An Effective Cloud Workflow Scheduling Approach Combining PSO and Idle Time Slot-Aware Rules
2021-04-13YunWangandXingquanZuoSeniorMemberIEEE
Yun Wang and Xingquan Zuo, Senior Member, IEEE
Abstract—Workflow scheduling is a key issue and remains a challenging problem in cloud computing. Faced with the large number of virtual machine (VM) types offered by cloud providers, cloud users need to choose the most appropriate VM type for each task. Multiple task scheduling sequences exist in a workflow application. Different task scheduling sequences have a significant impact on the scheduling performance. It is not easy to determine the most appropriate set of VM types for tasks and the best task scheduling sequence. Besides, the idle time slots on VM instances should be used fully to increase resources’ utilization and save the execution cost of a workflow. This paper considers these three aspects simultaneously and proposes a cloud workflow scheduling approach which combines particle swarm optimization (PSO) and idle time slot-aware rules, to minimize the execution cost of a workflow application under a deadline constraint. A new particle encoding is devised to represent the VM type required by each task and the scheduling sequence of tasks. An idle time slot-aware decoding procedure is proposed to decode a particle into a scheduling solution. To handle tasks’invalid priorities caused by the randomness of PSO, a repair method is used to repair those priorities to produce valid task scheduling sequences. The proposed approach is compared with state-of-the-art cloud workflow scheduling algorithms.Experiments show that the proposed approach outperforms the comparative algorithms in terms of both of the execution cost and the success rate in meeting the deadline.
I. INTRODUCTION
IN scientific computing communities, such as astronomy,physics, and bioinformatics, there are many large-scale and complex workflow applications consisting of tasks with data dependencies amongst them [1]. Those applications must be deployed in high-performance distributed computing environments for rapid execution. Cloud computing [2] offers cloud users elastic resources that can be acquired and released on demand. Cloud users pay for the leased resources on a payas-you-go basis. Such flexible resource provisioning and payas-you-go strategy attract enterprises or research institutes to run their workflow applications on clouds at low costs without the need of purchasing and maintaining any infrastructure.
In cloud computing, IT resources are often encapsulated as virtual machines (VMs). The running VMs are called VM instances. Cloud users usually want to obtain the computation result of a workflow within a given deadline at lower execution cost. Generally, the more computing power a VM has, the higher its price. To balance the execution cost and runtime of a workflow, scheduling the tasks of a workflow onto VM instances [3] is very vital for cloud computing.However, the flexible management of cloud resources and the complex workflow structure makes the cloud workflow scheduling challenging.
Cloud providers offer various VM types with different configurations (e.g., CPU, memory and disk size, and price)for users to choose. The number of VM types has been increasing. For example, the number of VM types provided by Amazon elastic computing cloud (Amazon EC2) has been recently increased from 8 to more than 35 [4]. Faced with so many VM types, scheduling algorithms need to choose the most appropriate VM type for each task to achieve the lowest cost for the whole workflow. However, when choosing a VM type for a task, current scheduling algorithms typically only consider the VM type that has the cheapest price and can meet the resources needed to complete the task, while ignoring the impact of the chosen VM type on other subsequent tasks. This manner of choosing VM type may encourage subsequent tasks to be scheduled on faster VM instances, thereby increasing the cost of a workflow [5].
Scheduling algorithms usually assign each task in the order of a task scheduling sequence to a VM instance. The task scheduling sequence has a significant impact on the execution time and cost of a workflow application [6]. For a workflow application, although precedence constraints exist for many tasks, there are many parallel tasks which do not directly have data dependencies with each other. On the premise of keeping the dependencies of tasks, the scheduling order of parallel tasks can be arbitrary. Thus, a workflow application may have lots of different task scheduling sequences. Moreover, the complex workflow structure makes a workflow have an exponential number of different task scheduling sequences.However, usually only a fixed task scheduling sequence is used in current scheduling algorithms, which restricts the search space for obtaining a better solution. It is necessary to determine the most appropriate task scheduling sequence to achieve a scheduling solution with better performance.
In addition, due to the precedence constraint amongst workflow tasks, idle time slots exist on VM instances. The more idle time slots a VM instance has, the lower its utilization is. Moreover, the billing interval for VM instances is usually set to one hour or one minute by cloud providers,such as Amazon EC2 and Google compute engine cloud. That means even if a VM instance is used for less than one billing period (e.g., one hour), users must pay for the whole hour. If a VM instance has an idle time slot between two running tasks and another task can be run within the slot, scheduling the task to that slot will save cost. It is vital to consider the scheduling of tasks to the idle time slots of VM instances to reduce the workflow’s cost and improve VMs’ utilization.
In this paper, we propose a new scheduling approach for the deadline constrained cloud workflow scheduling problem,with simultaneous consideration of aforementioned three aspects. This approach, termed HPSO, combines PSO and idle time slots-aware scheduling rules. To be specific, the VM type required by each task and the priority of each task are indicated by a particle in PSO. It means that a particle represents a specific mapping of tasks to VM types and a scheduling sequence of tasks. Idle time slot-aware scheduling rules are proposed to decode a particle into a scheduling solution. Those rules assign each task to a leased VM instance or to a new instance, making full use of idle time slots of VMs.
The contributions of this paper include:
1) A new approach for cloud workflow scheduling is proposed, which combines a meta-heuristic (PSO) and heuristic rules (idle time slot-aware scheduling rules).
2) A particle coding scheme is proposed, which represents the assignment of VM types and scheduling sequences for all tasks in workflow.
3) A PSO is devised to find the best particle, that is, the most appropriate assignment of VM types for tasks and the best task scheduling sequence, to achieve the best scheduling performance. To avoid infeasible solutions during the search of PSO, a repair method is devised to repair tasks’ invalid priorities to generate a valid task scheduling sequence.
4) Idle time slot-aware scheduling rules are devised to decode a particle into a scheduling solution. The decoding procedure makes full use of idle time slots of leased VM instances to improve VMs’ utilization and minimize costs.
The remainder of this paper is organized as follows. Section II outlines current cloud workflow scheduling algorithms.Section III introduces the model and the basic elements of the scheduling problem. Section IV presents the details of the proposed approach. Experimental results are described and discussed in Section V. Finally, we conclude our work and give insight into future works in Section VI.
II. RELATED WORK
Cloud workflow scheduling is a well-known nondeterministic polynomial (NP)-complete problem [7]. An exact approach cannot find the optimal solution within acceptable computational time for large-scale problem instances.Therefore, current research typically adopts meta-heuristic or heuristic rules to solve this problem. The former uses metaheuristics, such as PSO, genetic algorithm (GA), and ant colony optimization (ACO) to find a near-optimal solution.The latter obtains an approximate solution to the problem quickly using scheduling rules. Compared with heuristic rules,meta-heuristics can find higher quality solutions as they explore solutions by a guided search but take longer runtime[8].
In current research, many quality of service (QoS) metrics such as cost, makespan [9]–[12], energy consumption[13]–[15], budget [16]–[18], and security [19], [20] are often regarded as optimization objectives or constraints of the problem. This section mainly reviews literature on the deadline constrained cloud workflow scheduling problem, as those are related to our work. Approaches in those literature can be divided into two parts: meta-heuristic based scheduling approaches [21]–[30] and heuristic rules based scheduling approaches [5], [31]–[36].
A. Meta-Heuristic Based Cloud Workflow Scheduling
Rodriguez and Buyya [21] adopted a PSO method (SPSO)to minimize the workflow execution cost while meeting deadline constraint, in which the effect of VM performance variation is considered. SPSO maps tasks onto VM instances by a particle and determines a scheduling solution without considering idle time slots of leased VM instances. The number of VM instances needs to be predetermined. In [22], a GA-based approach was proposed for the cloud workflow scheduling with deadline constraint, where an adaptive penalty function is used for the strict constraints and the coevolution approach is used to adjust the crossover and mutation probabilities. Chen et al. [23] used dynamic objective strategy and proposed a dynamic objective GA approach to solve the cloud workflow scheduling with deadline constraint. Chen et al. [24] further developed an ACO-based approach to solve the same problem in [23].Considering the uncertainty of the runtime of tasks, Jia et al.[25] designed a new estimation model of the tasks’ runtime based on historical data. On this basis, an adaptive ACO based cloud workflow scheduling algorithm was proposed. In addition to PSO, GA and ACO, other meta-heuristics, such as flog leaping [26] and biogeography-based optimizations [27]have been applied to workflow scheduling problems.
In those meta-heuristics, the coding of scheduling solution usually represents the mapping of tasks to a set of VM instances. However, due to the infinite number of VM instances in clouds, a limited number of VM instances must be predetermined. But, it is not easy to predetermine an appropriate set of instances. Moreover, those algorithms usually only use a single task scheduling sequence while ignoring the impact of different task scheduling sequences on the cloud workflow scheduling performance.
Zuo et al. [28] proposed a self-adaptive learning PSO-based scheduling approach by considering multiple different task scheduling sequences. However, the algorithm was used for the scheduling of independent tasks on hybrid cloud, and not for the workflow application. Wu et al. [29] proposed a metaheuristic algorithm (LACO) and employed ACO to carry out deadline-constrained cost optimization. In LACO, different task scheduling sequences are constructed by different ant individuals. But the idle time slots on leased resources are not exploited adequately, and the method of determining the VM type required by each task is different from ours.
In addition, Yuan et al. [30] considered the uncertainty of arriving tasks and deemed that the energy price of private cloud data center (CDC) and the execution price of public clouds have the temporal diversity. A hybrid scheduling algorithm combining PSO and simulated annealing method(TTSA) is proposed to solve them. TTSA is used to schedule parallel tasks; not workflow tasks with data dependencies.Moreover, TTSA is to schedule all parallel tasks from a private CDC perspective, and our work is to schedule one workflow application from the cloud users’ perspective.Finally, the optimization objective of TTSA is to minimize the cost for private CDC, including the energy cost of private CDC and the execution cost generated by outsourcing tasks to public clouds, whereas ours is to minimize the cost of executing a workflow on a public cloud.
B. Heuristic Rules Based Cloud Workflow Scheduling
Heterogeneous earliest finish time (HEFT) [31] is one of the most widely used heuristic scheduling rules. It is first used to construct a task scheduling sequence based on tasks’priorities, and then assigns each task in order of the scheduling sequence to a processor that can meet the users’needs, such as the earliest finish time. Although HEFT was originally proposed for workflow scheduling in a limited number of heterogeneous processors, many modified versions of HEFT have been proposed for cloud workflow scheduling[16], [37], [38].
Abrishami et al. [32] introduced the concept of partial critical path (PCP) and proposed two algorithms, which are called IaaS cloud partial critical paths (ICPCP) and IaaS cloud partial critical paths with deadline distribution (ICPCPD2),respectively. ICPCP tries to minimize the execution cost of a workflow by scheduling a PCP path on a cheapest VM instance, which can finish all the tasks of the PCP before their latest finish time. Sahni and Vidgarthi [5] proposed a just-intime scheduling algorithm (JIT) while taking into account the VM performance variability and instance acquisition.Arabnejad et al. [33] proposed two algorithms, proportional deadline constrained (PDC) and deadline constrained critical path (DCCP), for the deadline-based workflow scheduling on dynamically provisioned cloud resources. In the aforementioned algorithms, the VM type for each task is usually chosen by heuristic information (such as the cheapest VM). Moreover, only the remaining time of the last time interval of leased instances is typically used while ignoring the availability of other idle time slots. Our approach selects the best VM type for each task by a PSO and considers the effective use of all idle time slots.
Recently, some studies [34]–[36] considered the efficient use of idle time slots to improve the performance of workflow scheduling. To mitigate the effect of performance variation of resources on soft deadlines of workflow applications,Calheiros and Buyya [34] used the idle time slots of leased resources and budget surplus to replicate task so as to meet the deadline constraint. The minimization of the execution cost of a workflow is not considered in their work. By considering realistic factors such as software setup time and data transfer time, Li and Cai [35] proposed a multi-rules based heuristic to solve the deadline-based workflow scheduling. Furthermore,three priority rules are developed to allocate tasks to appropriate available time slots. The heuristics for scheduling workflow tasks are based on reserved resources in clouds.How to determine the best task scheduling sequence was not considered.
To our knowledge, our work is the first study considering the following three aspects simultaneously: selecting the most appropriate VM type for each task, determining the best task scheduling sequence, and effectively using idle time slots. A PSO combined with idle time slot-aware rules is proposed to solve those aspects, to minimize the execution cost of a workflow while meeting the deadline constraint.
III. CLOUD WORKFLOw SCHEDULING PROBLEM AND FORMULATION
A. Workflow Model
A workflow is usually represented by a directed acyclic graph (DAG) consisting of vertexes and edges [39]. A DAG is formulated as a tuple G =
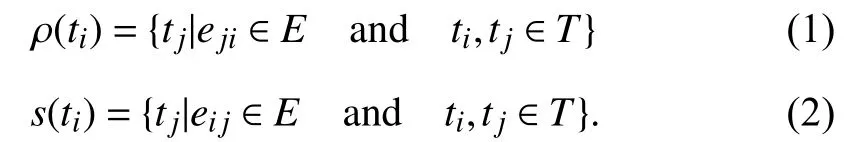
In DAG, a task without any parent is an entry task tentry.Similarly, a task without any children is called an exit task texit. There may be multiple entry tasks and exit tasks in a DAG. Fig.1 shows an example workflow with 5 tasks, where t1is the entry task and t5is the exit task.
B. Cloud Resource Model

Fig. 1. An example workflow with 5 tasks.
The cloud model consists of a single data center and has various VM types. A set П = {π1, π2, …, πm} represents all VM types, and m is the number of VM types. In this paper, all VM types are assumed to have enough memory to execute a workflow and only the CPU and network bandwidth of each VM type are considered. The number of instances a user can rent from the cloud is unlimited.
This paper assumes that the CPU capacity represented by floating-point operation per second (FLOPS) is available either from a cloud provider or estimated by a performance estimation method [40]. The workload of a task tiis assumed to be known in advance. Therefore, the execution time of task tion VM instance λj, χ(ti, λj), is defined as follows:

where α(λj) represents the CPU capacity of λj, and w(ti) is the workload of ti.
All VM instances are in the same data center. The average network bandwidth β between instances is roughly the same.The data transfer time between tiand tj, γ(ti, tj), is defined as(4), where the amount of data transferred between the two tasks, μ(ti, tj), is known. Note that the transfer time between two tasks is 0 when they are executed on the same VM instance.
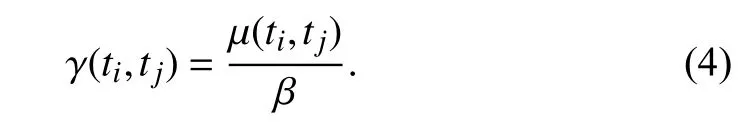
According to the pay-per-use strategy, all leased instances are charged for the number of used billing intervals. This paper assumes that the size of billing interval is one hour, just like the on-demand VM instances of Amazon EC2. The cost of data transfer is not considered because many commercial cloud providers do not charge the cost within a data center. In addition, we assume that the tasks of a workflow application cannot be preempted.
C. Basic Conceptions
This section introduces some basic concepts of workflow that are used in Section IV-D. The earliest start time of task tion one instance λj, EST(ti, λj), is determined by the finish time of all parents of ti. It means that all parents of timust be completed before executing ti. Besides, if tiis an entry task, its earliest start time on λjis 0. EST(ti, λj) is computed as follows:
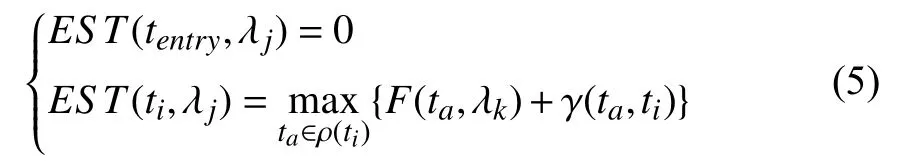
where F(ta, λk) is the actual finish time of taon instance λk, and tais a parent of tiand has been scheduled on λk. In order to utilize the idle time slots of instance λj, the calculation of EST(ti, λj) does not consider the final available time of λjin this paper. The actual start time of tion instance λj, S(ti, λj),must be greater than or equal its earliest start time.
The actual finish time of ti, F(ti, λj), equals the sum of S(ti,λj) and χ(ti, λj), and is computed as follows:

The latest finish time of ti, LFT(ti), is the latest time that tishould be finished to ensure a workflow will be finished before its deadline Δ.

where MET(tc) is the execution time of tcbased on the fastest VM, and tcis a child task of ti.
For more details about the above basic concepts of workflow, please refer to literature [31] and [39].
D. Cloud Scheduling Problem Description
This paper focuses on minimizing the cost of executing a workflow in clouds while meeting a deadline constraint. A scheduling solution is expressed as S = (R, M, Θ). R = {λ1,λ2, …, λl} is a set of l leased VM instances that will be used to execute tasks. Each VM instance in R has four attributes, that is, λi= (πi, Bi, Zi, Li), representing the VM type of VM instance λi, the lease start time and end time of λi, and tasks list scheduled on the instance, respectively. M = {m1, m2, …,mn} represents the mapping of tasks to instances in R. mi= (λj,S(ti), F(ti)) means that task tiis scheduled on the instance λjand is expected to start executing tiat time S(ti), and finish by time F(ti). The size of M is equal to the number of tasks n in the workflow, and the size of R is less than or equal to n. Θ is a task scheduling sequence and must follow the dependencies amongst tasks.
Based on S = (R, M, Θ), the execution cost Ψ and the execu tion time Ω of a workflow are calculated by the following formulas:

where Δ is the deadline of a workflow.
IV. PROPOSED APPROACH
PSO is a stochastic optimization algorithm which is inspired by the foraging behavior of bird flocks [41]. Because PSO has few parameters and is easy to implement, it has been widely applied to numerous fields, including production scheduling problems [42] and cloud resources scheduling [43], [44]. This paper uses PSO combined with idle time slot-aware rules to solve the workflow scheduling on clouds.
A. PSO for Cloud Workflow Scheduling

where inertia weight ω is used to balance the global and local search; r1and r2are uniform random numbers in [0, 1]; c1and c2are acceleration factors to control the influence of the social and cognitive components, and their values usually are set as 2 [41].
A pseudocode of PSO for the cloud workflow scheduling problem is described in Algorithm 1. It evolves iteratively a population of particles until the number of iterations is reached (lines 5–15) and then the scheduling solution of the global best particle is regarded as the final scheduling solution(line 16).
There are several issues to consider when using the PSO to solve the scheduling problem: the first is the encoding representation of a particle, which is elaborated in Section IV-B;the second is how to decode a particle into a scheduling solution (decoding procedure), which is shown in line 9 and detailed in Section IV-D; the third is to evaluate a particle by a fitness function, which reflects the optimization objectives. In this paper, the execution cost Ψ and the execution time Ω are calculated in the fitness function (in Section IV-E), and Ψ is used to evaluate a particle (line 10). The fourth issue is the population initialization that is described in Section IV-F; and the final issue is the treatment of the deadline constrain of the scheduling problem.
During the search of the PSO, some infeasible solutions that violate the deadline constraint may be generated. To handle those infeasible solutions, the constraint handing technique in[45] is introduced into the PSO. A solution is infeasible if it does not satisfy the deadline constraint. There are three cases for two solutions’ comparison: the solution with a better fitness value (execution cost) is better if the two solutions are both feasible; the feasible one is better if one solution is feasible and the other is unfeasible; the solution with the smaller execution time is better if both solutions are unfeasible. In lines 11 and 13, the historical best position of a particle and the global best particle are updated under the constraint-handing technique.
In addition, in line 1, the workflow is preprocessed to merge the “pipeline pair” tasks into a single task, which helps to reduce the runtime overhead of the scheduling algorithm and save the data transfer time between tasks [10]. The “pipeline pair” tasks refer to a special pair of tasks tiand tjwhich have a one to one relationship. That is, tionly has one child task tjand tjonly has one parent task ti.

Algorithm 1 PSO for Cloud Workflow Scheduling Input: The DAG of a workflow G =
B. Encoding Scheme
A key issue for PSO to solve a problem is to devise an effective particle encoding. Although VM instances in clouds are infinite, cloud providers provide a finite number of VM types. Inspired by this, the particle encoding only needs to consider the mapping of tasks to VM types (instead of VM instances). Besides, the priority of each task, which determines its scheduling order in all tasks, is encoded in the particle. A task scheduling sequence is obtained by sorting tasks’ priorities in ascending order. Therefore, a particle contains two parts: the first part (dimensions from 1 to n)embodies the mapping of tasks to VM types, and the second part (dimensions from n+1 to 2n) determines the priority for each task. The dimension of a particle D is equal to twice the number of workflow tasks. The value of each dimension in the first part falls within the real range of [1, m]. The values of the second part can be any positive real number.
Because PSO is for continuous optimization problems,whereas the workflow scheduling problem is a combinatorial one, the value of each dimension must be rounded to the nearest integer. Specifically, in the first part of a particle,dimensions from 1 to n correspond to tasks t1to tn,respectively. The rounded nearest integer of each dimension represents an index of VM type, which means the corresponding task is assigned to an instance with the same VM type. In the second part of a particle, the rounded nearest integer of dimension i∈[n+1,2n] represents the priority of task ti-n.
An example of an encoded particle for the workflow in Fig. 1 is shown in Fig. 2, where the number of VM types is assumed to be 4. In this example, dimension 1 corresponds to task t1and its value is 2.1. This means that the VM type required by t1is π2. The values of dimensions 2–5 follow the same logic.The values of dimensions 6–10 are rounded to 2, 9, 11, 3, and 14, indicating the priorities of t1–t5, respectively. Sorting those values in ascending order, the scheduling sequence of tasks is:t1-> t4-> t2-> t3-> t5.
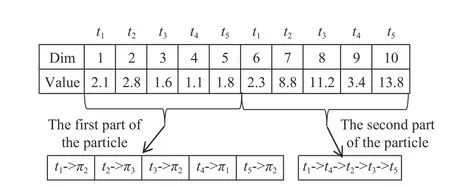
Fig. 2. A particle encoding for the workflow in Fig. 1.
By this encoding, different mapping combinations of tasks to VM types and different task scheduling sequences are represented by different particles. On this basis, an idle time slot-aware heuristic decoding procedure in Section IV-D can identify the VM instances to be leased and the scheduling of all tasks on those leased instances.
C. Repairing Method for Invalid Tasks ’s Priorities
A feasible task scheduling sequence must satisfy the data dependencies amongst tasks. However, those cannot be guaranteed during the iterative evolution because of the stochastic feature of PSOs. This paper sorts priorities of all tasks in ascending order to obtain a task scheduling sequence.This means the priority of each task must be greater than those of all its parents and cannot be the same as each other.Otherwise, the priority of the task is invalid.
A simple repairing method is designed to repair tasks’invalid priorities. Its main idea is to modify the invalid priority of a task to the maximum value of the priorities of all its parents plus 1, while ensuring that the modified priority is not equal to any other tasks’ priorities.
Algorithm 2 gives the detailed steps of the repairing procedure, where T is a set of workflow tasks, and set V is used to store those tasks with valid priorities and is initially set to be empty (line 2). The priority of an entry task tentrywith the minimum priority is deemed as valid (line 3). Based on this priority, lines 5–18 gradually judge whether the priorities of other tasks are valid. First, those tasks whose parents are in set V are selected from T and represented by set Q (line 6,).Then the following steps are to judge whether the priority of each task tjin Q is valid one by one (lines 8–17). If the priority of tj, η(j), is not bigger than the maximum priority value of all its parents, pmax, it is modified to pmax+ 1 (lines 10–12). Moreover, if the priority of tjis identical to that of one task in set V, it is modified to vmax+ 1 (lines 13–15), where vmaxis the maximum of the priorities of all tasks in set V (line 7).
Through this, the priority of each task is bigger than those of all its parents and all tasks have different priorities. Finally,once a task has a valid priority or the invalid priority of the task has been modified to a valid one, the task is added into V and removed from T (line 16).

Algorithm 2 Repair Invalid Priorities of Tasks.Input: A particle q and a set of tasks T ={t1, t2, …, tn}.Output: The repaired particle.1: η(1:n) = round (q(n+1:2n));∅2: V = ;3: Find an entry task tentry with the minimum priority;4: V = V∪{tentry}, and T = T{tentry};5: While (T is not empty)6: Find all tasks whose parents are in V, denoted by Q;7: vmax = max(priorities of tasks in V);8: For (each task tj in Q)9: pmax = max(priorities of tj’s parents);≤10: If η(j) pmax 11: η(j) = pmax+1;12: End if 13: If η(j) = = the priority of one task in V 14: η(j) = vmax +1;15: End if 16: V = V∪{tj}, and T = T{tj};17: End for 18: End while 19: q(n+1:2n) = η(1:n);20: Output the repaired particle;
D. Idle Time Slot-Aware Decoding Procedure
An idle time slot-aware decoding procedure is proposed to decode a particle into a scheduling solution. The decoding procedure makes full use of the idle time slots of leased VM instances to improve resource utilization and decrease execution cost of a workflow. Meanwhile, it can schedule tasks under their precedence constraints and tends to schedule them on the same VM instance to save the data transfer time between them.
Algorithm 3 presents the detailed steps. In line 1, R, M, and H are set as empty. Set H is used to store the applicable instances of a task tj. Herein, if a leased instance has one or more idle time slots that can be used to finish tjbefore tj’s latest finish time, LFT(tj), it is termed an applicable instance of tj. LFT(tj) is calculated by (7). Each task is scheduled in order of the scheduling sequence Θ to a leased instance in R or a new instance (lines 4–17). In line 5, the VM type πj, required by tjis obtained from the jth dimension of the particle. Then,serial and parallel instances with the same type πj, denoted by X and Y, respectively, are selected from R (line 6). For tj,serial instances refer to those instances that have one or more parents of tjscheduled, and parallel instances are those that do not schedule any one of tj’s parents. Note that the VM type of an instance on which a task is scheduled must be the same as that required by the task.
In order to save the data transfer time, those serial instances which are applicable to tjare first selected from X and recorded by H (line 7). If there is no applicable instance of tjin X, namely the set H is empty (line 8), continue to find parallel instances that applicable to tjin Y (line 9). Finally, if there is still no applicable instance can be used to schedule tjin Y (line 13), a new instance λnwith πjis launched for tj(line 14).
There may be multiple applicable instances in H. The instance λa, which has the smallest cost difference between its execution cost before scheduling tjand that after scheduling tj,is chosen to execute tjfrom H (lines 11–12). The execution cost of an instance is calculated by (8), where l = 1. Furthermore, if there are multiple instances with the same smallest cost difference in H, select one of those instances randomly for tj.

Algorithm 3 An Idle Time Slot-Aware Decoding Procedure.Input: A particle q (1:2n).Output: A scheduling solution S = (R, M, Θ).∅∅∅1: R = , M = , H = ;2: Repair tasks’ invalid priorities in the particle q by Algorithm 2;3: Get a feasible scheduling sequence Θ based on the particle q;4: For each task tj, j∈{1, 2, …, n} in Θ do 5: πj = q (j);6: Select serial and parallel instances with VM type πj from R,denoted as X and Y, respectively;7: Search the applicable instances of tj from X, and recorded them by H;8: If H is empty then 9: Continue to search the applicable instances of tj (also recorded by H) from Y;10: End if 11: If H is not empty then 12: Allocate tj to the instance λa∈H with the smallest cost difference;13: Else 14: Launch a new instance λn with πj for tj;15: End if 16: Update R and M;17: End for 18: Output S = (R, M, Θ).
All applicable instances of tjin X and Y (lines 7 and 9) are identified by an insertion-based policy. The length of an idle time slot is equal to the difference between the execution start time and finish time of two tasks that were consecutively scheduled on the same instance [31]. If an idle time slot between txand tkis available to tj, it means that S(tj) ≥ F(tx),F(tj) ≤ S(tk), and F(tj) ≤ LFT(tj). Note that scheduling a task on an idle time slot must satisfy its precedence constraints.Therefore, the insertion-based policy first calculates the EST(tj) of tjon an instance by (5), and then check all idle time slots on the instance to determine whether available time slots exists to execute tj.
There may be multiple idle time slots available for executing tjon an applicable instance, and tjis scheduled in the first time slot in chronological order. The S(tj) on an applicable instance is finally determined during checking the idle time slots by the insertion-based policy, and F(tj) is calculated by (6).
E. Fitness Function
In this paper, the total execution cost of a scheduling solution Si= (R, M, Θ) derived from a particle is used as the fitness value of the particle. The total execution time of Siis used to judge whether the particle is feasible. For example, if the total execution cost of a particle q1is less than that of another particle q2, it means q1is better than q2. If the total execution time of a particle is bigger than the deadline, the particle is unfeasible; otherwise, it is feasible.

Algorithm 4 Fitness Function.Input: A solution Si = (R, M, Θ) of a particle Output: The execution cost and time of a workflow, Ψ and Ω.1: Ψ is calculated by (8), based on the R of Si;2: Ω is computed by (9), according to the M of Si;3: Output Ψ and Ω;
In Algorithm 4, all leased instances are in R, and the mappings between tasks and leased instances are in M. The lease expenses of all leased instances are summed up as the total execution cost by (8), and the total execution time is computed by (9). Finally, output the total execution cost and time of Si= (R, M, Θ) (line 3).
F. Population Initialization
In order to generate N particles with valid task scheduling sequences, the upward and downward ranks of a task, which are usually used in the list-based scheduling algorithms, are adopted to compute tasks’ priority in the initial population.
The upward rank of a task tiis the critical path length from tito the exit task, including ti’s average execution time. The down rank of tiis the longest distance from the entry task to it,excluding the average execution time of ti. Please refer to [39]for the calculations of tasks’ upward and downward ranks.
In the initiation of population, two populations, Ο1and Ο2,are first generated randomly, and each population has N particles. For each particle in Ο1, the value of dimension i∈[n+1,2n] is set to the downward rank of task ti–n. Besides,because this paper obtains the task scheduling sequence by sorting tasks’ priorities in ascending order, the priority of each task in Ο2is set as σ–ru(ti), where σ represents the maximum value of all tasks’ upward ranks and ru(ti) is the upward rank of ti. Finally, N particles are selected as the initial population from Ο1and Ο2in ascending order of their fitness values.
V. PERFORMANCE EVALUATION
A. Experimental Settings
Pegasus project [46] publishes some synthetic workflows resembling those used by real world scientific applications,including Montage, Epigenomics, Sipht, CyberShake, and LIGO’s Inspiral Analysis (Inspiral). These workflows have different characteristics and have been widely used to evaluate workflow scheduling algorithms. The DAGs of the five workflows are illustrated in Fig. 3. Each workflow has four different task sizes: small (about 30 tasks), medium (about 50 tasks), large (about 100 tasks), and extra-large (about 1000 tasks). The details of each workflow, including its DAG structure, the size of data transferring amongst tasks, and the running time of each task, are stored in an XML file. The corresponding XML files are available from the web site1https://confluence.pegasus.isi.edu/display/pegasus/WorkflowHub.

Fig. 3. DAGs of five synthetic workflows.
We use these five workflows to evaluate the HPSO algorithm. For each workflow, eight different deadlines are used to evaluate the capability of HPSO to meet the deadline constraint. These deadlines are calculated based on the fastest and the slowest execution time of a workflow. The slowest execution time, ζ, is the execution time of a workflow whose tasks are all scheduled on the same VM instance with the cheapest VM type. The fastest execution time of a workflow,δ, is estimated by letting each task of the workflow be scheduled separately on a different VM instance with the fastest VM type. The data transmission time is ignored when computing the two time values ζ and δ.
Moreover, the slowest execution time of a workflow is usually two or even more orders of magnitude higher than the fastest one, and the difference between them depends on the structure of the workflow [25]. In order to reflect the capability of different algorithms to meet deadlines, an appropriate set of deadlines must be determined. By trial and error, eight deadlines of a workflow are computed by the following formula:
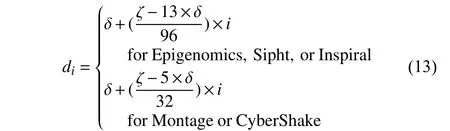
where the values of i are set as 1, 2, …, 8 to calculate eight different deadlines with d1being the tightest deadline and d8being the loosest one.
A cloud computing environment was simulated using CloudSim toolkit [47] to compare the performance of HPSO and other methods. This paper selects ten VM types with known number of computing unit (ECU) from Amazon EC2,as shown in Table I. Reference [40] shows that an ECU is roughly 4400 million floating point operations per second(MFLOPS). All VM instances are assumed to be in the same data center. The network bandwidth amongst VM instances is roughly equal and is set to 20 Mbps [32]. The billing period of all VM types is assumed to be one hour.
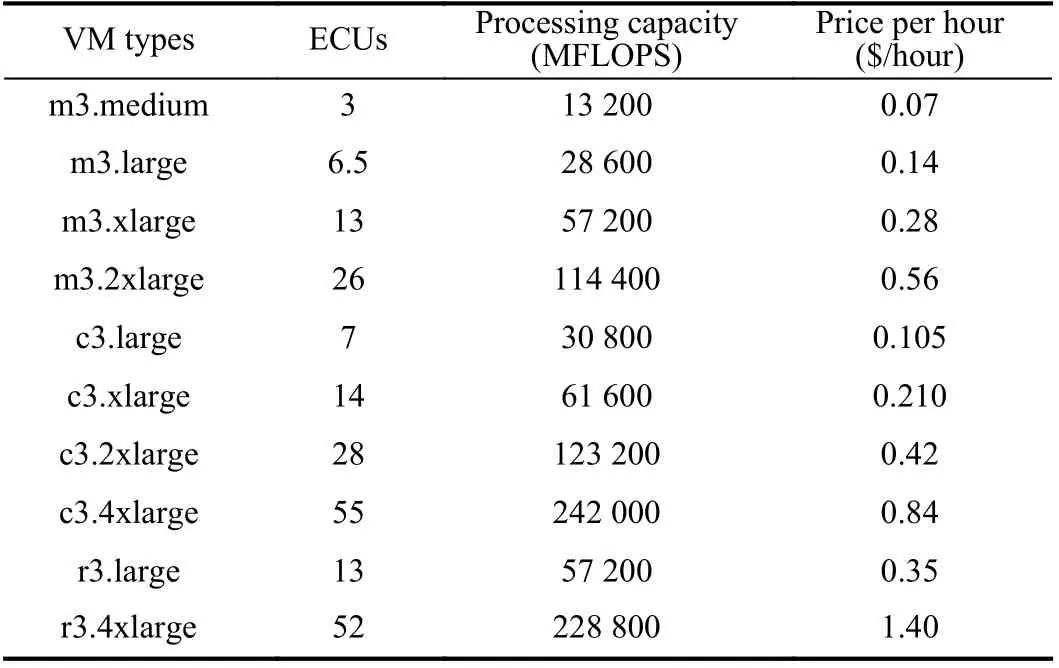
TABLE I VM TYPES BASED ON AMAzON EC2
B. Compared Algorithms
To verify the performance of HPSO, five state-of-the-art cloud workflow scheduling algorithms, namely PSO-based scheduling algorithm (SPSO) [21], GA-based scheduling algorithm (EMS-C) [9], ACO-based scheduling algorithm(LACO) [29], and two heuristic scheduling algorithms ICPCP[32] and JIT [5], are selected as comparative algorithms. In current literature on cloud workflow scheduling problems,those algorithms are often used as comparative algorithms.The scheduling problem solved by SPSO, LACO, ICPCP, and JIT is exactly the same as ours (minimizing the execution cost of a workflow while meeting its deadline constraint). EMS-C is a multi-objective optimization algorithm for minimizing the execution time and cost of a workflow simultaneously.
SPSO adopts the PSO to solve the deadline constraint and cost minimization problem, while considering fundamental features of the dynamic provisioning and heterogeneity of unlimited computing resources as well as VM performance variation. It maps tasks onto VM instances by a particle and determines a scheduling solution without considering idle time slots of leased VM instances. The number of VM instances needs to be predetermined.
ICPCP uses the concept of partial critical path (PCP). A PCP contains many tasks and is first scheduled on an already leased instance that can meet the latest finish time of the tasks.If no such instance exists for the path, a new instance with the cheapest VM type able to finish the tasks before their latest finish time is leased for the PCP.
JIT aims to exploit the advantage offered by cloud computing while considering the virtual machine (VM)performance variability and instance acquisition delay to identify a just-in-time schedule of a deadline constrained scientific workflow at lesser costs.
LACO employs ant colony optimization to carry out deadline-constrained cost optimization: the ant constructs an ordered task list according to the pheromone trail and probabilistic upward rank. The reason to choose LACO for comparison is that it considers different task scheduling sequences by using different ants and uses a simple heuristic method to decode an ant to a scheduling solution. However,LACO does not consider the selection of the best VM type for each task and the effective utilization of idle time slots of VM instances.
The reason to choose EMS-C for comparison is that it is based on GA. In EMS-C, the encoding of a chromosome includes the mapping of tasks to VM instances, the mapping of VM instances to VM types, and the scheduling order of each task. Because EMS-C is for multi-objective workflow scheduling, it is modified to fit the scheduling problem in this paper. The modified EMS-C (MEMS for short) keeps the single objective of minimizing the execution cost and adds deadline constraint. Like HPSO, MEMS uses the constraint handing technique in [45] to deal with infeasible solutions.Other operations (e.g., crossover and mutation) of MEMS are the same as those of original EMS-C.
C. Algorithm Parameter Discussions
HPSO does not contain any new parameter, except the parameters of PSO (inertia weight ω, acceleration factors c1and c2, population size N, and number of fitness function evaluations Κ). Those parameters are determined by the following two groups of experiments.
The first group experiment is to determine ω, c1and c2. In order to investigate how the three parameters affect the performance of HPSO, three different values are set for each parameter. For ω, its values are respectively set to 0.5,decreased linearly from 0.9 to 0.4 (0.9~0.4), and decreased linearly from 0.1 to 0.01 (0.1~0.01). The values of c1and c2are set to (2.0, 2.0), (2.0~0, 0~2.0), and (1.0~0, 0~1.0),respectively. Here, (2.0, 2.0) represents that the values of c1and c2are all set to be 2.0. (2.0~0, 0~2.0) denotes that c1decreases linearly from 2.0 to 0, whereas c2increases linearly from 0 to 2.0. The same logic is true for (1.0~0, 0~1.0). Table II shows the average execution costs of Montage-100 under the tightest deadline d1for different values of ω, c1and c2. Note that the experiment assumes that N is 20 and K is 1000, which are used to determine ω, c1and c2. In Table II, $2.40 is the lowest execution cost for Montage-100 under deadline d1.Therefore, parameters ω, c1and c2of HPSO are set as(0.1~0.01), (2.0~0), and (0~2.0), respectively.
The second group experiment is to determine the appropriate N and K, i.e., population size and the number of fitness function evaluations, to make a fair comparison of HPSO, LACO, SPSO, and MEMS. Table III shows the average execution costs of Montage-100 under deadline d1for different combinations of N and K.
Table III shows that with the increase of K and N, the execution cost values obtained by HPSO (SPSO, MEMS) are reduced from 2.4 (16.90, 23.02) to 1.79 (4.70, 11.79), and the cost values obtained by LACO fall within the range of [2.5.2.8]. Obviously, along with the increase of N and K, theexecution cost of SPSO and MEMS is improved, while the cost of HPSO and LACO does not change much.

TABLE II THE ExECUTION COSTS OF MONTAGE-100 FOR DIFFERENT INERTIA WEIGHTS AND ACCELERATION FACTORS
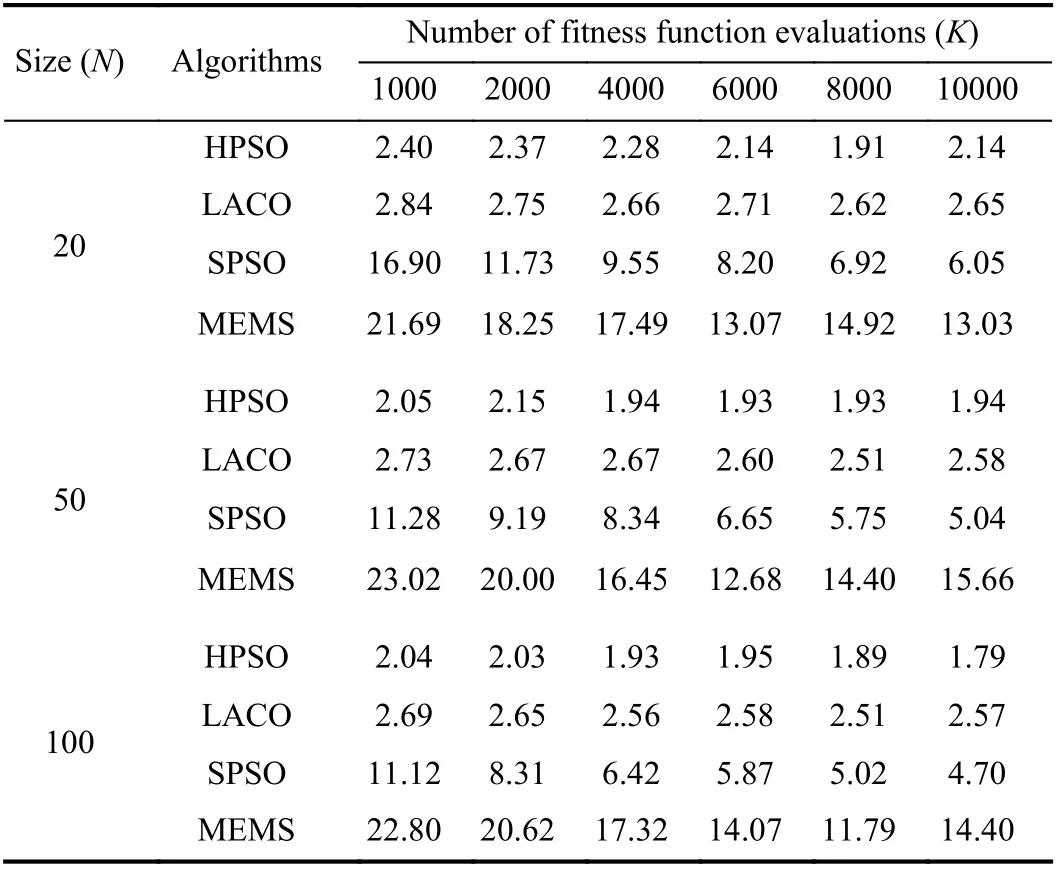
TABLE III THE ExECUTION COSTS OF THE MONTAGE-100 FOR DIFFERENT POPULATION SIzES AND NUMBER OF EVALUATIONS
If N and K are set too large, the four meta-heuristic based algorithms will consume too much time for extra-large and large workflows. Thus, the N value of the four algorithms is all set to 20. The K value of SPSO and MEMS is set to 10 000.As HPSO and LACO converge for almost all workflows when K is 1000 (see the third subsection of Section V-D), the K value of HPSO and LACO is all set to be 1000.
The SPSO [21], MEMS [9], and LACO [29] are all designed specifically for the cloud workflow scheduling problem, and in literature [9], [21] and [29], appropriate parameters are suggested. Therefore, other parameters of SPSO, MEMS, and LACO are taken from their literature: for SPSO, c1, c2, ω are set to 2, 2, 0.5, respectively; for MEMS,the probabilities of crossover and mutation are given by 1.0 and 1.0/n, respectively, and n is the number of workflow tasks; for LACO, the pheromone and the heuristic information are set to 1 and 2, respectively, and the pheromone evaporation coefficient is 0.2.
HPSO, SPSO, MEMS, and LACO perform 10 independent runs for each workflow application.
D. Results and Discussions
1) Deadline Constraint Evaluation
For a workflow with a deadline di, if the average execution time of the workflow scheduled by an algorithm is less than orequal to di, the algorithm meets the deadline constraint. This paper uses the success rate sr, which is the percentage of deadlines met by an algorithm among all deadlines, to evaluate the capability of an algorithm to meet the deadline of a workflow. The calculation of sris as follows [17]:
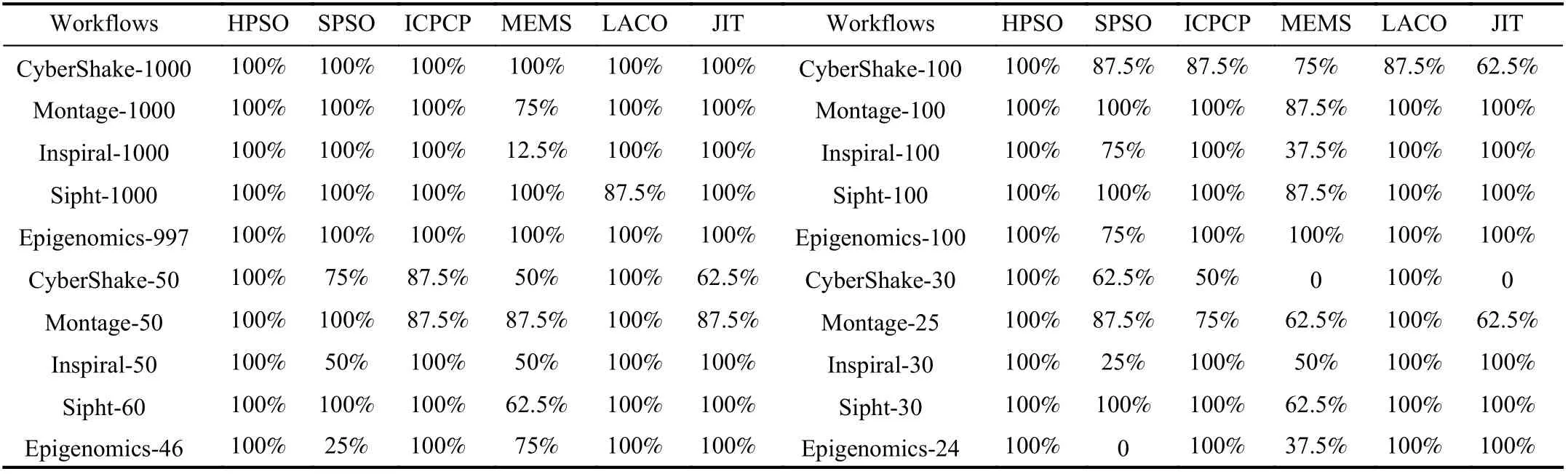
TABLE IV THE SUCCESS RATES OF SIx ALGORITHMS FOR ALL WORKFLOwS

where κ is the number of deadlines met by an algorithm, φ is the total number of deadlines. Table IV shows the success rate of each algorithm for each workflow.
The upper-left region of Table IV shows that HPSO, SPSO,ICPCP, and JIT have a 100% success rate for all extra-large workflows with about 1000 tasks, which means the eight deadlines of each extra-large workflow are met by them.LACO meets all deadlines of each extra-large workflow except Sipht-1000, for which the success rate of LACO is 87.5% because it fails to meet the tightest deadline d1. For MEMS, its success rates for Inspiral-1000 and Montage-1000 are 12.5% and 75%, respectively, and the success rates for the three other extra-large workflows are 100%.
For the large workflows with about 100 tasks, as shown in the upper-right region of Table IV, the deadlines of all large workflows are satisfied by HPSO. ICPCP, LACO, and JIT can meet all deadlines of large workflows except CyberShake-100, for which the success rates are 87.5%, 87.5% and 62.5%,respectively. SPSO has a 100% success rate only for Montage-100 and Sipht-100. Except Epigenomics-100,MEMS does not have a 100% success rate for other large workflows.
The lower-left and lower-right regions of Table IV show that for medium and small workflows, the performance differences in meeting deadlines amongst HPSO, LACO, and the four other algorithms are more obvious. HPSO and LACO can meet all deadlines of medium and small workflows,whereas the other algorithms perform less well in meeting deadlines as the size of a workflow decreases. Amongst small workflows, the success rates of MEMS and JIT for CyberShake-30 and the success rates of SPSO for Epigenomics-24 are all 0. It is because the deadline of a workflow calculated by (13) is shortened with the decrease of a workflow’s size, thus reflecting the capacity of different algorithms to meeting deadlines.
Overall, for all workflows with different sizes, HPSO has 100% success rates and is the best algorithm, followed by LACO, ICPCP, JIT, and SPSO, while MEMS is the worst.The main reasons of HPSO having good performance in meeting the deadlines are as follows: one is that idle time slots of leased instances are fully used, which means a task may be completed as early as possible; the second is multiple different task scheduling sequences are considered and used in the proposed method. LACO’s performance is slightly inferior to HPSO because idle time slots of a leased instance are not considered. ICPCP uses the PCP as a whole scheduling object,which means an instance must satisfy LFT values of all tasks on the PCP, so it is not easy to meet the more urgent deadlines. When choosing the cheapest VM type for a task,JIT considers its effect on the children of the task. However,there may be no existing VM types that can meet the requirements of the task and its children, thus making JIT fail to the tightest deadline of some workflows. For SPSO and MEMS, they both randomly implement the mapping of tasks to VM instances during the iteration process, and do not consider the LFT of a task and the idle time slots of a leased instance.
2) Execution Cost Evaluation
The performance of an algorithm in minimizing the execution cost of a workflow is evaluated by the average execution cost of the workflow scheduled by the algorithm.Figs. 4–7 show the performance of comparison algorithms in minimizing the execution cost of extra-large, large, medium,and small workflows, respectively.
Each curve in the figures consists of eight points (cost values), reflecting the average execution cost of a workflow scheduled by an algorithm under different deadlines. In figures, the point circled by an ellipse is an invalid point,which indicates the algorithm fails to meet the corresponding deadline. In this case, comparing the average execution costs of valid points and invalid ones is meaningless.

Fig. 4. Comparsion of six algorithms in terms of minimizing the execution cost for extra-large workflows.
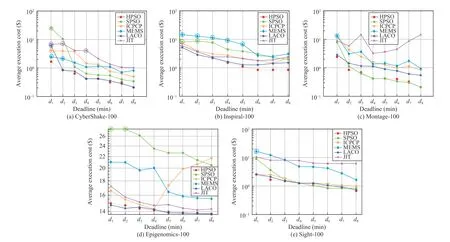
Fig. 5. Comparsion of six algorithms in terms of minimizing the execution cost for large workflows.
Amongst extra-large workflows, the execution cost of CyberShake-1000 scheduled by HPSO is lower than those scheduled by the five other algorithms, which is shown in Fig. 4(a);for Inspiral-1000 shown in Fig. 4(b), HPSO and LACO have better performance than other algorithms, and LACO is inferior to HPSO; for Montage-1000 shown in Fig.4(c), HPSO is slightly better than SPSO because the execution costs obtained by HPSO under the top two tightest deadlines are lower than those obtained by SPSO, and the performance of HPSO is significantly better than LACO and other algorithms;for Epigenomics-997 shown in Fig. 4(d), HPSO, LACO, and JIT perform almost the same and better than ICPCP, SPSO,and MEMS; for Sight-1000 and its top three tightest deadlines, as shown in Fig. 4(e), the execution costs obtained by HPSO are lower than those obtained by other algorithms.Overall, the performance of HPSO in terms of minimizing the execution cost of extra-large workflows is better than that of other algorithms.

Fig. 6. Comparsion of six algorithms in terms of minimizing the execution cost for medium workflows.
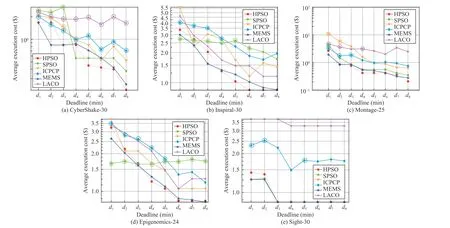
Fig. 7. Comparsion of six algorithms in terms of minimizing the execution cost for small workflows.
Amongst the large workflows shown in Fig. 5, the execution cost of CyberShake-100 scheduled by LACO under the tightest deadline d1is significantly higher than that scheduled by HPSO, and LACO fails to meet the deadline d1. For Inspiral-100, the execution costs obtained by HPSO under the deadlines from d4to d8are lower than those obtained by LACO. Thus for CyberShake-100 and Inspiral-100 shown in Figs. 5(a)–5(b), HPSO performs slightly better than LACO,and both of them are better than others; for Montage-100,HPSO has a similar performance to SPSO and is better than LACO and other algorithms. Fig. 5(d) shows that HPSO and LACO have similar performance for Epigenomics-100 and are better than SPSO and other algorithms. For Sipht-100, the execution cost obtained by HPSO, LACO, and SPSO is similar under the deadlines from d3to d8. Overall, compared to LACO, HPSO can obtain lower execution costs for CyberShake-100, Inspiral-100, and Montage-100. Similarly,compared to SPSO, HPSO performs better for CyberShake-100, Inspiral-100, and Epigenomics-100. For all large workflows, HPSO performs better than ICPCP, JIT, and EMES.
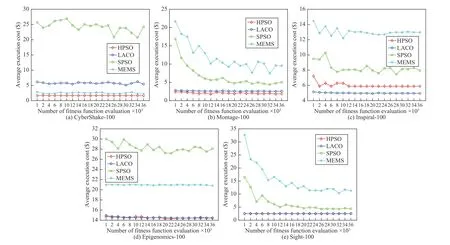
Fig. 8. Average evolutionary curves of HPSO, LACO, SPSO and MEMS on large workflows under the tightest deadline d1.
Amongst the medium and small workflows shown in Figs. 6–7,the execution costs obtained by HPSO and LACO for CyberShake-50, Epigenomcis-46/24, and Sipht-60/30 are similar; for Inspiral-50/30 shown in Fig. 6(b) and Fig. 7(b),the execution cost obtained by HPSO under deadlines d1–d4is higher than that obtained by LACO, while the cost obtained by HPSO under d5–d8is lower than that obtained by LACO.For Montage-50/25 shown in Fig. 6(c) and Fig. 7(c), HPSO performs better than LACO. Although Figs. 6–7 show that for medium and small workflows LACO performs similar with HPSO, HPSO can obtain lower execution costs than LACO for extra-large and large workflows (see Figs. 4–5). That is, as the size of the workflow increases, the performance of HPSO is better than that of LACO. Furthermore, HPSO can meet deadlines better than LACO for extra-large and large workflows (see Table IV).
In general, HPSO can achieve a lower execution cost for most workflows amongst the six algorithms, followed by LACO, SPSO and ICPCP, and JIT and MEMS. The rule based heuristic scheduling algorithms ICPCP and JIT can find quickly a feasible solution for each workflow, but the solution quality is lower than HPSO, LACO, and SPSO for most workflows. MEMS performs worse because the execution costs obtained in its different runs are significantly different,resulting in high average cost. HPSO has the best performance because HPSO combines PSO and idle time-aware rules,having the advantage of both meta-heuristics (PSO) and heuristic rules.
3) Convergence of HPSO, LACO, SPSO and MEMS
To observe the convergence of HPSO, LACO, SPSO, and MEMS, along with the increase of the number of fitness function evaluations, Fig. 8 shows the average evolutionary curves of the four algorithms on large workflows under the tightest deadline d1.
Fig. 8 shows that HPSO and LACO converge for almost all large workflows when the number of fitness function evaluations K reaches 1000. For CyberShake-100 and Epigenomics-100, MEMS converges when K reaches 1000,while for other large workflows MEMS converges when K is about 10 000. Similarly, SPSO converges for all large workflows when K is about 10 000.
Evolutionary curves of LACO show that LACO cannot find solutions with lower cost values as the number of fitness function evaluations increases. This means that the performance of LACO cannot be better than that of HPSO even if a larger number of evaluations are given.
4) Impact of Task Scheduling Sequence on Execution Cost

Fig. 9. Comparison of HPSO and HPSO with a single task scheduling sequence in terms of minimizing the execution cost.
In order to investigate the impact of multiple task scheduling sequences and a single task scheduling sequence on the execution cost of workflow, some modifications are made to HPSO. The modified HPSO only uses a single task scheduling sequence, which is obtained by topologically sorting all tasks of a workflow. Therefore, each particle in HPSO with a single task scheduling sequence only needs to represent the mapping of tasks to VM types, not including the priority of each task. Fig. 9 gives the performance comparison between HPSO and HPSO with a single task scheduling sequence, in terms of minimizing the execution cost of each large workflow under each deadline. In the figure, “HPSO”refers to HPSO with multiple task scheduling sequences.
Fig. 9 shows that under each deadline of each large workflow, the average execution cost obtained by HPSO is lower than or equal that obtained by HPSO with a single task scheduling sequence. For example, in Fig. 9(b), 9(c), and 9(e),the average execution cost of Montage-100, Insiral-100, and Epigenomics-100 under the tightest deadline d1scheduled by HPSO is significantly lower than that scheduled by HPSO with a single task scheduling sequence. Overall, HPSO with multiple different tasks scheduling sequences can achieve lower execution cost than HPSO with a single task scheduling sequence.
5) Comparison of Runtime
Compared with heuristic rules, meta-heuristic based scheduling algorithms usually need a longer computational time. This section compares the runtime of HPSO, SPSO,MEMS, and LACO. Fig. 10 gives the average runtime of each algorithm for different workflow sizes (30, 50, 100, and 1000). The runtime is calculated by first summing up the running time of an algorithm for each workflow instance and then divided by the total number of workflow instances. All four algorithms are coded in MATLAB R2016a and implemented on a PC with Core i7 2.50 GHz and Windows 7 operation system.
Fig. 10 shows that the average runtime of HPSO and LACO is less than that of SPSO and MEMS for workflows with 30 and 50 tasks, while the average runtime of HPSO for extralarge workflows is longer than that of LACO, SPSO, and MEMS. For workflows with 100 tasks, the average runtime of
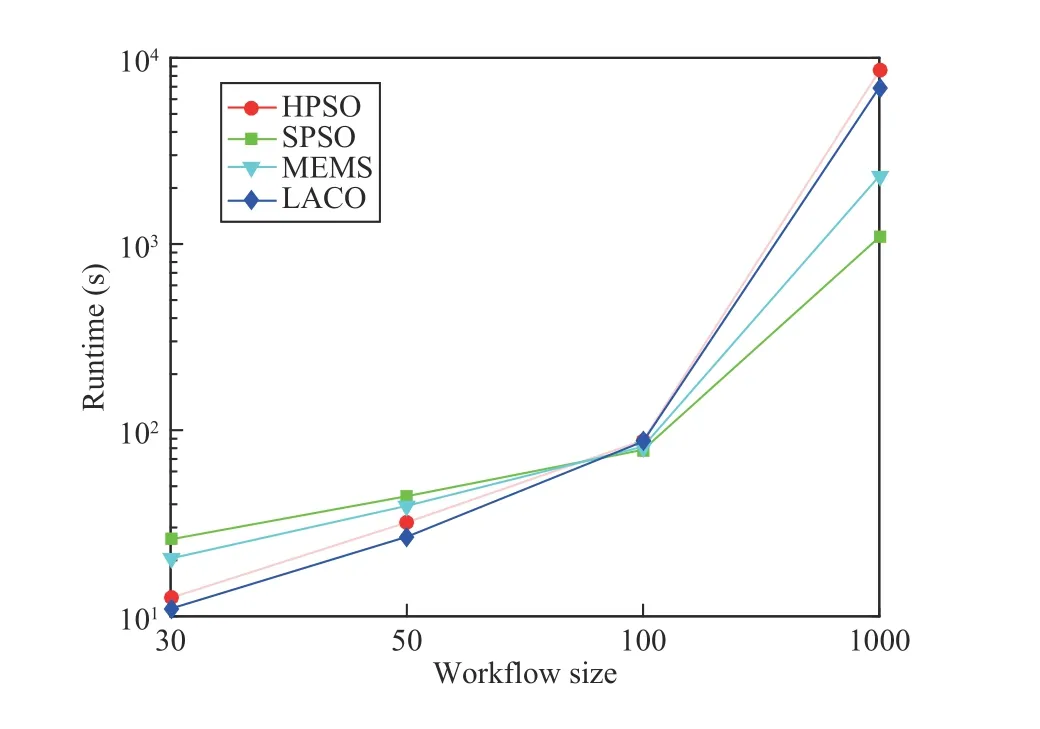
Fig. 10. The average runtime of HPSO, SPSO, MEMS, and LACO.
the four algorithms is very close.
VI. CONCLUSIONS AND FUTURE WORK
This paper proposes a hybrid particle swarm optimization(HPSO) for cloud workflow scheduling problem that considers three aspects, namely selecting the most appropriate VM type for each task, determining the best scheduling sequence for all tasks, and making full use of idle time slots.The first two aspects are combinational optimization problems, such that a PSO is used to solve them. In PSO, a particle represents the VM type required by each task and the scheduling sequence of tasks. Idle time slot-aware scheduling rules are proposed to decode a particle to a scheduling solution. During the decoding procedure, the rules assign each task in the order of the scheduling sequence to a leased VM instance or a new one, taking full use of idle time slots of leased VMs. As the randomness of PSO may cause priorities of some tasks to be invalid, making the task scheduling sequence violate the tasks’ precedence constraint, a simple repairing method is suggested to repair invalid priorities of tasks.
Experimental results based on synthetic workflows show that HPSO achieves 100% success rates in meeting workflows’ deadlines and outperforms the five other comparison algorithms. Moreover, compared with other algorithms, HPSO has better performance in minimizing the execution cost for most workflow applications.
In the future, we plan to implement a prototype system to further test HPSO. In addition, it is hard to predict task execution times exactly in advance. In [48], [49], a cloud system is modeled as a discrete-time-state space to deal with non-steady states of cloud system. Based on the idea of the discrete-time-state cloud system, we plan to combine HPSO with prediction technologies (such as analytic probabilistic models or deep learning) to study dynamic cloud workflow scheduling algorithms that considers the uncertainty of task execution times.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Review of Research and Development of Supernumerary Robotic Limbs
- Control of Non-Deterministic Systems With μ-Calculus Specifications Using Quotienting
- Decentralized Dynamic Event-Triggered Communication and Active Suspension Control of In-Wheel Motor Driven Electric Vehicles with Dynamic Damping
- ST-Trader: A Spatial-Temporal Deep Neural Network for Modeling Stock Market Movement
- Total Variation Constrained Non-Negative Matrix Factorization for Medical Image Registration
- Sampled-Data Asynchronous Fuzzy Output Feedback Control for Active Suspension Systems in Restricted Frequency Domain