基于改进的VGG-Net的手写蒙古文字元识别
2021-03-31石佳钰殷雁君刁明皓
石佳钰, 殷雁君, 刁明皓, 智 敏
(内蒙古师范大学 计算机科学技术学院,内蒙古 呼和浩特 010022)
我国是一个统一的多民族国家,有着丰富的民族语言资源。蒙古语,是我国少数民族语言之一,有着广泛影响力,除内蒙古自治区外,很多蒙古族聚集的省市也在使用蒙古文文字。近年来,随着社会信息化的发展,大量蒙古文古籍、资料需要用计算机进行处理和保存。人工录入方法消耗大量人力和物力,而且录入过程中不可避免地出现因误录而导致的错误。鉴于此,研究能够自动且高效识别海量蒙古文资料的蒙古文文字识别技术,对于促进蒙古族语言知识的共享和传播、推进蒙古族地区经济文化繁荣和发展有重要的现实意义。
1 相关研究
目前,图像文字识别的主流算法是卷积神经网络(CNN)。最初的卷积神经网络是LeCun[1]提出的LeNet-5网络模型,该模型在手写数字识别问题中取得了较高的识准率。在此基础上,Goodfellow等[2]提出基于多数字识别的卷积神经网络模型,为英文图像文字识别提供新的思路。随后,Jaderberg等[3]将卷积神经网络应用到自然场景下的图像文字识别,提出一次性识别整个英文单词的方法。为了能够识别图像中具有序列性的对象,Shi等[4]在卷积神经网络和循环神经网络的基础上,提出端到端可以识别任意长度序列的卷积递归神经网络模型(convolutional recurrent neural network,CRNN)。
英文图像文字识别发展较早,目前技术较为成熟。中文文字识别过程中也借鉴了许多成功的英文图像文字识别技术。例如,基于并行神经网络,于秀云[5]提出汉字匹配的印刷体汉字识别方法。在卷积神经网络基础上,Zhong等[6]提出增加多层卷积方法,用以解决印刷体汉字识别中多字体识别问题。孟彩霞等[7]采用深度残差网络模型解决汉字识别的网络模型较为复杂且不易简化问题。王建平[8]提出利用过程神经网络对手写汉字提取笔段特征进行手写汉字识别。针对在手写体汉字识别中数据不足问题,Yang等[9]通过对手写字体进行形变、非线性归一化等方法增加数据的多样性,提出基于指定特征的卷积神经网络手写汉字识别。
近几年,无论是印刷体还是手写体的汉字图像文字识别技术都取得了一定的研究进展,但蒙古文图像文字识别研究则相对滞后。蒙古文是一种拼音文字,在书写、阅读上与中英文有很大区别,其书写是以词为单位竖写,词与词之间用空格分隔。最初,蒙古文图像文字识别是将蒙古文字元切分后进行识别。例如,李伟等[10]在行切分和单词切分的基础上提出了印刷体蒙古文字元切分方法。李振宏等[11]提出采用综合统计识别与结构识别的网格特征作为分类依据进行蒙古文字元识别。目前,蒙古文图像文字识别主流方法是文字检测后进行识别。例如,魏宏喜[12]提出基于最小二乘法的蒙古文文本图像检测方法。刘聪[13]提出基于卷积循环神经网络与连接时序分类器相结合的手写蒙古文整词识别。李敏[14]提出针对蒙古文手写识别数据的预处理提出了距离夹角方法和坐标标准化方法。范道尔吉[15]结合切分后识别的方法,提出以字素码为蒙古文单词为分割单位的蒙古文大词汇量手写识别方法。
2 关键技术
VGG-Net是2014年由牛津大学和Google Deep Mind公司研究人员研发的深层卷积神经网络[14]。VGG-Net以较深的网络结构,较小的卷积核和池化采样域,使其能够获得更多图像特征的同时控制参数个数,避免过多计算量以及过于复杂的结构。VGG-Net通过反复地叠加卷积层和最大池化层,最终发现16层至19层深的网络模型性能较强。但是因为标准的VGG-Net应用的数据集与蒙古文字元数据集差异很大,直接应用会造成运算时间和运算空间的浪费,所以改进标准VGG-Net模型使其能够更好地完成蒙古文字元识别的任务,提高分类识别任务效率和准确率,同时节省运算空间。
2.1 VGG-Net
VGG-Net共有A、B、C、D、E六种结构配置,具体网络结构如图1所示。深度从11层到19层不等,应用最广泛的是VGG-16和VGG-19。VGG-Net将六种结构配置都分为五部分,每部分都由卷积层和池化层叠加而成,之后连接三个全连接层和一个softmax层。

图1 VGG-Net网络结构图[16]Fig.1 VGG-Net network structure diagram[16]
VGG-Net整个神经网络中卷积层的卷积核都采用3×3的小型卷积核,2×2的最大池化层。相比卷积核为5×5的一个卷积层,卷积核大小为3×3的两个卷积层不仅加深了网络深度、减少参数个数,同时加强了图像特征的提取能力。同理,相比大小为7×7的卷积核,三个3×3的小型卷积核效果会更好。
2.2 改进的VGG-Net模型
正如BP算法经典的2层算法一样,当网络增加至3层效果提升甚微,增加至4层、5层效果比2层差。神经网络的深度同样会影响识别蒙古文字元的效果。随着隐层数量增加,激活函数使用不当时会使得误差从输出层开始呈指数衰减,由于梯度消失导致深度结构的较低层甚至无法训练,而较高层却容易训练。较低层由于无法训练,容易把原始输入图像不经过任何非线性变换,或者错误变换送入高层,使得高层提取特征压力过大。如果特征无法提取,强制性的误差监督训练会使模型对输入数据直接做拟合,从而出现过拟合现象,故而神经网络深度需要根据任务进行调整。标准的VGG-16模型处理图像的尺寸为224×224×3,蒙古文字元图像的尺寸仅为32×32×1,远小于VGG-16的输入图像尺寸。VGG-16网络隐层较多,参数量大,在训练时会消耗较多计算资源,而蒙古文字元的分类无需复杂的隐层,反而复杂隐层可能造成运算空间浪费和出现过拟合。
本文提出基于VGG-16的改进模型,改进的VGG-Net模型结构如图2所示。改进的VGG-Net层级结构主要由数据输入层、卷积层、激活层、池化层和全连接层构成。改进的VGG-Net是将蒙古文字元图像进到2层的卷积层和最大池化层,再进到3层的卷积层和最大池化层,最后送入两层全连接。

图2 改进的VGG-Net网络结构示意图Fig.2 Improved VGG-Net network structure diagram
数据输入层主要是对蒙古文字元数据进行归一化和灰度化的预处理操作。卷积层用于提取蒙古文字元特征信息,核心参数包括卷积核(感受野)的尺寸大小、步长和填充,三者决定了输出特征图的尺寸大小。卷积核尺寸大小可以指定为小于输入图像尺寸的任意数值,本文将延续VGG-16网络的卷积核尺寸标准,使用的卷积核尺寸大小为3×3、步长为1、填充的属性是“same”。激活层是将卷积层的输出进行非线性的映射计算,本文统一采用Relu激活函数,并在Relu激活函数后衔接BN正则化层。池化层可以有效地缩小特征矩阵减少参数,降低过拟合的风险。本文采用最大池化,尺寸为2×2,步长为2。例如,在蒙古文字元的32×32×64特征图进过第一层最大池化层处理数据压缩为16×16×64。全连接两层,第一层共有128个神经元,第二层23个神经元。
改进的VGG-Net与VGG-16的区别在于将VGG-16的13层卷积层缩减为5层,最大池化层的5层减少至2层,全连接层由3层变为2层,改进的VGG-Net网络各层参数如表1所示。改进的VGG-Net网络节省了运算空间,提高了运算速度,并大幅度提升了识别率,更适用于蒙古文字元识别任务。
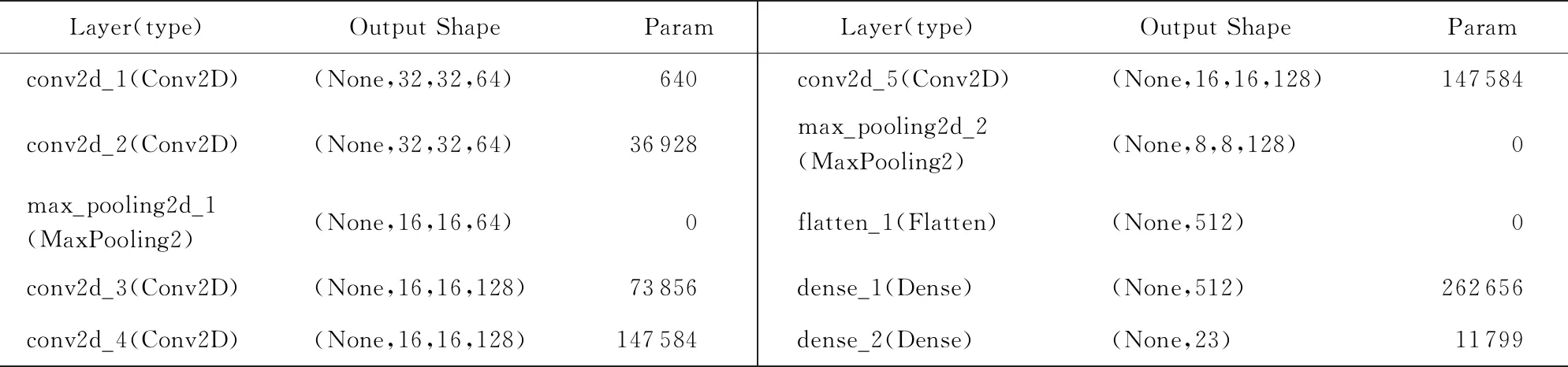
表1 网络模型各层参数示意表Tab.1 Schematic table of parameters of each layer of the network model
3 实验设计
本文的实验环境: 操作系统处理器为Intel(R) Core(TM) i7-8750HCPU@2.20GHz,内存为8GB,编程语言为python 2.7,使用的深度学习框架为Keras 2.2.4。
开展食葵机械化收获技术研究,有助于进一步提升食用向日葵的机械化收获水平,减轻了农民的体力劳动,将更多地劳动力从土地中解放出来,创造更多地经济价值[2]。
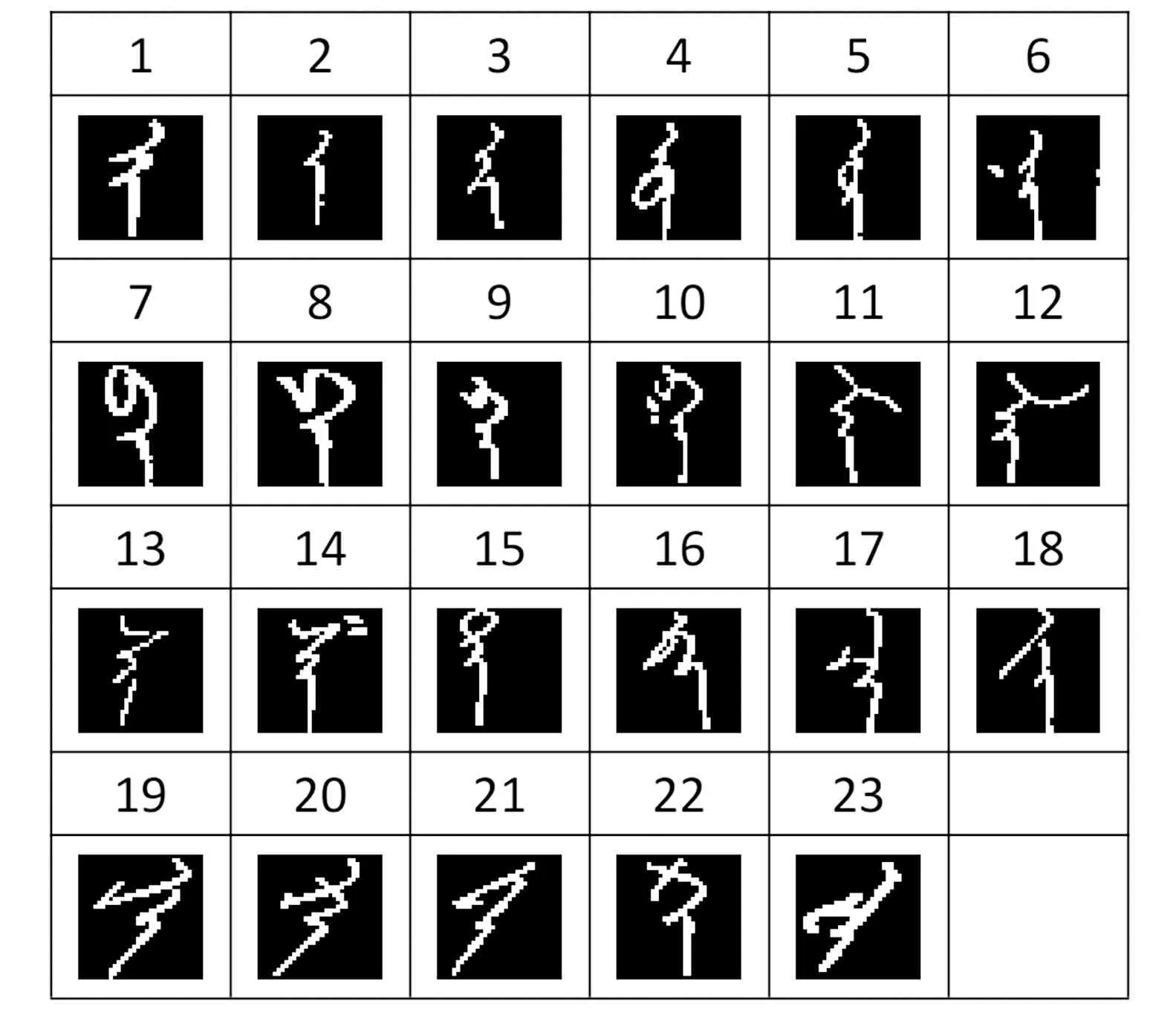
表2 手写蒙古文字元数据集
初始数据集为RGB蒙古文字元手写体图像,如表2所示,由内蒙古师范大学计算机科学技术学院采集。初始数据集中包含6 670张图像,每张图像包含一个蒙古文字元样本。蒙古文字元表中共包含23个字元,其中5个表示元音,18个表示辅音。
初始数据集图像进行预处理,处理后为32×32×1的灰度图像。6 670张图像以28∶1的比例分为训练集与测试集,训练集每类图像280张,共6 440张; 测试集每类图像10张,共230张。
图片预处理: 将图片压缩成与mnist数据集格式相同的数据集。首先生成测试集标签test-labels,将第1至第4个字节存放文件头魔数(magic number); 第5至第8个字节存放蒙古文字元图像数据的标签个数,即230; 第9字节开始每个字节存储一个图片的标签信息,即数字0-23中的一个。其次生成测试集test-images,第1至第4个字节存放文件头魔数; 第5至第8个字节存放蒙古文字元图像数据个数,即230; 第9至第16个字节存放蒙古文字元图像数据的宽度和高度,即32; 从第17个字节开始,每个字节存放一个像素值,每32×32个字节大小存放一幅图像数据。以相同的方法,生成训练集的标签(train-labels)和训练集数据(train-images)。
4 实验结果与分析
本文以实验的损失值、识别准确率和F1值作为评价指标,探究迭代次数和学习率对蒙古文字元识别准确率的影响,改进的VGG-Net由正态分布随机初始化开始训练,采用随机梯度下降的方法来优化网络。
损失值是通过学习得出的分类特征值与真实样本的特征值之间做多分类交叉熵函数计算得出,损失值越小表示模型分类能力越强,检验结果越准确。对于样本点(x,y)来说,y是真实标签。在多分类问题中,其取值只可能为标签集合labels。有K个标签值(K为23),且第i个样本预测为第k个标签值的概率为pi,k。有N个样本,损失函数如下:
(1)
准确率(Accuracy)是最为直观的评价指标之一,可通过分类正确的样本数与所有样本数的比值计算得出:
(2)
精确率(Precision)衡量真正样本占被预测为正样本的比例:
(3)
召回率(Recall)衡量真正样本占所有实际为正样本的比例:
(4)
F1值需综合考虑精确率和召回率:
(5)
其中:Tp(true positive)表示真正例,预测为正、实际也为正;Fp(false positive)表示假正例,预测为正、实际为负;Fn(false negative)表示假反例,预测为负、实际为正;Tn(true negative)表示真反例,预测为负、实际也为负。
4.1 迭代次数对蒙古文字元识别的影响
本次实验选取6 440张32×32的蒙古文字元图片作为训练数据集和230张蒙古文字元图片作为测试数据集,学习率设置为0.01。迭代次数初始值设置10次、步长设置为10,设计九组实验分析不同迭代次数对蒙古文字元识别性能产生的影响。实验结果如图3所示。

图3 随迭代次数变化实验结果汇总图Fig.3 Summary of experimental results with the number of iterations
从图3中得出,训练集和测试集都随着迭代次数的增多,准确率提升到最大值95.94%,饱和之后开始下降,损失值和F1值同样增加到最大值然后下降。与迭代10次的结果相比,迭代40次的测试准确率由90.26%提升为95.94%,损失值由0.351 4降至0.216 1,F1值也由0.889 1提升至0.956 8。从实验中可以得出: 选择40次迭代次数最为合适,蒙古文字元识别的准确率和F1值最高,损失值最低。
4.2 学习率对蒙古文字元识别的影响
本实验选取6 440张32×32的蒙古文字元图片作为训练数据集和230张蒙古文字元图片作为测试数据集,迭代次数设置40。改变学习率,分别设置0.1、0.05、0.01、0.005、0.001共五组实验,实验得到的损失值、准确率和F1值如图4所示。

图4 随学习率变化实验结果汇总意图Fig.4 Summary of experimental results with learning rate changes
从图4中得出,训练集和测试集都随着学习率的减小,准确率提升到最大饱和值后下降,损失值和F1值的变化相同。与学习率为0.1时相比,0.01时准确率由93.34%提高到峰值的95.94%,损失值为由0.969 8降至0.216 1,F1值也由0.921 2提高到0.956 8。当学习率降低为0.001时,准确率为91.07%,损失值为0.257 8,F1值为0.908 7。本次实验表明学习率取0.01最为合适。
4.3 不同模型对蒙古文字元识别的对比试验
基于上述实验结果,选取6 440张32×32的蒙古文字元图片作为训练数据集和230张蒙古文字元图片作为测试数据集,学习率设置为0.01,迭代次数设置40次,同时使用标准的VGG-16模型与改进的VGG-Net 模型进行蒙古文字元识别。实验得到的损失值、准确率实验耗时和F1值如表3所示。

表3 不同模型的实验数据汇总Tab.3 Summary of experimental data of different models
从表3可知,在蒙古文字元手写数据集中,VGG-16模型经过40次学习,准确率为90.58%,损失值为1.819 3,F1值为0.902 9,耗时1.616 2 h,而改进的VGG-Net模型经过40次学习,准确率为95.94%高于标准VGG-16模型,F1值为0.956 8大于VGG-16模型的0.902 9,损失为0.378 3也小于VGG-16模型的1.819 3,且只需要0.530 3 h就可以完成训练。本次对比试验表明本文提出的改进的VGG-Net模型在手写蒙古文字元数据集上识别效果远优于标准的VGG-16卷积神经网络。
5 结语
本文针对蒙古文字元识别的具体问题改进VGG-Net并应用于手写蒙古文字元识别,设计了由VGG-16模型的改进的VGG-Net网络模型用于手写蒙古文字元的识别,实验结果表明在学习率为0.01、迭代40次、以7 440张蒙古文字元图像作为训练样本的条件下,训练得到改进的VGG-Net模型对230张字元图像进行检测,能得到96.83%的准确率,F1值为0.961 2,证明了使用改进的VGG-Net对手写蒙古文字元的识别分类效果良好。
与VGG-16模型相对比,本文的网络模型在减少参数的同时提升了识别准确率,蒙古文字元识别训练更快、消耗运算空间更少、更加灵活,而且便于应用到其他配置较低的设备,从而使得应用范围更加广阔。
手写蒙古文数据集较小可能是导致网络模型效果无法进一步提升的主要原因,后续将从数据增强的方面深入研究,进一步提高蒙古文字元的识别效果。
