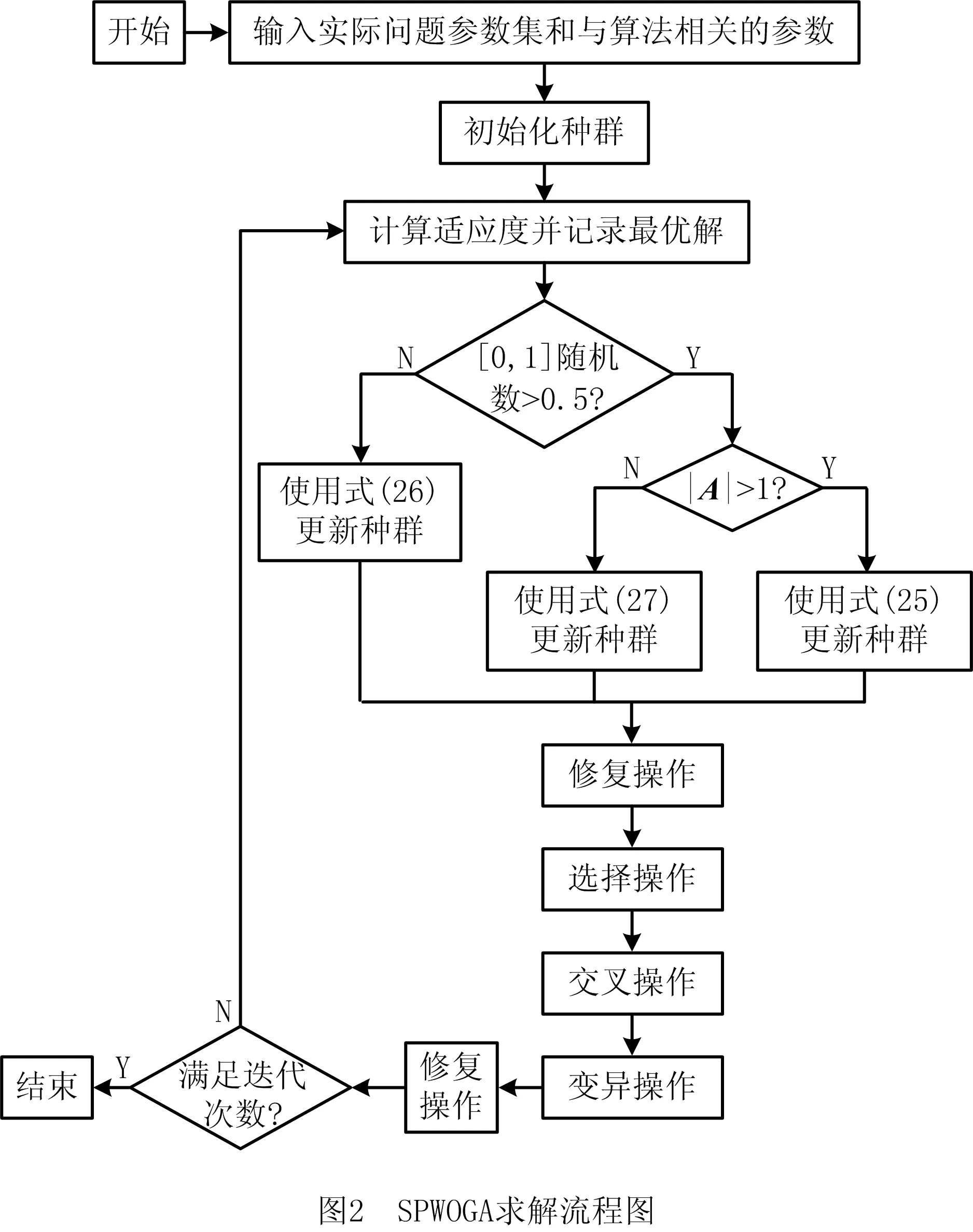
4.1 鲸鱼优化算法
已有文献指出,WOA是一种模仿座头鲸泡泡网觅食行为的随机群体智能算法[24-25],其流程用数学描述如下:
(1)包围猎物
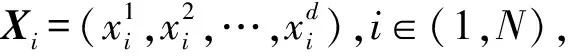
X(t+1)=X*(t)-A·|C·X*(t)-X(t)|。
(25)
式中:t为当前迭代次数;X*为截止到当前最优解的位置向量;X为当前解的位置向量;A=2a·r1-a和C=2·r2,r1和r2为[0,1]之间的随机向量;a=2-2t/T,T为最大迭代次数。
(2)螺旋气泡网攻击
鲸以螺旋运动不断接近猎物,通过式(26)计算当前解X和截止当前最优解X*之间的距离来模拟螺旋运动的过程。
X(t+1)=D′·ebl·cos(2πl)+X*(t)。
(26)
式中:D′=|X*(t)-X(t)|为鲸鱼X和猎物的距离;b为螺旋形状定义的常量;l为取值在[-1,1]间的随机数。
(3)随机搜寻猎物
鲸鱼除了用泡泡网捕食,还采用随机选择的方法更新位置。当|A|<1时,进行(2)的收缩包围和螺旋更新,|A|≥1时,执行等式
X(t+1)=Xrand(t)-A·|C·Xrand(t)-X(t)|。
(27)
式中Xrand为从当前种群中随机选取的鲸鱼位置向量。
4.2 鲸鱼优化算法操作
如图2所示,将当前最优解作为猎物的位置,每条鲸鱼(个体)向其靠近,首先产生[0,1]范围内的随机数m,若m≤0.5,则按式(26)更新;否则,判断是否|A|>1,是则按式(25)更新位置,否则按照式(27)更新位置。该操作只用于变更所有任务栏部分拖轮的位置,而且保持任务所需的拖轮总量不变。
4.3 个体编码结构
本文的个体编码采用港口拖轮调度计划表表示,即在满足任务所需功率和能否按时到达任务所要求的作业起点两个条件下,安排某一拖轮从哪个基地出发完成了第几个任务再回到哪个基地,不执行任务的拖轮的基地位置不发生变化,具体示例如表1所示。表1为一个可行的港口拖轮调度计划,假设有8个可用拖轮、3个基地和5个任务,表中:任务右边括号里的数字表示当前任务所需的拖轮数;第1行表示拖轮1的调度计划,即拖轮1从初始基地1出发完成任务1后回到基地1,然后不执行任务2和任务3(任务2和任务3的任务栏为0)留在基地1,接着从基地1出发完成任务4后回到基地3,最后不执行任务5并留在基地3,拖轮2~8的调度计划以此类推。
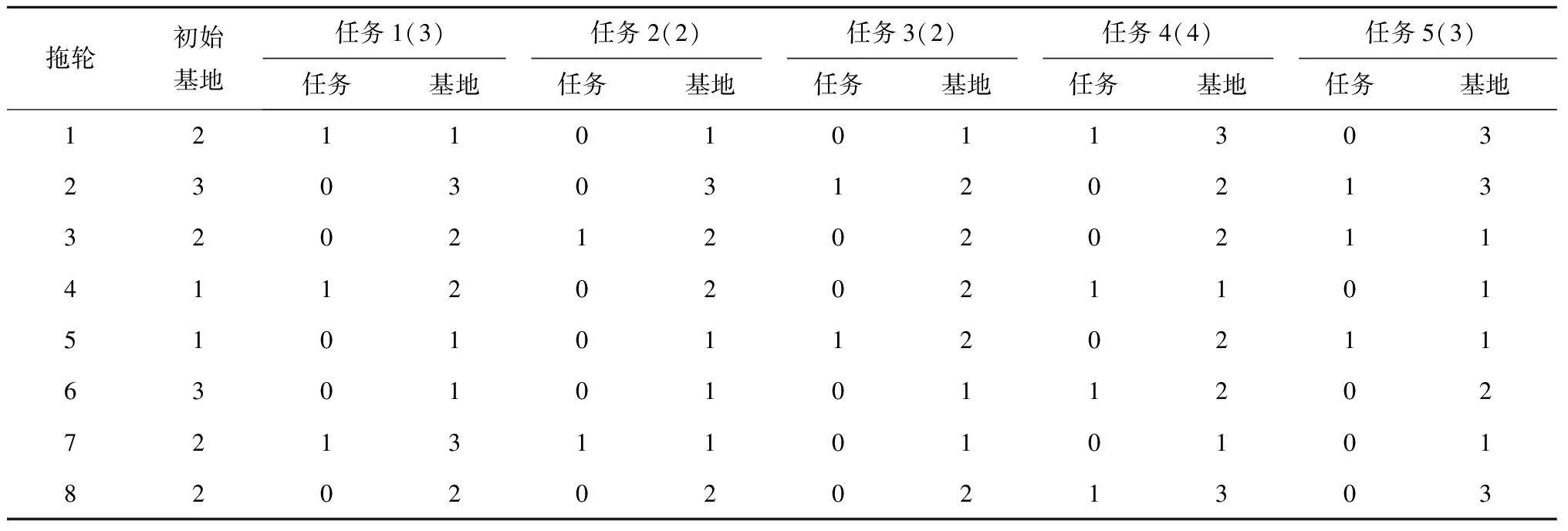
表1 一个可行的港口拖轮调度计划
4.4 适应度与选择操作
适应度为目标函数值的倒数,即适应度=1/个体目标函数值。选择操作采用最优保存策略和轮盘选择法相结合的方法。
4.5 交叉操作
采用单点交叉的方法确定交叉操作的父代,随机将父代个体群两两分组,每组重复以下过程(交叉操作的伪代码):
输入:拖轮总数M;任务总数N;父代个体P1(1:M,1:N),P2(1:M,1:N)。
输出:子代个体G1(1:M,1:N),G2(1:M,1:N)。
步骤1 在[1,N-1]随机选择一个整数z。
步骤2 以任务z作为分界线,交换任务z后面的部分,即:
G1(1:M,1:z)=P1(1:M,1:z),G1(z+1:N)=P2(1:M,z+1:N);
G2(1:M,1:z)=P2(1:M,1:z),G2(z+1:N)=P1(1:M,z+1:N)。
步骤3 合理地调整交换后两个个体的调度计划。
采用表1作为示例,具体操作如下:
步骤1确定两个不同的个体,并在[1,4]的整数中随机选择(例如选择数字2)。交换前的个体如表2和表3所示。

表2 交换前的个体1
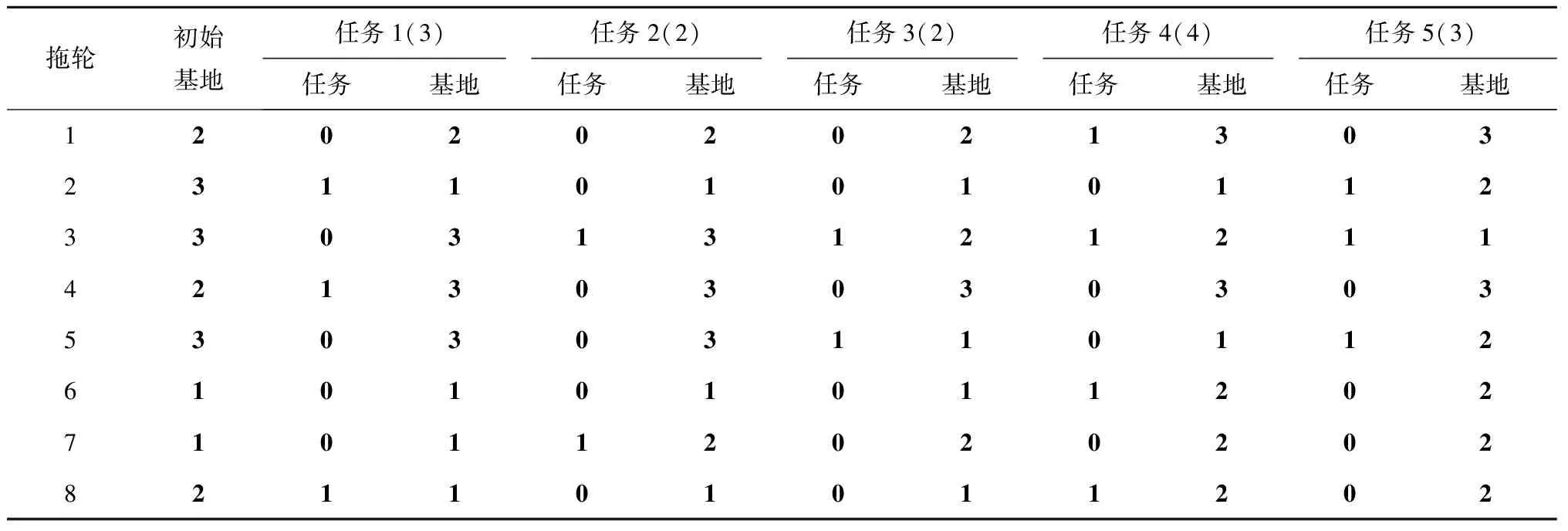
表3 交换前的个体2
步骤2以任务2为分界线,交换任务2后面的部分,并合理地调整交换后两个个体的调度计划,如表4和表5所示。
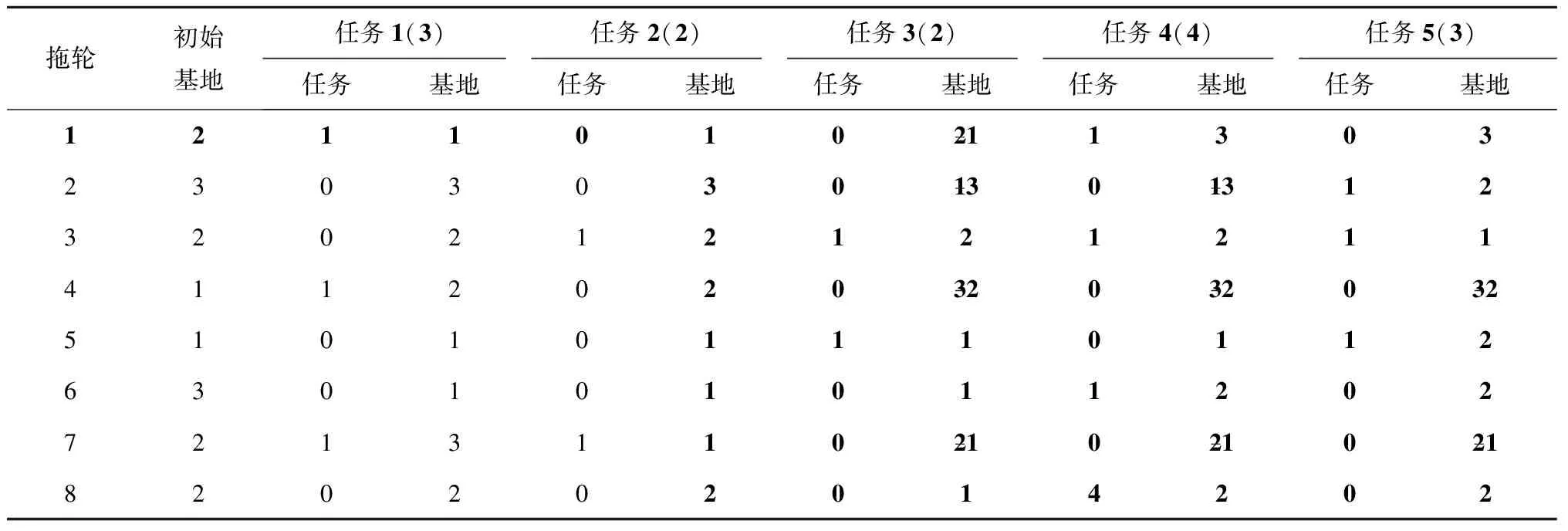
表4 交换后的个体1
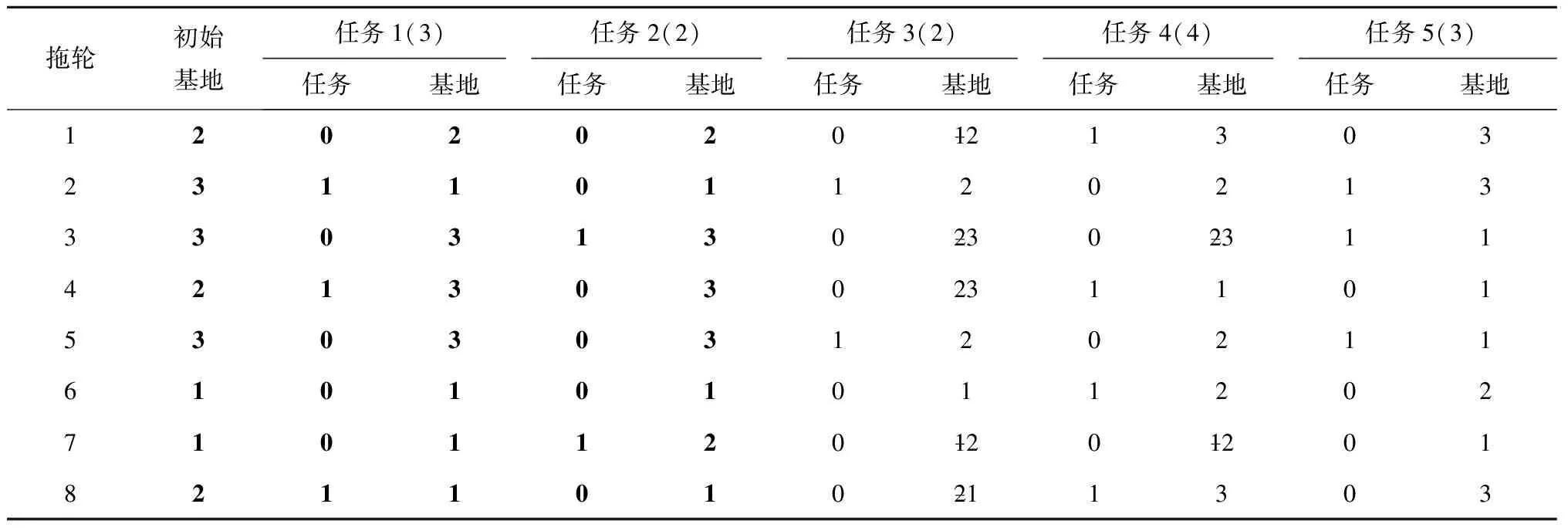
表5 交换后的个体2
4.6 变异操作
按照50%的概率采用交换变异或变化变异,具体操作如下(以表1的可行计划为例):
(1)交换变异 对任务1~任务5取一列中的两行数字进行交换,例如交换任务3的第2行和第6行,并合理地调整交换后拖轮2和拖轮6的调度计划,经过检查,拖轮6的调度计划合理,拖轮2任务3和任务4的基地需要更改为3,如表6所示。
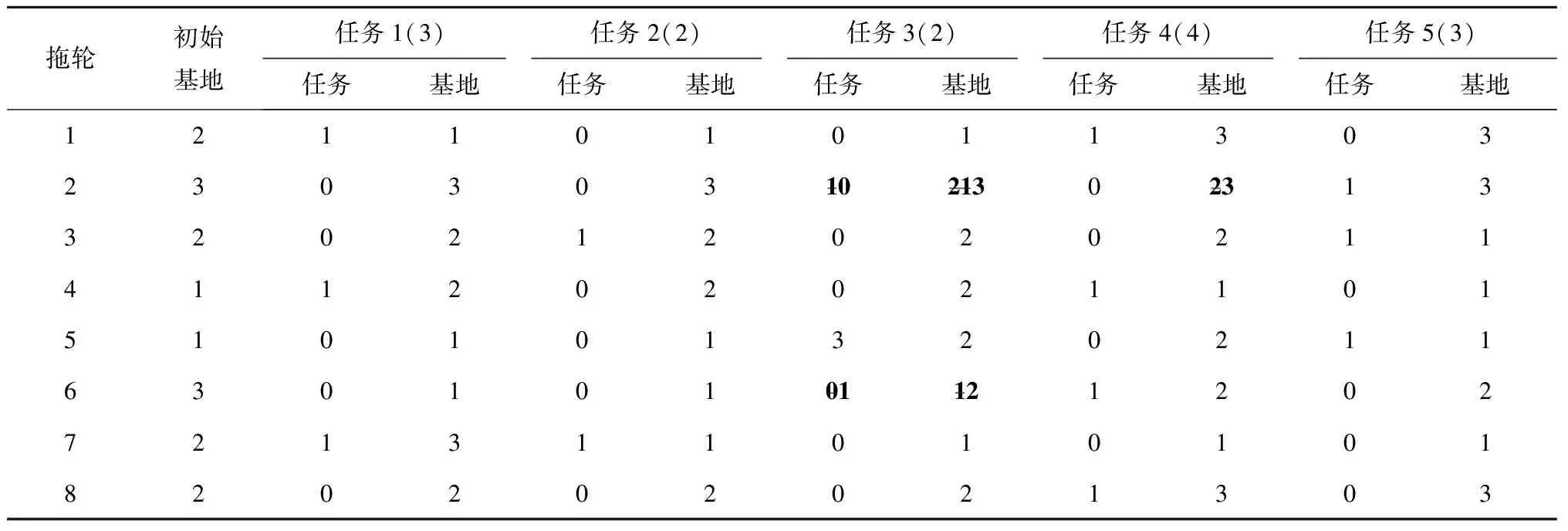
表6 交换变异操作后的个体
(2)变化变异 对于任务1~任务5取一列中的基地数字进行改变,例如将任务2中拖轮3的基地更改为3,并合理地调整拖轮3的调度计划,经过检查,拖轮3的任务3和任务4的基地需要更改为3,如表7所示。
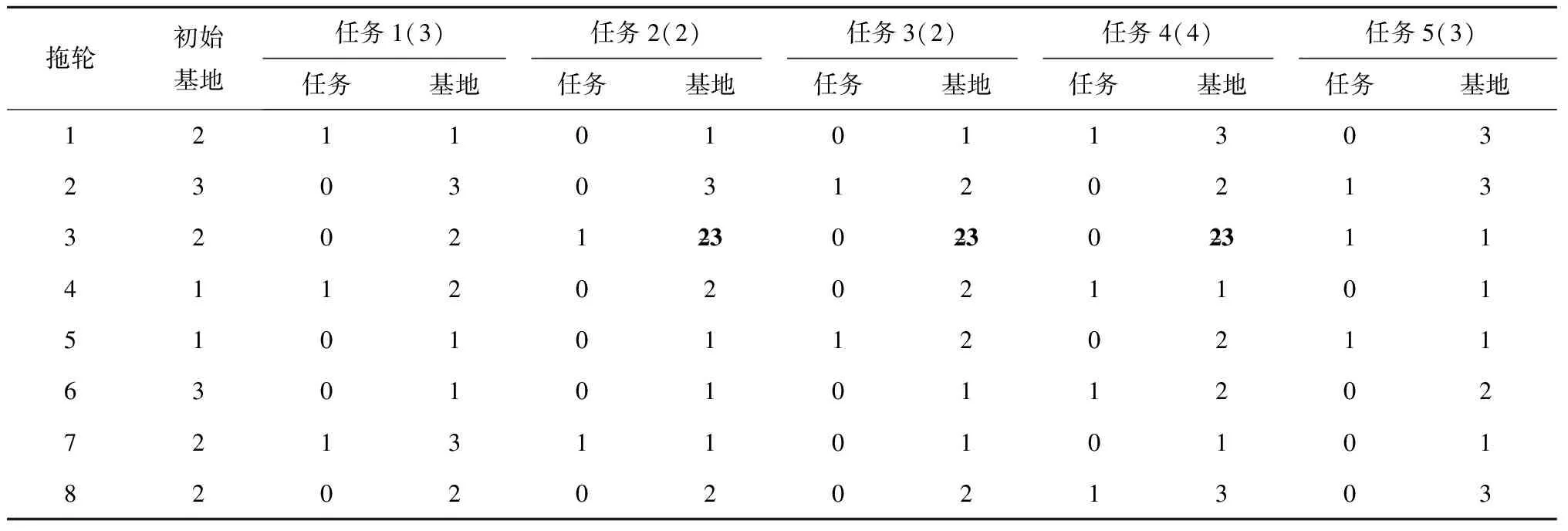
表7 变化变异操作后的个体
4.7 修复操作
交叉和变异操作后的个体可能会打破解的可行性,即不符合拖轮按时到达任务所要求的作业起点,此时需要对个体编码进行可行性修复,修复操作的伪代码如下:
输入:
M:拖轮的总数
P1,P2:父代个体
G:子代个体
输出:
R:子代可行个体
步骤1 For i=1:M。
步骤2 If当前任务结束时间+当前任务地点回到基地的时间+从该基地到下一任务所用时间>下一任务开始时间。
步骤3 then用P1或P2当前拖轮对应任务所停靠的基地编号在G相应位置进行替换。
End If
步骤4 合理地调整拖轮i的整个调度计划。
End For
步骤5 R=G。
例如对交叉后的个体2进行可行性检查,检查到拖轮3执行完任务2后回到基地3,而且从基地3到任务5的起点超过任务5的开始时间,此时需要更改完成任务2后到达的基地,参考交叉操作前的个体2,需要将任务的基地3改为2,同时对其合理性进行调整,即将任务3和任务4的基地改为2,如表8所示。
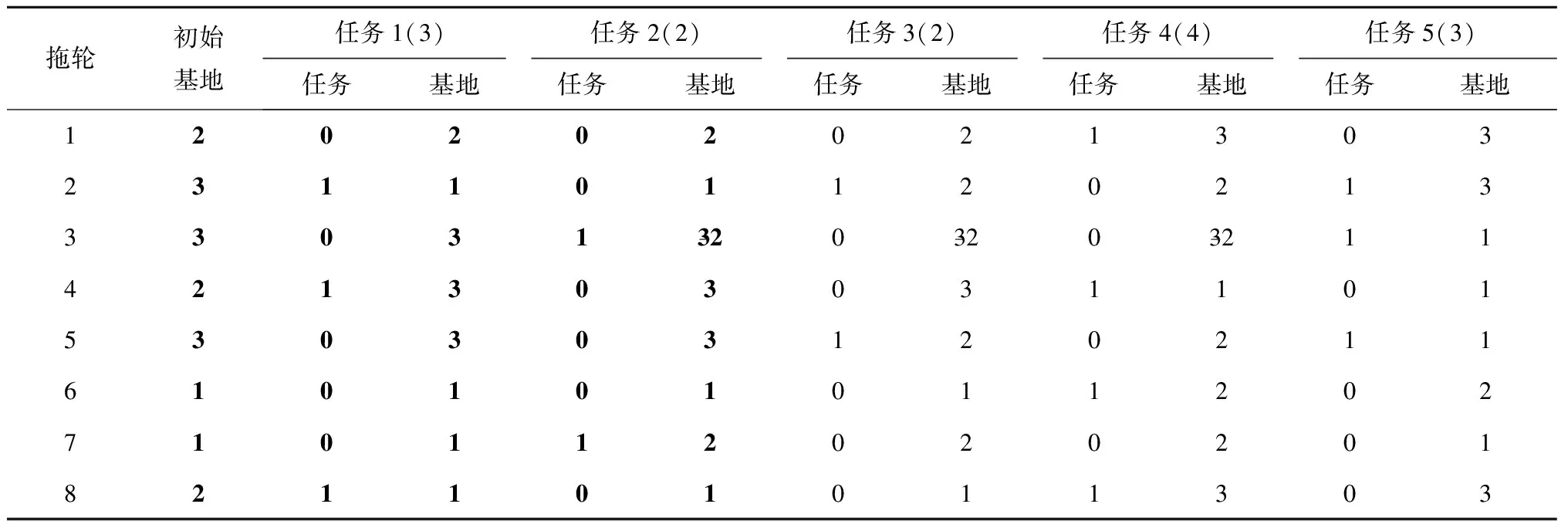
表8 修复操作后的个体
5 算例分析
为了评价SPWOGA在港口拖轮调度问题中的性能,将其与文化基因算法(Memetic Algorithm,MA)进行比较。与本文所提SPWOGA的特点类似,MA结合基于群体的搜索方法和邻域知识[29-30],其个体编码、适应度、选择操作、交叉操作和修复操作与本文一样,其中邻域搜索的操作方法采用动态邻域搜索,具体操作如下:
邻域搜索:75%的概率进行下面的步骤
步骤1 For i=1 to(10+g/8)
步骤2 If i<4 then运用本文变异操作中的交换方法
步骤3 Else运用本文变异操作中的变化方法
End If
步骤4 If所得邻域文化基因的适应度值比当前文化基因的适应度值好then所得邻域文化基因替换当前文化基因
步骤5 Else以(0.05×w)的概率将当前文化基因替换为所得邻域文化基因
End If
End For
其中:g为当前迭代的次数;w=(n-g)/(3×n),n为总迭代数。
另外,M2模型在CPLEX12.8上编码和运行,将SPWOGA与求解器所得结果进行对比。SPWOGA和MA算法均采用软件MATLAB 7.0编写代码,软件MATLAB 7.0和CPLEX的运行环境为Intel(R)Core(TM)i7 2.70 GHz处理器、4 GB内存、Window10(64 bit)操作系统的手提电脑。本文根据表9和表10随机生成12个规模不同的算例。
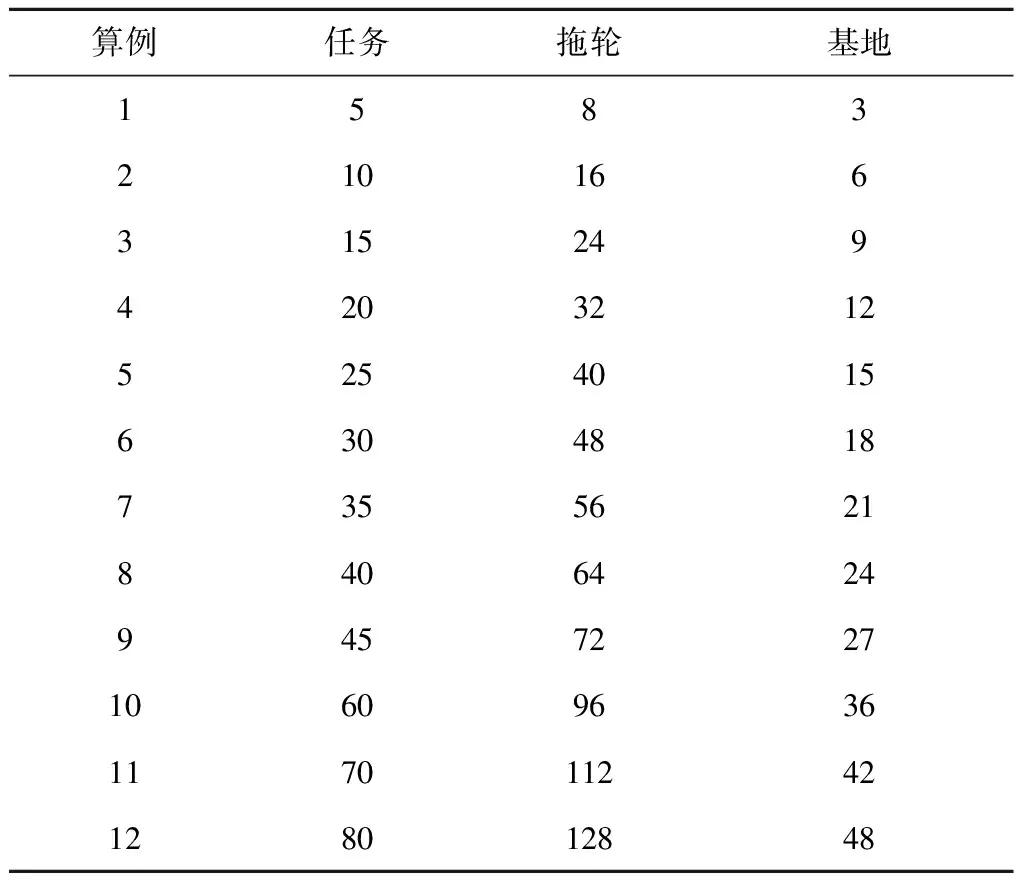
表9 算例的规模
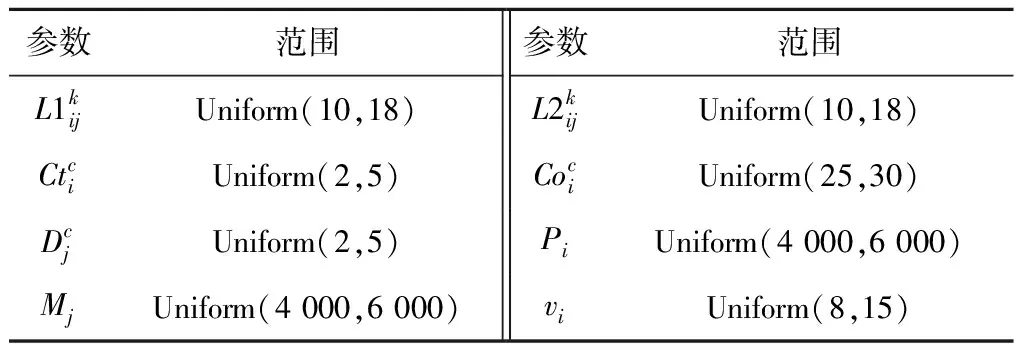
表10 算例中的参数范围
设定置信水平为1,SPWOGA和MA的交叉率和变异率分别取60%~70%和10%~15%。算法对每个算例运行20次,结果如表11所示。

表11 运算结果
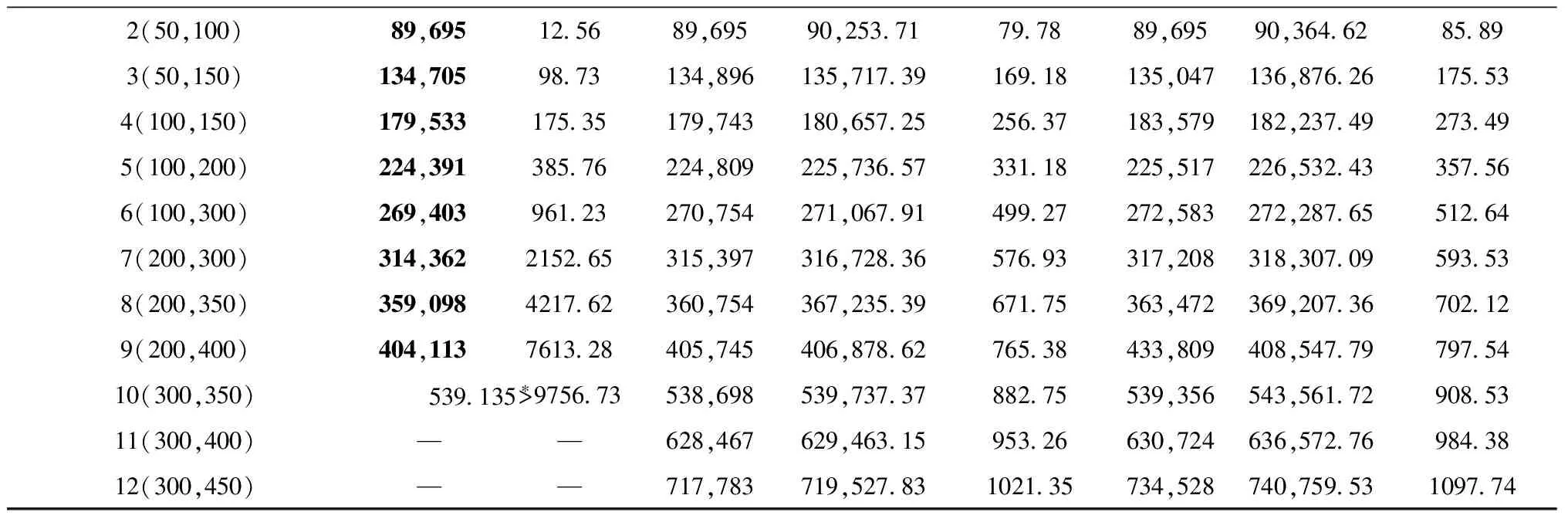
续表11
表11中,对于算例1和算例2,SPWOGA的运行时间比CPLEX长,但SPWOGA所得目标函数值与CPLEX相同,表明SPWOGA适用于规模较小的问题,但效率明显比CPLEX低;对于算例3和算例4,SPWOGA所得目标函数值比CPLEX大,且运行时间比CPLEX长;对于算例5~算例9,SPWOGA所得目标函数值比CPLEX大,但是运行时间明显比CPLEX短,表明对于规模稍大的问题,SPWOGA的精度降低,效率明显提高;对于算例10,SPWOGA所得目标函数值比CPLEX小,且运行时间比CPLEX短;对于算例11和算例12,CPLEX在系统内存不足的情况下不能给出可行解,而SPWOGA能够在可接受的时间范围内给出一个较好的解。因此,由以上分析可得,SPWOGA具有较高的精度。
另外,对于算例1和算例2,SPWOGA与MA得到的最好目标值相同;对于算例3~算例12,SPWOGA得到的目标值比MA小;对于全部测试问题,MA运行时间比SPWOGA长,而且随着算例规模的增大,MA所用时间增加得越多。这是由于MA的动态邻域搜索操作花费的时间较多,而SPWOGA可以在较短时间内得到较好的解,说明SPWOGA的求解效率较高,尤其是在求解大规模问题时更具优势。
为了比较SPWOGA和MA的收敛速度和求解精度,选取大规模测试算例10进行求解,结果如图3和图4所示。图3中,在迭代次数、种群规模及其他各个参数相同的情况下,SPWOGA在全局和局部搜索以及寻优精度上都表现出了优越性;图4中,在时间、种群规模及其他各个参数相同的情况下,SPWOGA的收敛速度较MA快,并找到了精度更高的可行解,证明了混合算法的优越性。
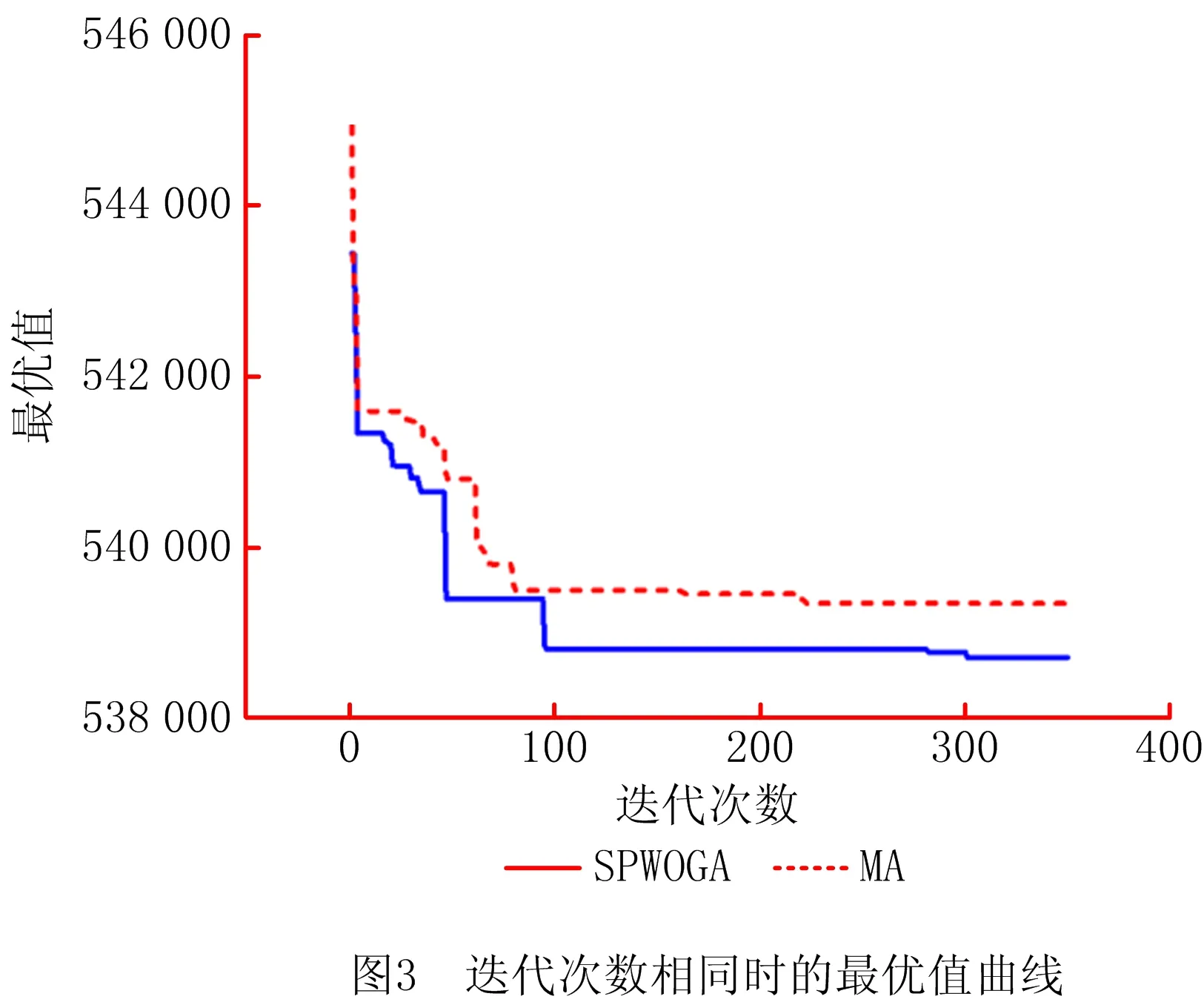
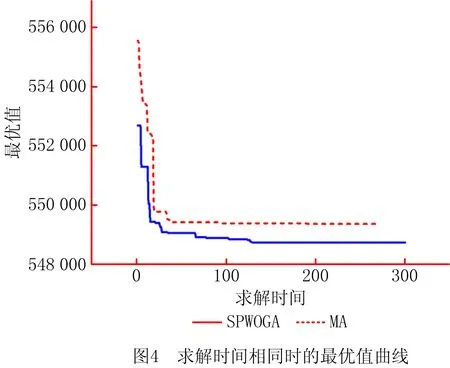
实际生活生产中,港口管理者经常面对规模很大的调度安排问题,希望尽快得到一个较好的调度方案来降低成本,而一般优化软件需要较长的时间才能得到解决方案,因此并不适用。本文所提SPWOGA可以在合理的时间内得到一个较优的解决方案,权衡计算时间和最优方案,具有一定的实际应用意义。
为了分析模糊参数对物流网络的影响,本文利用算例1研究网络模型,并给出主要数据,如表12和表13所示。

表12 与拖轮相关的数据

表13 与任务相关的数据
在0%~100%之间取置信水平,采用SPWOGA求解,得到各置信水平下闭环供应链网络模型的计算结果,如表14~表16所示。

表14 置信水平变化时的目标函数值
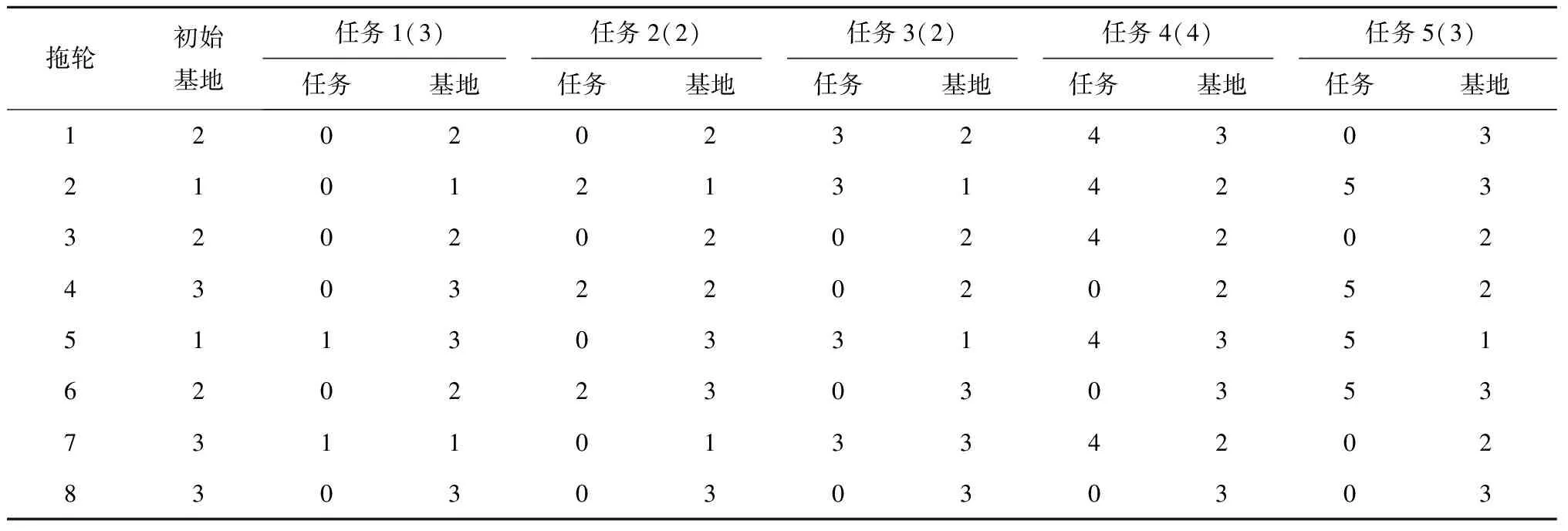
表15 置信水平为10%~100%的调度计划
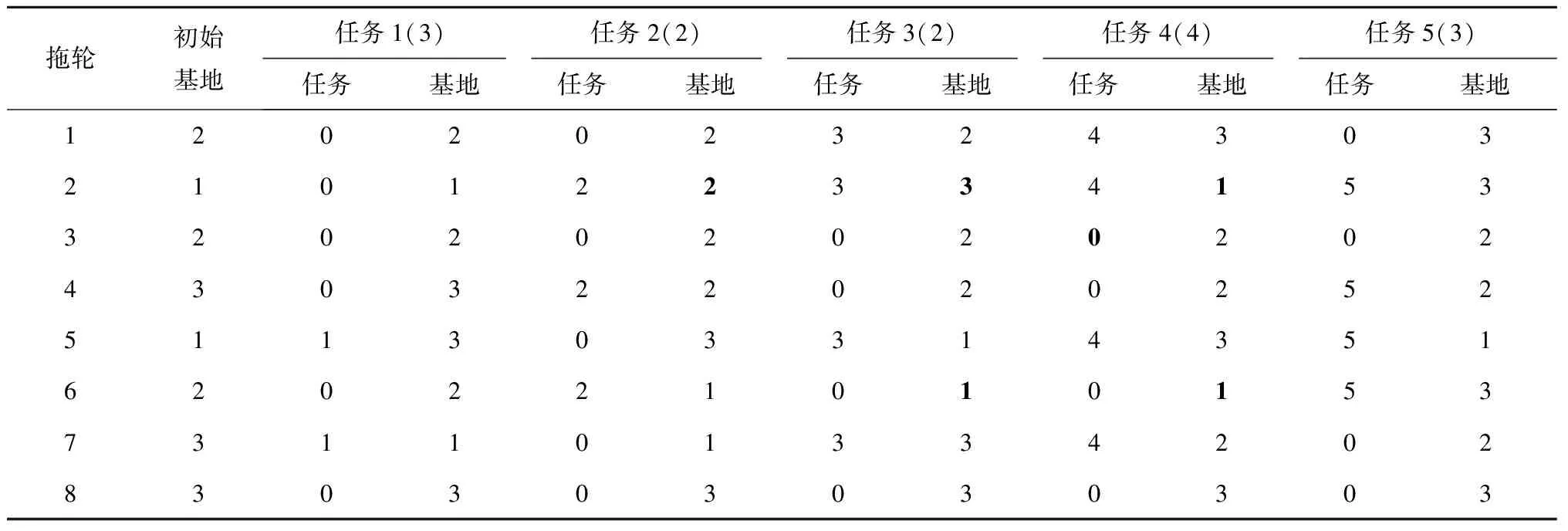
表16 置信水平为0%的调度计划
由表14~表16可见,置信水平0%~10%的目标值增加,这是因为增加置信水平使得任务所需拖轮数量增加,从而增加拖轮的航行成本和作业成本;置信水平10%~100%的目标值不变,这是因为增加置信水平没有导致任务所需拖轮数量增加,不需要增加额外的航行成本和作业成本。因此,置信水平影响目标值,存在一定风险。
对比表15和表16的调度方案可知,置信水平为0%所得调度方案与置信水平为10%~100%的不同在于,置信水平为0%的方案在拖轮2完成了任务3和任务4后分别回到基地3和基地1,拖轮3不执行任务4以及拖轮6在任务3和任务4作业期间均停靠在基地1,说明置信水平影响调度计划。
综上所述,由于置信水平对调度计划有明显的影响,企业管理者需要正确合理地分析和估计港口作业的变化来确定作业强度,在选择适当的置信水平的同时承担相应的风险水平,战略性地安排调度计划。
6 结束语
本文以港口拖轮为研究对象,考虑参数的不确定性,以燃油总成本最小化为目标,建立了一个多停泊基地、多任务和多拖轮的模糊调度混合线性规划模型,并设计了SPWOGA,最后通过算例证明了算法的有效性和模型的适用性,所得结果具有决策支持和方法指导的意义。
未来研究如下:①在多目标方面,除了成本最少化之外,现实中为了使拖轮调度问题更贴近实际,还需要考虑拖轮调度的效率最大化;②在不确定性方面,因故障导致拖轮不能按时完成既定的任务时,在中断的情况下对调度计划进行调整并保持其优越性。
