基于相码模型的汉字表征
2021-05-07范晓明王斌君
范晓明, 王斌君
(1.中国人民公安大学信息技术与网络安全学院, 北京 100038; 2.北京警察学院网络安全保卫系, 北京 102202)
汉字表征(characterization of Chinese characters),可理解为通过某些特定的字符或符号集表示汉字的过程,而表征技术则可看作一种变换函数,将汉字映射到某一特殊的向量空间,这一向量空间由一组给定的字符集表示。对汉字表征技术的研究,可追溯到中文信息技术发展初期,当时主要围绕如何高效实现汉字录入的问题进行研究,以五笔为代表的形码表征方式和以拼音为代表的音码表征方式分别借助汉字字形特征和汉语拼音方案实现了汉字集向小字符集(键盘对应的字符)映射,后期出现的手写汉字识别[1]、语音识别[2]等技术,则是将汉字视为笔画、音节的空域或时域序列信号,利用隐马尔可夫模型(hidden Markov model,HMM)[3]等统计模型进行汉字相关特征的识别。目前,利用越来越成熟的中文分词[4]以及词嵌入(word embedding)[5]技术,基本可将适用英文的自然语言处理(natural language processing,NLP)深度学习模型迁移到中文处理中,但在解决未登录词(out of vocabulary,OOV)和低频词(low frequency words)问题时,由于汉字的复杂性,中国学者无法直接将英文场景中的字符级(character-level)语言模型进行同级别迁移,需要借助笔画、部件、拼音等转码方式进行中文文本的细粒度表达,围绕这一需求,现尝试构建一种新的编码模型,期望能得到拉丁字母序列码与汉字的最佳映射关系,能以类似英文单词(word)的编码融合汉字的多种字符级特征,并用于NLP相关模型中。
1 相关研究
传统方法中,文本主要以独热(One-Hot)编码、词频-逆文件频率(TF-IDF)、词袋(BOW)等方式表示。Bengio等[6]使用神经网络语言模型(nerual network language model,NNLM)将文本从One-Hot输入成功转为词向量,Mikolov等[7]提出词嵌入方法,其提出的word2vec模型将词向量维数降低到100~300,之后,Pennington等[8]利用共现矩阵实现了GloVe模型,后来出现的ELMo[9]、BERT[10]等模型则通过注意力机制具备了动态向量表征的能力。
为解决OOV问题,字符级的文本表征方式开始受到重视,并取得了一定的进展。Zhang等[13]在Kim等[11-12]提出的TextCNN基础上,将文本视为一种字符级别的原始信号,利用一维卷积实现了字符级文本分类模型CharCNN。在相关模型迁移到中文时,部分研究者尝试将汉字作为基本字符进行模型的改造,王丽亚等[14]将字符级词向量用于情感分析,李伟康等[15]探索了神经网络框架下汉语字向量和词向量的结合问题,并在基于文档的问答系统中进行了验证。更多研究者则是关注到与汉字相关的拼音、笔画、部件等低层级要素,将汉字特征进行细粒度拆分。一种思路是基于形码的汉字表征,主要将汉字视作笔画、部件等基本元素的组合,Li等[16]构造了以部首为主的部件信息向量,Sun等[17]通过部首来增强word embedding,构造了RECWE模型,Su等[18]通过图形字符来增强词的表示,Cao等[19]通过笔画的n-gram(n元模型)特征构建了cw2vec模型,赵浩新等[20]提出了笔画字向量模型,Yang等[21]将五笔编码作为描述汉字的字符级编码用于命名实体识别(NER)任务中。第二种思路是基于拼音实现汉字特征替换或补充,刘敬学等[22]通过拼音序列对原始汉字序列进行语义拓展,在字级别卷积神经网络上,得到了比词级别更好的短文本分类效果;张曼等[23]通过小字符集映射嵌入的方式,构造了全卷积的字符级神经网络 LRN-CharFCN,并在文本分类任务中取得良好表现;还有一种思路是结合汉字音形特征进行尝试,胡浩等[24]结合汉字5种基本笔画和拼音,将汉字映射为32维的向量,提高了短文本相似性比较的性能。
一般来说,文字均可看成具有某种层级结构[25]关系R的元素(基本笔画、基本字母等)集合,如英文可以看作是26个基本字母集并拥有字母、单词二级层级结构关系的字母集合,中文可视为由基本笔画集按某种层级结构关系R构成的集合,也可视为由拼音字母按层级结构关系R构成的字母集合,但这种层级关系远比英文复杂。一方面,中文的基本字符集远大于英文的基本字符集,英文的26个字母基本不能作为基本语义单位,其最小语义单位是单词(word),对应中文的词,现代汉语虽然主要以词作为表达单位,但很多汉字本身也充当语义单位的角色;另一方面,汉字比英文字母表现出更明显的二维特征,音形分离程度相对较大,并且汉字还可进一步拆分为笔画、部件,所以中文文本在细粒度区分和表达上比英文更复杂。
从向量表征粒度看,英文中的word对应中文的“词”,包括单字词(uni-word)、二字词(bi-word)、三字词(tri-word)、多字词(n-word)等,而由于汉字的复杂性,英文中的character并不能与中文的“字”有效对应,这也是当前中文字符级(character-level)表征存在多种处理方法的原因。2016年,Sennrich等[26]提出subword的概念,对word实现子词级别(subword-level)的拆解,有效缓解神经网络机器翻译(neural machine tranlation, NMT)任务中的OOV问题;2017年,Bojanowski等[27]也采用了subword-level的word描述策略,得到增强型词向量,以提高训练及预测效率。同时发现,汉字构词作用与subword极其相似,所以,认为汉字恰好处于subword层面,向上可组成word,向下可继续细分为character,并恰好与英文形成如表1所示的层级对照结构。

表1 中英文字词层级对照
此外,参考心理学领域的相关文献[28]表明,汉字表征需适当考虑用户交互的需求,这样找出的小字符集可同时作为一种助记符号体系使用,方便研究人员对比分析。借助统计规律和大量实验,对汉字进行了character-level层面的拆解,得到了一种人工干预下的预编码,充分考虑了汉字的音形特征以及字频等信息,初步实现汉字和拉丁字母的可逆映射,并在新闻文本分类任务中取得了较好的效果。
2 对汉字主要属性的统计与划分
2.1 对中文字(词)频规律的统计
从公开统计数据[29]看,如图1所示,单字形式下,《信息交换用汉字编码字符集 基本集》(GB 2312—1980)中规定的3 000个汉字可覆盖日常所用汉字的99%以上,若将词作为基本表征单元,汉语中单字词、二字词使用频度最高,词频靠前的8 000词可覆盖常用词的85%以上,其中单字词占18.5%,二字词占60%。

图1 汉语字(词)频统计结果Fig.1 Statistical results of Chinese characters (words) frequency
2.2 对形、音、义特征的统计与改进
2.2.1 基本笔画
汉字笔画可划分为“点、横、叉、撇、竖、折”六类,其中“点、横、撇、竖、折”为基本笔画,依据《现代汉语通用字笔顺规范》划分;“叉”类笔画包含“扌”“艹”“廴”“乂”“九”“又”“丰”“毋”等,其主要特征是有两个或两个以上的基本笔画相交。
2.2.2 偏旁归类
参考《汉字部首表》[30],选取161个部首作为偏旁,并根据偏旁组字能力强弱(含有该部首的汉字多少)排序,并结合音、形、义特征,可将排序靠前的55个偏旁归类为如表2所示的20个固定子集,用20个字母表示。
对组字能力偏弱的其余106个偏旁,可依据起笔、声调特征动态归类,并用B、G、W、F 4个字母表示,如表3所示。
2.2.3 音节的主备韵规律及双拼方案的改进
根据汉语拼音方案,为压缩码长,可采用图2所示的双拼方案,将声母zh、ch、sh分别用e、v、u表示,韵母自成音节的,将字母“o”作为其双拼声母,同时,将韵母压缩到26个字母键位上。
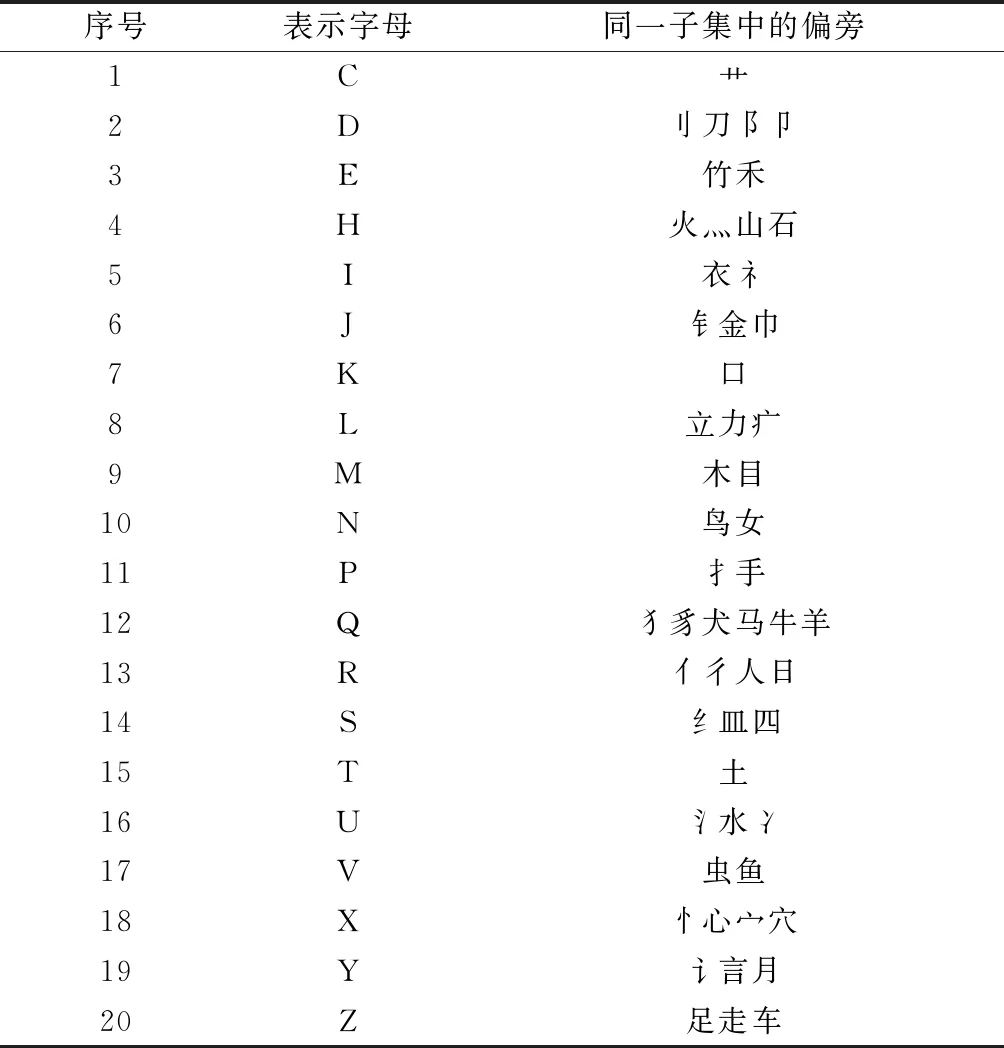
表2 偏旁固定归类表

表3 偏旁动态归类表
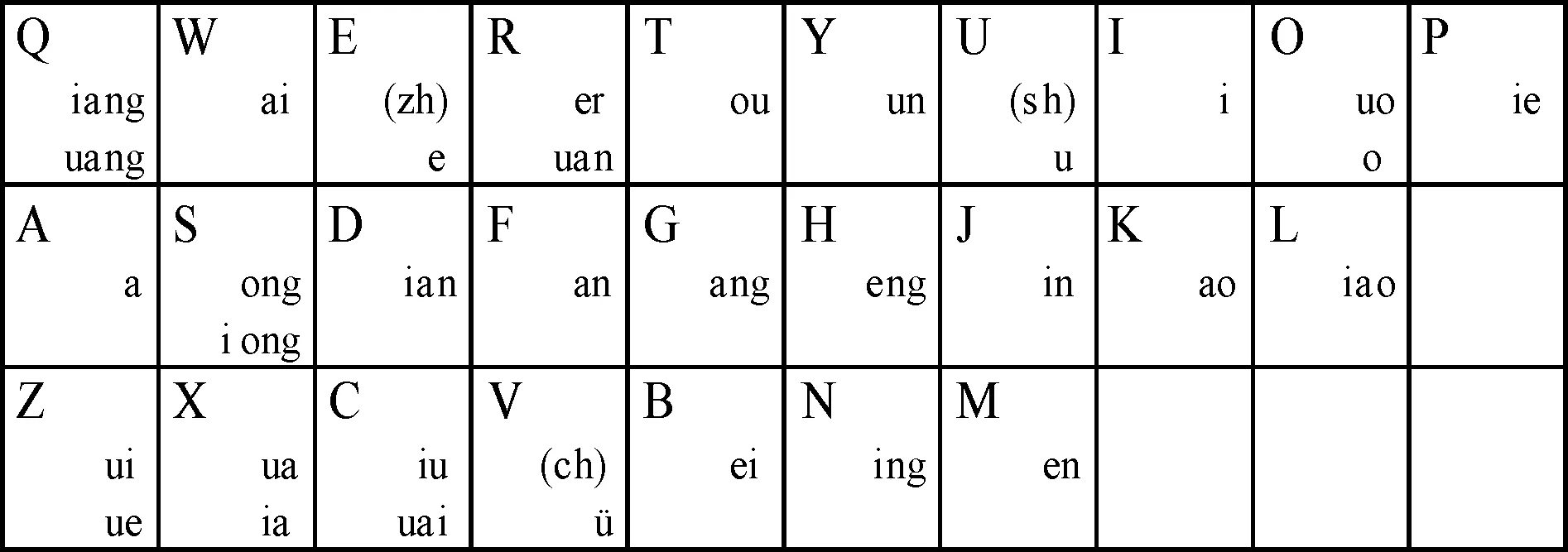
图2 相码双拼键位图Fig.2 Key map of XQMA double spelling scheme
经统计,汉字音节对应的汉字分布极其失衡,以i、u为韵母的同音字最为明显,《信息技术 中文编码字符集》(GB 18030—2005)中yi音节对应的同音字多达480个,而zei、zen等音节对应的同音字不足10个。在词组中,重码率较高的也多为以i、u为韵母的汉字。故需要考虑改进现有的双拼方案。
(1)定义一。成音码对:两个字母拼读时存在对应的汉字音节,则两个字母称为成音码对。非音码对:两个字母拼读时不存在对应的汉字音节,则两个字母称为非音码对。
统计表明,使用双拼方案时,同声母的成音码对与某些非音码对之间存在互补性,且具有一定规律,可用来提高编码密度。
(2)定义二。主备韵关系:某些存在互补性且成对出现的韵母(如d与f、h与n),其互补性对很多声母均适用,如表4所示,这些韵母,若其处于成音码对,称为主韵,对应的音节为主韵音节,若其处于非音码对,称为备韵,对应的音节为备韵音节。主韵音节和备韵音节之间的关系,称为主备韵关系。双拼方案下,对具有主备韵关系的汉字,可用主韵音节和备韵音节对同音字进行二分类,有效解决编码稀疏问题。
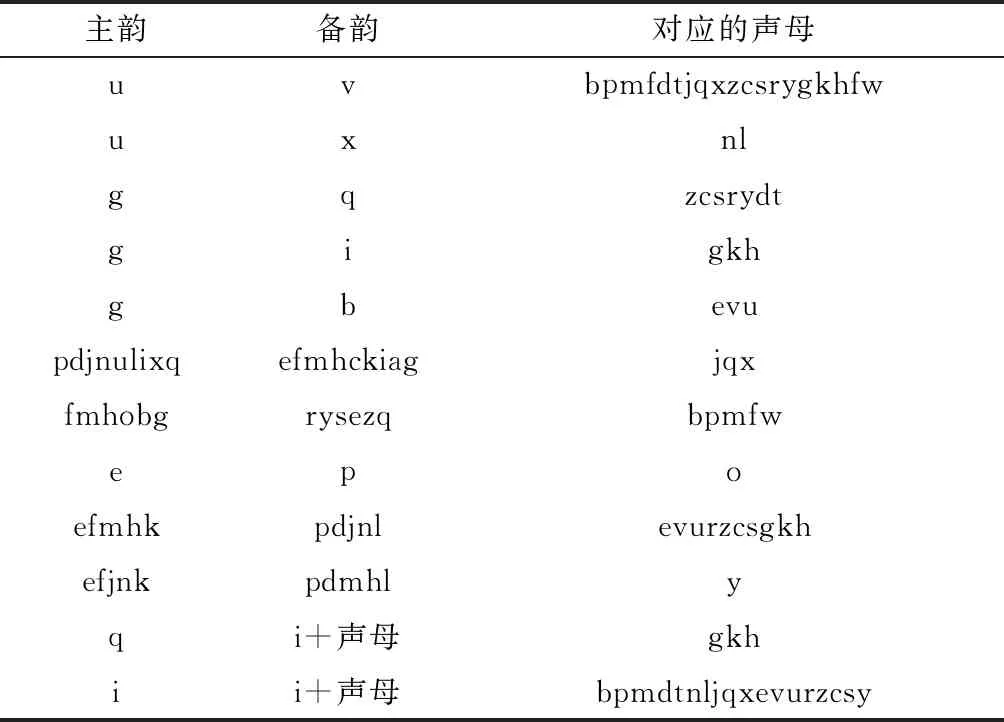
表4 双拼方案下的主备韵关系表
2.3 利用统计规律划分汉字子集
结合起笔的统计规律,汉字可相对均衡地归为两类,其中一类以点横叉起笔,另一类以撇竖折起笔。结合形旁特征,汉字可划分为基本字、衍生字。当某一汉字无偏旁或该汉字加偏旁后能构成三个以上其他汉字时,可判定其为基本字,否则为衍生字;基本字主要通过读音区分,衍生字则需在读音的基础上增加偏旁归类码区分。其数量比例关系如图3所示。
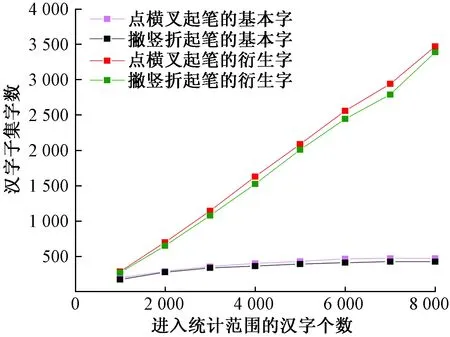
图3 常用汉字统计规律Fig.3 Statistical results of common Chinese characters
对基本字,可根据汉字使用频率以及汉字的表音、表形、表义等属性,进一步划分为声调字、偏旁字、特高频字、普通字,进一步提高编码的可读性。
3 XQMA模型
模型全称为跨象限助记符映射模型,英文名称为cross-quadrant mnemonic mapping model,用X代替cross,并取其余关键字缩写为XQMA。模型可按照特定的规则,交叉利用词组和单字的各项特征,自动将汉字映射到码元(26个拉丁字母)序列构成的空间中,可实现拼读、拼写、键盘录入的一致性。典型的单字表征码如图4所示,典型的词组表征码如图5所示,利用字母、数字的可变长序列表示跨象限助记符,称为相码,为模型描述而构造的象限图,称为相位图。
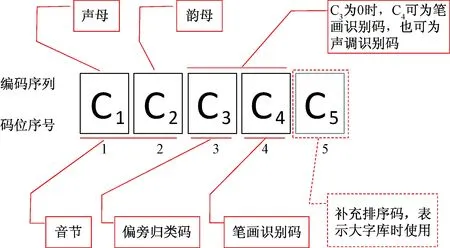
图4 典型单字编码相位图Fig.4 Coding phase diagram of typical Chinese characters
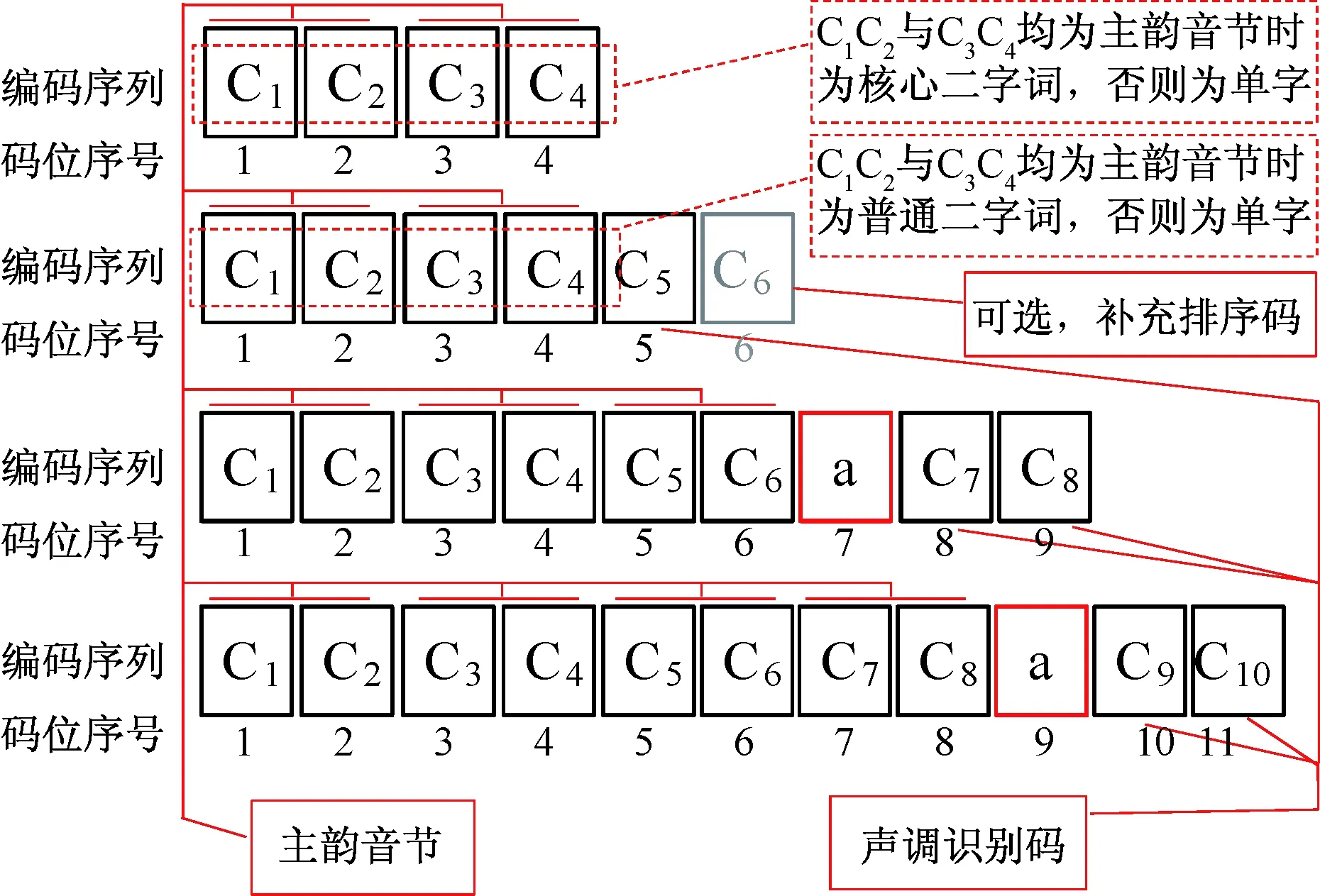
图5 典型词组编码相位图Fig.5 Coding phase diagram of typical Chinese words
3.1 模型基本设定
3.1.1 子集划分
根据第2节的统计结论,可依据起笔和形旁特征将汉字划分出如表5所示的4个子集。
同时,根据音节的主备韵规律,可将起笔特征与汉字发音的主备韵关系相匹配,以主韵表示点横叉起笔的汉字,备韵表示撇竖折起笔的汉字,得到如表6所示的结果。
3.1.2 笔画识别码
利用汉字本身的笔画特征作为单字的笔画识别码;主要方法是将组成该汉字的所有笔画中“点”“横”“叉”的数量值“模5”(即除以5的倍数,保证余数在01234的范围内)后,所得余数值对应的字母作为识别码,如表7所示。
3.1.3 主备韵规则
对存在主备韵关系的汉字,当汉字属于JD或YD,其读音编码为其主韵音节的编码,称作主韵码;当汉字属于JP或YP,其读音编码为其备韵音节的编码,称作备韵码。如图6所示,采用主备韵规则后,极大提高了编码密度,编码空间的利用率可由59.2%提高至83.4%。

表5 汉字子集划分

表6 汉字编码的子集划分
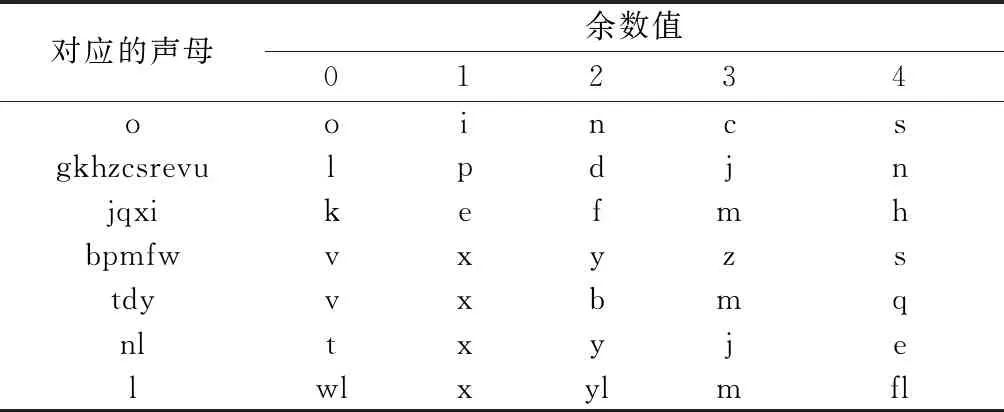
表7 笔画识别码
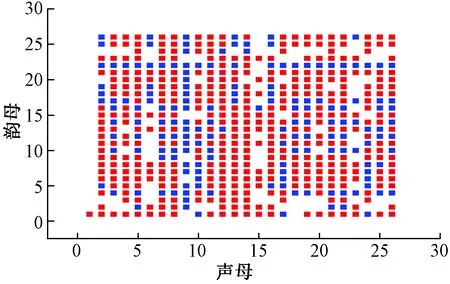
图6 采用主备韵规则后的音节分布Fig.6 Syllable distribution after adopting the active-standby switch rules
3.1.4 偏旁归类码
对衍生字区分时以发音和偏旁码为主,参照表2、表3,由24个字母代表20类确定性偏旁和4类非确定性偏旁。采用偏旁归类码后,5 000个常用汉字可在3码长度内表示,若将编码所用的26个拉丁字母按字母表排序映射为1~26的整数,则5 000常用汉字单字在编码空间的三维分布如图7所示,为方便分析,将第3码元对应的坐标值进行了着色。
3.1.5 声调识别码
对单字,分别用“XYZD”表示该字发音为1、2、3、4声。对二字词,引入如表8所示的声调识别码,表示前后字分别为1、2、3、4声所形成的16种声调组合,字母“TEMP”分别表示前字发音为1、2、3、4声且后字为轻声时形成的4种情况。对三字词,前两字的声调识别码参照二字词处理,第三字的声调识别码分为由字母“TEMPO”表示该字发音为1、2、3、4声及轻声的情况。四字词以两字为一组,声调识别码参照二字词处理。
3.1.6 补充排序码
为保证模型的可扩展性,在对大字库编码和二字词编码时,当重码过多,可在末位引入补充排序码,单字在第5码位、二字词在第6码位,依次用“oincsvlqbjuxyzdwtempghkrfa”表示0~25个候选位序,其中“o”备用。
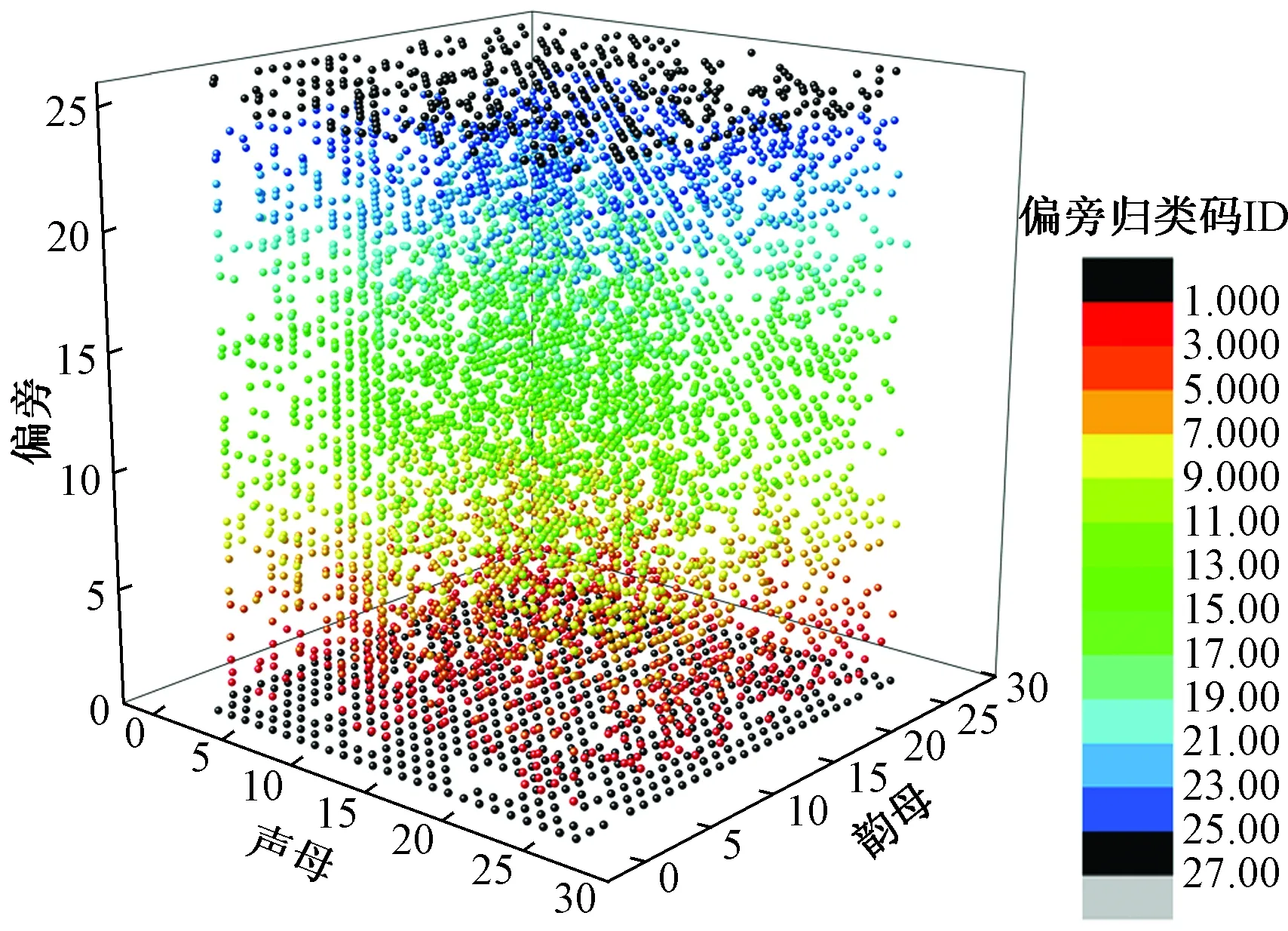
图7 常用汉字在3码长编码空间的分布Fig.7 Distribution of common uni-word in 3-coding space
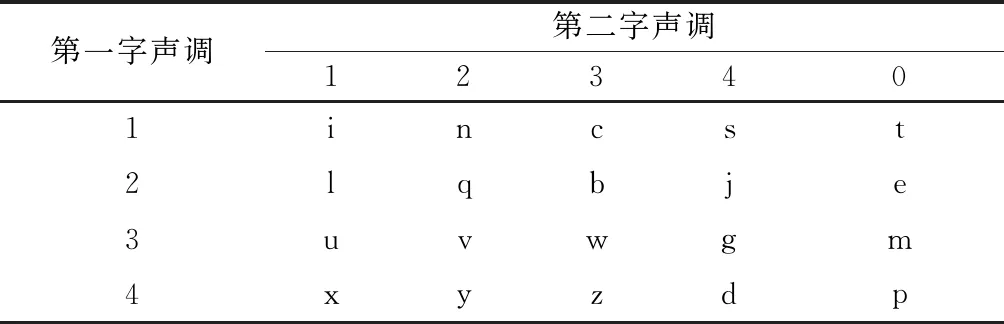
表8 声调识别码
3.2 汉字的区分策略
3.2.1 根据频率和声调规律区分基本字
基本字在编码时用读音区分,按字频由高到低,用形如aC1C2、C1C2、C1C2a、C1C2o和C1C2ox、C1C2oy、C1C2oz、C1C2od两组编码表示声调字,分别代表声调为1、2、3、4声的相应汉字。用形如C1、aC1、oC1的形式表示特高频字、偏旁字、特殊字。
普通字为以上方式无法覆盖到的基本字,用形如C1C2oC3(当该字声调为1声或2声)或形如C1C2iC3(当该字声调为3声或4声)的编码表示,C3位置为笔画识别码。
3.2.2 根据偏旁和笔画规律区分衍生字
衍生字需在读音的基础上增加偏旁归类码区分,典型表示方式为C1C2C3,C3位置为偏旁归类码。如“wum”表示汉字“梧”。若有重码,用形如C1C2C3C4的编码表示,C4位置为笔画识别码。对大字符集单字编码时,对以上方式无法覆盖到的衍生字,需用形如C1C2C3C4C5的编码表示,其中C5位置为补充排序码,依次用“incsvlqbjuxyzdwtempghkrfa”表示1至25个候选值。
3.2.3 单字无歧义表示
采取改进的双拼方案表示汉字发音,在保留音节信息的同时,引入主备韵规律、高频字优先策略和偏旁动态归类、笔画识别机制,提高编码密度,4码范围内实现7 000个常用单字的独立无歧义表示。
3.2.4 字词独立无重编码
实行显式的字词分离。当编码的前四码无法用双拼的方式拼读时,该编码代表单字。
对核心字库中的汉字单字的编码长度压缩在4码以内,最长码表示为C1C2C3C4的形式,对扩展字库,编码长度压缩在5码以内,用形如C1C2C3C4C5的形式表示。
将常用二字词作为核心词,码长为4,取两字的双拼读音,其余词为普通词,二、三、四字词的码长分别为5、9、11,在双拼读音的基础上增加了声调识别码,以降低同音词的识别难度。
3.2.5 拼读、拼写及助记
为提高助记符的易用性,选取25个特征字,对26个字母构造如图8所示的特征键位图。整个编码规则充分考虑了手写需求,可直接将模型规则用于手动拼写、盲文替代、速记、变量命名等场景。
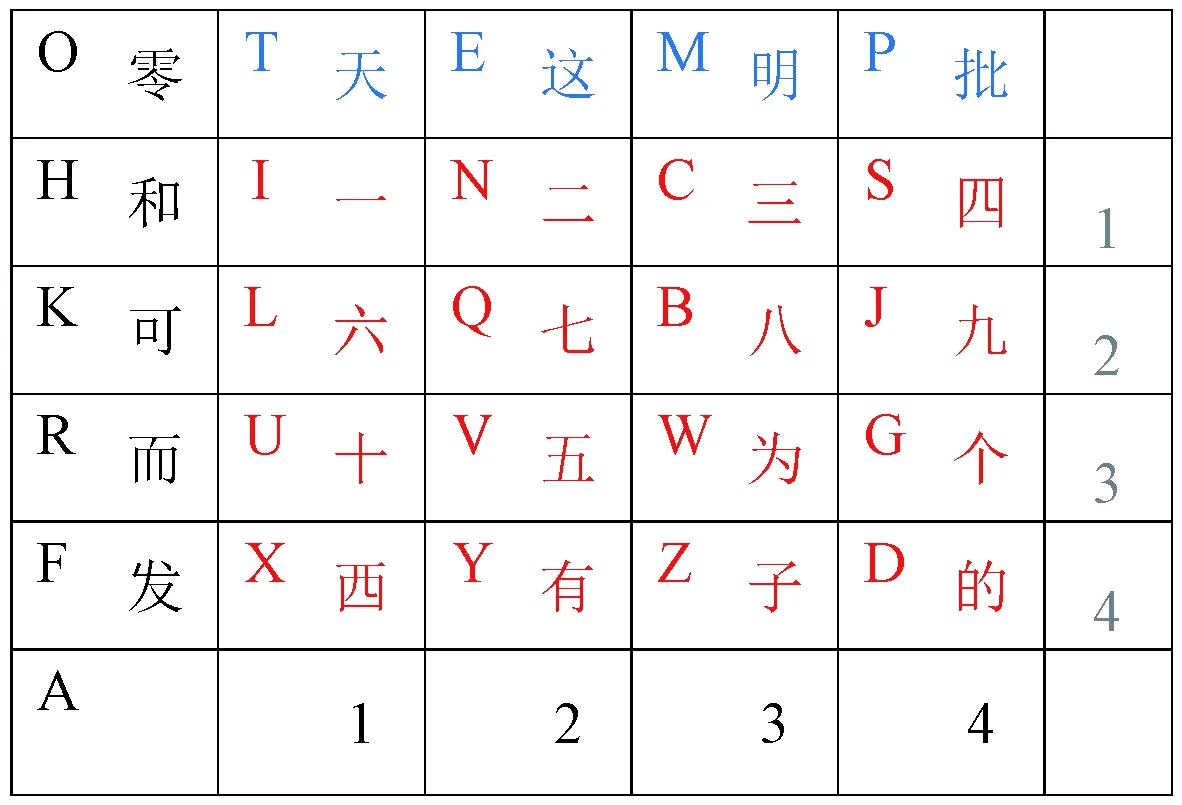
图8 助记字特征键位图Fig.8 Mnemonic feature key map
4 实验及分析
4.1 数据准备及评估指标
4.1.1 模型编码所用数据准备
下载汉字编码字符集,分别符合《信息交换用汉字编码字符集 基本集》(GB 2312—1980)和《信息技术 中文编码字符集》(GB 18030—2005)标准。收集整理公开语料库,构建汉语字、词的频率特征库。同时,利用pypinyin,标注相应汉字、词组的声调及拼音。参考文献[31-32]中的模型,结合人工校验,构建汉字单字偏旁库以及相应偏旁的汉字单字拆分库、基于6种基本笔画的笔画笔顺库。
4.1.2 模型验证数据准备
验证实验基于Windows 10环境,搭建TensorFlow 1.13平台,采用Python3语言,数据集为清华NLP组提供的THUCNews新闻文本分类数据集的一个子集,如表9所示,包含10个分类,每个分类6 500条数据。
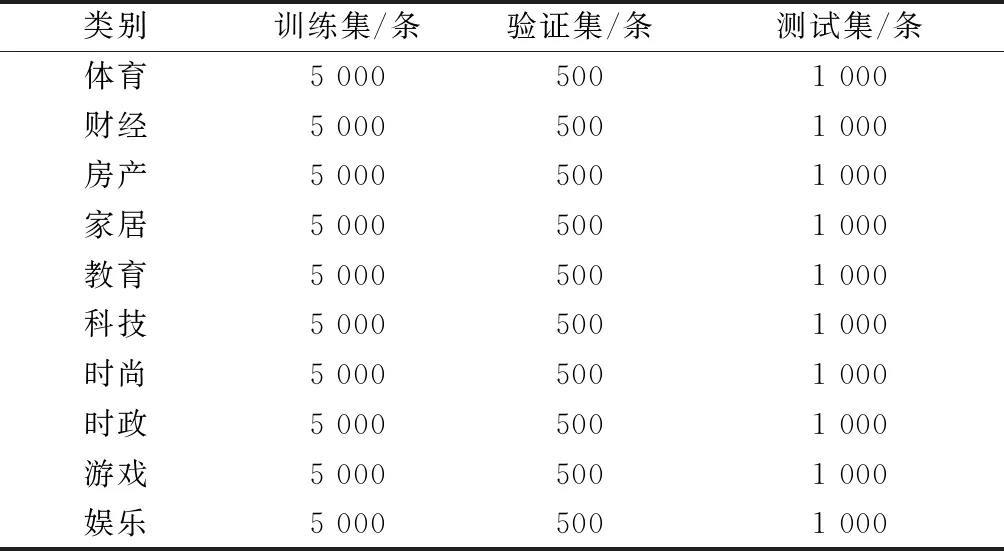
表9 测试所用数据集分布
4.1.3 评价指标
在自动标注场景中,主要通过实际效果进行可行性验证;在中文字符级向量表示场景中,引入以下指标对分类效果进行评价。
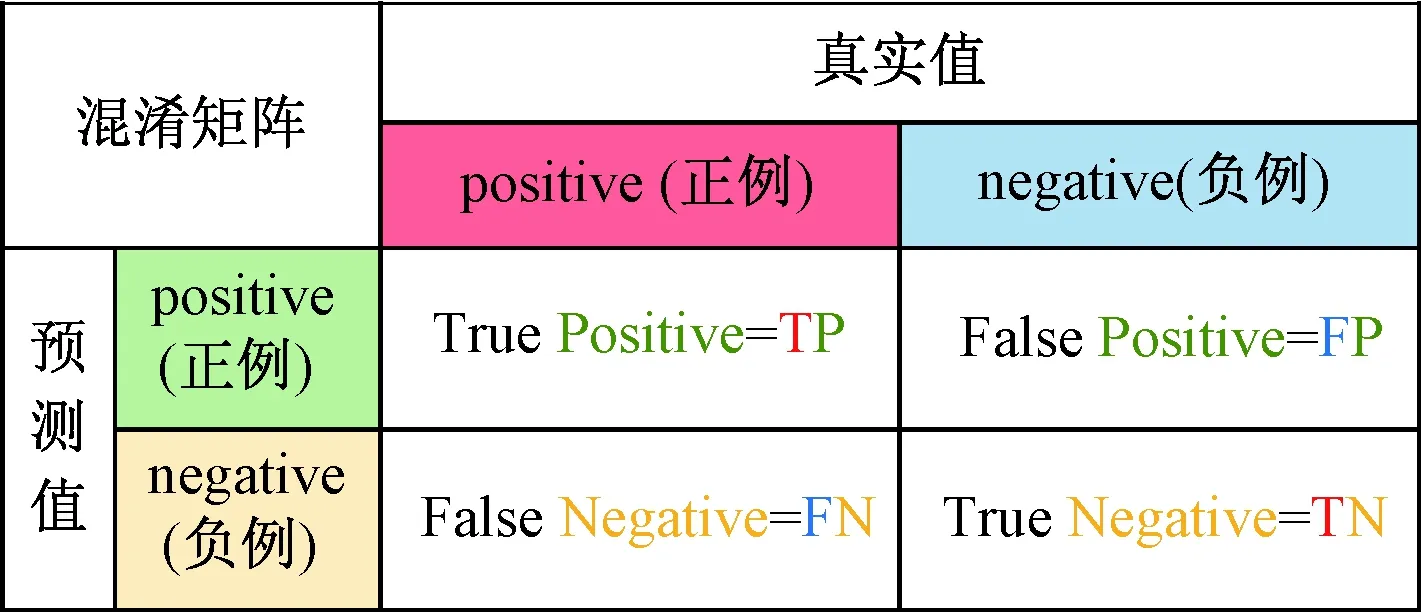
图9 二分类情况下混淆矩阵示意图Fig.9 Confusion matrix diagram in binary classification
(1)混淆矩阵(confusion matrix)。也称误差矩阵,经常用来对机器学习算法的可视化评估,以大小为n×n的方阵形式对分类结果进行展现,其中n表示类的数量。矩阵的每一行代表实际类中的实例,而每列代表预测类中的实例(行列也可互换)。如图9所示,在二分类情况下,绿色代表模型预测为正例的情况,黄色代表模型预测为负例的情况。TP表示预测为正例,实际也为正例,FP表示预测为正例而实际为负例,FN表示预测为负例而实际为正例,TN表示预测为负例而实际也为负例。
(2)召回率(R)。也称查全率,指所有实际是正例的有多少被正确预测为正例,其公式为
R=TP/(TP+FN)
(1)
(3)精准率(P)。也称查准率,即预测对的正例数占预测为正例总数的比率,其公式为
P=TP/(TP+FP)
(2)
(4)准确率(Acc)。反映分类器对整个样本的预测能力,能将正的预测为正,负的预测为负,计算公式为
Acc=(TP+TN)/(TP+FP+TN+FN)
(3)
(5)F1值。精准率与召回率的加权调和平均数,公式为
F1=2PR/(P+R)
(4)
4.2 XQMA模型的实现
4.2.1 主体框架
模型主体功能框架如图10所示。
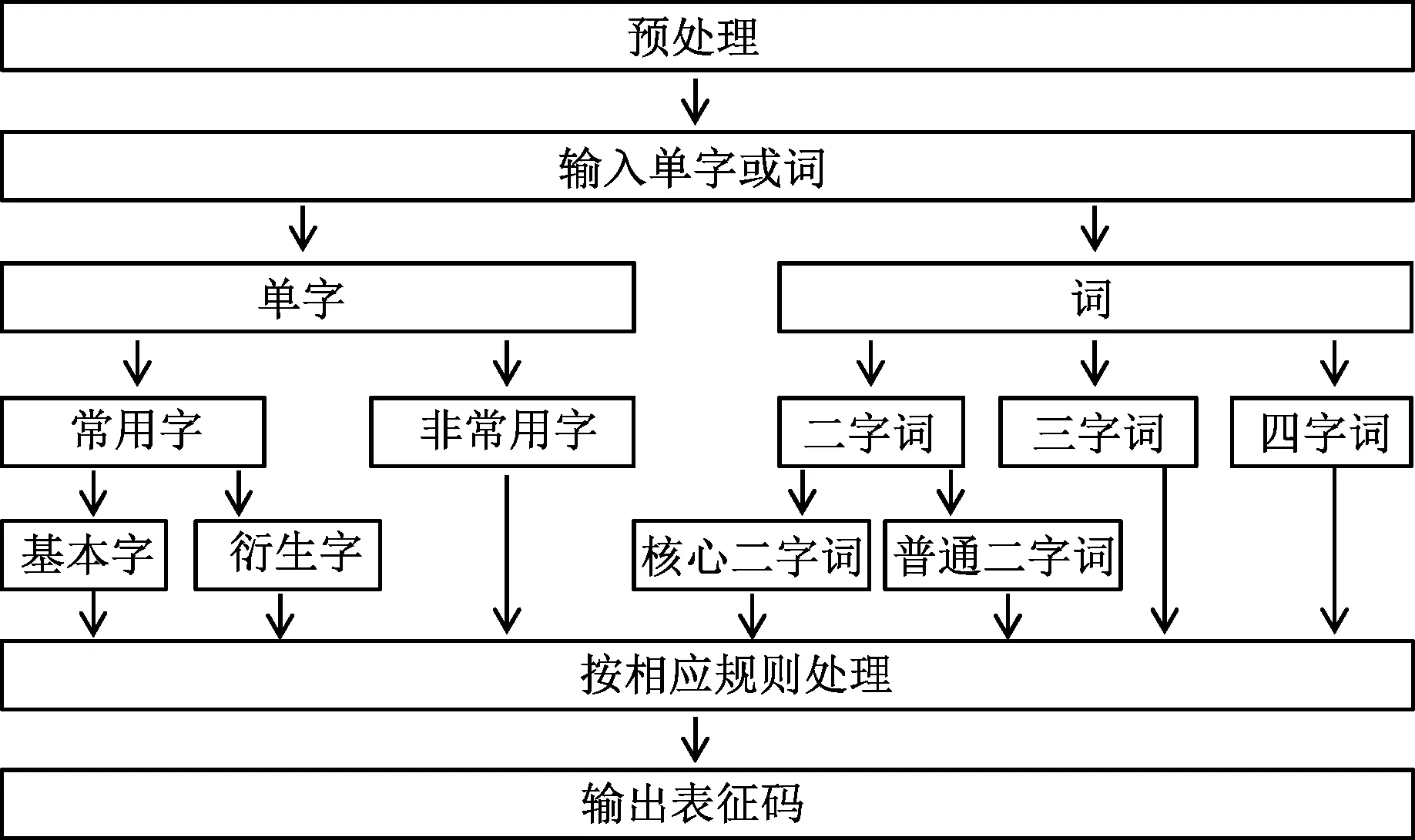
图10 相码模型主体功能框架Fig.10 The main function framework of XQMA model
4.2.2 单字表征关键代码
对《信息技术中文编码字符集》(GB18030—2005)中规定的7 000个常用汉字,可按基本字、衍生字分别处理,算法可用伪代码描述如下。
(1) if 汉字 ∈ 基本字:
(2) 若 为 特高频字or 特殊字 or 偏旁字:
(3) 分别用C1、oC1、aC1的形式表示
(4) 若 适用主备韵原则:
(5) 依起笔确定音节使用主韵或备韵
(6) 分别用aC1C2、C1C2、C1C2a、C1C2o表示1234声
(7) 若 有重码:
(8) C1C2ox、C1C2oy、C1C2oz、C1C2od表示1234声
(9) 若 仍有重码: //在第4码位使用笔画识别码
(10) 若 声调为1、2声: 用C1C2oC3表示
(11) 否则 用C1C2iC3表示
(12)else: //汉字 ∈ 衍生字
(13) 用形如C1C2C3的编码表示 //C3为偏旁归类码
(14) 依起笔确定音节C1C2使用主韵或备韵
(15) 若 有重码: //在第4码位使用笔画识别码
(16) 用形如C1C2C3C4的编码表示
4.2.3 词表征关键代码
对4字词以上的汉字词,需先进行拆分;4字词以下的词,可按长度分别处理,其过程可用伪代码描述如下。
(1) if 词∈二字词:
(2) 若 为 核心二字词:
(3) 用C1C2C3C4的形式表示
(4) 否则 在第5码位引入声调识别码
(5) 用C1C2C3C4C5的形式表示
(6) 若 仍有重码://在第6码位引入补充排序码
(7) 用C1C2C3C4C5C6的形式表示
(8) elif词∈三字词://在8,9码位引入声调识别码
(9) 用形如C1C2C3C4C5C6aC7C8的编码表示
(10)elif词∈四字词://在10,11码位引入声调识别码
(11) 用形如C1C2C3C4C5C6C7C8aC9C10的编码表示
(12)else //词不在既有词库中
(13) 拆分为单字组合或字词组合,分别处理
(14) 将编码用5连接,用形如C1C2C35C1C2C3的形式表示
4.2.4 基于相码的中文文本转换
利用XQMA模型得到的编码具有唯一性,所以可对中文文本自动完成可逆变换。在深度学习中,可将中文文本转换为一种类似英文的字母序列,减少或降低学习模型的转换成本。这种可逆转换有两种形式,一种为单字直接映射,可通过查找码表的方式直接转换,对码表中未能覆盖的单字,将其Unicode编码值逐字节映射为相应的补充排序码,并以所生成的编码代替该字;另一种为字词混合映射,需要先借助jieba等分词工具对文本进行分词,然后利用查表方式进行转换,对既有词库未能覆盖的分词,拆分为单字处理。其过程可用伪代码描述如下。
(1) 读入需转换的文本
(2) if 以单字直接转换:
(3) 若 单字 in 单字码表: 直接转换为相应相码
(4) 否则 得到该字的Unicode编码uc
(5) 将uc逐字节映射为相应的补充排序码得到xc
(6) 将字母a与xc拼接得到最终编码
(7) 循环执行(3)~(6),直至转换完成
(8) else: //字词混合转换
(9) 将文本分词,得到词序列
(10) 若词 in 字词码表:
(11) 直接转换为相应相码
(12) 否则 拆分为单字
(13) 按单字编码
(14) 循环执行(10)~(13),直至转换完成
4.3 模型验证及结果分析
4.3.1 同音单字的独立无歧义表示
这里引用著名语言学家赵元任先生写的同音字奇文《施氏食狮史》《季姬击鸡记》来测试模型的同音字区分效果。结果表明,XQMA模型能兼顾可读性与单字无歧义表达两个需求。图11为模型对《施氏食狮史》自动标注后的效果截图。
按照图7的构造思路,并将第四码元的位序值大小与三维图中代表汉字的小球体积相对应,则与“狮”“季”相对应的同音字在编码空间中的分布可用图12表示。

图11 同音字区分及自动标注效果图Fig.11 Result of homophone distinction and automatic annotation
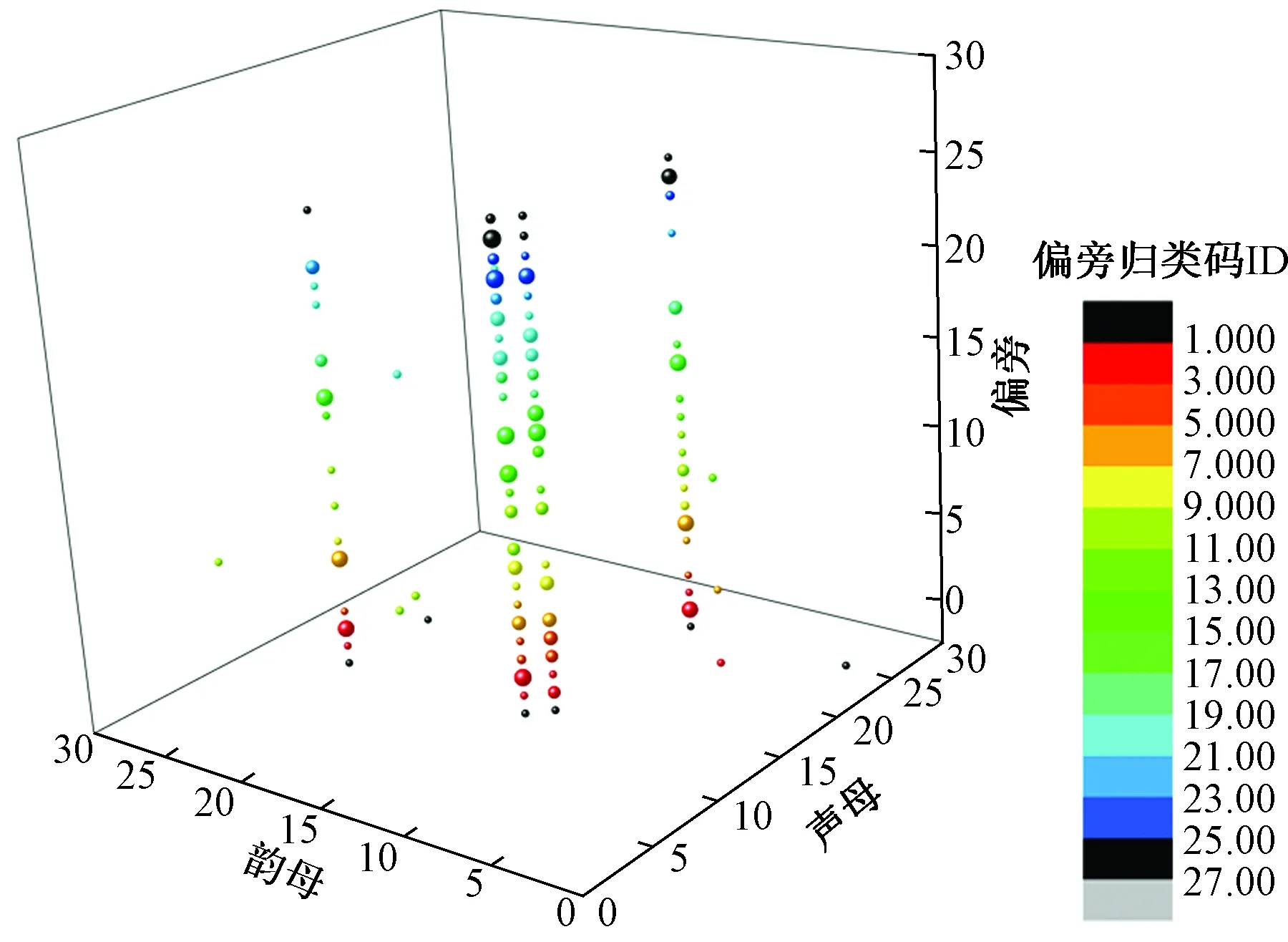
图12 狮、季所在音节同音字在编码空间的分布Fig.12 Distribution of homophones of ui and ji in codes space
4.3.2 同音字、词的编码性能分析
单字编码时,对《信息交换用汉字编码字符集 基本集》(GB 2312—1980)中规定的汉字,模型能在4码范围内实现单字的唯一编码,以上字符集未能覆盖的汉字,模型可在5码范围内实现唯一编码,词组编码时,利用jieba分词对“新闻语料(news2016zh)”和“维基百科(wiki2019zh)”两个语料库统计得到的词条,可得到如表10所示的结果,实验表明,相对传统拼音方案,模型的无歧义表征优势较为明显。
按照图12的构造思路,《信息交换用汉字编码字符集 基本集》(GB 2312—1980)中6 763个汉字的分布规律可用图13表示,结果表明,模型能在4码空间内实现常用汉字单字(uni-word)的唯一描述,编码分布相对均衡。
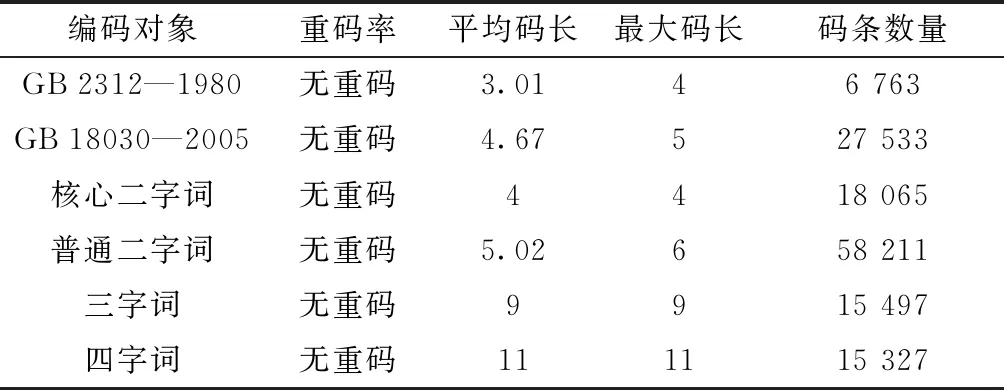
表10 相码模型编码性能分析
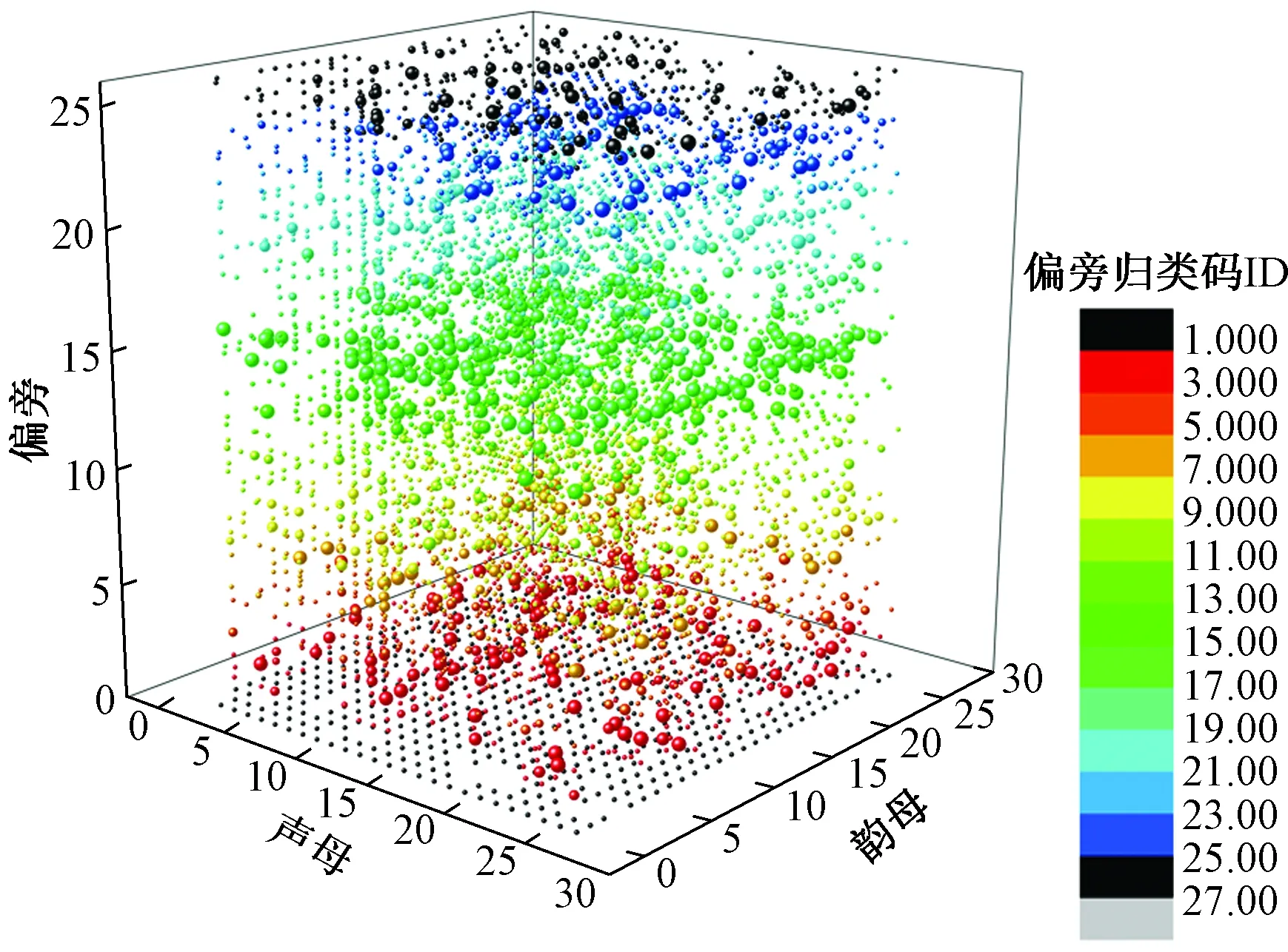
图13 常用汉字在4码长编码空间的分布Fig.13 Distribution of common uni-words in 4-code space
参照图12的构造思路,若分别以前后单字音节、声调识别码为坐标,将补充排序码的值与表示词的小球体积相对应,则表10中所列二字词(bi-word)在6码长编码空间的分布如图14所示。
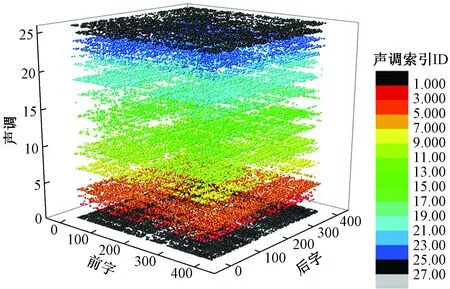
图14 常用二字词在编码空间的分布Fig.14 Distribution of common bi-words in coding space

图15 对法律文本的自动标注效果图Fig.15 Result of automatic annotation of legal text
4.3.3 法律类文本以词为最小单元的自动标注
现代汉语中,法律文本对编码的无歧义表示需求更明显,为进一步检验模型的有效性,特选取“刑法修正案(九)”进行测试,其标注效果如图15所示。
考虑到现代汉语以词为最小表示单元,并以二字词占比最大,单字词和三、四字词次之,而模型只针对词频居前的二、三、四字词构建基本词库,进行了固定编码,对基本词库未覆盖的词,可将其进行拆分后分别编码,然后将各编码用数字“5”进行连接,连接后得到的编码即为该词的编码,其标注效果如图15所示。
从标注效果看,XQMA模型生成的表征码长度合理,比拼音携带更多的音形信息,符合用户的日常识记习惯,可为中文自动标注、盲文汉字表示、程序代码中实现类汉字标识符提供一种新途径。
4.3.4 相码用于中文字符级向量表示
在自然语言处理场景中,相码可提供一种类似于英文的中文转换码,为检验其转换后的实用价值,参照文献[33]的方法,利用改造后的字符级TextCNN模型进行新闻文本分类测试,采用一维卷积、一个卷积层、一个全连接层的主体结构,模型参数设置如表11所示。
与原作中的方法不同,本文模型不直接将汉字作字符级embedding,而是首先将数据集按不同编码方式转换为相应的字符序列码形成新数据集,此时可得到较小的词汇表,之后按新词汇表对每一字符作字符级embedding,然后输入TextCNN进行分类训练。实验分别测试了采用相码、拼音、五笔、unicode编码直接视为字符串等转换方式下的分类效果,并在转换时细分为按单字逐字编码(单字编码)和先分词再编码(字词混合编码)两种场景。实验结果如表12所示。
从实验结果看,unicode转换方式分类效果不如其他方式,反映出该转换方式丢失的信息较多。拼音编码方式分类效果弱于五笔编码方式,这与拼音方式下同音字、同音词重码较多有关。相码编码方式在实验中表现较好,准确率分别达到了96.76%和96.78%,其他评估指标也表现良好,在精准率、召回率、F1值上与原作中结果基本相当,个别结果略好。图16和图17分别展示了采用相码单字编码时的训练过程和测试结果。
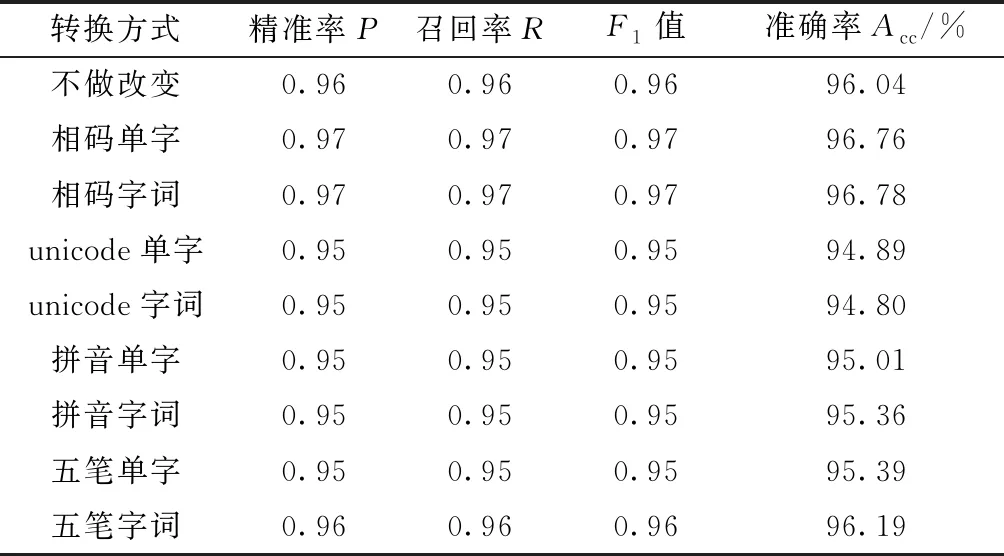
表12 不同编码方式下文本分类结果对比
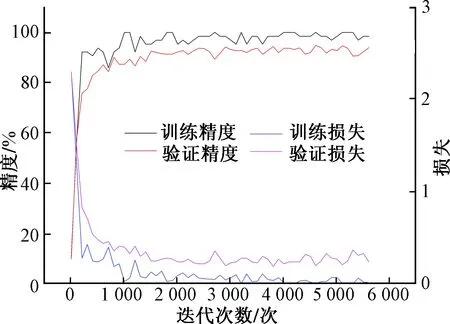
图16 采用相码单字编码的训练过程Fig.16 The training process when using xqma uni-word coding
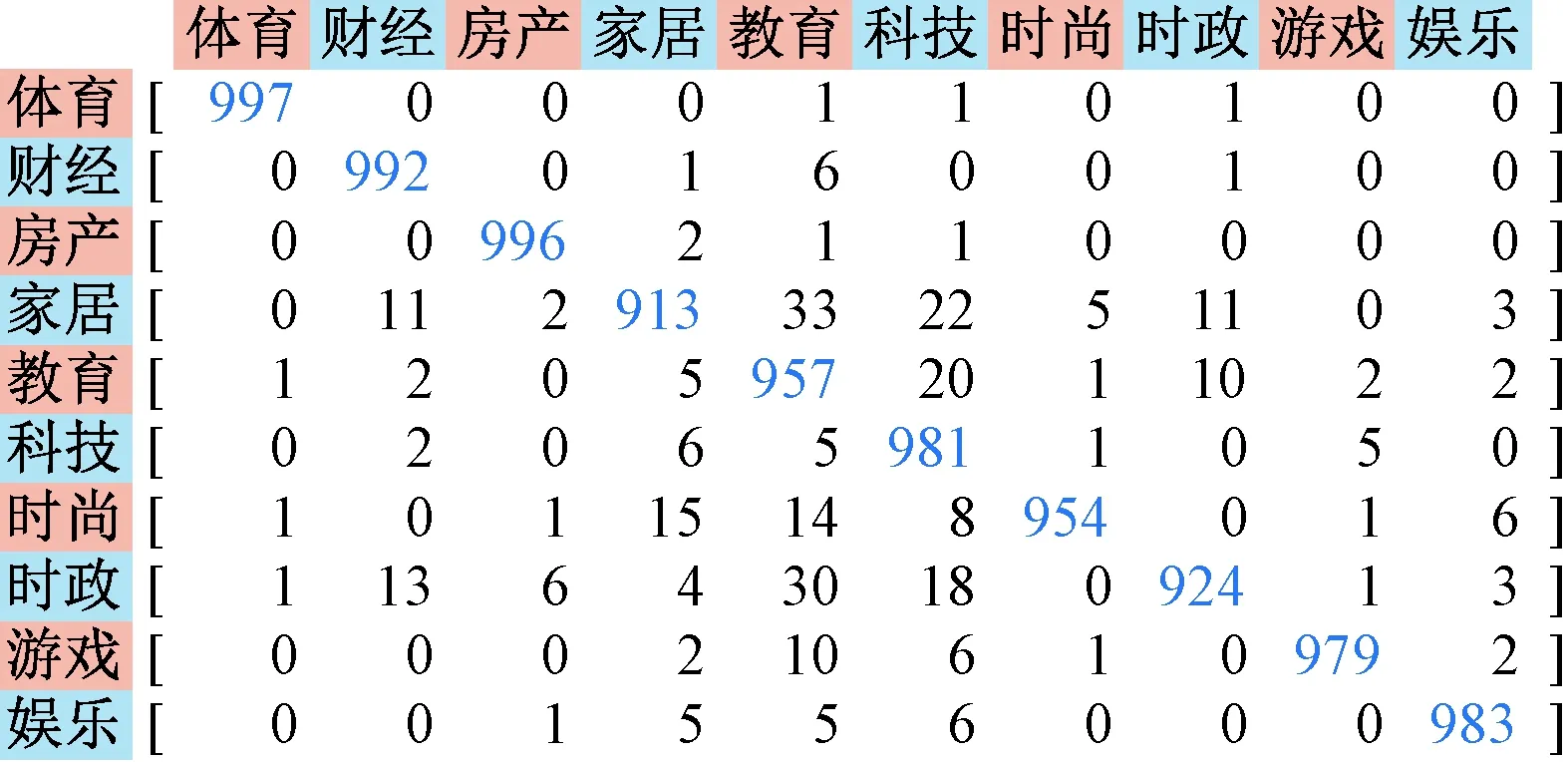
图17 采用相码单字编码时的混淆矩阵Fig.17 Confusion matrix when using xqma uni-word encoding
从验证效果看,XQMA模型得到的汉字编码确实能提供一种新的字符级中文向量表示方式,可有效解决OOV问题,具有一定的实用价值。在本例中,考虑到新闻文本中存在不少标点、数字等非汉字字符,所以卷积模型中的词汇表由系统自动按统计频率取前128个字符形成,未人为指定。若测试对象为纯汉字文本,则可直接将词汇表限定为26个字母。
5 结论
针对字符级语言模型的细粒度汉字表征需求,提出了跨象限助记符映射(XQMA)模型。模型有效融合了汉字的多种特征,可实现中文文本的预编码,为汉字细粒度表征提供了一种新方法,实验结果表明,该模型在TextCNN文本分类任务上表现良好,同时,模型可实现中文语料的批量可逆转码和唯一标注,存在较为广阔的应用前景。
虽然初步验证了相码编码在中文文本字符级向量的有效性,但并未在机器翻译、命名实体识别等相关模型上进行测试,后续研究中还需逐步进行验证,同时,可考虑将相码模型与其他中文字符级语言模型相融合,使模型有更好表现。
