无人仓系统订单分批问题及K-max聚类算法
2021-06-01李珍萍田宇璇卜晓奇吴凌云
李珍萍,田宇璇,卜晓奇,吴凌云
(1.北京物资学院 信息学院,北京 101149;2.中国科学院 数学与系统科学研究院,北京 100190;3.中国科学院大学 数学科学学院,北京 100049)
0 引言
近年来,电子商务迅速发展,电商企业每天要处理的订单数量和订单类型越来越多。在大型配送中心内部,订单拣选作业时间约占总作业时间的30%~40%,拣选作业成本占到总作业成本的60%[1],对订单采取分批拣选策略可以有效减少作业时间、降低拣选成本[2-3]。因此,研究如何对订单进行分批是电商企业关注的重要问题之一。
传统的电商企业物流配送中心大多采用以人工作业为主的“人到货”拣选模式,该模式耗时长、效率低,容易出差错。近年出现的无人仓系统(如Kiva System[4-5])采用以自动导引小车(Automated Guided Vehicle, AGV)为主要运载工具的“货到人”拣选模式,这种模式具有拣选效率高且劳动强度低的优点,特别适合电商企业的多品种、小批量、多批次订单[4-5]。在基于AGV的无人仓系统中,对于每一组待处理订单列表(拣选单),首先由计算机控制系统确定需要搬运的货架和搬运路线,然后指派AGV将货架搬运至工作台前,等待工作人员从货架上拣取商品,再将货架送回仓库适当的位置。无人仓系统用AGV搬运货架代替人工行走,大大降低了工作人员的劳动强度。
无论是基于人工拣选的传统仓库,还是基于AGV的无人仓系统,订单分批策略都是直接影响订单拣选效率和拣选成本的最主要因素之一[2,4-5]。订单分批问题就是将陆续到达的众多订单按照一定规则划分为若干批次,每个批次对应一个订单列表(称为一个拣选单),每一批次订单同时进行拣选[6]。
订单分批问题本质上属于聚类问题,因此不同场景下的订单分批问题均可转化为特定目标下的聚类问题。传统仓库的订单分批问题与无人仓系统订单分批问题的主要区别在于优化目标不同,其中传统仓库中订单分批问题的优化目标是减少工作人员在仓库中的行走距离或行走时间[7-8]。常用的订单分批策略包括根据订单到达顺序依时间窗分批[9-10]和根据订单中的商品所在货位或通道进行分批[11-15]等,传统仓库的订单分批算法主要通过计算订单之间的相似度进行聚类。
由于作业模式不同,基于AGV的“人到货”仓库系统中的订单分批问题算法不能直接用于解决传统“货到人”仓库系统中的订单分批问题。
在无人仓系统中,影响订单拣选时间和拣选成本的主要因素包括工作人员从货架上拣取商品的次数和AGV搬运货架的次数,因此无人仓系统订单分批问题的优化目标中应该同时包括减少工作人员从货架上拣取商品的次数和减少AGV搬运货架的次数。近年来,国内外学者对无人仓系统订单分批问题开展了初步研究[16-18]。李晓杰[16]以减少货架搬运次数为优化目标,设计了求解订单分批问题的相似度函数,建立了聚类模型和策略评估模型;Xiang等[17]研究了Kiva系统中的储位分配和订单分批问题,以最小化货架的搬运次数作为订单分批问题的优化目标,通过最大化顺序关联或最小化顺序异化获得初始可行解,并采用变邻域搜索算法对可行解进行改进;Boysen等[18]则以搬运货架次数最少为目标研究了订单的排序处理问题,该问题等价于允许拆单的订单分批问题。
以上研究的主要优化目标是减少AGV搬运货架的次数,很少考虑工作人员从货架上拣取商品的次数,而两者是无人仓系统中影响订单拣选效率和拣选成本的重要因素,研究订单分批问题时应该同时考虑,以便将无人仓系统的任务分配和多机器人路径规划等子问题整合在一起,实现仓库运作效率的整体最优[19]。
本文同时考虑工作人员拣取商品次数和AGV搬运货架次数,建立以订单拣选总成本最小化为目标的订单分批问题优化模型。根据订单分批问题的数据特点和优化模型的目标函数表达式,采用取大(max)运算符定义订单分批问题的聚类中心和订单到聚类中心的加权距离,进一步设计求解订单分批问题的改进聚类算法。
1 无人仓系统订单分批问题描述与分析
无人仓系统中的订单分批问题可以描述为:无人仓中有M种商品存放在S个货架上,每个货架上有V个货位,每个货位只能存放一种商品,已知每种商品在仓库中的储位,且每种商品在相应货位上的存放数量充足。该无人仓采用“货到人”拣选模式,货架搬运设备为AGV机器人。假设某时段内共接到N张订单需要拣选,对这N张订单进行分批,使总拣选成本最低。
为了简化问题,假设:每种商品在货架上的货位固定,每个货架在仓库中的存放位置固定;每种商品恰好存放在一个储位上,即每种商品仅与一个货架对应;在订单拣选过程中,同时考虑两种成本,即机器人搬运货架的成本和拣选人员从货架上拣取商品的成本;AGV机器人每次搬运各个货架的成本均相同;拣选人员从货架上拣取每种商品的成本均相同。
在以上假设下,影响每个批次订单拣选效率和拣选成本的主要因素包括:①工作人员从货架上拣选商品的种类;②AGV将货架搬运至拣选工作台的次数。
基于以上假设,如果两个订单中包含的商品品项相同,将其合并拣选可使工作人员从货架上拣取商品的次数减少一半;如果两个订单中包含的商品存放在同一个货架上,将其合并拣选可使AGV搬运货架的次数减少一半。因此在进行订单分批时,应综合考虑订单中包含的商品品项信息和商品所在货架信息。
2 订单分批问题的整数规划模型
(1)符号和变量
为了建立订单分批问题的数学模型,引进如下符号:
i为订单索引,i=1,2,…,N;
k为批次索引,k=1,2,…,K;
s为货架索引,s=1,2,…,S;
t为商品索引,t=1,2,…,M
e为每个批次允许的最大订单数量;
c1为工作人员从货架上拣取一种商品的成本;
c2为AGV搬运一次货架的成本。
定义决策变量如下:
(2)整数规划模型
基于以上符号和变量,无人仓系统订单分批问题可以表示为如下0-1规划模型:
(1)
s.t.
(2)
(3)
(4)
(5)
xik∈{0,1},∀i,k;
(6)
yks∈{0,1},∀k,s;
(7)
zkt∈{0,1},∀k,t。
(8)
其中:目标函数(1)表示最小化拣选的总成本,总成本包括工作人员从货架上拣取商品的成本(第1项)和机器人搬运货架的成本(第2项);约束条件(2)表示每个订单恰好被分配到一个批次中;约束条件(3)表示分配到每个批次中的订单数量不超过批次容量限制;约束条件(4)表示如果分配到批次k的某个订单中包含商品t,则批次k包含商品t;约束条件(5)表示如果批次k中包含商品t,则拣选批次k时需要搬运一个包含商品t的货架;约束条件(6)~(8)表示决策变量取值约束。
3 K-max聚类算法
由于订单分批问题属于NP-hard问题[20],当问题规模较大时,在短时间内无法通过求解整数规划模型得到精确最优解,需要设计快速有效的近似算法。考虑到订单分批问题本质上属于聚类问题,可以按照聚类问题的求解思路设计算法。
K-means是聚类算法中最常用的一种快速聚类方法[21-23],该方法原理简单,适合处理样本量较大的聚类问题。传统的K-means聚类算法适用于取值为数值型的样本聚类问题,其类中心定义为类内样本的均值,样本与类中心的距离通常采用欧式距离。因为订单分批问题的样本取值为分类型数据,其样本均值没有意义[24],所以订单分批问题的类中心不能使用样本均值;另一方面,对于分类型数据,欧氏距离不能准确反映样本与类之间的差异,因此订单分批问题中订单与类(批次)之间的差异不能直接使用欧氏距离计算。由此可见,传统的K-means聚类算法不能直接用来求解订单分批问题。
本章将结合无人仓系统订单分批问题的分类型数据特征和数学模型结构,对K-means聚类算法进行改进,重新定义类中心和订单到类中心的距离,在此基础上设计求解订单分批问题的新聚类算法——K-max聚类算法。
3.1 类中心
从订单分批问题数学模型的目标函数表达式可以看出,订单分批问题的优化目标是尽可能减少同一批次订单中包含的商品种类和拣选同一批次订单需要搬运的货架数量,因此可以按照同一批次订单中包含的所有商品种类和拣选同一批次订单需要搬运的所有货架定义类中心,由此给出基于商品品项信息的类中心和基于货架信息的类中心的定义。
(1)基于商品品项的类中心
基于商品品项的类中心根据同一批次订单中包含的商品种类信息定义。根据整数规划模型的约束条件(4),只要某个批次中有一个订单包含商品t,则该批次订单中包含商品t。假设批次k包含的订单序号集合为Pk,定义批次k对应的基于商品品项的类中心为:
Qk=(qk1,qk2,…,qkM);
(9)
例如,某一批次订单中包含3个订单(如表1),订单1~订单3中包含的商品集合分别为{C,D},{A,C,D},{D,E},则该批订单对应的基于商品品项的类中心为(1,0,1,1,1),表示拣选该批次订单需要从货架上拣取A,C,D,E 4种商品。

表1 某批次3个订单对应的商品信息和基于商品品项的类中心
(2)基于货架信息的类中心
基于货架信息的类中心根据同一批次订单中包含的商品所在货架的信息定义。根据整数规划模型的约束条件(5),如果某批次订单中包含商品t,则拣选该批次订单需要搬运一个包含商品t的货架。由于拣选每个订单中的商品需要搬运的货架可以通过订单中包含的商品和商品在货架上的存储位置确定,假设拣选订单i需要搬运的货架已知,引入符号
假设批次k包含的订单序号集合为Pk,则定义批次k对应的基于货架信息的类中心为
Rk=(rk1,rk2,…,rkS);
(10)
例如,某批次包含3个订单,各订单中的商品对应的货架信息如表2所示,订单1~订单3中的商品对应的货架集合分别为{2},{1,2},{2,3},则该批订单基于货架信息的类中心为R=(1,1,1),表示拣选该批订单需要搬运仓库中所有的货架,即货架{1,2,3}。

表2 某批次3个订单对应的货架信息和基于货架信息的类中心
3.2 订单到批次(类中心)的距离
根据无人仓系统订单分批问题的整数规划模型目标函数表达式(1),给定一个待分类订单i和一个订单批次(或订单类)k,可以按照如下思想定义订单i到批次k的距离。如果将订单i加入批次k,批次k对应的类中心不发生变化,则定义订单i到批次k的距离为0;否则,根据加入订单i后,批次k对应的类中心增量定义订单i到批次k的距离。下面分别根据订单i中包含的商品品项及其所在的货架,定义两种订单i到批次k的类中心之间的距离,将这两种距离进行加权作为订单i到批次k的加权距离。
(1)基于商品品项的订单到批次的距离
基于商品品项的订单i到批次k的距离定义为:将订单i加入批次k以后,批次k中新增加的商品种类数。假设Ai为订单i包含的商品品项向量,
Ai=(ai1,ai2,…,aiM),
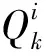
根据批次k基于商品品项的类中心定义,得到
基于以上符号,定义订单i与批次k之间基于商品品项的距离
(11)
式中dik表示将订单i加入批次k后,拣选批次k时额外增加的拣取商品种类数,对应整数规划模型目标函数(1)的第1项。
表3第2行表示订单4加入之前某个批次的类中心,第3行表示订单4中包含的商品品项信息,因此订单4与该批次类中心之间的距离为2。

表3 基于商品品项订单到批次之间距离的示例
(2)基于货架信息的订单到批次的距离
基于货架信息的订单i到批次k的距离定义为:将订单i加入批次k后,拣选批次k时新增加的搬运货架次数。假设Ui为订单i包含的商品所在的货架向量,
Ui=(ui1,ui2,…,uiS),

根据批次k基于货架信息的类中心定义,得到
基于以上符号,定义订单i到批次k基于货架的距离
(12)
式中gik表示将订单i加入批次k以后,拣选批次k时额外增加的搬运货架次数,对应整数规划模型目标函数(1)的第2项。
表4第2行表示订单5加入之前某个批次的类中心为{2,4,5},订单5对应的货架集合为{1,2,5},将订单5加入该批次后拣选该批次订单需要多搬运一个货架4,因此订单5与该批次之间的距离为1。

表4 基于货架信息的订单到批次之间距离的示例
(3)订单到批次的加权距离
基于商品品项的订单i到批次k的距离dik反映了在批次k中加入订单i后新增加的商品数目,将订单加入与其距离最小的批次可以减少从货架上拣取商品的总次数;基于货架信息的订单i到批次k的距离gik反映了在批次k中加入订单i后增加的货架搬运次数,将订单加入与其距离最小的批次中可以减少货架搬运的总次数。根据整数规划模型的目标函数表达式(1),将订单i加入批次k后,拣选批次k需要增加的总成本为c1dik+c2gik。基于以上分析,定义任意订单i到批次k的加权距离
wik=c1dik+c2gik。
(13)
加权距离综合考虑了商品拣选成本(次数)和货架搬运成本(次数)。根据加权距离进行聚类,使同一批次内订单的平均加权距离极小化等价于使订单拣选总成本极小化(即整数规划模型的目标函数(1)极小化),因此根据加权距离进行聚类可以得到订单分批问题的近似最优解。基于以上分析,本文设计K-max聚类算法。
3.3 K-max聚类算法步骤
K-max聚类算法步骤如下:
步骤1根据每一批次能容纳的最大订单数e确定批次数量K,任意选择K个订单作为初始类中心。
步骤2对每个i=1,2,…,N,按照式(11)~式(13)计算订单i到任意类中心k(k=1,2,…,K)的加权距离wik,并按wik由小到大对批次(类)进行排序。
步骤3在满足各批次订单容量约束的前提下,依次将各订单分配到加权距离最小的批次中。
对于每个待分配订单i(i=1,2,…,N),首先选择对应wik最小的批次k,若批次k包含的订单总量尚未达到最大订单数量,则将待分配订单i分配到批次k中,更新批次k内包含的订单信息;否则,从尚未达到最大订单量的批次中,选择与待分配订单i之间加权距离最小的批次h,将待分配订单i分配到批次h中,更新批次h内包含的订单信息,直到为所有订单重新分配了类别(批次)。
步骤4对每一个批次k=1,2,…,K,分别按式(9)和式(10)重新计算其对应的两种类中心,返回步骤2。
重复步骤2~步骤4,直到各批次对应的两种类中心均不发生变化,或迭代次数达到预先设定的最大值为止。输出订单分批结果,计算对应的拣选总成本。
在步骤1中,每一批次能容纳的最大订单数e根据实际情况设定,最大分批批次数K=[N/e]+1,其中N为订单总数,[]为取整函数。
为了减少算法的迭代次数,在步骤1中确定K个初始类中心时,应该使初始类中心彼此间的距离尽可能远。本文算法步骤1的设计思路如下:首先,将每个订单作为类中心,计算任意订单到任意类中心的加权距离,并找出最大加权距离对应的订单和类中心作为两个初始类中心k和h;然后,寻找与类中心k距离最大的订单i和与类中心h距离最大的订单j,分别计算i和j到k和h的加权距离之和,选择加权距离之和较大的订单对应的类中心作为新的初始类中心。依次寻找与已得到的类中心加权距离之和最大的订单作为新增加的初始类中心,直到找到K个初始类中心。
与K-means聚类算法不同,步骤4中计算两种类中心时采用的式(9)和式(10)均使用了取大运算符,因此称该算法为K-max聚类算法。
3.4 算法复杂性分析
定理1设置最大迭代次数为T,则K-max聚类算法的计算复杂度为O(N2MlogN)+O(TNK(M+S))。
证明K-max聚类算法步骤1中,如果按照最远距离策略选择类中心,则总的计算次数为O(N2MlogN);步骤2计算订单到类中心的加权距离运算次数为O(NK(M+S)),将每一个订单对应的加权距离排序的运算次数为O(NlogK),因此步骤2的总运算次数不超过O(NK(M+S));步骤3为每一个订单确定分类的运算次数为O(NK);步骤4重新计算类中心的运算次数不超过O(N(M+S))。
当设置最大迭代次数为T时,K-max聚类算法的总计算次数不超过O(N2MlogN)+O(TNK(M+S))。
3.5 订单分批问题数学模型和算法的几点说明
3.5.1 商品拣选成本与货架搬运成本
本文建立的订单分批问题数学模型目标函数中同时考虑了商品拣选成本和货架搬运成本。本文算法基于订单之间的加权相似度进行聚类,其中按照订单中包含的商品品项进行分批(聚类)可以减少商品拣取次数,按照订单对应的货架进行分批(聚类)可以减少货架搬运次数。虽然在无人仓中,工作人员从货架上拣取商品的次数和AGV搬运货架的次数之间存在较强的相关性,但是两者并不能互相替代。下面用两个例子说明,对于一些特殊情况,只考虑一个指标时不一定能得到最优分批结果。
例110种商品{1,2,3,4,5,6,7,8,9,10}存放在同一个货架上。有10个订单需要拣选,10个订单包含的商品品项分别为G1=G2={1,2},G3=G4={3,4},G5=G6={5,6},G7=G8={7,8},G9=G10={9,10}。假设每个批次最多包含2个订单。

分批结果①中,每批次两个订单中均包含4种商品,5个批次对应的商品拣选总次数为20次;分批结果②中,每批次两个订单中均包含2种商品,5个批次对应的商品拣选总次数为10次。显然分批结果②优于分批结果①。由于对应货架搬运次数最少的解有多个,在不考虑商品拣选次数的情况下,很难保证得到分批结果②;如果在进行订单分批时,同时考虑商品拣取次数最少,即利用加权相似度指标进行分批,则可以直接得到分批结果②,即最优分批结果。
例2已知仓库中有2个货架,共存放了10种商品,各种商品在货架上的分布情况为S1={1,2,3,4,5},S2={6,7,8,9,10}。现有10个订单需要拣选,每个订单恰好包含一种商品,即G1={1},G2={2},…,Gj={j},…,G9={9},G10={10}。假设每个批次最多包含2个订单,则10个订单至少需要分成5批。
因为任何两个订单中包含的商品均不相同,所以任意两个订单之间基于商品品项的相似度均为0。如果只考虑商品拣选次数,即利用基于商品品项的订单相似度进行分批,则一共有105种不同的分批结果,每种分批结果对应的拣选商品总次数均为10次。进一步分析发现,不同分批结果对应的货架搬运次数可能差别较大。例如:①B1={G1,G6},B2={G2,G7},B3={G3,G8},B4={G4,G9},B5={G5,G10};②B1={G1,G2},B2={G3,G4},B3={G5,G6},B4={G7,G8},B5={G9,G10}。
分批结果①对应的搬运货架总次数为10次,分批结果②对应的搬运货架总次数为6次,显然分批结果②为最优分批结果。
实际上,例2的10个订单中,前5个订单中包含的商品均存放在第1个货架上,后5个订单中包含的商品均存放在第2个货架上。因此,前5个订单和后5个订单各自之间基于货架的相似度均为1,但分别来自于不同组的两个订单之间基于货架的相似度为0。
对于例2中的数据,若不考虑货架搬运次数,只考虑商品拣取次数,则很难找到最优分批结果。如果在进行订单分批时同时考虑商品拣选次数和货架搬运次数,利用加权相似度进行分批,则可以直接得到分批结果②,即最优分批结果。
综上所述,由于实际无人仓系统中的订单具有小批量多批次的特征,例1和例2对应的特殊情况时有发生,为了确保在各种情况下均能得到最优的分批结果,在进行订单分批时,需要同时考虑商品拣选次数和货架搬运次数。已有文献多按照订单中包含的商品品项相似度进行分批,或者单纯以搬运货架次数最少为目标进行分批[17],然而对于无人仓系统中的一些特殊情况,单纯考虑一个指标的分批方法可能得不到最优分批方案。本文模型和算法同时考虑商品拣选次数和货架搬运次数,可以确保在各种情况下均能得到整体最优的订单分批方案。
3.5.2 分批拣选之后按订单拆分产生的成本
在本文的订单分批拣选问题数学模型的目标函数(1)中,只包括AGV搬运货架产生的成本,和工作人员从货架上拣取商品产生的成本,没有考虑订单分批合并拣选之后,进一步按订单拆分产生的成本。
实际中,当订单分批拣选后,需要进一步按订单拆分同一批次订单合并后拣取到的商品,并对各个订单进行打包和配送,由此产生按订单拆分成本。
按订单拆分产生的成本主要包括两部分:①同一批订单合并后,将货架上拣取到的每一种商品按照其对应的订单拆分成若干份,分别放入各个订单箱;②对每一个订单箱中的所有商品进行打包和配送。下面证明在一定假设下,以上两部分成本之和均为常数。

另一方面,对每个订单箱中的商品进行打包和配送所产生的成本与订单数量成正比,不妨设比例系数为γ,则对所有订单进行打包和配送的总成本为γM,也为常数。
如果将某批次订单合并后拣取的任一种商品拆分并放入相应订单箱所需要的时间(成本),与该商品对应的订单(箱)数量之间不为正比例关系,则按订单拆分的总成本有可能与订单分批策略有关。此时需要在订单分批问题数学模型的目标函数中增加一项按订单拆分产生的成本,然后结合目标函数的具体表达式重新设计求解模型的算法,后续研究将对该问题开展深入探讨。
4 模拟计算与结果分析
4.1 算例描述
某电商企业小型无人仓中30种商品存放在10个货架上,每个货架上恰好有3个货位,每种商品恰好存放在一个货位上,各种商品在货架上的存放位置如表5所示,在某段时间内收到的100个订单(如表6)需要分批拣选。
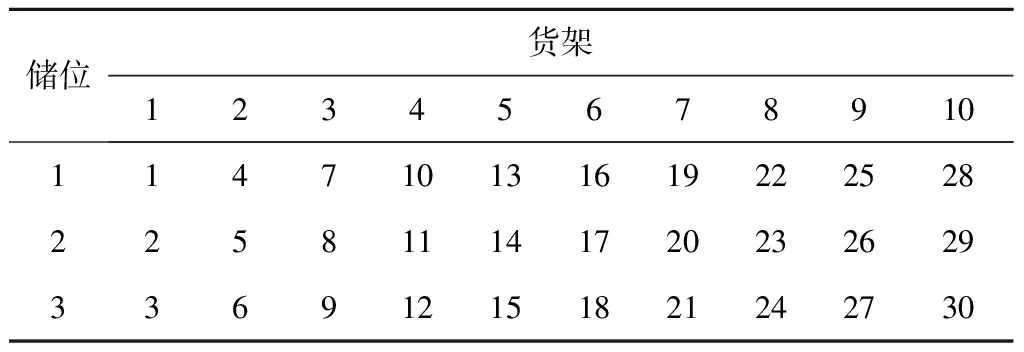
表5 无人仓中10个货架上存放的商品序号

表6 各订单中包含的商品信息

续表6
目前公司按照订单到达的先后顺序进行分批,将每10个订单作为一个批次进行拣选。按照这种分批策略,拣选100个订单需要工作人员从货架上拣取商品的总次数为140次,AGV机器人搬运货架的总次数为73次。
为了采用本文模型和算法进行分批,并比较不同分批结果的优劣,本文首先设置模型中用到的两个主要参数:工作人员拣选一种商品的平均成本c1和AGV搬运一次货架的平均成本c2。其中:c1=工作人员的单位时间工资×拣选一种商品的平均时间;c2=AGV来回搬运一次货架的平均折旧成本+平均能耗成本,平均折旧成本按每台AGV的平均价格和平均使用寿命计算。
在实验室环境模拟无人仓系统工作人员拣选商品的过程并获取实验数据,统计分析得到工作人员从货架上拣取一种商品并按订单信息将商品放入各个订单(箱)的平均时间为0.75 min。参考国家统计局2019年5月份公布的全国规模以上企业的平均工资68 380元/年,按照每年52周,每周5个工作日,每天工作8 h计算,工作人员每分钟的平均工资约为0.547元。根据拣选每种商品平均耗时0.75 min,可得c1=0.4元。
根据网上调查资料,每台AGV的平均价格为15万元,平均使用寿命为10年(约合3 650天)。根据实验室模拟运行的统计数据,去掉充电和设备检修时间,AGV每天搬运货架的平均工作时间为12 h,每小时平均可以搬运6次货架,由此得到AGV每次搬运货架的平均折旧成本约为0.57元。参照Kiva机器人的各项性能参数计算AGV每次搬运货架的能耗成本。Kiva机器人的能源来自4个串联的12 V,28 Ah铅蓄电池,充一次电可以使用8 h~10 h。参照工业用电价格1.5 元/度,AGV每次充电可以使用9 h,平均每小时可以搬运6次货架,据此计算出AGV平均每次搬运货架的耗电量约折合0.037元。因此c2=0.6元。
本文利用以上参数计算100个订单的不同分批结果对应的拣选总成本。
目前公司的做法是按照订单到达的先后顺序进行分批,将每10个订单作为一个批次进行拣选。按照这种分批策略,拣选100个订单需要工作人员从货架上拣取商品的总次数为140次,AGV机器人搬运货架的总次数为73次,拣选100个订单的总成本为99.8元。
接下来采用K-max聚类方法进行分批,并比较K-max聚类方法得到的分批结果与按订单到达先后顺序分批结果对应的工作人员拣取商品次数,以及AGV搬运货架次数和拣选100个订单的总成本变化情况。
4.2 K-max聚类结果分析
采用MATLAB软件编写K-max聚类算法实现程序,设定每个批次中最多包含11个订单,最大迭代次数为100次,在Intel(R)Core(TM)i5-3320M CPU@2.60 GHz笔记本电脑上运行程序,经过9.477 s,得到100个订单的分批结果,如表7所示。按照表7中的分批结果,工作人员需要拣取商品的总次数为93次,AGV搬运货架的总次数为48次,拣选100个订单的总成本为66元。
与企业当前采取的按订单到达先后顺序分批的策略相比,根据K-max聚类算法进行分批,可使工作人员拣选商品的次数降低47次,AGV搬运货架的次数降低25次,节约总拣选成本33.8元,拣选100个订单的总成本降低34%。由此可见,采用K-max聚类算法进行订单分批可以有效降低拣选成本、提高拣选效率。
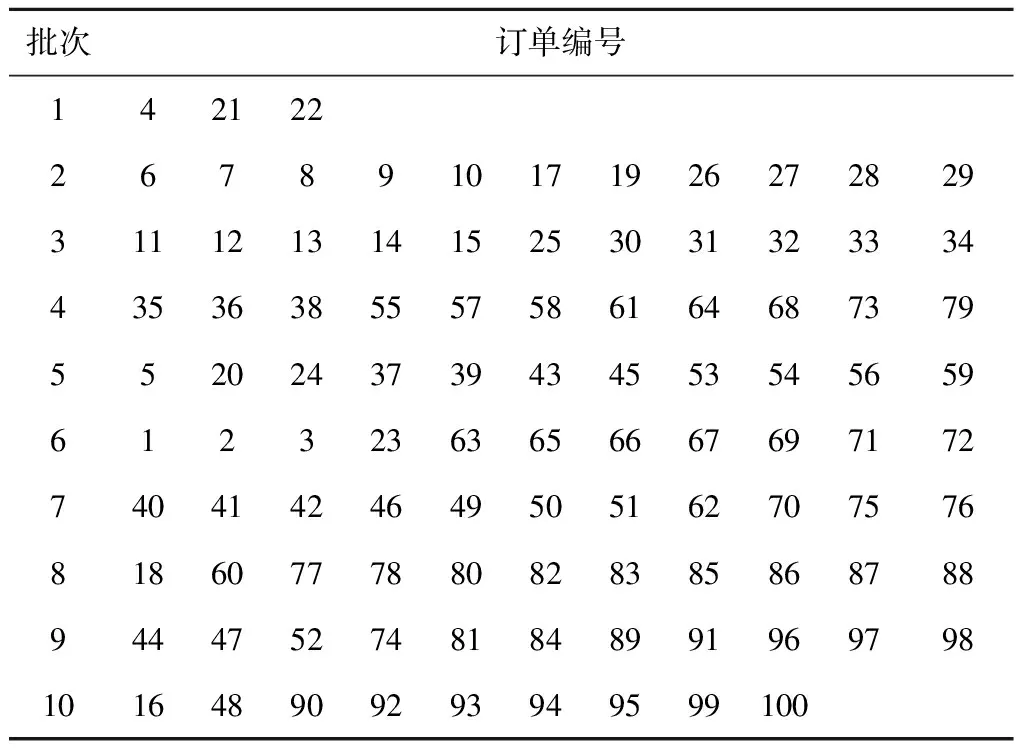
表7 采用K-max聚类算法得到的分批结果
为了分析本文模型和算法的有效性,利用文献[17]模型对算例进行求解。文献[17]模型的目标函数是最小化货架搬运次数,等价于本文只考虑基于货架的相似度指标。按照文献[17]模型计算得到的分批结果为:工作人员需要拣取商品次数115次,AGV需要搬运货架次数37次。可见,当只考虑货架搬运次数最少时,所得分批结果对应的货架搬运次数比本文模型(同时考虑商品拣取次数和货架搬运次数时)所得分批结果对应的货架搬运次数减少了11次,但其对应的商品拣选次数增加了22次,相应的总拣选成本为68.2元,比本文模型和算法得到的总成本66元增加了2.2元。分析可见,如果增加工作人员拣选商品的单位成本,则按照文献[17]模型得到的分批结果与本文模型得到的分批结果之间的误差会越来越大,即随着人工作业成本的增加,本文模型和算法的优越性会越来越明显。
4.3 灵敏度分析
本节采用算例分析参数c1,c2的变化对聚类结果的影响,包括工作人员拣取商品总次数、AGV搬运货架总次数和总拣选成本等随参数变化的趋势。
(1)参数c1变化
固定AGV搬运一次货架的成本c2=1元,令c1从0.1元逐渐增加到1元,分析其对聚类结果的影响。
设置最大迭代次数为100次,分别计算每组参数下的订单分批结果,如表8所示。可见,随着c1的增大,基于商品品项距离所占的比重越来越大,而基于货架距离所占的比重越来越小,分批结果对应的工作人员拣取商品的总次数呈现单调递减的趋势,AGV搬运货架的总次数呈现单调递增的趋势,拣选100个订单的总成本呈现单调递增的趋势。

表8 参数c1变化的分析结果
(2)参数c2变化
固定c1=0.1元,令c2从0.1元逐渐增加到1元,分析c2的变化对聚类结果的影响。
设置最大迭代次数为100次,分别计算每组参数下的订单分批结果,如表9所示。可见,随着c2的增大,基于货架距离所占的比重越来越大,基于商品品项距离所占比重越来越小。分批结果对应的AGV搬运货架次数呈现单调递减的趋势,工作人员拣取商品总次数呈现单调递增的趋势,拣选100个订单的总成本呈现单调递增的趋势。

表9 参数c2变化的分析结果
以上针对c1和c2的灵敏度分析结果,与订单分批问题数学模型的目标函数表达式中蕴含的数量关系完全吻合。
5 结束语
本文研究了基于AGV的无人仓库系统订单分批问题,同时考虑了工作人员从货架上拣取商品的成本和AGV搬运货架的成本,以总成本极小化为目标建立了订单分批问题的整数规划模型。基于常用的K-means聚类算法的思想,设计了求解订单分批问题的K-max聚类算法,其主要创新点在于,结合订单分批问题的数据特征和整数规划模型的目标函数表达式,利用取极大(max)算子分别定义了两种类中心和订单到类中心的距离;进一步以工作人员拣取一种商品的成本和AGV搬运一个货架的成本为权重,定义了订单到类中心的加权距离。最后利用具体算例进行模拟计算,分析了K-max聚类算法的分批效果,以及加权系数变化对分批结果和总费用的影响,验证了采用K-max聚类算法求解订单分批问题的有效性。
通过比较K-max聚类算法的分批结果与按时间窗分批结果对应的拣选总成本发现,利用K-max聚类算法进行订单分批,可大幅降低工作人员拣取商品总次数、AGV搬运货架总次数和订单拣选总成本,本文算例利用K-max聚类算法得到的分批结果,比按时间窗分批结果对应的订单拣选总成本降低了34%。
通过比较本文同时考虑商品拣选次数与货架搬运次数的订单分批模型和文献中仅考虑货架搬运次数的订单分批模型的计算结果发现,本文模型得到的订单分批结果优于文献模型得到的分批结果,且随人工拣选成本的增加,本文模型和算法的优越性愈加明显。
从灵敏度分析结果可见,当AGV搬运一次货架的成本保持不变时,随着工作人员拣取商品单位成本的增大,K-max聚类算法分批结果中的工作人员拣取商品总次数单调递减,AGV搬运货架总次数单调递增。当工作人员拣取商品的单位成本保持不变时,随着AGV搬运货架单位成本的增大,K-max聚类算法分批结果中的AGV搬运货架次数单调递减,工作人员拣取商品总次数单调递增。
对于本文包含100个订单的算例,笔者曾尝试直接采用商业软件求得其对应的整数规划模型的精确解,由于模型为非线性,用Lingo软件编程直接求解时,程序运行26 h仍然得不到最终结果,而采用K-max聚类算法在几秒内就可以得到近似最优解。由于实际中的订单分批问题均为大规模在线问题,必须在短时间内得到近似最优结果,因此本文设计的K-max算法是求解这类问题的有效方法。
本文仅研究了基于AGV的无人仓系统订单分批问题的简单情况,实际中还会涉及到很多不确定性和更复杂的因素,有待深入研究。如:本文假设一个货位上最多存放一种商品且没有考虑缺货情况,实际中为了提高拣选效率,经常会将同一种商品存放在多个不同的货架上。另外本文假设待分批的订单是已知的且具有相同的优先级,没有考虑订单实时到达和不同订单的优先级差别,后续研究中,可以研究考虑订单优先级的在线订单分批问题。
本文假设无人仓系统中货架在仓库中的位置固定,AGV搬运各个货架的成本均相同。然而在实际中,货架在仓库中的存放位置不同,AGV搬运该货架需要行走的距离不同,搬运成本也不同,考虑该成本差异,需要将订单分批拣选问题与货架位置的动态调整问题联合优化,从而得出总成本更低的仓储运作方案,未来可以对这类联合优化问题进行深入探讨。
K-max聚类算法专门针对分类型数据的聚类问题设计,可用于求解无人仓系统的订单分配问题,还可推广应用到其他分类型数据的聚类问题。然而K-max聚类算法中最大化算子对应的函数为分段函数,而且因为在分段点不连续,所以基于取大算子定义的距离与欧氏距离完全不同。因此K-max聚类算法与K-means聚类算法必然存在很多不同的性质,后续研究需要对K-max聚类算法进行理论分析,以进一步优化算法步骤,提高求解效率。
