文本关键词抽取方法及在几种民族语言上的应用
2021-03-31白曙光李艳玲张树钧
白曙光, 林 民, 李艳玲, 张树钧
(内蒙古师范大学 计算机科学技术学院,内蒙古 呼和浩特 010022)
自然语言处理是人工智能的重要组成部分,在学术研究和实际应用等各个方面都有重要地位,关键词抽取技术作为自然语言处理的基础技术之一,其结果的优劣直接影响后续任务的性能。
关键词抽取能够帮助读者获取文章的中心思想,迅速了解一篇文章,或者从海量语料中快速获得文章主题。在文本检索、文本摘要等领域,关键词抽取的准确程度对其他下游任务具有重要意义[1]。有效提取文本中关键词有助于读者快速、及时、高效、准确地获取信息。文本关键词可以提高文档管理和检索效率,还可为文本的分类、聚类、检索、分析和主题搜索等文本挖掘任务提供丰富的语义信息。因此,关键词抽取与其他下游任务是密切相关的。
1 文本关键词抽取研究难点
关键词抽取是自然语言处理领域的研究热点,目前存在以下六个研究难点,严重制约了关键词抽取技术的发展。
(1) 文本预处理不够准确。近几年文本表示学习、预训练等技术的发展有了一定提升,但是在精度和深度上仍不能满足研究需要,直接影响上层应用效果和智能水平。不能从语义上准确理解文本是关键词抽取技术的一大难点。
(2) 效率低,复杂度高,尤其是融合方法的复杂度更高。目前许多自然语言处理任务为了达到较好效果,需要利用大量标注数据进行训练,但是常会出现训练语料不足的问题,而且标注数据费时费力[2],所以,当数据资源有限时,如何增强资源启动和多语种场景的应用成为亟待解决的问题。
(3) 语义关联关系的去重、歧义消解等问题。深度学习的应用虽然使众多自然语言处理的任务性能得到提升,但是如何设计更好的语义表达方式仍未解决,而且中文存在语义歧义现象,如“郭德纲的粉丝想吃粉丝”这句话中,两个“粉丝”代表不同的语义,但向量表示形式一致,所以语义歧义现象在一定程度上制约了关键词抽取技术的发展,解决语义歧义问题可在一定程度上提高文本关键词抽取任务的性能。
(4) 抽取得到的关键词对文档主题覆盖性不高。在一个文档中,经常有多个主题,现有方法没有有效机制对主题进行较好的覆盖[3]。
(5) 文档与关键词之间存在一定的差异性。很多关键词在文档中的频率低,导致文档和关键词之间存在差异[4]。
(6) 少数民族语言文本的关键词抽取存在自身的难点。如因文本自身的特征,预处理操作较为困难。
2 文本关键词抽取技术和方法
关键词抽取方法目前有三种: 有监督、半监督和无监督。其中,无监督方法包含基于统计特征、主题模型及图网络,其中被广泛应用的有词频-逆文档频率(term frequency-inverse document frequency,TF-IDF)算法[5]、LDA (latent dirichlet allocation)主题模型[6]和TextRank等算法[7-10]。
2.1 有监督方法
有监督关键词抽取方法的主要思想一般是先建立一个大规模标注好的关键词训练语料,然后利用训练语料对关键词抽取模型进行训练。有监督的关键词抽取方法常用的模型有朴素贝叶斯(naive bayesian,NB)[11]、决策树(decision tree,DT)[12]、最大熵(maximum entropy,ME)[13]、支持向量机(support vector machine,SVM)[14]等。
有监督的方法中关键词抽取问题被转化为分类问题或标注问题,即判断每个文档与已构建好的词表中每个词的匹配程度,然后把文档中的词作为候选关键词,通过分类学习方法或序列标注方法判断这些候选词是否为关键词,进而实现关键词抽取的效果。当将关键词抽取任务看作是一个二分类任务时,需要在一个有标注的数据集上训练分类器。当将关键词抽取任务看作是标注问题时,研究人员需要从训练集中建立一个语言模型,并选出符合关键词特征的模型,再利用人工标注信息作为特征进行关键词抽取。
有监督学习的关键词抽取方法通常需要建立大规模训练集合即语料库(corpus),是由大量实际使用的语言信息组成,并需要针对通用或特定需求进行人工标注。训练语料的质量对模型的准确性至关重要,直接影响模型的性能,从而影响关键词抽取的结果。目前,已经标注好关键词的语料有限,训练集又需要大规模的语料,所以需要人工标注,带有一定主观性,易造成实验数据的不真实[15]。因此,高质量的训练集合对有监督学习方法的性能是至关重要的。有监督的学习方法具有较高的准确性和较强的稳定性,更加科学、有效,但存在人工标注工作量大、数据量激增、内容实时性强、耗时耗力等问题。如果将关键词抽取问题视为一个二分类问题,那么对每个单词的独立处理忽略了文本的结构信息[16],对模型性能有一定影响。
2.2 无监督方法
无监督关键词抽取方法无需人工标注语料,该方法根据词汇的重要程度进行排序,抽取排名靠前的作为关键词。无监督方法是近年来研究和应用的重点,常见的无监督关键词抽取方法有三种: 基于统计特征[17]、基于主题模型[18]和基于网络图模型[19]的关键词抽取。无监督的文本关键词抽取流程如图1所示。

图1 无监督文本关键词抽取方法流程图Fig.1 Unsupervised keyword extraction method in text
2.2.1 基于统计特征的方法 基于统计特征的关键词抽取方法是一种传统机器学习方法,主要是利用文档的统计学特征抽取关键词。首先对文本进行预处理操作,去除不规范内容,获得候选词集,然后计算候选词集中词汇的统计学特征,根据特征值对词汇进行排序,根据排序从候选集中抽取关键词。常用的统计特征包括词权重、词位置、词的关联信息等[20]。
词权重特征主要包括词长度、词性、词频、TF-IDF等。词性是通过分词、语法分析后得到的结果,一般为名词或动词,更能表达一篇文本的中心思想。词频一般可以认为文本中出现频率越高的词越有可能成为关键词。但仅依靠词频得到的关键词对长文本的不确定性很高,会有较大噪音; 而且,语句的位置也反映了其在文章中的重要性,文章标题、引言、段首句、段尾句均对文章有重要意义,这些词作为关键词可以表达整个文本的主题[21]。标题和摘要更能概括文本的中心思想,具有一定代表性,因受到作者写作方式的影响,具有不确定性。基于词的关联信息的特征量化信息一般包含词和词、词和文本之间的关联程度,关联信息通常包括互信息、HITS(hyperlink-induced topic search)值、贡献度、依存度、TF-IDF值等。
TF-IDF算法是关键词抽取方法中的一种基础算法,因其简单有效而被广泛应用。TF-IDF值是指如果某个词语在一篇文本中出现的频率(term frequency,TF)高,而其他文本中较少出现,即逆文档频率(inverse document frequency,IDF)低,则认为该词语能较好地代表当前文本的含义。TF-IDF算法主要用于评价一个词对于一个文档的重要程度。在TF-IDF算法中,字词的重要性随着该字词在文档中出现的次数呈正比,但同时也会随着它在该文档出现的频率呈反比。TF-IDF算法的计算如公式(1)-公式(3),词频即一个词在文档中出现的频率,一个词的IDF表示这个词在整个语料数据库中出现的频率。

(1)

(2)
It(i,j)=Iω(i,j)×Id(i,j),
(3)
其中:It(i,j)是指词i相对于文档j的重要性值;Iω(i,j)是指某一个字词在该文档中出现的次数占比,即给定的词语在该文档中出现的频率,计算公式如(4);Id(i,j)是指词i的逆文档频率,是用总文档数目除以包含指定词语的文档数目,再将得到的商取对数,计算公式如(5)。
(4)
其中:ni,j表示词i在文档j中出现的次数;nk,j表示文档j字词出现的次数。
(5)
其中:D表示语料库中文档的总数; {j:ti∈dj}表示包含词语ti的文档数目。
TF-IDF算法存在如下不足: 一是对语料库的质量要求较高,而且在跨领域语料上表现较差; 二是对一些在文本中出现频率高并具有代表性的词语不能很好表示; 三是精度不高,由于IDF有一种试图抑制噪声的加权,本身会倾向于文本中出现频率较小的词,从而导致TF-IDF算法精度不高; 四是对词汇位置不敏感,没有考虑不同位置上词汇的不同重要性,例如在标题、句首和句尾等位置出现的字词往往含有较重要的信息,应该赋予较高的权重[22]。可以通过将多个短文本归并为一个文本的方法来改进TF-IDF算法,不仅可以增加TF值,而且可以增加IDF值,但同时也会增加模型的计算成本。此外,TF-IDF仅能考虑到词自身的频度,无法将其与语义语法相结合,影响了关键词抽取的性能。
基于统计特征的关键词抽取方法主要是通过词权重、词的文档位置、词的关联信息等特征量化指标对关键词按照其重要程度从高到低排序,获取Top K个词作为关键词。
2.2.2 基于主题模型的方法 关键词抽取与内容的主题相关,因此提取文本内容的主题至关重要。主题模型又称文档生成模型,它认为文档是主题的概率分布,而主题是词汇的概率分布[23]。LDA利用隐含主题模型发现文档主题,然后再选取主题中具有代表性的词作为该文档的关键词。
基于主题的关键词抽取方法主要是利用主题模型中关于主题的分布性质进行关键词抽取。首先从文本中获取候选关键词,然后利用有关键词的语料训练出一个主题模型,并得到主题分布和词汇分布[24],最后在主题空间上计算候选关键词和文本的相似度,根据相似度从大到小排序,选取前n个词作为关键词。具有代表性的是pLSA (probability latent semantic analysis)[25]模型、LDA模型等。pLSA将概率引入主题模型中,文档主题之间、主题词汇之间的隐含语义空间不再是一个抽象的概念空间,而是一个特定的概率分布空间,计算公式为

(6)
其中w表示词语,D表示文档,T表示主题。

图2 LDA模型图Fig.2 LDA model
2003年D.M.Blei提出了LDA主题模型[6],与pLSA相似,LDA也从文档、主题、词三个层面进行分析,并认为文档有其主题概率分布,主题有其词汇概率分布文档可以在主题空间上进行表示,并根据主题的相似性进行文本聚类或者文本分类。LDA模型如图2所示。LDA通过采用词袋模型(bag-of-words,BOW)的方法简化了问题的复杂性,认为一篇文档是由一些词组成的集合,词与词之间没有先后关系。与pLSA分布不同的是,主题概率分布和词汇概率分布的参数不是唯一的,这两个分布的参数都符合Dirichlet分布。
在LDA模型中,包含词、主题、文档三层结构。该模型认为一篇文档的生成过程是:先为一篇文档选择若干主题,然后为每个主题挑选若干词语,最后将这些词语组成一篇文章。所以主题对于文章以及单词对于主题都服从多项分布。由此可以得到: 如果一个单词w对于主题t很重要,而主题t对于文章d又很重要,那么可以推出单词w对于文章d就非常重要,并在同主题的词wi(i=1,2,3,…)中,词w的权重也会较大。
根据上述,需计算以下概率。主题Tk下各个词wi的权重计算公式为
(7)

文档Dm下各个主题Tk的权重计算公式为
(8)
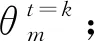
指定文档下某个主题出现的概率,以及指定主题下某个单词出现的概率计算公式为
(9)
由公式(9)可以得到单词i对于文档m主题的重要性。在LDA主题模型中,由于所有的词都会以一定的概率出现在每个主题中,因此会导致最终计算的单词对于文档的主题重要性区分度受到影响。为避免该情况的出现,一般将单词相对于主题低于一定阈值的概率设置为0。基于LDA的关键词抽取方法,在主题层面上对文档关键词进行分析。这种方法不仅挖掘了文本的深层语义即文本的主题,而且可以将文档集中的每篇文档按照概率分布的形式表示,文档的主题维度一般远小于文档的词汇个数,所以也有研究者根据主题对文本进行分类。但基于主题模型提取到的关键词比较宽泛,不能很好地表示文档主题; LDA模型同样耗时耗力; 在LDA中,主题的数目没有固定的最优解[26]。模型训练时,需事先设置主题数,训练人员需要根据训练出来的结果,手动调参,通过优化主题数目,进而优化文本分类结果。对此,可以借助知网、同义词林等外部资源获得更加准确的单词语义关系。
在pLSA模型中,主题分布和词分布的参数都是唯一确定的。而在LDA中,主题分布和词分布的参数是变化的,LDA的研究人员采用贝叶斯派的思想,认为参数应服从某个分布。主题分布和词分布呈多项式分布,因为多项式分布的共轭先验分布是狄利克雷分布(Dirichlet distribution),所以在LDA中主题分布和词分布的参数应服从Dirichlet分布。可以说LDA就是无监督的pLSA的贝叶斯化版本。
2.2.3 基于网络图的方法 TextRank是一种基于图排序的算法。TF-IDF对于多段文本的关键词抽取非常有效,但对单篇或者篇幅较长的文本效果一般。TF-IDF仅考虑词语自身的频度,而TextRank考虑了文档内词间语义关系,可以有效提取文本的关键词。
TextRank基本思想来源于Google的PageRank[27]算法,通过把文本切分为若干组成单元(单词、短语或者句子)建立图模型。首先将文本中的词作为节点,词之间的关系作为边,建立文本词汇网络图,然后根据图结构挖掘词汇之间的关联关系,找到整个网络中具有重要地位的词或短语,作为关键词[28]。顾亦然[29]提出基于PageRank算法,利用词频特性,结合语言习惯特性定义位置权重系数,在新浪新闻语料上进行实验,有效提升了新闻类文本关键词提取的结果。随机游走算法中具有代表性的是PageRank算法,它通过网页之间的超链接来计算网页重要性[30]。TextRank算法借鉴了这种重要性可传递的思想。
李航[31]为克服传统TextRank的局限性,提出对词语的平均信息熵、词性、位置的特征进行自动优化的神经网络算法,通过优化词汇节点的初始权重以及概率转移矩阵,进而提高关键词抽取准确度。柳青林[32]通过引入马尔可夫状态转移模型,对TextRank算法本身进行了完善,得到的单文本关键词提取结果与人工提取结果更加一致。
TextRank算法对一段文本多次出现的词赋予更大的权重,因为词的共现关系即为边,一个词的共现词越多,网络中与这个词相连的节点就越多,这样会使类似于“的”“这”“那”等没有特别含义的停用词的权重增大[33]。对于这种情况,可在对文本进行切分时,去掉停用词或其他符合一定规则的词语。基于图的算法,计算词与词之间的共现关系,结合其他特征为每个词打分,从而找到关键词。近年来,基于图算法的模型有Top-icRank[34]、SalienceRank[35]、PositionRank[36]。
2.3 TF-IDF和TextRank融合方法
TF-IDF和TextRank算法各有不足。TextRank算法为每个节点赋予相等的初始权重,没有考虑到节点本身不同的重要性,在计算过程中节点的分数也是平均分配到周围节点,没有考虑到被分配节点与分配节点的相关程度[37]。为解决这些问题,通常将多种方法进行组合来弥补单一算法的缺点。例如将TF-IDF和TextRank算法相结合,将其作为词节点之间的特征权重,调整词节点间的影响力,或者综合TF-IDF与词性得到关键词等。

图3 改进TextRank算法的关键词抽取流程图Fig.3 The keyword extraction flowchart of the improved TextRank algorithm
尤苡名等[38]提出融合TF-IDF与TextRank 算法的关键词抽取方法,通过引入用户浏览评论后的反馈,提高重要词语的权重,对TF-IDF算法进行改进。将改进后的词频逆文档频率作为词节点特征权重加入TextRank 算法中,提高有效评论中关键词的权重。陈志泊[39]等通过改进TextRank算法,将计算的综合权值作为词语特征值,得到高品质的词语集合,判定信息类型,然后将关键词和信息类型相结合,实现对文本关键信息的抽取,最终形成的信息类型集合在紧密性、间隔性、综合评价指标上均表现良好。改进的TextRank 算法关键词抽取流程如图3所示。
刘啸剑等[23]提出一种结合LDA与TextRank 的关键词抽取模型,并在Huth200和DUC2001数据集上验证了该方法的有效性。张瑾[40]将特征词位置及词跨度权值引入到TF-IDF中,并在提取新闻情报关键词实验中证明了算法的有效性。谢玮等[41]利用TF-IDF对词语的位置进行加权,并采用TextRank实现关键词抽取任务。
2.4 基于深度学习的文本关键词抽取方法
随着人工智能的不断发展,深度学习方法被广泛应用于文本关键词抽取方法中。成彬等[42]利用条件随机场(conditional random field,CRF)模型[43]处理序列标注问题的优势,通过将词性信息和CRF模型融入双向长短时记忆(bidirectional long short term memory,BiLSTM)网络[44],实现期刊关键词的自动抽取。融合词性与BiLSTM-CRF的关键词抽取模型如图4。首先需要对文本进行预处理操作,包括分词、词性标注和依存句法分析,然后使用word2vec[45]向量化表示文本,最后使用BiLSTM-CRF模型进行关键词的自动抽取。基于融合词性特征的BiLSTM-CRF期刊关键词抽取方法,不仅实现了数据时序和语义信息挖掘,而且保证了单词与单词之间的关联性。

图4 融合词性与BiLSTM-CRF的关键词抽取模型Fig.4 Keyword extraction model for journals based on part-of-speech and BiLSTM-CRF

图5 基于注意力机制的关键词抽取结构图Fig.5 Structure of keyword extraction based on attention mechanism
杨丹浩等[46]提出基于序列标注的关键词抽取模型,该模型将BiLSTM与注意力机制相结合用于论文关键词的提取。在实验过程中,将字的向量表示与词的向量表示作为模型的输入,将不同颗粒度的向量表示相融合,相比于传统的无监督模型TextRank,TF-IDF性能有明显提升。该模型的结构框如图5所示。
虽然基于序列标注的关键词抽取模型有效利用了BiLSTM和注意力模型,但实验仍存在两点不足:一是该实验仅将论文中的关键词进行标注并训练,没有考虑该关键词与文章内容的相关性; 二是没有考虑论文标题与关键词的关系,将论文标题有效结合提取关键词有待进一步的研究。
考虑到词向量的优势,宁建飞等[47]使用Word2vec算法计算文本集词向量,并构建文本层面的词汇相似矩阵,同时改进TextRank 算法的初始权重分配方式和迭代计算过程中的概率转移矩阵。周锦章等[48]针对单词语义的差异性对TextRank算法的影响这一问题,提出一种基于词向量与TextRank的关键词抽取方法。同时利用FastText将文本集进行词向量表示,基于隐含主题分布思想和利用单词间语义的不同,构建TextRank转移概率矩阵,最后进行词图的迭代计算和关键词抽取。实验结果表明,该方法的抽取效果优于传统方法,同时证明了词向量可以简单有效地改善TextRank 算法性能。
2.5 几种民族语言的文本关键词抽取方法
多民族是我国的重要特征之一,结合现代技术研究少数民族语言对各民族历史文化的传承,增加我国社会人文内涵,具有重要作用。同时,利用现代信息技术结合大数据的优势,可以更加深入挖掘分析民族语言文字中隐含的规律,提高民族语言文字数据的处理效率,为少数民族语言文字的研究提供有效帮助。目前研究中主要涉及的少数民族语言文字有藏文、维吾尔文、蒙古文、哈萨克文等,并采用例如LDA模型、深度神经网络等方法进行研究。我国少数民族中,藏族、维吾尔族和蒙古族具有相对完整的民族语言文字,形成了相对成熟的民族教育体系,相关领域拥有相对较多的民族科学研究人员,因此本文主要研究藏文、维吾尔文和蒙古文三种少数民族语言文字。
2.5.1 蒙古语 蒙古文作为蒙古族通用语言文字,是目前世界上极少数竖向排列的文字之一,从上到下连写,从左到右移行。回鹘式蒙古文是有记载以来最早的蒙古族文字,回鹘式蒙古文文献对蒙古族历史文化和蒙古语发展变化及蒙古文词法、词汇的研究具有重要学术价值。但由于蒙古文文字编码不统一,导致难以制定蒙古文通用规则,而且相对于其他语言的研究相对起步较晚,所以目前蒙古文的研究还处于初级阶段。
斯日古楞等[49]基于LDA模型建立蒙古文文本主题模型,分析隐藏在文档内不同主题和词之间的关系,通过实验计算文本的主题分布和查询语句主题之间的相似度,较好地实现了蒙古文文本主题语义的检索效果。Hongxiwei等[50]通过在检索时合成分词后的蒙古文历史文献图像序列,提取基于轮廓特征表示的文字图像并进行固定长度的特征向量在线匹配,从而得到降序后的相似度排序结果,以此定位蒙古文历史文献图像中的关键词。白淑霞等[51]考虑到词袋模型(Bag-of-words model)可能忽略单词间的空间关系和语义信息问题,提出一种基于LDA的主题模型,用以解决蒙古文古籍的关键词检索。该方法的性能优于视觉词袋模型(bag of visual word model)[52]。王玉荣等[53]设计并实现了一个基于云架构的分布式蒙古文硕士论文检索系统,设计完成了满足分布式要求的蒙古文分析器,作为系统核心模块在分布式多节点上实现了蒙古文的索引和检索功能; 使用BM25概率模型可对蒙古文论文检索和排序,并具有关键词或摘要的中文检索功能。
2.5.2 藏语 藏语的主要表现形式是藏文,藏文分为辅音字母、元音符号和标点符号3个部分。其中有30个辅音字母,4个元音符号,以及5个反写字母用以拼写外来语。藏文采用上下叠写的方法自左向右横写。目前藏文的关键词研究大多基于藏文新闻网页,为后续藏文古籍翻译、藏文情感识别以及藏文舆情分析工作奠定了基础。虽然藏文文字排序方面的研究取得一定进展,但藏文文字中的几种特殊音节字母到目前还没有标准处理方法。
通过对中文关键词抽取方法的学习,对网页模块中智能识别后的藏文文本进行自动分词,采用以此为基础改进后的TF-IDF算法得到基础词集,根据词向量特征扩展构建候选关键词集,分析利用其语义相关度值并在一定程度上更高效率的提取藏文网页关键词[54]。艾金勇[55]为提升藏文文本关键词的抽取效果,针对藏文文本特点,将藏文文本的多种特征和TextRank相结合,同时根据词语之间的语法关系给出了候选关键词的量化权值。与传统方法相比,关键词抽取效果明显提升。洛桑嘎登等[56]结合藏文分词标注研究并实现了一种基TextRank算法的藏文关键词提取技术,该文在1 500句的藏文问句上进行了实验研究,总体效果较好。才让卓玛等[57]通过借鉴中文关键词抽取方法,提出一种基于语料库的藏语高频词抽取算法,并提出对藏语文本的预处理方法,实验结果表明,该算法的准确率达86.22%。徐涛等[58]针对藏文新闻网页提出卡方统计量结合词与词推荐相结合的方法,并通过实验得出该方法效果优于融入位置的TF-IDF算法。
2.5.3 维吾尔语 维吾尔文是新疆大多数人互相交流的语种之一。我国维吾尔族使用的是以阿拉伯字母为基础的拼音文字。相对于通用语言文字的识别,维吾尔文的识别研究起步相对较晚,电子化维吾尔文本数据较少,语料规模较小,质量不高,为维吾尔文的研究带来了困难。研究者们通过直接识别维吾尔文图片、借鉴中文关键词的语义分析等技术,试图克服上述问题。
李静静等[59]提出并实现一种基于由粗到细层级匹配的关键词文档图像检索方法,通过支持向量机(SVM)分类器学习,从单词图像提取方向梯度直方图(HOG)的特征向量,可以有效实现维吾尔文关键词图像检索。阿力甫·阿不都克里木等[60]提出一种基于TextRank算法的维吾尔文关键词提取方法,首先对输入文本进行预处理,滤除非维吾尔语的字符和停用词,然后利用词语语义相似度、词语位置和词频重要性加权的TextRank算法提取文本关键词集合。实验结果表明,该方法能够提取出具有较高识别度的关键词。热依莱木·帕尔哈提[61]通过实验对维吾尔文文本基于TextRank、TF-IDF、SDA(system display architecture)、SparseSVM四种方法分别进行关键词提取和文本文本分类,实验效果可满足需求。买买提阿依甫等[62]通过对维吾尔文语言特殊性的分析,提出一种结合word2vec和LDA模型生成主题特征矩阵,获取语义粒度层面特征信息,通过丰富卷积网络池化层特征来提高情感分类的准确率,取得了比传统机器学习方法更好的情感分类性能。
2.6 关键词抽取技术总结
本文通过对各种关键词抽取方法进行阐述,分别分析了无监督方法和有监督方法的技术特点、代表性模型及其优缺点,结果见表1。

表1 文本关键词抽取技术总结Tab.1 Summary of text keyword extraction technologies
3 关键词抽取的评价方法
关键词抽取质量优劣的评价标准是其符合文本的实际语义,高质量的关键词应具备可读性、相关性、覆盖性和简洁性等特质,即关键词不仅具有实际意义,而且关键词和文本主题保持一致,更能够覆盖文本的各个主题。此外,关键词还应简洁明了,各个关键词之间也应相关联。目前对关键词抽取任务一般有两种方法,一种是由领域专家进行人工评价,这种方式可操作性强但缺点也明显,比如认识分歧、词或短语的组合歧义等问题。另一种常用的评价指标是: 准确率P(precision)、召回率R(recall)和F值(F-measure)。
(10)
其中KP表示抽取出的正确关键词条数,K表示抽取出的关键词条数。
(11)
其中DK表示文档中的关键词条数。
(12)
其中: 准确率和召回率的取值范围为[0,1],取值越接近1,分别表示抽取出的关键词正确率越高和越多的关键词被正确抽取;F值为准确率和召回率的调和平均值,能够综合准确率和召回率; ∂为调节参数,当∂=1时,表示为F1值,即
(13)
4 总结与展望
通过总结文本关键词抽取的各种方法,考虑到应用环境复杂性的影响,对于不同类型的文本,例如长文本和短文本,通用语言文本和少数民族语言文本,采用同一种文本关键词抽取方法得到的性能结果会有所不相同。所以,针对不同类型、不同民族语言的文本应采取不同的算法。针对目前文本关键词抽取技术面临的研究难点,提出以下需进一步研究内容:
(1) 多种方法的有效融合。使用传统方法和基于深度学习的方法,或者其他的多种方法相融合的方式改进中文或少数民族语言文本关键词抽取的性能。
(2) 结合语义的方法。随着深度学习的发展,相较于传统机器学习时代,自然语言处理技术发生了翻天覆地的变化。从word2vec模型,到Elmo模型,再到后来Google提出的BERT语言模型,大幅度提升了自然语言处理多种任务的性能,BERT能动态调整语义信息有效解决一词多义的问题,将文本理解和语义表示推向了新高度。
(3) 借助外部知识库改善关键词抽取技术。神经网络在大规模语料训练过程中,并没有显式的将知识进行合理的结构化组织,从而导致模型领域泛化能力较弱。利用知识图谱等形式进行组织并实现知识融合,可以帮助模型提高泛化能力,是未来值得探索的重要方向。
