教育数据分析的研究路径及其在教育中的意义
2021-05-08王洁高爽
王洁 高爽
随着信息技术的高速发展, 各行各业都积累了大量的数据,科学有效地挖掘数据,将有力推进本领域的研究水平,因此,当前许多行业都非常重视数据的挖掘和分析技术。在教育领域,虽然信息技术早已进入学校,为学校积累了大量的学生、教师、家长等方面的数据, 但是大部分的数据并未有效地帮助学校发展、教师教学和学生成长。究其原因是数据分析技术在教育领域中的应用依然薄弱, 很多学科教研员以及学校的一线教师缺乏数据分析的能力, 无法有效地对信息平台中的数据进行挖掘, 信息平台提供什么数据就分析什么数据, 无法再对其做进一步的分析拓展。 因此,本文将从教育测量的角度,介绍应当如何根据实际需要分析使用教育大数据。
一、教育数据分析相关概念
1. 数据类型
数据通常可分为有名义数据、顺序数据、等距数据、等比数据四种类型。名义数据是指用数字对事物的标签、类别、对象进行分类,如用数字1 和2 分别表示男生和女生,用数字1、2、3 表示颜色的红、黄、蓝。虽然这些名词可用数字进行表示,但是这些数字无法进行数学运算。 顺序数据不仅能指代事物的类别,还能表明不同类别的大小、等级或事物具有某种特征的程度,如各种赛事中的排名。 虽然顺序数据有大小和程度之分,但是它仍然无法进行数学运算。 等距数据不仅能指代事物的类别、等级,而且具有相等的单位,如气温等。 等距数据可以进行加减运算,但是因为它没有绝对零点,所以无法进行乘除。 等比数据除具有类别、等级、等距的特征外,还有绝对零点,如身高、体重。 名义数据和顺序数据通常又被称为非连续数据, 等距尺度和等比尺度则被称为连续数据。
2. 变量类型
自变量是指在研究中由研究者所操纵的、 对被试的反应可能产生影响, 并且研究者希望观察其效应的变量, 其作用是用来区分或定义不同的研究条件[1]。 如教师的教学方法、学生性别、是否独生子女等。 因变量是研究中由操纵自变量而引起的被试的某种特定反应,是研究者所观察的变量,因此也称为反应变量[2],如学生的成绩、学生的心理健康水平等。自变量X 对因变量Y 的影响,如果通过影响变量M来实现,则称M 为中介变量[3]。 如学生的好胜心能影响学生的学习动机和学习成绩, 此时好胜心是自变量X, 学习动机是中介变量M, 学习成绩是因变量Y。 如果两个变量之间的关系(如Y 与X 的关系)是变量M 的函数,则称M 为调节变量,即Y 与X 的关系受到第三个变量M 的影响[4],自变量X 影响因变量Y 的程度受到M 的调节。 如教师教学方式对学生学业成绩的影响,受到学生个性的调节。协变量是研究者有意识加以控制、不让其发挥作用的变量,又称控制变量[5]。
二、教育数据分析路径图解
数据分析技术可分为因变量技术和相互依存技术。 因变量技术是指有一个或多个因变量需要被预测变量(预测变量指可能除自变量以外对因变量产生影响的变量,如中介、调节变量等)或自变量去解释的数据分析技术。 相互依存技术是指没有明确单个或分类自变量和因变量的数据分析技术。
在因变量技术中,首先需要考虑因变量的个数,可以分成三种情况:即自变量与因变量多元关系、多因变量单一关系、单因变量单一关系。自变量与因变量多元关系是指有多种自变量和多种因变量, 此时可采用结构方程模型。
多因变量单一关系是指有多个因变量, 多种自变量。 其与自变量因变量多元关系的区别在于对应的关系是单一还是多元。这时,如果因变量是非连续数据,可以采用带虚拟变量的典型相关分析;如果因变量是连续数据,则需要考虑自变量的数据类型:自变量是非连续数据时采用多变量方差分析, 自变量是连续数据时采用典型相关分析。 单因变量单一关系是指只有一个因变量。如果因变量是连续数据,则考虑自变量的数据类型: 自变量是连续数据时采用多元回归分析, 自变量是非连续数据时采用单变量方差分析。如果因变量是非连续数据,则采用多元判别分析和线性概率分析。 具体路径见图1。
当无法判断因变量和自变量时, 则采用相互依存技术。如果需要研究变量之间的结构,可以采用因子分析和验证性因子分析; 如果需要研究变量之间的相互关系,可以采用皮尔逊相关分析和信度分析。如果需要研究个体之间的分类情况, 可以使用聚类分析的方法。如果需要研究的是对象特征,则应考虑特征是连续数据还是非连续数据:如果是连续数据,则采用多维尺度分析和对应分析; 如果是非连续数据,则采用对应分析,对应分析法可以揭示同一变量的各个类别之间的差异, 以及不同变量各个类别之间的对应关系。 具体路径见图2。
各数据分析方法的计算公式见表1。
三、教育数据分析的实例
案例1:教师教学成绩差异分析
此案例中,在控制了教学内容、学生基础、教学条件的情况下,王老师教了学生1 和学生2,张老师教了学生3 和学生4, 王老师学生的平均分为60分,张老师学生的平均分为70 分,那么哪位教师的教学水平高?
首先,需要确定自变量和因变量。从上表的数据可以发现,因变量是学生的成绩,自变量是教师的教学方式。 其次,从数据的类型可以发现,学生的成绩是等比数据,教师的教学方式是名义数据。 即自变量是非连续数据,因变量是连续数据且只有一个。从图1 可知,可采用单变量方差分析。 对于教学水平高的老师来说,他所教授班级的学生成绩会呈现两种特征:
班级间的成绩差异大(组间差异,SSb或S2b),学生班级内的成绩差异小(组内差异,SSw或S2W),合并教学水平高的老师的两个指标:

也就是说,班级间成绩差异大,而学生间成绩差异小。若两者之比足够小,则可判断教师的教学水平高。表3 给出了本案例的计算过程(更多内部计算过程可参考张敏强的《教育与心理统计学》[6])。

图1
通过表3 的计算,整理出表4 的方差分析表,计算组间/组内,求出F 值,F 值是方差分析中比较组间变异与组内变异的比率值,如果F<1,说明不同实验处理之间差异不大; 如果F>1 并落入F 分布的临界区域,表明不同的实验处理之间存在显著差异。通过查F 值表可知p 值为0.072,大于0.05,如果计算的F 值大于p 为0.05 的临界值,就不能拒绝虚无假设,说明不同组的平均数之间没有显著差异。综上,统计结果表明两位教师的教学水平差异不显著。
案例2:学校如何进行教学质量增值分析与评价?
教育质量是学生的学业成就水平和学生在学校中获得知识、 技能及态度为其离开学校以后适应社会所需要的程度[7]。 对于高中学校来说,学生的高考成绩作为结果性评价通常是评价高中学校教育质量的重要因素。但是判断高中的教学成绩,不能仅仅依赖学校高考成绩的绝对数值, 更应该考虑学生在学校学习中获得的增值。 增值反映的是学校在帮助学生提高入学期间的初始成就水平方面所做的贡献[8]这时, 最直接的数据就是学生的中考成绩和高考成绩。 在本案例中,表5 显示校1 是普通高中,校2 和校3 是重点高中, 三个学校的高考平均成绩分别是450.13、546.42 和582.78, 如果仅从高考成绩判断学校的教学质量,显然最好的是校3,且普通中学一般情况下不可能比重点中学的高考成绩更高。

图2

表1 各数据分析方法的计算公式

表2 学生成绩样本
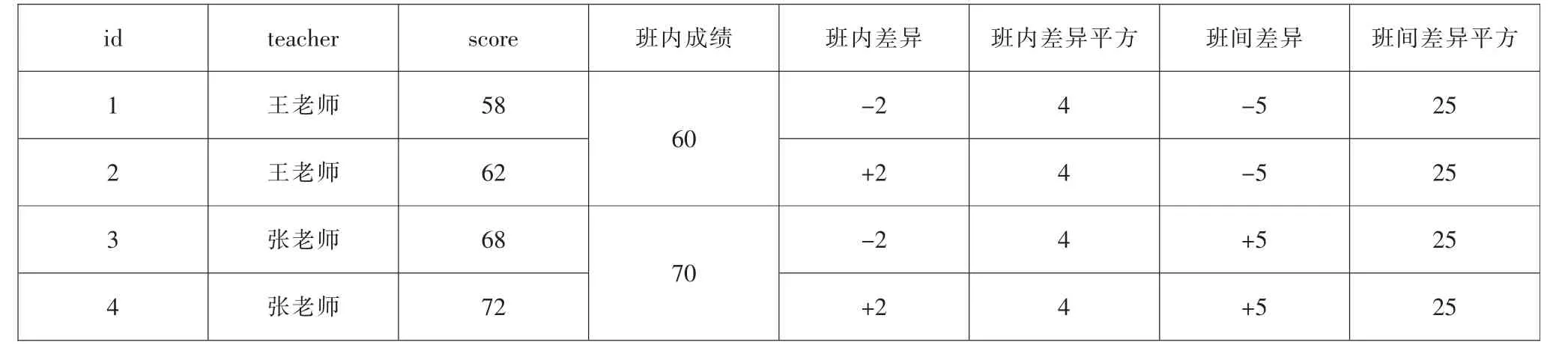
表3 方差分析计算过程

表4 方差分析表
但是如果从增值的角度看,教学质量优秀的未必是重点高中。 从三所学校的中考成绩看,校1、校2 和校3 的中考成绩分别是561.02、610.68 和626.83, 从前文可知,学校为顺序数据,成绩为等比数据,所以采用方差分析进行差异分析。通过方差分析发现,三所学校的p 小于0.05,说明三所学校的差异显著(见表6)。

表5 三所学校的高考成绩与中考成绩描述统计

表6 三所学校中考成绩方差分析
将高考成绩与中考成绩结合进行分析,因为高考成绩与中考成绩都是等比数据, 且为了判断学校变化的增量,所以采用回归分析。因为中考成绩与高考成绩的平均数和标准差不同, 所以在做回归时将中考成绩和高考成绩进行标准化处理,标准化的作用是去量纲,标准化回归系数之间可以比较大小。 分析结果可通过回归系数的正负和大小来判断。如果回归系数为正,说明学校对学生学业成绩有促进作用, 反之则说明有负向作用。 如果回归系数大,说明学校的增量大,该校对学生学业成绩更有促进作用;如果回归系数小,说明学校的增量小。 从表7 可知,校1、校2 和校3 的回归系数分别是-0.091、0.401 和0.296。 从数据看, 虽然校3的中考成绩和高考成绩高, 但是校2 的回归系数为正且更大,说明校2 更能促进学生学业成绩增长。
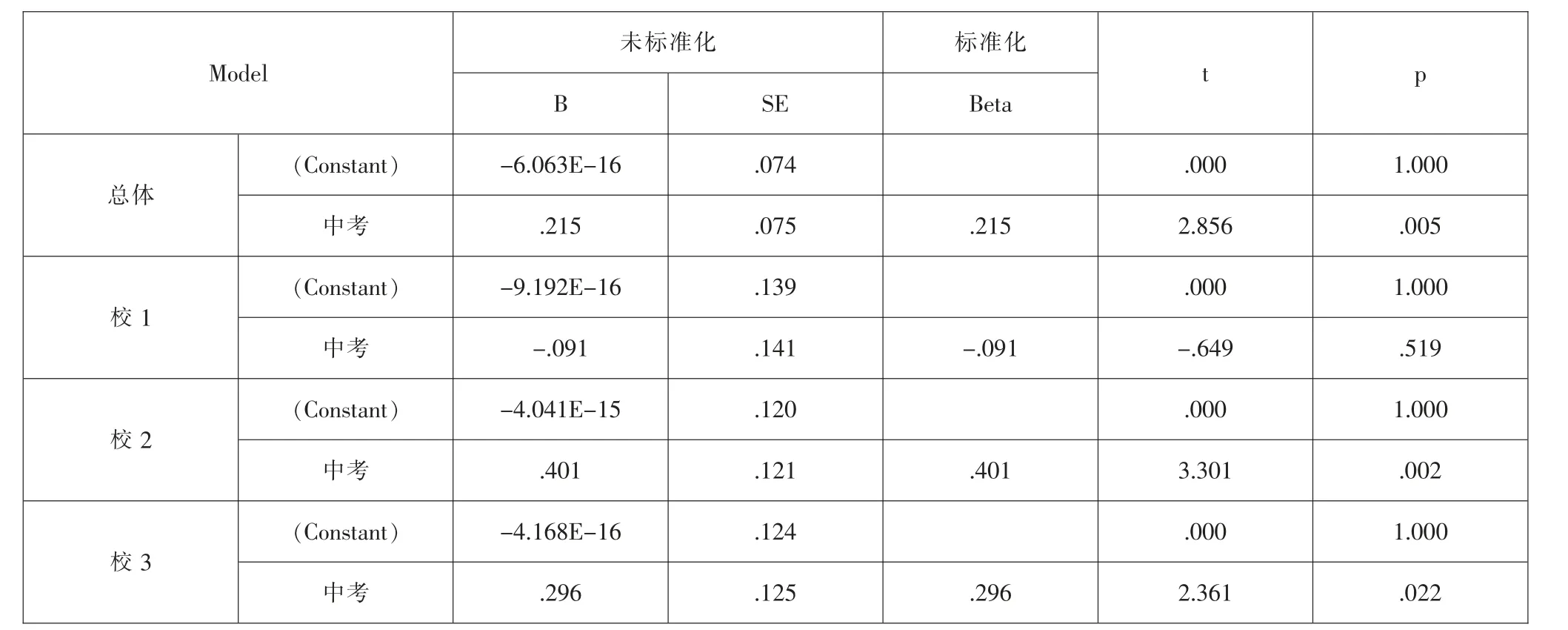
表7 三所学校回归分析
案例3:家庭社会经济地位对学业成绩的影响—学习动机和网络依赖的中介作用
该案例来自于浙江省2019 年初中教育质量监测, 从中随机抽取监测样本的10%。 学业成绩由语文、数学、科学组成,通过项目反应理论获得量表分。学习动机、家庭社会经济地位的测量方式参考PISA的计算方式, 网络依赖由网络依赖和网络成瘾的经典量表改编而成。 学习动机和家庭社会经济地位数值越高,说明学生的学习动机越强,家庭社会经济地位越高。 网络依赖数值越高,说明学生网络依赖程度越低。学业成绩、学习动机、网络依赖和家庭社会经济地位都是连续数据,所以,为了探索四个变量之间的关系,可以对变量进行描述统计和相关分析。 结果发现,学业成绩与学习动机的相关度最高,达到0.39,与网络依赖和家庭社会经济地位的相关度也达到0.33,变量间相关关系都达到显著水平(见表8)。

表8 学业成绩与各因素的相关分析
为进一步探讨家庭社会经济地位对学业成绩的影响, 并研究学习动机和网络依赖在此模型中的作用,建立家庭社会经济地位对学业成绩的中介模型,见图3。 SES 为家庭社会经济地位, 作为自变量;q5为学习动机,z2 为网络依赖, 分别作为中介变量;score 为学业成绩,作为因变量。
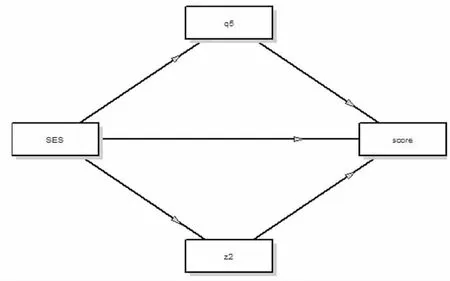
图3 中介模型
通过Bootstrap 法重复抽样1000 次, 检验学习动机和网络依赖的中介效应,在95% 显著性水平下的置信区间分别为[2.40,4.35]和[1.89,3.33],不包含0,说明中介效应显著。 从模型上可以发现,家庭社会经济地位可以影响学生的学习动机,进而积极影响其学业成绩。而家庭社会经济地位也可以影响学生的网络依赖,家庭社会经济地位越高,网络依赖的现象越少,进而积极影响学业成绩。 从侧面可以发现,家庭教育从不同的角度影响着学生的学业成绩(见表9)。
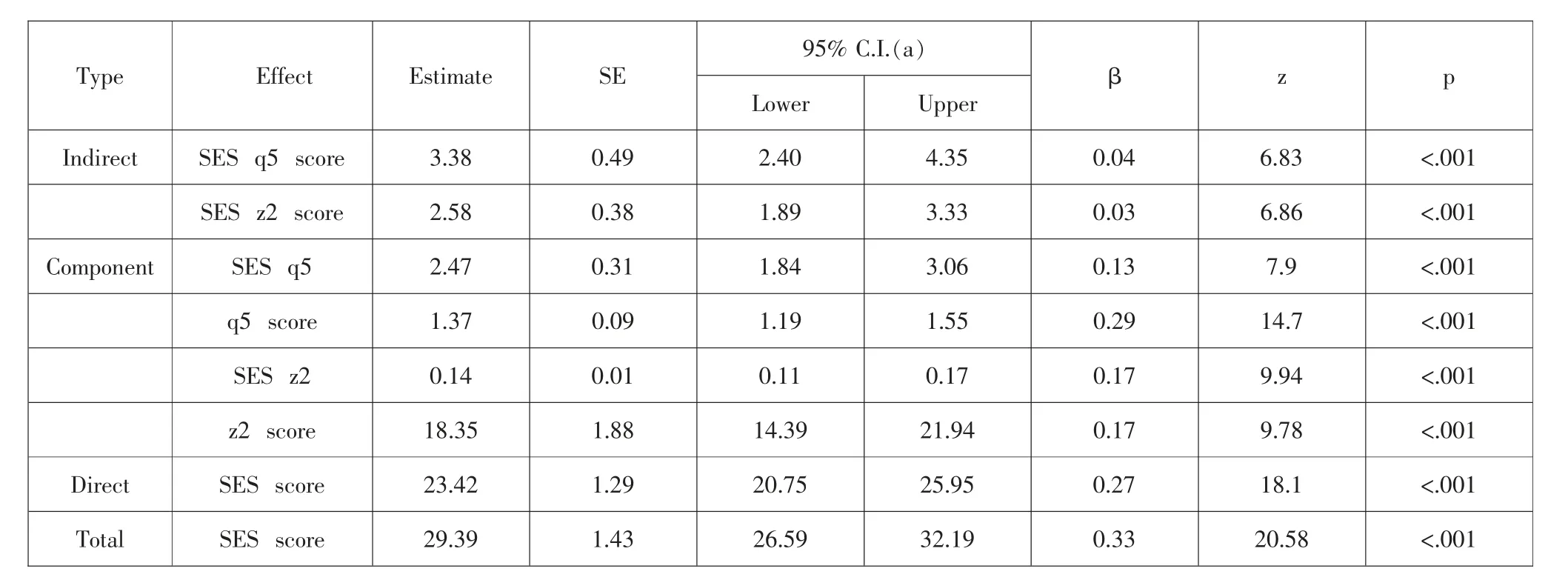
表9 中介效应分析模型
以上案例说明,数据分析时必须了解数据类型、变量类型(自变量、中介变量、调节变量、因变量)以及应用条件,这样才能正确选用数据分析方法,结果才具有可信度, 数据分析才会在学校教学和研究中发挥重要作用。
四、教育数据分析在教育教学中的意义
1. 基于数据提高教学评价的科学性
评价是评判学校教学成果、 教师教学水平的重要方式,但是科学的评价在教学实践中并非易事。通常, 教育行政部门对中学的评价标准以升学率为重要指标, 学校对教师的评价以班级平均成绩作为重要指标, 因此评价往往过于简单化。 如果能基于数据,应用数据进行评价,那么评价的科学性会明显提高。 如上文所述,教育行政部门在对高中评价时,如果只采用重点录取率作为考核的指标, 可能会打击普通学校教师工作的积极性, 但是如果基于数据进行增值评价, 不仅普通中学教师的工作积极性可以得到显著提升, 重点中学的教师工作积极性也会随之上升,起到事半功倍的效果。学校对教师的评价应该减少以单项指标——平均分作为单一衡量标准,如果在平均分指标这一基础上, 再增加标准差这一指标, 如通过以班级距离全校或整个区域的程度作为判断标准,分出5 级或7 级,如“明显低于”“低于”“差异不显著” “高于” “明显高于”,当教师所教班级在多次都落于“低于”区间时,可以对其进行指导,如果只是一次落于“低于”区间,则可以认为是误差所致,只需进行提醒。
2. 基于数据提升教学研究的科学性
以往教师的研究主要是关注如何教学, 或者在教学过程中所采用的创新性教学方式, 其研究往往缺乏数据分析。有些学校要求教师改变教学方式,那么就需要判断学生在学习上的变化状况, 以往可能依赖于教师或学校的定性评价, 或者通过班级的平均分判断学生学习状况的改变情况。 如果采用数据分析的方式,不仅可以收集到教学方式改变前后,学生在学习、心理、生活上的动态变化,还能找到哪些因素改变的最多,并依此拓宽教学科研的思路。
3. 基于数据矫正试题的信度和效度
试题命制是一门科学。一份科学的试题,需要具有较高的信度和效度。 虽然教师知道试题信度和效度的重要性,但是他们在命题时,因为没有掌握数据分析技术,所以最多关注的是难度,而信度和效度往往会被忽略。 国内外教育考试与评价部门已经大量使用数据分析的技术来矫正和验证试题, 如中国基础教育质量监测中心、国际经合组织的PISA、美国的SAT 和GRE 等在命题过程中都非常注重信度和效度的检验。这些机构以往常常采用经典测量理论,主要采用的数据分析方式是相关分析、 差异检验和结构方程模型,现在则以项目反应理论为主。项目反应理论是由逻辑回归延伸而来, 因为学生的测试成绩与自身的能力是非线性关系, 所以它在描述测试分数时会更加科学。 项目反应理论的软件主要由国外相关测评公司或者高校开发, 比较常用的软件有Conquest、Winsteps、FlexMIRT、Multilog、R 语言、Mplus等,其中PISA 采用的是Conquest。 如果具有一定编程基础, 相关研究者也可以使用Python 进行项目反应理论分析。通过这些软件进行数据分析,不仅可以判断信度、效度,还可以判断试题的难度、区分度、猜测率和失误率, 参考这些指标可以去矫正试题的题干、问题以及选项,提高试题的科学性。
4. 基于数据进行学科认知诊断评估
最近几年, 心理与教育测量界发展出了认知诊断理论。认知诊断理论指的是对个体知识结构、加工技能或者认知过程的诊断与评估[9],它是认知心理学与心理测量学相结合的一种新理论。 认知诊断理论与经典测量理论、 项目反应理论最大的区别在于,认知诊断理论很大程度上通过对数据的分析,着眼于评价学习和学习过程,而不是简单评价学习的结果[10]。认知诊断相当于对教学过程的诊断, 我国传统的考试主要是关注学习者的成绩, 对学习者的学习过程并不重视, 也没有一种切实有效的方法去评估学生的学习状况,认知诊断可以弥补这些缺陷。 例如,为了分析小学生分数运算掌握情况, 可以将分数运算能力分解成分数乘法、倒数、分数除法、百分数、分数乘除规则以及通分六个能力属性,通过认知诊断技术,不仅可以分析学生在哪些属性的掌握上存在问题,而且还可以分析学校在哪些属性的教学上存在问题, 并通过数据分析的结果对学生和学校进行有针对性的补救[11]。 目前,认知诊断的应用研究已涉及到小学的加减法、乘法、儿童数感、算术运算、因式分解、语文阅读,初中的平行四边形、力与运动、化学用语,高中的电磁学、化学平衡、几何学、向量,以及大学的英语听力、阅读等,甚至还可以对特殊儿童的数学、阅读障碍进行诊断。国内很多高校已经积累下丰富的研究成果,其中江西师范大学、北京师范大学和浙江师范大学在认知诊断方面的研究最多, 可以借鉴学习。 通过认知诊断理论可以了解学生的学习过程,并将信息反馈给学校和教师,进而让教师利用这些信息去精确指导学生的学习,避免题海战术,达到轻负高质的效果。 认知诊断技术的发展将推进学校学习走向智慧学习。
