基于关联挖掘的图书借阅分析
2021-04-02洪怡琳
洪怡琳
(宁波图书馆 浙江宁波 315000)
1 引言
图书馆拥有海量的馆藏图书资源和数字信息资源,能够为各种类型的读者提供完整、全面的图书借阅、信息咨询等文献信息服务。而目前大多数图书馆管理系统只提供查询、统计等基础功能,对于读者各类需求很难进行有效预测及把握。正因如此,在没有确定目标的情况下,读者往往需要花费大量的时间去检索、查找自己需要的图书,过滤掉大量价值不高、自己不感兴趣的图书。精准地捕捉到不同读者的需求,为其提供高质量的、有针对性的个性化图书推荐服务的重要性不言而喻。
大数据技术在近些年来不断发展完善,从数据的储存采集到数据的分析运算,都实现了技术提升。在图书馆的系统中,存储着大量的用户数据,这些数据的种类、数量、增长速度都与大数据的特征相符。关联规则(Association Rule)在数据挖掘技术中扮演着重要的角色,其目的在于发现数据项之间相互依赖的关系规则或关联的知识[1]。利用该技术对图书馆数据库中的海量借阅信息进行挖掘,可找到其中隐藏的关联规则,发现其中有价值的内容,以提高图书馆的服务质量,更好地服务于读者。
2 关联规则挖掘及Apriori算法
2.1 关联规则挖掘相关理论
数据库中存放着大量的数据,而数据与数据之间是存在着某种联系的,这种隐含的联系可以通过一定的方法和技术发现。这种数据与数据之间的联系是领域研究中的一个重要的知识,也是数据挖掘的对象,即关联规则挖掘[2]。
关联规则是指形如X⇒Y的式子,其中X⊂I,Y⊂I且X∩Y=Ø,X便是关联规则的前项,Y是后项,这一关联规则表示若项集X属于某一个事务集,那么Y也一定属于该事务集,且同时满足了最小支持度(Support)以及最小置信度(Confidence)。
支持度是指事务数据库中同时包含了事务X和事务Y的百分比,用公式表示为:

支持度是对关联规则重要性的衡量,它表明这条规则在所有事务中所具有的代表性,显然支持度越高,关联规则越重要;支持度低,说明该规则重要性就低,实际当中出现的机会很小。
置信度是指在事务数据库中包含了事务X的前提下又包含了事务Y的百分比,可表示为:

通常在进行数据挖掘时,会预先设定一个最小支持度阈值(min_sup)和最小置信度阈值(min_conf)。对于挖掘得到的满足最小支持度阈值和最小置信度阈值的关联规则称为强关联规则。
在关联规则挖掘中,还有一个很重要的数据指标:提升度。它可以更进一步筛选关联规则。提升度的计算公式为:

规则提升度由支持度等数据计算得出,当Lift大于1时,说明在关联规则X⇒Y中X的出现促进了Y的出现;相反的,当Lift小于1时,就说明X的出现抑制Y的出现。因此可知,只有提升度大于1时,规则具有实际意义。
2.2 Apriori算法
在关联规则挖掘的过程中,频繁项集的挖掘算法决定整个挖掘工作是否快速有效。在众多挖掘算法中,Apriori算法以其创新性的支持度剪枝,来控制候选频繁项集的指数级增长而被更多地应用[3]。Apriori算法是由Agrawal等人提出的[4],基本思想是使用一种逐层搜索的迭代算法,主要有两个步骤:①发现频繁项目集。一个频繁项目集是一个支持度大于最小支持度(min_sup)的项目集。②从频繁项目集中生成关联规则。在最大频繁项目集中,一个强关联规则(Confident Association)是置信度大于最小置信度(min_conf)的规则。关联挖掘的基本模型如图1所示。
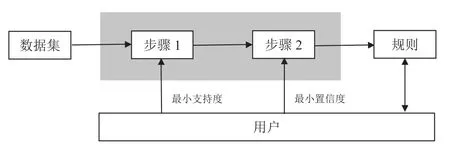
图1 关联挖掘流程图
Apriori算法的基本思想是:首先扫描事务数据库,计算各个项目出现的次数,产生频繁1-项集L1,再由L1*L1进行连接运算生成候选2-项集C2,然后扫描事物数据库统计各个候选2-项集出现的次数,确定其中的频繁2-项集L2。再由L2进行连接运算产生候选3-项集C3,继续这个过程生成频繁k-项集Lk,直到无法再生成频繁项集为止[2]。Apriori算法利用Apriori性质(任一频繁项集的所有非空子集都必须是频繁的)有效地对项集进行剪枝,尽可能不生成和不计算那些不可能是频繁项集的候选项集,从而生成较小的候选项集的集合[2]。
3 关联规则在图书借阅信息中的应用
3.1 数据准备
本文数据源选取浙江工商大学下沙校区图书馆的图书流通系统中的数据,具体内容系该高校2018年1月1日至2018年12月31日间发生的图书借阅记录信息,图书借阅数据表中含238 709条记录,包括学号、索书号、图书名称等字段,以2018年的借阅情况为基础,对所有借阅数据进行Apriori关联规则建模处理,分析用户借阅习惯,研究如何提高借阅效率问题,分析工具使用IBM公司的SPSS Modeler。
对于收集到的原始数据,由于可能存在缺失值或者噪声,不能直接用来建模,需要对数据进行预处理。通过数据的清理,减少人工输入数据的失误或数据收集时出现的漏洞、填充缺失,使数据的完整性和一致性得以保证。数据清理是提高数据质量和挖掘效率的关键环节。清理的数据主要包括了缺失数据、冗余数据和噪声数据。
(1)数据清理。在借阅数据表中可能存在空缺值,需要通过相关的数据表填充空值数据。例如,在图书借阅表中,图书索书号有空值出现,则需要根据相关信息将此空值填充完整。同时,还要对数据出现的随机错误或偏差进行有效干预。
(2)数据集成。在对挖掘数据进行空值和噪声处理之后,将多个数据源中的数据进行整合。例如,将读者借阅信息和图书信息结合,得到适合数据挖掘的有效数据。
(3)数据选择。选择挖掘所需的数据,可以大幅提高挖掘效率。例如,在图书借阅信息表中,可能存在同一读者多次借阅同一本图书的情况,这样的数据记录有效的仅仅是一条,其余记录无法提供任何有价值的信息,一般将重复无意义的数据进行删除,只保留一条借阅记录从而提高挖掘效率。数据预处理后如表1所示。
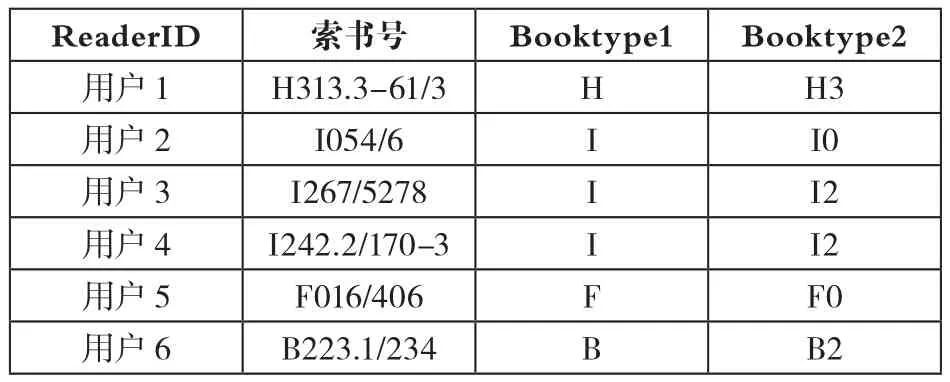
表1 用户借阅信息表(部分)
3.2 基于借阅图书的关联规则
运用SPSS Modeler软件对图书借阅数据表进行数据预处理后,还需要剔除全年只有一次借阅记录的信息,这部分数据有1 373条,剔除后剩余210 498条数据记录。通过关键字合并“选择”节点与“区分”节点后,过滤掉“索书号”与“Booktype2”字段,选择“使用事务处理格式”,以“ReaderID”字段为ID,以“Booktype1”字段为内容建立Apriori模型。经调试模型选项卡中“最低条件支持度”和“最小规则置信度”,最终确定设置最低条件支持度阈值为10%,最小规则置信度的阈值为75%,最大前项数为5项。具体流程图见图2;模型运行结果见表2。

图2 流程图
从上面得到的关联规则看出,后项是I文学类图书,规则支持度最高的三项为:借阅B哲学宗教类图书的读者会借阅文学类图书的可能性为76.763%,借阅K历史地理类图书的读者会借阅文学类图书的可能性为79.573%,借阅H语言文字类图书和F经济类图书的读者会借阅文学类图书的可能性为75.108%。以上关联规则的提升度均大于1,说明前项和后项正相关,即这些规则都具有实际指导意义。第14关联规则提升度最大,在所有有借阅历史的读者中,有1 709人借过B哲学宗教类图书和C语言文字类图书,占总数的11.478%,其中有1 286人同时借阅了F经济类图书。同时借阅哲学宗教类图书、语言文字类图书和经济类图书的读者占总读者数的8.637%。借阅哲学宗教类图书和语言文字类图书的读者同时借阅经济类图书的概率是随机读者借阅经济类图书的1.578倍,提升度越高关联强度越大。

表2 ReaderID & Booktype1建模结果
由于“ReaderID”和“索书号”两个字段的离散程度极高,所以在以其为基础建立关联规则模型时,只有把支持度和置信度阈值都设置得极低才能得到关联规则,且该情况下的规则提升度都不是很高。我们希望得到更细致的关联规则的同时,也能保证其支持度和置信度,故选择研究小类图书间的关联规则,即基于ReaderID&Booktype2的关联规则。经多次调试,最终确定设置最低条件支持度阈值为10%,最小规则置信度的阈值为70%,最大前项数为5项;运行前需要在“工具—流属性—选项”中将最大集大小调整至300。执行流后得到用Apriori算法建立的以ReaderID&Booktype2为基础的关联规则挖掘模型,其输出的关联规则见表3。
这9条规则中,前项主要是I3各国文学、I5欧洲文学和H3常用外国语图书,后项为I2中国文学类图书。规则中最高的置信度是第1条规则:82.857%,其含义为借阅I3各国文学类图书和I5欧洲文学类图书的读者则会同时借阅I2中国文学类图书,所有样本中借阅各国文学和欧洲文学小类图书的读者有1 505位,意味着向同时借阅I3各国文学类图书和I5欧洲文学类图书的读者推荐I2中国文学类图书的成功率是没有规则指导下推荐成功率的1.765倍。同时,还可以结合相应类别的热门书目进行推荐,提高推荐成功率。所有关联规则的提升度均大于1,具有实际指导意义。
在图书馆藏分布方面,如将I2、I3、I5类图书放在一起,方便读者进行选择,同时也提升了书籍的使用率,有利于将未被使用的书籍推向读者,在一定程度上也降低了文化资源的浪费。从规则中发现,I2类图书在各个规则中都有出现,说明I2类图书的借阅率很高,可以增加该类图书的馆藏资源,指导图书采购工作,同时做好预留图书架位的工作,避免频繁倒架,提高工作效率。
在读者服务工作方面,比如向借阅了I3类图书的读者推荐I2类型的图书,实现个性化推荐服务,对于借书频率较低的读者则可以推荐热门的I2类图书以增加其阅读兴趣,进而优化图书馆的服务质量。
4 结论
本文研究了Apriori算法在图书馆图书借阅数据中的应用,发现将关联规则应用在图书馆借阅系统有着重要的参考价值:①以读者为中心,提升读者的阅读体验。图书馆可以通过对读者的历史借阅情况进行统计分析,发现其中有意义的关联规则,使得读者喜爱的书目能够快速被读者找到,满足不同读者个性化需求,从而帮读者节省大量时间和精力。在当下快节奏的工作生活中,提高借阅效率,意味着读者会有更多的时间专注于阅读,而不是费尽心思寻找合适自己的书目,这无疑会提升读者的阅读体验,体现了以读者为中心的理念。②扭转图书馆的被动式服务理念。有效运用数据挖掘技术,分析读者的信息行为,从而了解不同读者的阅读需求和借阅行为,主动将现有的服务推送给读者,扭转传统的被动式服务理念。读者可以通过图书馆主动的阅读推送,获得贴心的阅读书目推送,这种方式可以将图书馆与读者之间的距离拉得更近,从而提升图书馆的服务质量。③图书管理决策智能化。由Apriori算法得到的关联规则能够给图书管理提供有利的数据支撑,图书馆员在管理过程中,可以依据实际情况进行图书上架的精细化管理,出于方便读者借阅的目的,把关联度较高的图书类型摆放在一起[5]。并且记录下各个区块图书借阅的相关数据,做好数据处理,以发现图书摆放之间的相关性。最后将相关图书信息进行处理分析,转化为随时可用的决策知识,防止将来因信息不足而造成图书管理的决策错误。

表3 ReaderID & Booktype2建模结果
